Ngày 4 tháng 5 năm 2026, Jack Clark, đồng sáng lập Anthropic, đã đăng một bài viết trên nền tảng xã hội X. Nguyên văn là: "Tôi hiện tin rằng, xác suất Cải tiến Đệ quy Tự thân (Recursive Self-Improvement, RSI) xảy ra trước cuối năm 2028 là 60%."
Chỉ vài phút sau khi bài đăng được đăng lên, nhà nghiên cứu lâu năm trong lĩnh vực an toàn AI Eliezer Yudkowsky đã trả lời bên dưới: "Vậy thì chúng ta sẽ cùng diệt vong". Ông ngay lập tức dẫn ra một phép loại suy, ám chỉ lỗi thiết kế của lò phản ứng hạt nhân Chernobyl RBMK, ngụ ý rằng hệ thống đang được khởi động này không ai thực sự biết cách dừng lại.
Cuộc đối thoại diễn ra trong vòng vài chục giây này giống như một que diêm thắp sáng cuộc thảo luận vốn luôn bị giấu kín trong các bài báo khoa học kỹ thuật và đánh giá nội bộ trước đó. Cải tiến Đệ quy Tự thân (RSI), tức hệ thống AI không chỉ tối ưu hóa đầu ra mà còn có thể tự chủ tối ưu hóa chính quá trình cải tiến, cuối cùng xây dựng các hệ thống kế thừa mạnh hơn chính nó - một khái niệm từ lâu bị gạt ra rìa lý thuyết - đã được đồng sáng lập Anthropic đặt vào đồng hồ đếm ngược với xác suất 60% trước cuối năm 2028.
Một tháng sau, Anthropic chính thức công bố một bài viết dài. Tiêu đề là "Khi AI tự xây dựng chính mình" (When AI builds itself). Bài viết do Marina Favaro và Jack Clark cùng chấp bút, được công bố bởi Anthropic Institute vừa thành lập vào tháng 3. Với một chuỗi dữ liệu nội bộ chưa từng công khai trước đây và một cấu trúc tự sự được hiệu chỉnh tinh tế, Anthropic đã trao cho thế giới bên ngoài một tấm thẻ tín hiệu gia tốc với thang đo chính xác. Tấm thẻ này vừa ghi "Chúng tôi chưa đạt đến đó", lại vừa ghi "Nhưng nó có thể đến nhanh hơn hầu hết các tổ chức đang chuẩn bị".
Cùng tháng đó, CEO DeepMind Demis Hassabis trên sân khấu Google I/O đã sử dụng một cách diễn đạt chưa từng xuất hiện trước công chúng: Nhân loại đang đứng ở "chân núi của Điểm Kỳ dị (Singularity)". Trong cuộc phỏng vấn sau đó, ông đã điều chỉnh lộ trình cho Trí tuệ Nhân tạo Phổ quát (AGI) từ "không lâu sau năm 2030" thành "năm 2029 là một khả năng thực sự", và thừa nhận rằng việc sử dụng ngôn ngữ kịch tính là "cố ý khiêu khích", nhằm tạo ra cảm giác cấp bách đối với chính phủ, các nhà kinh tế và công chúng.
Hai tổ chức hàng đầu lấy an toàn làm nền tảng, lâu nay đóng vai trò lực lượng kiềm chế trong ngành AI, gần như cùng một lúc điều chỉnh âm lượng và thang đo đối với việc phát ngôn ra bên ngoài. Bản thân thời điểm này cần được xem xét như một sự kiện độc lập.
Một bài viết dài được hiệu chỉnh tinh vi
Bài viết dài được Anthropic công bố vào ngày 4 tháng 6 ngay từ đầu đã thể hiện mục tiêu tự sự của mình. Nó muốn chứng minh không chỉ là một xu hướng kỹ thuật, mà là một quá trình có hướng đi, có gia tốc. Để làm điều đó, họ trải ra một nhóm dữ liệu nội bộ chưa từng được công khai trước đây.
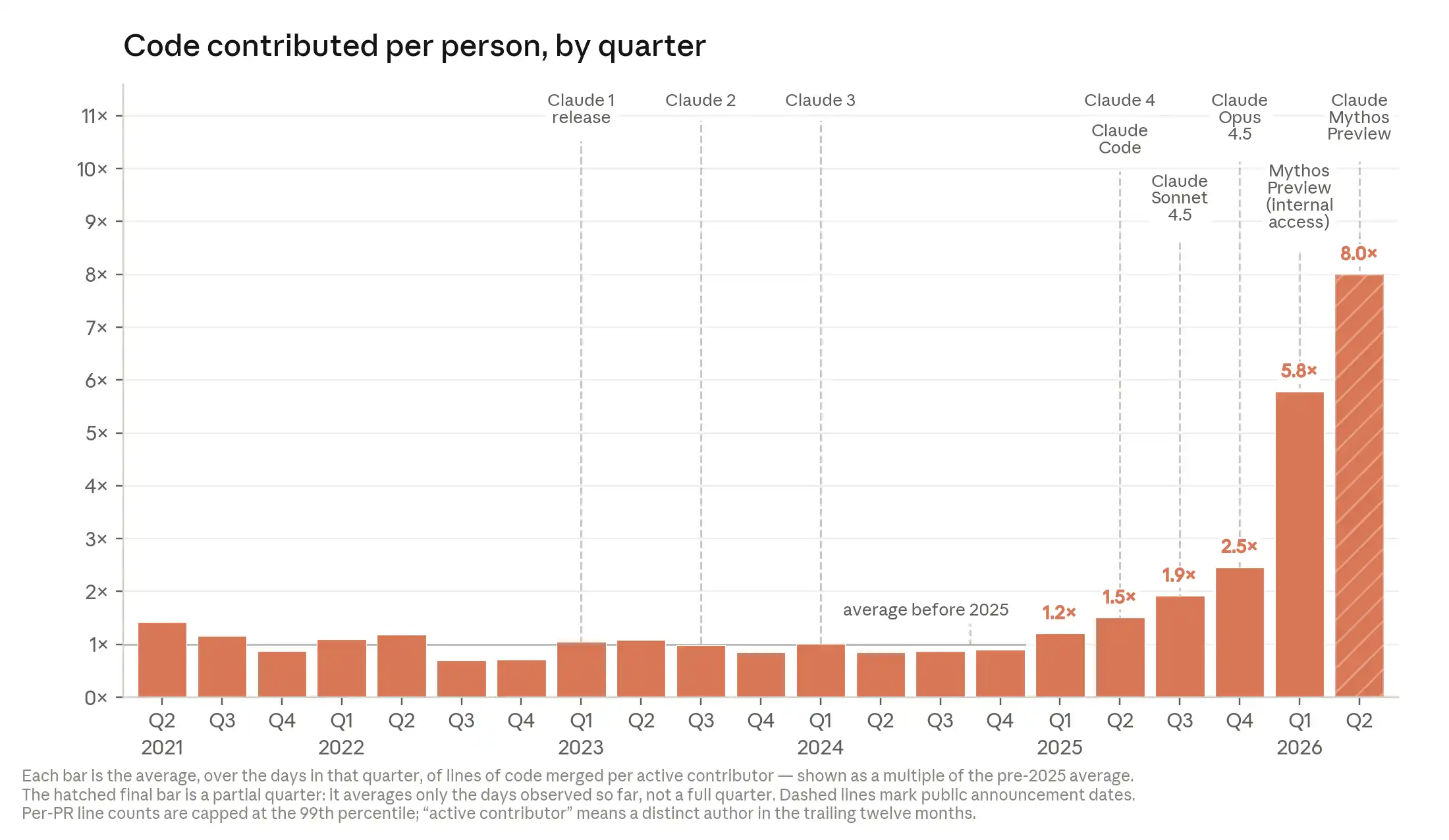
Nhóm số liệu đầu tiên chỉ ra một thay đổi cấu trúc: Tính đến tháng 5 năm 2026, hơn 80% mã được hợp nhất trong kho mã nguồn của Anthropic là do Claude viết. Đặt vào hai năm trước, con số này chỉ là một số thấp. Cùng bộ dữ liệu này cũng cho thấy, trong quý II năm 2026, lượng mã hợp nhất hàng ngày của một kỹ sư điển hình tại Anthropic gấp 8 lần năm 2024.
Có thể tưởng tượng phản ứng lần đầu tiên khi đọc hai con số này của bất kỳ ai không theo dõi sâu về ngành AI. Nhưng chính Anthropic trong phần chú thích cuối trang đã thừa nhận một số điều kiện hạn chế quan trọng: Ban lãnh đạo từng ước tính công khai rằng nếu tính cả mã kịch bản và mã thử nghiệm, tỷ lệ mã do Claude viết vượt quá 90%, 80% là thống kê thận trọng hơn theo cách tính mã hợp nhất; số dòng mã "là thước đo không hoàn hảo", có thể đánh giá cao sự gia tăng năng suất thực tế; bản thân đường ống xác định nguồn gốc mã có "khoảng trống".
Cách viết những chú thích này đáng để phân tích. Sự tồn tại của chúng bề ngoài là sự nhượng bộ trung thực, nhưng thực tế tác dụng là khiến các con số trong phần nội dung văn bản có vẻ đã qua quá trình tự lọc lựa thận trọng, từ đó đạt được độ tin cậy cao hơn. Đây là một cấu trúc hai lớp trong kỹ thuật tự sự: văn bản chính đưa ra tín hiệu, chú thích đưa ra tuyên bố miễn trừ trách nhiệm.
Nhóm số liệu thứ hai liên quan đến tốc độ. Về nhiệm vụ tối ưu hóa mã, Claude Opus 4 vào tháng 5 năm 2025 đạt được hiệu quả tăng tốc khoảng 3 lần, trong khi một nhà nghiên cứu con người thành thạo cần 4 đến 8 giờ để đạt mức tương tự. Đến tháng 4 năm 2026, Claude Mythos Preview đã đẩy con số này lên khoảng 52 lần. Thời lượng dài nhất mà AI có thể hoàn thành nhiệm vụ độc lập cũng tăng từ 4 phút vào tháng 3 năm 2024, tăng gấp đôi mỗi 4 tháng, lên đến 12 giờ vào tháng 3 năm 2026. Bản thân tốc độ tăng gấp đôi sau mỗi 4 tháng đã tạo thành một điểm nhớ dễ lan truyền, mang đậm trí tưởng tượng về cấp số nhân.
Một nhóm dữ liệu khác đến từ cuộc khảo sát nội bộ tháng 3 năm 2026 với 130 nhân viên nhóm nghiên cứu Anthropic. Người được hỏi ở mức trung vị ước tính, đầu ra khi sử dụng Mythos Preview cao gấp khoảng 4 lần so với khi không sử dụng AI. Phần chú thích lại chỉ ra rằng, nghiên cứu độc lập trước đây của METR cho thấy ước tính của nhà phát triển về mức tăng năng suất AI có thể bị đánh giá cao một cách tổng thể. Cấu trúc hai lớp tương tự lại xuất hiện.
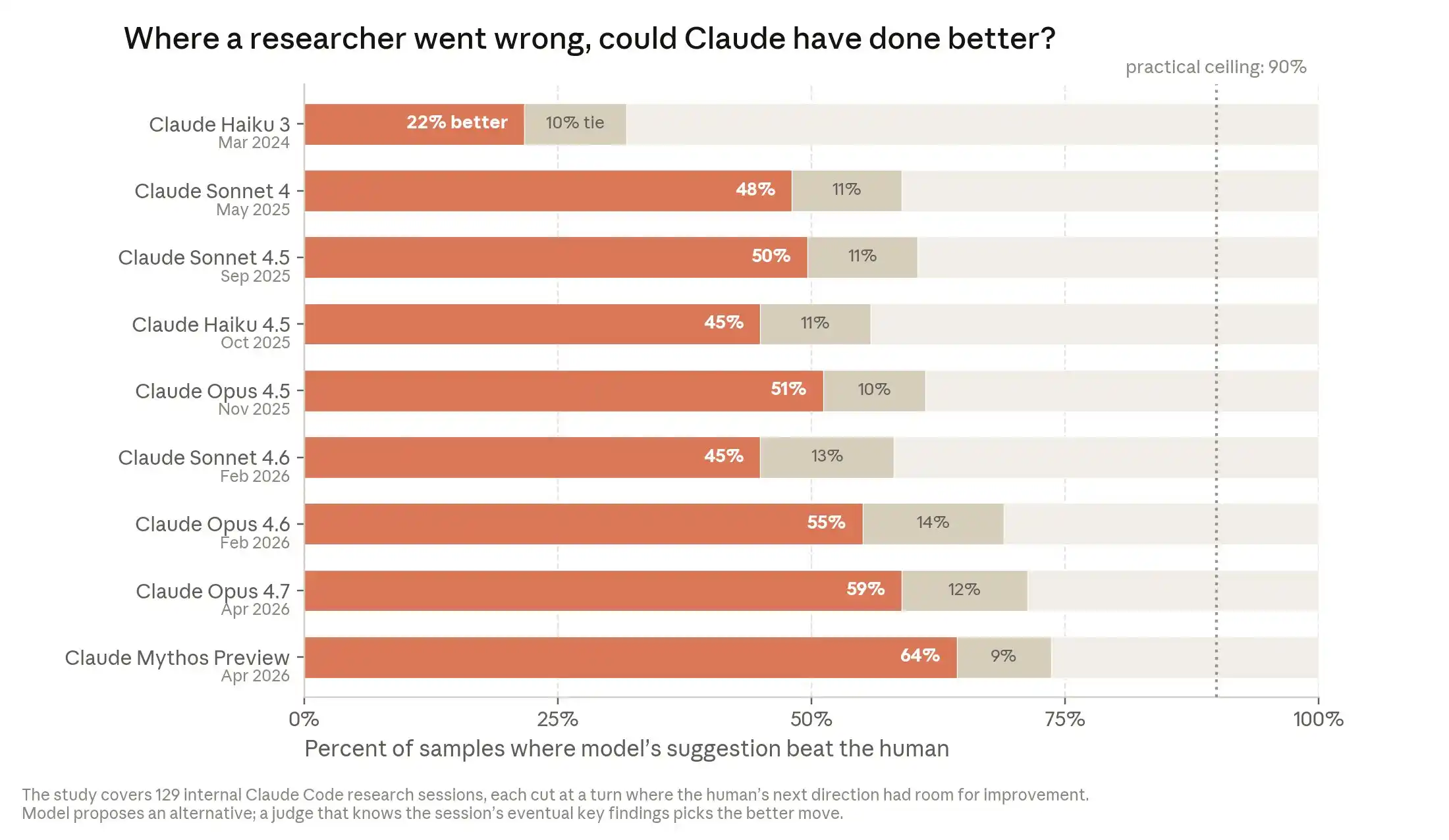
Nhóm số liệu thứ ba chỉ ra rằng AI đang tiến gần đến ranh giới phán đoán của nhà nghiên cứu con người. Vào tháng 11 năm 2025, Claude Opus 4.5 trong việc lựa chọn hướng nghiên cứu, có 51% trường hợp tốt hơn lựa chọn của nhà nghiên cứu con người. Đến tháng 4 năm 2026, con số này tăng lên 64%. Cỡ mẫu 129 trường hợp, Anthropic trong phần chú thích giải thích rằng đây là những thời điểm được con người cố tình lựa chọn, khi lựa chọn của con người có không gian để cải thiện.
Nếu tách riêng bất kỳ con số nào, đều có thể đặt vào các khung giải thích khác nhau. Nhưng khi đặt chúng lại với nhau, hướng đi là nhất quán: tốc độ đang tăng nhanh, khoảng cách đang thu hẹp, và tất cả điều này đang diễn ra bên trong kho mã nguồn và phòng thí nghiệm của chính Anthropic, không phải là suy diễn lý thuyết trên một tiêu chuẩn bên ngoài nào đó.
Sau khi liệt kê những dữ liệu này, bài viết dài đưa ra ba viễn cảnh tương lai.
Loại thứ nhất là xu hướng đình trệ, bước vào giai đoạn bão hòa của đường cong S. Cách diễn đạt của Anthropic là "chúng tôi không tin điều này có khả năng xảy ra".
Loại thứ hai là cải thiện hiệu quả tổng hợp, AI tiếp tục thay thế con người trong các khâu nghiên cứu phát triển rộng hơn, nhưng con người vẫn đặt ra phương hướng, xác định tiêu chuẩn thành công. Anthropic đánh giá là "bằng chứng cho thấy chúng tôi rất có thể đang hướng tới viễn cảnh này".
Loại thứ ba là Cải tiến Đệ quy Tự thân hoàn toàn, AI tự chủ thiết kế, huấn luyện và triển khai các hệ thống kế thừa mạnh hơn chính nó, con người không còn đứng trong vòng lặp. Cách diễn đạt là "có thể".
Thứ tự sắp xếp và phân bổ ngữ khí của ba viễn cảnh này tạo thành một gradient tự sự hoàn chỉnh. Loại thứ nhất được nhẹ nhàng đặt xuống, đóng vai trò thu hút những người hoài nghi; loại thứ hai được neo vào "bằng chứng", khoác lên bài viết lớp áo duy lý; loại thứ ba thông qua từ "có thể" và điều kiện "nếu xu hướng công nghệ tiếp tục", đẩy giả thuyết táo bạo nhất đến rìa trí tưởng tượng của người đọc, nhưng không cần gánh vác trách nhiệm chứng minh cho nó.
Ở phần cốt lõi nhất của toàn bài, thái độ của Anthropic được nén vào một câu: "Chúng tôi chưa đạt đến đó, và Cải tiến Đệ quy Tự thân cũng không phải là điều không thể tránh khỏi. Nhưng nó có thể đến nhanh hơn hầu hết các tổ chức đang chuẩn bị."
Từ "Sẵn sàng Tạm dừng" đến "Tạm dừng Đơn phương Chỉ khiến Kẻ Liều lĩnh Đuổi kịp"
Nếu bài viết dài ngày 4 tháng 6 là một bức ảnh nhanh được cấu trúc cẩn thận, thì đặt bức ảnh đó vào trục thời gian sẽ thấy một quỹ đạo dài hơn.
Năm 2023, Anthropic đã công bố Chính sách Mở rộng Có trách nhiệm (Responsible Scaling Policy - RSP). Cam kết cốt lõi của tài liệu chính sách này là: Nếu năng lực của mô hình vượt quá khả năng kiểm soát an toàn của công ty, công ty sẽ tạm dừng huấn luyện các mô hình mạnh hơn. Đây không phải là tuyên bố bằng lời nói, mà là một tài liệu quản trị nội bộ có khuôn khổ đánh giá, có điều kiện kích hoạt. Tài liệu này từng được giới an toàn AI coi là mẫu có thể vận hành của "quy định tự nguyện".
Năm 2024, CEO Dario Amodei đã đăng một bài viết được lan truyền rộng rãi, đề xuất khả năng "AI mạnh mẽ" (powerful AI) sẽ xuất hiện vào năm 2027. Khi đó, Anthropic vẫn thể hiện tư thế độc lập của phe an toàn, giữ một khuôn mặt điềm tĩnh trước việc mở rộng quy mô và các câu chuyện gia tốc.
Ngày 26 tháng 1 năm 2026, Amodei trên trang web cá nhân đã đăng một bài viết dài 38 trang "Thời Thanh thiếu niên của Công nghệ" (The Adolescence of Technology). Trong đó ông viết ra một nhận định sau này bị trích dẫn nhiều lần: "Vì AI hiện đang viết phần lớn mã nội bộ của Anthropic, nó đang thực chất thúc đẩy tiến độ xây dựng hệ thống AI thế hệ tiếp theo của chúng tôi. Vòng phản hồi này đang tích lũy sức mạnh theo từng tháng, có thể chỉ còn cách thời điểm thế hệ AI hiện tại tự xây dựng hệ thống kế thừa từ 1 đến 2 năm." Trong cùng bài viết, ông mô tả "AI mạnh mẽ" sắp tới là "quốc gia thiên tài trong trung tâm dữ liệu".
Đây gần như là điểm khởi đầu cho việc Anthropic bắt đầu phát đi một cách có hệ thống tín hiệu "vòng phản hồi tự cải tiến đang diễn ra". Và thời điểm công bố bài viết blog này, lại nằm ngay trong giai đoạn công ty đang nhảy từ mức định giá 3500 tỷ USD lên khu vực định giá cao hơn.
Chưa đầy một tháng sau, bước ngoặt đã đến.
Ngày 25 tháng 2 năm 2026, CNN đưa tin, Anthropic đã sửa đổi Chính sách Mở rộng Có trách nhiệm của mình, loại bỏ cam kết cốt lõi "tạm dừng huấn luyện các mô hình mạnh hơn nếu năng lực vượt quá khả năng kiểm soát an toàn", thay thế bằng một "Lộ trình An toàn Tiên phong" (Frontier Safety Roadmap) không ràng buộc. Cùng tuần đó, Bộ trưởng Quốc phòng Mỹ Pete Hegseth đã gửi tối hậu thư cho Dario Amodei: Rút lại lằn ranh đỏ an toàn, hoặc mất hợp đồng 200 triệu USD của Bộ Quốc phòng.
Bài báo dẫn lời phản hồi của Giám đốc Khoa học của Anthropic Jared Kaplan với tạp chí Time: "Chúng tôi cho rằng việc dừng huấn luyện mô hình thực sự không giúp ích cho bất kỳ ai... nếu đối thủ cạnh tranh đang chạy hết tốc lực." Cách diễn đạt trong phản hồi này rất đáng lưu ý. "Không giúp ích cho bất kỳ ai" không phải là lập luận kỹ thuật, mà là một cách diễn đạt về sự đấu tranh lợi ích của các bên liên quan. "Nếu đối thủ cạnh tranh đang chạy hết tốc lực" thì trong cấu trúc tự sự lại hoàn toàn đồng cấu trúc với "Tạm dừng đơn phương chỉ khiến những người tham gia thiếu thận trọng nhất đuổi kịp": Nó thay thế logic tạm dừng lấy khả năng an toàn của chính mình làm hệ quy chiếu, bằng logic tốc độ lấy hành động của đối thủ cạnh tranh làm hệ quy chiếu.
Anthropic vẫn nhấn mạnh trong bài báo của CNN rằng họ giữ lại hai lằn ranh đỏ: không sử dụng hệ thống AI để điều khiển hệ thống vũ khí, và không sử dụng để giám sát quy mô lớn trong nước. Điều này rất quan trọng, vì nó cho thấy Anthropic không từ bỏ hoàn toàn lập trường an toàn, mà đang thực hiện những nhượng bộ và giữ vững có chọn lọc trên các chiều an toàn khác nhau. Nhưng bản thân tính chọn lọc này cũng chính là manh mối trung tâm trong phân tích chiến lược tự sự: Họ nhượng bộ ở những mặt nào, giữ vững ở những mặt nào, ranh giới này khắc họa thang đo mà an toàn được hiệu chỉnh lại.
Ngày 11 tháng 3, Anthropic Institute chính thức thành lập, do Jack Clark lãnh đạo, định vị là "tổ chức nghiên cứu vì lợi ích công". Chưa đầy hai tháng sau, ngày 4 tháng 5, Clark đăng bài viết với con số "60%".
Một khi trình tự thời gian này được đặt cạnh nhau, mật độ tín hiệu và nhịp độ phát ra không phải là ngẫu nhiên. Từ bài viết cá nhân tháng 1 báo trước, đến sửa đổi chính sách tháng 2, thành lập tổ chức tháng 3, dự đoán xác suất của nhà sáng lập tháng 5, rồi đến công bố bài viết dài chính thức tháng 6, đây là một đường ống tự sự có nhịp điệu rõ ràng, cách diễn đạt dần được nâng cấp. Không thể từ đó suy ra trực tiếp rằng "tất cả đều được lên kế hoạch trước", nhưng bản thân trình tự này tạo thành một vấn đề mà bất kỳ nhà phân tích nào cũng phải đối mặt: Cảm giác về nhịp điệu này có phải cho thấy Anthropic đã đưa "câu chuyện gia tốc" vào phạm vi quản lý truyền thông công chúng của mình?
Sự khiêu khích cố ý của Hassabis
Nếu trong nửa đầu năm 2026 chỉ có mỗi Anthropic điều chỉnh cách nói, nhà phân tích có đủ lý do để tập trung sự chú ý vào logic quyết định nội bộ doanh nghiệp. Nhưng CEO DeepMind Demis Hassabis gần như đồng thời đã thực hiện những điều chỉnh cùng hướng, cùng mức độ, khiến cho cách giải thích "trường hợp cá biệt của một doanh nghiệp" không đứng vững.
Ngày 20 tháng 1, Diễn đàn Davos. Hassabis vẫn duy trì nhận định nhất quán trong nhiều năm của mình: AGI có 50% xác suất vào năm 2030. 3 tuần sau, ngày 18 tháng 2, tại Hội nghị Thượng đỉnh về Tác động AI ở Ấn Độ, ông đã nới lỏng: "AGI có thể đến trong vòng 5 năm."
Từ ngày 20 đến 22 tháng 5, Google I/O. Hassabis trong bài phát biểu chính nói rằng, nhân loại đang đứng ở "chân núi của Điểm Kỳ dị". Cùng thời kỳ, OpenAI đã phát hành GPT-5.3-Codex, tuyên bố mô hình này "đóng vai trò then chốt trong quá trình tự tạo ra chính nó", cụ thể bao gồm hỗ trợ gỡ lỗi quá trình huấn luyện, quản lý triển khai, phân tích kết quả đánh giá. Nhịp điệu của ba phòng thí nghiệm hàng đầu trong khung thời gian này bị nén lại để tính theo tuần.
Sau Google I/O, Hassabis đã tiếp nhận phỏng vấn từ Axios. Đoạn phỏng vấn này sau đó được trích dẫn nhiều, trong đó câu then chốt nhất là, ông thừa nhận việc sử dụng ngôn ngữ như "chân núi của Điểm Kỳ dị" là "cố ý khiêu khích", nhằm kích thích nhận thức của chính phủ, các nhà kinh tế và công chúng về tính cấp bách của sự phát triển gia tốc AI. Ông cũng điều chỉnh lộ trình AGI từ trước đó "không lâu sau năm 2030" thành "năm 2029 là một khả năng thực sự", mặc dù vẫn kỳ vọng rộng rãi là vào năm 2030, cộng trừ một năm.
Hassabis nói với Seoul Economic Daily còn trực tiếp hơn: "Năm đến mười năm nữa, khi chúng ta nhìn lại năm 2026 và 2027, chúng ta sẽ nói 'đó chính là thời điểm chúng ta bước vào thời đại AGI'."
Từ "cố ý khiêu khích" đáng được cân nhắc kỹ lưỡng. Đó là một cơ chế hiếm có, được chính người trong cuộc thừa nhận, về ý đồ tự sự mà trước đây dù bị nghi ngờ rộng rãi nhưng ít khi được thốt ra. Nó thừa nhận rằng, ít nhất một phần cách diễn đạt mà các nhà lãnh đạo phòng thí nghiệm tiên phong lựa chọn, là mang mục đích truyền thông rõ ràng. Điều này khiến tất cả các cách giải thích tuyên bố của họ phải đồng thời bao gồm hai đối tượng phân tích, tức là sự thật mà họ tuyên bố, và bản thân chiến lược tu từ mà họ sử dụng khi lựa chọn những tuyên bố đó như một sự kiện hành vi.
Sự tự giải thích của Hassabis về cách diễn đạt của chính mình đã mở ra một cánh cửa bên để giải mã loạt tín hiệu đồng bộ này. Thái độ "cố ý khiêu khích" của ông và "chú thích miễn trừ trách nhiệm" trong lập luận dữ liệu dài của Anthropic thể hiện cùng một tư thế lưỡng cư: một tay đẩy những tín hiệu đủ sức chấn động dư luận, tay kia giữ lại không gian an toàn để rút lui về "đây chỉ là một phần khả năng".
Cùng một nhóm dữ liệu, cách giải thích hoàn toàn khác
Khi Anthropic và DeepMind cùng xây dựng một khung tự sự "AI đang tự gia tốc tiến hóa", các nhà nghiên cứu độc lập bên ngoài đã cung cấp những cách giải thích khác cho cùng một nhóm dữ liệu và hiện tượng. Những cách giải thích này quan trọng không phải vì một bên nào nắm giữ sự thật tối hậu, mà vì chúng phơi bày khoảng giải thích có thể có của chính câu chuyện chính thức lớn đến mức nào.
Phản hồi sắc bén nhất đến từ Eliezer Yudkowsky. Ông không chỉ trả lời Jack Clark, mà còn tiếp tục lên tiếng trong nhiều dịp sau đó. Blog của MindStudio ghi lại thái độ đầy đủ của ông: Ông sử dụng lò phản ứng RBMK Chernobyl để loại suy với thiết kế an toàn của hệ thống AI hiện tại. Luận điểm cốt lõi của phép loại suy này là, nếu cần điều khiển và bộ tăng tốc được buộc trong cùng một hệ thống, khi bạn cố gắng giảm tốc, hệ thống thực tế sẽ mất kiểm soát nhanh hơn.
Nathan Lambert từ Allen Institute for AI đưa ra khái niệm "Cải tiến Tự thân có Hao hụt" (Lossy Self-Improvement - LSI). Luận điểm của ông tạo thành thách thức trực tiếp với mô hình "bánh đà gia tốc": Khi hệ thống ngày càng trở nên phức tạp, quá trình cải tiến ở mỗi thế hệ sẽ tạo ra ma sát và hao hụt, giống như tín hiệu bị suy giảm khi truyền đi khoảng cách dài. Theo logic này, những cải tiến khiến 80% hoặc 90% mã do AI viết trở nên khả thi, không thể sao chép vô hạn lên hệ thống thế hệ tiếp theo, vì thế hệ sau sẽ đối mặt với không gian vấn đề phức tạp hơn, và nhiễu cũng như sai số trong đầu ra của chính AI sẽ bị khuếch đại khi truyền qua các thế hệ.
Chuyên viên nghiên cứu cấp cao Dean Ball của Foundation for American Innovation cung cấp một khung ngôn ngữ trực tiếp hơn, giảm chiều dữ liệu của Anthropic. Ông nói với IEEE Spectrum: "Có lẽ cuối cùng họ sẽ tự động hóa thiên tài, nhưng không phải vào năm tới. Năm tới họ tự động hóa lao động chân tay." Sự phân biệt này chạm vào sự mơ hồ cốt lõi của "80% mã do AI viết". Nếu AI tự động hóa phần mẫu cố định trong kho mã, tạo ra tham số hàng loạt, cấu hình đường ống đầu cuối, thì những công việc này trong ngữ cảnh kỹ thuật phần mềm thực sự chỉ tương ứng với "lao động chân tay". 20% còn lại, có thể bao gồm thiết kế kiến trúc, phán đoán phương hướng, đánh đổi dựa trên thông tin không đầy đủ, đó mới là phần thiên tài.
David Scott Krueger từ Đại học Montréal, với tư cách là người sáng lập tổ chức phi lợi nhuận về an toàn AI Evitable, lằn ranh đỏ kích hoạt tạm dừng mà ông đề xuất là "99% mã do AI viết". Ông nói với IEEE Spectrum: "Tôi nghĩ bây giờ chúng ta có thể đang vượt qua lằn ranh này." Sự căng thẳng giữa khung của ông và cam kết tạm dừng mà chính Anthropic đã nới lỏng, chính là một trong những mâu thuẫn cấu trúc quan trọng nhất trong đợt tự sự này.
Nhà khoa học máy tính Jeff Clune của UBC khi được IEEE Spectrum phỏng vấn lại đứng ở một hướng khác. Ông nói: "Chúng ta đang ở điểm uốn của hệ thống Cải tiến Đệ quy Tự thân." Câu nói này của ông nếu thực sự được xác minh, có nghĩa là hồi chuông cảnh báo của Yudkowsky đã đúng nhịp.
Bốn nhóm tiếng nói, hướng đi khác nhau, thậm chí trong cùng một hướng còn có sự giằng co nội bộ giữa các phe phái. Nhưng điểm chung của chúng là, chúng không dựa vào khung tự sự chính thức, mà từ phương pháp luận của chính mình, đưa ra những đánh giá độc lập cho cùng một nhóm hiện tượng. Và bản thân tính đa dạng và mâu thuẫn lẫn nhau của những đánh giá này, chính là sự phản bác mạnh mẽ nhất đối với việc "bất kỳ câu chuyện đơn lẻ nào cũng đủ bao phủ toàn bộ sự thật".
Sự kết hợp giữa đường cong định giá và nhịp điệu tự sự
Tháng 1 năm 2026, Anthropic hoàn thành vòng gọi vốn, định giá 3500 tỷ USD. Nhà đầu tư bao gồm Microsoft và Nvidia. Con số này từ cuối năm 2025 đã được một số phương tiện truyền thông làm nóng trước, nhưng thời điểm chính thức hoàn tất lại nằm ngay sau khi Amodei công bố "Thời Thanh thiếu niên của Công nghệ".
Tháng 2, một vòng gọi vốn 300 tỷ USD nữa hoàn tất, định giá duy trì trong khoảng 3500 tỷ USD. Cùng tháng, chính sách an toàn được sửa đổi, loại bỏ cam kết tạm dừng. Lời đe dọa hợp đồng 2 tỷ USD từ Lầu Năm Góc được đưa ra.
Tháng 5, Reuters, New York Times và TechCrunch gần như đồng thời đưa tin, Anthropic đã hoàn tất một vòng gọi vốn 650 tỷ USD, định giá đạt 9650 tỷ USD. Con số này không chỉ vượt định giá của chính họ hai tháng trước, mà còn vượt qua định giá 8520 tỷ USD của OpenAI vào tháng 3 năm 2026. New York Times còn dẫn lời Dario Amodei tại hội nghị nhà phát triển, cho biết doanh thu hàng năm của công ty đạt 300 tỷ USD, bản thân ông thậm chí còn đùa rằng "hy vọng mức tăng doanh thu gấp 80 lần năm nay đừng tiếp tục, vì như vậy sẽ quá điên rồ".
Ngày 4 tháng 6, Anthropic Institute công bố bài viết dài "Khi AI tự xây dựng chính mình".
Việc xếp các mốc thời gian này thành hàng không phải để ngụ ý tồn tại một mũi tên chính xác trên biểu đồ. Nếu ai đó nói rằng tồn tại mối quan hệ nhân quả giữa những điều này, phải cung cấp bằng chứng trực tiếp. Trong điều kiện không có hồ sơ quyết định nội bộ, bất kỳ nhà phân tích nào cũng không thể và không nên đưa ra khẳng định như vậy.
Nhưng mặt khác, việc hoàn toàn không quan sát và ghi lại sự tương ứng của các mốc thời gian này, cũng là không hợp lý. Một doanh nghiệp chỉ trong vòng 5 tháng ngắn ngủi, định giá tăng từ 3500 tỷ USD lên 9650 tỷ USD, gần gấp ba lần, đồng thời trải qua một lần chuyển hướng chính sách an toàn lớn, đồng thời xây dựng một đường ống tự sự "tín hiệu gia tốc" do tổ chức nghiên cứu độc lập dẫn dắt, đồng thời đồng sáng lập của họ đưa ra dự đoán xác suất 60%. Khi tất cả các sự kiện này được nén dày đặc trong vòng 6 tháng, ít nhất các nhà đầu tư có quyền chất vấn: Việc phát ra các tín hiệu này có đang, và ở mức độ nào, thực hiện chức năng truyền tải thông tin "chúng tôi đang ở tiền tuyến gia tốc" ra thị trường?
Bản thân câu chất vấn này chính là giá trị của phân tích. Câu trả lời có thể mãi mãi không chỉ một. Nhưng một khi câu hỏi đã được đặt ra rõ ràng, sẽ không dễ dàng bị thu hồi.
Nguồn vốn toàn cầu cho thị trường AI đạt 29,7 nghìn tỷ USD trong quý I năm 2026, năm giao dịch hàng đầu chiếm tỷ trọng đáng kể trong tổng số này. Ở mức nước này, tất cả các phòng thí nghiệm tiên phong đều đối mặt với áp lực tương tự: Bạn cần thuyết phục nhà đầu tư rằng đường cong công nghệ của bạn sẽ dốc hơn đối thủ. Cảnh báo rủi ro của bạn cũng phải đủ lớn, để khi các nhà quản lý cuối cùng vào cuộc thiết lập quy tắc, tiếng nói của bạn đã được tích hợp sẵn vào khung chính sách. Câu chuyện của bạn, còn phải đủ hấp dẫn để các nhà nghiên cứu hàng đầu lựa chọn phòng thí nghiệm của bạn, đủ cảnh giác để duy trì cơ sở ngôn ngữ còn sót lại của bạn trong cộng đồng an toàn.
Giữa những nhu cầu này tồn tại mâu thuẫn nội tại. Việc điều chỉnh câu chuyện của Anthropic trong nửa đầu năm 2026 có thể được coi là sự hiệu chỉnh lại điểm cân bằng ở cấp độ ngôn ngữ giữa những nhu cầu mâu thuẫn lẫn nhau này. Việc làm suy yếu cam kết an toàn, tăng cường tín hiệu gia tốc, và việc sử dụng lặp đi lặp lại luận cứ "chúng tôi không thể đơn phương dừng lại", cùng tạo thành một nhóm vector chỉ về cùng một hướng.
Tín hiệu đã được phát đi, và sau đó
Cần quay lại vấn đề cốt lõi nhất: Những tín hiệu này, rốt cuộc giống như sự phản ánh của điểm uốn kỹ thuật hơn, hay là sự nâng cấp tu từ hướng tới vốn và quản lý?
Bằng chứng công khai hiện có không cho phép đơn giản đánh dấu vào một trong hai lựa chọn. Bởi vì bằng chứng mà hai cách giải thích sử dụng, thực tế là cùng một nhóm dữ liệu. Tỷ lệ 80% mã, hiệu quả tăng tốc 52 lần, thời gian nhiệm vụ tăng gấp đôi mỗi 4 tháng, đều có thể dùng để ủng hộ "điểm uốn đang đến", cũng có thể dùng để giải thích "chúng tôi đang truyền tải ra thị trường một nhận thức xu hướng mà chính các kỹ thuật viên của chúng tôi đã trải nghiệm", ranh giới giữa hai điều này là mơ hồ.
Nhưng có một số sự thật là xác định, không cần lựa chọn phe phái trong hai cách giải thích.
Thứ nhất, sự chuyển hướng tự sự mà Anthropic hoàn thành trong nửa đầu năm 2026 không phải là trường hợp đơn lẻ. Hassabis của DeepMind gần như trong cùng một quý đã thực hiện những điều chỉnh cùng hướng, mức độ khác nhau nhưng bản chất tương tự, Sam Altman của OpenAI tại hội nghị thượng đỉnh Ấn Độ nói "thế giới chưa sẵn sàng", và vào tháng 2 năm 2026 đã phát hành GPT-5.3-Codex tuyên bố "đóng vai trò then chốt trong quá trình tự tạo ra chính nó". Nếu chỉ có Anthropic phát đi tín hiệu, có thể phân tích từ góc độ chiến lược doanh nghiệp. Nhưng ba phòng thí nghiệm hàng đầu đồng thời tăng âm lượng trong vài tháng dày đặc, điều này tạo thành sự chuyển hướng tự sự ở cấp độ ngành.
Thứ hai, tồn tại mối tương ứng thời gian có thể theo dõi chính xác giữa nhịp độ phát tín hiệu và nhịp điệu của việc gọi vốn, điều chỉnh chính sách, tái cấu trúc tổ chức. Bản thân sự tương ứng này không cần chứng minh bất cứ điều gì, nó chỉ cần được trình bày một cách trung thực. Sau khi trình bày, phương pháp luận sẵn có của mỗi người sẽ quyết định họ nghĩ gì tiếp theo.
Thứ ba, trong khuôn khổ đánh giá nội bộ của chính công ty công bố những dữ liệu này, trạng thái mà Anthropic tự gán cho viễn cảnh thứ ba, tức "Cải tiến Đệ quy Tự thân hoàn toàn", vẫn là "có thể", chứ không phải "rất có thể". Điều này có nghĩa là trong khung đánh giá nội bộ của công ty công bố những dữ liệu này, câu chuyện gia tốc của họ vẫn chưa hoàn toàn khép kín. Những lực lượng khiến họ thói quen thêm điều khoản hạn chế trong các bài báo học thuật và viết blog, vẫn đang giữ dây cương cho cách diễn đạt công khai của họ.
Thứ tư, lời thú nhận "cố ý khiêu khích" của Hassabis đã xác nhận một cơ chế trước đây dù bị nghi ngờ rộng rãi nhưng hiếm khi được chính người trong cuộc thốt ra: Ít nhất một phần nhà lãnh đạo phòng thí nghiệm tiên phong khi lựa chọn cách diễn đạt, mang mục đích truyền thông rõ ràng. Điều này khiến tất cả các cách giải thích tuyên bố của họ phải đồng thời bao gồm hai đối tượng phân tích, tức là sự thật mà họ tuyên bố, và bản thân chiến lược tu từ mà họ sử dụng khi lựa chọn những tuyên bố đó như một sự kiện hành vi.
Những người đọc kỹ dữ liệu xuyên suốt của Anthropic, và những người chỉ nhớ hai con số "80% mã do AI viết" và "tăng tốc 52 lần", nhận được cường độ tín hiệu hoàn toàn khác nhau. Nhưng trong chuyện này, "được nhớ như thế nào" có lẽ nên được coi là đối tượng phân tích hơn là "thực tế đã nói gì".
Bản thân bài viết dài này chính là một mẫu chính xác của hiện tượng mà nó đang mô tả. Nó sử dụng dữ liệu xây dựng cảm giác gia tốc cận kề, lại sử dụng chú thích và điều khoản hạn chế để giữ lại không gian rút lui; nó kêu gọi sự phối hợp toàn cầu và làm chậm lại có thể xác minh, nhưng lại trong sửa đổi chính sách trước đó đã gỡ bỏ cam kết tạm dừng. Đây không phải là đạo đức giả, cũng không phải là sự không nhất quán giữa lời nói và việc làm một cách đơn giản. Đây là thuật cân bằng tự sự của một tổ chức giữa sự không chắc chắn về công nghệ, áp lực thương mại và trách nhiệm công cộng. Và lời thú nhận "cố ý khiêu khích" của Hassabis, tình cờ từ cánh cửa bên xác nhận rằng thuật cân bằng này trong các phòng thí nghiệm hàng đầu đã trở thành một phương pháp được sử dụng một cách tự giác.








