Область генерации изображений по тексту давно стала полем ожесточенной конкуренции, казалось бы, уже некуда развиваться.
Что нужно, чтобы обучить выдающуюся модель текстового изображения в наши дни?
Если исходить из текущих популярных подходов, то потребуется: предобученные кодировщик и декодировщик VAE, конкатенация текстовых кодировщиков, тщательно спроектированный механизм инжекции условий, огромные объемы данных, этап выравнивания RL или DPO...
В целом, все, кажется, молчаливо приняли предпосылку: создание моделей текст-в-изображение должно быть таким сложным.
А команда Хэ Каймина пошла другим путем, предложив новое осмысление в области генеративных моделей текст-в-изображение. Они представили MiniT2I — предельно минималистичную модель генерации изображений по тексту в пиксельном пространстве.
Без кодировщика/декодировщика VAE, без инжекции условий AdaLN, без вспомогательных функций потерь, без приватных данных, без выравнивания RL/DPO, чистый метод согласования потоков, обученный непосредственно на пикселях. Версия B/16 с 258 млн параметров достигает 0.87 на GenEval и 84.2 на DPG-Bench, превосходя модели в пиксельном пространстве с в несколько раз большим числом параметров.

Основная идея MiniT2I заключается в следующем: если рассматривать текстовые условия как «контекстные токены с семантической информацией», которые инжектируются в модель, то генерация по тексту и генерация с условием класса в ImageNet по сути не так уж сильно отличаются — архитектуры могут быть схожи, вычислительные ресурсы сопоставимы, и даже объемы данных можно привести в соответствие.

- Название статьи: A Minimalist Baseline for Text-to-Image Generation
- Технический блог: https://peppaking8.github.io/#/post/minit2i
- Репозиторий: https://github.com/PeppaKing8/minit2i-jax
Технический путь: вычитание на каждом шаге
Прямой вывод в пиксельном пространстве, без VAE
Первое конструктивное решение MiniT2I очень радикально: отбросить VAE и выполнять шумоподавление непосредственно на RGB-пикселях.
Латентные диффузионные модели (Latent Diffusion) — текущий мейнстрим: сначала сжатие изображения в пространство низкой размерности с помощью автокодировщика, затем диффузия. Это действительно делает работу с высоким разрешением возможной, но ценой введения ошибки реконструкции, дополнительного этапа обучения и проблемы несоответствия целей кодировщика и денойзера.
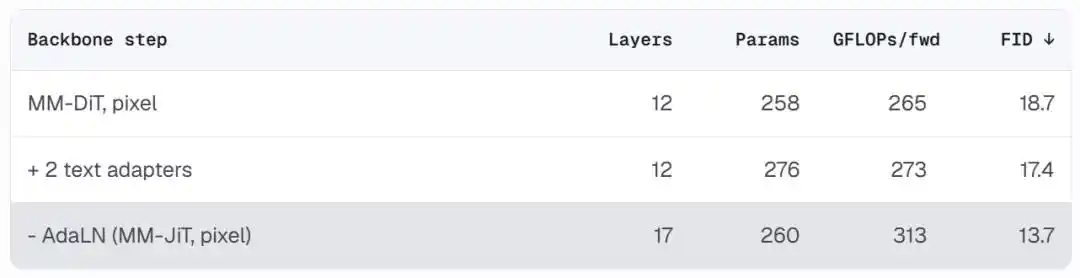
MiniT2I выбирает пиксельное пространство по практическим причинам: для разрешения 512×512, используя патчи 16×16, изображение разрезается на 1024 токена, длина последовательности полностью комфортна для Transformer. После удаления VAE объем вычислений за один прямой проход снижается с ~1379 GFLOPs до ~570 GFLOPs (для конфигурации B/16), и при этом нет потолка точности реконструкции — качество вывода ограничено только возможностями денойзера.
Эксперименты это подтверждают: при одинаковом бюджете параметров FID пиксельной модели сравним с латентной (18.7 против 19.0), но стоимость одного шага ниже в 5 раз.

Архитектура MM-JiT: возврат к простому Transformer
MM-DiT от SD3 использует AdaLN (Adaptive Layer Normalization) в каждом блоке для инжекции временного шага и пулинга текстового кодировщика в сеть — каждый подблок требует вычисления параметров scale, shift и gate через дополнительный MLP на основе условного вектора. Это изящный механизм модуляции, но MiniT2I показывает, что он не обязателен.
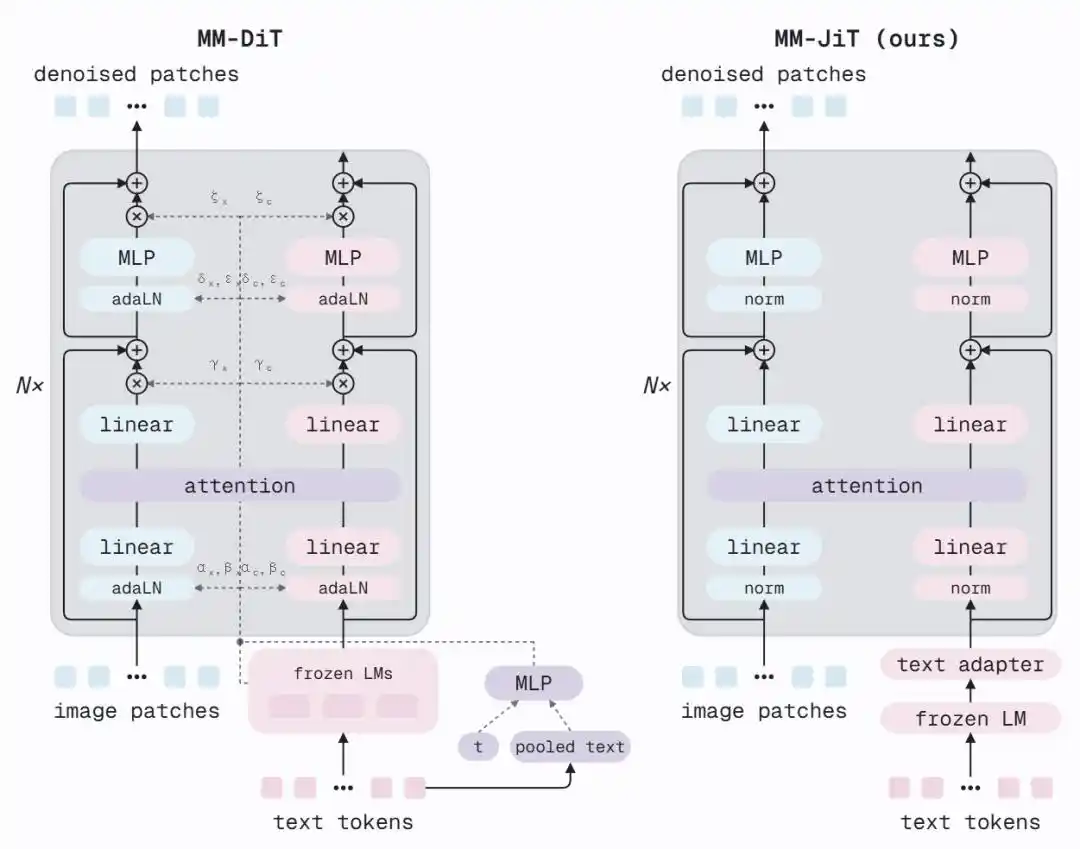
Предложенная архитектура MM-JiT делает две вещи:
1. Добавляет два текстовых адаптера: перед совместным вниманием вставляются два легких блока Transformer, чтобы замороженные признаки T5 сначала «адаптировались» к требованиям денойзера.
2. Удаляет ветку AdaLN: временной шаг и глобальная текстовая информация больше не инжектируются по дополнительным путям. Модель все еще может воспринимать уровень шума — потому что зашумленное изображение само по себе несет информацию о временном шаге.
Результатом является чистая архитектура, близкая к стандартному пред-нормализованному Transformer. После удаления AdaLN параметров становится меньше, но на том же вычислительном бюджете можно увеличить количество слоев (с 12 до 17). FID снижается с 18.7 до 13.7, при этом сама архитектура становится понятнее и легче в модификации.
Данные для обучения: полностью открытые, двухэтапные
Данные для обучения MiniT2I также стремятся к минимализму:
- Предобучение: LLaVA-recaptioned CC12M (открытый набор данных, переаннотированный VLM), 250 тыс. шагов.
- Дообучение (fine-tuning): ~120 тыс. пар изображение-текст высокого качества (BLIP3o-60K + LAION DALL・E 3 Discord set + ShareGPT-4o-Image), 40 тыс. шагов.
Эта двухэтапная схема «предобучение — дообучение» полностью соответствует парадигме обучения LLM: предобучение обеспечивает охват, дообучение учит модель, что является хорошим ответом. Абляционные исследования показывают, что оба этапа необходимы — только предобучение дает приемлемое качество изображений, но слабое следование промпту; только дообучение слишком сужает кругозор модели, и разнообразие генерации коллапсирует.
Результаты: маленькая модель, большие достижения
В сравнении моделей текст-в-изображение в пиксельном пространстве, ценность MiniT2I исключительно высока:
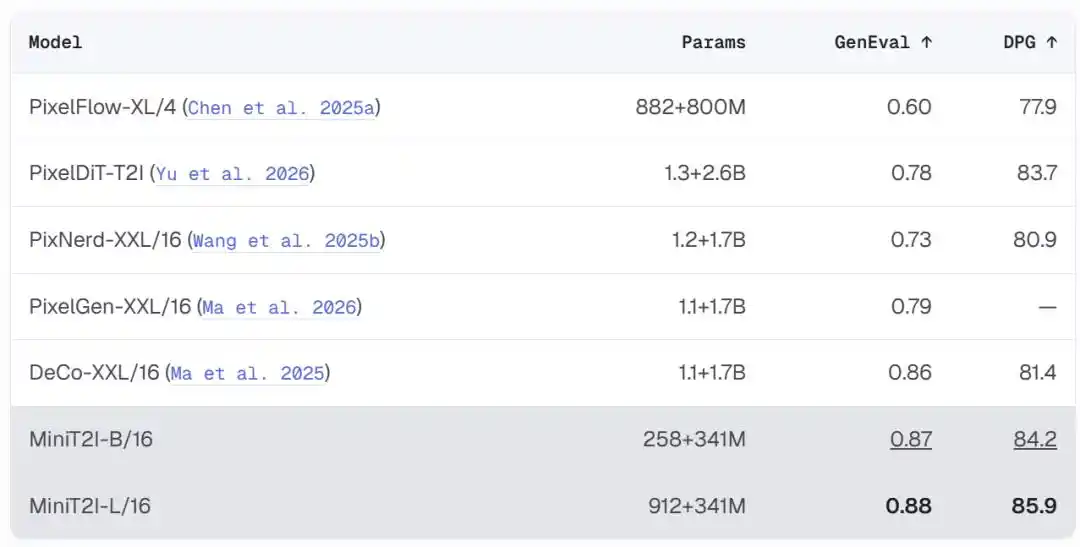
MiniT2I-B/16, используя всего около 600 млн общих параметров (включая текстовый кодировщик), превосходит на GenEval и DPG-Bench модели с в 3-4 раза большим числом параметров. И стоимость обучения крайне низка: абляционная модель B/32 обучается примерно за 3 дня на 8 картах H100, общий объем FLOPs при обучении сопоставим со стандартным 200-эпоховым экспериментом на ImageNet.
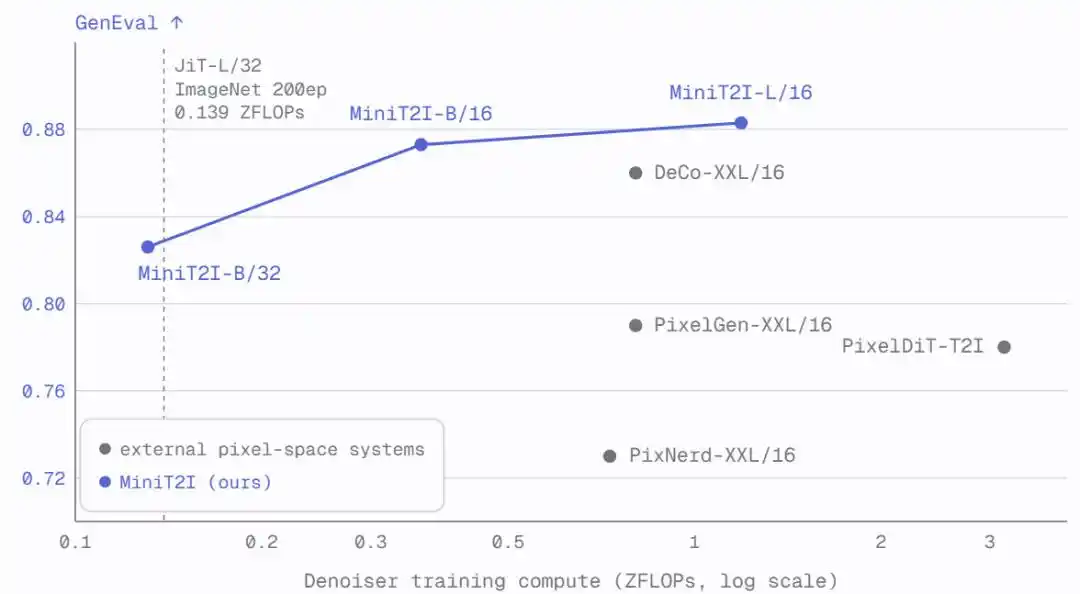
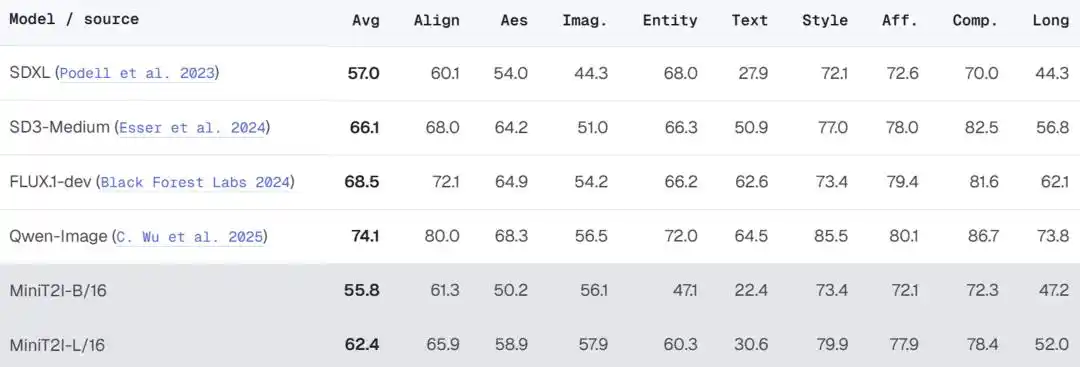
После масштабирования до L/16 (912 млн параметров) модель демонстрирует заметный прогресс в стилевом разнообразии, пространственных отношениях и рендеринге текста, достигая качества, сравнимого или даже превосходящего SD3-Medium (~2 млрд параметров) в сценах, требующих воображения.
В более комплексной оценке PRISM-Bench MiniT2I-L/16 показывает отличные результаты по измерениям стиля, композиции и воображения (79.9, 78.4, 57.9), приближаясь к уровню SD3-Medium. Но в рендеринге текста (30.6 против 50.9 у SD3) и именованных объектах (60.3 против 66.3) все еще есть отставание — команда честно признает, что это ограничение, присущее рецепту на открытых данных, и для его преодоления потребуются дополнительные специализированные данные.
Ограничения и перспективы
MiniT2I — это доказательство концепции технического пути, а не готовый продукт. Команда честно указывает на несколько нерешенных проблем:
- Артефакты патчей в пиксельном пространстве: измеримая прерывистость на границах патчей (градиент на границе на 17-22% выше, чем в центре), у латентных моделей этой проблемы нет.
- Побочные эффекты CFG в пиксельном пространстве: высокий коэффициент guidance (~6) отталкивает локальные токены от многообразия данных, что без «сглаживания» декодером напрямую проявляется как визуальные артефакты.
- Потолок разрешения: для 512×512 работает хорошо, но переход к 4K+ потребует более длинных последовательностей или более эффективных механизмов внимания.
- Ограничения данных: рендеринг текста и именованные объекты все еще слабее, чем у промышленных систем, требуется усиление специализированными данными.
MiniT2I доказывает, что современная генерация изображений по тексту — это уже не игра только для ведущих промышленных лабораторий.
Когда модель с 258 млн параметров, обученная только на открытых данных, за 3 дня на академических вычислительных мощностях, побеждает оппонентов, превосходящих ее в разы по размеру, возможно, генерация текст-в-изображение переживает смену парадигмы от «накопления ресурсов» к «очищению и оптимизации».
«Генерация текст-в-изображение больше не является непреодолимой стеной. Добро пожаловать к использованию и улучшению, созданию еще более простых базовых решений.»
Статья из WeChat Official Account «Машинный разум» (机器之心)







