The risks of AI-written code lurk within seemingly correct code, potentially leading to data breaches or asset loss. The open-source Narwhal AI Code Risks project compiles real-world cases, early warning signs, and typical risk pathways to help developers identify hidden dangers early and avoid repeating past mistakes.
In 2026, code is being generated at an ever-increasing pace, yet deployed with less and less scrutiny.
More and more often, user requirements are placed in a dialogue box, AI reads the context, completes functions, pulls dependencies, fixes configurations, and even conveniently generates tests.
Before you know it, a piece of code is already sitting in the repository, awaiting merge.
Users have developed a new habit: let the AI write it first and get it running, then see what needs fixing if there's a problem.
But in the software world, the most dangerous things are often pieces of code that appear utterly ordinary: syntactically correct, interfaces valid, tests passing, comments perfect.
Yet it may still introduce non-existent package names, open overly broad permissions, expose databases... or even allow an Agent capable of directly calling system tools to exfiltrate sensitive data from internal systems under prompt injection.
The real danger is not a flashing red error light. It's when all risk indicators show normal.
Risks from AI-generated code used to be scattered: a case buried in a security blog, a clue recorded in an Issue. When the next team encountered a similar problem, they had to piece together the source of risk from scratch and expend immense time and effort conducting large-scale empirical measurements on the code.
Now, Peking University's Narwhal-Lab has just open-sourced Narwhal AI Code Risks, which organizes these information fragments into three categories for researchers to examine: real incidents, early signals, and typical risk paths.

Paper link: https://github.com/Narwhal-Lab/Narwhal-aicode-risks
When All 28 Checks Pass, the System Still Veers Off Course
The first clue was a merged Pull Request, where the signature field prominently featured Claude Opus 4.6, Copilot, and four human developers. All 28 checks passed: No one spotted the issue.
Then, the liquidation bot took a few minutes and seized collateral worth $1,778,044.83.
The configuration file set the price of cbETH to its conversion ratio with ETH, approximately $1.12, instead of the actual price near $2,200.
A semantic price error slipped through development, review, and merge processes, ultimately turning into real loss in the financial system. This is the most glaring aspect of the Moonwell cbETH oracle configuration incident.
The problem lay in code without syntax errors, and human developers not immediately halting the anomalous process. On the contrary, it looked complete, smooth—a normal engineering delivery.
But it is precisely this undercurrent of normalcy that makes it a quintessential example of a security incident.
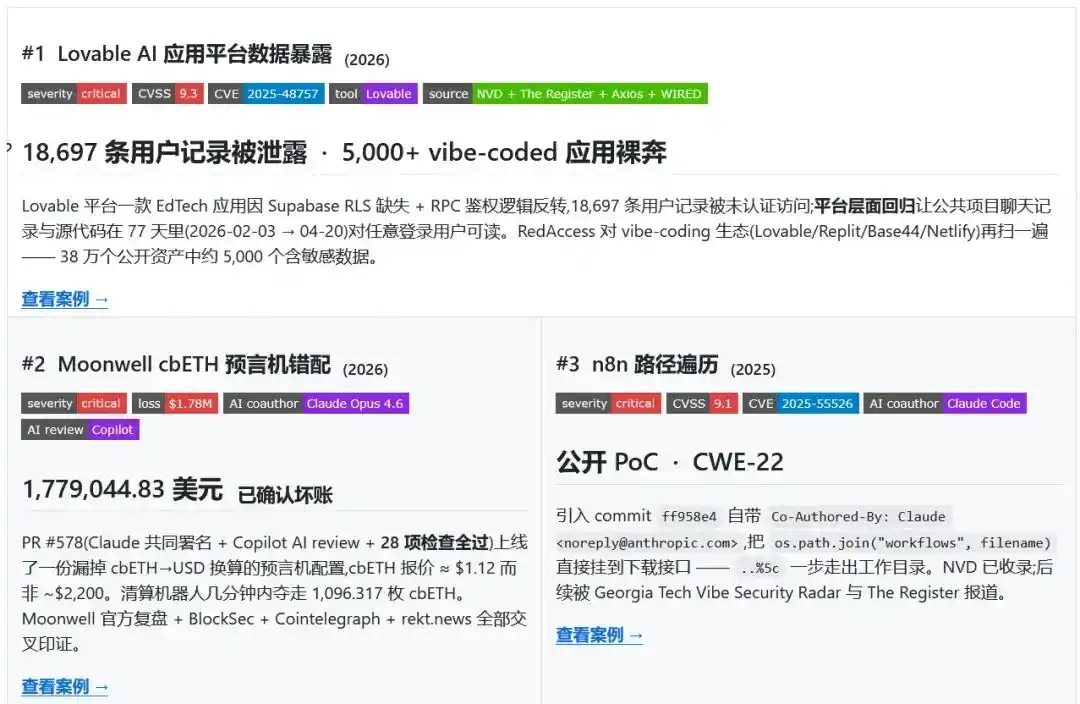
The risk of AI Coding lies in the fact that it doesn't always manifest as errors.
Often, it cloaks itself in the guise of a correct answer, quietly entering the engineering pipeline. The code runs, checks pass, PRs get merged, but the business semantics have already deviated from reality.
In low-risk projects, such semantic drift might just mean rework. But in sensitive contexts like finance or enterprise data systems, it directly leads to data leaks, exposed permissions, and asset loss.
When AI participates in writing code, modifying configurations, conducting reviews, or even co-signing and entering PRs, can we be sufficiently certain of how each deviation occurs?
The Green Light Doesn't Illuminate Every Corner
Early AI code assistants mostly remained at the level of local completions. If the syntax was wrong, the compiler would error, unit tests would fail, and the CI pipeline would block it.
Today's AI Coding ventures much further, while oversight has lagged behind.
It can read files, modify configurations, install dependencies, generate infrastructure scripts, and plan autonomously across multiple tasks via Agents.
AI is no longer just sitting on the sidelines handing over tools; it's beginning to enter longer chains of the software engineering process.
>The once-clear boundaries in software engineering are being reconnected by AI Agents into longer, harder-to-trace pathways.
Scattered Records Need a Common Logbook
Security incidents rarely start with complete conclusions. Some events have solid evidence and can enter the directory as real cases; some remain at the stage of community screenshots, researcher discussions, or preliminary disclosures, suitable only for continued observation; others are not tied to a single real event but have already formed clear patterns, suitable for proactive scenario planning.
Narwhal AI Code Risks divides the material into three layers: `cases/`, `inferred/`, and `scenarios/`.
`cases/` records real incidents with public sources and evidential chains; `inferred/` stores early signals not yet fully substantiated but worth continuous tracking; `scenarios/` organizes typical scenarios with clear risk paths, not yet bound to a single specific incident.
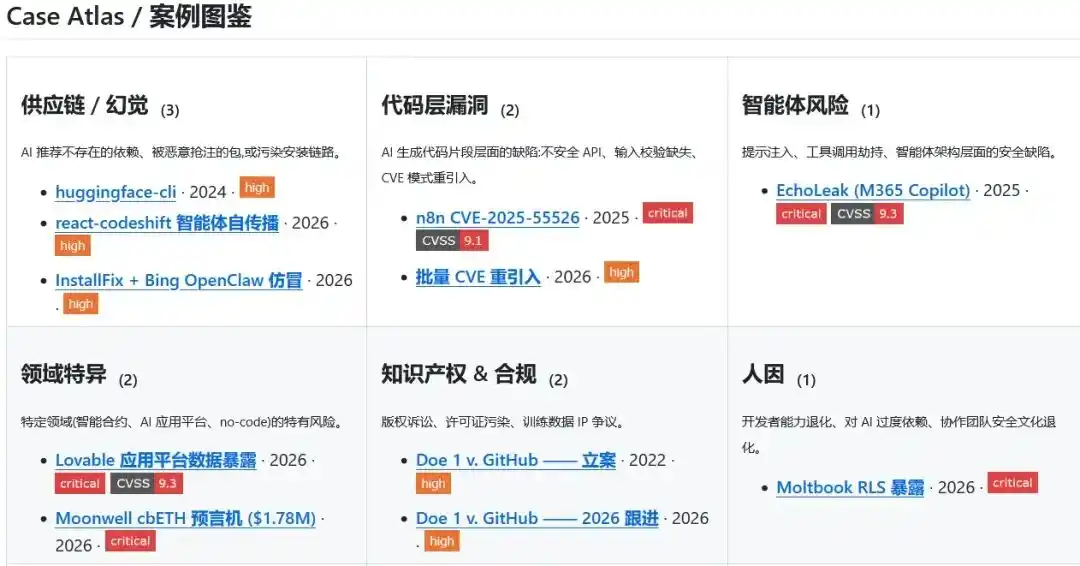
Without such public records, risks from AI Coding easily become short-term memories on the internet.
Today, everyone remembers a certain package name; tomorrow, they discuss a data exposure incident; after a few months, it's all covered by the next wave of tool hype. When similar problems arise again, teams still blunder like headless flies into waters of unknown risk.
What Narwhal AI Code Risks does is anchor these scattered risk fragments, allowing those who come later to turn to the same page.
Following Seven Index Categories to See Where Risks Come From
The problems brought by AI-generated code are not only in the code itself. They are in dependencies, in permissions, in Agent tool calls, and even more so in the way humans trust AI output.
Currently, Narwhal AI Code Risks categorizes risks into 7 types: Supply Chain, Code-Level Vulnerabilities, Cloud & Infrastructure Configuration, Agent Risks, Vertical Domain Risks, Intellectual Property & Compliance Risks, and Human Factors.
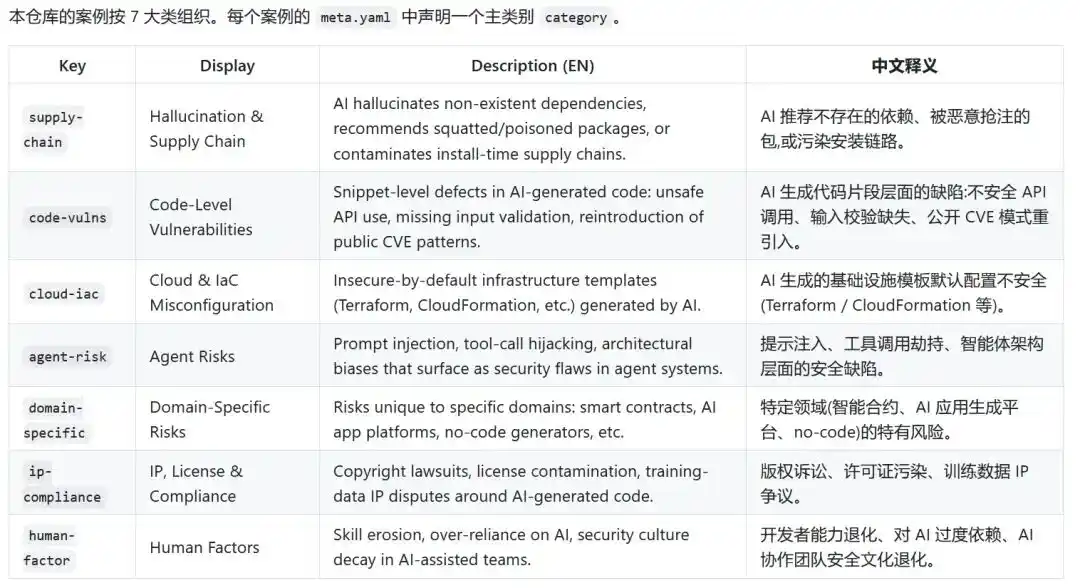
In Supply Chain risks, AI may recommend non-existent dependencies. In Code-Level Vulnerabilities, AI might reintroduce path traversal, missing input validation, or authentication issues into business code. In Cloud & Infrastructure Configuration, AI might grant overly broad permissions, public storage buckets, or exposed ports just to get the code running initially. Agent Risks are even more complex, moving beyond text generation to action execution. AI-generated artifacts are planting hidden dangers in real systems.
The AI Engine Is Firing Up, and the Logbook Is Just Beginning
As AI increasingly steps into the real world, related risk prevention and mitigation should not remain confined to post-mortems or scattered discussions.
The truly important aspect of Narwhal AI Code Risks is transforming risk cases into reusable knowledge.
Developers can use it to identify similar issues; security researchers can treat it as a sample library; tool vendors can extract detection rules and evaluation benchmarks from it; the open-source community can continue to contribute new cases, new evidence, and new risk types.
The AI engine is roaring, and every course deviation should leave its coordinates. Risks never disappear by being ignored, but experience can be recorded and passed on. The real value lies not in discovering a single vulnerability, but in ensuring later voyagers don't have to step into the same trap.
What Narwhal AI Code Risks is doing is providing an open-source logbook for the software world in the Year of AI Applications.
References:
https://github.com/Narwhal-Lab/Narwhal-aicode-risks
This article is from the WeChat public account "New Zhiyuan," author: LRST








