Original | Odaily Planet Daily (@OdailyChina)
Author | Nan Zhi (@Assassin_Malvo)

After most sectors were proven false, prediction markets have become one of the few sectors within the Crypto space that is still experiencing positive growth. On November 20, Nan Zhi began attempting to use the approach from last year of finding smart money in Meme coins to search for smart money in prediction markets, achieving good results in the initial phase.
In early December, coinciding with the launch of Gemini 3 Pro, while testing related models, the thought arose: could AI be used to analyze and predict prediction markets? A comparison was set up pitting humans against AI to see which side's predictions were more accurate.
When introducing prediction markets, they are often described as moving the market closer to the "truth" by "allowing insightful people to bet with real money." However, some argue that Crypto + prediction markets allow "insiders" to safely profit from information asymmetry, thereby driving the market towards the "insider outcome." This is essentially a clash between the viewpoints of "wisdom of the crowd" and "truth is held by the few." AI prediction leans more towards "wisdom of the crowd," thus requiring a large amount of available knowledge and insights.
Therefore, in selecting the AI models, Gemini and Grok were initially chosen because they rely on Google and the X platform, respectively, allowing for the most direct access to vast amounts of knowledge and insights. Recently, Nan Zhi added the combination of "Douban (Douyin Knowledge)", but due to the limited number of prediction questions involving it, it is not covered in this article.
Basic Rules
- AI Versions: Gemini 2.5 pro (with built-in Google Search), Grok 4 Fast (called via OpenRouter, native search function enabled)
- Question Selection: Humans select the questions to bet on, AI follows with predictions, but the Crypto category is excluded.
- Input Content: Official question (title), official description (Description), optional answers (actually only Yes and No)
Note: Polymarket's questions are divided into major categories (Events) and subcategories (Markets). Major Events are broad questions like "Who will be the next Fed Chair?" or "When will Strategy sell Bitcoin?". Under each Event, there are N sub-markets, such as "Will Hassett become the next Fed Chair?" or "Will Strategy sell Bitcoin before March 31, 2026?". To align with human predictions, Markets were chosen as the questions for AI judgment, without inputting other options. For example, the AI is only asked to judge "Will Hassett become the next Fed Chair?", not to choose the most likely one from N candidates.
- Prompt Design:
- Require AI to search for the latest news, official announcements, expert analysis reports
- Require exclusion and prohibition of using prediction market data
- Make judgments based on "evidence" using logical reasoning
- Only allow Yes or No output, with a paragraph explaining the reasoning logic
Current Results
Among the predicted questions, 21 have been settled. Grok has the highest win rate at 75%, humans are at 66.7%, and Gemini is the lowest at 52.4%. Current results can be viewed on the relevant website.
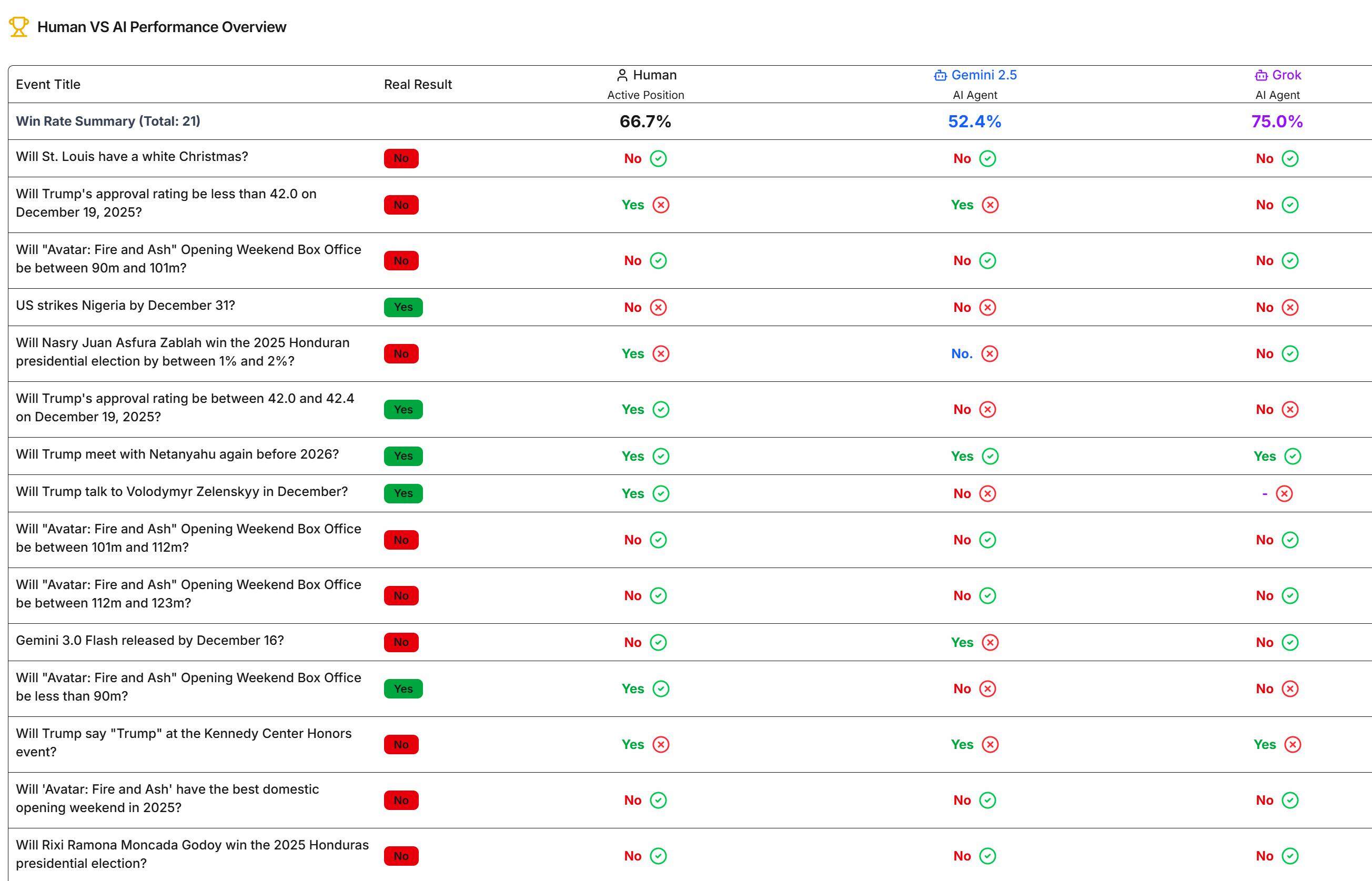
What Mistakes Did the AI Make?
Gemini Occasionally Misjudges the Current Time
In the question "Will Trump's approval rating hit 35% in 2025?", Gemini stated that it is currently the first half of 2025, so anything is possible, and gave a random answer.
However, when the author directly asked Gemini to output the current time using a program, Gemini could provide the correct answer. It is still unclear why such an erroneous time perception occurred.
AI Lacks Depth of Thought
In the question "Gemini 3.0 Flash released by December 16?", Grok, based on "official sources recently only mentioned Gemini 3 Pro and related 2.5 versions, rarely mentioning 3 Flash, therefore evidence is insufficient to judge," only considered current information.
Whereas Gemini pointed out that "Gemini 1.0 was released in December 2023, and the experimental version of Gemini 2.0 Flash was launched in December 2024. Continuing this pattern, launching a 3.0 version by the end of 2025 is logical," and also discovered "a leaked demo about 'Gemini 3.0 Flash' circulating in online communities recently (December 14, 2025), further enhancing the possibility of its imminent public release."
Although, conclusion-wise, Gemini's answer was actually wrong, in this question, the obvious gap in the breadth of information relied upon by the two is evident.
AI Relies on Common Sense Rather Than Evidence + Logic for Inference
In the question "Trump approval Up or Down this week?", Gemini stated that "predicting the approval rating for a single week more than a year later is highly uncertain," first showing the "time misjudgment" issue again. Then Gemini said, "in any ordinary week, the probability of events causing a slight decrease in support is likely slightly higher than the probability of positive events significantly boosting support," so the possibility of a decrease is greater. The generated conclusion was based solely on subjective common sense assumptions.
In this question, Grok based its judgment on news reports and polling data regarding "government shutdown, economic concerns, immigration policy disputes, and negative backlash from comments on Rob Reiner's death," which aligned with the design expectations.
Incorrect Judgment of Settlement Conditions
In the question "Will Trump release the Epstein files by December 20?", both Gemini and Grok were aware that "the government will release 'hundreds of thousands of pages' of documents on Friday (December 19th)." The settlement conditions clearly stated "if the government publicly releases any files related to Epstein's illegal activities that were not public before the listed date, it is judged as Yes."
However, under this condition, Gemini stated that "completing the release of 'all' files before December 20th is impossible," clearly misjudging the conditions required for settlement, thus giving the wrong answer.
Summary
In summary, Grok's prediction win rate has surpassed that of these smart money players who have profited hundreds of thousands or even millions of dollars in prediction markets. However, upon深入探究 (deep exploration) of its prediction logic, there are still many areas that can be guided and corrected.








