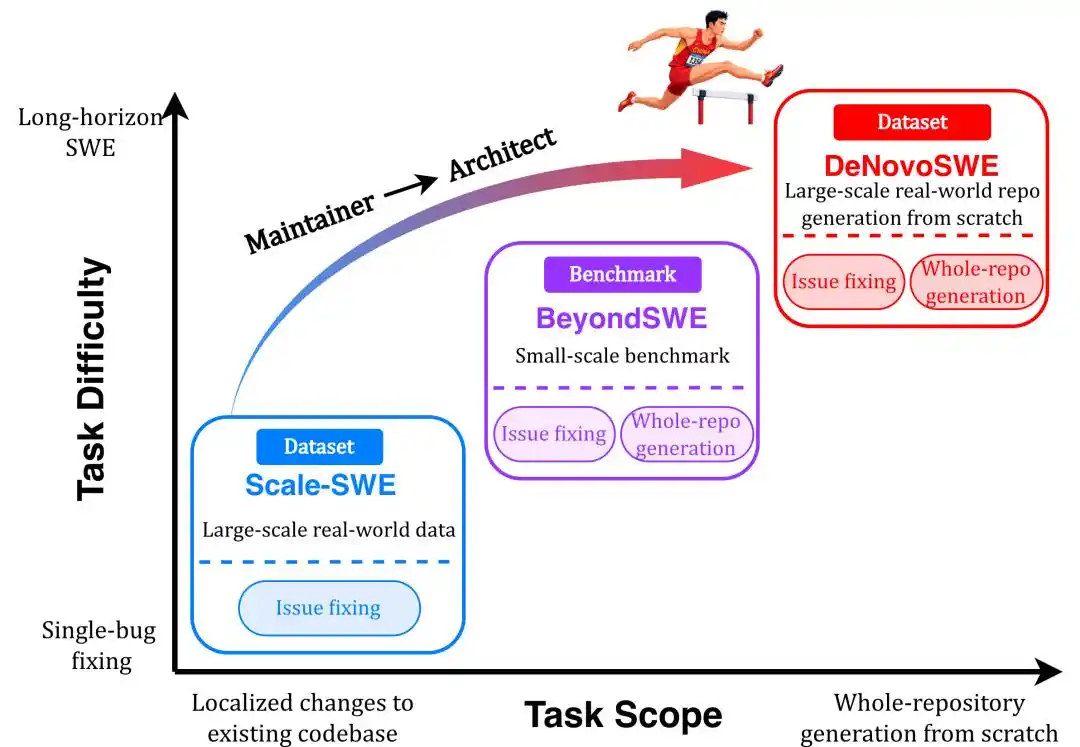
Với khả năng của LLM Code Agent ngày càng được nâng cao, ngày càng nhiều nhà nghiên cứu nhận ra đã đến lúc bước sang giai đoạn tiếp theo - những nhiệm vụ dài hạn gần với nhu cầu thực tế hơn. Do đó, một số benchmark đánh giá nhiệm vụ dài hạn đã xuất hiện như NL2RepoBench và BeyondSWE. Kỳ vọng về vai trò của Code Agent dần chuyển từ người bảo trì kho lưu trữ thành kiến trúc sư, có thể lập kế hoạch và hoàn thành các nhiệm vụ dài hạn liên quan toàn bộ mã nguồn trong kho.
Gần đây, Trường Cao học Trí tuệ Nhân tạo Gaoling, Đại học Nhân dân Trung Quốc đã hoàn thành nghiên cứu liên quan và công bố bộ dữ liệu DeNovoSWE, tập trung vào các nhiệm vụ kỹ thuật phần mềm dài hạn, đặc biệt là nhiệm vụ tạo mã cấp kho lưu trữ từ đầu.

Link bài báo: https://arxiv.org/pdf/2606.10728
Link kho lưu trữ: https://github.com/AweAI-Team/DeNovoSWE
Link dữ liệu: https://huggingface.co/collections/AweAI-Team/denovoswe
Bằng cơ chế Divide & Conquer và Critic & Repair để xây dựng bộ dữ liệu chất lượng cao, đồng thời thành công trong việc mở rộng quy mô cho nhiệm vụ SWE dài hạn, xây dựng bộ dữ liệu nhiệm vụ SWE dài hạn chất lượng cao mã nguồn mở chứa 4,818 dữ liệu thực tế - thành quả này cung cấp dữ liệu quy mô lớn cho việc đào tạo khả năng dài hạn của Code Agent, nâng cao đáng kể năng lực thực hiện nhiệm vụ dài hạn của Code Agent.
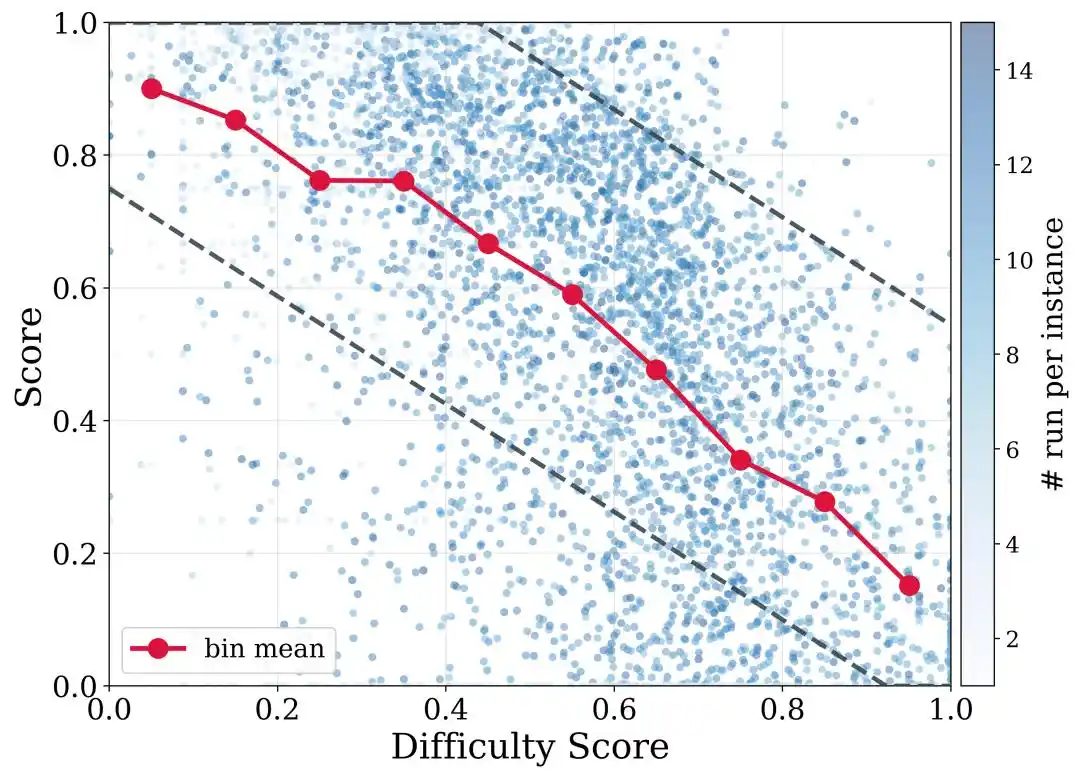
Bài báo cũng cung cấp phương pháp lọc dựa trên điểm độ khó của đề bài, giúp giảm thiểu hiệu quả vấn đề đánh đổi giữa tỷ lệ bài toán khó và chất lượng quỹ đạo.
Thí nghiệm cho thấy, Qwen3-30B-A3B-Instruct được huấn luyện dựa trên DeNovoSWE đã cải thiện từ 5.8% lên 47.2% trên BeyondSWE-Doc2Repo, và từ 4.3% lên 23.0% trên NL2RepoBench, thể hiện sự cải thiện đáng kể về khả năng tạo mã cấp kho lưu trữ nhờ dữ liệu dài hạn.
Từ Một Tài Liệu Bắt Đầu Tái Tạo Toàn Bộ Kho Lưu Trữ
Một năm qua, với việc mở rộng quy mô dữ liệu SWE lớn như Scale-SWE, các tác nhân mã thông minh đã tiến bộ nhanh chóng trên các nhiệm vụ kỹ thuật phần mềm thực tế như SWE-bench. Nhưng khi mô hình ngày càng giỏi "sửa một issue" hay "sửa vài dòng lỗi", một vấn đề then chốt hơn bắt đầu nổi lên: Liệu tác nhân thông minh có thực sự sở hữu năng lực kỹ thuật phần mềm dài hạn? Nhìn vào hiệu quả của các mô hình tiên phong trên BeyondSWE-Doc2Repo và NL2RepoBench, kết quả không lý tưởng.
Phát triển phần mềm trong thế giới thực thường không phải là sửa một hàm, bổ sung một điều kiện, mà là hiểu yêu cầu, lập kế hoạch kiến trúc, tạo tệp, thiết kế API, xử lý phụ thuộc, kết nối các module, và cuối cùng là đảm bảo toàn bộ kho chạy thông qua kiểm thử.
Nói cách khác, khó khăn nằm ở việc tạo cấp kho lưu trữ tầm nhìn dài hạn: từ một tài liệu nhiệm vụ, tạo ra một kho phần mềm hoàn chỉnh, có thể thực thi, có thể kiểm chứng. Đây chính là vấn đề DeNovoSWE muốn giải quyết.
Tài Liệu Nhiệm Vụ Chất Lượng Cao Cho Việc "Tạo Kho Từ Đầu"
Trong việc tạo kho lưu trữ từ tài liệu, tài liệu không chỉ là README, cũng không phải là danh sách API đơn giản. Về bản chất, nó là điểm vào nhiệm vụ duy nhất để tác nhân thông minh tái tạo toàn bộ kho.
Một tài liệu nhiệm vụ chất lượng cao ít nhất cần đáp ứng hai tiêu chuẩn cốt lõi.
Thứ nhất, nó phải được tổ chức tốt.
Nhiệm vụ cấp kho vốn dĩ phức tạp, chứa nhiều module, giao diện, cấu hình, cấu trúc dữ liệu và quy trình tương tác. Nếu tài liệu chỉ xếp chồng các mô tả hàm lên nhau, tác nhân thông minh dễ bị lạc trong thông tin mảnh vỡ. Do đó, tài liệu nên đưa ra cái nhìn tổng quan rõ ràng về kho trước, sau đó phân chia chương theo khả năng hoặc luồng công việc, để mỗi phần tương ứng với ranh giới chức năng rõ ràng.
Thứ hai, nó phải xuất phát từ góc độ đánh giá (evaluation) đáng tin cậy.
Tài liệu không thể quá ít, nếu không nhiệm vụ trở thành vấn đề không được định nghĩa đầy đủ, khiến mô hình có thể cần đoán mò mới vượt qua được evaluation; cũng không thể quá nhiều, nếu không sẽ tiết lộ chi tiết triển khai, làm mất đi tính thách thức của nhiệm vụ.
Tài liệu thực sự chất lượng cao nên mô tả các hành vi then chốt mà evaluation phụ thuộc vào: bao gồm đường dẫn import, API công khai, đầu vào/đầu ra, tham số mặc định, hành vi ngoại lệ, mục cấu hình, chuỗi mẫu, trường trả về, v.v., đồng thời cũng mô tả chức năng cần hoàn thành đại khái. Nói cách khác, tài liệu phải đủ để tác nhân thông minh tái hiện hành vi có thể kiểm thử, nhưng không được biến thành bản sao của mã triển khai.
Đây cũng là tư tưởng cốt lõi của DeNovoSWE: làm cho tài liệu vừa dễ đọc, có thể thực hiện, vừa có thể kiểm chứng.
Phương Pháp DeNovoSWE
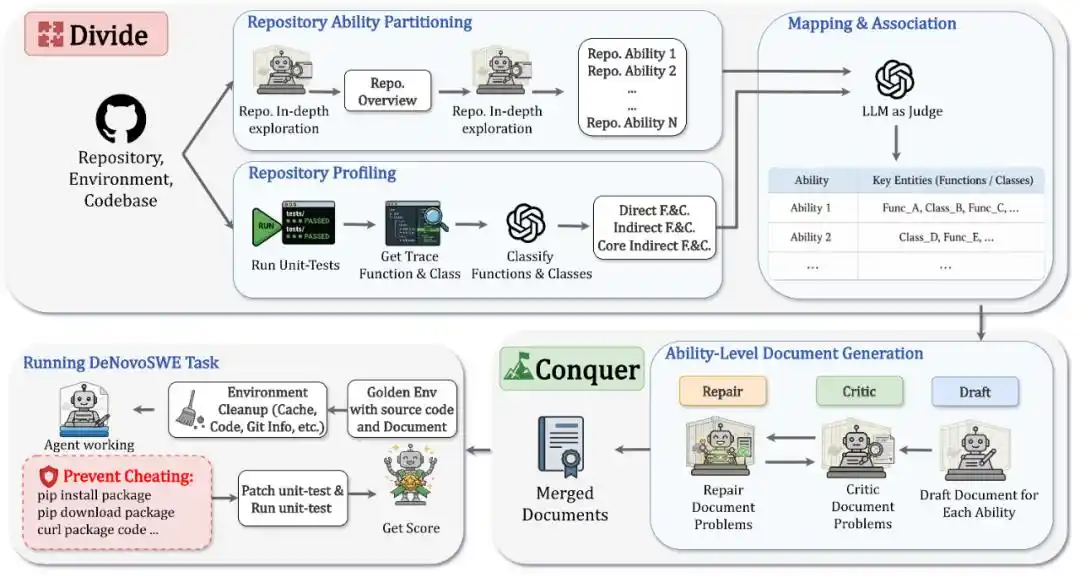
DeNovoSWE xây dựng "tạo kho hoàn chỉnh từ tài liệu" thành một nhiệm vụ kỹ thuật phần mềm dài hạn, quy mô lớn, có thể kiểm chứng. Nó không phải là viết tài liệu thủ công, mà là tự động xây dựng các ví dụ chất lượng cao thông qua một quy trình làm việc đa tác nhân trong môi trường sandbox. Toàn bộ phương pháp có thể tóm tắt thành hai bước: Chia để trị.
Trong giai đoạn Chia, hệ thống trước hết phân tích kho mục tiêu, tách nó thành nhiều khả năng của kho.
Mỗi khả năng tương ứng với một khả năng cốt lõi hoặc luồng công việc trong kho, ví dụ như xác thực và kết nối, đọc/ghi dữ liệu, xử lý hàng loạt, quy trình xuất, v.v. Như vậy, vấn đề tạo kho lớn ban đầu được chia thành nhiều chương tài liệu có cấu trúc rõ ràng.
Đồng thời, DeNovoSWE sẽ chạy kiểm thử đơn vị gốc và thu thập dấu vết thực thi, xác định hàm, lớp và giao diện nào thực sự ảnh hưởng đến evaluation, từ đó phân biệt thêm các thành phần trực tiếp, thành phần gián tiếp cốt lõi và thành phần gián tiếp không cốt lõi: các giao diện được gọi trực tiếp bởi kiểm thử phải được ghi lại chi tiết; các thành phần gián tiếp cốt lõi ảnh hưởng đến hành vi quan sát được cũng cần được bao phủ; còn các triển khai nội bộ không cốt lõi có thể để tác nhân thông minh tự do phát huy.
Trong giai đoạn Trị, DeNovoSWE sử dụng cơ chế Phác thảo-Phê bình-Sửa chữa để tạo tài liệu theo từng khả năng. Tác nhân Phác thảo viết bản nháp đầu tiên; Tác nhân Phê bình kiểm tra xem tài liệu có bỏ sót API then chốt, hợp đồng hành vi hoặc thông tin cấu trúc không; Tác nhân Sửa chữa sau đó sửa tài liệu dựa trên phản hồi. Vòng lặp này lặp lại liên tục cho đến khi mỗi chương về khả năng đủ rõ ràng, hoàn chỉnh và phù hợp với evaluation.
Cuối cùng, tài liệu của các khả năng khác nhau sẽ được hợp nhất thành một tài liệu nhiệm vụ hoàn chỉnh, làm cơ sở duy nhất để tác nhân thông minh tạo kho từ đầu.
Độ Khó: Tại Sao Đây Là Nhiệm Vụ Dài Hạn?
Độ khó của nhiệm vụ DeNovoSWE đến từ một thay đổi căn bản: nó không còn là sửa lỗi cấp issue, mà là tạo toàn bộ kho.
Trong các nhiệm vụ SWE truyền thống, tác nhân thông minh thường đối mặt với một kho đã tồn tại, chỉ cần định vị lỗi, sửa mã cục bộ và vượt qua kiểm thử.
Trong DeNovoSWE, tác nhân thông minh đối mặt với một môi trường đã được làm sạch: mã nguồn và kiểm thử gốc bị loại bỏ, lịch sử git được đặt lại, bộ nhớ đệm, tàn dư site-packages, pip wheel, sản phẩm biên dịch tạm thời và các kênh rò rỉ tiềm ẩn khác cũng sẽ bị xóa. Điều này có nghĩa là tác nhân thông minh phải thực sự dựa vào tài liệu để hoàn thành việc tái tạo toàn bộ kho. Nó cần lập kế hoạch cấu trúc dự án, tạo tệp module, định nghĩa giao diện công khai, triển khai tương tác xuyên tệp, xử lý phụ thuộc và cấu hình, đồng thời liên tục sửa lỗi trong nhiều vòng chỉnh sửa và phản hồi kiểm thử.
Bất kỳ sai lệch nào về chữ ký API, trường trả về, kiểu ngoại lệ hoặc hành vi mặc định đều có thể dẫn đến thất bại kiểm thử. Lỗi còn tích lũy trong quá trình dài hạn: một module được thiết kế không hợp lý từ sớm có thể ảnh hưởng đến nhiều tệp và chuỗi gọi sau này.
Để xử lý thêm sự khác biệt về độ khó giữa các kho, DeNovoSWE còn đề xuất lọc quỹ đạo nhận biết độ khó. Nói đơn giản, nhiệm vụ dễ nên yêu cầu tỷ lệ vượt qua cao hơn, còn nhiệm vụ khó không thể bị loại bỏ hoàn toàn chỉ vì không đạt điểm số hoàn hảo. DeNovoSWE dựa trên độ phức tạp cấu trúc và đánh giá độ khó của LLM để đặt ngưỡng lọc khác nhau cho các khoảng độ khó khác nhau, từ đó đạt được sự cân bằng giữa chất lượng và tính đa dạng.
Điều này đặc biệt quan trọng với nhiệm vụ dài hạn: kho càng phức tạp, càng khó vượt qua tất cả kiểm thử ngay lập tức, nhưng những quỹ đạo của kho khó, điểm thấp, thành công một phần trong đó vẫn chứa đựng khả năng lập kế hoạch và triển khai dài hạn quý giá.
Kết Quả Thực Nghiệm
DeNovoSWE cuối cùng đã xây dựng được 4818 ví dụ nhiệm vụ chuyển tài liệu thành kho chất lượng cao. Đây là môi trường kỹ thuật phần mềm dài hạn có thể thực thi, có thể đánh giá, có thể huấn luyện.
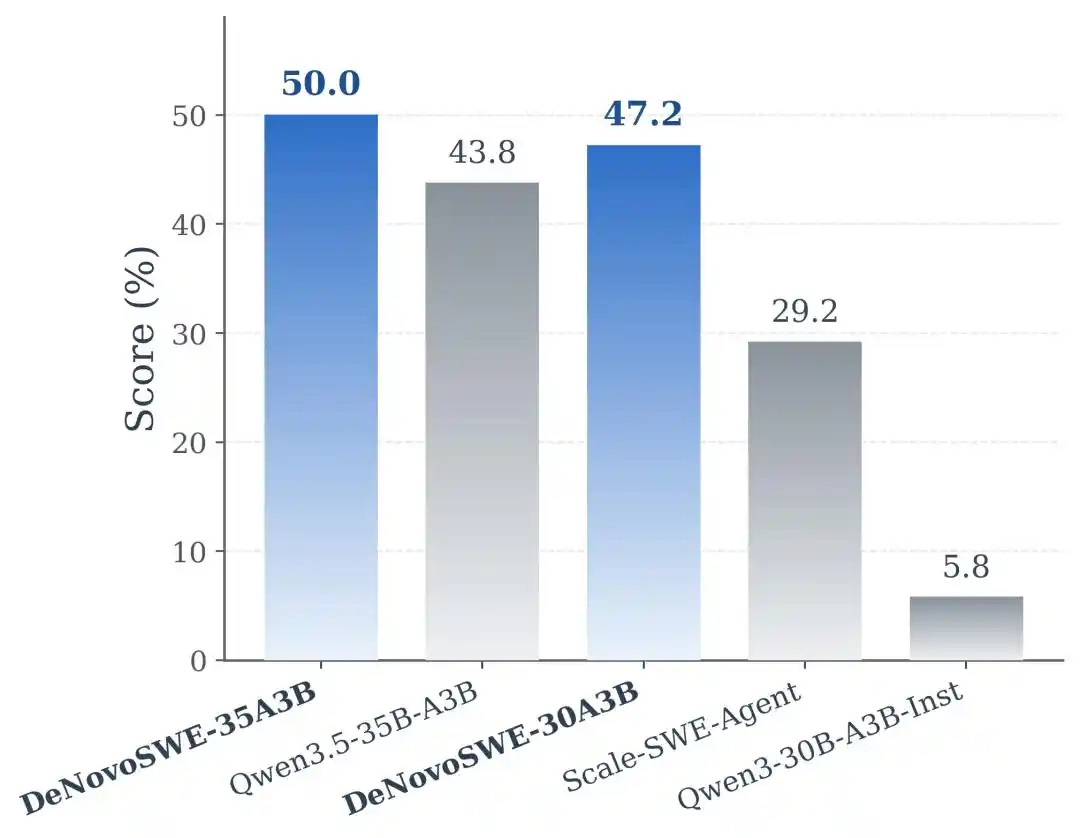
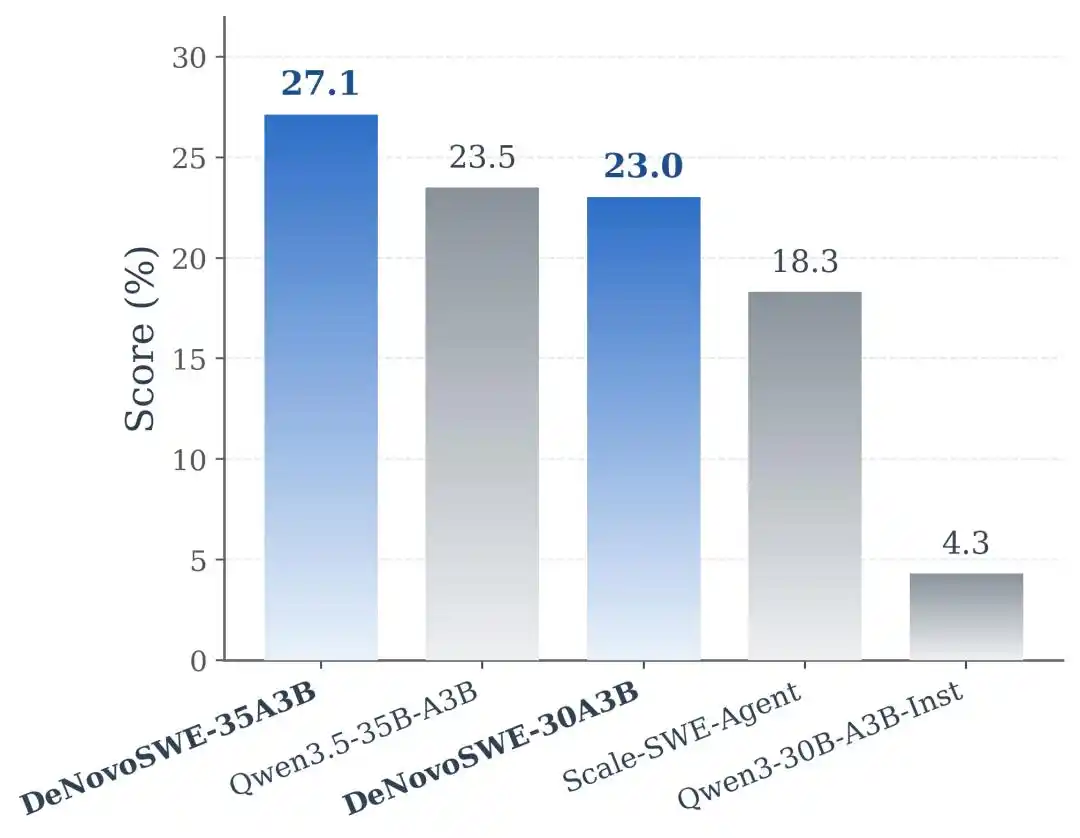
Kết quả thí nghiệm cho thấy, DeNovoSWE mang lại sự cải thiện đáng kể cho khả năng tạo kho dài hạn của mô hình. Trên Qwen3-30B-A3B-Instruct, mô hình gốc chỉ đạt 5.8% trên BeyondSWE-Doc2Repo và 4.3% trên NL2RepoBench. Scale-SWE-Agent được huấn luyện bằng dữ liệu SWE cấp issue thông thường có thể nâng lên 29.2% và 18.3%, cho thấy dữ liệu SWE thông thường thực sự có hiệu ứng chuyển giao. Nhưng khi mô hình được huấn luyện bằng DeNovoSWE, hiệu suất lại được nâng cao thêm lên 47.2% và 23.0%.
Điều này cho thấy, dữ liệu hướng đến "sửa lỗi" không thể hoàn toàn thay thế dữ liệu dài hạn hướng đến "tạo kho hoàn chỉnh". Muốn tác nhân thông minh thực sự học được kỹ thuật cấp kho, cần xây dựng môi trường huấn luyện chuyên biệt cho nhiệm vụ dài hạn.
Trên backbone mạnh hơn Qwen3.5-35B-A3B, DeNovoSWE cũng mang lại lợi ích ổn định: BeyondSWE-Doc2Repo tăng từ 43.8% lên 50.0%, NL2RepoBench tăng từ 23.5% lên 27.1%. Điều này củng cố thêm rằng lợi ích của DeNovoSWE không phải ngẫu nhiên thích ứng với một mô hình cụ thể, mà đến từ chính chất lượng cao của dữ liệu dài hạn.
Kết Luận
Giai đoạn tiếp theo của tác nhân mã thông minh không chỉ là sửa từng issue nhanh hơn, mà còn là có thể hiểu tài liệu, lập kế hoạch kiến trúc, tổ chức module, triển khai giao diện, và cuối cùng tạo ra một kho phần mềm hoàn chỉnh, có thể chạy được.
DeNovoSWE đã xây dựng có hệ thống mục tiêu này thành một tập dữ liệu có thể huấn luyện, có thể kiểm chứng, có thể mở rộng. Nó trả lời một câu hỏi then chốt: Loại dữ liệu nào mới thực sự có thể huấn luyện ra tác nhân thông minh sở hữu năng lực kỹ thuật phần mềm dài hạn?
Câu trả lời không phải là nhiều mã mảnh vỡ hơn, cũng không phải là bài toán đơn giản hơn, mà là nhiệm vụ tạo toàn bộ kho chất lượng cao, có cấu trúc, phù hợp với evaluation, chống rò rỉ.
Từ một tài liệu bắt đầu, tái tạo toàn bộ kho. Đây là ngưỡng cửa mà tác nhân mã thông minh dài hạn cần vượt qua.
Tài liệu tham khảo: https://arxiv.org/pdf/2606.10728
Bài viết này đến từ tài khoản WeChat công chúng "Tân Trí Nguyên", biên tập: LRST






