Dalam beberapa tahun terakhir, Model Mixed Expert (MoE) telah banyak digunakan untuk model besar di cloud. Namun, di sisi perangkat seluler, Model Bahasa Besar (LLM) masih didominasi oleh arsitektur padat (dense). Dulu, kendala perangkat seluler terhadap memori, daya komputasi, dan latensi lebih ketat, sehingga penelitian sistematis tentang MoE sisi perangkat dengan parameter aktif dalam kisaran sub-miliar masih kurang. Kini, dengan peningkatan kapasitas DRAM perangkat seluler, MoE juga mulai berpeluang untuk di-deploy ke smartphone.
MobileMoE yang diusulkan oleh tim Meta, untuk pertama kalinya mewujudkan inferensi MoE yang efisien pada smartphone komersial. Hasilnya menunjukkan, dalam 14 tes dasar, MobileMoE-S/M dengan memori yang sebanding, hanya menggunakan 1/2 hingga 1/4 dari beban komputasi inferensi baseline padat, mampu mencapai akurasi rata-rata yang setara atau bahkan lebih tinggi. Dalam pengujian nyata, MobileMoE-S menunjukkan percepatan paling signifikan di backend GPU/MLX iPhone 16 Pro, pada fase input dapat dipercepat hingga 3,8 kali lipat.

Tautan makalah: https://arxiv.org/abs/2605.27358
Tim peneliti juga mengusulkan seperangkat aturan penskalaan MoE sisi perangkat, yang digunakan untuk menentukan struktur model yang lebih cocok untuk deployment di ponsel. MobileMoE membangun frontier Pareto baru untuk model bahasa besar sisi perangkat, mencapai hasil yang lebih optimal dalam trade-off antara akurasi dan biaya komputasi inferensi.
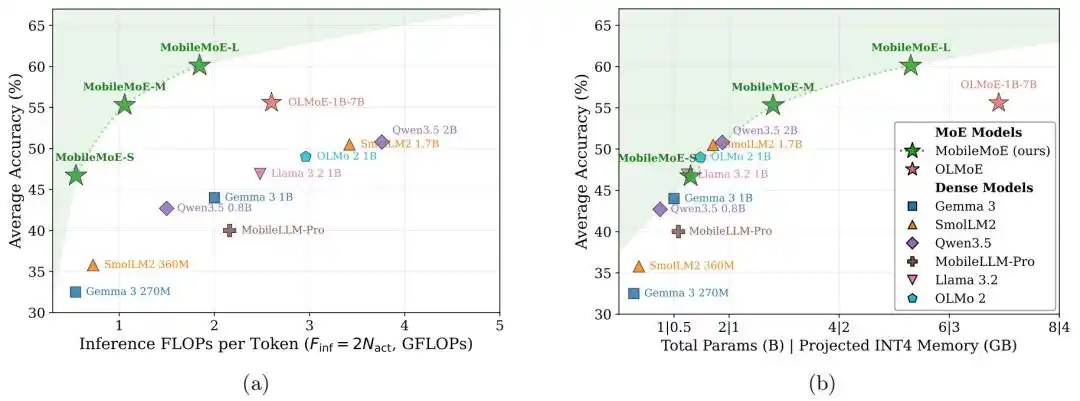
Gambar|MobileMoE membangun frontier Pareto baru untuk model bahasa besar sisi perangkat.
Bagaimana MobileMoE Dirancang?
MobileMoE dapat dipahami seperti ini: ini adalah kelas model bahasa MoE yang dirancang untuk deployment sisi perangkat. Secara keseluruhan tetap Transformer decoder-only, tetapi lapisan feed-forward padat asli diganti dengan lapisan MoE. Router akan memilih sedikit pakar (expert) dengan skor tertinggi untuk setiap token untuk berpartisipasi dalam komputasi, dan ada juga satu pakar bersama (shared expert) yang selalu berpartisipasi. Seluruh alur pelatihan dibagi menjadi empat langkah: pra-pelatihan, pelatihan menengah, fine-tuning terawasi (SFT), dan pelatihan sadar kuantisasi.
Pra-pelatihan: Tim peneliti melakukan pra-pelatihan dengan panjang konteks 2048 token, menggunakan data berlisensi terbuka sekitar 6T token, data secara keseluruhan didominasi Web, sambil mencakup bidang matematika, kode, pengetahuan, dan sains.
Pelatihan menengah: Tim peneliti memperluas panjang konteks menjadi 8192, dan lebih meningkatkan proporsi data berkualitas tinggi seperti pengetahuan, kode, matematika, dan sains, dengan total skala sekitar 500B token.
Fine-tuning Terawasi (SFT): Tim peneliti melakukan fine-tuning pada MobileMoE-Base menggunakan data instruksi fine-tuning berlisensi terbuka dengan lebih dari 80 juta sampel.
Pelatihan Sadar Kuantisasi: Tim peneliti mengkuantisasi lapisan linear dan embedding ke INT4, mengkuantisasi aktivasi dinamis ke INT8, sementara router tetap menjaga presisi FP32.

Gambar|Empat tahap pelatihan MobileMoE.
Hasil Eksperimen
Hasil Eksperimen Ablasi
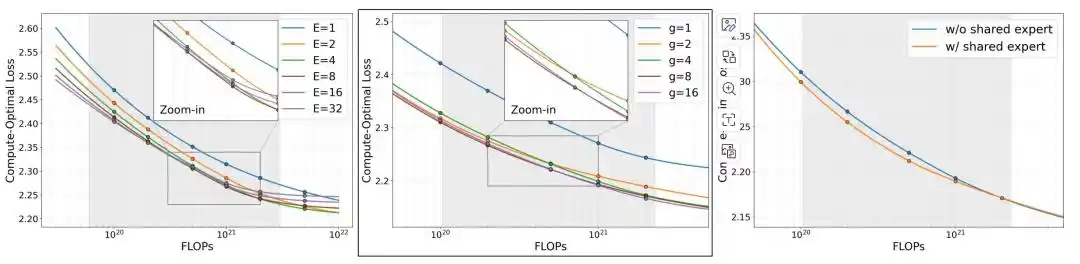
Tim peneliti pertama membandingkan tiga variabel arsitektur: jumlah pakar E, granularitas pakar g, serta apakah menambahkan pakar bersama.

Gambar|Penskalaan jumlah pakar E.
Dalam anggaran memori tetap, ketika memori di atas sekitar 0,25GB, loss MoE mulai lebih rendah daripada model padat yang sesuai. Melanjutkan peningkatan jumlah pakar E, loss akan turun lebih jauh, tetapi ketika E bertambah menjadi 8, keuntungan marjinal sudah melemah nyata. Eksperimen pada granularitas pakar g menunjukkan, konfigurasi pakar yang lebih halus secara keseluruhan lebih baik, dengan g=8 mencapai keseimbangan yang baik antara efektivitas dan biaya pelatihan; ketika g bertambah dari 8 ke 16, perbaikan loss kurang dari 0,01, tetapi durasi pelatihan meningkat sekitar 50%. Dalam anggaran komputasi yang sama, dengan menambahkan pakar bersama, loss model turun lebih jauh.
Berdasarkan hasil eksperimen ablasi, tim peneliti akhirnya mengadopsi konfigurasi E=8, g=8, dengan pakar bersama, yaitu 60 pakar rute granular halus, rute Top-4, dan 1 pakar bersama, dan menggunakan struktur ini untuk tiga versi MobileMoE-S/M/L.
Gambar|Melakukan penskalaan pada model MoE dalam kondisi komputasi optimal.
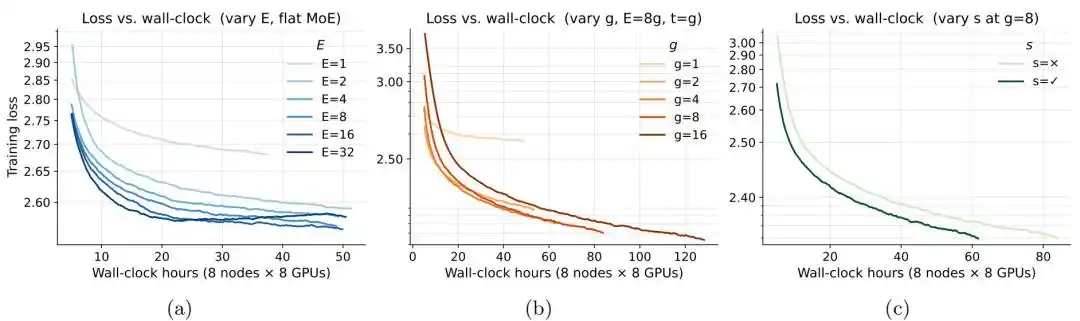
Gambar|Efisiensi pelatihan arsitektur MoE.
14 Evaluasi Dasar: Membangun Frontier Pareto Baru Sisi Perangkat
Tim peneliti dalam lima kategori evaluasi dasar yaitu penalaran common sense, pengetahuan, sains, membaca, dan penalaran yang total 14 item, mengevaluasi kembali MobileMoE bersama model seperti Gemma 3, SmolLM2, Qwen3.5, OLMo 2, OLMoE-1B-7B dalam pengaturan yang seragam.
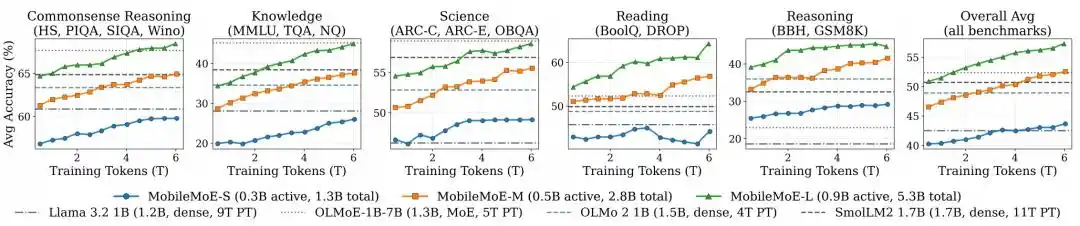
Gambar|Jejak pra-pelatihan MobileMoE.
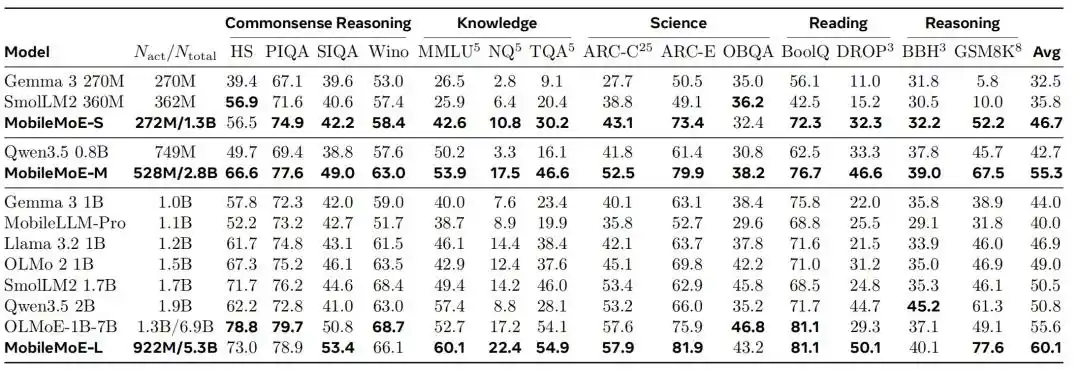
Hasil perbandingan model Base menunjukkan, rata-rata skor MobileMoE-M lebih tinggi daripada Qwen3.5 2B, rata-rata skor MobileMoE-L lebih tinggi daripada OLMoE-1B-7B, dengan ukuran model yang dibutuhkan juga lebih kecil; tim peneliti juga menyebutkan, versi Base MobileMoE-L rata-rata skornya sudah lebih tinggi daripada versi Instruct OLMoE-1B-7B. Dalam skala pelatihan, MobileMoE menggunakan sekitar 6T token pra-pelatihan, lebih sedikit daripada 9T token Llama 3.2 1B dan 11T token SmolLM2 1.7B. Dalam perbandingan keseluruhan model hasil instruksi fine-tuning, rata-rata akurasi MobileMoE-M sudah mendekati OLMoE-1B-7B, tetapi parameter aktif dan total parameter lebih sedikit sekitar 60%.

Gambar|Perbandingan model MobileMoE-Base.
Evaluasi Lanjutan: Keunggulan Lebih Menonjol dalam Tugas Kode dan Matematika
Dalam evaluasi lanjutan setelah instruksi fine-tuning, MobileMoE menunjukkan performa lebih menonjol pada tugas kode dan matematika. Misalnya MobileMoE-L, rata-rata skornya pada kedua kategori evaluasi kode dan matematika lebih tinggi daripada Qwen3.5 2B dan OLMoE- 1B-7B. Namun, tim peneliti juga menyebutkan, pada dua kemampuan instruksi following dan penalaran pengetahuan, Qwen3.5 2B masih lebih kuat.
Gambar|Perbandingan model Instruct pada benchmark lanjutan.
Kuantisasi dan Deployment Sisi Perangkat: Tetap Kompetitif Setelah INT4, Percepatan Nyata di Sisi Ponsel
Setelah kuantisasi, rata-rata skor keseluruhan MobileMoE-S/M/L menurun dibandingkan versi BF16 masing-masing, tetapi penurunannya berkisar antara 2 hingga 3 poin. Meski begitu, performa versi INT4 MobileMoE-L masih lebih tinggi daripada versi BF16 OLMoE-1B-7B Instruct.
Tim peneliti juga mendeploy MobileMoE ke Samsung Galaxy S25 dan iPhone 16 Pro untuk pengujian. Hasil menunjukkan, dalam kondisi memori bobot INT4 yang sebanding, MobileMoE-S dibandingkan MobileLLM-Pro, pada fase input dipercepat 1,8-3,8 kali lipat, pada fase generasi token demi token dipercepat 2,2-3,4 kali lipat.
Dalam hal penggunaan memori, pada Samsung Galaxy S25, konteks 8K, dan kondisi prompt nyata, RSS puncak MobileMoE-S adalah 1,49GB, lebih rendah daripada 1,91GB MobileLLM-Pro.

Gambar|Latensi runtime sisi perangkat.
Kekurangan dan Arah Masa Depan
Saat ini, pada kemampuan instruksi following yang lebih tinggi serta kemampuan pengetahuan dan penalaran, MobileMoE yang telah difine-tuning instruksi masih tertinggal dari Qwen3.5 2B. Tim peneliti berpendapat, kesenjangan ini mungkin terkait dengan pelatihan pasca (post-training) yang lebih matang. Di masa depan, untuk mengecilkan kesenjangan ini, sisi pelatihan perlu memperkuat distilasi, post-training yang berorientasi pada penalaran, serta ekspansi multimodal.
Selain itu, tim peneliti mencatat, penggunaan memori MoE di ponsel akan berubah seiring dengan konten input. Dibandingkan dengan input templat tetap, input nyata biasanya membawa penggunaan memori yang lebih tinggi. Jika pengujian hanya didasarkan pada input ter-templat, mungkin akan meremehkan tekanan memori dalam skenario deployment nyata. Di masa depan, untuk mengevaluasi lebih akurat performa memori nyata MoE sisi perangkat, masih diperlukan lebih banyak data pengukuran nyata berdasarkan pengujian nyata.
Di saat yang sama, tim peneliti telah menyelesaikan pengujian sistematis perangkat nyata di backend CPU dan GPU, tetapi jalur NPU masih perlu dieksplorasi. Sementara itu, penggunaan memori runtime MoE cukup sensitif terhadap konten input. Di masa depan, routing dinamis, pemangkasan pakar (expert pruning), kuantisasi presisi campuran, serta deployment NPU sisi perangkat seluler, semuanya adalah arah untuk terus meningkatkan efisiensi sisi perangkat.
Detail teknis lebih lanjut, lihat makalah asli.
Artikel ini berasal dari akun WeChat publik "Academic Headlines" (ID: SciTouTiao), penulis: Xia Qiansi





