Кресси, от имени "Оффнорной студии" Квантум Би | Официальный аккаунт QbitAI
DSpark, опубликованный всего неделю назад, уже перенесли на компьютеры Apple.
Перенесённая версия называется mlx-dspark, она запускает модели Gemma-4 12B и Qwen3-4B.
После установки скорость генерации этих двух моделей на Mac увеличилась в 1,6 и 1,4 раза соответственно.
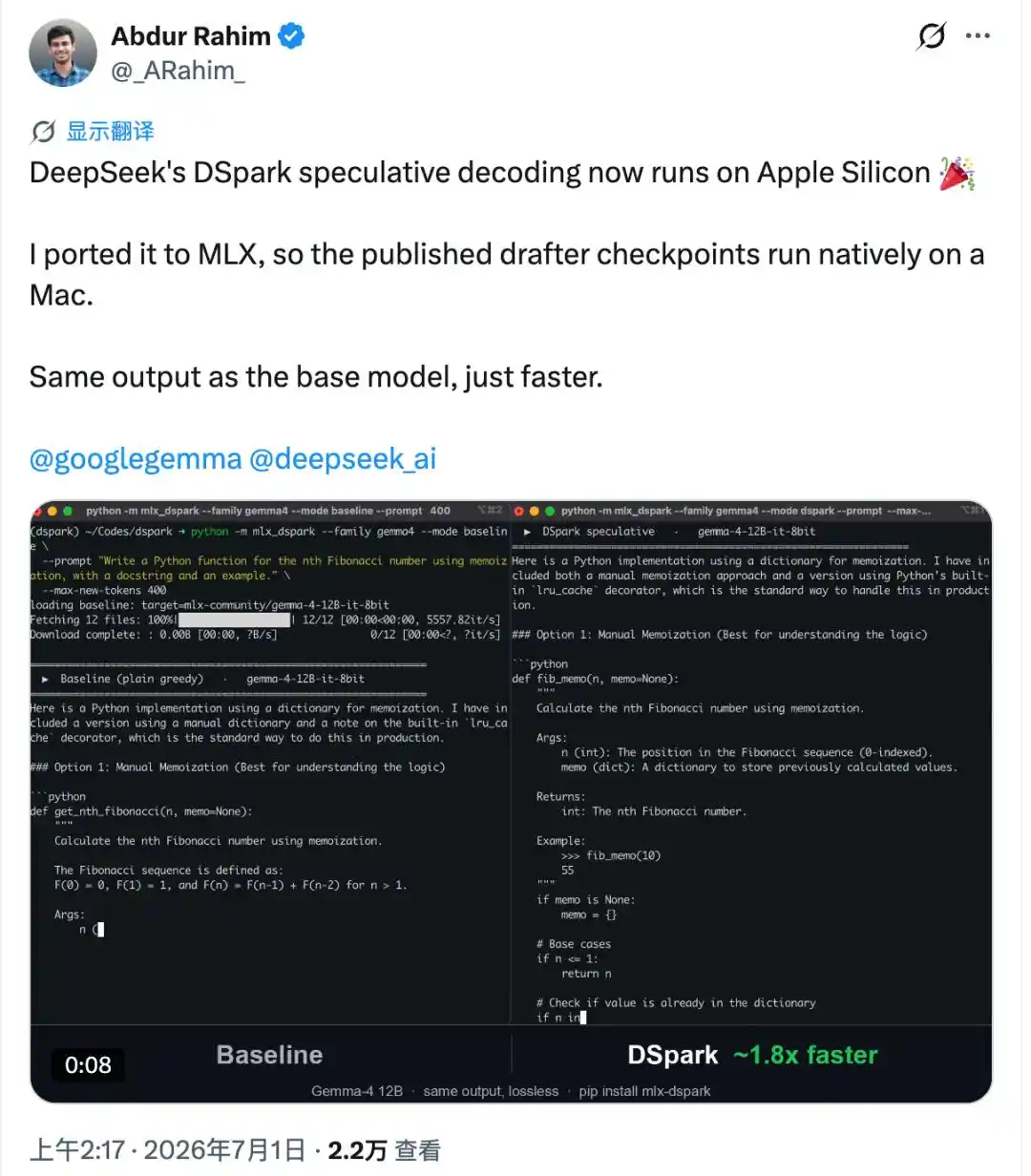
Но самое сложное — это то, что она сделала то, что не удаётся большинству перенесённых версий — вывод в точности совпадает с исходной моделью байт в байт, ни на одну букву не отличается.
То есть, скорость увеличена, а качество нисколько не пострадало.
Создал это Абдур Рахим, инженер, в свободное время занимающийся открытыми проектами. Первая нативная версия для Mac, созданная с момента открытия исходного кода DSpark, — это его работа.
Запуск больших моделей на Mac: ускорение на 60%
Согласно официальным данным для DSpark, открытого DeepSeek 27 июня, ускорение в сценариях серверного применения составляет от 60% до 85%.
Однако на тот момент эта технология была реализована только для GPU в дата-центрах, версии для чипов Apple не было.
mlx-dspark является первой нативной версией этой технологии для чипов Apple.

Идея DSpark заключается в том, чтобы назначить меньшую модель в помощь целевой модели. Маленькая модель сначала выдаёт несколько кандидатных токенов, а целевая модель затем проверяет их все сразу, принимая правильные и отправляя неправильные на пересмотр.
Стоимость этого шага различна для дата-центра и компьютера Apple.
На GPU в дата-центре проверка партии кандидатов больше похожа на аренду автомобиля с водителем — фиксированная цена независимо от количества пассажиров. Декодирование и так является узким местом по памяти, проверка нескольких дополнительных токенов почти не занимает лишнего времени.
Чипы Apple больше похожи на такси со счётчиком — чем больше проверяешь кандидатов, тем больше «накручивает» счётчик.
Рахим провёл замеры: для Gemma-4 12B проверка каждого дополнительного токена занимает около 14 мс. Он рассчитал это в виде модели затрат и пришёл к выводу, что предельная скорость ускорения на чипах Apple составляет около 2,2 раза.
В общем, Рахим перенёс эту вспомогательную маленькую модель из чекпоинта HuggingFace и подключил её к целевым моделям Gemma-4 12B и Qwen3-4B.
Он также перестроил процесс проверки в рамках MLX, проведя квантизацию весов до 4 бит.

В результате, на M4 Pro, по сравнению с официальным инструментом Apple MLX, скорость генерации Gemma-4 12B увеличилась с 18,4 токенов/с до примерно 30 токенов/с, что примерно в 1,6 раза выше; Qwen3-4B — с 52,9 токенов/с до примерно 73 токенов/с, что примерно в 1,4 раза выше.
Кроме того, в mlx-dspark Рахим сделал то, чего не делается в большинстве работ по переносу.
Перенесённая версия также может достичь высокой точности воспроизведения
Большинство версий, переносящих большие модели на локальные устройства, поддерживают только жадное декодирование, то есть на каждом шаге выбирают токен с наивысшей вероятностью.
Рахим в mlx-dspark реализовал метод температурной выборки, изначально описанный в статье о DSpark: черновая модель выдаёт кандидатов, вероятность принятия — min(1, p/q), непрошедшие части заново семплируются из остатка.
Он сам проверил: вывод, полученный по этой схеме, строго соответствует точному распределению, которое выдала бы целевая модель при той же температуре, а не является упрощённой аппроксимацией.
Большинство вариантов спекулятивного декодирования реализуют только жадный режим, потому что проверить его корректность легко — достаточно побайтового сравнения.
Дополнительный шаг, который сделал Рахим, — это самостоятельная проверка распределения выходных данных, полученного в режиме выборки, и подтверждение отсутствия искажений.
Какая точность должна быть у целевой модели, отвечающей за проверку, — это ловушка, которую он обнаружил на собственном опыте.
Если маленькая модель подключена к базовой версии целевой модели, не прошедшей инструктивную тонкую настройку, только 47% выданных кандидатных токенов проходят проверку; при использовании соответствующей версии с инструктивной тонкой настройкой этот показатель возрастает до 82%.
Он также тестировал замену целевой модели на точность bf16: стоимость проверки росла быстрее, чем процент прохождения, что, наоборот, замедляло работу, поэтому для целевой модели оптимальнее всего оставить точность по умолчанию 8-bit.
Для маленькой модели, отвечающей за предварительный подбор кандидатов, используется другой уровень точности.
Сама черновая модель была им сжата — после квантизации до 4 бит она занимает всего 1,8 ГБ, без проблем помещается в память и работает без потерь.
В результате DSpark не только обеспечил ускорение, но и действительно воспроизвёл на устройстве упомянутое в статье увеличение процента принятия на 16%–18%.
DFlash также подключён, задачи по коду выполняются быстрее
После публикации твита в комментариях появилось сообщение от Цзянь Чэня, одного из авторов статьи о DFlash, который спросил, можно ли попробовать их модель.
DFlash — это другая схема спекулятивного декодирования, предложенная в статье лаборатории z-lab в мае этого года. Руководитель авторского коллектива — Чжицзянь Лю, доцент UCSD и одновременно научный сотрудник NVIDIA.
Подход DFlash отличается от DSpark. Он использует однократное параллельное «блочное диффузионное» устранение шума для целого блока из 16 токенов, а не предсказывает пошагово, как DSpark, с учётом зависимостей.
Рахим быстро взялся за дело.
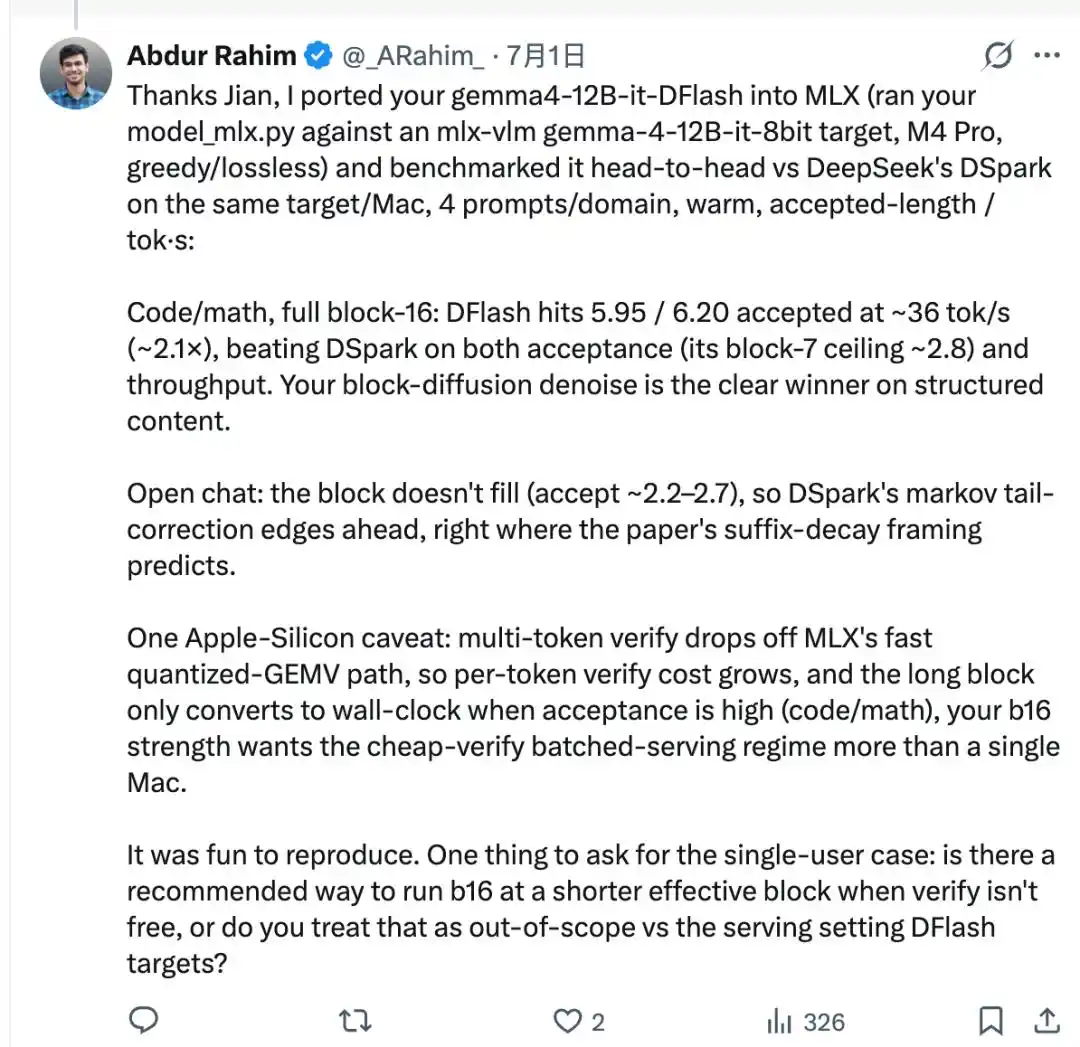
Используя скрипт переноса, написанный самим Цзянем, он подключил gemma4-12B-it-DFlash, выпущенную z-lab, к целевой модели Gemma-4 в mlx-vlm и на том же Mac провёл прямое сравнение с только что протестированным DSpark.
На задачах по коду и математике эффективная длина принятия при блочном декодировании DFlash достигала 5,95–6,20, скорость — около 36 токенов/с, ускорение примерно в 2,1 раза, что превзошло DSpark.
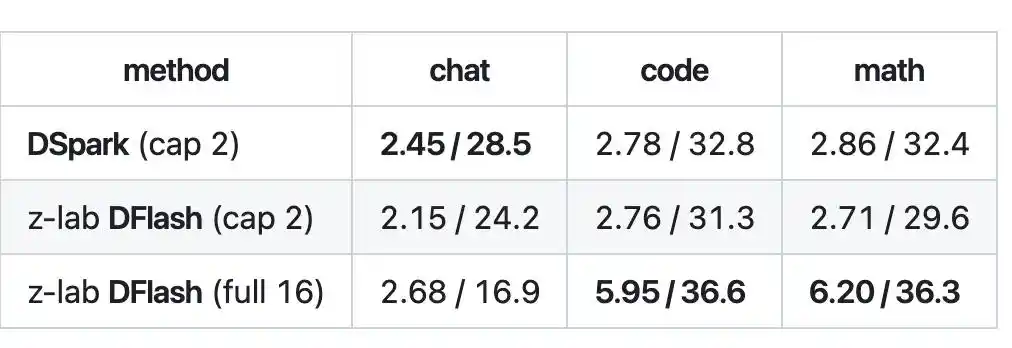
Однако DFlash за один раз генерирует целый блок из 16 токенов, но целевая модель может принять не все, фактически проверку проходит только часть из них. В отрасли это называется «эффективная длина принятия» — блок не всегда заполняется полностью.
Поэтому в таких сценариях, как открытый чат, где содержание трудно предсказать, эффективная длина принятия невысока, блок не заполняется, и преимущество DFlash не раскрывается.
Марковский выход DSpark как раз существует для решения этой же проблемы: при параллельной генерации целого блока токенов, чем дальше позиция, тем более независимыми становятся вычисления, и они могут плохо сочетаться друг с другом. Марковский выход добавляет между этими позициями слой зависимостей, специально корректируя эту проблему.
В результате, в сценариях чата DSpark, наоборот, оказался быстрее DFlash.
В более позднем обновлении mlx-dspark v0.0.3 официально подключили оригинальный DFlash от z-lab в пакет и добавили параметр, позволяющий вручную уменьшать эффективную длину блока для DFlash: в чатах использовать короткие блоки, а в сценариях работы с кодом и математикой — по-прежнему полные блоки по 16.
После этого на одном и том же Mac, с одним и тем же пакетом, можно одновременно выполнять задачи как чата, так и работы с кодом и математикой, не переключаясь между проектами DSpark и DFlash.
Рахим написал в твите, что тот же метод, вероятно, будет работать и с более крупными черновыми моделями Qwen3-8B и 14B.
Ссылки:[1]https://x.com/_ARahim_/status/2072021710602432577[2]https://github.com/ARahim3/mlx-dspark
Статья из официального аккаунта WeChat «Квантум Би», автор: Гуаньчжу Цяньянь Кэцзи (Следим за передовыми технологиями)






