By Silicon-based Spark
That famous Sam Altman meme has now come true for everyone.
Last year, while promoting GPT-5, the OpenAI CEO said something that later became an internet sensation: "The feeling is like witnessing an atomic bomb explosion, leaving one dizzy and collapsing." Since then, whenever the AI community releases a new product with exaggerated marketing copy, this meme gets dragged out and ridiculed repeatedly.

But late the night before last, it wasn't Altman who was left dizzy and collapsing. This time, it was all the users staring at their screens waiting for OpenAI to play its hand.
Altman, as usual,故作神秘故作神秘 (played it coy故作神秘故作神秘), posting a tweet: "We've prepared something fun."
By 3 a.m., GPT-Image 2 was released. The global AI community exploded.
"Images are a language, not decoration."
This is the first sentence written on OpenAI's release page. Translated, it means one thing: from today, images are no longer just decorations; they are a language in themselves. This is a declaration of a generational leap for the entire computer vision industry.
For the past year, AI image generation was stuck in the aesthetic quagmire of "does it look realistic?" The arrival of GPT-Image 2 directly pressed the switch—AI image generation officially entered the intelligence exam hall of "is the logic correct?".
The precision of this model can be described as "terrifying."
It topped both the text-to-image and image editing rankings on Artificial Analysis, and its practical performance is crushing.
The feeling is like when Seedance 2.0 arrived in the video generation field—it long ceased being just an auxiliary tool for humans; it is defining the new industry standard.
Note: All images in this article are generated by GPT-Image 2. The image content is purely fictional.
01 The Awakening of the Thinking Engine
In the past, the primary standard for judging an image model was how much it resembled a real person or a reference object.
In the face of this monster, GPT-Image 2, that standard is obsolete. Completely obsolete.
The core breakthrough of the new model is this: it is an image model that supports a thinking mode.
What does that mean? After the user inputs a prompt, the model doesn't simply denoise and stitch pixels. It first completes a round of thinking and modeling in the background, *then* it starts drawing.
A test image leaked from the Linux.do community best illustrates the point. The model simulated a live stream of Lei Jun running:
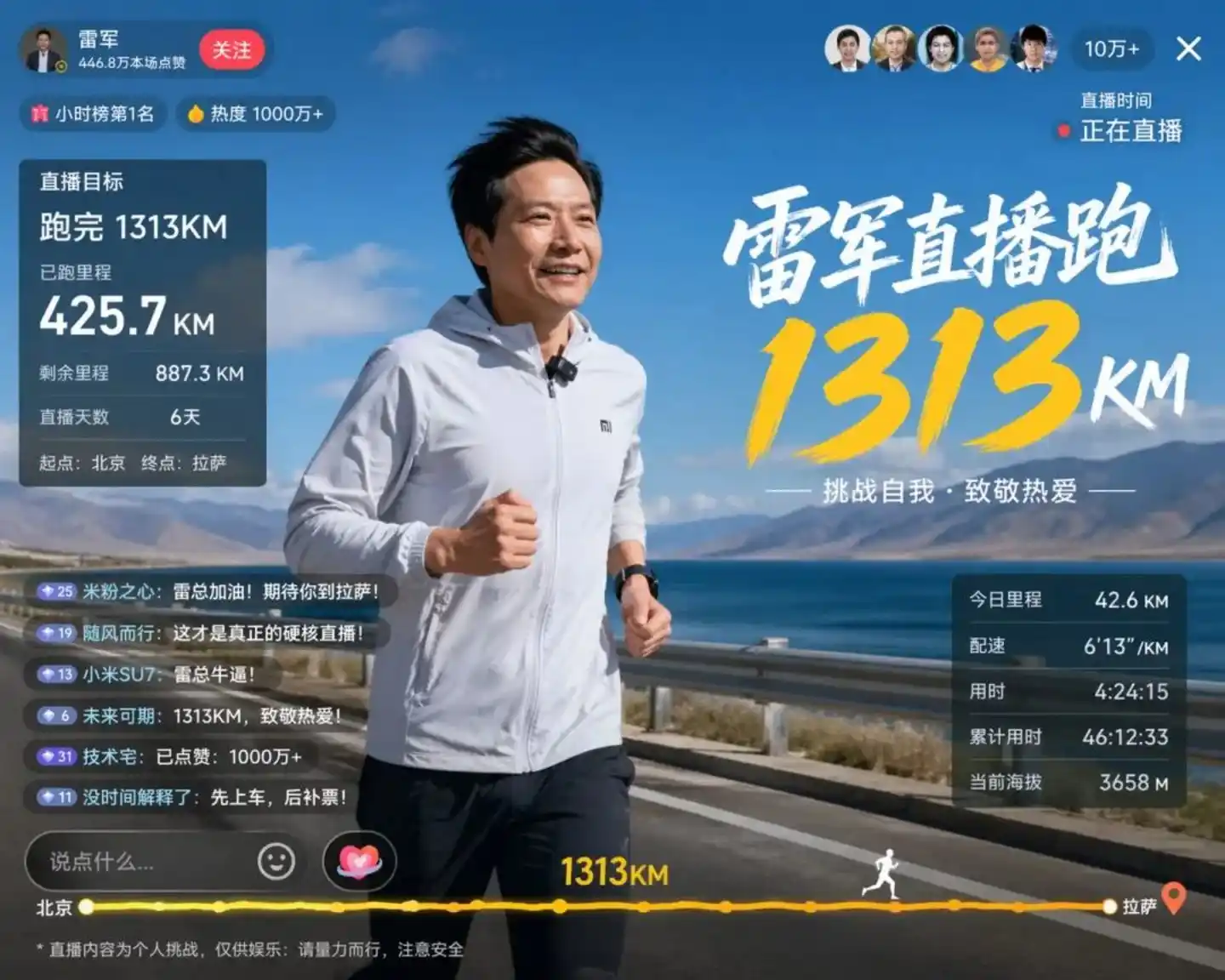
Image source: https://cdn3.linux.do/original/4X/0/f/3/0f37c8bc968e3d563cc6100d8e7f80ee305661ff.jpeg
This image made many developers gasp. Lei's facial features are accurately reproduced—almost like a photo—the image clearly shows: Live stream target 1313km, Distance run 425.7km, Remaining distance 887.3km. Even more impressive, the current altitude is marked as 3658m.
What does 3658m mean? From Beijing to Lhasa, the typical altitude upon entering the Tibetan region is precisely this number.
In human eyes, this is simple arithmetic and common geographical knowledge. But think about it: For an image model, what does the triple unification of mathematical logic + geographical常识 (common sense) + UI specifications mean?
The conclusion is straightforward: Before generating the first pixel, GPT-Image 2 had already completed a round of reasoning. It understood the meaning of "distance," understood the logical relationship of addition and subtraction, and also understood the visual characteristics of high-altitude areas.
This isn't drawing. This is thinking.
02 From Toy to Productivity Tool
In the face of this capability, everyone's attitude towards image models needs to change.
It's long ceased to be a toy for drawing avatars or making wallpapers. It has stepped over the "usable" threshold and rushed directly into the "easy to use" zone—a tool that can be thrown into commercial scenarios to get work done.
Take poster design. GPT-Image 2's composition aesthetics, light and shadow processing, and grasp of brand tone have undoubtedly reached a height that the vast majority of ordinary human designers find difficult to achieve.

Image source: https://cdn3.linux.do/original/4X/7/a/1/7a12ccd6b745be5ad8828eb0ac225d218fb43cbc.jpeg
In human society, hiring a senior graphic designer to create a commercial-grade poster often entails significant communication costs, time costs, and design fees of over a thousand yuan, which can be a heavy burden for small and medium-sized enterprises.
However, with GPT-Image 2, even if you are unsatisfied and need to adjust dozens of times, the cost is only a few dollars.
In fields like poster design, marketing materials, and illustration, what users care about is not "realism," but "is it good-looking, is it accurate." Precisely because of this, AI's replacement efficiency is devastating.
In the synchronously updated developer documentation, there is also an exciting detail hidden: the sample code frequently appears model: "gpt-5.4".
The thinking mode combined with the flagship model hints at one thing: GPT-Image 2 is by no means an isolated product. It is the visual terminal born for the next generation of large language models.
Through the new Responses API, the image generation process will interact as naturally as chatting with a large language model. The model adds a function that allows for multi-turn conversational modifications. After the initial image generation, users can propose various instructions that give human designers high blood pressure for modifications.
Through the new Responses API, the image generation process will interact as naturally as chatting with a large language model. The model adds a multi-turn conversational modification function. After the first version is generated, users can propose various instructions that would send a乙方 (Party B) designer's blood pressure soaring: "Make the background a bit darker." "Move the logo a few pixels to the side."
These interactive real-time modification demands are precisely the most tedious and patience-consuming parts of a designer's daily work. Now, they are solved.
03 The Pinnacle of Chinese Rendering
Although GPT-Image 2 is a foreign model, domestic users are overwhelmingly positive.
There's only one reason: Its support for Chinese characters is nearly perfect.
In the community's actual test return images, you can see the famous debate scene between Luo Yonghao and Wang Ziru:
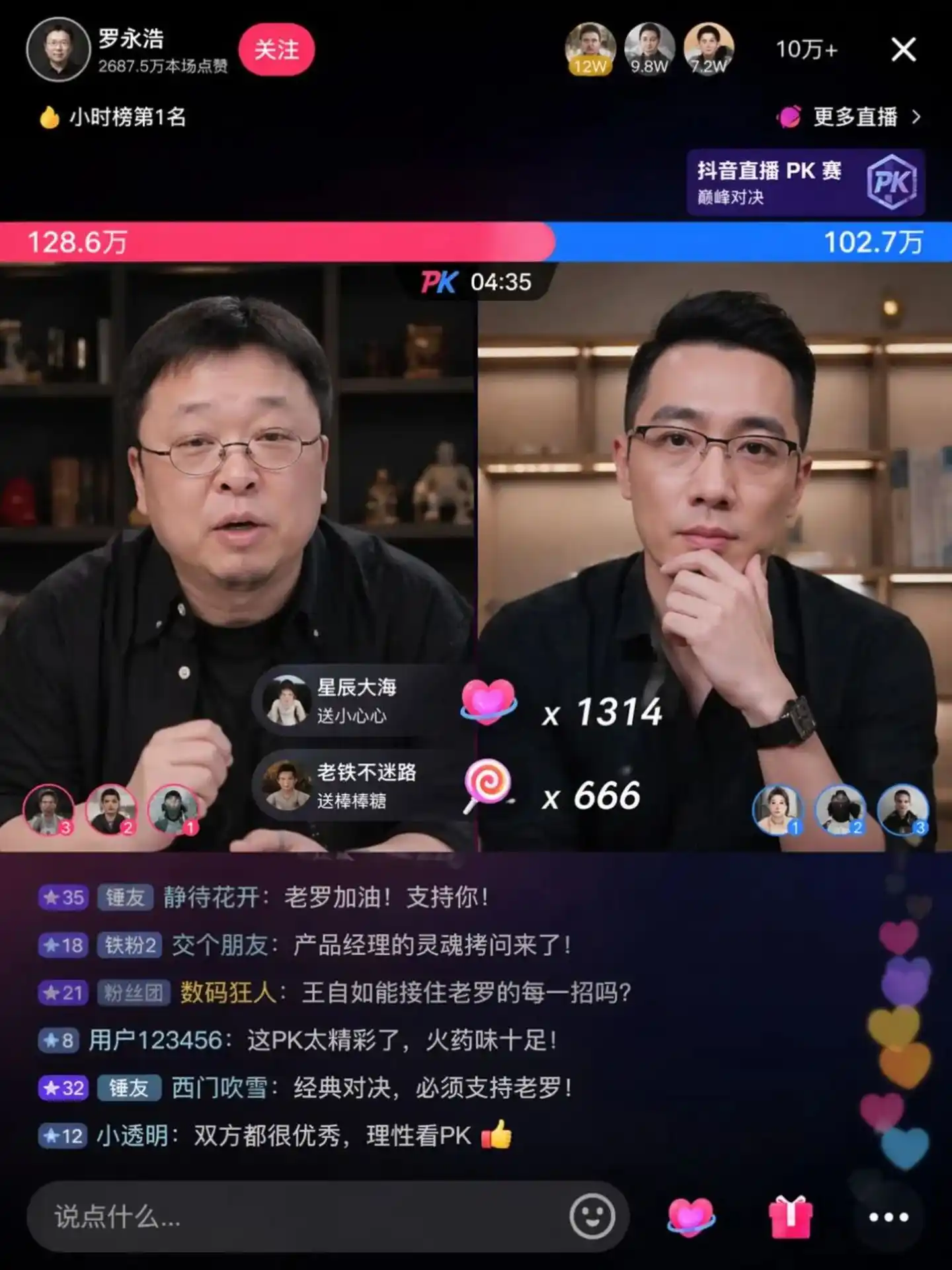
Image source: https://cdn3.linux.do/original/4X/0/9/7/097ed46991d2464442aebc6b1076a292cc839fec.jpeg
You can see Elon Musk live-streaming sales of Lao Gan Ma chili sauce:

Image source: https://cdn3.linux.do/original/4X/2/f/a/2fa77cf040e6337643829df4ec5ca6467d2866b2.jpeg
You can even see a doctor's prescription:

Image source: https://cdn3.linux.do/original/4X/9/f/f/9ffeab83675648b43116cd0763f6c8b560611ae6.jpeg
The text in these images is no longer crooked,胡乱拼凑的 (haphazardly拼凑的) "pseudo-Chinese characters," but mature design drafts possessing calligraphic charm, typographical hierarchy, and排版 (layout) artistry.
Clearly, OpenAI has injected a massive amount of Chinese language image data into the training set and conducted targeted intensive training.
Compared to the previous generation model, GPT-Image 2's power is even more淋漓尽致地 (thoroughly) evident.
In comparative tests, the previous generation model, version 1.5, could draw something resembling a recipe, but upon closer inspection, the text was almost all gibberish.

Image source: https://cdn3.linux.do/optimized/4X/2/b/3/2b38f3c1a134515d564f07f81661c0bd9578c6b9_2_750x750.jpeg
But the same recipe generated by GPT-Image 2 shows a milestone breakthrough in text clarity and aesthetics.
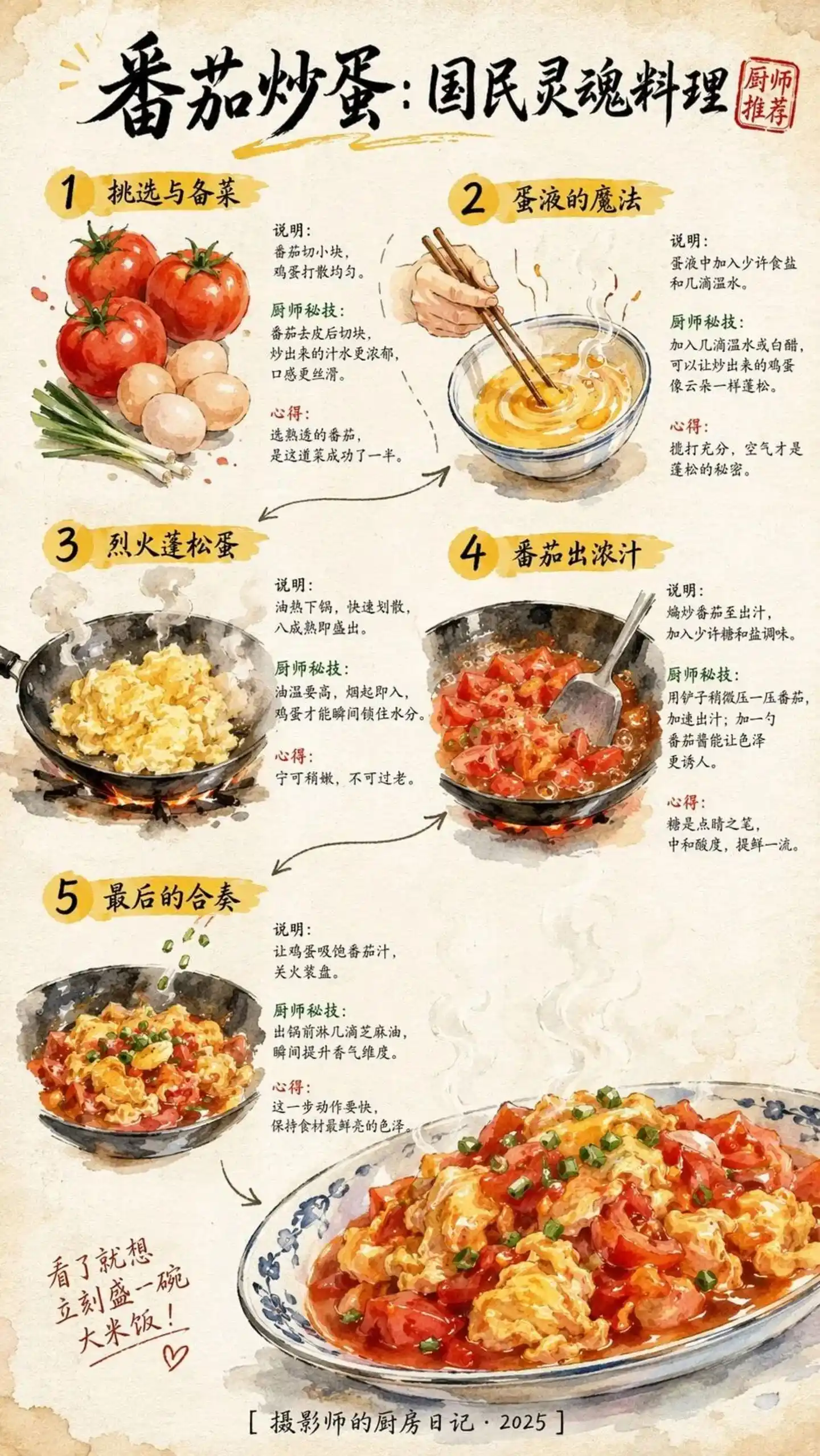
Image source: https://cdn3.linux.do/original/4X/0/2/5/02513b10135d824ccb1c22bd0c7eb441f1e34455.jpeg
For prompts with over a hundred Chinese characters, the five steps are still clearly visible, and the图文一致性 (text-image consistency) is satisfactory. This isn't just an image; it's a reproducible practical guide.
However, this also raises an interesting technical question: Has the image model really completely solved the gibberish problem?
My judgment is: Probably not.
Large language models generate tokens based on semantic logic. During the reinforcement learning phase, it's based on probability; the higher the quality and quantity of the training data, the more logical the output. But the essence of an image model is, after all, pixel generation. The logical relationship between pixels is fundamentally different from the logical relationship between words.
In other words, as powerful as GPT-Image 2 is, it does not truly "understand" the rules of text. It has merely memorized the pixel-level appearance of text by rote.
An image of doing business with Altman暴露 (exposes) this point: The large characters "Mengniu" and "Wanglaoji" on the two boxes of drinks are written perfectly, but the small text below is still模糊的色块 (blurry color blocks).

Image source: https://cdn3.linux.do/original/4X/d/7/c/d7c4fb063202bcbf56b9ca0623aa0ce6fc26e542.jpeg
Under the current technical paradigm, the generation logic is still "arrange by pixels," which is fundamentally different from "render by characters." Extremely subtle gibberish may never be completely eradicated.
But that said, for over 90% of commercial application scenarios, this is already sufficient.
04 Un-deified Flaws and Boundaries
Even though it already sits on the world's number one throne, GPT-Image 2 also has its clumsy side.
Actual tests found that because the thinking mode calls for web searches and performs logical reasoning, when processing extremely complex fictional tasks, the model occasionally falls into a logical loop—thinking for nearly 40 minutes and still unable to answer.
At the same time, the API's claimed support for 2K甚至 (even) 4K resolution implies extremely high token consumption and latency.
For ordinary users, how to balance ultimate image quality with response speed will be a required course for future use.
In the field of technology, powerful capability is always a double-edged sword.
Whether it's image models or video models, they inevitably face the ethical challenges of deepfakes.
In most current test cases, the AI generates images of well-known figures, but if they are replaced with ordinary people who have posted photos on various social media platforms, it is already extremely difficult to distinguish the fake from the real without knowing the person.
Apart from the occasional gibberish in the background that might give the AI away, the human body itself has no flaws left.
Therefore, those fields that once required real people are facing an unprecedented crisis of trust.
The release of GPT-Image 2 has moved image generation models from toys to productivity tools.
In the past, people used AI for inspiration, but now AI is beginning to尝试接管 (attempt to take over) the entire process from conception, calculation, typesetting, to finished product.
For design practitioners, this is an era filled with FOMO (Fear Of Missing Out).
But for those who are good at using tools, possess product aesthetics, and logical thinking, this is also the best of times.
Images are beginning to learn to think,文字不再是像素的杂音 (text is no longer the noise of pixels).
People may truly be only one step away from that visual singularity of所思即所得 (what you think is what you get).








