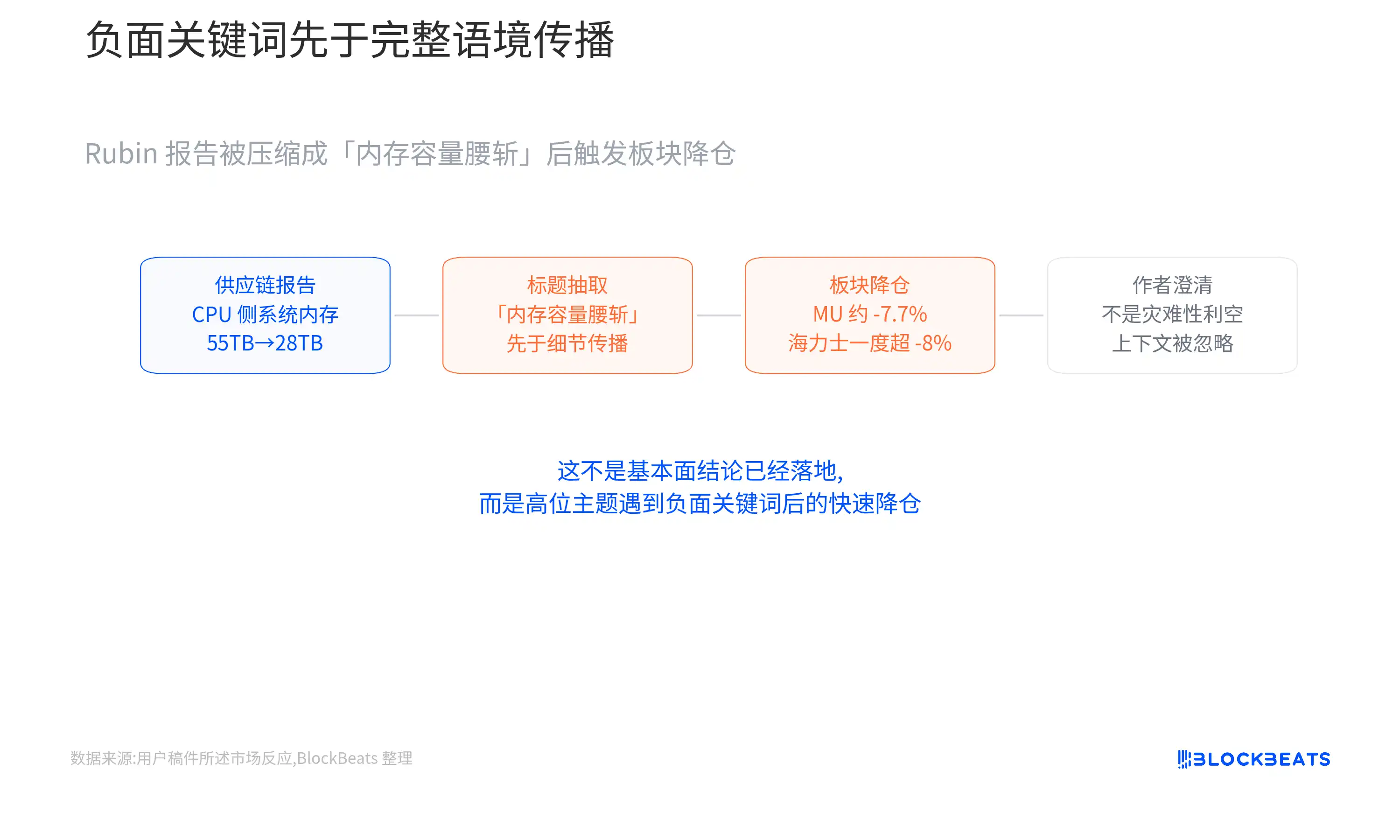
A supply chain report regarding NVIDIA's Rubin rack caused a first-round decline in the AI memory sector.
The report mentioned that single-rack memory capacity might drop from approximately 55TB to about 28TB. Subsequently, Micron fell about 7.7% in a single day, and SK Hynix opened down more than 8% the next day. More subtly, the report's author, Dylan Patel, later clarified that many reposts only captured the most eye-catching part, and this was not a "catastrophic bearish" report.
The reason for such a significant reaction is that it touched the most sensitive point of the current AI hardware trend. Over the past period, the market has been trading not on an ordinary memory cycle, but on the expectation that after the Rubin platform enters mass production, AI racks will continue to drive demand for HBM and supporting memory, thereby re-elevating memory suppliers' revenue and pricing power. Since GTC earlier this year, themes like HBM4, SK Hynix's market share, and Micron catching up in AI memory have been repeatedly traded in the market.
However, the phrase "memory being cut" is too crude.
The adjustments disclosed by SemiAnalysis primarily refer to changes in the configuration of SOCAMM and LPDDR on the CPU side within the Rubin NVL72 rack. Most systems might adopt 96GB modules instead of higher-capacity 192GB modules, reducing single-rack memory capacity from a planned ~55TB to ~28TB. This change affects the system memory value per rack but cannot directly imply that HBM4 demand on the GPU side has been simultaneously downgraded.
What really needs to be dissected is which profit pool this adjustment affects and which expectation the market is currently trading on.
Why Did AI Memory Stocks Plunge Collectively?
The market sold off based on a positioning reaction when a high-flying theme encountered negative keywords.
Currently, the confirmed part is that the market reaction was heavy, but the event itself remains at the level of a supply chain report. SemiAnalysis disclosed that NVIDIA might downgrade the CPU-side SOCAMM configuration to ensure the delivery schedule for the Rubin NVL72. The numbers mentioned in the report include single-rack memory capacity dropping from ~55TB to ~28TB, and rack cost decreasing from ~$7.6 million to ~$6.8 million. These numbers should be understood as the reporting perspective of SemiAnalysis, not yet the final confirmed BOM (Bill of Materials) from NVIDIA.
Over the past few quarters, the rise of AI memory stocks relied on a very smooth narrative: the more AI racks, the greater the shortage of advanced memory, and the thicker the profits for suppliers.
The simpler this story, the greater the killing power of a negative headline. Once "memory capacity halved" appeared, the market would first downgrade the memory value per rack, rarely distinguishing immediately which type of memory was being adjusted.
Micron's reaction is most illustrative.
It is both a traditional DRAM supplier and a beneficiary of AI server memory upgrades. Much of the upside previously priced in by the market came from the repricing notion that "AI memory is no longer just a cyclical product." If Rubin's per-rack system memory capacity declines, capital would immediately worry whether expectations for Micron's per-rack revenue from SOCAMM and LPDDR segments were set too high.
SK Hynix also followed the decline, indicating the shock has extended beyond a single supplier.
It is stronger in the HBM field, and the market had previously circulated rumors that it secured the majority of HBM orders related to Vera Rubin. But when AI memory trading becomes crowded, capital does not wait to verify all details before acting. The synchronous decline of memory stocks reflects a contraction in sector risk appetite, not that each company suffered the same fundamental shock.
Dylan Patel's subsequent clarification also points to this. He stated the report was not intended to create a "disaster" narrative, and many missed the context.
Translated into market language, capital did not fully trade on a supply chain analysis but rather on a rapid position reduction after a high-flying sector encountered negative keywords.
AI Memory Begins Redividing Profit Pools
What was primarily downgraded this time is the CPU-side system memory, not the GPU-adjacent HBM4.
Memory in a Rubin rack cannot be summarized with one word. The simplest breakdown is into two layers:
The first layer is GPU-side HBM4, serving the accelerator chip itself;
The second layer is CPU-side SOCAMM and LPDDR, more akin to the system RAM for the entire machine.
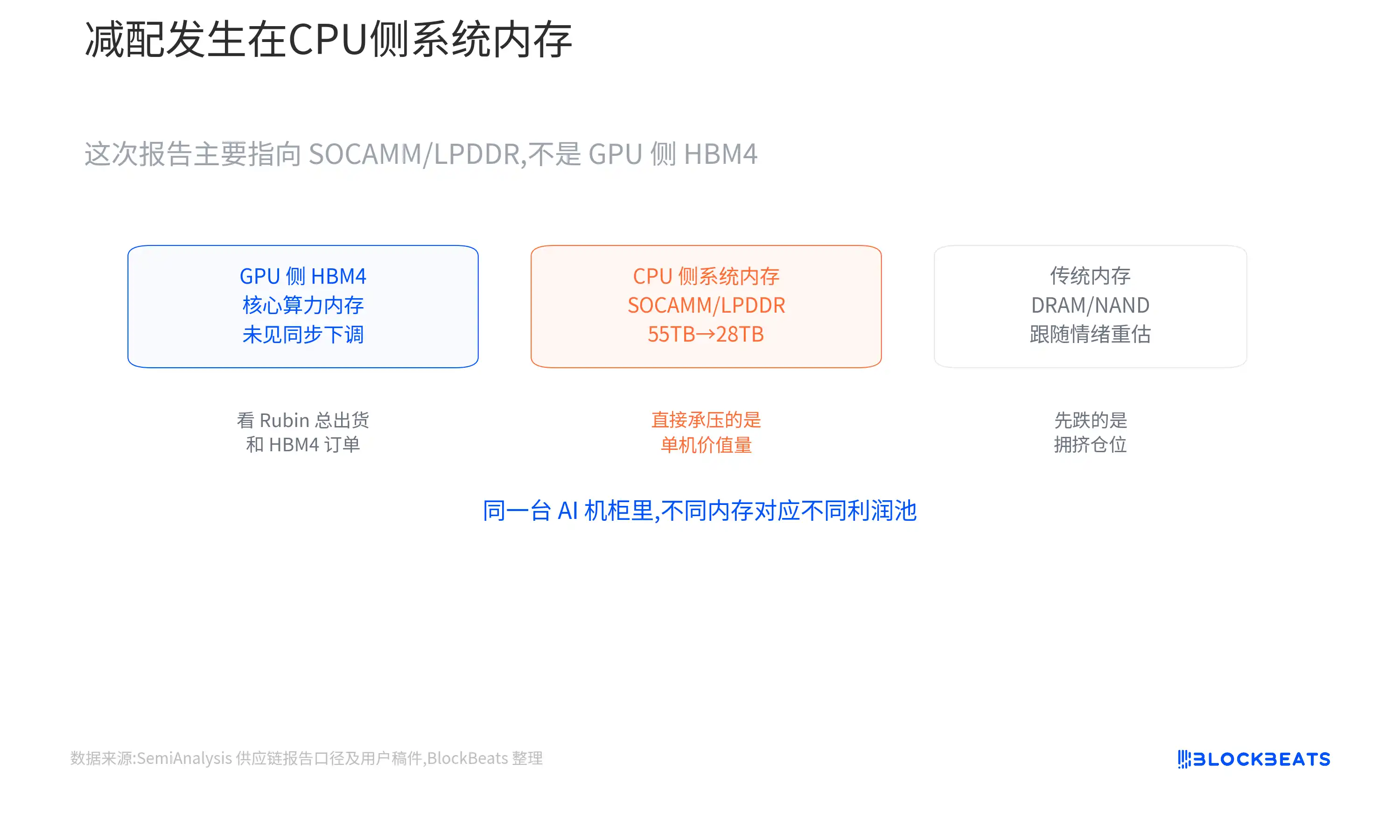
The former determines the speed at which data is fed to the GPU, while the latter affects overall machine scheduling, maintenance, and the performance of some workloads.
The "55TB to 28TB" mentioned by SemiAnalysis primarily falls on CPU-side system memory.
It might change the quantity, capacity, and procurement cost of SOCAMM modules per Rubin NVL72 rack. If most systems shift from 192GB modules to 96GB modules, the per-unit value of high-capacity SOCAMM indeed decreases, pressuring the revenue upside for related suppliers.
But GPU-side HBM4 is another line.
The Rubin platform still revolves around the Rubin GPU and Vera CPU, and HBM4 remains the core memory component for GPU packaging and computing power release. Current information does not show that HBM4 capacity or Rubin GPU shipments have been simultaneously downgraded. Previous multi-party predictions still regard HBM as one of the tightest and most pricing-powerful segments in AI servers, with SK Hynix also seen by the market as a primary beneficiary.
Think of an AI rack as an extremely expensive high-performance server.
HBM is closer to high-speed memory attached next to the GPU, while SOCAMM is closer to replaceable system memory for the whole machine. This adjustment mainly targets the latter.
For holdings, the distinction is very direct: if Micron has greater exposure in the SOCAMM segment, the downgrade in per-unit value would hit its expectations first; SK Hynix's HBM logic is relatively independent but would also be dragged down by sector sentiment in crowded trading.
Extrapolating system memory reduction directly into a breakdown of HBM4 demand lacks sufficient evidence.
A more reasonable breakdown is that the CPU-side profit pool indeed faces downward revision pressure, while the GPU-side HBM still depends on total Rubin shipments and HBM4 order cadence.
The AI memory theme can no longer be covered by a single line of "all memory is strong." Micron, SK Hynix, and Samsung Electronics have different exposures in HBM, SOCAMM, traditional DRAM, and NAND. Different types of memory within the same rack also correspond to different prices, margins, and supply-demand constraints.
Can Cost Reduction Translate to More Rack Shipments?
An optimistic interpretation stems from cost and delivery cadence.
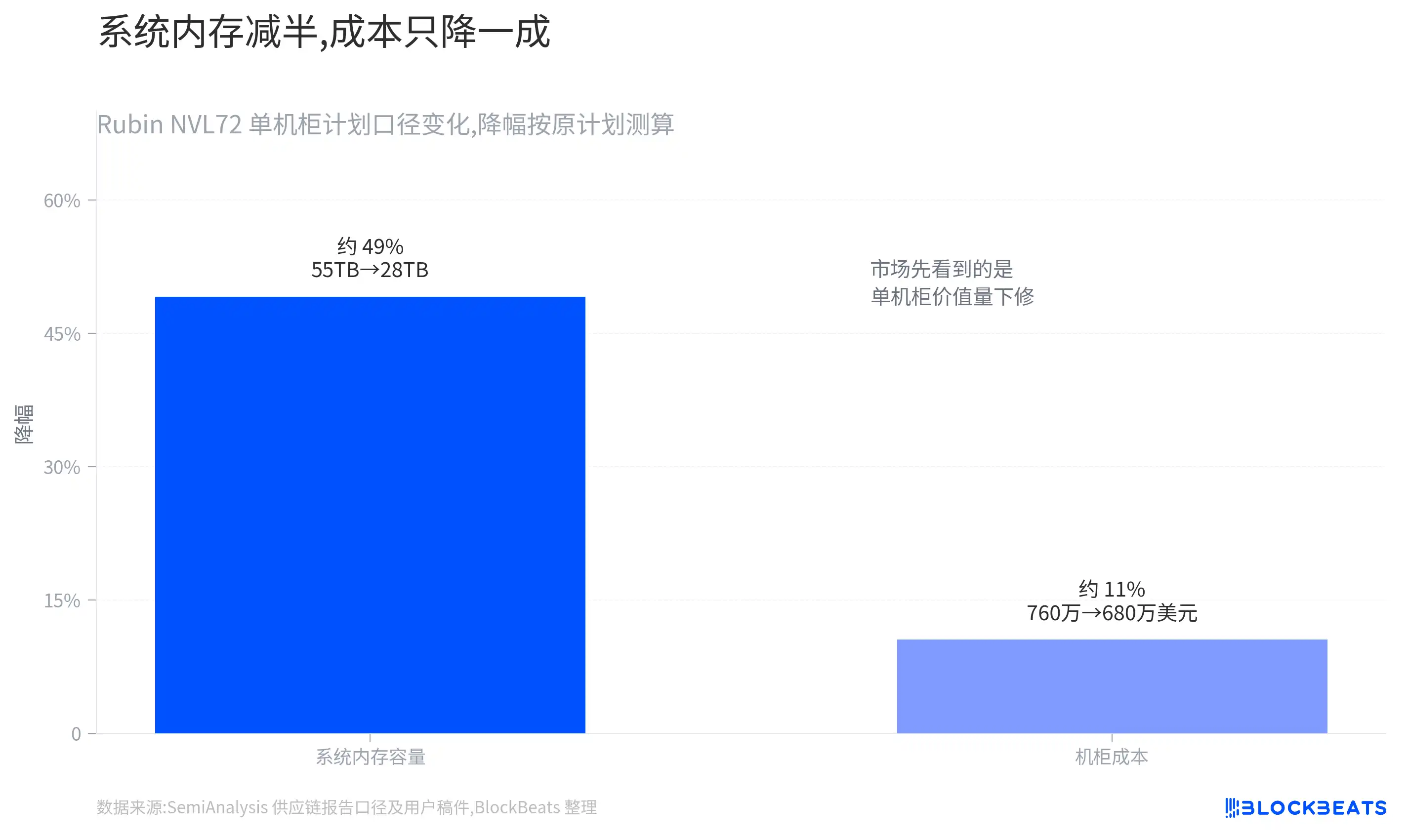
SemiAnalysis's calculations show that the Rubin NVL72 rack cost might drop from ~$7.6 million to ~$6.8 million, a reduction of ~$800,000.
For cloud vendors like Microsoft, Google, Amazon, and Meta, AI racks are not just hardware purchases but involve calculating hourly computing costs, delivery time, and stability of large-scale deployment.
If a reduced configuration allows Rubin to be delivered faster, some per-unit value decline might be offset by more racks.
The logic is not complicated. If high-capacity SOCAMM supply is tight, NVIDIA choosing a more readily available configuration can lower the BOM per rack and reduce the risk of a single component delaying overall machine delivery.
For buyers, if a lower system memory configuration does not significantly impact core workloads, getting racks earlier might be more attractive than waiting for fully configured versions.
The problem is that this step remains speculative for now.
Cost reduction does not automatically equal increased orders. For "per-unit value decline" to be offset by "increased total rack volume," NVIDIA needs to deliver more Rubin NVL72 racks, and cloud vendors also need to add or advance purchases.
Existing materials lack public orders, quarterly guidance, or actual shipment data to prove this.
To understand with a simple scenario: if a certain SOCAMM capacity is nearly halved per rack, then total rack shipments need to increase significantly for the total Bit demand in this segment to return to previous expectations.
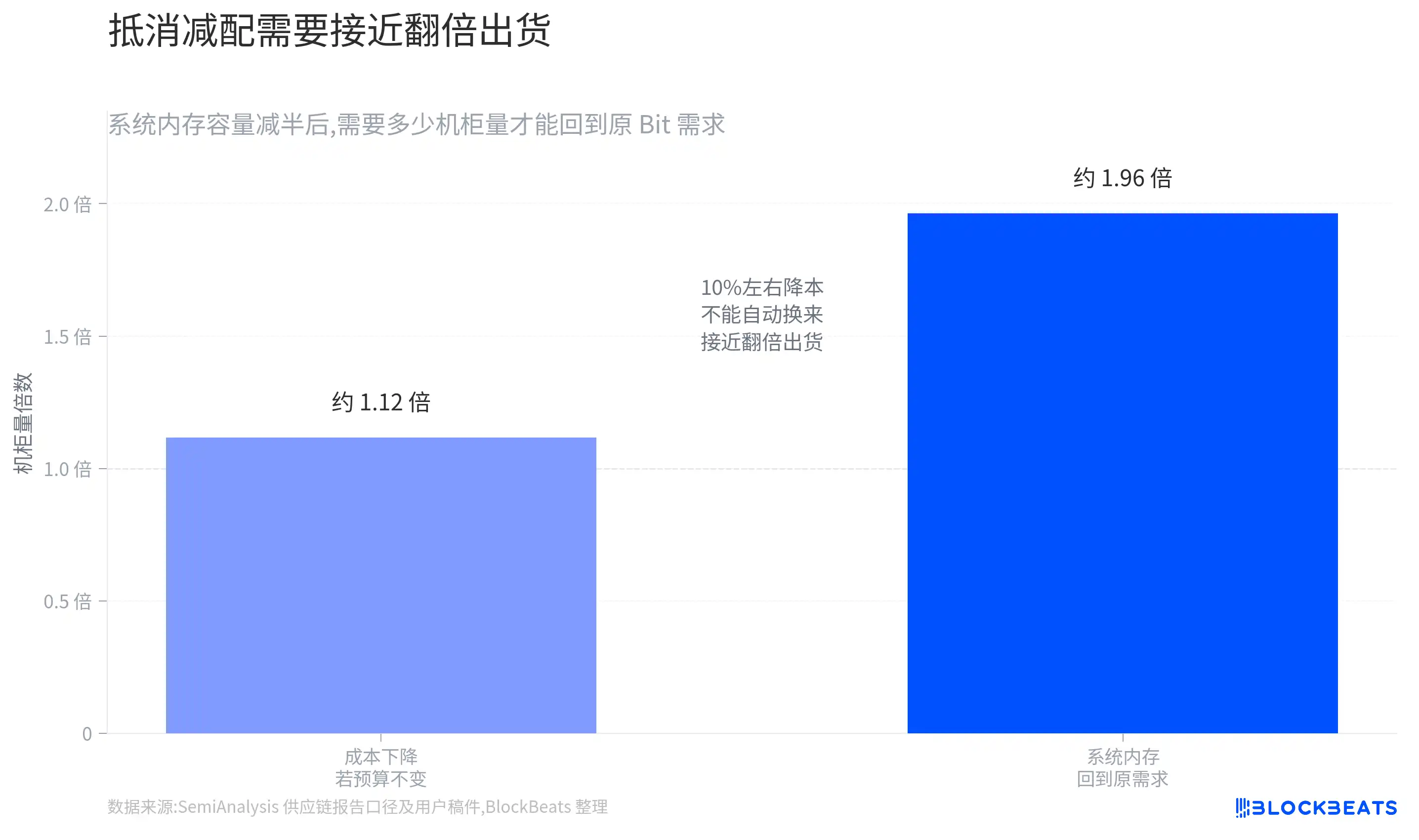
Even with a ~10% cost reduction, one cannot directly conclude that customers will buy enough extra racks. Large cloud vendor procurement is also influenced by power, data center construction, GPU supply, advanced packaging, and networking equipment; a single BOM reduction is just one variable.
The HBM situation is relatively more stable but not completely immune.
If total Rubin shipments remain robust, HBM4 will still be one of the most direct beneficiaries; if subsequent evidence shows overall machine delivery is hampered by other bottlenecks, HBM would also be affected by the platform's shipment cadence.
The difference is that this report did not directly downgrade HBM4 configuration. What the market awaits is total rack shipment volume, not just focusing on SOCAMM capacity numbers.
Shipment Data is the True Pricing Anchor
The current biggest risk is that the market first revalues based on profit pool breakdown, but subsequent data fails to back the optimistic interpretation.
If NVIDIA or the supply chain ultimately confirms that Rubin NVL72 will long-term adopt lower SOCAMM configurations, while total rack shipments are not significantly revised upward, CPU-side system memory suppliers will face more lasting compression of revenue expectations.
For Micron, the key is not just the overall label of "benefiting from AI memory," but the revenue breakdown of different products.
In subsequent earnings reports and conference calls, it's necessary to see if management discloses growth cadence for AI server-related DRAM, SOCAMM, HBM, and whether margins change due to specifications, prices, or customer bargaining power.
If the company only provides optimistic statements on overall demand but cannot explain the impact of SOCAMM configuration adjustments, the market may continue to discount it.
For SK Hynix, the verification point leans more towards HBM.
If its HBM4 order share, shipment cadence, and pricing maintain strength, this pullback resembles more of a sector sentiment fluctuation; if subsequent Rubin total shipments or HBM delivery cadence also show downgrades, the market would then extend the shock from SOCAMM to the HBM theme.
This is also a typical evolution as the AI memory theme reaches its mid-stage.
Early on, the market bought the direction: more AI racks are being built, and advanced memory is getting scarcer.
Now, representative stocks have accumulated significant gains, and capital is beginning to scrutinize whether each piece of profit is truly materializing. A single supply chain detail can trigger a 7%-8% intraday swing, indicating sector trading has become somewhat crowded, making negative information easier to amplify.
Before actual shipment and earnings breakdowns emerge, labeling this pullback as "bad news fully priced in" or "AI demand collapse" is premature.
A more prudent view is to acknowledge the pressure of per-unit value downgrade on the CPU side, while pricing HBM4 and SOCAMM separately.
What can most change the judgment next is still whether NVIDIA confirms the final BOM for Rubin NVL72, whether actual Rubin rack shipment plans can be revised upward, and the revenue exposure and margin changes for Micron, SK Hynix, and Samsung Electronics in HBM versus SOCAMM/LPDDR.