如果把AI丢进一个没有标准答案的工程现场,它还能活下来吗?
长期以来,AI Agent看起来无所不能,实则大多是在已知知识库里“翻记忆”。
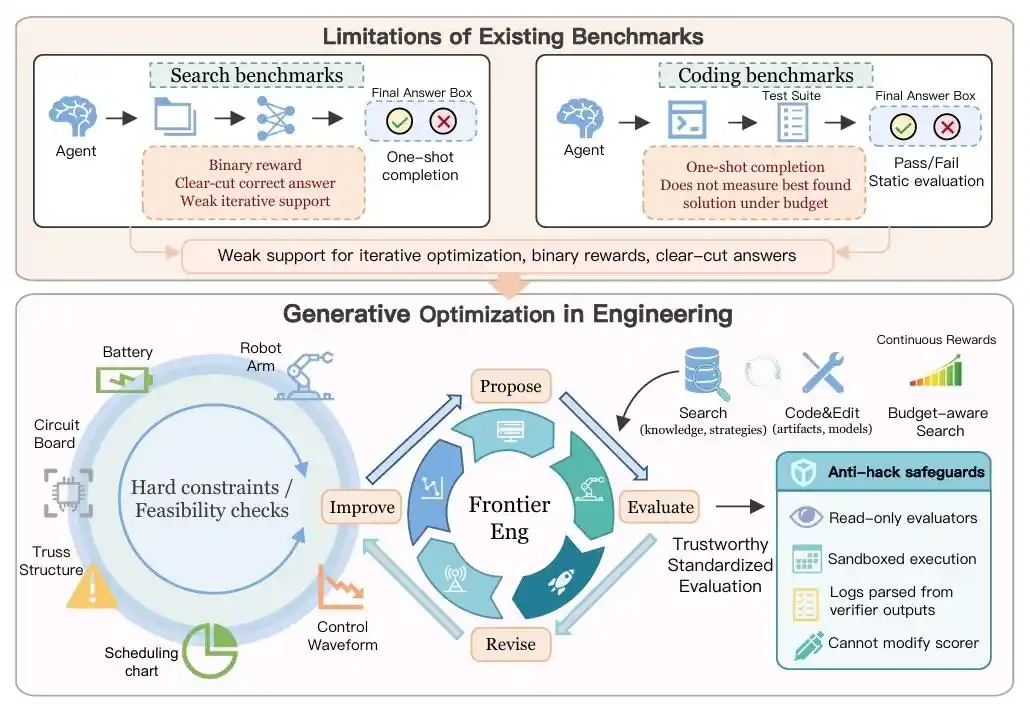
但真实的工程世界是残酷的:水下机器人的稳定性、动力电池的析锂边界、量子线路的噪声控制......这些问题没有“满分”,只有“更逼近极限的优化”。
近期,Einsia AI旗下Navers lab发布的Agent Benchmark——Frontier-Eng Bench,正式撕掉了AI“做题家”的标签。

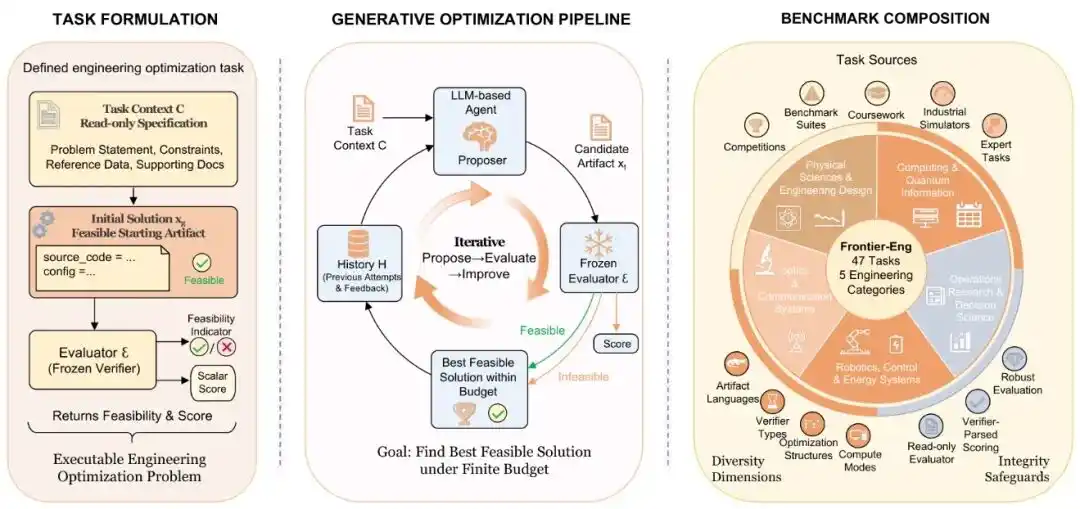
研究团队没有让AI刷那些陈旧的代码题,取而代之的是,给了它一套完整的“工程闭环”:提出方案、接入仿真器、吃报错、改参数、重跑。
在47个多学科交叉的硬核任务面前,AI必须表现得像资深工程师一样,在功耗、安全、性能的“不可能三角”中寻找最优解。
这不仅仅是一个测试集,它更像是一场关于Agent“进化”的预演。
当AI开始学会在反馈中自我修正,那个“人类提目标、AI则24小时不间断迭代”的Auto Research时代,可能比我们想象中更近了。
AI开始干“硬活”了
过去的大模型,更像一个超级学霸。
你抛出问题,它从海量训练数据里“翻记忆”,然后拼凑成一个看起来很合理的答案。
这种模式下,大模型本质上是在玩“文字接龙”,而非解决现实问题。
但Frontier-Eng Bench的出现,却让AI干起了“工程优化”的活儿。
流程转而变成了让AI先提出方案、再接入simulator跑实验、继而获取反馈和报错、修改参数和代码、再继续重跑,直到性能继续上涨。
在这种闭环系统中,AI的身份发生了质变。
你想让水下机器人更稳定?AI必须开始自动调控制器。
你想把机械臂速度再提升一点?AI得自己跑仿真。
某种程度上,AI们已经脱离了单纯的语义理解,开始像一个职业工程师那样,在真实环境反馈里做持续优化。
△
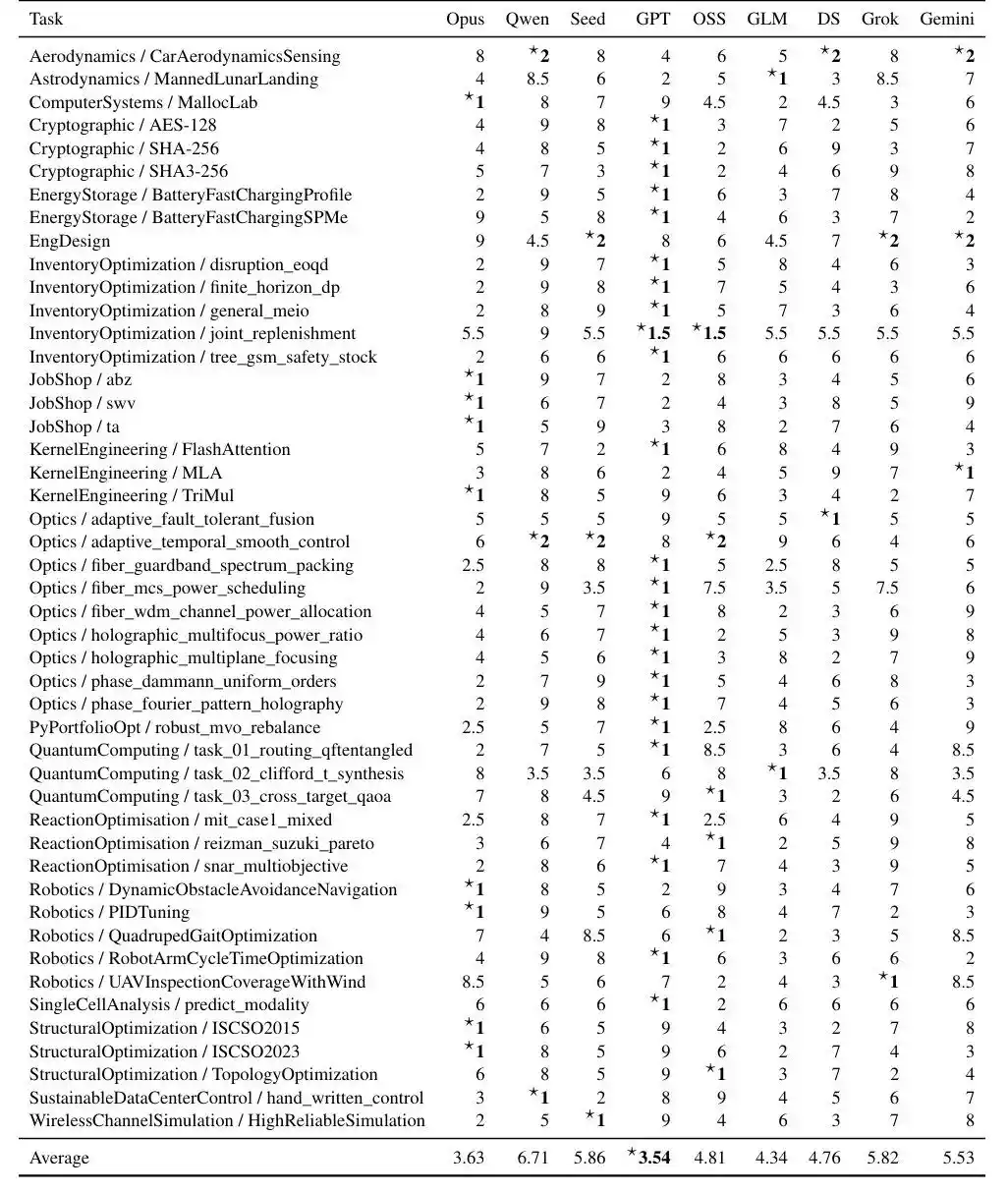
Frontier-Eng Bench最有意思的地方在于:它测的不是AI“答对没有”,而是AI到底能不能持续变强。
因为真实的工程优化,从来不是做选择题,没有唯一的标准答案。
以电池快充为例,目标听起来很简单——充得越快越好,但现实没那么容易。
AI必须在温度不能爆表、电压不能超速、电池寿命不能掉太快、还要避免析锂的严苛约束下,精准踩中性能的平衡点。
这意味着AI无法通过任何技巧性的“刷题”来通关,它必须在长程反馈中展现出持续进化的耐力。
那AI能不能在真实环境里做长期优化?
从结果来看,GPT5.4整体表现最稳,但距离把Benchmark“做穿”,AI们要走的路还很远。
△
Auto Research进入“迭代优化”时代
研究团队在论文里提了一个非常有意思的点:
真正高级的智能,本质上都依赖长期反馈闭环。
正如AlphaGo之所以能击败李世石,在于其每一步决策背后深不见底的海量模拟与即时反馈,而非对既定棋谱的死记硬背。
真正的科研也一样,顶级实验室并不依赖某一次的灵感爆发,而是不断地提假设、跑实验、看结果、改方案、再继续尝试。
工程优化也是同理,第一版往往谁都能做,真正难的,其实是最后那1%的性能跃迁。
Frontier-Eng Bench的意义就在于:它第一次开始系统性地测试AI的“迭代优化能力”,并总结出了两条近乎残酷的AI进化规律。
△
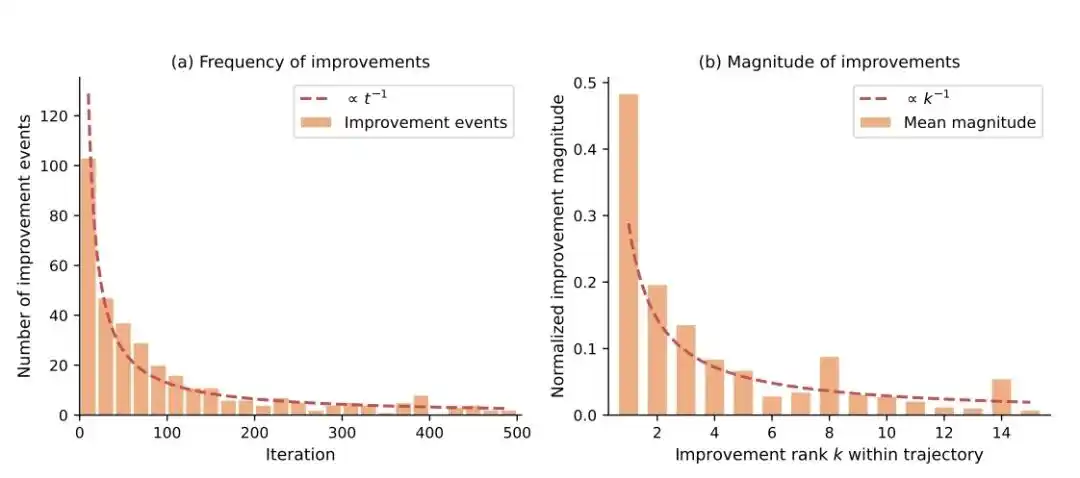
第一个规律是:越往后,提升越难。
这篇论文发现,Agent的改进频率和幅度都呈现幂律衰减:
- 改进频率∝ 1/迭代轮数
- 改进幅度∝ 1/改进次数
简单说就是:前面几轮涨得最快,后面越来越难、越来越小。
这很像真实研发过程,第一版AI能快速干掉大量“低垂果实”,但越往后越接近瓶颈,想再抠一点性能都得下狠功夫。
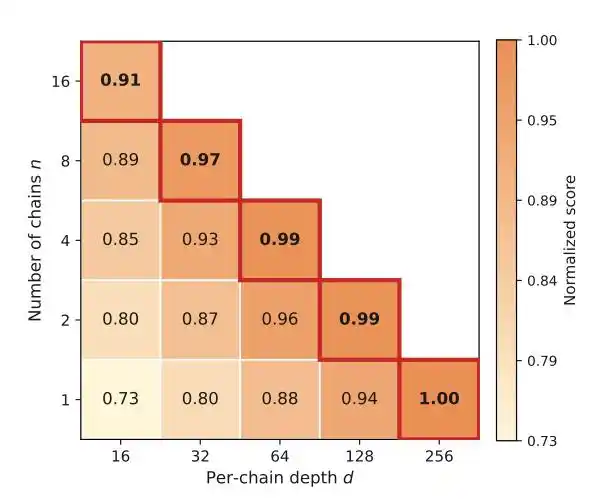
那是不是多开几条路并行试错,会更划算?答案藏在第二个规律里。
△
第二个规律:宽度有用,但深度更不可或缺。
并行多跑几条线能避免卡壳,但预算固定时,每多开一条链就会压浅深度。
很多工程突破需要靠持续积累、不断修正,才会出现结构性跃迁,并不是说靠“多试几次”就能实现。
这其实提示了我们下一代Agent的发展方向:不是“一次出答案”的模型,而是能在长程反馈里持续迭代、自我进化的系统。
AI工程师,可能真的要来了
这项研究真正的深远意义,在于它初步勾勒出了一套开始接近真实工程循环的AI系统。
△
试想一下,当AI接入工业软件、仿真环境、CAD系统、芯片设计工具、科学计算平台......
一场生产力模态的剧变便呼之欲出。
未来的实验室里,很可能会出现这样一种分工:
人类研究员负责提出方向和目标。
例如“把这个部件的能耗降低30%”、“把这个模型前向的GPU占用率压得更低”、“让机器人控制的稳定性再提升一点”、“让量子线路的保真度继续逼近极限”等等。
而AI负责“死磕路径”,它们围绕这些目标,持续优化。
例如自动运行仿真与实验、自动读取verifier与simulator的反馈,再继续修改和优化,24小时不停迭代。
这种进化逻辑,让AI摆脱了“辅助工具”的身份,开始像一个真正的工程团队那样去解决复杂系统问题,而且不知疲倦。
而Frontier-Eng这一Benchmark揭示的问题,其实也非常直接:
当AI开始学会“长期优化”,它距离真正的工程智能,还有多远?
论文题目:Frontier-Eng: Benchmarking Self-Evolving Agents on Real-World Engineering Tasks with Generative Optimization
项目主页:https://lab.einsia.ai/frontier-eng/
Arxiv: https://arxiv.org/abs/2604.12290
GitHub repo: https://github.com/EinsiaLab/Frontier-Engineering
本文来自微信公众号“量子位”,作者:允中






