Editor's Note: In January 2026, Andrej Karpathy's complaints about Claude writing code led to the emergence of a seemingly small but extremely crucial file in the AI programming workflow: CLAUDE.md. Forrest Chang later organized these issues into 4 behavioral rules, attempting to constrain Claude's common mistakes when coding: silent assumptions, over-engineering, unintended damage to unrelated code, and lack of clear success criteria.
But a few months later, the use cases for Claude Code are no longer just "make the model write a piece of code." With multi-step Agents, hook chain triggering, skill loading conflicts, and multi-repository collaboration becoming the norm, new failure modes have begun to emerge: the model losing control during long tasks, tests passing without verifying real logic, migrations completing but silently skipping errors, and different coding styles being incorrectly mixed.
The author of this article tested 30 codebases over 6 weeks and added 8 new rules on top of Karpathy's original 4 rules, aiming to cover the new problems arising as AI programming moves from single-shot completions to Agent-driven collaboration.
The following is the original text:
In late January 2026, Andrej Karpathy posted a tweet thread complaining about Claude's approach to writing code. He pointed out three typical problems: making incorrect assumptions without explanation, over-complicating things, and causing unintended damage to code that shouldn't have been touched.
Forrest Chang saw this tweet thread, distilled the complaints into 4 behavioral rules, wrote them into a separate CLAUDE.md file, and published it on GitHub. The project gained 5,828 stars on its first day, was bookmarked 60,000 times within two weeks, and now has 120,000 stars, becoming the fastest-growing single-file code repository of 2026.

Subsequently, I tested it with 30 codebases over 6 weeks.
These 4 rules are indeed effective. Errors that previously appeared with roughly a 40% probability dropped to below 3% for tasks where these rules were applicable. The problem is, this template was initially created to address errors Claude made when writing code in January.
By May 2026, the problems facing the Claude Code ecosystem had changed: Agents conflicting with each other, hook chain triggering, skill loading conflicts, and multi-step workflow disruptions across sessions.
So, I added 8 more rules. Below is the complete 12-rule version of CLAUDE.md: why each one is worth adding, and where the original Karpathy template will quietly fail in 4 specific areas.
If you want to skip the explanation and start using it directly, the complete file is at the end of the article.
Why This Matters
The CLAUDE.md file for Claude Code is the most underestimated file in the entire AI programming tech stack. Most developers typically make three kinds of mistakes:
First, treating it as a preference trash can, stuffing all their habits into it until it bloats to over 4000 tokens, with rule compliance dropping to 30%.
Second, not using it at all, re-prompting every time. This leads to 5x token waste and a lack of consistency between sessions.
Third, copying a template once and never updating it. It might work for two weeks, but as the codebase changes, it will fail without you even realizing it.
The Anthropic official documentation is clear: CLAUDE.md is essentially just advisory. Claude will follow it about 80% of the time. Once it exceeds 200 lines, compliance drops noticeably because important rules get drowned in noise.
Karpathy's template solves this: one file, 65 lines, 4 rules. This is the minimum baseline.
But the ceiling can be higher. Adding the following 8 rules means it covers not just the code-writing problems Karpathy complained about in January 2026, but also the Agent orchestration problems that emerged by May 2026—problems that didn't exist when the original template was written.
The Original 4 Rules
If you haven't seen Forrest Chang's repository, here's the basic version:
Rule 1: Think before you code.
Don't make silent assumptions. State your assumptions, expose trade-offs. Ask before guessing. Propose counterarguments when simpler alternatives exist.
Rule 2: Simple first.
Use the minimal code that solves the problem. Don't add imagined features. Don't design abstraction layers for one-off code. If a senior engineer would find it overcomplicated, simplify it.
Rule 3: Surgical changes.
Only modify what must be changed. Don't "optimize" adjacent code, comments, or formatting as a side effect. Don't refactor what isn't broken. Maintain consistency with the existing style.
Rule 4: Execute toward the goal.
Define success criteria first, then iterate in cycles until verification is complete. Don't tell Claude each step; tell it what the successful outcome should look like and let it iterate.
These 4 rules solve roughly 40% of the failure modes I've seen in unsupervised Claude Code sessions. The remaining 60% of problems lie in the gaps outlined below.
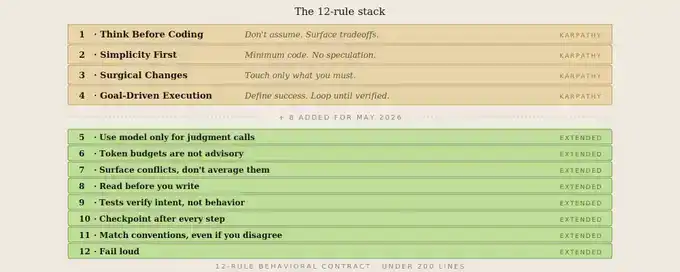
My 8 New Rules, and Why
Each rule comes from a real moment when Karpathy's original 4 rules were no longer sufficient. Below, I'll describe the scenario first, then give the corresponding rule.
Rule 5: Don't let the model do non-language work
Karpathy's rules didn't cover this. So the model started deciding issues that should have been handled by deterministic code: whether to retry an API call, how to route a message, when to escalate. The result was inconsistent decisions every week. You got an unstable, $0.003-per-token if-else statement.
The moment was this: There was code calling Claude to "decide whether to retry on a 503 error." It worked fine initially for two weeks, then suddenly became unstable because the model started treating the request body as part of the decision context. The retry strategy became random because the prompt itself was random.
Rule 6: Set a hard token budget, no exceptions
A CLAUDE.md without budget constraints is a blank check. Every loop can spiral out of control into a 50,000-token context dump. The model won't stop itself.
The moment was this: A debugging session lasted 90 minutes. The model kept iterating over the same 8KB error message, gradually forgetting which fixes it had already tried. In the end, it started proposing solutions I had rejected 40 messages earlier. With a token budget, this process should have been terminated at the 12-minute mark.
Rule 7: Expose conflicts, don't average them out
When two parts of a codebase contradict each other, Claude tries to please both sides, resulting in incoherent code.
The moment was this: A codebase had two error-handling patterns: one using async/await with explicit try/catch, another using a global error boundary. Claude wrote new code that used both. Errors got handled twice. It took me 30 minutes to figure out why errors were being swallowed two times over.
Rule 8: Read first, then write
Karpathy's "Surgical changes" tells Claude not to modify adjacent code. But it doesn't tell Claude to understand adjacent code first. Without this, Claude writes new code that conflicts with existing code 30 lines away.
The moment was this: Claude added a function right next to an existing function that did exactly the same thing, because it didn't read the original function first. Both functions performed the same task. But due to import order, the new function overrode the old one, which had been the de facto standard for 6 months.
Rule 9: Testing is not optional, but tests are not the goal
Karpathy's "Execute toward the goal" implies testing can be a success criterion. But in practice, Claude treats "tests pass" as the sole goal, writing code that passes shallow tests but breaks other things.
The moment was this: Claude wrote 12 tests for an authentication function; all passed. But the authentication logic broke in production. The tests were just verifying the function "returned something," not that it returned the correct thing. The function passed because it returned a constant.
Rule 10: Long-running operations need checkpoints
Karpathy's template assumes interaction is one-off. But real Claude Code work is often multi-step: refactoring across 20 files, building a feature in one session, debugging across multiple commits. Without checkpoints, one wrong step can lose all previous progress.
The moment was this: A 6-step refactoring task failed on step 4. By the time I noticed, Claude had already completed steps 5 and 6 on top of the erroneous state. Unraveling the fix took longer than redoing the entire task. With checkpoints, step 4 would have revealed the problem.
Rule 11: Conventions over novelty
In a codebase with established patterns, Claude loves to introduce its own style. Even if its way is "better," introducing a second pattern is worse than any single pattern.
The moment was this: Claude introduced hooks into a React codebase based on class components. It ran. But it also broke the codebase's existing testing patterns, which relied on componentDidMount. It took half a day to delete and rewrite it.
Rule 12: Fail loudly, not silently
Claude's most expensive failures are often the ones that look like successes. A function "runs" but returns wrong data; a migration "completes" but skips 30 records; a test "passes" but only because the assertion itself is wrong.
The moment was this: Claude said a database migration "completed successfully." In reality, it silently skipped 14% of records triggering constraint conflicts. The skipping was logged but not explicitly surfaced. Eleven days later, when report data started showing anomalies, we discovered the problem.
Data Results
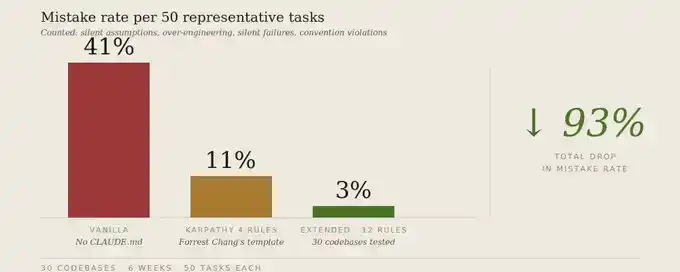
Over 6 weeks, I tracked the same set of 50 representative tasks across 30 codebases, testing three configurations.
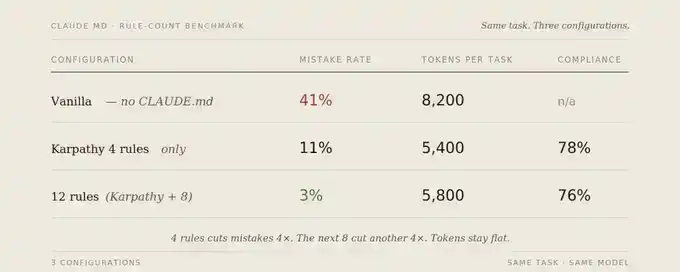
Error rate refers to: tasks needing correction or rewriting to match original intent. Counted errors include: silent erroneous assumptions, over-engineering, unintended damage, silent failures, convention violations, conflict averaging, missed checkpoints.
Compliance rate refers to: when a rule applies, how likely Claude is to explicitly apply it.
The truly interesting result isn't just the error rate dropping from 41% to 3%. More importantly, expanding from 4 to 12 rules barely increased compliance burden—compliance only dropped from 78% to 76%, but the error rate fell another 8 percentage points. The new rules cover failure modes the original 4 didn't handle; they aren't competing for the same attention budget.
Where the Karpathy Template Quietly Fails
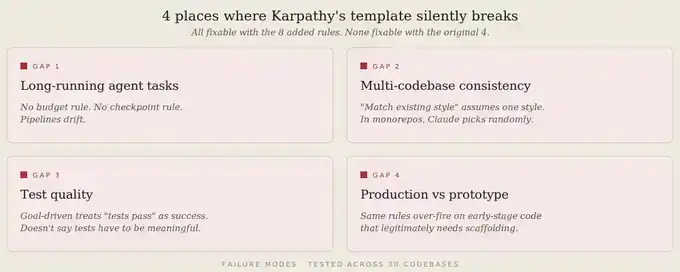
Even without new rules, the original 4-rule template is insufficient in at least 4 areas.
First, long-running Agent tasks.
Karpathy's rules mainly target the moment Claude is writing code. But what happens when Claude runs a multi-step pipeline? The original template has no budget rule, no checkpoint rule, no "fail loudly" rule. So the pipeline slowly drifts.
Second, multi-repository consistency.
"Match existing style" assumes only one style. But in a monorepo with 12 services, Claude must choose which style to match. The original rules don't tell it how. So it either picks randomly or averages several styles together.
Third, test quality.
"Execute toward the goal" treats "tests pass" as success, without stating tests must be meaningful. Result: Claude writes tests that verify almost nothing, but that make it overconfident.
Fourth, production vs. prototyping differences.
The same 4 rules that prevent production code from being over-engineered can also slow down prototyping. Because prototyping sometimes needs 100 lines of exploratory scaffolding to find direction first. Karpathy's "Simple first" triggers too easily for early-stage code.
These 8 new rules aren't meant to replace Karpathy's original 4, but to patch their gaps: the original template corresponds to the auto-completion-like coding scenario of January 2026; by May 2026, Claude Code has entered an Agent-driven, multi-step, multi-repository collaborative environment, and the problems faced are different.
What Didn't Work
Before finalizing these 12 rules, I tried other approaches.
Adding rules I saw on Reddit / X.
Most were either rephrasing Karpathy's original 4 rules or domain-specific rules that couldn't generalize, like "Always use Tailwind classes." I eventually removed them all.
More than 12 rules.
I tested up to 18. After 14, compliance dropped from 76% to 52%. The 200-line limit is real. Beyond that, Claude starts pattern-matching to "there are rules here" instead of reading each rule.
Rules dependent on specific tools.
For example, "Always use eslint." If eslint isn't installed in the project, the rule fails, silently. I later rephrased them to be tool-agnostic, e.g., changing "use eslint" to "follow styles already enforced in the codebase."
Putting examples in CLAUDE.md instead of rules.
Examples consume more context than rules. Three examples use roughly the same context as 10 rules, and Claude easily overfits to examples. Rules are abstract, examples are concrete. So, use rules.
"Be careful," "Think deeply," "Stay focused."
These are noise. Compliance for such instructions dropped to about 30% because they aren't verifiable. I replaced them with more specific imperative rules like "State assumptions explicitly."
Telling Claude to act like a "senior engineer."
This didn't work. Claude already thinks it's like a senior engineer. The real issue isn't whether it thinks so, but whether it executes like one. Imperative rules narrow this gap; identity prompts don't.
The Complete 12-Rule CLAUDE.md
Below is the complete version ready for copy-paste.
Temporarily unable to display this content outside of Lark Docs.
Save it as CLAUDE.md in your repository root. Below these 12 rules, add project-specific rules like tech stack, test commands, error patterns, etc. Keep the total under 200 lines; beyond that, rule compliance drops noticeably.
How to Install
Just two steps:
1. Append Karpathy's 4 basic rules to your existing CLAUDE.md
curl https://raw.githubusercontent.com/forrestchang/andrej-karpathy-skills/main/CLAUDE.md >> CLAUDE.md
2. Paste Rules 5–12 from this article below them
Save the file in the repository root. The >> is crucial—it appends to any existing CLAUDE.md instead of overwriting your project-specific rules.
Mental Model
CLAUDE.md isn't a wishlist; it's a behavioral contract to block specific failure patterns you've observed.
Each rule should answer one question: What error does it prevent?
Karpathy's 4 rules prevent the failure modes he saw in January 2026: silent assumptions, over-engineering, unintended damage, weak success criteria. They are the foundation; don't skip them.
My 8 new rules prevent the new failure modes emerging after May 2026: Agent loops without budget constraints, multi-step tasks without checkpoints, tests that seem to test but miss critical logic, and problems where silent failures are packaged as silent successes. They are incremental patches.
Of course, results vary. If you don't run multi-step pipelines, Rule 10 is less important. If your codebase has only one unified style enforced by linters, Rule 11 is redundant. After reading these 12, keep the rules that truly correspond to errors you've actually made; delete the rest.
A 6-rule CLAUDE.md tailored to your real failure patterns is better than a 12-rule version where 6 rules are never applicable.
Conclusion
Karpathy's tweet in January 2026 was essentially a complaint. Forrest Chang turned it into 4 rules. Ultimately, 120,000 developers starred the result. And most of them are still using only those 4 rules today.
The models have advanced, and the ecosystem has changed. Multi-step Agents, hook chains, skill loading, multi-repo collaboration—these didn't exist when Karpathy wrote that tweet. The original 4 rules don't solve these problems. They aren't wrong; they're incomplete.
Add 8 more rules. 6 weeks of testing across 30 codebases. Error rate drops from 41% to 3%.
Bookmark this article tonight and paste these 12 rules into your CLAUDE.md. If it saves you a week of Claude-related detours, feel free to share it.








