Keresi gửi từ Ốc Phi TựQbitAI | Công chúng hào QbitAI
DSpark vừa mới được mở nguồn một tuần, đã được chuyển sang máy tính Apple.
Phiên bản chuyển đổi có tên là mlx-dspark, chạy hai mô hình là Gemma-4 12B và Qwen3-4B.
Sau khi cài đặt, tốc độ tạo của hai mô hình này trên Mac lần lượt tăng 1.6 lần và 1.4 lần.
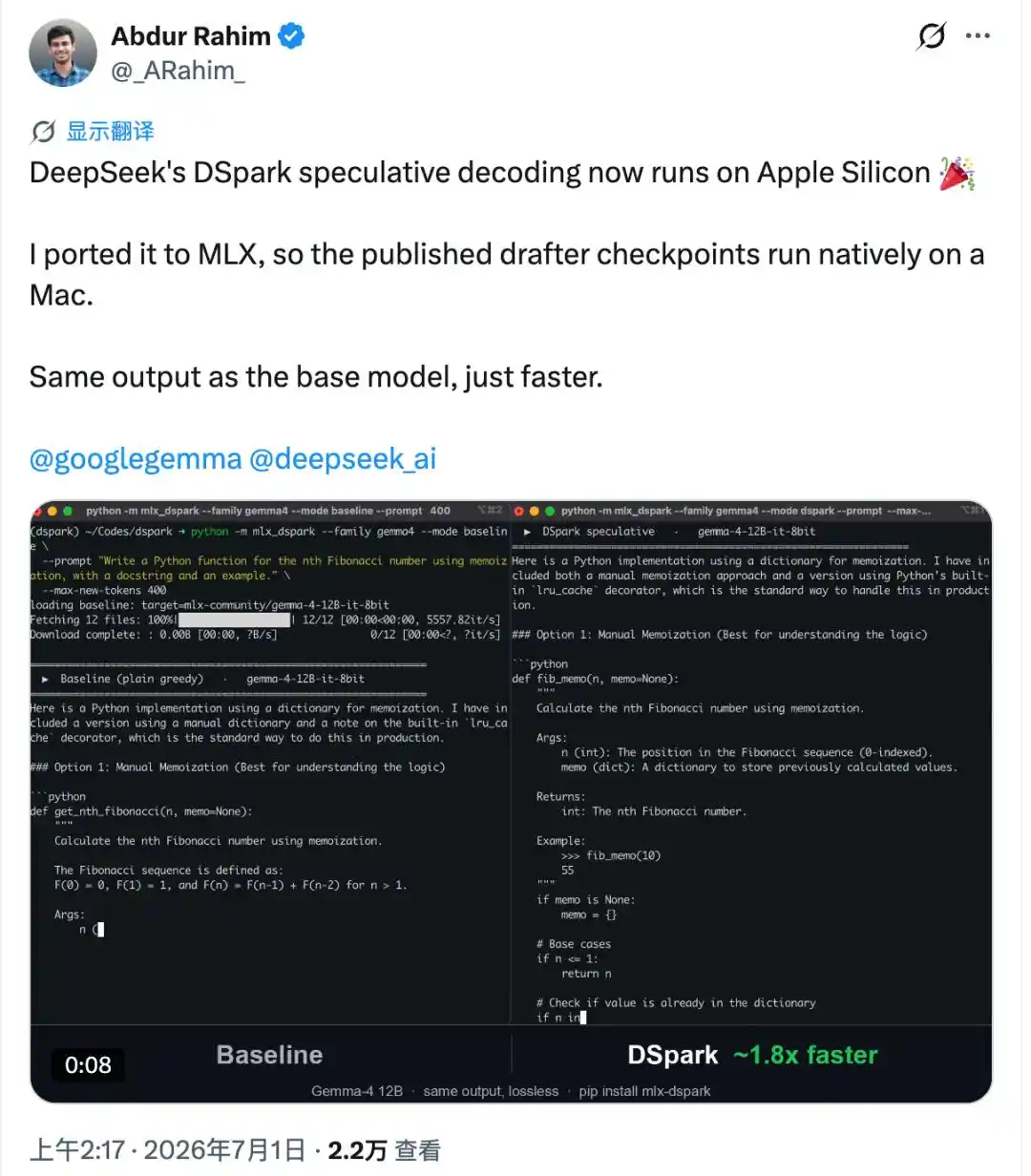
Khó hơn nữa, nó đã làm được một điều mà hầu hết các phiên bản chuyển đổi không làm được - đầu ra giống hệt từng byte so với mô hình gốc, không sai một chữ.
Tức là, tốc độ đã được cải thiện, chất lượng không hề giảm.
Người thực hiện là Abdur Rahim, một kỹ sư làm các dự án mã nguồn mở trong thời gian rảnh, phiên bản gốc Mac đầu tiên của DSpark kể từ khi được mở nguồn đều do một mình anh ta thực hiện.
Chạy mô hình lớn trên máy tính Apple, tăng tốc 60%
Đối với DSpark do DeepSeek mở nguồn vào ngày 27 tháng 6, số liệu chính thức cho thấy có thể tăng tốc từ 60% đến 85% trong kịch bản máy chủ.
Tuy nhiên, công nghệ này lúc đó chỉ có phiên bản triển khai cho GPU trong trung tâm dữ liệu, không có phiên bản tương thích cho chip Apple.
mlx-dspark là phiên bản gốc đầu tiên dành cho chip Apple của công nghệ này.

Tư tưởng của DSpark là bố trí một mô hình nhỏ hơn để hỗ trợ mô hình mục tiêu, mô hình nhỏ này trước tiên đưa ra một lúc vài từ ứng viên, sau đó mô hình mục tiêu kiểm tra một lượt, từ nào đúng thì nhận, từ nào sai thì trả lại để đoán lại.
Chi phí của bước này trên trung tâm dữ liệu và máy tính Apple là khác nhau.
Trên GPU của trung tâm dữ liệu, việc kiểm tra một loạt từ ứng viên giống như thuê xe cả chuyến, giá cố định dù có bao nhiêu người, quá trình giải mã vốn đã là nút cổ chai về bộ nhớ, kiểm tra thêm vài từ hầu như không tốn thêm thời gian.
Chip Apple giống như taxi tính theo đồng hồ, càng kiểm tra nhiều từ ứng viên thì đồng hồ càng nhảy nhanh.
Rahim đã thực tế kiểm tra, Gemma-4 12B mỗi khi kiểm tra thêm một token, phải mất thêm khoảng 14 mili giây. Anh ta đã tính toán chi phí này thành một mô hình chi phí, kết luận rằng, giới hạn tốc độ trên chip Apple là khoảng 2.2 lần.
Tóm lại, Rahim đã chuyển mô hình nhỏ hỗ trợ này từ checkpoint của HuggingFace, lần lượt bố trí cho hai mô hình mục tiêu Gemma-4 12B và Qwen3-4B sử dụng.
Anh ta còn xây dựng lại quy trình kiểm tra trong khung MLX, lượng tử hóa trọng số thành 4-bit.

Kết quả là, trên M4 Pro, so với công cụ MLX chính thức của Apple, tốc độ tạo của Gemma-4 12B tăng từ 18.4tok/s lên khoảng 30tok/s, gấp khoảng 1.6 lần; Qwen3-4B tăng từ 52.9tok/s lên khoảng 73tok/s, gấp khoảng 1.4 lần.
Ngoài ra, trong mlx-dspark, Rahim còn làm một việc mà hầu hết các công việc chuyển đổi không làm.
Phiên bản chuyển đổi cũng có thể phục hồi độ chính xác cao
Hầu hết các phiên bản chuyển mô hình lớn về chạy cục bộ chỉ hỗ trợ giải mã tham lam, tức là mỗi bước đều chọn từ có xác suất cao nhất.
Rahim trong mlx-dspark đã triển khai phương pháp lấy mẫu nhiệt độ được mô tả trong bài báo DSpark gốc, mô hình nháp đưa ra từ ứng viên, xác suất chấp nhận là min(1, p/q), phần không vượt qua được lấy mẫu lại từ phần dư.
Anh ta tự mình kiểm tra, đầu ra chạy qua quy trình này bằng chính xác với phân bố mà mô hình mục tiêu sẽ đưa ra ở cùng nhiệt độ, không phải là phiên bản xấp xỉ giảm chất lượng.
Hầu hết các phương pháp giải mã đầu cơ chỉ làm phiên bản tham lam, vì việc kiểm tra tính chính xác của chế độ tham lam rất đơn giản, chỉ cần so sánh từng chữ.
Bước Rahim làm thêm là tự mình kiểm tra lại phân bố đầu ra chạy ở chế độ lấy mẫu, xác nhận không bị biến dạng.
Mô hình mục tiêu chịu trách nhiệm kiểm tra nên sử dụng độ chính xác nào, là một lỗi anh ta tự mình thử nghiệm ra.
Nếu mô hình nhỏ được bố trí với mô hình mục tiêu cơ bản chưa qua tinh chỉnh hướng dẫn, từ ứng viên đưa ra chỉ có 47% vượt qua kiểm tra; đổi sang phiên bản tinh chỉnh hướng dẫn tương ứng, tỷ lệ này tăng lên 82%.
Anh ta cũng đã thử đổi mô hình mục tiêu sang độ chính xác bf16, chi phí kiểm tra tăng nhiều hơn so với tỷ lệ vượt qua, trái lại còn chậm hơn, vì vậy để mô hình mục tiêu mặc định ở 8-bit là có lợi nhất.
Mô hình nhỏ chịu trách nhiệm chạy trước đưa ra từ ứng viên, sử dụng một độ chính xác khác.
Bản thân mô hình nháp đã được anh ta nén, sau khi lượng tử hóa 4-bit chỉ còn 1.8GB, cài vào bộ nhớ hoàn toàn không có áp lực, chạy vẫn không mất dữ liệu.
Kết quả là, DSpark không chỉ thực hiện tăng tốc, mà còn thực sự tái hiện được mức tăng tỷ lệ chấp nhận từ 16% đến 18% được đề cập trong bài báo, trên thiết bị đầu cuối.
DFlash cũng được kết nối, nhiệm vụ mã nguồn nhanh hơn
Sau khi bài tweet được đăng, phần bình luận có một bình luận, một trong những tác giả của bài báo DFlash Jian Chen hỏi, có thể thử mô hình của nhóm họ không.
DFlash là một phương án giải mã đầu cơ khác được đề xuất trong bài báo do z-lab công bố vào tháng 5 năm nay, trưởng nhóm tác giả Zhijian Liu, trợ lý giáo sư UCSD, đồng thời là nhà khoa học nghiên cứu của NVIDIA.
Tư tưởng của DFlash không giống với DSpark, nó sử dụng một lần "khuyếch tán khối" song song để khử nhiễu cả một khối 16 token, chứ không phải như DSpark từng bước đoán với quan hệ phụ thuộc.
Rahim nhanh chóng hành động.
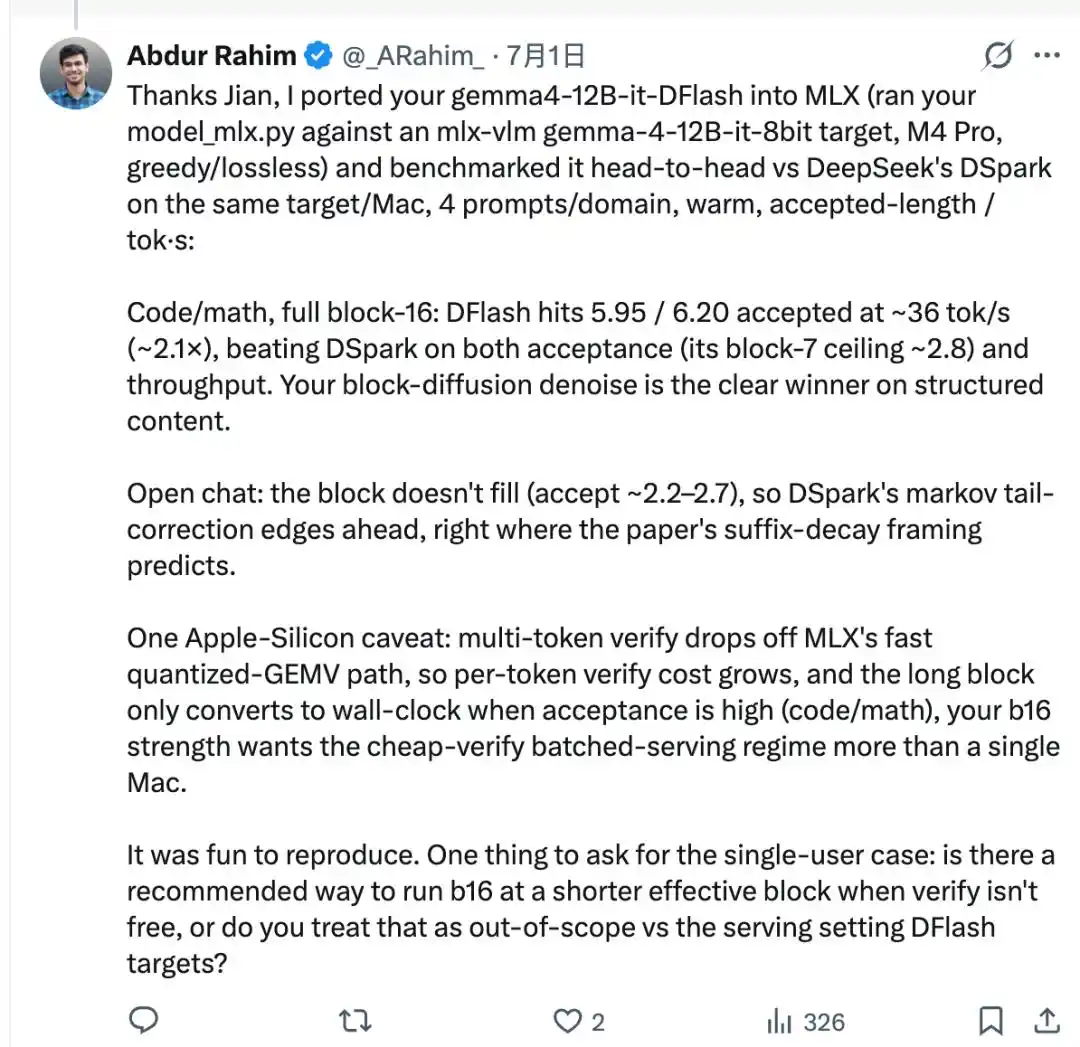
Anh ta sử dụng kịch bản chuyển đổi do Jian tự viết, kết nối gemma4-12B-it-DFlash do z-lab phát hành với mô hình mục tiêu Gemma-4 của mlx-vlm, trên cùng một máy Mac, chạy một vòng so sánh trực tiếp với DSpark mà anh ta vừa kiểm tra xong.
Trong nhiệm vụ mã nguồn và toán học, độ dài chấp nhận của DFlash giải mã cả khối có thể đạt 5.95 đến 6.20, tốc độ khoảng 36tok/s, đạt khoảng 2.1 lần, vượt qua DSpark.
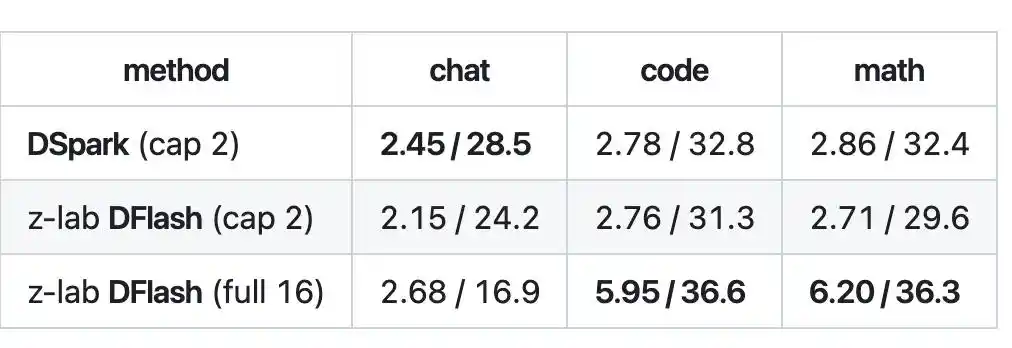
Tuy nhiên, DFlash một lần phải đưa ra cả một khối 16 token, nhưng mô hình mục tiêu chưa chắc đã công nhận toàn bộ, thực tế chỉ một phần trong đó vượt qua kiểm tra, trong ngành gọi đây là "độ dài chấp nhận", không phải lúc nào cũng có thể lấp đầy cả 16.
Vì vậy, trong các tình huống trò chuyện mở nội dung khó dự đoán, độ dài chấp nhận không tăng lên, khối không được lấp đầy, ưu thế của DFlash không phát huy được.
Markov head của DSpark chính là để đối phó với cùng một vấn đề này, song song đưa ra cả một khối từ, càng về sau các vị trí được tính toán độc lập, dễ không phù hợp với nhau, Markov head thêm một lớp quan hệ phụ thuộc giữa các vị trí này, chuyên sửa chữa vấn đề này.
Kết quả là, trong tình huống trò chuyện, DSpark trái lại nhanh hơn DFlash.
Và sau đó, mlx-dspark v0.0.3 được cập nhật, chính thức kết nối DFlash gốc của z-lab vào gói, còn thêm một tham số, có thể điều chỉnh thủ công độ dài khối hiệu quả của DFlash ngắn hơn, tình huống trò chuyện sử dụng khối ngắn, tình huống mã nguồn và toán học vẫn sử dụng khối đầy 16.
Sau đó, cùng một máy Mac, cùng một gói, có thể đồng thời hoàn thành nhiệm vụ trò chuyện và mã nguồn, toán học, không cần phải di chuyển qua lại giữa hai dự án DSpark và DFlash nữa.
Rahim nói trong bài tweet, phương pháp tương tự, sử dụng trên mô hình nháp Qwen3-8B và 14B lớn hơn cũng có thể chạy thông.
Tài liệu tham khảo:[1]https://x.com/_ARahim_/status/2072021710602432577[2]https://github.com/ARahim3/mlx-dspark
Bài viết này từ công chúng hào "QbitAI", tác giả: Quan tâm khoa học công nghệ tiên phong






