
Google Research baru-baru ini menerbitkan sebuah makalah, poin utamanya dapat disimpulkan dalam satu kalimat: Daripada bersikeras "membuat AI serba tahu dan serba bisa", lebih baik ajari dia mengatakan "Saya tidak yakin".
Makalah yang berjudul "Hallucinations Undermine Trust; Metacognition is a Way Forward" ini diselesaikan bersama oleh Google Research dan Universitas Tel Aviv, dan telah diterima oleh ICML 2026 Position Track. Makalah ini mengemukakan bahwa tren utama industri AI dalam melawan "halusinasi" saat ini mungkin pada dasarnya salah arah—semua orang sibuk memberi model lebih banyak pengetahuan, tetapi mengabaikan kemampuan yang lebih krusial dan kurang dihargai: membuat AI merasakan dan mengungkapkan tingkat keyakinannya terhadap setiap jawaban.
(Alamat makalah: [2605.01428] Hallucinations Undermine Trust; Metacognition is a Way Forward)
Pajak Kegunaan: Biaya Nyata Memberantas Halusinasi
Mari mulai dari situasi yang dihadapi semua orang.
Anda menanyakan sebuah pertanyaan kepada asisten AI, dia menjawab dengan nada yang sangat yakin, pilihan kata ketat, logis lengkap, tampaknya tak bercela. Setelahnya Anda periksa, jawaban itu sepenuhnya ngawur. Yang lebih menyebalkan, dia mengatakannya tanpa ragu sedikit pun, seolah-olah menyaksikan sendiri.
Inilah "halusinasi" AI—model menghasilkan konten dengan kesalahan faktual, namun menyajikannya kepada pengguna dengan cara yang tak terbantahkan. Masalah ini sangat mematikan dalam skenario berisiko tinggi seperti medis, hukum, penelitian ilmiah.
Cara industri menangani halusinasi pada dasarnya ada dua jalur. Jalur pertama: Membuat AI tahu lebih banyak, dengan memperluas data pelatihan, menambah parameter model untuk mencakup lebih banyak fakta. Jalur kedua: Membuat AI diam ketika tidak yakin, saat menghadapi pertanyaan yang tidak pasti langsung menolak menjawab.
Kedua jalur memiliki kelemahan jelas. Fakta di dunia tak terbatas, model tidak mungkin mengingat semua hal, jadi jalur pertama selalu memiliki celah yang tidak tercakup. Masalah jalur kedua adalah, begitu AI mulai menolak menjawab dalam skala besar, dia berubah dari "asisten berguna" menjadi "barang tak berguna yang tidak berani berkata apa-apa"—pengguna menanyakan sepuluh pertanyaan, delapan ditolak, pengalaman sangat buruk.
Makalah memberi biaya jalur kedua nama yang tepat: "Pajak Kegunaan" (utility tax)—untuk menurunkan tingkat halusinasi, Anda harus mengorbankan banyak informasi yang sebenarnya dapat dijawab dengan benar.
Mengapa pajak ini begitu berat? Akarnya terletak pada AI yang kekurangan satu kemampuan kunci. Agar strategi "menolak menjawab" bekerja tepat sasaran, model perlu membedakan secara akurat antara "pertanyaan ini saya jawab benar" dan "pertanyaan ini saya jawab salah"—hanya menolak yang salah, mempertahankan yang benar. Namun kenyataannya, model tidak bisa melakukan pembedaan akurat ini. Makalah membedakan dua konsep yang mudah membingungkan tetapi maknanya sangat berbeda untuk menjelaskan masalah ini.
Kalibrasi (calibration) mengukur apakah tingkat kepercayaan diri AI secara keseluruhan sesuai dengan tingkat akurasi keseluruhannya. Contoh, AI menjawab 100 pertanyaan, setiap kali berkata "Saya 60% yakin", dan dari 100 pertanyaan itu tepat 60 yang benar, ini adalah kalibrasi sempurna.
Diskriminasi (discrimination) mengukur apakah AI dapat membedakan secara akurat pada setiap pertanyaan spesifik antara "saya benar" dan "saya salah". Sebuah AI memberi kepercayaan 60% untuk semua masalah, tingkat akurasi keseluruhan tepat 60%, kalibrasi nyaris sempurna, tetapi daya diskriminasi nol—dia sama sekali tidak bisa membedakan mana yang harus dipercaya, mana yang harus diwaspadai. Kalibrasi baik tidak sama dengan daya diskriminasi kuat, inilah inti masalahnya.
Makalah menyusun banyak literatur dan menemukan bahwa model besar utama saat ini pada tugas tanya jawab pengetahuan nyata memiliki metrik daya diskriminasi AUROC terkonsentrasi antara 0,70 hingga 0,85. Angka ini terdengar lumayan, tetapi sebenarnya jauh dari cukup. Makalah melakukan simulasi dengan parameter AUROC=0,71, hasilnya mengejutkan: asumsikan tingkat kesalahan dasar AI 25%, untuk menekan tingkat kesalahan menjadi 5%, AI harus menolak menjawab lebih dari 52% pertanyaan yang benar. Bahkan jika daya diskriminasi ditingkatkan ke level 0,85 yang mendekati batas atas literatur, tetap harus mengorbankan 28% jawaban benar. Hanya ketika daya diskriminasi mencapai di atas 0,95, biayanya dapat diabaikan—dan saat ini tidak ada metode yang mendekati angka ini pada tugas intensif pengetahuan.
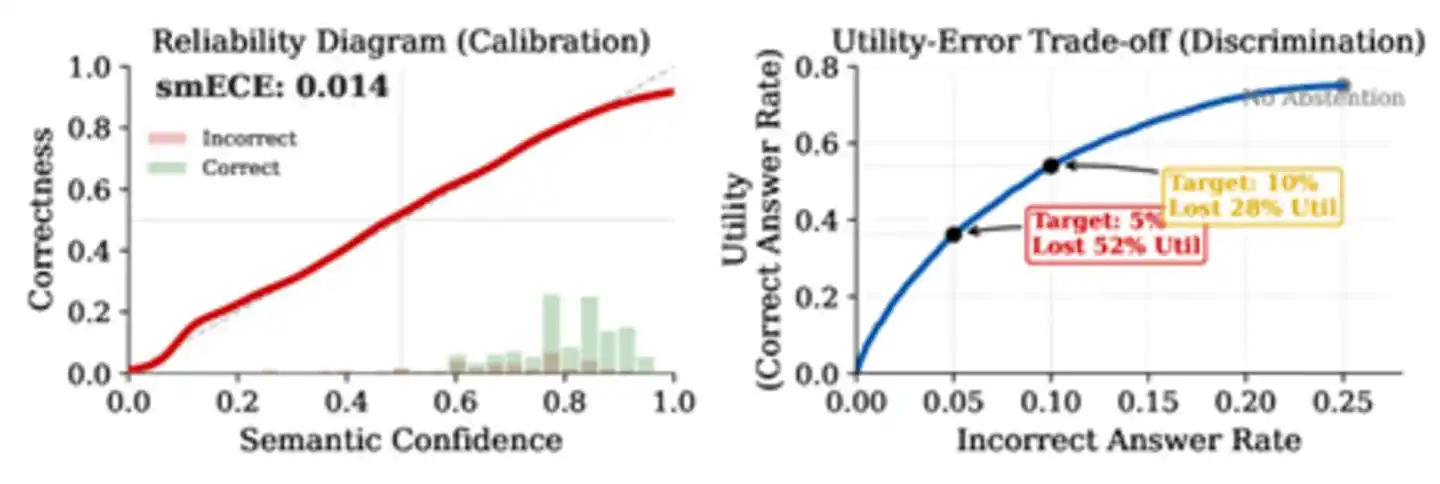
Gambar: Perbedaan kalibrasi dan diskriminasi. Grafik kiri menunjukkan model terkalibrasi baik (garis merah mendekati garis diagonal), grafik kanan mengungkapkan realitas kejam—bahkan dengan kalibrasi sempurna, untuk menekan tingkat kesalahan dari 25% menjadi 5%, harus mengorbankan 52% jawaban benar.
Data nyata mengonfirmasi penilaian ini. Makalah menganalisis kinerja berbagai model terdepan pada pengujian patokan SimpleQA Verified, hasilnya jelas agak kejam: sebagian besar model terdistribusi sepanjang garis diagonal "semakin banyak dijawab, semakin banyak salah", beberapa model yang mengejar akurasi tinggi melalui banyak penolakan jawaban menukar akurasi per soal lebih tinggi, tetapi membayar harga kegunaan yang sangat besar. Area ideal "sudut kanan atas"—menjawab banyak dan sedikit salah—saat ini kosong tak berpenghuni. Kekosongan ini tepatnya adalah "Kesenjangan Diskriminasi" yang disebutkan makalah.
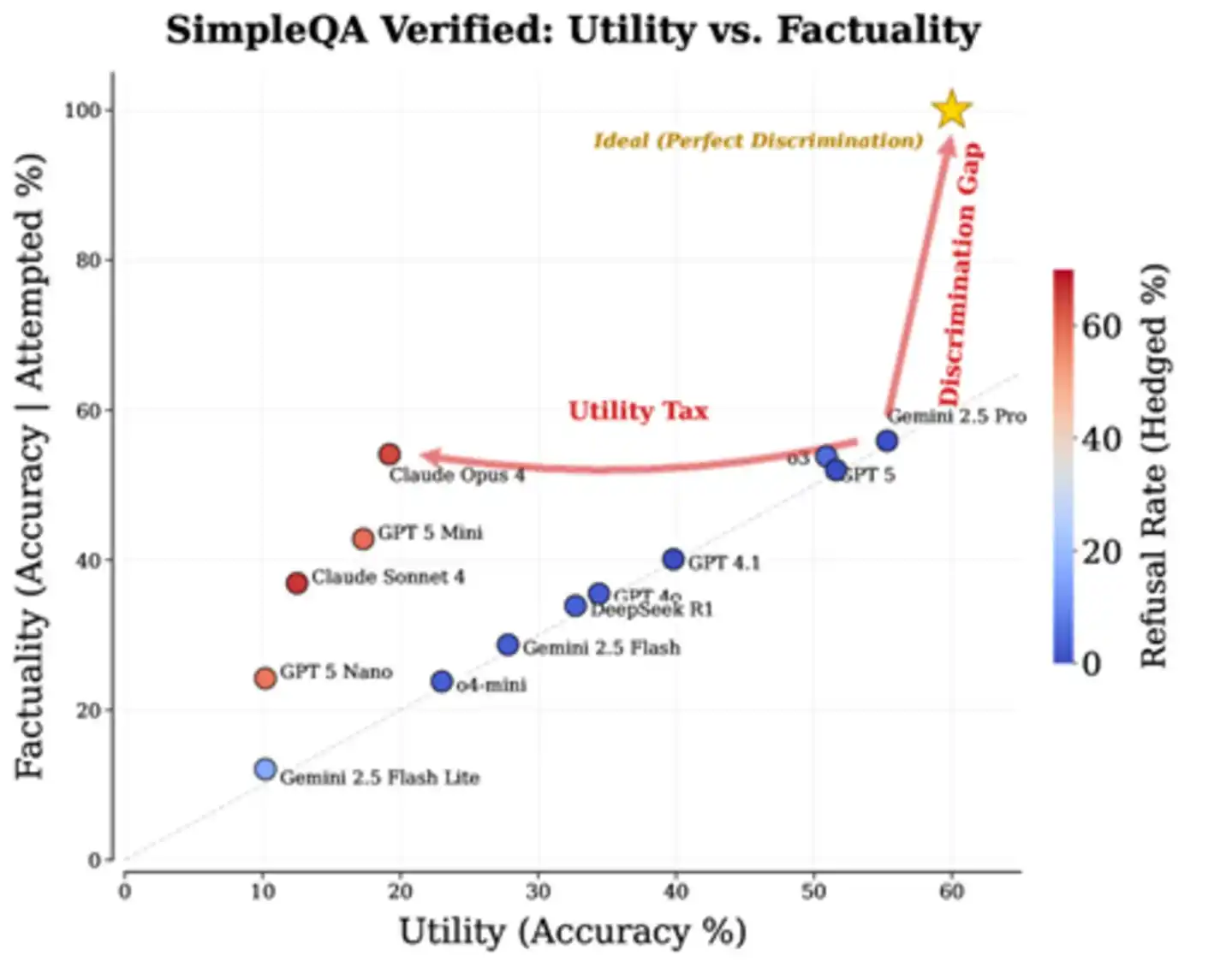
Gambar: Kinerja terukur berbagai model utama pada SimpleQA Verified. Bintang segilima di sudut kanan atas adalah target ideal, "Discrimination Gap" menandai jurang antara model yang ada dengan yang ideal, "Utility Tax" menandai harga kegunaan yang dibayar Claude Opus 4 untuk menukar akurasi tinggi.
Karena "menjejali lebih banyak pengetahuan" memiliki titik buta, "tidak yakin maka diam" biayanya terlalu tinggi, apakah ada jalur ketiga?
Mendefinisikan Ulang Halusinasi: Bukan "Salah Berkata", Tapi "Tidak Berhak Yakin Tapi Berbicara dengan Yakin"
Kontribusi inti makalah ini bukan pada mendiagnosis masalah, tetapi pada mendefinisikan ulang masalah itu sendiri.
Selama ini, industri mendefinisikan "halusinasi" sebagai "AI mengeluarkan informasi salah", ini mengandung premis implisit: membasmi halusinasi = membasmi semua kesalahan. Namun makalah mengusulkan, coba dari sudut lain—halusinasi bukan "AI salah bicara", tetapi "AI tidak berhak yakin, namun dengan nada yakin memberikan informasi yang salah".
Perbedaan ini tampak halus, tetapi dampaknya mendalam. Contoh: dokter melihat laporan pemeriksaan lalu berkata "Anda terkena penyakit X", jika sebenarnya dia hanya menebak berdasarkan intuisi, ini tidak bertanggung jawab. Namun jika dia berkata "Gejala saat ini mengarah ke X, tetapi perlu pemeriksaan lebih lanjut untuk memastikan", meskipun arah penilaian awal ada penyimpangan, cara ekspresi ini sendiri jujur—dia memberi tahu pasien "Harap hati-hati menanggapi penilaian ini". Kesalahan bukan tidak dapat diterima, yang tidak dapat diterima adalah jelas-jelas tidak yakin tetapi berpura-pura yakin.
Berdasarkan definisi baru ini, muncul jalur ketiga: Ketidakpastian Setia (faithful uncertainty)—membuat AI pada tingkat bahasa mengungkapkan tingkat keyakinan yang sesuai dengan tingkat keyakinan kondisi internalnya yang sebenarnya.
Secara spesifik, "ketidakpastian internal" AI dapat diukur secara objektif melalui pengambilan sampel berulang: pertanyaan yang sama ditanyakan seratus kali, setiap kali memberikan jawaban sama, menunjukkan keyakinan dalam hati; jawaban beraneka ragam, menunjukkan internal sebenarnya goyah. "Ketidakpastian bahasa" adalah kepastian yang tercermin dalam pilihan kata AI—"4 Agustus 1961" dan "Saya sepertinya ingat tahun 1961, tetapi tidak sepenuhnya yakin", memberi sinyal yang sangat berbeda kepada pembaca.
Ketidakpastian Setia mensyaratkan keduanya sejajar: saat hati goyah, pilihan kata memberi ruang; saat hati yakin, baru gunakan nada yang pasti. Makalah menekankan, target ini lebih dapat dicapai daripada "membasmi semua kesalahan". Alasannya, Ketidakpastian Setia hanya membutuhkan output bahasa AI sesuai dengan kondisi internalnya sendiri—ini adalah masalah tertutup, sinyal ada di dalam model, tidak bergantung pada kebenaran eksternal. Sedangkan membasmi kesalahan membutuhkan output AI sepenuhnya sesuai dengan kebenaran dunia eksternal, makalah merujuk masalah penghentian (halting problem) dan teori komputasi menunjukkan, ini secara teoretis memiliki batasan mendasar.
Makalah merangkum kemampuan ini menjadi konsep yang lebih tinggi: Metakognisi (metacognition)—AI dapat merasakan ketidakpastian dirinya sendiri, dan dapat menyesuaikan perilaku berdasarkan persepsi ini. Konsep ini dipinjam dari psikologi, arti aslinya "kognisi terhadap proses kognisi sendiri", dalam konteks AI, berarti AI memiliki kesadaran yang jelas tentang apa yang dia tahu dan tidak tahu.
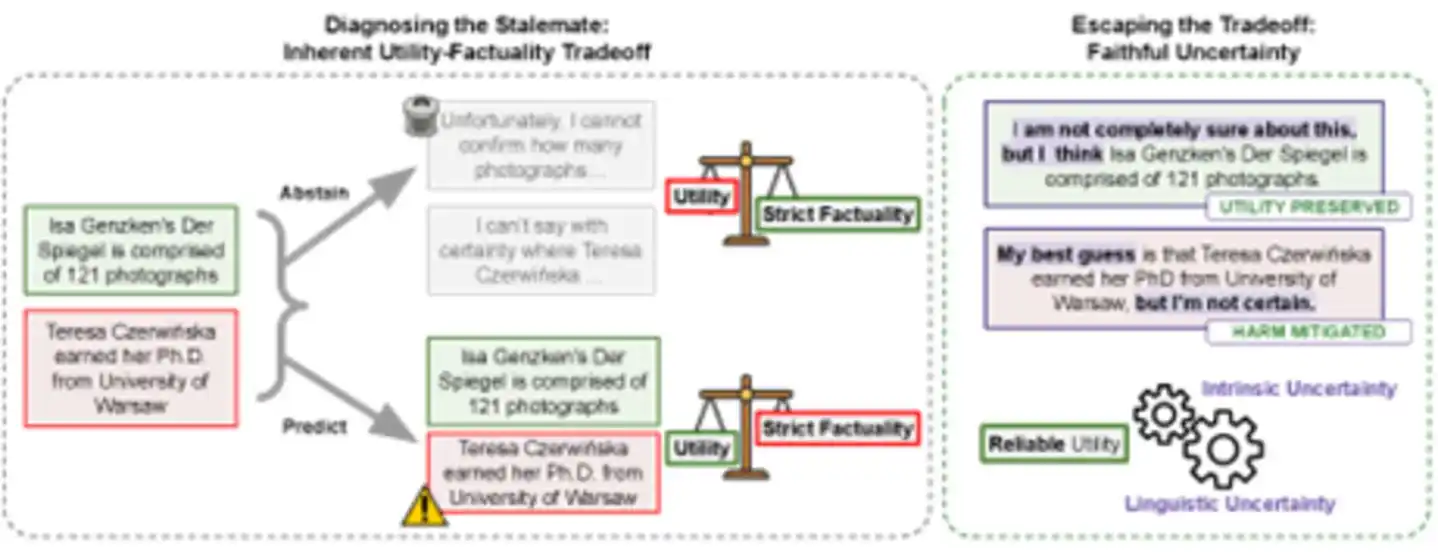
Gambar: Kiri adalah dilema tradisional—"menjawab" berisiko halusinasi, "menolak menjawab" memiliki biaya kegunaan. Kanan adalah jalur baru—dengan mengungkapkan ketidakpastian secara setia, mempertahankan informasi berguna sekaligus meminimalkan bahaya informasi salah, mencapai "kegunaan yang dapat diandalkan".
Era Agen AI: Tanpa Metakognisi, Agent Adalah "Terbang Buta"
Nilai Metakognisi tidak terbatas pada skenario percakapan. Di era Agen AI, ini menjadi lebih kritis.
Secara sekilas, memasang mesin pencari ke AI dapat menyelesaikan masalah kekurangan pengetahuan—tidak tahu ya cari, takut apa halusinasi? Tetapi makalah menunjukkan, alat yang diperkenalkan bukan "solusi penyimpanan", melainkan "masalah kendali".
Dengan adanya alat, AI menghadapi serangkaian keputusan baru: Apakah saya tahu jawaban pertanyaan ini sendiri, perlu mencari? Apakah informasi yang ditemukan dapat dipercaya? Jika hasil pencarian bertentangan dengan informasi yang saya kuasai, dengar yang mana? Kapan harus berhenti mencari?
Semua keputusan ini bergantung pada persepsi akurat AI terhadap tingkat keyakinan internalnya sendiri. Agen AI tanpa kemampuan metakognisi, seperti pilot tanpa dashboard—mesin sudah alarm, dia malah mempercepat.
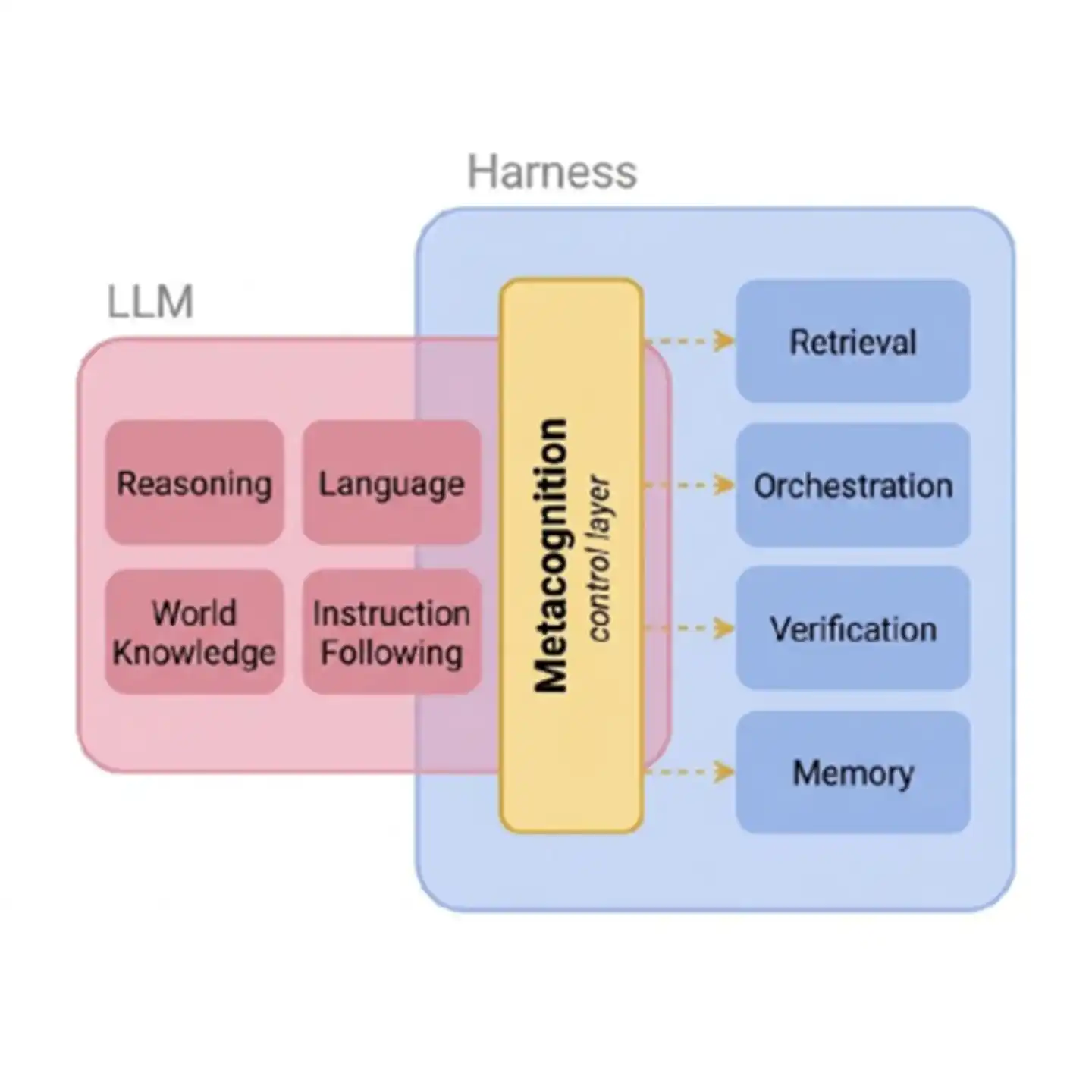
Gambar: Lapisan kendali metakognisi sebagai jembatan antara kemampuan dasar AI dan sistem alat eksternal. Tanpa lapisan ini, penjadwalan Agent terhadap alat eksternal seperti "terbang buta"—tidak tahu harus cari atau tidak, setelah mencari harus percaya atau tidak, sampai sejauh mana percaya.
Penelitian yang dirujuk makalah menunjukkan, agen AI yang ditingkatkan pencarian saat ini umumnya memiliki masalah penyalahgunaan alat—untuk pertanyaan yang sama sekali tidak perlu dicari juga dicari, efisiensi rendah dan memperkenalkan kebisingan yang tidak perlu. Alasannya sederhana: AI tanpa metakognisi sama sekali tidak bisa menilai "apakah saya perlu informasi tambahan".
Di Jalan Menuju Metakognisi, Masih Ada Beberapa Tantangan Keras
Makalah juga secara jujur menunjukkan tantangan kunci dalam jalur implementasi.
"Paradoks Bootstrap": Mengajari AI mengungkapkan ketidakpastian memerlukan data pelatihan yang mendemonstrasikan "saatnya ragu, ragu", tetapi batas pengetahuan AI bersifat dinamis. Satu sampel data berlabel "Saya tidak yakin" mungkin setelah evolusi model berubah menjadi konten yang dia ketahui dengan pasti. Menggunakan data statis untuk mengajari kemampuan dinamis akan melatih AI yang "pura-pura tidak yakin". Ini memerlukan pengembangan infrastruktur data dinamis yang dapat mencerminkan batas pengetahuan model saat ini.
"Sinyal Penghancuran Penyelarasan": Penelitian menemukan, AI setelah pra-pelatihan sebenarnya sudah memiliki sinyal ketidakpastian internal yang bagus—kondisi internalnya dapat membedakan "soal ini agak yakin" dan "soal ini kurang yakin". Namun pelatihan penyelarasan seperti RLHF akan menghapus sinyal ini. Alasannya, preferensi manusia adalah jawaban dengan nada yakin, ini memaksa AI belajar bahwa betapapun goyah hatinya, di luar selalu tampil percaya diri.
"Evaluasi Kausalitas": Masalah yang lebih dalam adalah, bagaimana memastikan AI benar-benar membaca sinyal internal, bukan hanya belajar "menghadapi kata langka langsung bilang tidak yakin" seperti strategi permukaan? Membedakan "metakognisi sejati" dan "pertunjukan metakognisi", adalah masalah evaluasi ilmiah mendasar.
Makalah juga mengusulkan saran spesifik kepada komunitas penelitian: Jangan lagi hanya menggunakan satu angka akurasi untuk mengevaluasi metode anti-halusinasi, seharusnya divisualisasikan kurva lengkap "tawar-menawar kegunaan-tingkat kesalahan", lihat dengan jelas apakah suatu metode benar-benar meningkatkan kemampuan diskriminasi dasar, atau hanya menaikkan ambang batas penolakan jawaban pada kurva yang sama. Bersamaan harus mendeteksi "kerusakan sampingan"—untuk menurunkan tingkat kesalahan tanya jawab pengetahuan, apakah telah membayar harga tak terduga pada tugas penalaran, pemrograman, penulisan, dll.
Pada akhirnya, pesan inti yang ingin disampaikan makalah ini adalah: AI dapat tidak serba tahu dan serba bisa, tetapi dia harus memiliki pengenalan jujur tentang apa yang dia tahu dan tidak tahu, dan menyampaikan pengenalan ini kepada pengguna.
Kita mempercayai profesional, bukan karena mereka tidak pernah salah, tetapi karena mereka dapat jujur membedakan "saya yakin" dan "saya menebak"—justru perbedaan ini yang membedakan profesional dan tidak profesional. AI juga harus menempuh jalan ini. Daripada mengejar tanpa henti ilusi sempurna tak bersalah, lebih baik ajari AI satu hal yang lebih realistis: tahu kapan dia ngawur, dan secara jujur beri tahu pengguna. (Artikel ini pertama kali diterbitkan di TMTPost App, penulis | Silicon Valley Tech_news, editor | Jiao Yan)






