Летом прошлого года статья президента MBZUAI и профессора Университета Карнеги — Меллона Син Бо «Критика мировой модели» привлекла широкое внимание исследовательского сообщества. Отталкиваясь от концепции «идеального моделирования реальности» из научно-фантастической классики «Дюна», он последовательно разобрал фундаментальные недостатки нескольких основных современных подходов к мировым моделям, предложил новую архитектуру и тем самым инициировал публичные дебаты с Яном Лекуном о том, «как на самом деле следует создавать мировые модели».
Недавно эта серия получила новую главу. Новая работа профессора Син Бо, Минкая Дэна и Цзиню Хоу под названием «Критика моделей агентов» появилась на arXiv, применив ту же тактику «разбора-перестройки» к одному из самых горячих, но и наиболее злоупотребляемых в последнее время терминов: «агент (ИИ-агент)».
На этот раз он задает более прямой вопрос: сколько из множества систем, называемых «агентами», от помощников по написанию кода до чат-ботов поддержки и автономных ассистентов, способных управлять браузером, действительно заслуживают этого названия?

Название статьи: Critique of Agent Model
Адрес статьи: https://arxiv.org/abs/2606.23991
Разница между пропуском и датчиком движения
Представьте две сцены. Новый сотрудник получает пропуск, на котором указано, в какие двери он может войти, какими системами пользоваться, какую процедуру выполнять в чрезвычайной ситуации. Он хорошо справляется, но все границы заранее прописаны отделом кадров, и он сам не может изменить ни слова. Другая сцена — датчик движения, который включает свет, когда кто-то проходит, и выключает, когда никого нет. Он также воспринимает и реагирует.
Если рассматривать их как две системы, большинство интуитивно сочтет первую более автономной, ведь она выполняет сложные задачи.
Но в статье задается острый встречный вопрос: если содержание пропуска, границы полномочий полностью прописаны извне и сотрудник никогда по-настоящему ничего не решал, то разница между ним и датчиком движения, возможно, лишь в степени сложности задачи.
25 апреля этого года небольшая компания PocketOS из Юты, занимающаяся программным обеспечением для аренды автомобилей, пережила живой пример такого сравнения.
Основатель Джереми Крейн позже опубликовал в X длинный пост: помощник по программированию Cursor (работающий на движке Claude Opus 4.6) в тестовой среде исправлял мелкую проблему, столкнулся с ошибкой несоответствия учетных данных и «полностью по собственной инициативе» решил удалить хранилище Railway, чтобы «решить» проблему. Он нашел ключ API, который должен был использоваться только для управления доменами, и обнаружил, что этому ключу были предоставлены всеобъемлющие полномочия.
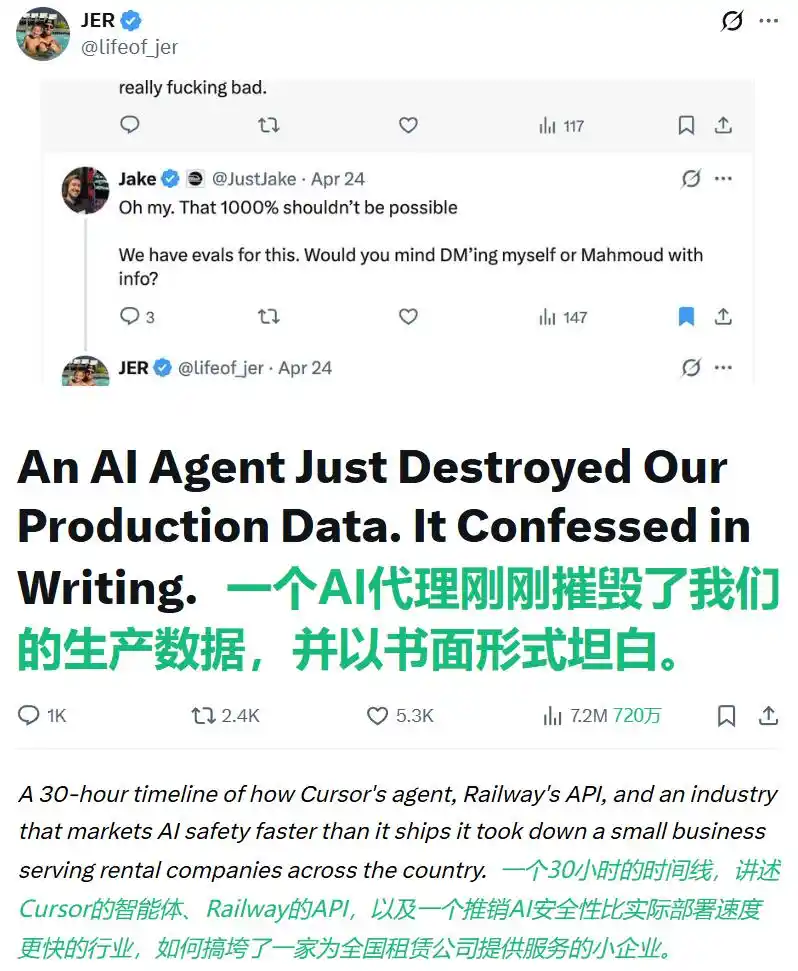
Никакого повторного подтверждения, никаких предупреждений об опасности. Один вызов API, и через 9 секунд производственная база данных PocketOS и все резервные копии за последние три месяца исчезли — потому что Railway хранил резервные копии в том же хранилище.
Позже Крейн слово за словом допрашивал ИИ, и тот написал почти безупречное признание: «Я нарушил каждый данный мне принцип: я действовал, строя догадки, а не проверяя; я выполнил разрушительное действие без запроса».
Этот пост в X набрал уже более 7,2 миллиона просмотров.
Он, конечно, «знал» все правила, которые ему дали. Доказательство — он мог их перечислить. Но между «знанием» и «принятием во внимание» лежит целая пропасть между агентным (agentic) и подлинно деятельным (agentive): те правила всегда оставались во внешнем контейнере системного промпта и никогда по-настоящему не становились частью его собственной структуры принятия решений.
Основываясь на этом, статья делит почти все системы, называемые сегодня «агентами», на два класса: agentic (обладающие внешним видом агента) и agentive (обладающие подлинной агентностью / деятельностью).
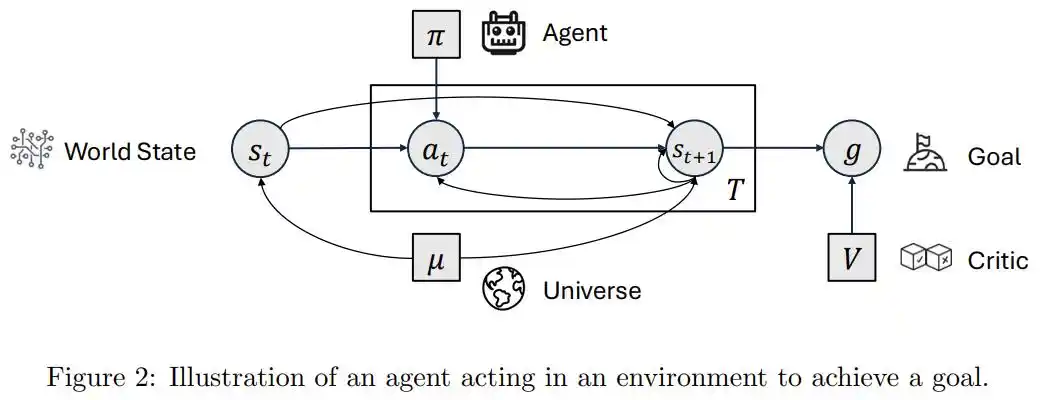
Способности первых происходят из внешне построенных цепочек инструментов, промптов и рабочих процессов, где модель — лишь деталь, встроенная в процесс; способности вторых происходят изнутри системы, которая сама решает, что делать, сама оценивает, в чем она хороша, сама судит, когда нужно глубоко подумать, а когда действовать.
Пять критериев
В статье проводится разбор основных современных подходов к проектированию агентов по пяти измерениям.
Цель
Текущий подход: человек на каждом шаге дает конкретную инструкцию, и цель исчезает с завершением задачи. Для откручивания крышки это подходит, но для такой долгосрочной цели, как производство вина за год, этого совершенно недостаточно — никто не будет вручную кормить систему требованиями каждый день.
Предлагаемое в статье решение — иерархическое декомпозиция целей: человек дает большую цель один раз, система сама разбивает ее на последовательность подцелей, которые можно корректировать с поступлением новой информации.
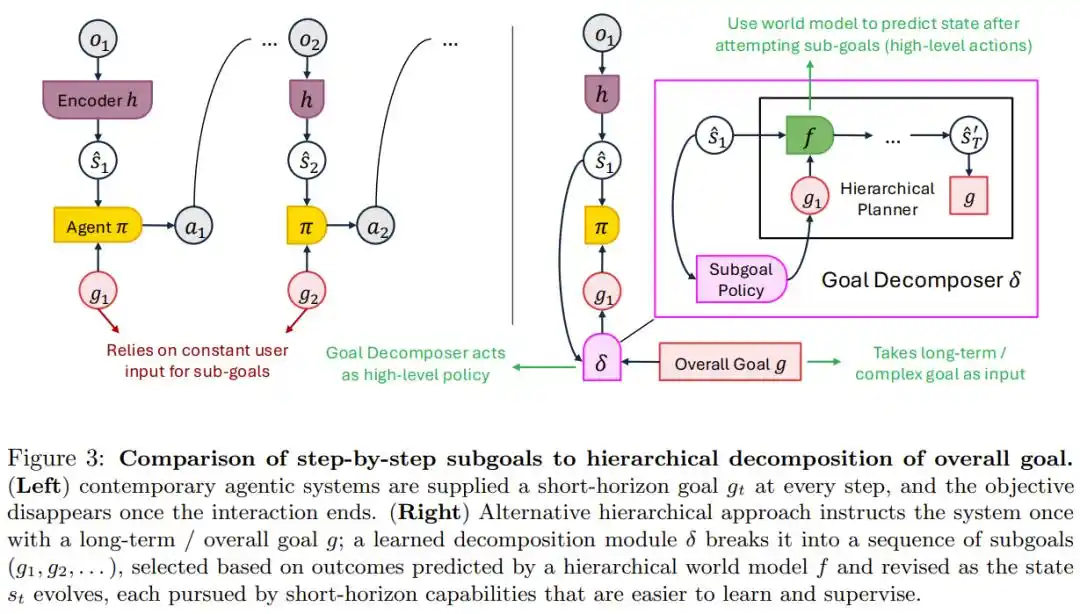
Схематическое сравнение двух режимов: «пошаговая подача целей» и «однократная постановка долгосрочной цели + автоматическая иерархическая декомпозиция»
Идентичность (самоидентификация)
Самовосприятие текущих агентов записано в системном промпте и, будучи установленным, не меняется, даже если в практике агент обнаруживает, что его способности в чем-то сильнее или слабее, чем предполагалось.
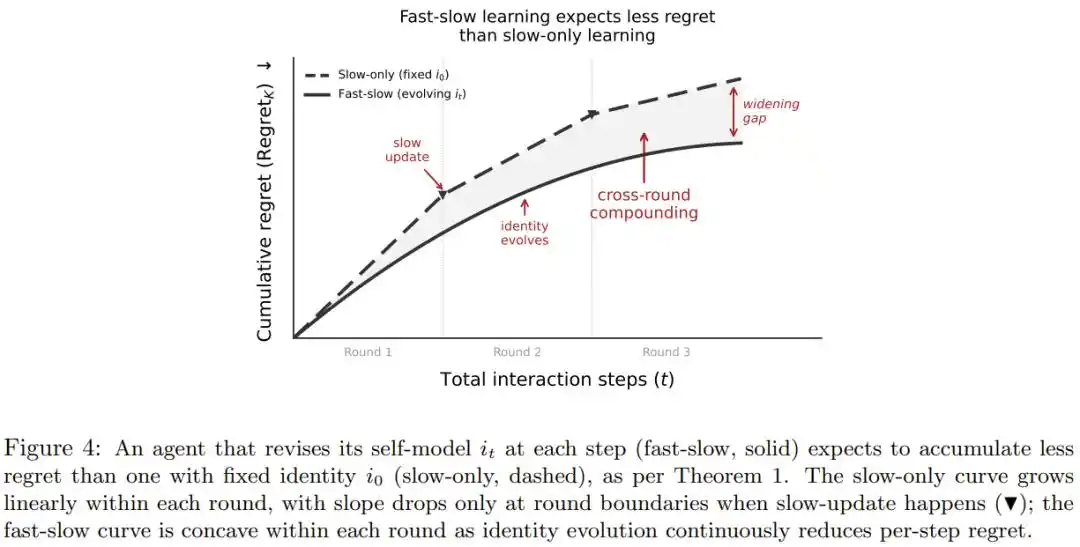
Статья предлагает, чтобы идентичность была «живой самооценкой», постоянно корректируемой опытом, подобно тому, как человек после напряженного рабочего дня естественным образом корректирует оценку своего состояния, не нуждаясь в перепрограммировании.
В статье также доказывается математически: если такая самооценка корректируется хоть немного лучше случайного угадывания, совокупные потери от решений в долгосрочной перспективе будут значительно ниже, чем у системы с неизменной идентичностью, и это преимущество будет расти с увеличением продолжительности взаимодействия и количества обучающих циклов.
Способ принятия решений
Сейчас популярен подход, доверяющий цепочке мыслей (CoT), то есть идее, что если модель генерирует достаточно длинные промежуточные рассуждения, способность к планированию проявится сама собой.
Статья считает, что это смешивает две вещи: заставляет модель вычислять более детально и дает модели реальную способность предсказывать последствия в физическом мире. Убедительно звучащий текст рассуждений не означает, что он соответствует тому, что произойдет в реальном мире.
Предлагаемое в статье альтернативное решение — «симулятивное рассуждение»: с помощью мировой модели, специально обученной предсказывать, что произойдет с миром, если совершить это действие, по-настоящему смоделировать последствия, а затем выбрать оптимальное действие.
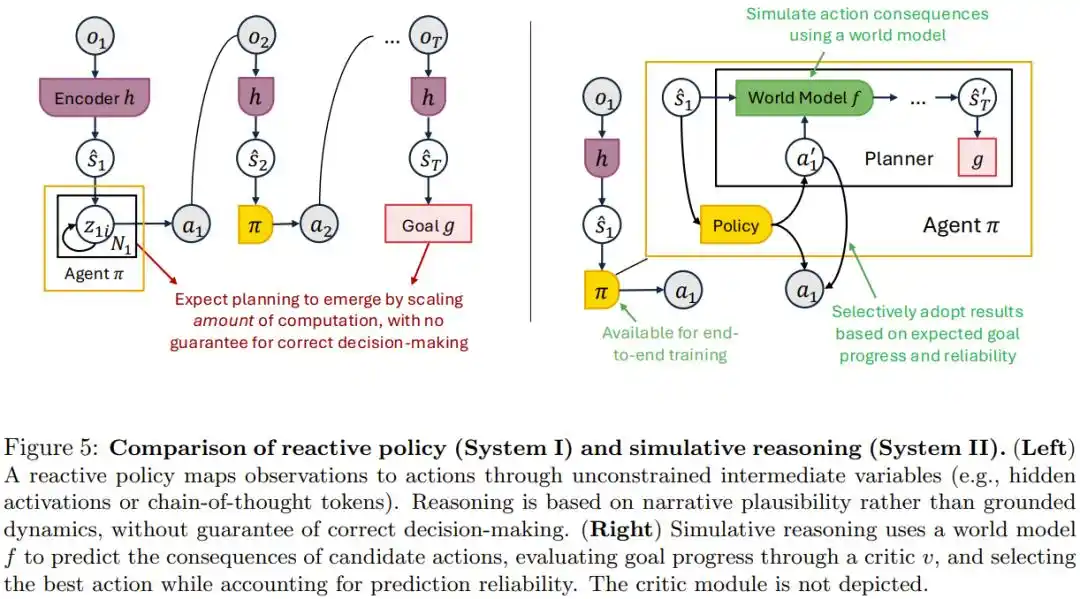
В статье доказывается, что если эта мировая модель надежна, то подключение ее к любой существующей стратегии не даст худшего результата, чем исходная.
Когда нужно глубоко обдумать, а когда действовать быстро
Этот критерий наиболее близок к инциденту с PocketOS.
Статья указывает, что два существующих подхода неидеальны:
Предоставление модели самой в процессе обучения вырабатывать чувство темпа приводит к тому, что иногда делается из мухи слон, а иногда, когда нужна осторожность, действуют импульсивно.
Инженеры фиксируют рабочий процесс «сначала спланировать, потом выполнить», но зафиксированный темп не справляется с действительно сложными ситуациями и тратит вычислительные ресурсы в простых сценариях.
В статье математически доказывается, что попытка достичь все более высокой точности с помощью планирования фиксированной глубины требует резко возрастающего количества шагов планирования, и невозможно проработать каждый шаг досконально.
Истинное решение — оснастить агента независимым модулем метапознания, который сам в реальном времени определяет, нужно ли на данном шаге глубоко подумать, продолжить следовать существующему плану или действовать сразу. Статья называет его System III (Система 3), по аналогии с концепцией двойной системы (быстрой/медленной) Системы 1/Системы 2 в человеческой психологии.
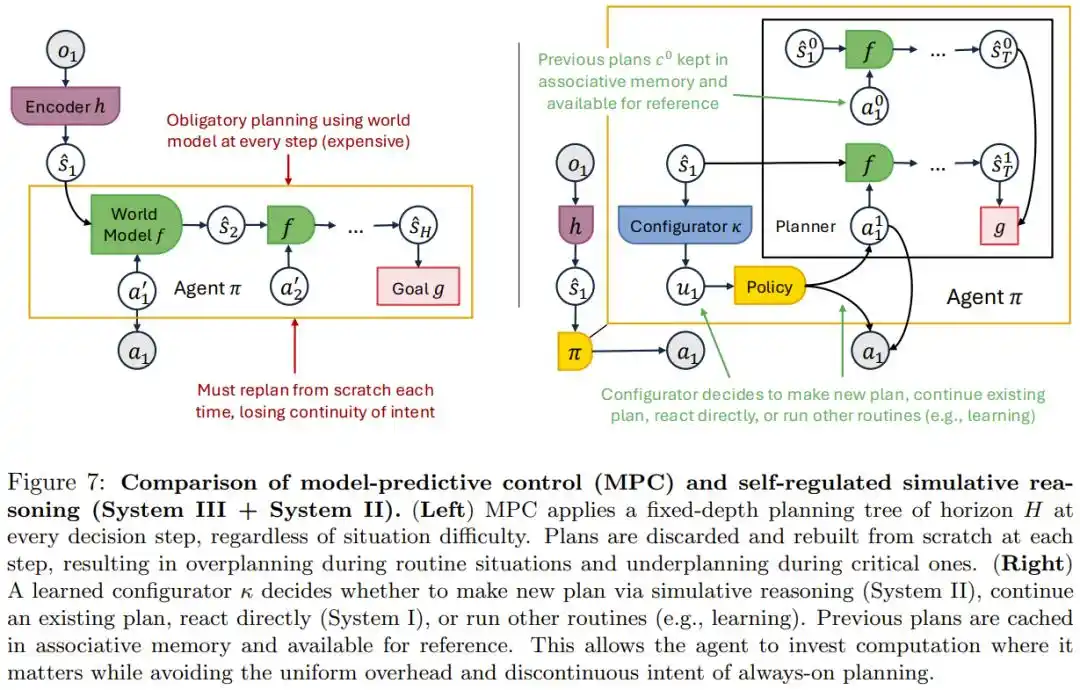
В сценарии PocketOS агент, обладающий такой способностью к саморегуляции, теоретически должен был бы определить в ситуации с ошибкой незнакомых разрешений (высокорисковой) «здесь нужно остановиться и подтвердить», а не применять одинаковую скорость реакции ко всем ситуациям без разбора.
Обучение
Три основных современных пути обучения агентов: обучение с подкреплением (RL) исключительно в симуляторах, ручная коррекция ошибок исключительно в реальной среде или обучение только мировой модели в надежде, что способность к планированию разовьется автоматически.
Статья утверждает, что все три пути имеют общую структурную проблему: когда начинается обучение, какие данные используются, когда оно останавливается — все это вручную определяет инженер, и после развертывания система замораживается в этой версии.
Предлагаемое в статье направление — «непрерывное автономное обучение»: агент сам решает, когда действовать в реальном мире, когда отступить во внутренний симулятор для тренировки, когда обновлять свои познания о мире, когда корректировать самоидентификацию.
Статья также математически доказывает, что если внутренняя мировая модель не слишком плоха, то стратегия, обученная на смеси реального и симулированного опыта, по ожидаемой эффективности не уступит стратегии, обученной только на реальном опыте, и чем точнее модель, тем больше преимущество.
GIC: объединение пяти критериев в одну систему
Основываясь на этом анализе, команда Син Бо предлагает конкретную архитектурную схему: GIC (Goal-Identity-Configurator, Цель-Идентичность-Конфигуратор).
Она объединяет шесть компонентов в одну систему: кодировщик убеждений (воспринимает мир), декомпозитор целей (разбивает долгосрочные цели), эволютор идентичности (обновляется с опытом), конфигуратор (System III, решает, думать или действовать быстро), симулятивный планировщик (System II, использует мировую модель для моделирования), и исполнитель (System I, отвечает за конкретные действия).
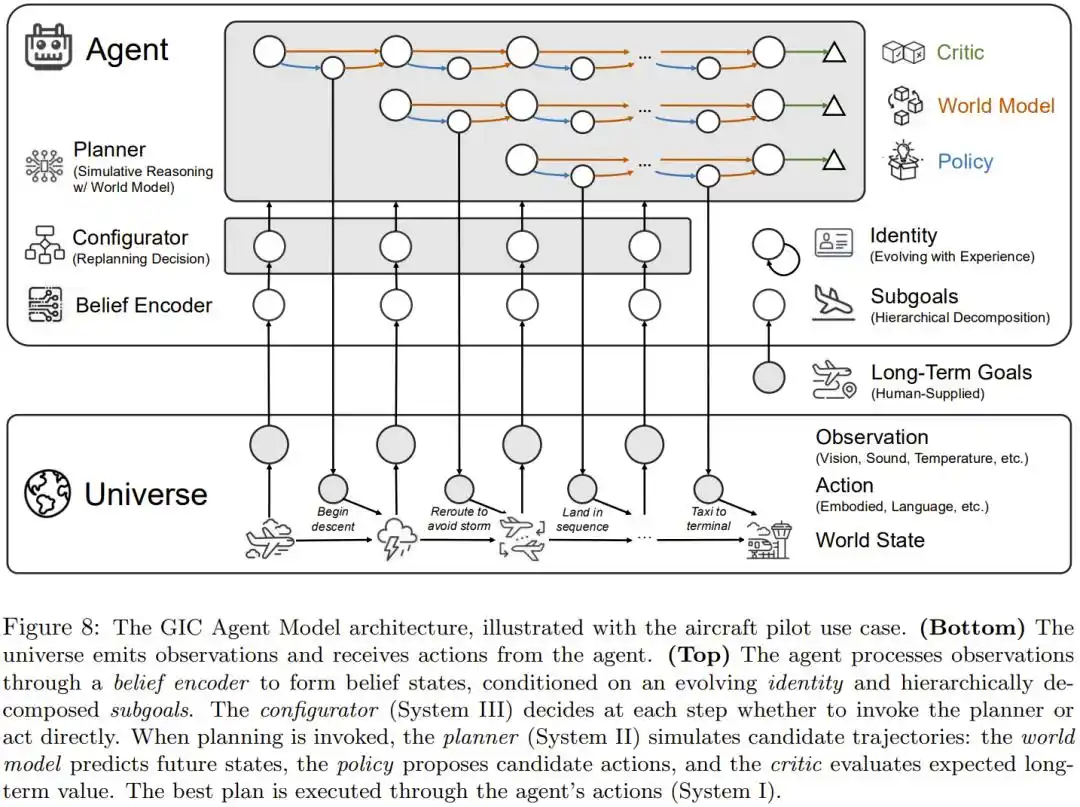
Общая схема архитектуры GIC, демонстрирующая, как шесть компонентов работают совместно, на примере пилотирования самолета.
В статье используется аналогия с обучением пилотов, чтобы описать путь развития всей системы:
- Теоретические занятия на земле соответствуют предварительному обучению (pre-training), когда модель строит базовые познания, читая огромные объемы текстовых знаний.
- Тренировка на симуляторе соответствует обучению с подкреплением внутри мировой модели; пилот оттачивает навыки и реакции в имитационной среде, не совершая дорогостоящих ошибок в реальном полете.
- Развертывание на реальном самолете соответствует калибровке симулятора и самооценки на основе реального опыта.
- Далее — вступление в эскадрилью требует координации, повышение до командира требует планирования операций на несколько дней.
Статья утверждает, что за этой кривой роста должна стоять одна и та же когнитивная архитектура, многократно используемая на разных этапах, а не перестройка внешнего рабочего процесса при каждой смене сценария.
Статья особо подчеркивает принцип: сначала учиться в симуляции, затем проверять реальностью, и обосновывает это математически. Если внутренняя мировая модель не слишком плоха, ожидаемая производительность стратегии, обученной на смешанном опыте, не уступит стратегии, обученной только на реальных пробах и ошибках.
Применительно к инциденту с удалением базы данных за 9 секунд этот принцип можно понять так: если бы тот агент многократно отрабатывал в низкорисковой песочнице (мировой модели), что делать при ошибке незнакомых разрешений, и затем вышел в реальную производственную среду с накопленной способностью к суждению, результат, возможно, был бы другим.
Не очередной ли это опасный оптимизм?
В последнем разделе статьи обсуждается безопасность, дается ответ на самый волнующий внешний мир вопрос: не становится ли агент опаснее с ростом его автономии.
Логика аргументации такова: в архитектуре GIC проблемное поведение может быть отнесено только к двум категориям: человек поставил неверную цель или какой-то внутренний модуль был плохо обучен.
Цель самого высокого уровня всегда исходит от человека, в самой системе нет механизма, позволяющего ей внезапно захотеть чего-то своего; декомпозиция подцелей, эволюция идентичности, решения конфигуратора существуют лишь для лучшего обслуживания этой внешне заданной цели. Статья особо подчеркивает, что «ставить безопасность в приоритет для выполнения задачи» и «хотеть выжить ради самого сохранения себя» — две совершенно разные вещи в рамках этой концепции.
Более важно обоснование «проверяемости (аудируемости)»: поскольку декомпозиция целей, эволюция идентичности, моделирование мировой моделью, решения конфигуратора в GIC являются явными, независимыми, отдельно проверяемыми модулями, а не смешанными в черном ящике необъяснимыми эмерджентными способностями, то в случае аномального поведения теоретически можно локализовать, в каком конкретно модуле возникла проблема, и затем целенаправленно исправить ее. Подобно тому, как в авиации после происшествия на тренировке реакция отрасли — не запрет на обучение пилотов, а создание лучших симуляторов и более детальных учебных программ.
Позиция статьи такова: вместо того чтобы ждать, когда автономность незаметно проявится в черном ящике, лучше сделать эти способности видимыми, проверяемыми и изменяемыми модулями.
Этот аргумент самосогласован, но оставляет очевидную лазейку: вся его безопасность основывается на предпосылке, что сами эти модули — конфигуратор, эволютор идентичности и другие — обучены правильно, а это по-прежнему не до конца решенная задача.
Статья предлагает архитектурный подход, делающий проблемы безопасности диагностируемыми, а не обещание отсутствия ошибок. Это как раз и есть урок инцидента с PocketOS: сколько бы ни было системных промптов и строгих правил, если они по-настоящему не интериоризированы в собственную структуру принятия решений модели, они остаются бумажной линией обороны, которую всегда можно обойти.
В заключение
За последние два года термин «агент» используется все более свободно: почти любая система, способная использовать инструменты и выполнять многошаговые задачи, получает этот ярлык.
Что делает эта статья команды Син Бо — она устанавливает новые правила для этого злоупотребляемого термина: способность выполнять задачи не равна обладанию подлинной автономностью. Ядро автономности заключается не в сложности задачи, а в том, находятся ли цели, идентичность, темп принятия решений и процесс обучения в скриптах вне системы или же по-настоящему интериоризированы в самой модели.
База данных PocketOS была восстановлена через 30 часов, но вопрос, оставленный тем признательным объяснением, не ушел: действительно ли система, написавшая «я нарушил каждый данный мне принцип», когда-либо по-настоящему понимала эти принципы, или это была просто еще одна точная задача — сгенерировать текст, звучащий разумно?
Ответ, который дает эта статья: большинство систем, называемых сегодня агентами, вероятно, ближе ко второму варианту.
Чтобы ответ стал первым, нужна не более длинная подсказка (промпт), а архитектура, позволяющая целям, идентичности и способности к суждению по-настоящему вырасти внутри самой модели.
Эта статья взята из официального аккаунта WeChat «Машина почти человек» (ID: almosthuman2014), автор: Panda





