Los riesgos de que la IA escriba código se esconden en código aparentemente correcto, pudiendo provocar fugas de datos o pérdida de activos. El proyecto de código abierto Narwhal AI Code Risks ha recopilado casos reales, señales tempranas y rutas de riesgo típicas para ayudar a los desarrolladores a identificar peligros con antelación y evitar cometer los mismos errores.
En 2026, el código se genera a un ritmo cada vez mayor, pero se despliega con cada vez menos revisión.
Cada vez más, los requisitos del usuario se introducen en un cuadro de diálogo, la IA lee el contexto, completa funciones, añade dependencias, ajusta configuraciones y genera pruebas de paso.
Cuando te das cuenta, ya hay un fragmento de código en el repositorio, esperando a ser fusionado.
Los usuarios ya han adquirido el nuevo hábito: primero dejar que la IA lo escriba y lo haga funcionar, y si hay problemas, entonces ver qué hay que cambiar.
Pero en el mundo del software, lo más peligroso suele ser el código que parece anodino: sintácticamente correcto, con interfaces legales, pruebas aprobadas, comentarios perfectos.
Sin embargo, aún puede introducir nombres de paquetes que no existen, abrir permisos excesivos, exponer bases de datos... o incluso permitir que un agente que puede llamar directamente a herramientas del sistema, bajo un ataque de inyección de prompt, saque datos sensibles de un sistema interno.
Lo realmente peligroso no es que se encienda una luz de error, sino que todos los indicadores de riesgo muestren normalidad.
Hasta ahora, los riesgos de que la IA escriba código estaban dispersos por todas partes: un caso escondido en un blog de seguridad, una pista registrada en un Issue. Cuando el siguiente equipo se enfrentaba a un problema similar, tenía que reconstruir desde cero el origen del riesgo y dedicar una enorme cantidad de tiempo y esfuerzo a realizar mediciones empíricas a gran escala del código.
El Narwhal AI Code Risks, recientemente abierto por el Narwhal-Lab de la Universidad de Pekín, ya ha organizado estos fragmentos de información, clasificándolos en tres tipos: eventos reales, señales tempranas y rutas de riesgo típicas, para que los investigadores puedan consultarlos.

Enlace del paper: https://github.com/Narwhal-Lab/Narwhal-aicode-risks
Cuando pasan las 28 comprobaciones, el sistema aún se desvía
La primera pista fue un Pull Request ya fusionado, cuyo campo de autoría mostraba claramente a Claude Opus 4.6 y Copilot, junto con cuatro desarrolladores humanos. Las 28 comprobaciones se aprobaron: nadie detectó el problema.
Luego, un bot de liquidación tardó unos minutos en tomar una garantía valorada en 1,778,044.83 dólares.
El precio de cbETH en el archivo de configuración se estableció en la tasa de conversión con ETH, aproximadamente 1.12 dólares, en lugar de su precio real cercano a los 2,200 dólares.
Así, un error semántico de precio atravesó todo el proceso de desarrollo, revisión y fusión, convirtiéndose finalmente en una pérdida real en el sistema financiero. Este es el aspecto más llamativo del incidente de configuración del oráculo de Moonwell cbETH.
El problema radica en que el código no presentaba errores de sintaxis y los desarrolladores humanos no bloquearon de inmediato el flujo anómalo. Al contrario, parecía completo, fluido, era una entrega de ingeniería normal.
Pero precisamente esta aparente normalidad bajo la superficie lo convierte en un ejemplo típico de incidente de seguridad.
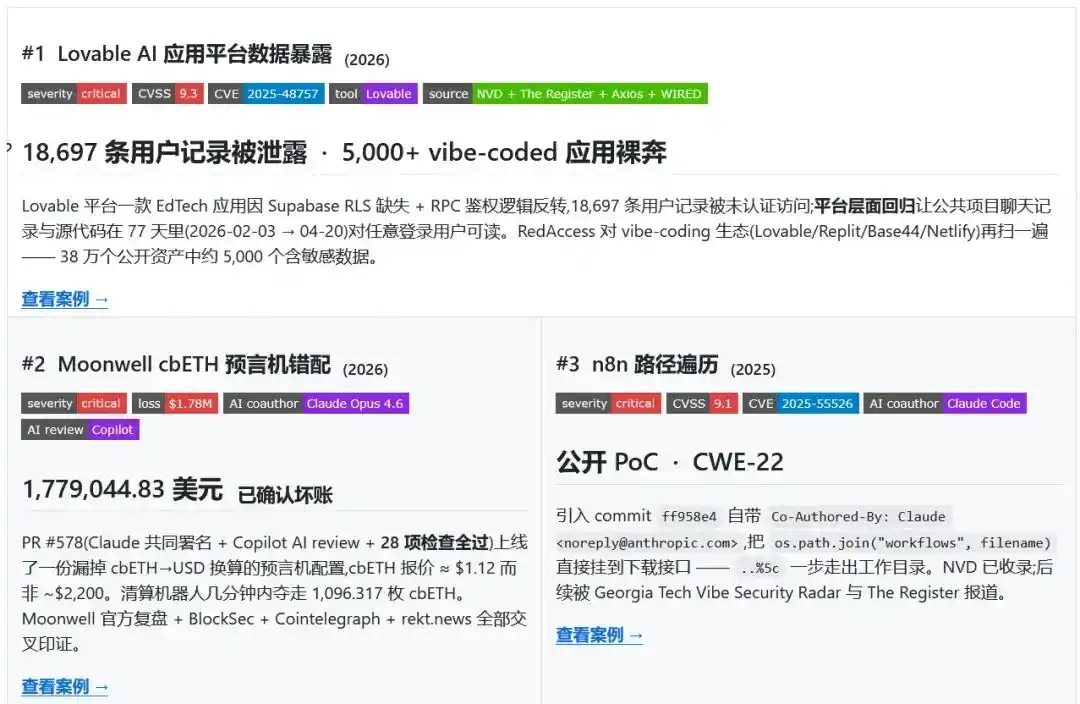
El riesgo de la codificación con IA radica en que no siempre se manifiesta como un error.
Muchas veces, se viste con la apariencia de una respuesta correcta y entra silenciosamente en el flujo de ingeniería. El código funciona, las comprobaciones pasan, el PR se fusiona, pero la semántica del negocio ya se ha desviado del mundo real.
En proyectos de bajo riesgo, esta desviación semántica puede ser solo una reelaboración; pero en escenarios sensibles como finanzas o sistemas de datos empresariales, provocará directamente filtraciones de datos, exposición de permisos y pérdida de activos.
Cuando la IA participa escribiendo código, modificando configuraciones, haciendo revisiones, o incluso firmando conjuntamente en los PR, ¿tenemos la suficiente certeza de saber cómo ocurre cada desviación?
Señales verdes de paso que no iluminan todos los rincones
Al principio, la IA que ayudaba a escribir código se limitaba principalmente a completar fragmentos locales. Si la sintaxis era incorrecta, el compilador mostraba un error, las pruebas unitarias fallaban y el flujo de CI lo rechazaba.
Hoy en día, la codificación con IA va mucho más allá, mientras que la supervisión tarda en llegar.
Puede leer archivos, modificar configuraciones, instalar dependencias, generar scripts de infraestructura, y también, a través de agentes, planificar de forma autónoma entre múltiples tareas.
La IA ya no se limita a estar al lado pasando herramientas; ha comenzado a integrarse en cadenas más largas de la ingeniería de software.
Los límites originalmente claros en la ingeniería de software han sido reconectados por los agentes de IA en rutas más largas y difíciles de rastrear.

Registros dispersos que necesitan un cuaderno de bitácora público
Los incidentes de seguridad rara vez tienen conclusiones completas desde el principio. Algunos tienen pruebas suficientes y pueden entrar en el directorio como casos reales; otros se quedan en capturas de pantalla de la comunidad, discusiones entre investigadores o divulgaciones preliminares, y solo son adecuados para seguir observándolos; otros más no están vinculados a un solo evento real, pero ya han formado un patrón claro, adecuado para realizar simulaciones preventivas.
Narwhal AI Code Risks divide el material en tres capas: `cases/`, `inferred/` y `scenarios/`.
cases/ registra eventos reales con fuentes públicas y una cadena de evidencias que los respalda; inferred/ guarda señales tempranas que aún no están completamente confirmadas, pero que merecen un seguimiento continuo; scenarios/ organiza escenarios típicos que no están vinculados a un solo evento, pero cuya ruta de riesgo es lo suficientemente clara.
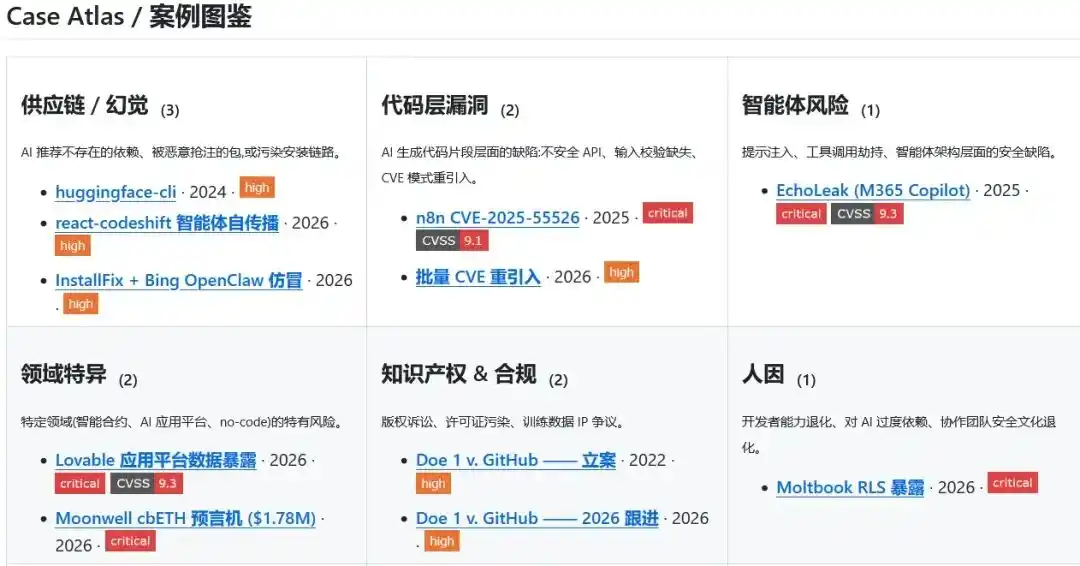
Sin un registro público como este, los riesgos de la codificación con IA pueden convertirse fácilmente en recuerdos a corto plazo en internet.
Hoy se recuerda un nombre de paquete, mañana se discute una exposición de datos, y en unos meses queda sepultado por la nueva ola de herramientas. Cuando surge un problema similar de nuevo, el equipo sigue entrando como una mosca ciega en zonas de navegación de riesgo desconocido.
Lo que hace Narwhal AI Code Risks es fijar estos fragmentos dispersos de riesgo, para que quienes vengan después puedan consultar la misma página.
Siguiendo siete tipos de índice, ver el camino del riesgo
Los problemas que trae la escritura de código por IA no están solo en el código. Están en las dependencias, en los permisos, en las llamadas a herramientas de los agentes, y aún más, en la forma en que los humanos confían en la salida de la IA.
Actualmente, Narwhal AI Code Risks divide los riesgos en 7 categorías: cadena de suministro (supply chain), vulnerabilidades a nivel de código, configuración de la nube e infraestructura, riesgos de agentes, riesgos de dominio vertical, riesgos de propiedad intelectual y cumplimiento normativo, y factores humanos.
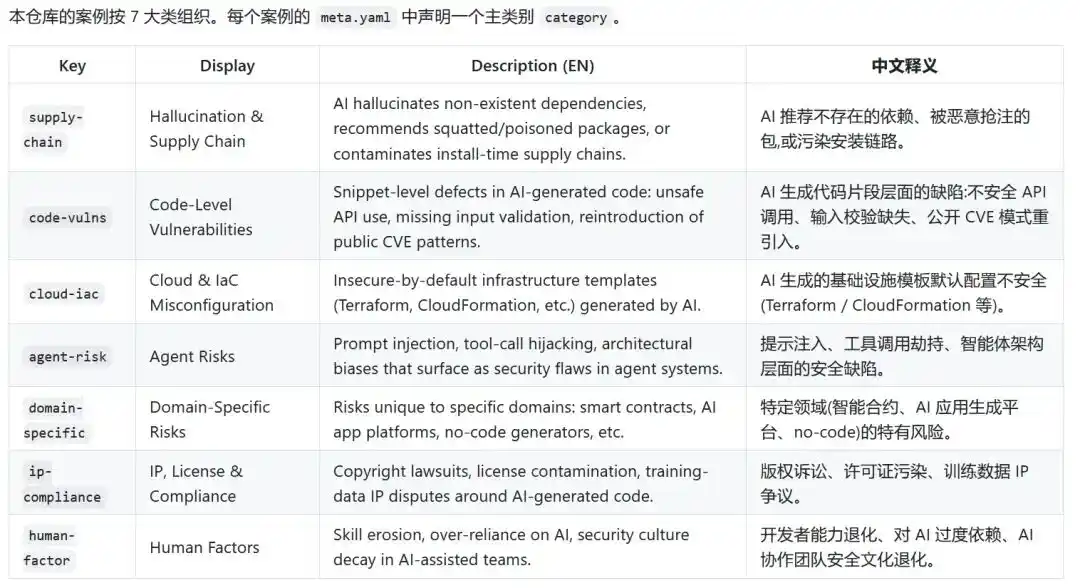
En los riesgos de cadena de suministro, la IA puede recomendar dependencias que no existen. En las vulnerabilidades a nivel de código, la IA puede volver a introducir en el código de negocio problemas como el recorrido de rutas (path traversal), la falta de validación de entradas o problemas de autorización. En la configuración de la nube y la infraestructura, la IA puede otorgar permisos excesivos, buckets de almacenamiento públicos o puertos expuestos con tal de hacer funcionar el código. Los riesgos de los agentes son aún más complejos, ya que no solo generan texto, sino que comienzan a ejecutar acciones. Los artefactos generados por la IA están sembrando peligros en sistemas reales.
El motor de la IA está encendido, y el cuaderno de bitácora acaba de abrirse
Cuando la IA avanza paso a paso hacia el mundo real, la prevención y gestión de sus riesgos asociados no debería limitarse a análisis posteriores a los hechos o a discusiones dispersas.
Lo realmente importante de Narwhal AI Code Risks es convertir los casos de riesgo en conocimiento reutilizable.
Los desarrolladores pueden usarlo para identificar problemas similares; los investigadores en seguridad pueden tomarlo como una biblioteca de muestras; los fabricantes de herramientas pueden extraer de él reglas de detección y puntos de referencia para evaluaciones; la comunidad de código abierto también puede seguir complementándolo con nuevos casos, nuevas evidencias y nuevos tipos de riesgo.
El motor de la IA está rugiendo, y cada desviación también debería dejar sus coordenadas. El riesgo nunca desaparece por ser ignorado, pero la experiencia puede ser registrada y transmitida. Lo verdaderamente valioso no es descubrir una vulnerabilidad, sino evitar que quienes vengan después tengan que caer en la misma trampa.
Lo que Narwhal AI Code Risks está haciendo es dejar un cuaderno de bitácora de código abierto para el mundo del software en el Año Uno de las Aplicaciones de IA.
Referencias:
https://github.com/Narwhal-Lab/Narwhal-aicode-risks
Este artículo procede del WeChat público "新智元" (New Zhi Yuan), autor: LRST








