Biên tập viên lưu ý: Nhiều người khi sử dụng Claude Code có cảm nhận trực quan nhất là Token tiêu hao quá nhanh, các phiên dài rất dễ hết hạn mức. Nhưng từ góc nhìn của các kỹ sư Anthropic, thứ thực sự ảnh hưởng đến chi phí, thường không phải là bạn đã viết bao nhiêu mã, mà là hệ thống có liên tục tái sử dụng ngữ cảnh đã xử lý hay không.
Điểm cốt lõi được chia sẻ trong bài viết này, chính là cách tiết kiệm Token thông qua cơ chế caching. Tác giả đã tái sử dụng hơn 300 triệu Token thông qua caching trong một tuần, lượng cache trong một ngày đạt 91 triệu. Do chi phí của Token cache chỉ bằng 10% so với Token đầu vào thông thường, điều này có nghĩa là 91 triệu Token cache thực tế tính phí tương đương với khoảng 9 triệu Token thông thường. Lý do các phiên dài của Claude Code có vẻ "bền" hơn, không phải vì mô hình làm việc miễn phí, mà là do một lượng lớn ngữ cảnh lặp lại đã được tái sử dụng thành công.
Chìa khóa của Prompt caching nằm ở việc "không làm gián đoạn cache". Claude Code sẽ lưu cache theo tầng cho prompt hệ thống, định nghĩa công cụ, CLAUDE.md, quy tắc dự án và lịch sử hội thoại; chỉ cần tiền tố của yêu cầu tiếp theo giữ nguyên, Claude có thể đọc trực tiếp từ cache, thay vì xử lý lại toàn bộ ngữ cảnh. Anthropic nội bộ cũng sẽ giám sát tỷ lệ tái sử dụng prompt cache, bởi vì nó không chỉ ảnh hưởng đến hạn mức người dùng, mà còn liên quan trực tiếp đến chi phí dịch vụ mô hình và hiệu quả vận hành.
Đối với người dùng thông thường, không cần phải hiểu tất cả các chi tiết nền tảng, chỉ cần nắm vững một vài thói quen quan trọng: không để phiên rảnh rỗi quá 1 giờ; khi chuyển đổi nhiệm vụ, hãy thực hiện tốt việc bàn giao phiên (session handoff); tránh chuyển đổi mô hình quá thường xuyên; các tài liệu lớn nên đưa vào Projects, thay vì dán đi dán lại vào cuộc hội thoại.
Bài viết này, hơn là nói về một mẹo tiết kiệm Token, có thể nói là cung cấp một bộ phương pháp sử dụng Claude Code gần hơn với tư duy kỹ sư: coi ngữ cảnh như tài sản cần quản lý, để cache được tái sử dụng liên tục, để các phiên dài ít phải tính toán lặp lại.
Dưới đây là bản gốc:
Tuần này tôi đã tiết kiệm được 300 triệu Token, 91 triệu trong một ngày, hơn 300 triệu trong một tuần.
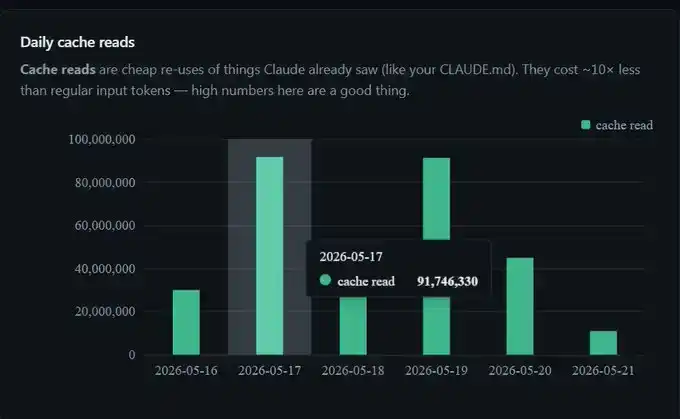
Tôi không thay đổi bất kỳ cài đặt nào. Đây chỉ là prompt caching đang hoạt động bình thường ở phía hậu trường.
Nhưng khi tôi thực sự hiểu cache là gì, và làm thế nào để tránh "làm gián đoạn" cache, dưới cùng một hạn mức sử dụng, các phiên của tôi có thể kéo dài hơn. Vì vậy, đây là hướng dẫn nhập môn 80/20 về prompt caching của Claude Code, không liên quan đến các chi tiết sâu ở cấp độ API.
TL;DR
Chi phí của Token cache chỉ bằng 10% so với Token đầu vào thông thường. 91 triệu Token cache, thực tế tính phí tương đương với khoảng 9 triệu Token.
TTL cache của phiên bản đăng ký Claude Code là 1 giờ; API mặc định là 5 phút; Sub-agent luôn là 5 phút.
Cache được chia thành ba tầng: tầng hệ thống, tầng dự án, tầng hội thoại.
Chuyển đổi mô hình giữa phiên sẽ phá hủy cache, bao gồm cả việc bật chế độ "opus plan".
Cache thực sự được tính tiền như thế nào?
Mỗi Token được cache, chi phí đều bằng 10% so với Token đầu vào thông thường.

Vì vậy, khi bảng điều khiển của tôi hiển thị một ngày nào đó có 91 triệu Token trúng cache, thực tế tính phí chỉ tương đương với việc xử lý khoảng 9 triệu Token. Đây cũng là lý do tại sao so với việc không có cache, khi sử dụng Claude Code trong thời gian dài, sẽ khiến người ta cảm thấy phiên hội thoại gần như được kéo dài "miễn phí".
Có hai con số trong bảng điều khiển đáng để chú ý:
Cache create: Chi phí một lần phát sinh khi ghi nội dung vào cache. Nó sẽ bắt đầu phát huy tác dụng trong lượt hội thoại tiếp theo.
Cache read: Token mà Claude tái sử dụng từ cache, chẳng hạn như CLAUDE.md, định nghĩa công cụ, tin nhắn trước đó của bạn, v.v. So với việc xử lý lại như đầu vào, chi phí rẻ hơn 10 lần.

Nếu con số Cache read của bạn cao, điều đó có nghĩa là bạn đang tận dụng cache hiệu quả; nếu con số này thấp, có nghĩa là bạn đang trả phí lặp lại cho cùng một loạt ngữ cảnh.
Thariq của Anthropic có một câu nói khiến tôi ấn tượng sâu sắc: "Chúng tôi thực sự sẽ giám sát tỷ lệ trúng cache của prompt, một khi tỷ lệ trúng quá thấp, sẽ kích hoạt cảnh báo, thậm chí tuyên bố sự cố cấp độ SEV."
Anh ấy cũng đã viết một bài X rất hay. Khi tỷ lệ trúng cache cao, bốn điều sẽ xảy ra đồng thời: Claude Code cảm giác nhanh hơn, chi phí dịch vụ của Anthropic giảm xuống, hạn mức đăng ký của bạn trở nên bền hơn, và các phiên lập trình dài cũng trở nên khả thi hơn.
Nhưng nếu tỷ lệ trúng thấp, mọi người đều sẽ chịu thiệt.

Vì vậy, động lực của cả hai bên thực ra là nhất quán: Anthropic muốn tỷ lệ trúng cache của bạn cao hơn, và bản thân bạn cũng muốn tỷ lệ trúng cao hơn. Thứ thực sự kéo chân lại, chỉ là một số thói quen nhỏ tưởng chừng không đáng kể, nhưng lại âm thầm đặt lại cache.
Cache tăng trưởng như thế nào trong mỗi lượt hội thoại?
Cache phụ thuộc vào prefix matching, tức là "khớp tiền tố".
Bạn không cần sa vào quá sâu các chi tiết kỹ thuật, chỉ cần hiểu một điểm: chỉ cần nội dung trước một vị trí nào đó hoàn toàn giống với nội dung đã được cache, Claude có thể tái sử dụng phần Token cache này.
Một phiên hội thoại hoàn toàn mới, về cơ bản sẽ diễn ra như sau:
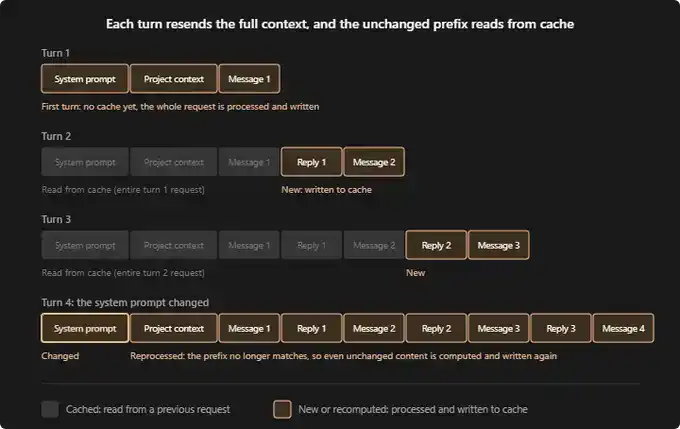
Theo tài liệu Claude Code, một phiên hoàn toàn mới thường chạy như thế này:
Lượt hội thoại thứ nhất: Chưa có bất kỳ cache nào. Prompt hệ thống, ngữ cảnh dự án của bạn (ví dụ: CLAUDE.md, memory, quy tắc), cũng như tin nhắn đầu tiên của bạn, tất cả đều sẽ được xử lý lại một lần và ghi vào cache.
Lượt hội thoại thứ hai: Tất cả nội dung trong lượt đầu tiên hiện đã được cache. Claude chỉ cần xử lý phản hồi mới của bạn và tin nhắn tiếp theo. Chi phí lượt này sẽ thấp hơn nhiều.
Lượt hội thoại thứ ba: Logic tương tự. Các cuộc hội thoại trước đó vẫn được giữ trong cache, chỉ có lượt tương tác mới nhất cần được xử lý lại.
Bản thân cache có thể được chia thành ba tầng:

Từ bài viết X của Thariq:
Tầng hệ thống (System layer): Bao gồm hướng dẫn cơ bản, định nghĩa công cụ (read, write, bash, grep, glob) và phong cách đầu ra. Tầng này được cache toàn cục.
Tầng dự án (Project layer): Bao gồm CLAUDE.md, memory, quy tắc dự án. Tầng này được cache theo dự án.
Tầng hội thoại (Conversation): Bao gồm phản hồi và tin nhắn, sẽ tăng liên tục theo mỗi lượt hội thoại.
Nếu giữa phiên hội thoại, bất kỳ nội dung nào của tầng hệ thống hoặc tầng dự án thay đổi, tất cả nội dung phải được cache lại từ đầu. Đây là thao tác "đắt" nhất. Hãy tưởng tượng: Bạn đã trò chuyện đến tin nhắn thứ 16, lúc này đột nhiên thay đổi prompt hệ thống, hoặc tạm dừng một giờ, thì tất cả Token từ tin nhắn thứ 1 trở đi đều phải được xử lý lại.
Sự nhầm lẫn giữa 1 giờ và 5 phút
Đây là điểm dễ gây hiểu lầm nhất.
Phiên bản đăng ký Claude Code: TTL mặc định là 1 giờ.
Claude API: TTL mặc định là 5 phút. Bạn có thể trả chi phí cao hơn để nâng nó lên 1 giờ.
Sub-agent dưới bất kỳ gói nào: Luôn là 5 phút.
Claude.ai trò chuyện trên web: Không có ghi chú chính thức rõ ràng. Có thể giống phiên bản đăng ký, nhưng tôi chưa xác nhận.
Vài tháng trước, nhiều người phàn nàn rằng hạn mức đăng ký Claude tiêu hao quá nhanh. Khi đó có người nghĩ rằng Anthropic đã lén giảm TTL từ 1 giờ xuống 5 phút, mà không thông báo cho người dùng. Nhưng thực tế không phải vậy, TTL của Claude Code vẫn là 1 giờ.
Vấn đề nằm ở chỗ, tài liệu của Claude Code và API được đặt riêng biệt, và bản thân hai thứ này vốn là những thứ hoàn toàn khác nhau, do đó gây ra không ít nhầm lẫn.
Nếu bạn đang chạy nhiều luồng công việc Sub-agent, hoặc sử dụng API trực tiếp, thì con số 5 phút này rất quan trọng. Nhưng đối với 95% người dùng Claude Code, thứ thực sự cần quan tâm, thực ra chỉ có cửa sổ 1 giờ đó.
Ba thói quen bao phủ 95% người dùng
Dưới đây là những phần tôi cảm thấy thực sự hữu ích trong sử dụng hàng ngày.
Đừng tạm dừng quá lâu
Nếu bạn đã rảnh rỗi hơn một giờ, nội dung trước đó về cơ bản đều đã hết hạn từ trong cache. Tin nhắn tiếp theo của bạn sẽ xây dựng lại cache. Trong trường hợp này, thay vì tiếp tục khôi phục một phiên cũ đã "nguội", việc thực hiện một lần bàn giao rõ ràng, sau đó mở một phiên mới, thường có chi phí thấp hơn.
Khi chuyển đổi nhiệm vụ, hãy bắt đầu lại trực tiếp
/compact hoặc /clear vốn dĩ sẽ phá hủy cache, vì vậy thay vì tiếp tục, hãy tận dụng thời điểm này để thực sự đặt lại một lần.
Tôi tự làm một kỹ năng session handoff, để thay thế cho /compact. Nó sẽ tổng kết những gì chúng ta đã hoàn thành, còn những quyết định nào đang chờ xử lý, những tệp nào quan trọng nhất, và tiếp theo nên tiếp tục từ đâu. Sau đó tôi thực hiện /clear, dán bản tóm tắt này vào, và có thể tiếp tục thúc đẩy như thể không có gì bị gián đoạn.
Lệnh compact đôi khi cũng chạy khá chậm. Còn kỹ năng handoff này thường hoàn thành trong chưa đầy một phút.
Trong cuộc trò chuyện Claude, tài liệu lớn hãy cố gắng đưa vào Projects
Cơ chế cache trên Claude.ai không có giải thích chính thức chi tiết, nhưng Projects rõ ràng được tối ưu hóa theo cách khác so với các chuỗi hội thoại thông thường. Vì vậy, nếu bạn muốn dán các tài liệu rất lớn, tốt nhất nên đưa chúng vào Project, thay vì nhét trực tiếp vào cuộc hội thoại.
Những thao tác nào sẽ âm thầm phá hủy cache?
Có vài việc sẽ đặt lại toàn bộ cache mà không có cảnh báo rõ ràng.
Chuyển đổi mô hình: Vì cache phụ thuộc vào khớp tiền tố, và mỗi mô hình có cache riêng của nó. Chỉ cần chuyển đổi mô hình, yêu cầu tiếp theo sẽ đọc lại toàn bộ lịch sử trong tình trạng không có lần trúng cache nào.
Chế độ "Opus plan": Cài đặt này sẽ sử dụng Opus trong giai đoạn lập kế hoạch và Sonnet trong giai đoạn thực thi. Trước đây tôi đã từng giới thiệu nó trong một số video tối ưu token, là có lý do. Nhưng cần hiểu rằng, mỗi lần chuyển đổi plan, về bản chất là một lần chuyển đổi mô hình, cũng có nghĩa là phải thiết lập lại cache. Về lâu dài, nó vẫn giúp kéo dài hạn mức phiên, nhưng bạn cần biết dưới nền tảng thực sự đang xảy ra điều gì.
Chỉnh sửa CLAUDE.md giữa phiên hội thoại là được: Sửa đổi này sẽ không có hiệu lực ngay lập tức, mà phải đợi lần khởi động lại tiếp theo mới được áp dụng. Do đó, cache đang chạy hiện tại sẽ không bị ảnh hưởng.
Bảng điều khiển Token miễn phí của tôi
Ảnh chụp màn hình tôi hiển thị trước đó, đến từ một bảng điều khiển token.
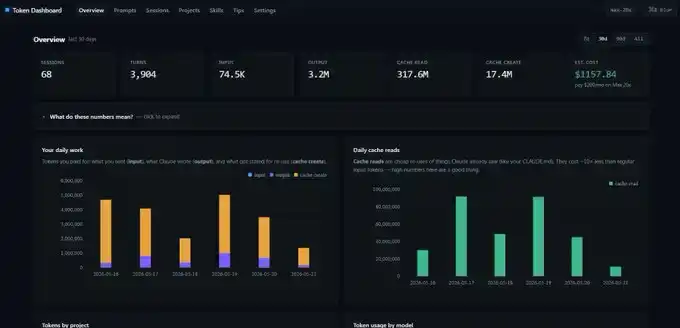
Đây là một kho lưu trữ GitHub rất đơn giản. Bạn đưa liên kết cho Claude Code, để nó triển khai trên localhost, nó sẽ đọc tất cả bản ghi phiên của bạn trong quá khứ, thay vì bắt đầu thống kê từ trạng thái trống. Bạn sẽ thấy ngay dữ liệu input, output, cache create và cache read hàng ngày.
Tuy nhiên có một điểm cần lưu ý: Bảng điều khiển này thống kê dữ liệu Token trên thiết bị cục bộ. Nếu bạn chuyển từ máy tính để bàn sang máy tính xách tay, các con số sẽ không hoàn toàn nhất quán. Mỗi thiết bị có một bộ chế độ xem thống kê riêng.
Tóm tắt
Prompt caching là một thứ có thể nghiên cứu rất sâu. Bài viết của Thariq nói đầy đủ hơn ở đây, nếu bạn muốn xem toàn cảnh, đáng để đọc.
Nhưng bạn không cần phải hiểu hoàn toàn tất cả chi tiết, mới có thể hưởng lợi từ nó. Bạn chỉ cần nắm vững 80/20 then chốt nhất: Token cache rẻ hơn 10 lần so với Token thông thường; TTL của Claude Code là 1 giờ; chuyển đổi mô hình sẽ phá hủy cache; việc thực hiện bàn giao rõ ràng giữa các nhiệm vụ, thường có lợi hơn so với việc để một phiên cũ "hết hạn" rồi lại cứng nhắc tiếp tục sử dụng.






