La loi de Moore est-elle sauvée ?
IBM dévoile le premier nœud de fabrication de puces au monde en 0,7 nanomètre, intégrant près de 100 milliards de transistors sur une puce de la taille d'un ongle, avec une densité double de celle des puces en 2 nm.
Auparavant, la technologie la plus avancée de TSMC était le 2 nm, progressant difficilement depuis plusieurs années.
Jensen Huang, PDG de Nvidia, a maintes fois affirmé que la loi de Moore était morte. Voilà enfin un tournant.

0,7 nanomètre, soit 7 angstroms. Pour la première fois, les transistors fabriqués par l'homme franchissent la barrière du 1 nm, s'approchant de l'échelle d'un atome individuel (0,1 à 0,5 nm).
Comparé au procédé en 2 nm, cela peut améliorer les performances de 50 %, ou l'efficacité énergétique de 70 %, selon le choix.
L'architecture NanoStack fait son entrée
Au cœur de cette percée se trouve l'architecture « NanoStack » d'IBM, la première conception de transistor 3D vertical empilé basée sur des nanofeuillets.
Pour comprendre NanoStack, il faut revenir sur l'évolution de l'architecture des puces ces dernières années.
À l'ère des 7 nm et 10 nm, la solution dominante était le transistor FinFET (à ailettes), où la grille enveloppe le canal sur trois côtés pour contrôler le courant. En deçà des 5 nm, les problèmes de fuite du FinFET sont devenus critiques, l'empêchant de tenir.
En 2017, IBM a introduit la technologie des nanofeuillets à grille entourante totale (GAA), où la grille enveloppe complètement les canaux constitués de nanofeuillets empilés horizontalement, améliorant grandement le contrôle électrostatique. Cela est devenu la base de ses puces en 2 nm, et a été adopté par les principaux fabricants comme TSMC et Samsung.
Fin 2021, IBM et Samsung ont conjointement présenté le transistor à effet de champ à transmission verticale (VTFET), changeant la direction du courant de l'horizontale à la verticale. Les simulations montraient un doublement des performances ou une réduction de 85 % de la consommation par rapport aux FinFET de même taille.
NanoStack est une extension de cette voie.
La méthode consiste à :
Prendre deux tranches de silicium comportant des transistors à nanofeuillets, retourner l'une et la superposer sur l'autre, puis les coller par liaison diélectrique ultra-mince, formant une structure 3D verticalement interconnectée. Chaque couche peut utiliser des combinaisons de matériaux différentes, les transistors de type n et de type p étant optimisés indépendamment, sans interférence.
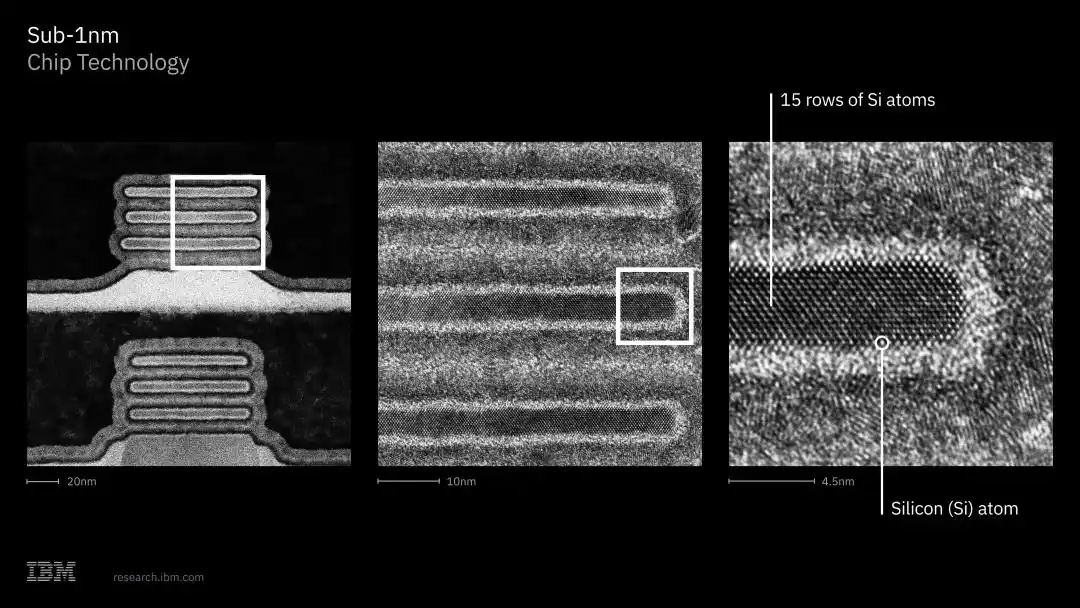
IBM a déjà validé cette technologie en laboratoire, démontrant l'intégration CMOS, les capacités d'ingénierie à double canal, ainsi qu'un inverseur CMOS fonctionnel avec des performances de commutation conformes aux attentes, confirmant que cette technologie peut être fabriquée et supporter des calculs réels.
Lors de la conférence VLSI 2026, IBM a en outre présenté les résultats de NanoStack sur la SRAM : une réduction de surface de 40 %. La SRAM est un composant clé de la mémoire cache sur puce, dont la miniaturisation est depuis longtemps très difficile. Cette avancée est cruciale pour les chemins de données à haute bande passante nécessaires aux puces d'IA.
« Personne ne veut payer la facture d'électricité »
Huiming Bu, vice-président chargé de la R&D des puces chez IBM Research, a déclaré : Tout le monde veut de meilleures performances, mais personne ne veut payer la facture d'électricité.
C'est la réalité à laquelle fait face la course actuelle à la puissance de calcul pour l'IA. La consommation énergétique des puces IA est passée d'un problème technique à un problème d'infrastructure, certains projets de centres de données connaissant des retards de construction faute d'accès à suffisamment d'électricité.
Le gain d'efficacité énergétique de 70 % offert par la technologie 0,7 nm répond directement à cette demande.
Cependant, IBM ne fabrique et ne vend plus de puces. Son centre de R&D à Albany, dans l'État de New York, développe des procédés de fabrication qu'il concède sous licence aux fabricants de puces.
Parmi les anciens licenciés figurent Samsung et la nouvelle société japonaise de semi-conducteurs Rapidus. Huiming Bu a refusé de révéler les clients potentiels de la technologie 0,7 nm.
Du côté de la concurrence, l'institut de recherche belge Imec développe une autre solution d'architecture 3D, construisant les transistors par empilement couche par couche, attirant l'attention de plusieurs fondeurs.
Concernant la production de masse, le calendrier d'IBM est le suivant : La technologie NanoStack pourrait entrer en production de masse d'ici 5 ans au plus tôt.
La feuille de route des semi-conducteurs d'IBM prévoit que, grâce à l'architecture NanoStack, la miniaturisation des puces pourra se poursuivre au moins dix ans de plus.

Liens de référence :
[1]https://newsroom.ibm.com/2026-06-25-ibm-debuts-worlds-first-sub-1-nanometer-chip-technology
Cet article provient du compte public WeChat « Quantum Bit », auteur : Meng Chen








