Представьте себе такую ситуацию:
Пожилой человек, живущий один, поскользнулся и упал в гостиной, боль не позволяет ему позвать на помощь. В этот момент интеллектуальное устройство на его теле или камера в доме «видит» аномалию, и ИИ, не дожидаясь голосовой команды, активно отправляет предупреждение и быстро связывается с родственниками или службой спасения.
Или, допустим, вы смотрите напряженный футбольный матч, в момент ключевого гола у вас нет времени отмотать назад и задать вопрос, а умные очки с ИИ автоматически предоставляют вам замедленный повтор и тактический анализ.
Эти сценарии больше не являются фантазиями о будущем. Это реальные задачи, которые первая в мире полностью открытая стечная визуально-языковая модель взаимодействия JoyAI-VL-Interaction, недавно опубликованная JD.com, пытается решить.

За последние два года границы возможностей больших моделей постоянно расширялись, но основным способом взаимодействия по-прежнему остается логика «пользователь задает вопрос — модель отвечает». Это эффективно, но во многих ситуациях нелогично. Многие важные события происходят слишком быстро, и пользователь не успевает задать вопрос; во многих ситуациях голосовых команд тоже просто нет.
В этом году в индустрии формируется консенсус: ИИ переходит от «предсказания следующего токена» к «предсказанию следующего физического состояния». Это также означает, что ИИ должен эволюционировать от пассивного обработчика информации к активному участнику.
Именно в этот момент JD.com открыла исходный код JoyAI-VL-Interaction — первой в мире полностью открытой модели для взаимодействия с реальным временем на основе зрения и языка, способной в непрерывном видеопотоке самостоятельно определять, когда отвечать, когда молчать и когда передавать сложные задачи фоновой модели.
JoyAI-VL-Interaction стремится доказать: ИИ, который действительно войдет в физический мир, не должен постоянно ждать вопроса. Он должен научиться видеть, активно оценивать ситуацию и оказывать помощь в нужный момент.
Это также более масштабный сигнал от JD AI: от возможностей моделей до отраслевых сценариев, конкуренция в сфере ИИ переходит от вопросов и ответов на экране к реальному миру.
Почему именно визуально-языковое взаимодействие?
В реальном физическом мире огромное количество ключевой информации возникает в моменты, когда пользователь не успевает задать вопрос. Ощущение «не успеваю» в некоторых случаях является проблемой опыта, но чаще — следствием ограничений, налагаемых парадигмой взаимодействия.
Индустрия осознает эти ограничения.
В первой половине 2026 года интерактивность в реальном времени стала самым популярным ключевым словом в области мультимодального ИИ. Индустрия в целом двигается по двум направлениям: одно — сделать диалог в формате «ходов» быстрее, другое — сделать голосовые звонки более естественными.
Первое делает акцент на низкой задержке или произвольном вводе/выводе, но по сути остается в рамках логики «спросишь — ответит»; второе позволяет модели слушать и говорить одновременно, перебивать, что делает опыт ближе к реальному разговору, но фокус остается на голосовых сценариях.
Проблема в том, что многие изменения в реальном мире не превращаются сначала в слова. Пожар, падение, приближающийся автомобиль, изменение содержимого экрана, аномалия на производственной линии — сначала появляется изображение, а потом уже речь. Если ИИ может работать только после того, как человек заговорит, ему сложно быть по-настоящему «присутствующим».
Похожее суждение одновременно с JD.com высказала Thinking Machines Lab, основанная Мирой Мурати. 11 мая эта компания представила концепцию «моделей взаимодействия» (interaction models) и опубликовала предварительные демонстрационные исследования, указав, что парадигма автономного отклика моделей взаимодействия открывает больше пространства для воображения в области сотрудничества «Человек-ИИ» по сравнению с традиционной парадигмой «вопрос-ответ».
Тот факт, что две команды практически одновременно пришли к одной и той же идее, сам по себе является сигналом: превращение интерактивности в собственные, масштабируемые возможности модели — это направление, которого индустрия не сможет избежать в ближайшие годы.
Разница заключается в том, что JD.com ставит визуально-языковое взаимодействие в более центральное положение, выделяя речь в виде подключаемого ввода/вывода, делая визуально-языковую модальность «первоклассной движущей модальностью» для автономного принятия решений моделью.
Другими словами, с момента включения камеры JoyAI-VL-Interaction будет постоянно «наблюдать» за изменениями в физическом мире и самостоятельно решать, стоит ли говорить, что говорить и нужно ли передавать задачу.
Именно здесь заключается потенциал визуального взаимодействия: его можно использовать в таких сценариях, как уход за пожилыми людьми и детьми, помощь слепым, умные очки, комментарии к спортивным событиям, инспекция магазинов, складская логистика, сотрудничество роботов и т.д. Пользователю не нужно сначала формулировать проблему в виде предложения; ИИ может уловить потребность из изменений в окружении.
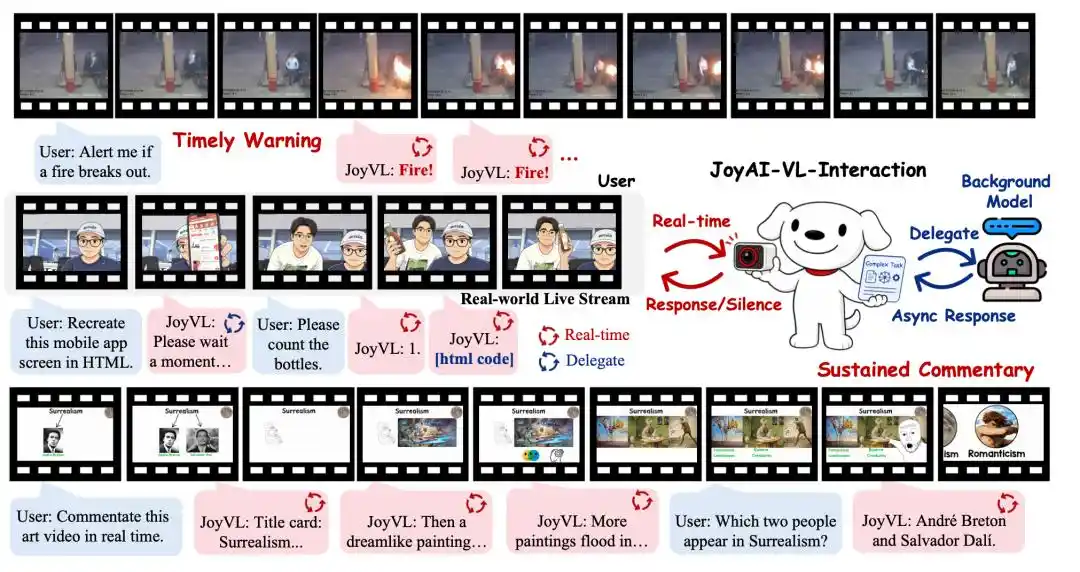
Таким образом, зрение — это не просто другой способ ввода информации, а незаменимый сенсорный канал для движения ИИ к «предсказанию следующего физического состояния».
Технический отчет JD по JoyAI-VL-Interaction также подчеркивает это. В отчете указано, что в шести реальных потоковых сценариях показатель победы JoyAI-VL-Interaction над ведущими китайскими моделями составил 77,6%, а над зарубежными моделями — 87,9%; в сценарии мониторинга и предупреждения, который больше всего проверяет способность обнаружения событий, показатель победы достиг 100%. В отчете говорится, что разница заключается не только в качестве ответов, но и в способности действовать в нужный момент.
Однако реализовать активное визуальное взаимодействие действительно сложнее.
Данные для голосового взаимодействия получить относительно проще: большое количество наборов данных с голосовыми командами позволяет модели учиться тому, когда люди говорят, как перебивают, как отвечают. Данные для визуального взаимодействия нужны совершенно другие. Модель должна научиться понимать, какие сигналы в непрерывно меняющемся изображении заслуживают ответа, а какие требуют молчания.
Более глубокая проблема — способность определять сценарии. В голосовом взаимодействии есть естественная граница запуска: когда пользователь начинает говорить, начинается взаимодействие. В визуальном взаимодействии нет четкого начала и конца, модель должна сама определять границы в безграничном потоке информации.
И здесь заключается уникальность JD.com: эта компания ищет сценарии не в абстрактной лаборатории, а естественным образом работает в реальных бизнес-сетях, таких как розничная торговля, логистика, здравоохранение, промышленность и т.д.
Это означает, что ИИ JD.com сталкивается не с единственным чат-интерфейсом, а с огромным количеством реальных задач: как перемещаются товары, как взаимодействует оборудование, как сотрудничают роботы и люди, как заранее обнаруживаются аномалии. Модель может учиться на реальных потребностях и итеративно улучшаться на основе реальной обратной связи.
Несмотря на технические компромиссы, будущая форма взаимодействия для универсального AGI обязательно будет активным интеллектом. Интеллектуальные агенты должны обладать полным циклом: восприятие окружающей среды, автономное принятие решений и отклик в реальном времени. Поэтому многие компании не отказываются от создания больших моделей для визуального взаимодействия, а просто пока не имеют достаточной почвы для его развития. Вот почему капитал и вычислительные ресурсы сначала устремились в область голосового взаимодействия.
Таким образом, выбор JD.com начать с визуального взаимодействия — это не только технический выбор, но и следствие стратегической позиции. По сравнению со многими игроками в сфере больших моделей, JD.com находится ближе к операционным реалиям физического мира и больше нуждается в ИИ, способном активно воспринимать и реагировать в реальном времени.
Чтобы этот день наступил быстрее, кто-то должен стартовать раньше.
Легковесность, открытый исходный код, возможность развертывания
Что означает «первый в мире полностью открытый стек»?
Переопределение парадигмы взаимодействия звучит масштабно, но когда дело доходит до реальных приложений, первый порог весьма прост: ИИ не должен постоянно мешать людям, но и не должен молчать, когда нужно предупредить.
Обычно от ИИ ожидают, что он будет как можно более разговорчивым, но в сценариях визуального взаимодействия в реальном времени модель, которая постоянно встревает в речь, не выглядит умной. По-настоящему ценная способность — активно появляться в ключевые моменты и сохранять тишину в нерелевантные моменты.
Поэтому JoyAI-VL-Interaction превратил «молчание» в обучаемую способность. Модель должна овладеть тремя уровнями суждений: в каких сценариях следует активно реагировать, в каких — сохранять молчание, а в каких — передавать задачу другим моделям.
Если эти возможности останутся только на бумаге, их ценность ограничена. Акцент JD.com на «полностью открытом стеке» заключается именно в совместной публикации модели, системы вывода и пути создания приложений, чтобы разработчики действительно могли запускать, изменять и использовать их.
JD.com выбрала инженерный путь, способствующий более широкому распространению: модель с 8 миллиардами параметров, которую можно развернуть на одной видеокарте GeForce RTX 3090. При таких параметрах модель сможет работать у индивидуальных разработчиков, на потребительском оборудовании и на периферийных устройствах.
Для визуального взаимодействия в реальном времени такая легкость не означает сокращения возможностей, а скорее более четкое разделение труда.
JoyAI-VL-Interaction больше похож на уровень предварительного взаимодействия, отвечающий за восприятие окружения, определение момента и выполнение краткой коммуникации. При столкновении со сложными задачами, требующими глубокого анализа, он автоматически передает их выбранному пользователем фоновому агенту, такому как OpenClaw, Codex, Claude Code и т.д. Поэтому модели с 8 миллиардами параметров достаточно.
Например, модель может сначала сказать пользователю «Дайте подумать», а затем передать сложную задачу в фоновый режим, продолжая оставаться активной; после получения результата из фонового режима она может синхронизировать ответ с пользователем. В этом процессе она также может продолжать помогать пользователю с другими мгновенными взаимодействиями.
JD.com также разработала облегченную архитектуру на уровне базовой системы: с помощью видеокодирования, долгосрочной памяти и сжатия контекста модель может с относительно низкими затратами непрерывно наблюдать длинные видеопотоки, а сквозная задержка контролируется на уровне доли секунды. Для обычного читателя важны не эти технические термины, а результат: ИИ может дольше и с более низким порогом входа оставаться в реальных сценариях.
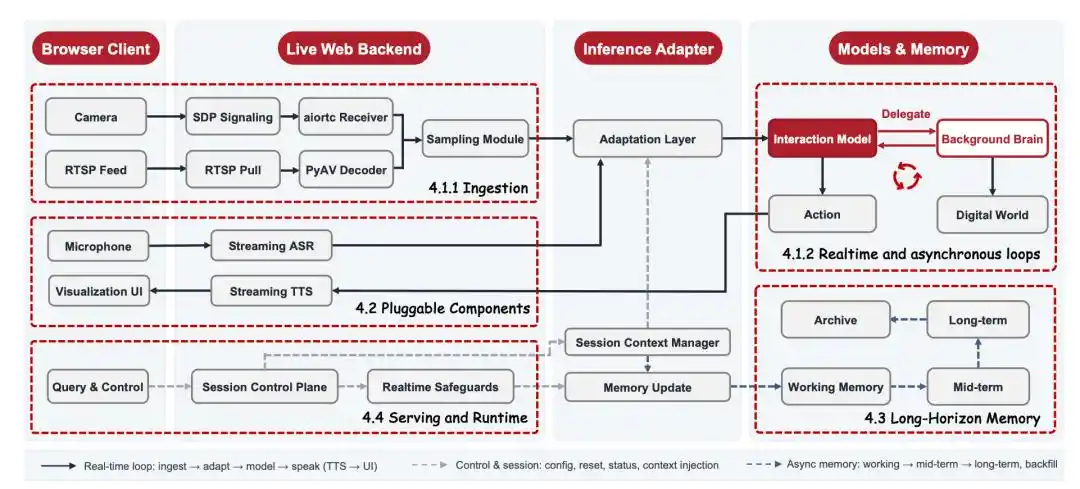
Высокая рентабельность и возможность практического применения также напрямую ведут к стратегии открытого исходного кода JD.com. Только если модель достаточно легкая, система достаточно целостная, а порог развертывания достаточно низкий, визуальное взаимодействие в реальном времени может превратиться из эксперимента нескольких команд в экосистему приложений, которую совместно исследуют больше разработчиков и компаний.
JD.com уже открыла исходный код этой системы вывода, и цель ясна: позволить любому, у кого есть видеокарта GeForce RTX 3090 или выше и камера, быстро создать собственное приложение для визуального взаимодействия в реальном времени.
JoyAI-VL-Interaction получил поддержку vLLM-Omni day-0 и изначально интегрирован в основную ветку vLLM-Omni.
Вернуть ИИ в физический мир
Цель открытия исходного кода — передать потенциал применения на более широкий рынок. Потому что ценность технологического прорыва в конечном итоге должна быть проверена реальным миром.
Первые возможности применения JoyAI-VL-Interaction уже довольно очевидны: в прямых трансляциях спортивных событий ИИ может автоматически комментировать ключевые голы или решающие моменты; при наблюдении за фондовым рынком он может постоянно отслеживать изменения на экране и предупреждать об аномалиях; в домашнем уходе он может активно предупреждать о падениях пожилых людей или приближении детей к опасным зонам; в сочетании с умными очками он может помогать пользователям распознавать дороги, товары, экраны и окружающую обстановку; при обслуживании слепых людей он может преобразовывать визуальную информацию в помощь в реальном времени.
Для JD.com больше всего ожиданий связано с его применением на роботах: модель, которая понимает, когда говорить, когда молчать и когда обращаться за помощью к фоновой системе, может сделать роботов более эффективными и более близкими к ожидаемому «тактичному» интеллектуальному помощнику.
Основная причина, по которой JD.com осмелилась «встряхнуть» эту область в данный момент, заключается в том, что она обладает активами данных физического мира, которыми не обладают другие игроки в сфере больших моделей.
В координатах индустрии 2026 года ценность активов данных физического мира особенно велика.
2026 год в индустрии называют «годом данных воплощенного интеллекта». На этом фоне возникает острое противоречие: высококачественные данные о физическом взаимодействии чрезвычайно дефицитны и далеко не удовлетворяют потребности в масштабном обучении, а узкое место итерации алгоритмов полностью смещается от стороны моделей к стороне данных.
В этот момент JD.com объявила, что в течение двух лет накопит 10 миллионов часов высококачественных видеоданных реальных сценариев, мобилизовав 600 000 человек для сбора.
У JD.com более 3000 реальных бизнес-сценариев, охватывающих розничную торговлю, логистику, здравоохранение, промышленность и другие области. В этом году в Сучжоу была внедрена модель сбора данных на уровне сообществ, массово развернуты самостоятельно разработанные гарнитуры JoyEgoCam, мобилизованы местные малые и средние предприятия и жители для сбора данных в реальных рабочих сценариях.
Скорость развертывания высока. В марте JD.com объявила о создании в Сучжоу первого в мире центра сбора данных для воплощенного интеллекта; в апреле была выпущена первая в индустрии инфраструктура данных для воплощенного интеллекта, охватывающая весь цикл: сбор, хранение, маркировку, обучение, оценку, симуляцию и тестирование; в майте JoyEgoCam запущены в массовое производство для непрерывного сбора данных от первого лица.
Эти данные являются самым дефицитным топливом для обучения воплощенных моделей и моделей визуального взаимодействия. С добавлением данных воплощенного интеллекта в обучение ценность JoyAI-VL-Interaction также возрастет от «модели, которая может активно видеть» до более конкретных физических пространств, таких как роботы, беспилотные автомобили, склады, магазины и дома.
Между моделями и приложениями JoyAI-Echo, открытая JD.com 3 июня, также играет ключевую роль. Echo специализируется на генерации в реальном времени длинных видео, а Interaction — на понимании и взаимодействии в реальном времени. Открытие исходного кода двух моделей в течение месяца означает, что JD.com уже соединила входные и выходные стороны видео-мультимодальности и поставила выход ИИ в физический мир на более долгосрочную позицию.
На презентации запуска 618 в этом году JD.com заявила, что хочет стать «крупнейшим в мире операционным центром физического мира».
В эпоху взаимодействия человека и машины индустрия все больше обращает внимание на то, как ИИ понимает физический мир, но подход JD.com к решению этой проблемы отличается от подхода большинства игроков в сфере больших моделей: эта компания изначально работает в физическом мире.
Склады, доставка, розничная торговля, здравоохранение, промышленность — все это является как тренировочной площадкой, так и полигоном для ИИ и воплощенного интеллекта. Только в логистике JD.com за пять лет планирует внедрить 3 миллиона роботов, 1 миллион беспилотных автомобилей и 100 000 дронов. Эта аппаратная часть также станет местом применения JoyAI-VL-Interaction.
Будь то голосовое или визуальное взаимодействие, модели взаимодействия по сути предназначены для соединения физического и цифрового миров, понимания физического мира и управления цифровым миром.
Открытый исходный код — это первое окно, которое JD.com открывает вовне. На этой трассе, где спрос продвигает технологии, JD.com публикует модели, обучающие данные и целостные системы, делая ставку на более долгосрочное дело: превратить активное взаимодействие из идеи нескольких команд в один из основных путей выхода ИИ в физический мир.
Вы можете запустить сервис одним кликом в vLLM-Omni или запустить его одним кликом из репозитория:
Адрес кода: https://github.com/jd-opensource/JoyAI-VL-Interaction
Адрес модели: https://huggingface.co/jdopensource/JoyAI-VL-Interaction-Preview
Адрес набора данных: https://huggingface.co/datasets/jdopensource/JoyAI-VL-Interaction
Адрес технического отчета: https://huggingface.co/papers/2606.14777








