Akhir 2024, sebuah makalah berjudul "Streaming Deep Reinforcement Learning Finally Works" (arXiv:2410.14606) memicu diskusi luas di kalangan akademik. Penulisnya dari tim Mahmood di University of Alberta, mereka menghabiskan banyak halaman menggambarkan kenyataan yang memalukan: Reinforcement Learning (RL) sebagai metode yang seharusnya 'belajar sambil berjalan', di era jaringan saraf dalam hampir tidak dapat melakukannya. Hanya dengan menghapus replay buffer, atau menetapkan ukuran batch menjadi 1, pelatihan akan gagal. Mereka menyebutnya sebagai "stream barrier" (penghalang streaming).
Makalah tersebut mengusulkan algoritma seri StreamX, yang mengandalkan pengaturan hyperparameter yang sangat halus, inisialisasi sparse, dan berbagai trik stabilisasi, baru bisa melampaui tembok ini.
Namun, kurang dari satu setengah tahun kemudian, seorang anggota dari kelompok penelitian yang sama, bersama dengan kolaborator dari Openmind Research, memberikan jawaban yang sangat berbeda: Akar dari stream barrier bukanlah "data tidak cukup", melainkan "satuan langkah yang salah".

Judul Makalah: Intentional Updates for Streaming Reinforcement Learning
Alamat Makalah: https://arxiv.org/pdf/2604.19033v1
Repositori Kode: https://github.com/sharifnassab/Intentional_RL
Menekan Gas, Seberapa Besar Lubang yang Terbuka
Bayangkan Anda sedang belajar parkir mobil. Pelatih memberi tahu Anda untuk "menginjak gas selama 0,1 detik" setiap kali. Masalahnya, meskipun menginjak 0,1 detik yang sama, di tanjakan, turunan, kosong, atau penuh, jarak mobil bergerak bisa sangat berbeda. Kadang kurang satu sentimeter tepat masuk, kadang kurang 30 sentimeter langsung menabrak.
Langkah pembelajaran gradien tradisional melakukan hal yang persis sama: ia menentukan seberapa besar parameter bergerak setiap kali, tetapi sama sekali tidak mengendalikan berapa banyak output fungsi yang sebenarnya berubah. Dalam pelatihan batch, rata-rata kesalahan dari ratusan hingga ribuan sampel mengencerkan kasus ekstrem, masalahnya tidak terlalu terlihat. Tetapi dalam lingkungan "streaming", setiap langkah hanya memiliki satu sampel, tidak ada rata-rata. Begitu arah gradien tidak stabil, magnitudo pembaruan akan besar-kecil secara tidak menentu — hari ini maju 30 cm, besok mundur 50 cm, proses pembelajaran runtuh dalam osilasi yang keras.
Fenomena "overshooting and undershooting" ini sangat parah dalam reinforcement learning, karena gradien pada setiap time step tidak hanya memiliki magnitudo yang berbeda, tetapi arahnya juga berubah dengan sangat cepat.
Mendefinisikan Ulang "Seberapa Banyak Satu Langkah Harus Dilakukan"
Arsalan Sharifnassab dari Openmind Research, bersama Mohamed Elsayed, A. Rupam Mahmood, dan Richard Sutton dari University of Alberta, dalam makalah yang baru diterbitkan mengusulkan solusi untuk berpikir dari sudut pandang lain: Daripada menentukan seberapa banyak parameter bergerak, lebih baik menentukan secara langsung seberapa banyak output fungsi yang harus berubah.
Ide ini tidak muncul begitu saja. Pada tahun 1967, ilmuwan Jepang Nagumo dan Noda dalam makalah "A learning method for system identification" telah mengusulkan algoritma "Normalized Least Mean Squares" (NLMS) dalam bidang adaptive filtering; pada dasarnya juga menggunakan perubahan output yang diharapkan untuk menghitung mundur langkah, bukan sebaliknya. Hanya saja algoritma itu hanya berlaku untuk skenario linear sederhana.
Para peneliti menggeneralisasi ide ini ke dalam deep reinforcement learning. Mereka menyebutnya sebagai "Intentional Updates" (Pembaruan Intensional): Sebelum setiap pembaruan, tentukan dulu "apa yang ingin saya capai dengan langkah ini", kemudian hitung mundur langkah yang seharusnya digunakan.
Untuk pembelajaran nilai (yaitu memprediksi reward masa depan), mereka mendefinisikan intensi sebagai: Setelah setiap pembaruan, kesalahan prediksi nilai state saat ini harus menyusut dengan proporsi tetap — misalnya menyusut 5%, tidak lebih dan tidak kurang. Untuk pembelajaran kebijakan (yaitu mengoptimalkan keputusan tindakan), mereka mendefinisikan intensi sebagai: Probabilitas pemilihan tindakan saat ini hanya diperbolehkan berubah dengan jumlah yang "moderat" setiap langkah.
Dengan analogi mengemudi: Ini seperti pengemudi memutuskan sebelum setiap operasi "Saya ingin mobil bergerak maju 20 cm", kemudian secara otomatis menghitung seberapa dalam gas harus diinjak berdasarkan kondisi jalan saat ini (kemiringan, muatan), daripada menginjak kedalaman yang sama setiap kali dan menyerahkannya pada nasib.
Penerima Turing Award dan Teka-tekinya
Salah satu penandatangan makalah adalah Richard S. Sutton — penerima Turing Award 2024, yang secara luas disebut sebagai "Bapak Reinforcement Learning Modern".
Posisi Sutton di dunia akademis kira-kira setara dengan Feynman dalam fisika: Dia tidak hanya mengusulkan pembelajaran selisih waktu (TD learning) dan gradien kebijakan (policy gradient), dua kerangka dasar RL modern, tetapi juga bersama Andrew Barto menulis buku teks paling otoritatif di bidang ini, "Reinforcement Learning: An Introduction" (sekarang edisi kedua, dapat dibaca online gratis). Dia dan Barto berbagi Turing Award 2024, dengan kata-kata penghargaan "untuk meletakkan dasar konseptual dan algoritmik bagi reinforcement learning".
Setelah mendapat penghargaan, Sutton tidak memilih pensiun, tetapi menginvestasikan hadiahnya untuk mendirikan Openmind Research, khusus mendanai para peneliti muda yang bersedia "mengeksplorasi masalah mendasar dalam lingkungan tanpa tekanan komersialisasi". Makalah baru ini lahir dari lembaga nirlaba ini.
Dan penulis pertama Sharifnassab, sebelumnya baru saja menerbitkan kerangka MetaOptimize di ICML 2025, mempelajari cara menyesuaikan learning rate secara online dan otomatis. Fokus kedua topik ini sangat konsisten: bagaimana membuat langkah itu sendiri menjadi lebih cerdas.
Detail Algoritma: Lebih Sederhana dari yang Dibayangkan
Penurunan matematis dari "intentional updates" tidak rumit, rumus intinya dapat digambarkan dalam satu kalimat: Langkah sama dengan "jumlah perubahan output yang diharapkan" dibagi dengan "pengaruh aktual arah gradien terhadap output".
Dalam pembelajaran nilai, "pengaruh aktual" ini adalah norma vektor gradien (setara dengan mengukur seberapa "curam" area parameter saat ini): semakin curam, semakin kecil langkahnya; semakin datar, semakin besar langkahnya, sehingga memastikan dampak setiap pembaruan terhadap fungsi nilai tetap konsisten.
Dalam pembelajaran kebijakan, "jumlah perubahan yang diharapkan" didefinisikan sebanding dengan fungsi keunggulan (advantage function): seberapa baik tindakan saat ini dibandingkan rata-rata, kebijakan bergerak ke arah itu sebanyak itu — dinormalisasi besarnya dengan running average, memastikan bahwa dalam jangka panjang, besarnya perubahan kebijakan stabil dalam rentang yang dapat dijelaskan.
Para peneliti juga menggabungkan ide inti ini dengan dua praktik rekayasa: penskalaan diagonal gaya RMSProp (menangani perbedaan skala dimensi parameter yang berbeda) dan eligibility traces (membantu sinyal reward menyebar ke time step sebelumnya).
Akhirnya membentuk tiga algoritma lengkap: Intentional TD (λ) untuk prediksi nilai, Intentional Q (λ) untuk kontrol tindakan diskrit, dan Intentional Policy Gradient untuk kontrol kontinu.



Hasil Eksperimen: Bisa Menyamai SAC Tanpa GPU
Makalah ini mengevaluasi metode ini di beberapa benchmark standar, dan hasilnya sangat mengesankan.
Pada tugas kontrol kontinu MuJoCo (termasuk robot simulasi kompleks seperti Ant, Humanoid, HalfCheetah), metode baru Intentional AC dalam pengaturan streaming (ukuran batch = 1, tanpa replay buffer) kinerja akhirnya berulang kali mendekati bahkan menyaingi SAC — sebuah algoritma yang menggunakan replay buffer batch besar, hampir menjadi standar emas untuk tugas kontrol kontinu saat ini. Dalam hal komputasi, operasi floating point yang dibutuhkan untuk setiap pembaruan Intentional AC hanya sekitar 1/140 dari satu pembaruan SAC.
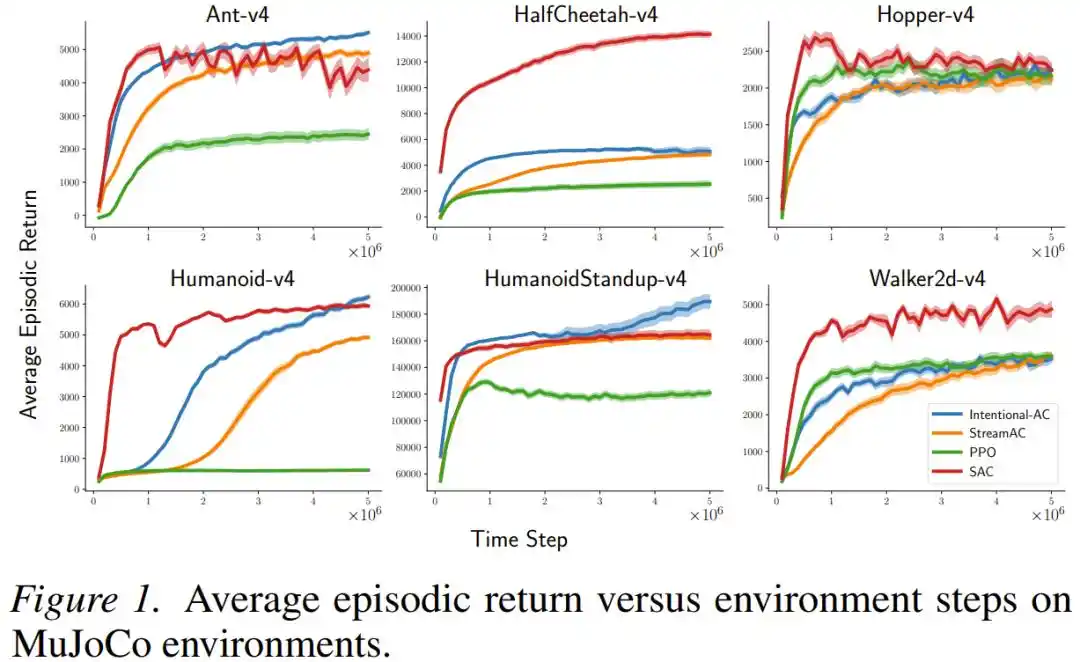
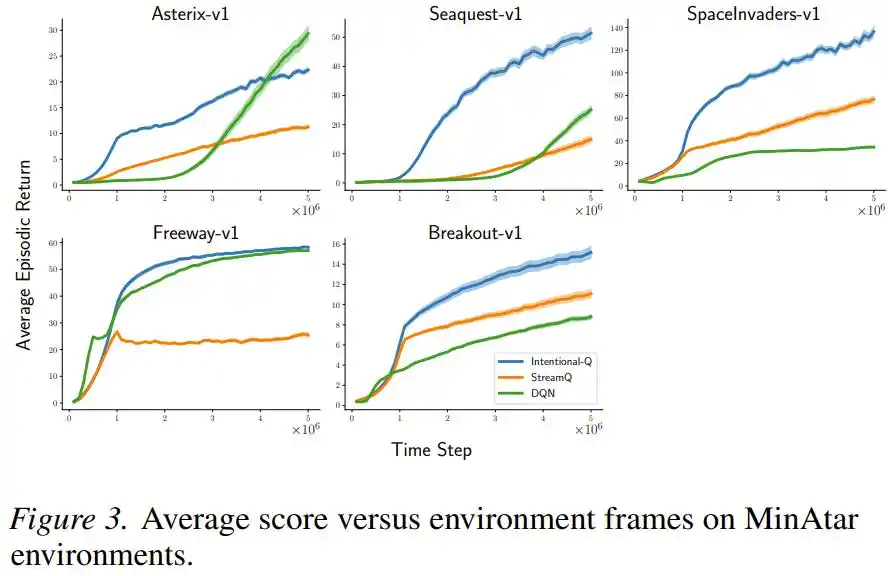
Pada permainan dengan tindakan diskrit Atari dan MinAtar, kinerja Intentional Q-learning juga setara dengan DQN yang menggunakan replay buffer, dan berhasil menjalankan semua tugas dengan setelan hyperparameter yang sama, tanpa perlu penyesuaian satu per satu.
Para peneliti juga secara khusus memverifikasi apakah "intensi" benar-benar tercapai: Mereka mengukur rasio jumlah pembaruan aktual dengan jumlah yang diharapkan. Dalam pengaturan sederhana dengan traces tidak diaktifkan, deviasi standar rasio ini hanya 0,016 hingga 0,029, persentil ke-99 berada dalam 1,07; artinya dalam sebagian besar kasus, pembaruan memang melakukan "apa yang dikatakan akan dilakukan".
Selain itu, satu set eksperimen ablasi menunjukkan bahwa menghilangkan normalisasi RMSProp atau istilah σ menyebabkan penurunan kinerja tetapi masih kompetitif, dan "penskalaan intensi" ini sendiri adalah kontributor utama, komponen lainnya hanyalah penunjang.
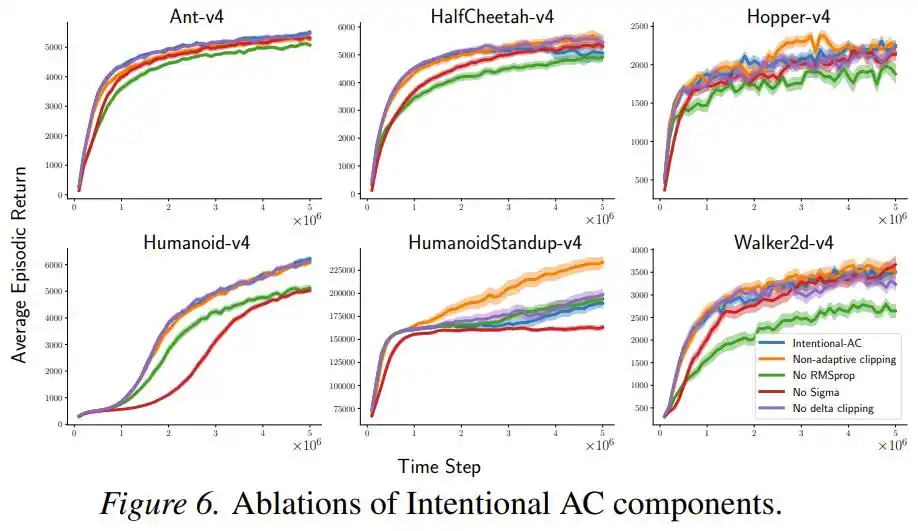
Masih Ada Masalah
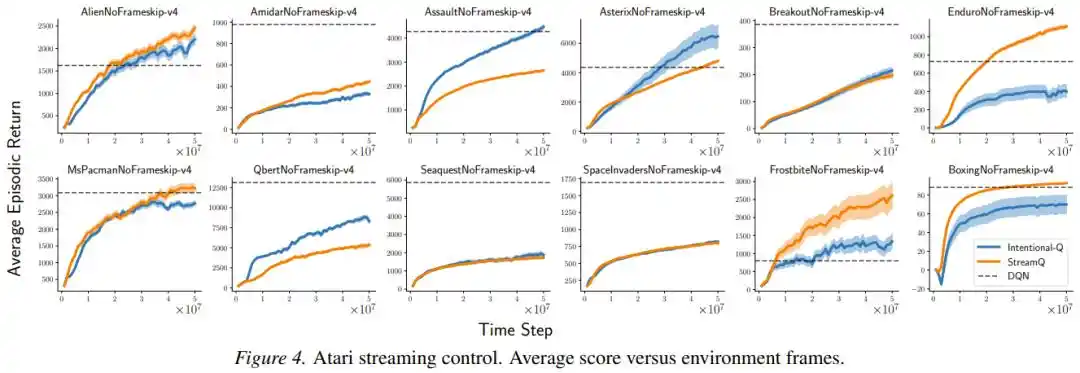
Kerangka "intentional updates" juga menunjukkan keunggulan yang jelas dalam hal ketangguhan. Ketika para peneliti satu per satu menghilangkan berbagai trik stabilisasi tambahan yang menjadi sandaran metode StreamX (inisialisasi sparse, penskalaan reward, normalisasi input, LayerNorm), degradasi kinerja Intentional AC jelas lebih sedikit daripada StreamAC asli, menunjukkan bahwa penskalaan intensi mengurangi ketergantungan pada "tongkat penyangga" eksternal dari akarnya.
Namun, makalah ini juga secara jujur mengakui masalah yang belum sepenuhnya terpecahkan: Dalam pembelajaran kebijakan, langkah bergantung pada tindakan yang di-sampel saat ini, yang secara implisit memberikan "bobot" yang berbeda pada tindakan yang berbeda, mungkin mengubah arah yang diharapkan dari gradien kebijakan. Dalam tugas Humanoid dan HumanoidStandup, dengan mengukur kesamaan kosinus arah pembaruan yang diharapkan, para peneliti menemukan bias ini mendekati 0,96 pada fase pembelajaran kritis (hampir tidak berpengaruh); tetapi di Ant-v4, keselarasan turun ke median 0,63, menunjukkan bahwa masalah tidak selalu bisa diabaikan.
Penulis menunjukkan bahwa penelitian di masa depan harus mencari strategi pemilihan langkah yang tidak bergantung pada tindakan, sehingga "intensi" juga tetap tidak bias dalam arti harapan. Ini adalah pekerjaan rumah yang jelas bagi para peneliti berikutnya dalam arah ini.
Kesimpulan: Membuat AI Belajar Sambil Bertindak Seperti Manusia
Paradigma pelatihan model besar saat ini bergantung pada pencernaan batch data dalam jumlah besar: memasukkan semua teks dan kode dari internet, mengulanginya berulang kali, akhirnya memunculkan kemampuan yang menakjubkan. Rute ini telah terbukti efektif, tetapi pada dasarnya adalah "belajar dulu baru digunakan": setelah pelatihan selesai, model dibekukan, tidak dapat terus diperbarui dari setiap interaksi aktual berikutnya.
Apa yang dikejar oleh pembelajaran penguatan streaming adalah mode pembelajaran yang sangat berbeda: tidak bergantung pada replay massal, tidak bergantung pada kluster GPU besar, setiap langkah pengalaman segera diubah menjadi pembaruan parameter, berkelanjutan, murah, dan adaptif. Ini lebih mendekati cara belajar manusia dan hewan yang sebenarnya.
Dari terobosan awal Elsayed dkk. pada 2024 yang "akhirnya berhasil", hingga prinsip "intentional updates" yang diusulkan dalam makalah ini, pembelajaran penguatan dalam streaming sedang menuju kematangan dengan kecepatan yang mengejutkan. Ia tidak akan menggantikan model besar yang dilatih secara batch, tetapi untuk robot yang membutuhkan adaptasi online jangka panjang, perangkat edge, dan skenario aplikasi apa pun yang tidak mampu menanggung buffer replay dan kluster GPU skala besar, jalur ini semakin meyakinkan.
Langkah bukan hanya hyperparameter, itu adalah janji AI tentang "berapa banyak yang ingin dilakukan" setiap langkah. Ketika janji ini akhirnya dapat dikendalikan, pembelajaran itu sendiri menjadi stabil.
Artikel ini berasal dari akun WeChat "机器之心" (ID: almosthuman2014), penulis: 关注RL的





