Il y a quelques jours, Anthropic a publié un article intitulé "When AI Builds Itself" (Lorsque l'IA se construit elle-même), suscitant rapidement un large débat. L'article révèle un ensemble de données internes frappantes : d'ici mai 2026, plus de 80 % du code de la base de code d'Anthropic aura été écrit par Claude ; la quantité quotidienne de code fusionné par les ingénieurs est 8 fois supérieure à celle de 2024. Dans un test interne, Claude a amélioré la vitesse d'exécution d'un code d'entraînement d'environ 52 fois par rapport à une référence, alors qu'un chercheur humain expérimenté aurait généralement besoin de 4 à 8 heures pour atteindre une accélération de 4 fois.
Anthropic dirige cette trajectoire vers une destination plus profonde : « l'amélioration de soi récursive » - des systèmes d'IA conçoivent, construisent et entraînent de manière autonome leurs versions successives, l'humain ne pilotant plus chaque étape. Il est à noter que l'entreprise appelle également à une coordination sectorielle, pour disposer d'options de pause voire d'arrêt temporaire du développement de l'IA de pointe lorsque le moment de l'amélioration de soi récursive arrivera. Et Anthropic agit déjà en ce sens : il restreint l'utilisation du dernier Claude Fable 5 pour la recherche en IA de pointe.
Et maintenant, Recursive Superintelligence annonce avoir franchi la première étape vers la recherche en IA automatisée.
Cette nouvelle société co-fondée par Tian Yuan Dong est sortie du mode furtif il y a seulement un mois, et publie déjà son premier résultat technique public. Ils ont créé un système ouvert de découverte automatisée des connaissances, et ont obtenu des résultats SOTA sur trois benchmarks. En termes simples, ils ont réussi à faire en sorte que l'IA exécute les expériences à votre place.

https://x.com/tydsh/status/2065062838255649082
Premier résultat : faire exécuter vos expériences par l'IA
Le premier résultat technique public de Recursive s'intitule « Premiers pas vers la recherche en IA automatisée ».

Tweet : https://x.com/Recursive_SI/status/2064980090702962699
Dépôt Git : https://github.com/recursive-org/first-steps-toward-automated-ai-research
Article de blog : https://www.recursive.com/articles/first-steps-toward-automated-ai-research
En une phrase, le cœur de ce travail est : construire un système capable de faire progresser de manière autonome la boucle de recherche en IA, et battre les meilleurs scores sur trois benchmarks.
Avant de détailler les résultats, il est nécessaire de comprendre la logique de conception de ce système.
Le processus traditionnel de recherche en IA est une boucle « idée → code → expérience → analyse des résultats → nouvelle idée » fortement dépendante de l'humain. Son goulot d'étranglement n'est pas la puissance de calcul, mais l'humain. Les chercheurs capables de concevoir des pipelines d'entraînement de pointe dans le monde se comptent sur les doigts d'une main, et chaque itération expérimentale nécessite leur forte implication.
Le système de Recursive tente d'automatiser cette boucle.
Son mode de fonctionnement est le suivant : pour un objectif d'optimisation clair, le système propose automatiquement des idées d'expériences, implémente le code, exécute la validation, apprend des résultats, puis décide de la prochaine étape de recherche. Plusieurs pistes de recherche peuvent être menées en parallèle, les découvertes efficaces peuvent être réutilisées entre tâches, et un mécanisme de détection du "reward hacking" (triche sur la récompense) est intégré dans toute la boucle, empêchant le système de "tricher" en faisant monter les métriques d'évaluation sans vraiment améliorer quoi que ce soit.
Ce n'est pas un outil spécialisé pour un seul problème, mais plutôt un cadre générique d'automatisation de la recherche, transversal aux domaines. Recursive utilise trois scénarios de test très différents pour le démontrer.
Trois terrains d'expérimentation, trois nouveaux records
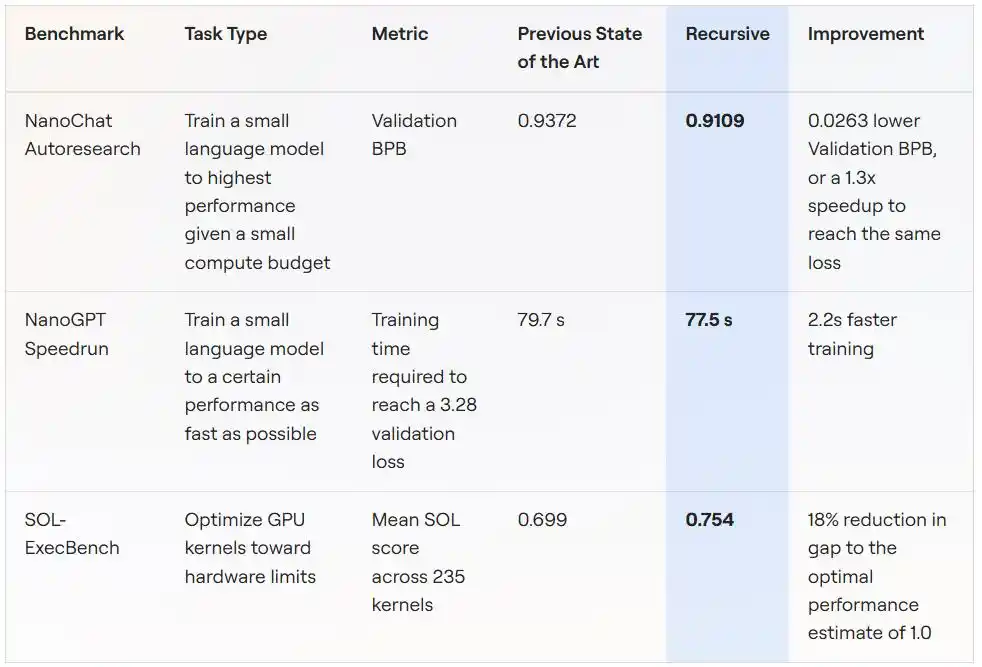
Scénario 1 : Entraînement de petit modèle avec un budget de calcul fixe (NanoChat Autoresearch)
Ce benchmark vient du projet "autoresearch" lancé par Andrej Karpathy (auteur de GPT-2, cofondateur d'OpenAI) : sur un seul GPU, avec un budget d'entraînement fixe de cinq minutes, entraîner un petit modèle de langage pour obtenir la plus faible perte de validation possible (mesurée en BPB, plus bas c'est mieux).
Ce scénario se prête naturellement à la recherche automatisée : cycles d'expérimentation courts, variance des métriques faible, comportements frauduleux relativement faciles à détecter. C'est pourquoi un projet communautaire nommé « autoresearch@home » tourne sur ce benchmark depuis longtemps – des dizaines de chercheurs humains et des centaines d'agents d'IA collaborent pour repousser continuellement la métrique.
Le système de Recursive, partant du même code initial, a finalement fait passer le BPB de validation du meilleur score communautaire de 0,9372 à 0,9109, une amélioration de 0,0263 BPB. Autrement dit : pour la même qualité d'entraînement, la solution de Recursive nécessite 1,3 fois moins de temps d'entraînement que celle des concurrents.
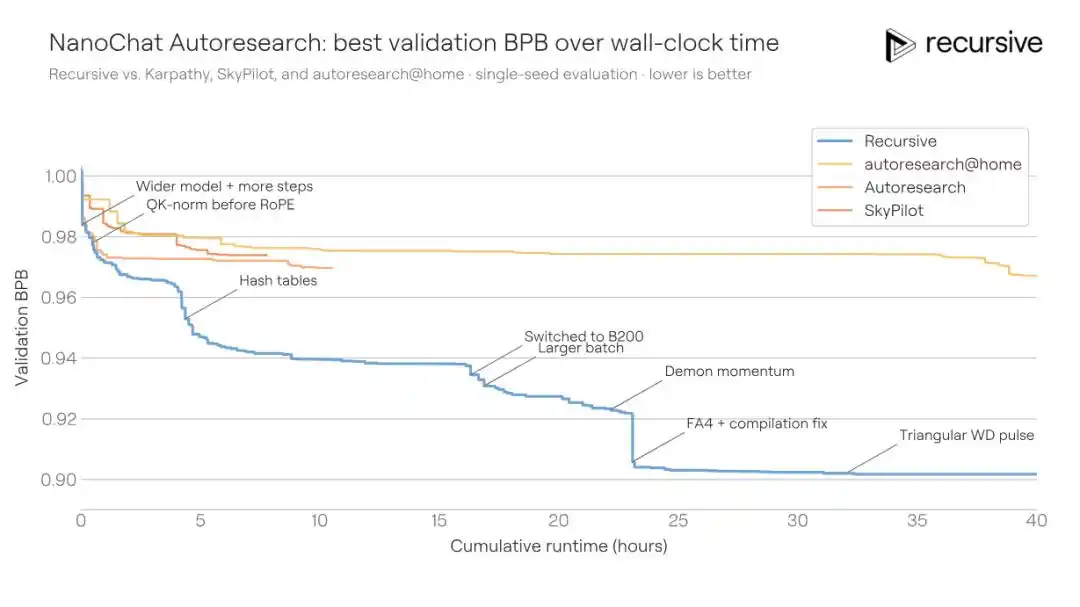
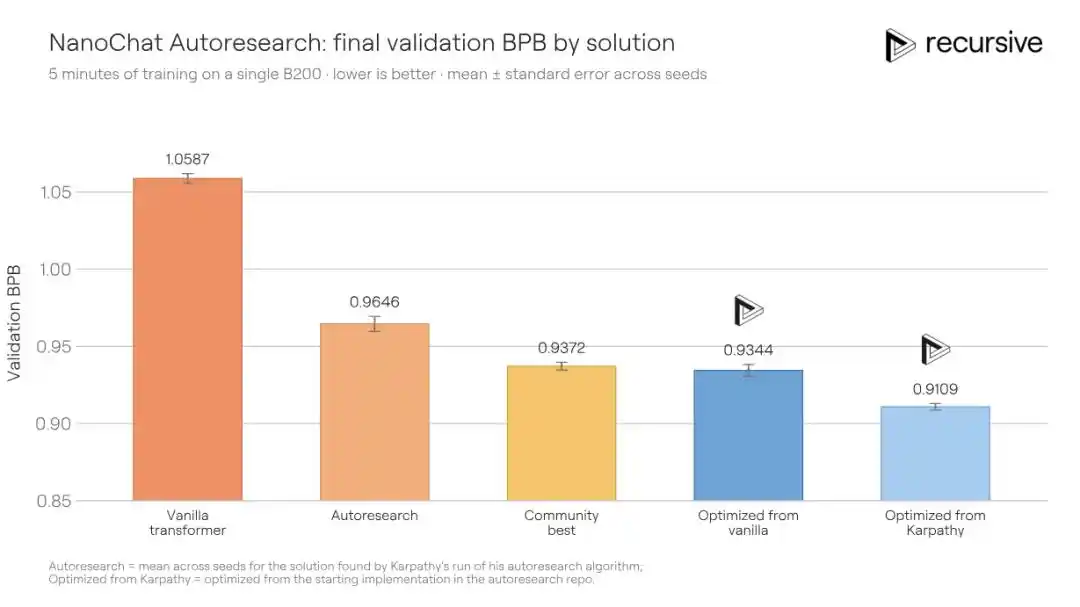
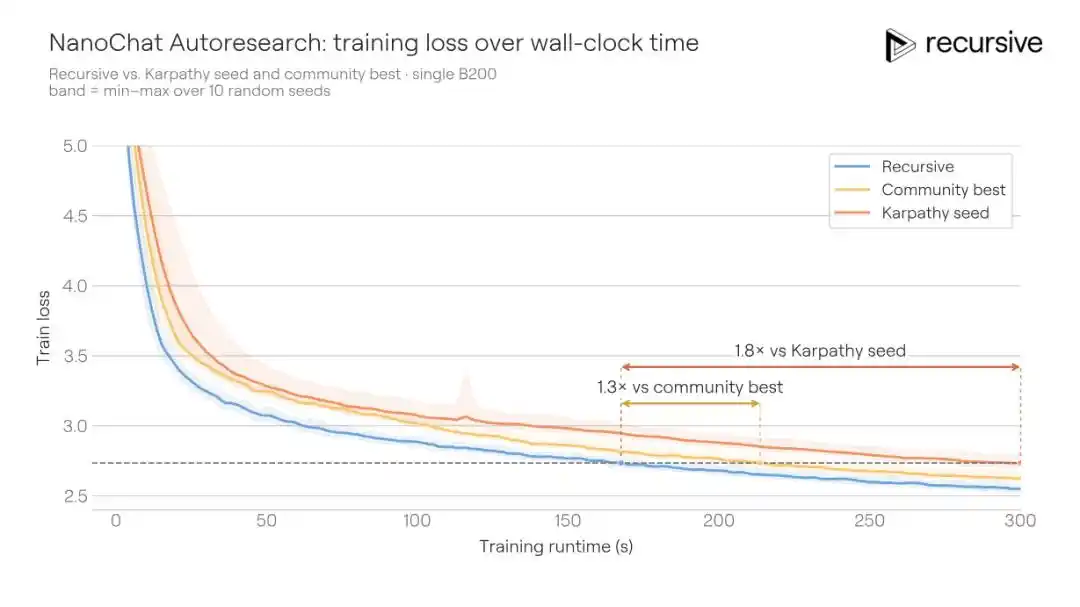
Les améliorations découvertes par le système ne sont pas dues à une seule astuce. Il combine des ajustements d'architecture, des pertes auxiliaires, des modifications du mécanisme d'attention, le comportement de l'optimiseur, la planification de la décroissance de poids (weight decay), les paramètres du compilateur, entre autres. L'une des découvertes clés est un mécanisme de mémoire de contexte court plus riche : dans le chemin "value" de l'attention, incorporer simultanément des informations sur les bigrammes (paires de mots adjacents) et les trigrammes (triplets) via une table de hachage, avec une pondération apprise par une porte. Différentes couches de Transformer utilisent différentes fonctions de hachage, réduisant ainsi la probabilité de collisions répétées entre les couches.
Cette astuce est conceptuellement liée à des travaux comme DeepSeek Engram, mais le système l'a déployée sous une variante spécifique non encore documentée dans la littérature publique, dans un scénario à budget fixe.
Scénario 2 : Course à la vitesse d'entraînement maximale (NanoGPT Speedrun)
Si le premier scénario consiste à « aller un peu plus loin » sur un résultat d'une communauté active, celui-ci est bien plus difficile.
NanoGPT Speedrun est un autre benchmark lancé par Karpathy, optimisé par la communauté pendant plus de deux ans : le temps minimum requis pour entraîner un modèle GPT jusqu'à une perte de validation de 3,28 sur 8 GPU H100. Depuis mi-2024, la communauté a compressé le temps d'environ 45 minutes à 79,7 secondes grâce à 83 contributions documentées. Chaque nouvelle solution doit gagner du temps sur une base de code déjà extrêmement optimisée, ce qui est très difficile.
Le système de Recursive, partant de la solution optimale existante, a de nouveau compressé le temps d'entraînement à 77,5 secondes, économisant 2,2 secondes. Cela équivaut, voire dépasse, les améliorations récentes réalisables par les contributeurs humains.
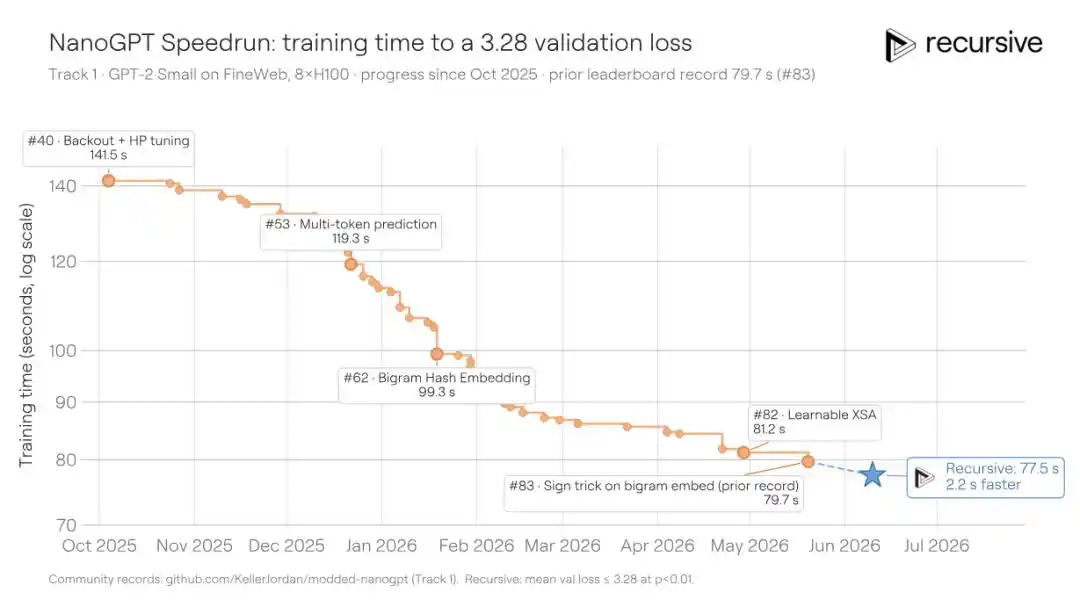
Les astuces principales trouvées par le système cette fois-ci incluent :
Calcul de l'attention en précision FP8. La solution communautaire n'utilise FP8 (virgule flottante 8 bits) que dans la dernière couche du modèle (la tête de modèle de langage), alors que le système étend FP8 aux opérations matricielles des couches d'attention, utilisant FP8 en propagation avant pour doubler le débit des Tensor Cores, et conservant BF16 en rétropropagation pour maintenir la stabilité.
Bruit d'exploration avec recuit dans l'optimiseur. Le système injecte un bruit gaussien de moyenne nulle dans les étapes de mise à jour de l'optimiseur NorMuon, l'amplitude du bruit décroissant linéairement jusqu'à zéro avec la progression de l'entraînement. Cela ressemble à donner à l'optimiseur un mode de comportement « exploration audacieuse d'abord, convergence robuste ensuite », aidant la solution finale à se situer dans un bassin de perte plus plat.
Un noyau MLP fusionné plus léger. Le système a réécrit un noyau GPU Triton pour que la propagation avant ne stocke que les valeurs d'activation après application de ReLU et élévation au carré, et recalcule les résultats intermédiaires non carrés à l'intérieur du noyau lors de la rétropropagation, économisant un aller-retour complet de lecture/écriture du tenseur d'activation dans la mémoire vidéo à haute bande passante – c'est une accélération directe au niveau matériel.
Trois améliorations, relevant de trois domaines d'expertise différents : stratégie de précision, conception d'optimiseur, programmation de noyaux GPU. Le fait que le système ait trouvé de la marge sur un résultat optimisé par la communauté pendant deux ans parle de lui-même.
Scénario 3 : Optimisation de noyaux GPU (SOL-ExecBench)
Les deux premiers scénarios opèrent au niveau de l'entraînement des modèles, le troisième s'enfonce plus profondément : l'optimisation des noyaux de calcul GPU.
SOL-ExecBench est un benchmark proposé par NVIDIA, contenant 235 tâches d'écriture de noyaux, couvrant de multiples charges de travail réelles : multiplication matricielle, réduction, couches de normalisation, composants d'attention, routines de quantification, blocs fusionnés, etc. Le critère de notation est le score SOL : 0,5 correspond à une implémentation PyTorch de référence, 1,0 correspond à la limite théorique du matériel. Le meilleur score public précédent était de 0,699.
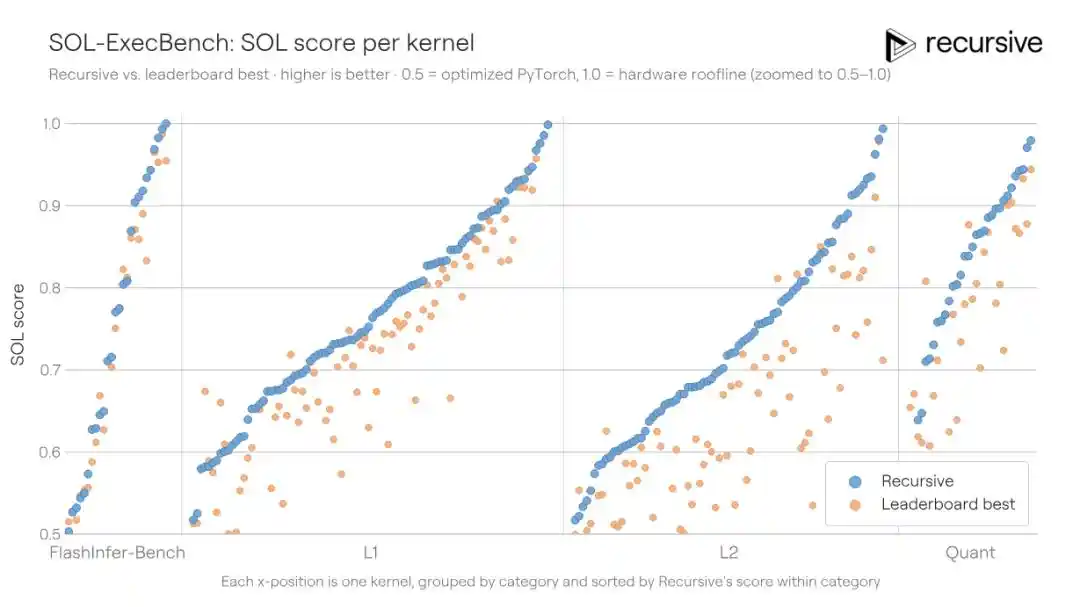
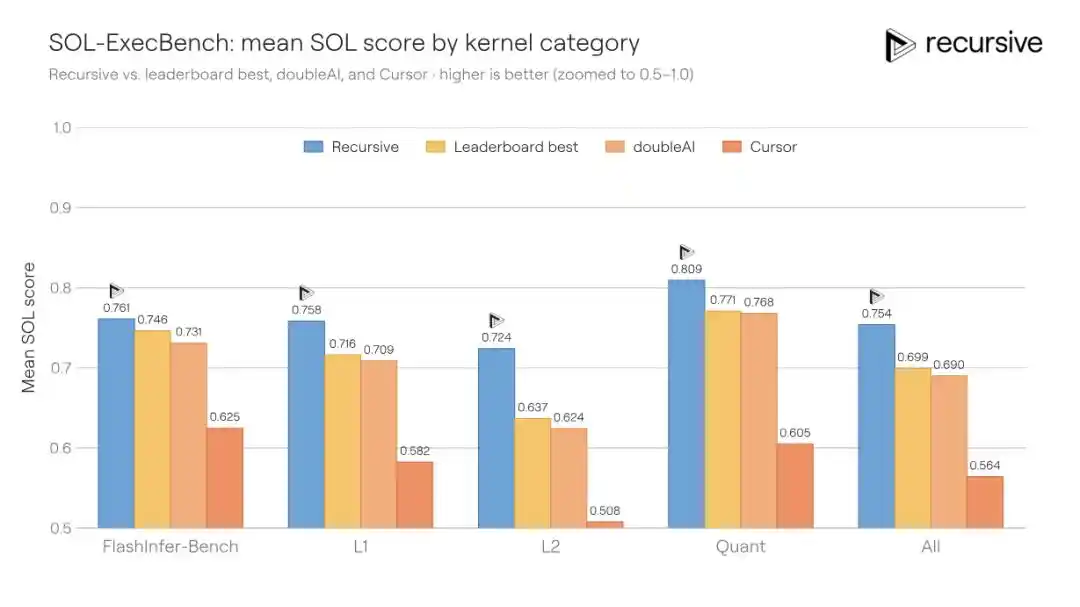
Le système de Recursive a été exécuté sur l'ensemble des 235 noyaux, permettant la réutilisation des modèles d'optimisation découverts entre les tâches (par exemple, les stratégies de transfert mémoire, les méthodes de tiling, les astuces de réduction). Le score final est monté à 0,754, réduisant l'écart avec la limite matérielle de 18%.
Ce scénario a une signification particulière, car l'ingénierie des noyaux est un domaine extrêmement spécialisé – les ingénieurs capables d'écrire des noyaux Triton/CUDA efficaces sont également rares à l'échelle mondiale. L'équipe de Recursive admet d'ailleurs dans son article de blog qu'eux-mêmes ne sont pas des experts du domaine des noyaux : « Ces idées viennent du système lui-même, et non de notre expertise de fond. »
Recursive : Utiliser l'IA pour améliorer récursivement l'IA
L'entreprise derrière ce résultat, Recursive Superintelligence, a été fondée fin 2025 - début 2026 et est sortie du mode furtif le mois dernier. Les membres fondateurs, outre Tian Yuan Dong, ancien directeur scientifique chez Meta FAIR, incluent :
Richard Socher, PDG de Recursive, ancien Chief Scientist de Salesforce
Alexey Dosovitskiy, ancien chercheur chez Google DeepMind et premier auteur du Vision Transformer, plus de 160 000 citations Google Scholar
Tim Rocktäschel, ancien scientifique principal chez DeepMind et professeur d'intelligence artificielle à l'UCL
Peter Norvig, ancien directeur de la recherche chez Google, co-auteur avec Stuart Russell du célèbre manuel "Artificial Intelligence: A Modern Approach"
Caiming Xiong, ancien vice-président AI de Salesforce
Tim Shi, ancien chercheur chez OpenAI, co-fondateur et CTO de l'entreprise d'IA Cresta
Josh Tobin, CTO de Recursive, ancien responsable de recherche chez OpenAI et Uber ATG
Jeff Clune, ancien vice-président de la recherche chez Google DeepMind, professeur d'informatique à l'Université de Colombie-Britannique, Canada
Et cette startup, avant même d'avoir un produit public, a déjà levé 6,5 milliards de dollars de financement, avec une valorisation de 46,5 milliards de dollars, menée par GV (Google Ventures) et Greycroft, avec la participation de NVIDIA et AMD Ventures.
La proposition centrale de l'entreprise correspond directement à son nom : construire des systèmes d'IA capables d'améliorer récursivement leurs propres capacités de recherche, faire participer et accélérer le processus de R&D de l'IA elle-même, pour finalement former une boucle d'auto-amélioration continue.
Pour plus de détails, voir l'article « Après avoir quitté Meta, Tian Yuan Dong vient d'annoncer sa création d'entreprise ».
Bien sûr, sur le plan du secteur, Recursive n'est pas seul. AMI Labs de Yann LeCun a levé 10 milliards de dollars en mars de cette année, Ineffable Intelligence de David Silver a obtenu 11 milliards de dollars en tour de seed en avril, tous deux visant une direction similaire : faire en sorte que les systèmes d'IA génèrent des connaissances de manière autonome, réduisant l'intervention humaine dans le processus de recherche. Mais en termes de rythme des résultats publics, cette « première étape » de Recursive est probablement l'une des démonstrations techniques les plus concrètes et reproductibles parmi les entreprises similaires à ce jour.
L'aube du paradigme récursif
Ce résultat publié par Recursive, dans le contexte plus large du secteur, représente la mise en œuvre préliminaire d'un nouveau paradigme de R&D en IA : faire porter au système d'IA lui-même le rôle principal de la recherche.
La logique centrale de cette « IA récursive » n'est pas complexe : L'IA améliore les capacités de recherche en IA, l'IA améliorée peut ensuite s'améliorer elle-même plus efficacement, et ainsi de suite. Elle ne dépend pas d'une percée unique, mais d'un système générant continuellement des percées.
Cette approche a une signification importante pour l'économie même de la recherche en IA. Les pipelines d'entraînement des modèles de pointe dépendent encore fortement d'un petit nombre de chercheurs possédant des compétences spécifiques, et les personnes capables de ce travail ne sont pas plus de quelques milliers dans le monde. Si des systèmes de recherche automatisés peuvent prendre en charge ne serait-ce qu'une partie de ce travail, la vitesse de progrès de l'IA et les courbes de coûts changeront.
Ce constat fait écho à d'autres voix récentes du secteur. Par exemple, l'article d'Anthropic "When AI Builds Itself" mentionné en début d'article, dont le ton n'est pas léger – il appelle à une coordination sectorielle, pour avoir des options de pause voire d'arrêt temporaire du développement de l'IA de pointe lorsque le moment de l'amélioration de soi récursive arrivera, afin de laisser le temps aux structures sociales et à la recherche sur l'alignement (alignment) de suivre le rythme. Pour plus de détails, voir « L'auto-évolution de l'IA est trop rapide, Anthropic appelle à une suspension mondiale du développement ».

https://www.anthropic.com/institute/recursive-self-improvement
Ces deux événements simultanés sont révélateurs. D'un côté, Anthropic documente et met en garde contre la direction de cette trajectoire, de l'autre, des équipes comme Recursive font précisément, étape par étape, devenir cette trajectoire une réalité.
Bien sûr, Recursive reconnaît lui-même que ce n'est que la « première étape » : le système actuel fonctionne mieux dans des scénarios où les métriques sont claires, les retours rapides et la triche détectable. Il reste une distance considérable avant de pouvoir aborder de manière autonome des problèmes scientifiques ouverts. La prévention du "reward hacking" sera un défi central permanent sur la voie de la mise à l'échelle.
Mais une boucle a commencé à tourner. La question suivante est simplement : à quelle vitesse va-t-elle tourner ?
Cet article provient du compte WeChat officiel "机器之心" (ID : almosthuman2014), auteur : 递归进化中的机器之心, éditeur : Panda






