Prompt умер, да здравствует loop.
Именно так Женевьева нарисовал новый акцент для тренда ИИ в недавних горячих обсуждениях в Интернете:
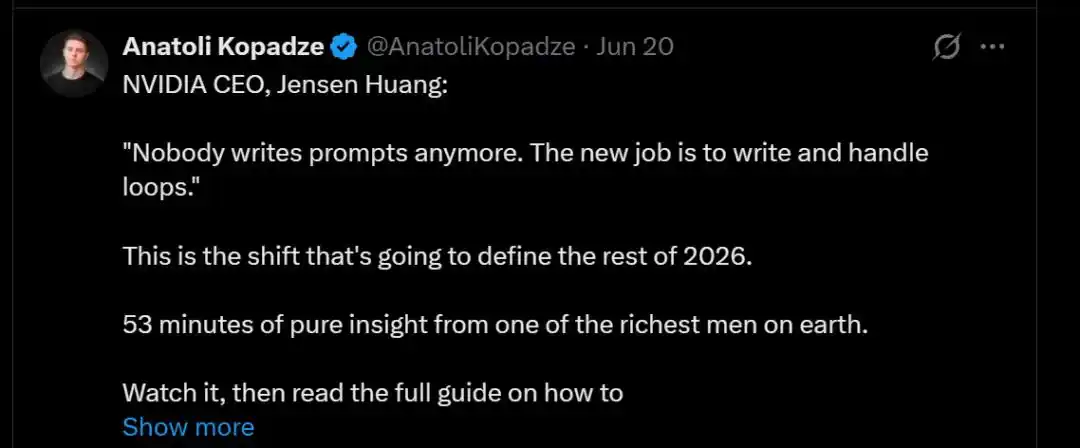
Никто больше не пишет prompts. Новая работа — писать и управлять loops. (Сейчас вообще никто не пишет Prompt, ключевая работа новой эпохи — это написание и управление loop.)
Что такое loop? Дословно это слово переводится как «цикл», а на языке мира ИИ это:
Вы больше не отдаёте инструкции ИИ вручную, а проектируете систему, которая сама отдаёт команды, сама проверяет результат и, если не годится, переделывает, пока задача не будет выполнена.
Хм? А разве это не то, чем сейчас занимаются Agent'ы? Зачем тогда выдумывать новую концепцию?
Пока оставим этот вопрос в стороне. Оглядевшись вокруг, я обнаружил, что этот «loop» действительно набирает популярность —
Помимо Хуана, о нём говорят и активно продвигают «отец лобстеров» Питер, «отец Claude Code» Борис Черный, Эндрю Ын и другие большие шишки.
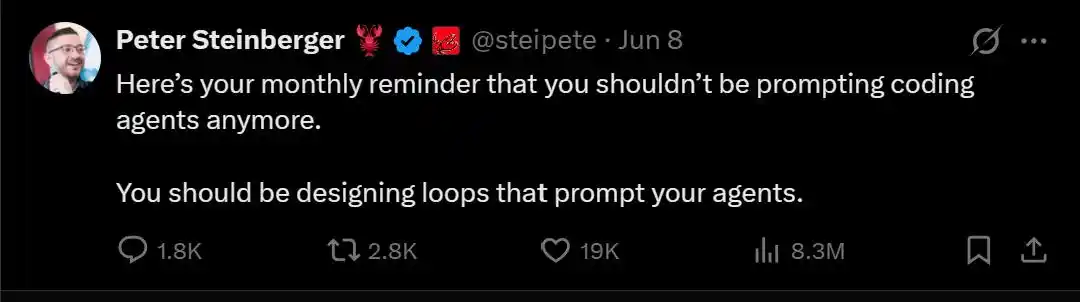
(Питер) Перестаньте писать промты для программирующих Agent'ов, проектируйте циклы, пусть циклы дают подсказки Agent'ам за вас.
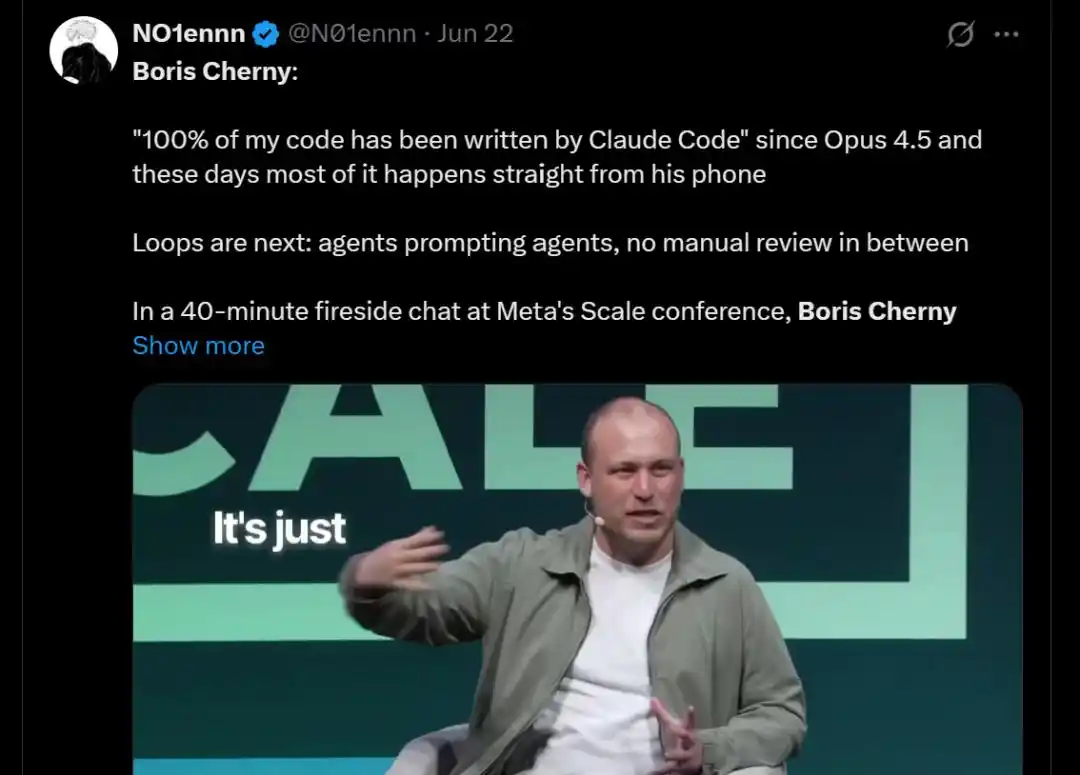
(Борис) Я больше не пишу промты для Claude. У меня работает куча циклов, именно они отдают команды Claude и решают, что делать дальше. Моя работа — писать циклы.
И когда «написание loop» стало для больших шишек новой рутиной вместо «написания prompt», очевидно, что loop перешагнул стадию «просто ещё одной новой концепции».
Остаются только вопросы:
Что конкретно означает loop? Почему он вдруг стал таким популярным?
Что же такое loop на самом деле
Чтобы понять эту новую штуку, нужно сначала вспомнить старую парадигму.
Стандартная процедура ИИ-программирования последних двух лет выглядела так:
Вы пишете один prompt, ИИ выдаёт кусок кода, вы недовольны, пишете ещё один, ИИ исправляет, вы снова смотрите......
В общем, постоянное перетягивание каната, человек постоянно следит.
Капатхи ранее косвенно критиковал то, что «человек — это узкое место», и советовал:
Нельзя сидеть и ждать, чтобы написать промт для каждого шага, нужно вытащить себя из процесса.
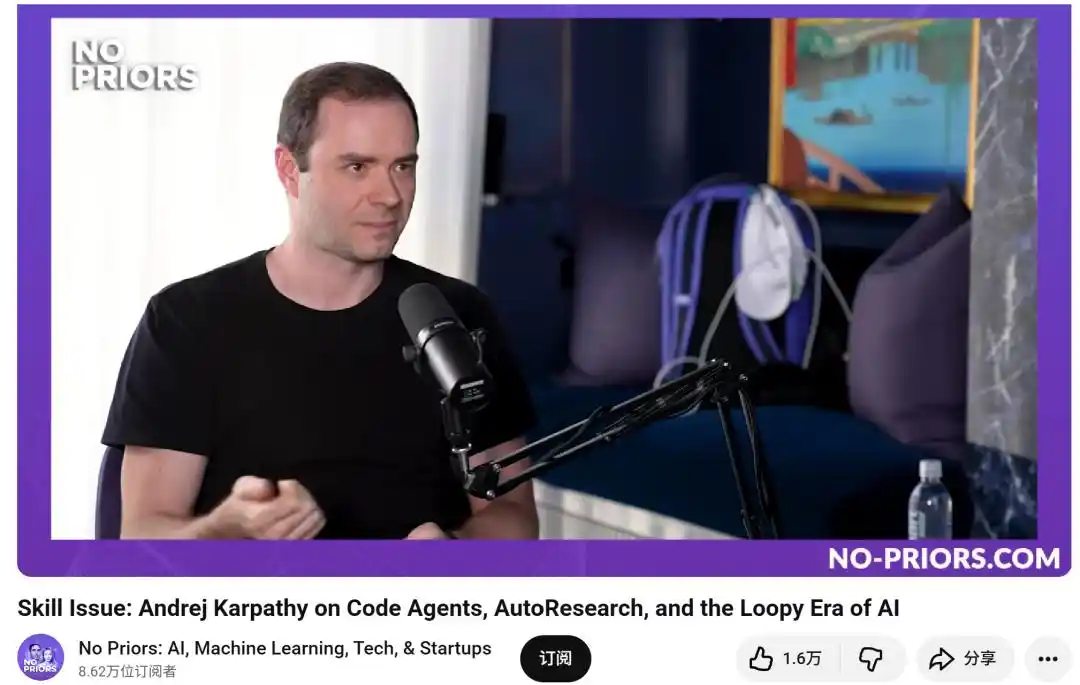
Вытащить человека из процесса — это как раз то, что решает loop.
Его основная логика заключается всего в одной фразе:
Вы определяете цель, ИИ работает самостоятельно, по завершении сам проверяет результат, если не проходит — начинает новый раунд с сообщением об ошибке, и так до успеха или до достижения лимита бюджета.
В этот момент роль человека меняется с «посредника» на «проектировщика правил».
Так что возвращаемся к первоначальному вопросу: чем это отличается от Agent?
Очевидно, Agent — это тот, кто выполняет работу, а loop — это механизм управления, который позволяет этому работнику продолжать работу без вашего присмотра.
Agent без loop — вы говорите, он делает, по сути оставаясь послушным инструментом.
Agent с loop действительно превращается в самодостаточную систему.

Принцип действительно не кажется сложным, но всё ещё выглядит несколько абстрактно.
Не спешите, я покопался в текущей практике внедрения loop и обнаружил, что он уже спрятан в знакомых нам системах.
Вокруг loop на уровне внедрения продуктов уже сложилась «дуополия».
Одна из них — это Claude Code, которым мы все пользуемся каждый день. Вокруг loop он построил три компонента:
/loop отвечает за периодические циклы, /goal — за целевое управление (работает до достижения условия проверки), /schedule — за облачные периодические задачи (могут работать и при закрытом ноутбуке).
Самая тонкая конструкция среди них — это /goal, за которой скрывается ключевой принцип loop — нельзя проверять свою же работу.
Claude Code встроил этот принцип прямо в архитектуру продукта:
Код пишет большая модель, проверяет результат — отдельная небольшая модель Haiku, каждая модель выполняет свою роль.
Таким образом, Agent не может сам себе ставить высокие оценки, и проверка имеет реальную силу.

Другая — это OpenAI Codex.
Подход Codex больше похож на комбинацию «автоматизированного конвейера + целевое управление + несколько под-Agent'ов». На практике некоторые разработчики видят, как одновременно работает до 8 Agent'ов в своих облачных песочницах, каждый делает свою работу, а потом результаты сводятся вместе.
Интересно, что хотя пути реализации двух компаний различаются, конечная форма оказывается очень похожей —
Обе дробит сложные задачи, распределяет их между несколькими Agent'ами для параллельного выполнения, а затем объединяет результаты.
По публичным оценкам и отзывам сообщества, их производительность уже очень близка.
Это также говорит о том, что сами модели уже не дают большого преимущества, реальная разница заключается в организации loop на верхнем уровне.
Сказав это, давайте просто посмотрим, как работает «отец Claude Code» Борис Черный каждый день, и всё станет ясно.
Он сам говорит, что в ноябре прошлого года удалил IDE, месяц не открывал её и в итоге удалил.
Сейчас у него одновременно работают сотни маленьких Agent'ов: одни сканируют issues на GitHub, другие читают отзывы пользователей в Slack, третьи следят за падениями CI. Каждый Agent работает в своей изолированной ветке кода: один пишет код, другой запускает тесты для проверки.
Только те задачи, с которыми не справились, попадают в его почтовый ящик, чтобы он мог принять решение.
По его словам, с момента выхода Opus 4.5 весь его код написан Claude Code, и теперь большая часть кода пишется прямо на его телефоне.
Далее идёт цикл, Agent'ы подсказывают друг другу, промежуточный человеческий контроль не требуется.
Видите, конечная форма loop уже очень ясна:
Человек не пишет код и не пишет промты, он только пишет правила и условия, всё остальное отдаётся на откуп loop.
Как запустить loop
Итак, как же нам запустить loop?
В X блогер по имени Codez уже всё обобщил за всех, он опубликовал практическое руководство из 14 шагов, я выбрал самое важное.

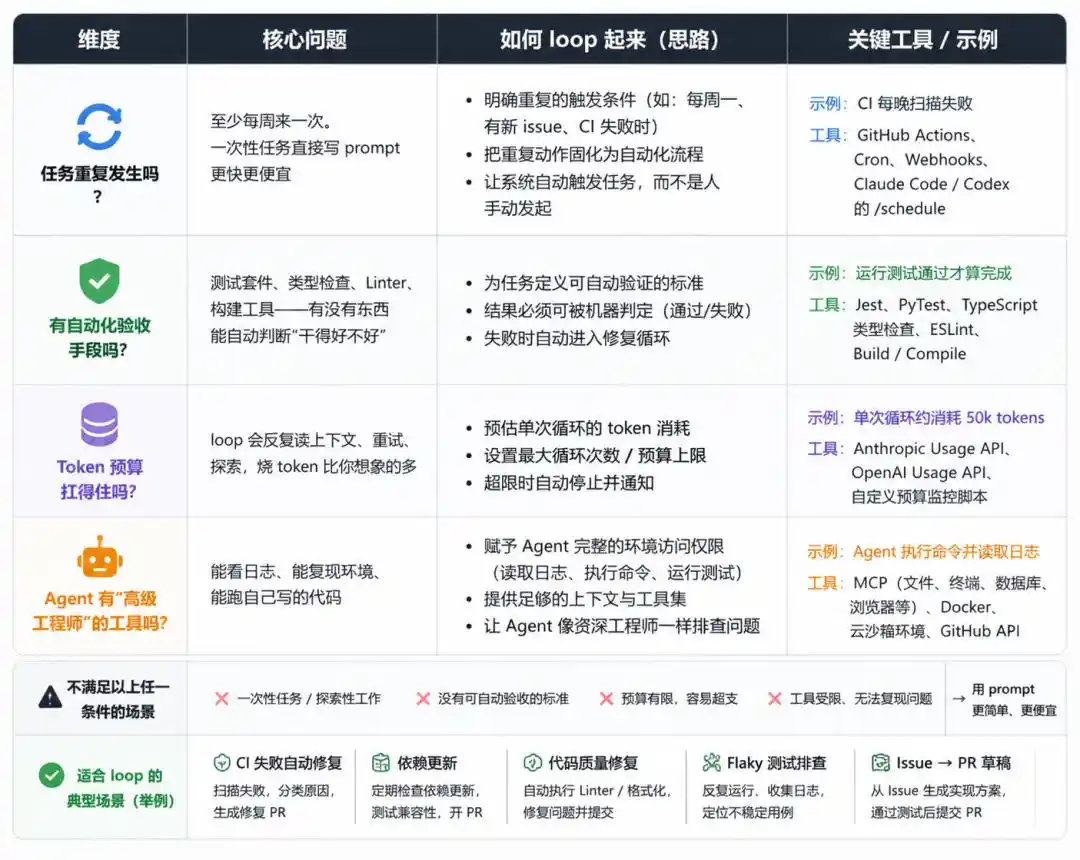
Шаг 1: Не спешите строить, сначала проведите «тест по 4 условиям»
Не всякую работу можно запихнуть в loop, слепое создание приведёт только к убыткам.
Прежде чем действовать, ответьте на четыре вопроса:
Задача повторяется?
Есть ли средства автоматической проверки?
Бюджет на токены выдерживает?
Есть ли у Agent'а инструменты «старшего инженера»?
△
Только если все четыре условия выполнены, стоит создавать loop.
Шаг 2: Начните с минимально жизнеспособного loop
В первый раз не выпендривайтесь, создайте просто четыре компонента:
Триггер (Automation): периодический запуск, запуск по событию — что угодно. В Claude Code используйте /loop, в Codex — панель Automations.
Навык (Skill): запишите контекст проекта в STATE.md, чтобы не приходилось объяснять всё заново при каждом запуске.
Файл состояния (State File): используйте Markdown для записи «на чём остановились, что получилось, что сломалось», чтобы продолжить в следующий раз.
Ворота (Gate): тесты, проверка типов, сборка — всё, что может автоматически блокировать плохие результаты.
И последовательность очень важна: сначала запустите вручную один раз → запишите как Skill → упакуйте в loop → и только потом настройте периодичность.
Пропуск шагов — основная причина смерти loop в производственной среде.
Шаг 3: Будьте тем, кто «разделяет работы», а не тем, кто «проверяет работы»
Самый важный принцип во всём дизайне loop, о котором уже говорилось, — пишущий код и проверяющий код должны быть разделены.
Применение на практике:
Одна модель (или под-Agent) отвечает за написание, другая независимая модель (или под-Agent) отвечает за проверку, причём проверяющий не должен видеть процесс рассуждения пишущего.
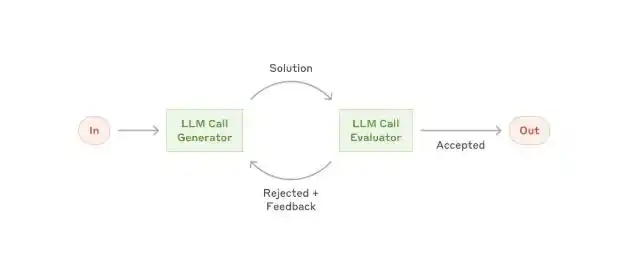
Почему это так важно? Потому что, когда модель оценивает свой собственный код, она часто «слишком мягко судит».
Весь код, который «выглядит хорошо», скорее всего, имеет кучу недостатков перед лицом независимого проверяющего.
Шаг 4: Не наступайте на грабли, на которые уже наступили другие
Вот несколько советов, как избежать ловушек.
1. Отсутствие жёстких условий остановки. Loop будет работать, пока вы не заметите счёт или не упрётесь в лимит, поэтому нужно установить лимит токенов, лимит итераций, ограничение по времени.
2. Состояние не сохраняется. Память Agent'а кратковременна, то, что он узнал сегодня, он забудет завтра, поэтому нужно записывать в файл состояния (STATE.md) и читать при каждом запуске.
3. Не поручайте loop работу, требующую «суждения». Рефакторинг архитектуры, код авторизации, логика оплаты, принятие решений о направлении продукта — не трогайте это loop'ом. Loop подходит для работы с «чётким правильным/неправильным, проверяемой машиной, не зависящей от человеческого суждения», такой как автоматическое исправление Lint, PR обновления зависимостей, классификация падений CI, воспроизведение плавающих тестов.
4. Не читайте Diff. Loop сливает код всё быстрее, ваше понимание кодовой базы становится всё более поверхностным. Это «долг понимания» — реальная цена не в счёте за токены, а в том, что однажды вам придётся отлаживать систему, которую никто в команде не читал. Поэтому советую читать Diff, хотя бы бегло просматривать.
Шаг 5: Измерительный показатель только один
Не обращайте внимания на то, сколько токенов потрачено, сколько PR открыто, сколько задач выполнено.
Единственный полезный показатель: Сколько в среднем стоит каждое принятое изменение.
Если ваш «процент принятия» ниже 50%, значит, вы делаете работу по проверке, которую loop должен был бы взять на себя, то есть loop приносит убытки.
От промтов к loop: четыре смены парадигмы
Принципы и методы понятны, остаётся только один вопрос:
Почему loop стал популярным именно сейчас?
Хотя, строго говоря, концепции Loop Engineering не более трёх недель.
Но она возникла не из ниоткуда, если посмотреть на временную шкалу, можно увидеть очень чёткий путь эволюции.
Большие шишки уже обобщили этот путь, давайте просто воспользуемся их работой:
От Prompt → Context → Harness → loop, всего четыре перехода.
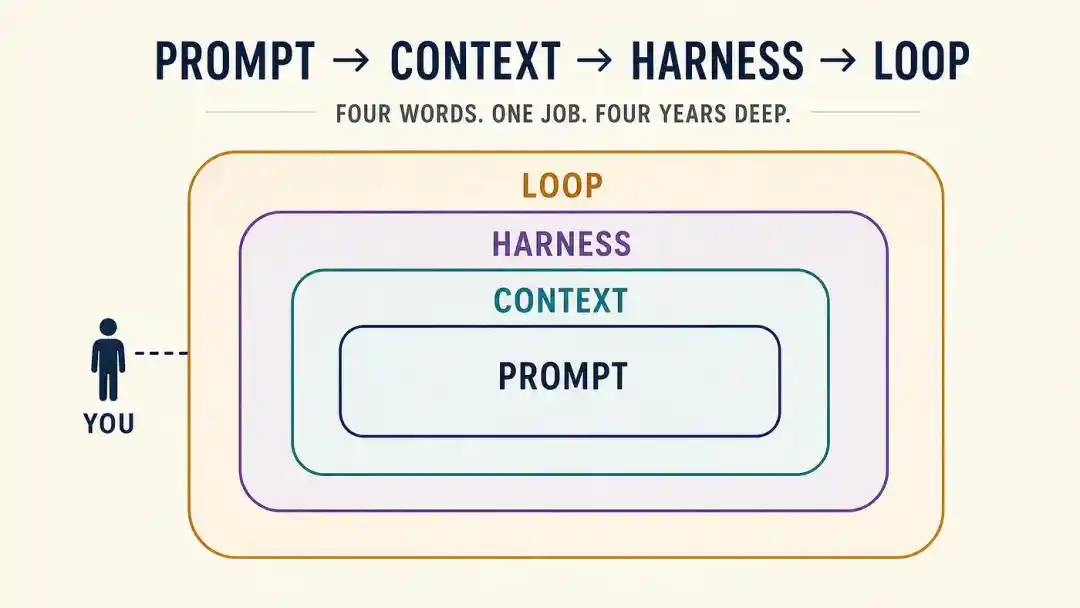
Проще говоря, в 2023–2024 годах это было царство Prompt Engineering.
Тогда все ломали голову над одним вопросом: как написать промт, чтобы ИИ хорошо работал.
Хорошо написанный и плохо написанный промт давали совершенно разные результаты, поэтому в то время «умение писать промт» в значительной степени равнялось «умению пользоваться ИИ».
На этом этапе отношения между человеком и ИИ оставались на самом поверхностном уровне — вы говорите, он отвечает, каждая инструкция должна быть введена человеком лично.
Но по мере усиления возможностей моделей, увеличения контекстного окна, а также распространения RAG и подключения кодовых баз, проблема начала мигрировать в первый раз.
Примерно в 2024–2025 годах индустрия начала подчёркивать важность «Context Engineering», акцент сместился с «как спросить» на «что показать ИИ».
Другими словами, ИИ больше не полагается только на один промт, а зависит от всего предоставленного вами контекста.
На этом этапе способность организовывать информацию стала важнее, чем умение писать промты, а уровень контроля поднялся с «одной фразы» до «кучи информации».
К 2025–2026 годам, по мере того как системы Agent постепенно внедрялись в реальный процесс разработки, проблема продолжила расширяться.
Тогда люди обнаружили, что предоставления информации и контекста тоже недостаточно. ИИ должен уметь подключать инструменты, запускать код, вызывать API, проходить проверки разрешений.
Поэтому ему нужно создать рабочую среду, в которой он может работать, иметь ограничения и получать доступ к ресурсам реального мира.
«Harness Engineering» был создан именно для этого.
И на основе Harness «Loop Engineering» стало новейшим направлением эволюции.
Если Harness решает проблему «может ли ИИ работать в реальной среде», то loop решает проблему «может ли ИИ продолжать работать в этой среде, самостоятельно продвигать задачи, без необходимости, чтобы человек следил за каждым шагом».
Его суть больше не в способности к однократному выполнению, а в способности работать как замкнутая система.
Таким образом, от Prompt к Context, затем к Harness и, наконец, к loop — выглядит как смена концепций, но по сути это непрерывный путь миграции:
Степень человеческого контроля над ИИ постоянно повышается: от «написания одной фразы» до «предоставления информации», затем до «построения системы» и, наконец, до «проектирования цикла».
Процесс постепенного освобождения человеческих рук.

На самом деле, хотя эта штука под названием loop только начала набирать популярность в промышленности, подобная идея в академических кругах уже давно существует.
И многие важные работы связаны с человеком, которого мы все знаем: Шуньюй Яо (из Tencent).
Одна из его самых репрезентативных работ в области больших моделей Agent — это фреймворк ReAct (Reason+Act) 2022 года.
Эта работа получила уровень Oral на ICLR 2023, а затем набрала десятки тысяч цитирований.
ReAct сделал одну ключевую вещь: связал «рассуждение» и «действие» в единый циклический процесс.
Большая модель больше не выдаёт ответ единовременно, а сначала проводит интерпретируемые размышления, затем вызывает инструменты для выполнения действий, после выполнения наблюдает за обратной связью среды, а затем переходит к следующему раунду рассуждений. В абстракции это выглядит так:
Думать → Действовать → Наблюдать → Снова думать → Снова действовать...
Эта структура по сути является самым ранним систематически выраженным прообразом «agent loop».
После ReAct это направление постоянно расширялось: например, Reflexion ввёл механизм обратной связи «учиться на ошибках», Tree of Thoughts расширился до многопутевого поискового рассуждения, а также серия последующих работ по tool-use agent'ам, постепенно усовершенствовавшая полный путь «планирование + выполнение + обратная связь».
Эти академические результаты медленно двигались вперёд, пока в конечном итоге не сошлись в инженерном мире в сегодняшнюю «loop-систему».
Таким образом, с академической точки зрения loop — это не чьё-то изобретение, это постепенно сходящийся технологический путь.
Просто на этом пути оказался знакомый нам китаец, стоявший на ключевом узле.
В заключение не могу не отметить, насколько быстро развивается ИИ — от Prompt до Loop.
Слишком быстрое развитие приводит к тому, что одни взволнованы, а другие не могут скрыть беспокойства.
Именно к последним относится автор термина «Loop Engineering», технический руководитель Google Эдди Османи.
В своей статье «Loop Engineering» он пишет предельно ясно:
Ещё очень рано. Я отношусь сдержанно. Стоимость токенов — нужно быть очень осторожным.

Слова Капатхи заставляют задуматься ещё больше, на конференции Sequoia Capital AI Ascent 2026 он процитировал фразу, которую сам постоянно вспоминает:
Вы можете делегировать своё мышление, но вы не можете делегировать своё понимание.
Переводя: ИИ может придумать решение за вас, но вы сами должны по-настоящему понимать суть проблемы.
Это, пожалуй, самый трезвый голос во всей волне loop.
Ссылки:
[1]https://x.com/i/trending/2068190968809980300
[2]https://x.com/addyosmani/status/2064127981161959567
Эта статья из официального аккаунта WeChat «Qubit» (量子位), автор: И Шуй (一水).





