AI ngày càng giống người, khiến con người bắt đầu buộc phải chứng minh mình không phải là AI.
Chỉ trong tháng này, giới văn học đã xảy ra hai sự việc.
Một, là một tác phẩm đoạt giải của Giải Truyện ngắn Khối Thịnh vượng chung, bị một công cụ kiểm tra AI của bên thứ ba đánh giá là “100% do AI tạo ra”. Ban tổ chức dùng Claude kiểm tra lại, nhưng không nhận được kết quả tương tự.
Sự việc khác, là tiểu thuyết mới của một tác giả đoạt giải Nobel Văn học chưa ra mắt, đã bị nghi ngờ là do AI viết.
AI ngày càng mạnh, văn bản, hình ảnh và video ngày càng khó phân biệt bằng mắt thường. Nhưng đồng thời, công cụ đánh giá trong tay con người lại không đáng tin cậy như vậy.
Và thế là, một trật tự mới xuất hiện.
Người đoạt giải văn học phải giải thích tác phẩm của mình, nhà văn Nobel phải giải thích cách sáng tác, họa sĩ phải ghi màn hình, mở livestream, trình diễn các layer, blogger bình thường cũng có thể bị bình luận nghi ngờ “có mùi AI quá nặng”.
Trước đây là máy móc nỗ lực vượt qua bài kiểm tra Turing, chứng minh mình giống người.
Giờ đây, ngày càng nhiều người bắt đầu tham gia một bài kiểm tra Turing đảo ngược: chứng minh mình không phải là máy.
01
Người đoạt giải Nobel Văn học cũng không thoát khỏi việc ‘giám định AI’
Tháng 5 năm nay, một tác phẩm đoạt giải của Giải Truyện ngắn Khối Thịnh vượng chung, đã gây ra một cuộc tranh cãi lớn về “giám định AI”.
Gây tranh cãi là truyện ngắn của nhà văn Trinidad và Tobago Jamir Nazir.
Tác phẩm này đã đoạt giải khu vực Caribbean của Giải Truyện ngắn Khối Thịnh vượng chung 2026, và được đăng trên tạp chí văn học Granta. Chẳng mấy chốc, độc giả và giới chuyên môn bắt đầu nghi ngờ, ngôn ngữ trong truyện ngắn này có dấu vết AI rõ rệt: phép ẩn dụ hỗn tạp, câu văn chỉnh tề, tu từ giống như được tạo ra hàng loạt.

Sau đó, công cụ phát hiện AI Pangram đưa ra một phán đoán trông có vẻ rất chắc chắn: 100% do AI tạo ra.
Con số 100% trông như một bằng chứng sắt đá, nhưng nó không lập tức trở thành phán quyết.
Quỹ Thịnh vượng chung cho biết, tất cả tác giả lọt vào vòng chung kết đều xác nhận không sử dụng AI hỗ trợ; Granta cũng không thể chỉ dựa vào một kết quả kiểm tra mà kết luận tác giả vi phạm.

Thế là, sự việc bước vào một giai đoạn cực kỳ lố bịch. Tạp chí Granta thử dùng Claude kiểm tra lại truyện ngắn này, muốn để một AI khác phán xem nó có phải do AI viết hay không.
Kết quả, Claude không đưa ra được câu trả lời có thể kết luận chắc chắn, tức là, tác phẩm mà Pangram khẳng định là “100% do AI tạo ra”, Claude lại cho biết không xác định được.
Người đoạt giải Nobel Văn học Olga Tokarczuk gần đây cũng vướng vào tranh cãi.
Nguyên nhân sự việc, là bà trong một cuộc phỏng vấn có nói, mình sẽ dùng AI hỗ trợ phác thảo ý tưởng, sắp xếp tài liệu, nghiên cứu sơ bộ và kiểm tra sự thật.

Cách nói này nhanh chóng gây ra thảo luận bên ngoài. Vấn đề là Tokarczuk sắp ra sách mới, vì vậy mọi người đều bàn tán xem tiểu thuyết mới của bà có phải do AI viết không.
Sau đó, Tokarczuk buộc phải công khai làm rõ, cuốn sách mới bằng tiếng Ba Lan của bà dự kiến xuất bản vào mùa thu 2026, không phải do AI hay người khác viết hộ. Bà nhấn mạnh, hàng chục năm nay, bà luôn viết một mình.
Suy cho cùng, giờ AI thực sự ngày càng mạnh, việc giám định AI đang ngày càng trở nên khó khăn.
Cuối năm ngoái, tờ The New Yorker đăng một bài viết thử nghiệm. Nhà nghiên cứu dùng tác phẩm của nhiều nhà văn để tinh chỉnh mô hình, để AI học và bắt chước phong cách cá nhân của họ.
Trong thí nghiệm, sinh viên chuyên viết sáng tạo đọc văn bản của người và văn bản AI trong tình trạng không biết trước, và đánh giá mình thích đoạn nào hơn. Kết quả, trong gần hai phần ba trường hợp, họ thích phiên bản do AI tạo ra hơn.
Điều này còn phiền phức hơn “AI có thể viết tiểu thuyết”.
Tác giả The New Yorker Vauhini Vara trong bài viết còn viết, bạn bè và độc giả chuyên nghiệp sẽ nhận nhầm câu do AI tạo ra là cách viết của chính bà, cũng sẽ phê bình đoạn văn bản bà thực sự viết ra là “giống AI”.
02
Họa sĩ quay video toàn bộ ‘tự chứng minh mình trong sạch’ khóc không ra nước mắt
“Hiệu ứng thung lũng kỳ lạ” tuyệt đối không chỉ giới hạn ở một thực thể giống người mà không giống, khi văn bản, hình ảnh và video AI đầu ra ngày càng tiệm cận con người, thậm chí đến cả “phong cách” đầy tính người nhất cũng bị chinh phục, con người không thể tránh khỏi bị kích thích khủng hoảng hiện sinh.
Đây là một động cơ cốt lõi của việc “giám định AI bằng miệng” đang thịnh hành hiện nay.
Nói cách khác, mọi người “giám định AI” là có thể hiểu được, đằng sau thực chất là một nỗi sợ hãi nào đó – đây là người sao? Đây là AI sao? Tôi lại là ai? Chúng ta là ai?
Nhưng có thể hiểu không có nghĩa là vĩ đại chính đại, việc “giám định AI” đang gây rắc rối cho người sáng tác ở các lĩnh vực khác nhau, khiến họ ngoài sáng tác còn phải tăng thêm chi phí “tự chứng minh mình trong sạch”.
Nói về tác động mà AI mang lại, giới hội họa không xa lạ. Chúng ta đã từng thảo luận về tác động của AI lên giới hội họa và sự phản đối AI của nhiều họa sĩ từ vài năm trước.
Tuy nhiên ở thời điểm hiện tại, rắc rối mà các họa sĩ đối mặt không chỉ là cần đề phòng AI luyện hóa thành quả của mình, mà còn là tác phẩm tự tay mình làm bị “giám định AI”.
Tìm kiếm “UP vẽ tranh tự chứng minh” trên nền tảng mạng xã hội, sẽ thấy nhiều trường hợp.
Có họa sĩ sau khi bị “giám định AI”, đã quay màn hình trình diễn tất cả các layer, để chứng minh tác phẩm xuất phát từ chính tay mình.
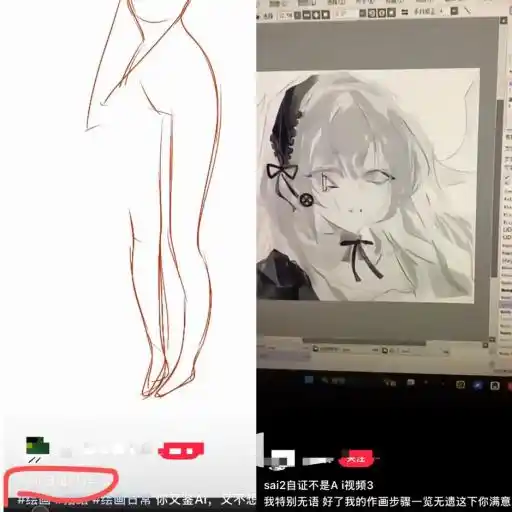
Nhưng nhiều khi, điều này vẫn chưa đủ.
Một người bạn họa sĩ minh họa cho biết, hiện nay nhiều họa sĩ minh họa sẽ quay màn hình toàn bộ quá trình vẽ tranh, đề phòng khi bị “giám định AI” khó tự chứng minh, đây cũng là cách làm ổn thỏa nhất hiện nay.
Nếu không quay màn hình, hoặc là có bằng chứng quay màn hình nhưng vẫn bị nghi ngờ là “in ra đồ lại”, thì còn có bước tiếp theo – cá cược.
Đúng vậy, giới hội họa vì AI đã phát triển ra việc cá cược giữa bên “giám định AI” và bên “bị giám định AI”. Trong một trường hợp chúng tôi thấy, người đăng bài đưa ra một số lý do như “tóc đứt liên kết”, “kết cấu vai cổ có vấn đề” v.v., giám định tác phẩm của một họa sĩ nào đó nghi ngờ là đặt ảnh AI bên dưới đồ lại hoặc theo ảnh AI lâm mô.
Hai bên cá cược 2000 tệ, cuối cùng họa sĩ “tự chứng minh thành công”, người đăng bài trả 2000 tệ cho họa sĩ AI.
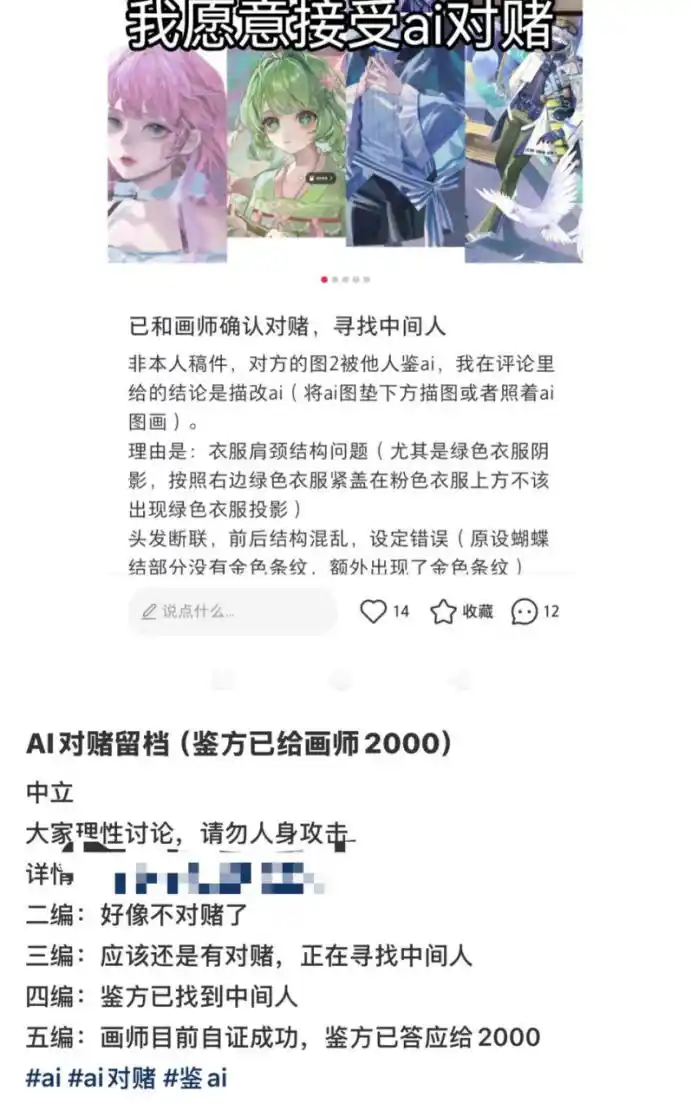
Nói chung, khâu “tự chứng minh” trong “cá cược”, là hai bên thống nhất thời gian tiến hành một buổi livestream vẽ tranh. Và livestream cần nhiều camera, ví dụ một camera trình diễn quá trình vẽ trên màn hình, một camera khác ghi hình họa sĩ vẽ tranh, để tránh có người “viết hộ”.
Từ nhiều bài đăng “tự chứng minh” của các họa sĩ không khó để thấy tâm trạng bất đắc dĩ, họ thường cảm thán “cuối cùng cũng đến lượt mình”, và thề “đây là lần đầu tiên và cũng là lần cuối cùng tự chứng minh”.
Cứ như vậy, một mặt ghét “giám định AI bằng miệng”, mặt khác khi thực sự đến lượt mình lại không thể không “tự chứng minh mình trong sạch”, thật khó chịu.
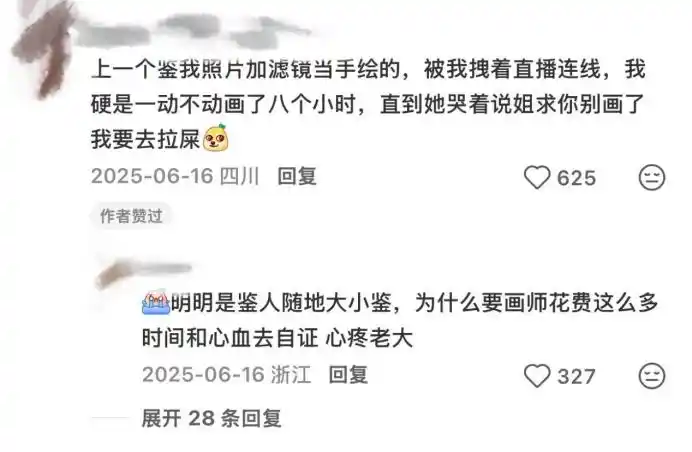
Có trường hợp “giám định AI” nhưng họa sĩ “tự chứng minh” thất bại không? Có. Nhưng điều này vẫn không thể khiến hành vi “giám định AI” trở nên chính nghĩa hơn. Xét cho cùng, chi phí “giám định AI”, hầu như không có.
Còn thủ đoạn “giám định AI”, càng thô sơ – dựa vào mắt người.
Ở đây không thể không nhắc đến một chuyện cười gần đây, một người dùng X đăng một bức ảnh, nói là ảnh “phong cách Monet” do mình dùng AI tạo ra, còn bảo mọi người “cố gắng chi tiết giải thích vì sao nó không bằng Monet thực sự”.

Bài đăng sau đó đạt 7 triệu lượt xem, bình luận nhiều người bắt đầu nghiêm túc “giám định AI”, nói nó thiếu chiều sâu, màu sắc không thống nhất, không có hơi người, bố cục không bằng tranh thật, thậm chí có người phân tích đầu đuôi từ nét bút và cảm giác không gian.

Kết quả đảo ngược là: bức ảnh đó vốn dĩ là tranh thật của Monet.
03
“Giám định AI” rốt cuộc ai có tiếng nói?
Vì vậy đây thực chất là mâu thuẫn giữa nỗi sợ AI ngày càng giống người, và không có biện pháp “giám định AI” hoàn hảo.
Thủ đoạn “giám định AI” thô sơ, là nhân tố quan trọng khác khiến người sáng tác tập thể rơi vào cảnh “tự chứng minh mình trong sạch”.
Ngoài phương thức “giám định bằng mắt người” ra, như tác phẩm đoạt giải vô địch cuộc thi văn học được nhắc đến ở trên, phương thức chính khác của “giám định AI” là công cụ phát hiện của bên thứ ba Pangram.
Công cụ phát hiện AI thường dùng trong lĩnh vực văn bản, dễ tạo ra một ảo giác: nó sẽ đưa ra một tỷ lệ phần trăm, ví dụ “80% do AI tạo ra”, “100% do AI tạo ra”. Con số này trông rất giống kết luận, thậm chí giống một loại giám định kỹ thuật nào đó.

Nhưng phát hiện văn bản và giám định DNA không phải là một chuyện. Cái nó phán đoán thực chất là “đoạn văn tự này trên đặc trưng thống kê giống cái gì hơn”.
Công cụ phát hiện AI, cũng là đang xem “trông có giống do AI viết không”.
Pangram trên trang web chính thức giải thích, bộ phát hiện AI của họ sẽ dùng công nghệ xử lý ngôn ngữ tự nhiên và lượng lớn dữ liệu viết của người, viết của AI, phân tích cấu trúc, phong cách và mô hình ngữ nghĩa trong văn bản AI. Báo cáo kỹ thuật của Pangram cũng cho biết, cốt lõi của nó là một bộ phân loại mạng nơ-ron dựa trên Transformer, mục tiêu huấn luyện chính là phân biệt văn bản do mô hình ngôn ngữ lớn viết ra và văn bản do con người viết ra.
Có nghĩa là, loại công cụ này không phải là cầm một bài văn đi tra “cơ sở dữ liệu văn bản AI”, xem nó có trúng vào mẫu đã biết nào không.
Nó giống như đang làm nhận dạng mẫu hơn. Lựa chọn từ vựng, nhịp điệu câu, sắp xếp cấu trúc, cách thức kết nối ngữ nghĩa của văn tự này, gần với văn bản của người nó từng thấy hơn, hay gần với văn bản AI nó từng thấy hơn.
Phiền phức hơn là, trong đó có quá nhiều trường hợp đặc biệt. Nếu một bài văn là người viết bản thảo đầu, rồi dùng AI trau chuốt vài câu, tính sao? Nếu là AI tạo đề cương, người viết lại thành toàn văn, tính sao? Nếu một đoạn tài liệu tiếng Anh được AI dịch sang tiếng Trung, tác giả sửa lại bằng tay, công cụ phát hiện còn có thể phán đoán không? Nếu một học sinh vốn là người viết không phải tiếng mẹ đẻ tiếng Anh, câu văn càng chỉnh tề, càng mẫu hóa, có phải càng dễ bị vạ lây hơn không?
Trong lĩnh vực hội họa cũng vậy. Có họa sĩ thống thiết – thực sự vẽ kết cấu có vấn đề, đó là vì kỹ nghệ của tôi còn cần rèn luyện, không phải vì đây là tranh AI đâu!
Năm 2023, nhà nghiên cứu Đại học Stanford thử nghiệm 7 bộ phát hiện văn bản AI.
Họ chọn 91 bài luận TOEFL của học sinh không phải tiếng mẹ đẻ tiếng Anh – những bài luận này đến từ kho ngữ liệu thi chính thức TOEFL, bản thân đã là học sinh viết tay hoàn thành trong môi trường thi thực tế, vì vậy có thể xác nhận không phải do AI tạo ra.
Kết quả trong đó 89 bài ít nhất bị một bộ phát hiện đánh dấu là do AI tạo ra; tỷ lệ báo động sai trung bình đạt 61.22%; còn 18 bài bị 7 bộ phát hiện nhất trí phán đoán là do AI tạo ra. Có nghĩa là, những học sinh này rõ ràng đang viết một ngoại ngữ, nhưng vì biểu đạt chỉnh tề hơn, gần mẫu hơn, bị công cụ coi là máy móc.
Tất nhiên, công cụ phát hiện năm 2023, 2024 không thể đơn giản tương đương với công cụ phát hiện ngày nay. Mấy năm qua, bộ phát hiện thương mại thực sự đã lặp lại, biểu hiện của một số công cụ mới trong thử nghiệm cụ thể đã được nâng cao rõ rệt.
Nhưng vấn đề không được giải quyết.
“Phán đoán sai” không được loại bỏ hoàn toàn, sẽ để lại kẽ hở cho mâu thuẫn.
Xét cho cùng, công cụ đưa ra vốn dĩ là xác suất, nhưng rơi vào người, thì biến thành cáo buộc.
04
Vậy còn “watermark” hứa hẹn thì sao?
Vấn đề lớn hơn nằm ở chỗ, công ty AI có nên làm “đánh dấu nguồn gốc” không?
Đánh “watermark” nguyên sinh lên tất cả nội dung AI – loại không thể xóa được, không phải là có thể giải quyết vấn đề giám định sao?
Nhiều người nghe đến “watermark”, nghĩ đến vẫn là logo ở góc ảnh, nhãn hiệu nền tảng trên màn hình video, hoặc mấy chữ “AI tạo ra”.
Nhưng watermark AI ngày nay sớm không chỉ là loại ký hiệu nhìn thấy bằng mắt này nữa.
Trong ngành đại khái có hai loại cách làm: một loại là siêu dữ liệu (metadata), ví dụ C2PA và Content Credentials, tương đương với đính kèm một “giải thích thân phận” cho nội dung số, ghi lại nó được tạo bởi công cụ gì, khi nào tạo ra, trải qua những chỉnh sửa nào;
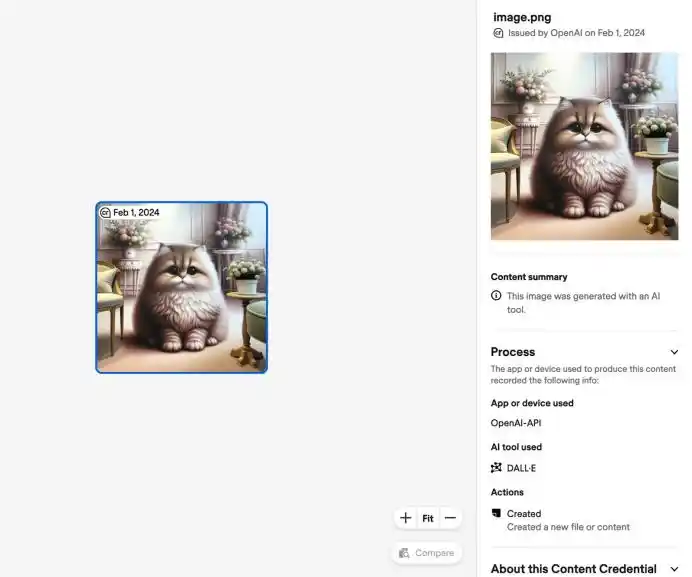
Loại khác là watermark vô hình, nhúng tín hiệu mắt người khó phát hiện nhưng máy móc có thể nhận biết vào hình ảnh, âm thanh, video thậm chí văn bản.
Trong lĩnh vực hình ảnh và video, những giải pháp này đã bắt đầu triển khai.
SynthID của Google DeepMind có thể nhúng watermark vô hình vào nội dung do các công cụ như Imagen, Veo, Lyria, Gemini tạo ra.
Meta cho biết, hình ảnh do Meta AI tạo ra hoặc chỉnh sửa sẽ thêm watermark nhìn thấy, watermark không nhìn thấy và siêu dữ liệu; OpenAI cũng cho hình ảnh do DALL·E 3 và ChatGPT tạo ra thêm chứng chỉ nội dung C2PA, và sau này giới thiệu watermark vô hình SynthID. Adobe, Microsoft, Google, Meta, OpenAI và các công ty khác cũng tham gia vào hệ sinh thái C2PA và chứng chỉ nội dung.

Điều này cho thấy, công ty AI cũng hiểu chỉ dựa vào mắt người phán đoán “có giống AI không” là không đủ. Họ đã thử dùng siêu dữ liệu, chứng chỉ nội dung, watermark vô hình và nhãn nền tảng, để lại tín hiệu nguồn gốc máy có thể đọc cho nội dung do AI tạo ra.
Nhưng những giải pháp này không hoàn hảo. Siêu dữ liệu có thể bị mất khi chụp màn hình, nén, chuyển tiếp, tải lên lại; watermark nhìn thấy có thể bị cắt bỏ hoặc che đi; watermark vô hình bền hơn, nhưng cũng có thể bị xử lý hậu kỳ, nhiễu loạn hoặc tạo lại làm suy yếu.
Quan trọng hơn, những giải pháp này thường chỉ có thể nhận biết nội dung đã tiếp cận hệ thống tương ứng, và giữ lại ký hiệu tương ứng. Có nghĩa là, SynthID của Google chủ yếu nhận biết nội dung có SynthID, chứng chỉ nội dung của OpenAI chủ yếu giải thích nội dung đến từ hệ thống OpenAI. Chỉ cần nội dung đến từ mô hình không tiếp cận đánh dấu, hoặc trải qua nhiều lần vận chuyển, chuỗi nguồn gốc có thể bị đứt.
Đến văn bản, vấn đề càng phức tạp.
Văn bản tất nhiên cũng có thể làm watermark. Nguyên lý của nó là khi mô hình tạo ra văn tự, lén thay đổi xác suất lựa chọn của một số từ, để văn bản cuối cùng thể hiện ra một mô hình thống kê mắt người đọc không ra nhưng bộ phát hiện có thể nhận biết. Nói đơn giản, là để AI để lại “dấu vân tay dùng từ” của mình.
Google đã công khai SynthID-Text, cho biết nó có thể nhúng watermark vào văn bản do Gemini tạo ra. OpenAI cũng sớm được kỳ vọng giải quyết vấn đề này. Tháng 7 năm 2023, OpenAI, Google, Meta, Amazon, Anthropic, Microsoft và các công ty khác đạt được cam kết tự nguyện, cho biết sẽ nghiên cứu cơ chế, giúp người dùng nhận biết nội dung do AI tạo ra, bao gồm watermark và đánh dấu nguồn gốc nội dung.
Nhưng mấy năm qua, giải pháp đánh dấu hình ảnh, âm thanh, video không ngừng thúc đẩy, văn bản vẫn chưa có một đáp án chung thông dụng, mặc định bật, công chúng có thể dùng rõ ràng.
OpenAI từng ra mắt AI Text Classifier vào năm 2023, dùng để phán đoán một đoạn văn tự có phải do AI tạo ra không, nhưng khi lên đã nhắc nhở người dùng không nên dùng nó làm căn cứ quyết định duy nhất.
Nửa năm sau, OpenAI vì tỷ lệ chính xác quá thấp mà gỡ xuống.
Năm 2024, tờ Wall Street Journal lại đưa tin, nội bộ OpenAI thực tế đã phát triển ra một công cụ watermark văn bản, trên văn bản do ChatGPT tạo ra đủ dài, hiệu quả có thể đạt 99.9%. Nhưng OpenAI cuối cùng không công bố nó.
Nguyên nhân cũng không hoàn toàn là vấn đề kỹ thuật. Bài báo đề cập, OpenAI lo ngại watermark văn bản gây phản ứng ngược từ người dùng, ảnh hưởng sử dụng sản phẩm, cũng lo ngại người dùng không phải tiếng Anh chịu sự kỳ thị thêm.
Còn điều tra cho thấy, gần 30% người dùng ChatGPT cho biết, nếu bật watermark văn bản, họ có thể giảm sử dụng.
Cuối cùng, quay lại sự kéo co giữa hai bên “giám định AI” và “tự chứng minh mình trong sạch”, tất cả giải pháp watermark được nhắc đến ở trên, vẫn chưa thể làm được vạn vô nhất thất.
Con người có một câu nói là “đạo cao một thước, ma cao một trượng”, còn có một câu nói là “trên có chính sách, dưới có đối sách”, chỉ cần con người còn tin hai câu này, “giám định AI” sẽ không dừng lại.
Có lẽ một ngày nào đó, “AI tham gia” trở thành trạng thái mặc định, “nguyên bản của người” trở nên cực kỳ hiếm có, cuộc kéo co “giám định AI” và “tự chứng minh mình trong sạch” quy mô lớn này mới mất đi ý nghĩa.
Bài viết này đến từ tài khoản công chúng WeChat “Đối diện AI” (ID: faceaibang), tác giả: Tiểu Cẩm Nha, biên tập: Vương Tĩnh






