После ухода из Meta Тянь Юаньдун также начал заниматься стартапом.
Стартап Recursive_SI официально представился, опубликовав список основателей, в который входит и Тянь Юаньдун.

Помимо Тянь Юаньдуна, в состав основателей входят Ричард Сохер (CEO), Тим Роктэшель, Джефф Клун, Тим Ши, Сяо Цаймин, Алексей Досовицкий и другие.
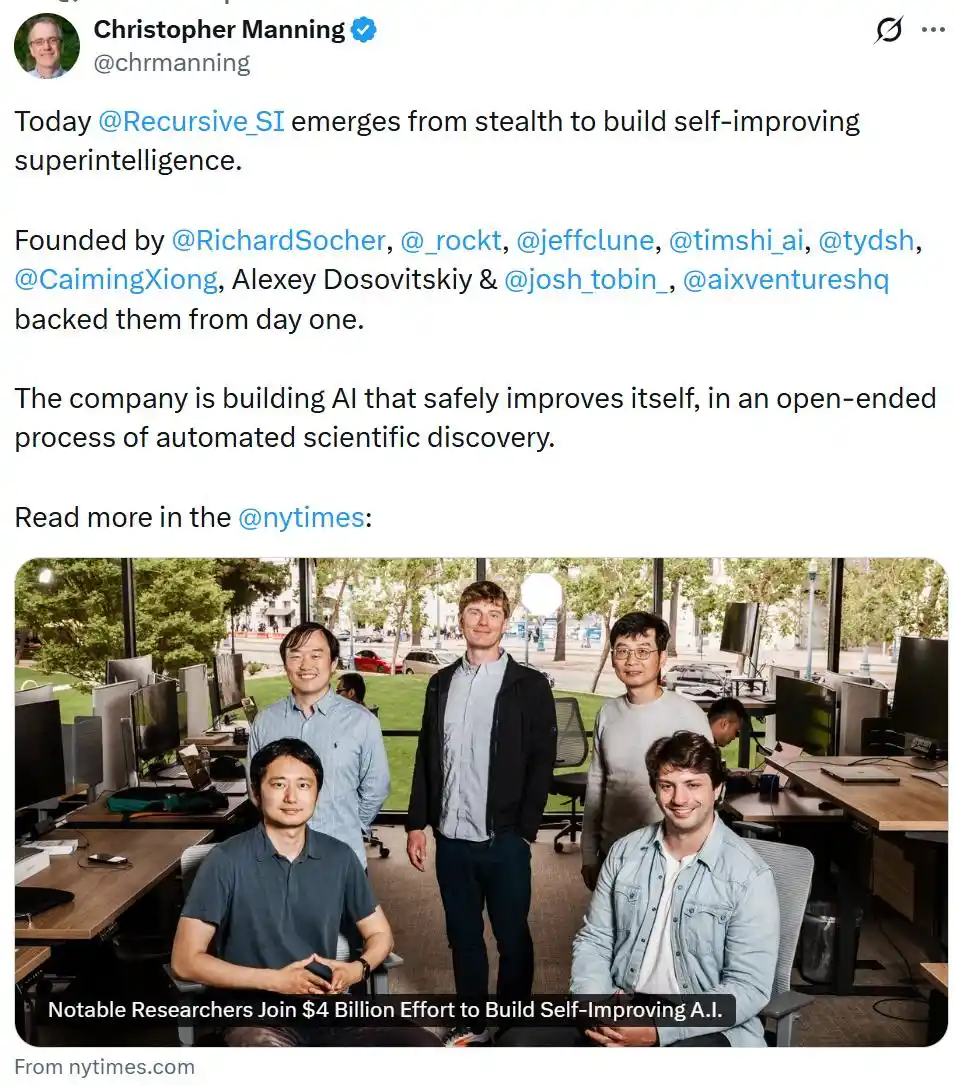
Эти основатели участвовали в создании исследовательских лабораторий ИИ в Salesforce и Uber, занимали руководящие должности в таких командах, как OpenAI, DeepMind, Google Brain и Meta, обладая богатым научно-исследовательским и предпринимательским опытом.
Recursive_SI стремится создать искусственный интеллект, способный самостоятельно проводить эксперименты и безопасно самосовершенствоваться — непрерывно эволюционировать в процессе открытого автоматизированного научного открытия, что считается наиболее вероятным путем к сверхинтеллекту.
На данный момент Recursive привлекла 6,5 миллиардов долларов при оценке в 46,5 миллиардов долларов. Лидерами раунда стали GV (Google Ventures) и Greycroft, значительные инвестиции также внесли AMD Ventures и NVIDIA.
Команда насчитывает более 25 человек и продолжает расти, привлекая множество талантливых специалистов, включая Чжугэ Минчэня, который скоро присоединится.
Чжугэ Минчэнь в настоящее время является учредителем (Founding Member) в Recursive. Он защитил докторскую диссертацию по компьютерным наукам в Университете науки и технологий имени короля Абдаллы (KAUST) под руководством профессора Юргена Шмидхубера, известного как «отец LSTM». Его исследования в основном сосредоточены на кодирующих агентах (Coding Agents), рекурсивном самосовершенствовании (Recursive Self-Improvement, RSI) и парадигмах машин следующего поколения (Next-generation Machine Paradigms).
С 2023 года Чжугэ Минчэнь начал систематически исследовать направление рекурсивного самосовершенствования (RSI).
Во время работы над MetaGPT он выдвинул идею, что агенты должны обладать механизмами постоянной самооптимизации и эволюции способностей, и продолжал продвигать эту исследовательскую линию в последующих работах. Среди них GPTSwarm считается одной из самых ранних парадигм систем RSI в эпоху LLM, впервые систематически предложив и проверив основанную на графах (Graph-based Agents) структуру самоорганизующегося сотрудничества, реализующую координацию, обратную связь и эволюцию способностей между агентами через динамическую графовую структуру. Её ключевые идеи впоследствии были широко приняты в многочисленных работах по мультиагентным системам и Agentic AI. Работа Agent-as-a-Judge дополнительно исследовала механизмы непрерывной обратной связи и самооценки в долгосрочных задачах, пытаясь решить проблемы непрерывности и стабильной оптимизации агентов в сложных задачах. Исследование NeuralComputer было направлено на архитектуру систем ИИ следующего поколения, изучая новые машинные парадигмы, объединяющие память, рассуждение и способность к автономной эволюции.
Видно, что исследовательская команда Recursive обладает глубоким академическим опытом в области рекурсивного самосовершенствования.
Тянь Юаньдун и другие основатели анонсировали проект в X: «Мы создаем искусственный интеллект, способный автономно открывать знания и рекурсивно самосовершенствоваться — этот открытый процесс фундаментально изменит способ прогресса в науке и технологиях».
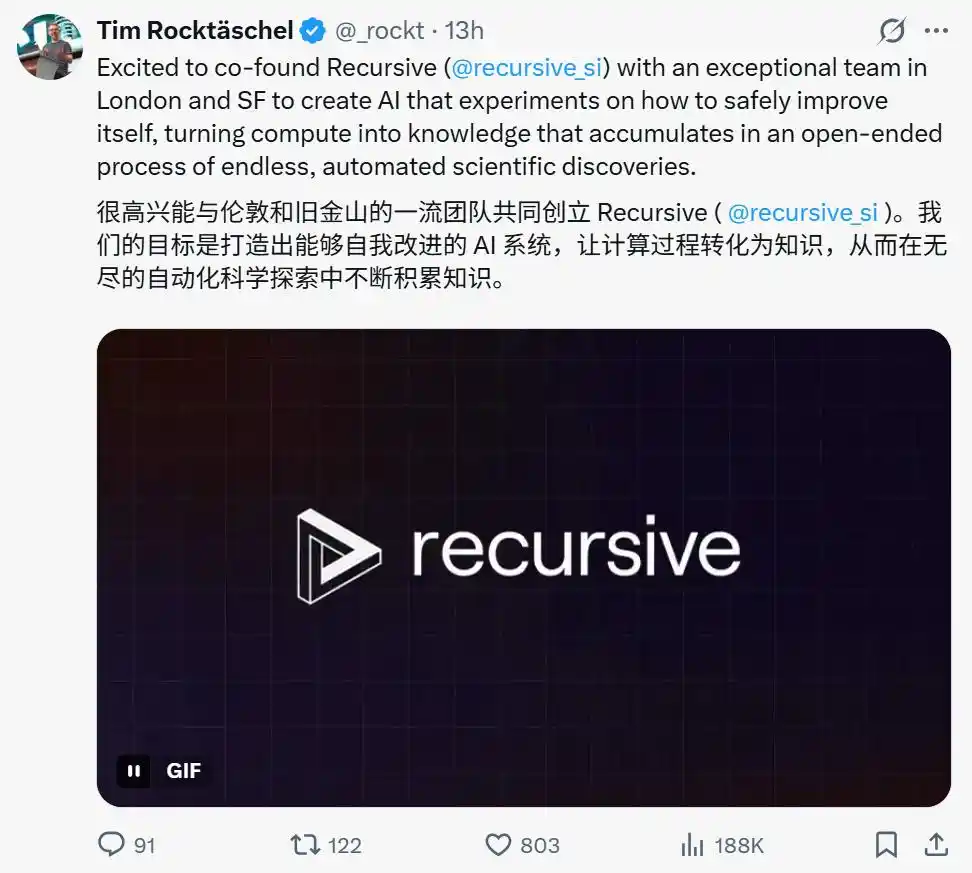
Команда находится на передовом рубеже отрасли в нескольких ключевых областях ИИ с рекурсивным самосовершенствованием.
Члены команды ранее добивались значительных прорывов в таких направлениях, как открытые алгоритмы, алгоритмы качества и разнообразия, алгоритмы генерации ИИ, самосовершенствующиеся программирующие агенты, автоматизированное краснокомандное тестирование и обнаружение возможностей, инженерия промптов и её автоматизация, генерация обучающих задач и сред, базовые мировые модели, глубокое обучение в обработке естественного языка, визуальные трансформеры, генерация с увеличением выборки (RAG), а также ИИ-ученый.
Таким образом, мы с большим нетерпением ждем дальнейших исследований Recursive_SI.
Эта статья взята с официального аккаунта WeChat «机器之心», автор: 机器之心, редактор: 机器之心编辑部