Hari ini, peringkat terbaru Code Arena resmi dirilis!
Qwen3.7-Max dengan skor 1541 berhasil masuk ke empat besar global, melampaui sejumlah model top seperti GPT-5.5 dan Gemini 3.5 Flash.
Di depannya, hanya tersisa Claude Opus 4.7 dan Opus 4.6.
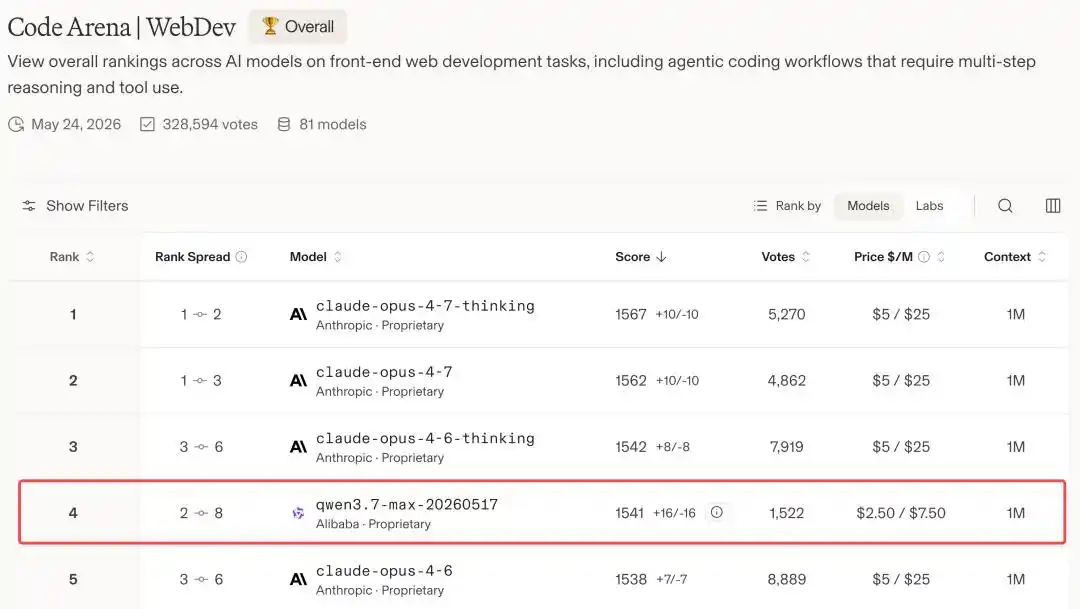
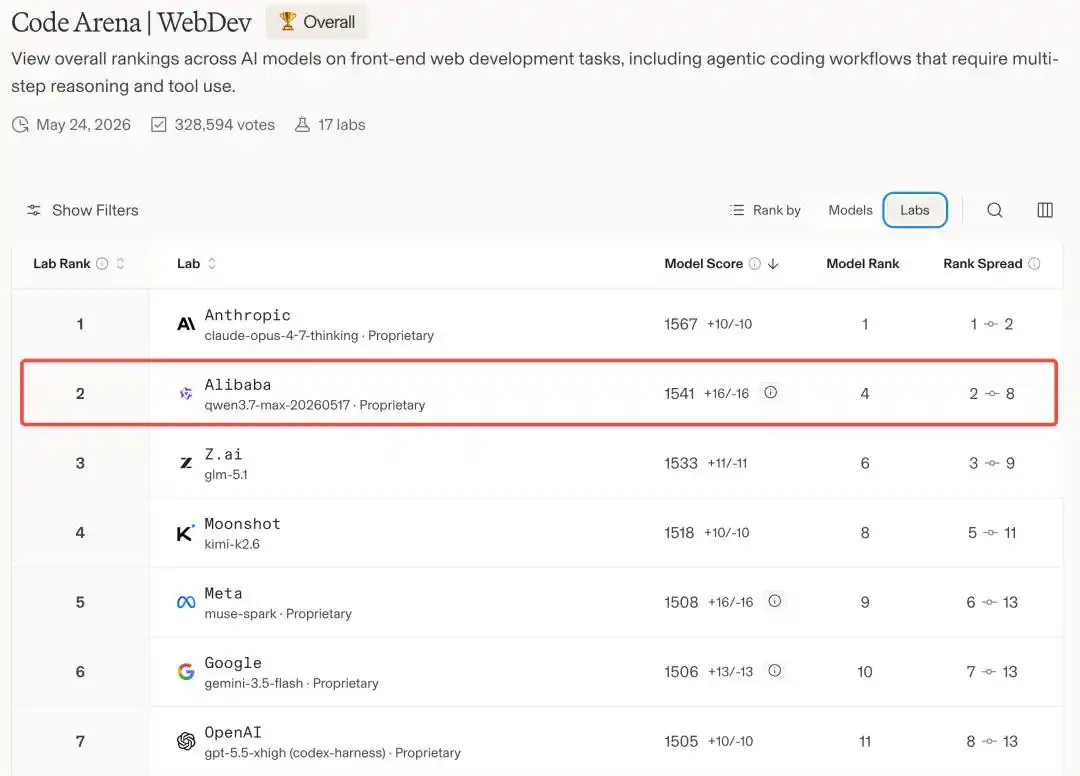
Dengan kata lain, di arena pertandingan model pemrograman global, Alibaba adalah satu-satunya perusahaan China yang berhasil masuk ke meja permainan ini, berada di posisi kedua setelah Anthropic.
Qwen3.7-Max Masuk Lima Besar Global
Satu-satunya Model Non-Claude
Sebenarnya, sebelum peringkat Code Arena dirilis, Qwen3.7-Max sudah terkenal di kalangan developer luar negeri.
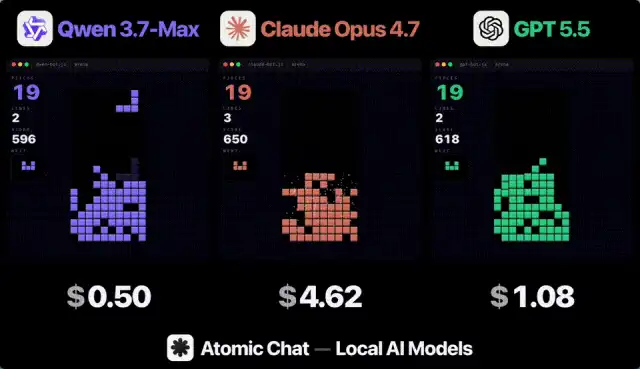
Atomic Chat melakukan perbandingan langsung, membuat Opus 4.7, GPT-5.5, dan Qwen3.7-Max bertanding, dengan tugas menulis AI Tetris yang bisa melatih dirinya sendiri.
Hasilnya, Qwen3.7-Max tidak hanya melampaui Opus 4.7 dan GPT-5.5 dengan biaya token hanya $1.32, tetapi juga meningkatkan kinerja hingga 56%.
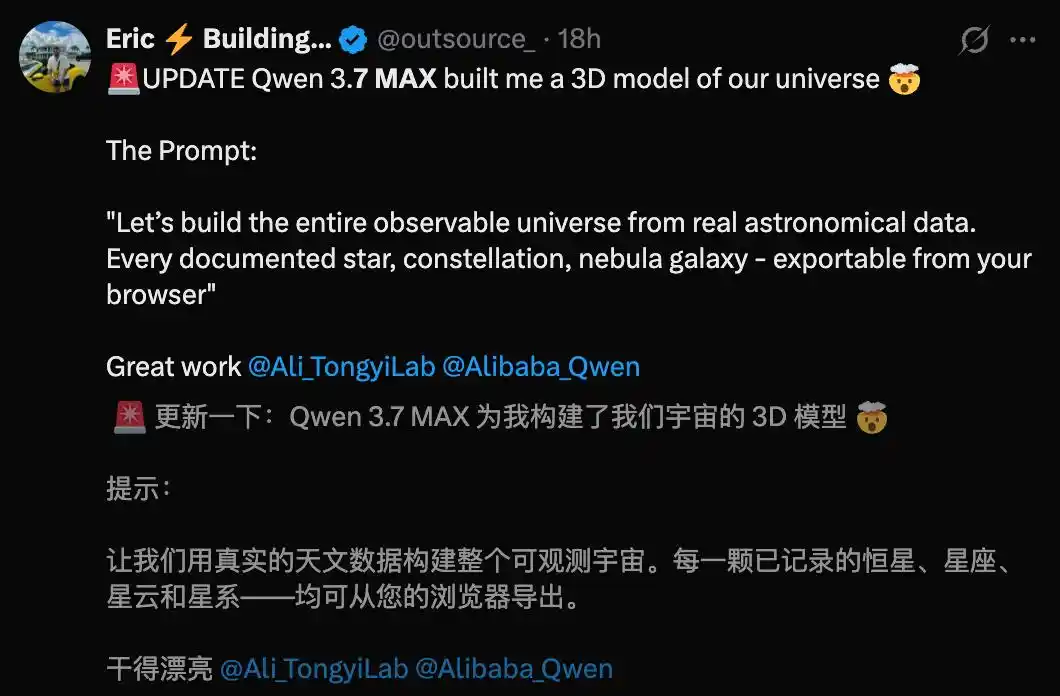
Seorang developer luar negeri lain meminta Qwen3.7-Max membuat model 3D alam semesta, hasilnya cukup mengesankan.
Dalam tugas pembuatan "Model Pagoda Miniatur dengan Gaya Pixel 3D", kecepatan dan kualitas output Qwen3.7-Max juga sepenuhnya mengungguli yang lain.

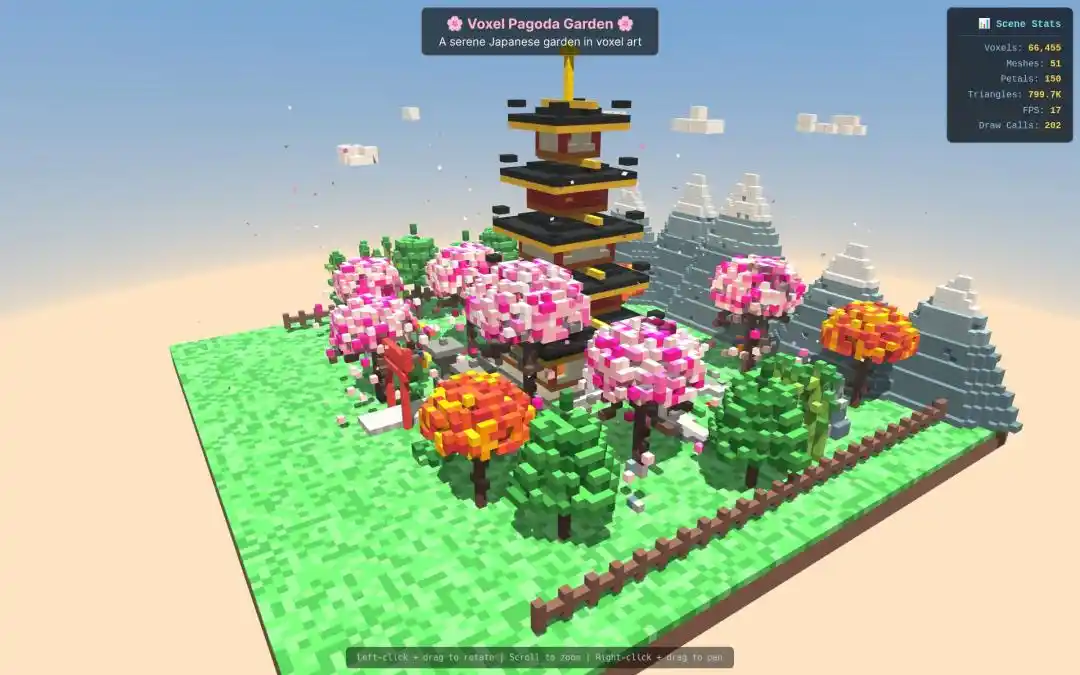
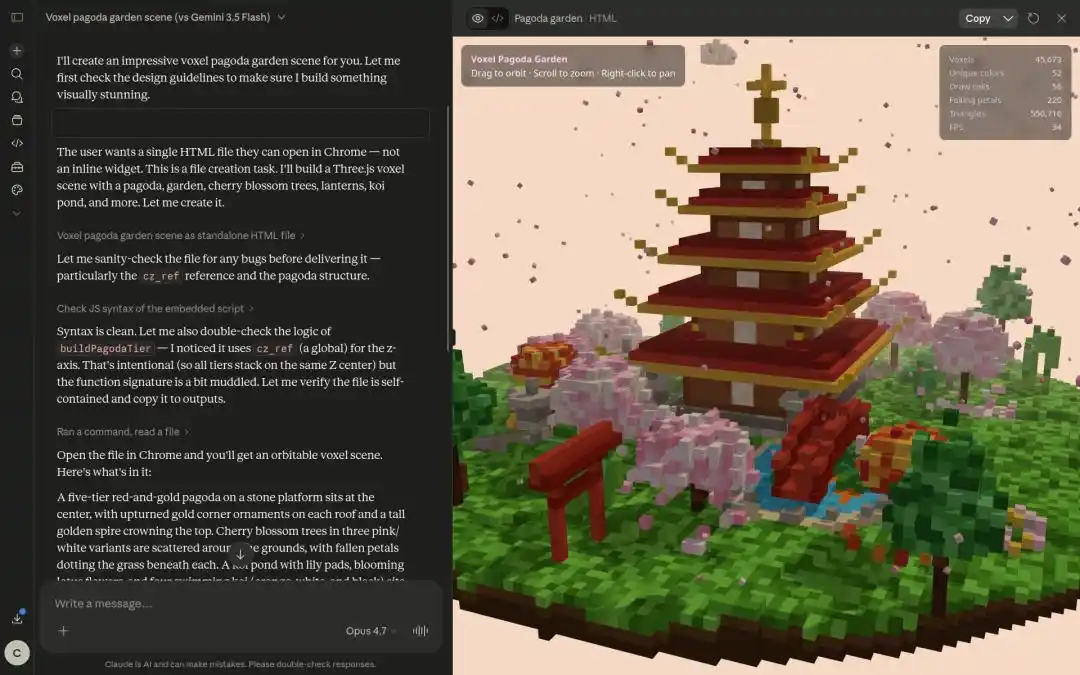
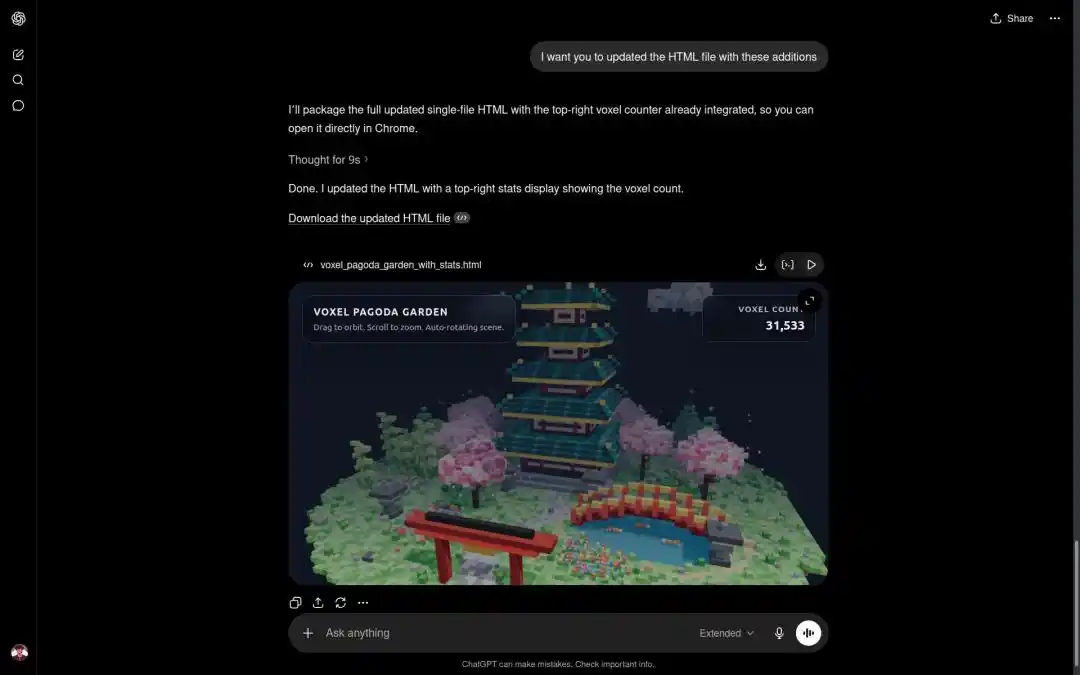
Developer Paul Couvert bahkan memuji, setelah Qwen3.7-Max terintegrasi dengan Hermes Agent dan OpenCode, pada dasarnya dapat menggantikan GPT-5.5 dan Opus 4.7.
Pemrograman, Sangat Tangguh
Namun, skor benchmark setinggi apapun, lebih baik diuji secara langsung.
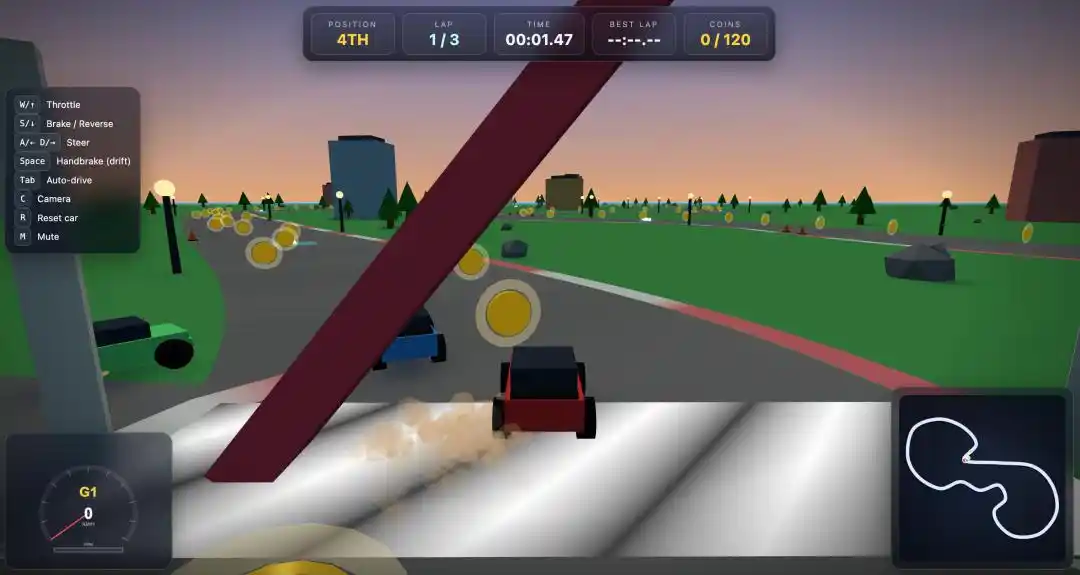
Kami memberikan Qwen3.7-Max tantangan "Game Balap" yang sulit.
Setelah dimasukkan prompt yang detail, Qwen3.7-Max langsung menghasilkan file HTML yang bisa dimainkan.

Versi pertama ada bug kecil, tombol belok A/D terbalik.
Tapi setelah penyesuaian sederhana dalam dialog putaran kedua, game balap 3D yang lengkap langsung bisa dijalankan.

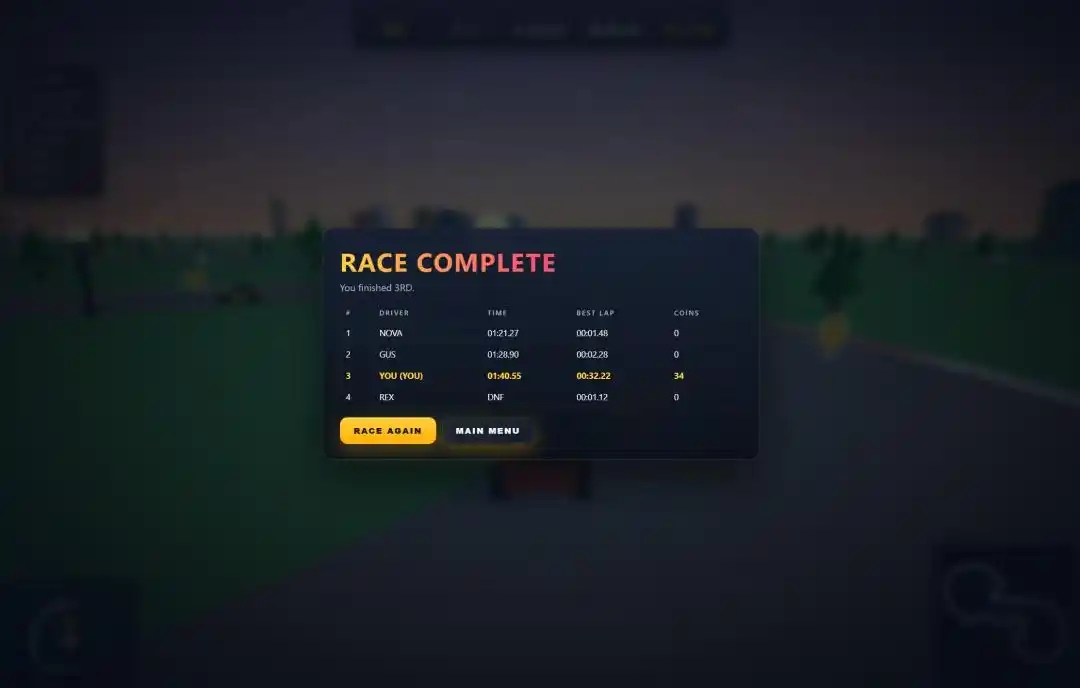
Setelah dibuka, jujur, agak terkejut.
4 mobil bersaing, lintasan melingkar 3 lap, lebih dari 100 koin tersebar di trek, menabrak rintangan akan memperlambat dan kehilangan kendali.
Panel skor setelah balapan, peringkat, waktu, jumlah koin, putaran tercepat, semuanya ada.
Tapi yang benar-benar mengejutkan adalah dua detail yang hanya dilakukan oleh Qwen3.7-Max.
Satu adalah layar awal. Setelah menguji keempat model secara horizontal, hanya dia yang membuat halaman awal yang layak untuk game, klik "Start" baru masuk ke pertandingan. Tiga lainnya langsung berjalan begitu dibuka, bahkan tanpa layar judul.
Lainnya adalah efek suara. Di akhir prompt ada permintaan untuk menambahkan efek suara mesin dan suara mengambil koin. Dari keempat model, hanya dia yang memenuhinya, suara mesin dan denting koin sudah disiapkan.
Mari lihat performa peserta lainnya.
Visual Gemini 3.5 Flash jelas lebih sederhana satu tingkat, kurang ada kesan 3D yang nyata.
Layout UI juga bermasalah, informasi dasbor tersebar di empat sudut layar, fokus visual berantakan.
Sebaliknya, Qwen3.7-Max menempatkan indikator kunci di tengah layar, lebih sesuai dengan titik pandang alami pemain.

Efek Claude Opus 4.6, agak sulit diungkapkan.
Tidak hanya koin di lintasan sangat sedikit, tetapi juga 3 mobil AI hampir berjalan bersamaan, tanpa keacakan, seolah-olah dicopy-paste.
Terakhir adalah GPT-5.5.
Bisa dilihat, kualitas visual memang lebih baik dari dua model sebelumnya, dan lebih lancar saat dioperasikan.
Tapi entah kenapa, koin dibuat menjadi "donat" kuning...
Bentuk bukan masalah besar. Kuncinya adalah, Gemini, Claude, ChatGPT ketiganya harus memperbaiki bug beberapa kali agar semua fungsi bisa berjalan.
Hanya Qwen3.7-Max yang pada putaran pertama sudah menghasilkan sesuatu yang bisa dimainkan.
Skor benchmark mendekati, uji nyata tidak mengecewakan, harga hanya sepersekian. Kesimpulan selanjutnya, tunggu saja developer memilih dengan tindakan.
Model "Landasan" di Era Agent
Alasan mengapa Qwen3.7-Max bisa mencapai level seperti ini di arena pemrograman yang paling kompetitif, jawabannya tersembunyi dalam posisi produknya.
Beberapa hari yang lalu, saat Alibaba meluncurkan Qwen3.7-Max, memberinya label yang sangat khusus: Model Landasan Agent.
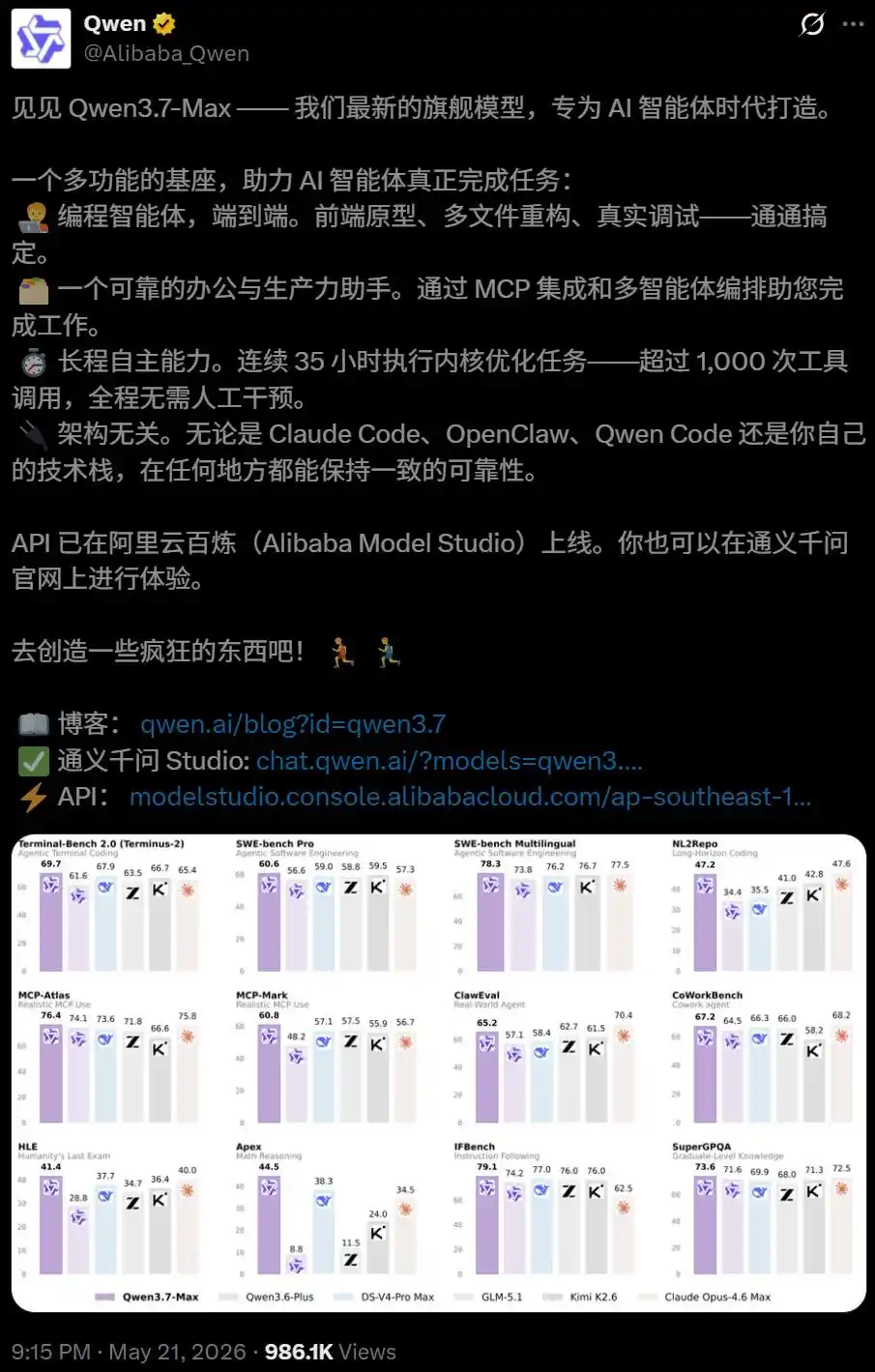
Dia memang dirancang untuk model yang dapat menjalankan tugas secara mandiri dalam waktu lama.
Data uji internal menunjukkan, dalam satu tugas pemrograman mandiri, Qwen3.7-Max berjalan terus menerus selama 35 jam, melakukan 1158 kali pemanggilan alat.
Kode yang dihasilkan akhirnya mencapai percepatan rata-rata geometrik 10 kali lipat yang menakjubkan dibandingkan implementasi referensi Triton.
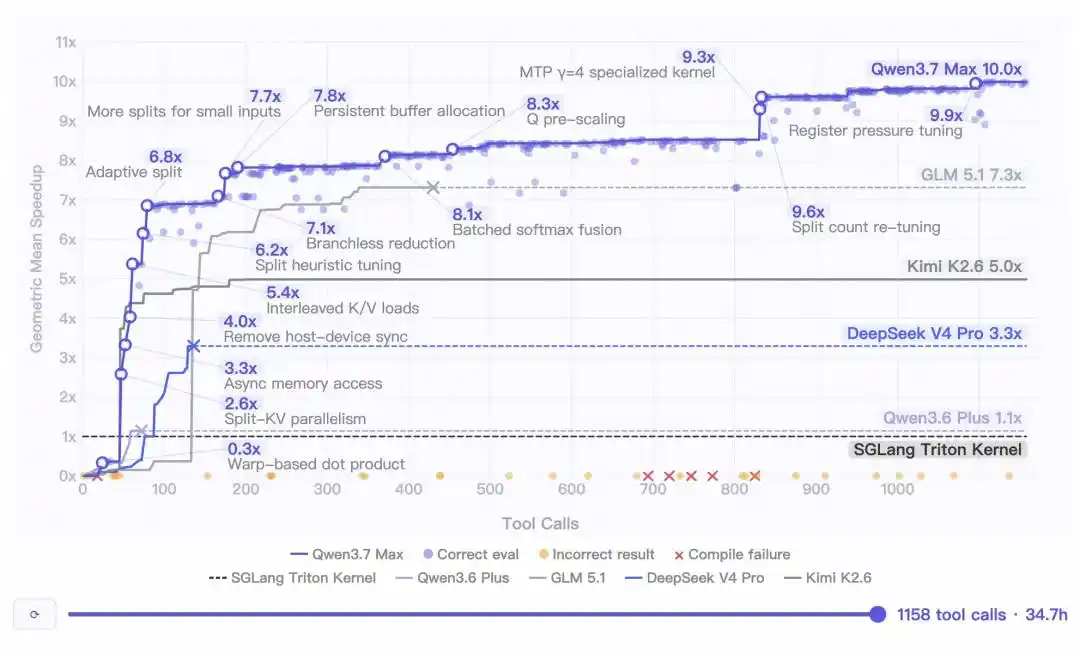
Yang lebih mengesankan adalah kemampuan "perang berkepanjangan"-nya —
Setelah deduksi berjalan lebih dari 30 jam, model tetap tajam, terus menemukan ruang optimasi baru.
Sepanjang proses, nol degradasi konteks, nol pergeseran instruksi, nol perulangan tak berujung!
Harus diakui, kesulitannya bukan pada 1000 kali pemanggilan alat itu sendiri. Setelah protokol MCP diperluas, memanggil alat 1000 kali bukan hal aneh.
Kesulitannya terletak pada penalaran koheren selama 35 jam.
Sebagian besar model akan gagal dalam tugas panjang: konteks semakin menumpuk dan kacau, tujuan yang ditetapkan di awal terlupakan di belakang; atau masuk ke perulangan tak berujung, berulang kali mencoba solusi yang sama yang gagal.
Qwen3.7-Max berhasil mewujudkan hal "terus melakukan hal yang benar".
Mengungkap Teknologi Inti
Lompatan pemrograman Qwen3.7-Max ini, kami pahami mungkin terkait dengan peningkatan dua metode pelatihan.
Pertama adalah, ekstensi lingkungan.
Saat melakukan pelatihan pemrograman, setiap tugas di Qwen3.7-Max dipecah menjadi tiga dimensi independen: tugas itu sendiri, kerangka kerja eksekusi, dan cara verifikasi, ketiganya dapat dikombinasikan secara bebas.
Soal yang sama, kadang-kadang dikerjakan dalam kerangka kerja Claude Code, kadang-kadang di OpenClaw, kadang-kadang dengan cara verifikasi yang berbeda.
Efeknya seperti seorang magang yang dipindahkan ke semua tim proyek. Apa yang dipelajari secara paksa adalah strategi umum untuk memecahkan masalah, bukan "bagaimana cara mencari jalan pintas dalam kerangka kerja tertentu".
Ini menjelaskan fenomena kontra-intuitif, performa Qwen3.7-Max dalam kerangka kerja Claude Code, OpenClaw, dan Qwen Code sangat stabil, tidak ada situasi "sangat kuat di kerangka kerja sendiri, tetapi buruk saat berganti".

Peningkatan kedua adalah, eksekusi mandiri jarak jauh.
Dalam pelatihan, tim memperkenalkan kerangka kerja "permainan akumulatif dinamis".
Artinya, model membuat lebih dari seribu keputusan berurutan dalam lingkungan simulasi yang terus berubah, membangun hipotesis sendiri, menyesuaikan strategi berdasarkan umpan balik, dan tidak boleh mengalami "pembusukan konteks" karena berjalan terlalu lama.
Ada data intuitif di sini, YC-Bench mensimulasikan operasi perusahaan startup selama setahun penuh, Qwen3.7-Max menghasilkan pendapatan $2,08 juta, dua kali lipat dari generasi sebelumnya ($1,05 juta).
Yang lebih penting adalah, dia menunjukkan evolusi strategi, dapat menyesuaikan arah secara mandiri saat menghadapi krisis di tengah jalan, mengidentifikasi dan memblokir klien jahat, dan akhirnya menyatu ke dalam siklus eksekusi yang stabil.
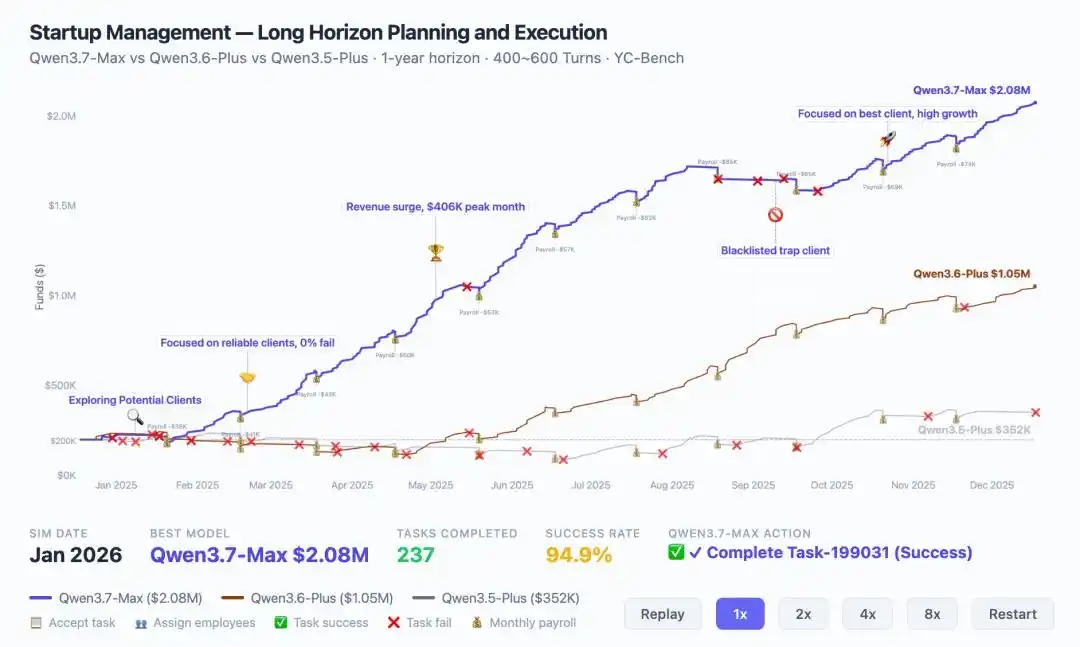
Inilah dukungan mendasar dari kasus optimasi kernel 35 jam, dan juga alasan mengapa di Kernel Bench L3, Qwen3.7-Max dapat menghasilkan efek percepatan pada 96% skenario.
Dan pemrograman hanyalah medan pertempuran pertama. Fondasi penalaran jarak jauh ditambah pemanggilan alat ini mengarah pada ambisi yang lebih besar — Landasan Agent Umum.
Final Pemrograman, Bertambah Satu Pengacau
Sejak diluncurkan, Code Arena selalu menguji kemampuan keras: penalaran multi-langkah, pengaturan alat, pengiriman proyek lengkap, semuanya adalah pertarungan nyata tingkat Agent.
Hari ini, Qwen3.7-Max dengan skor 1541 menempati posisi keempat, berada di antara Opus 4.6 Thinking dan Opus 4.6.
Di lintasan yang telah dikuasai Claude selama setengah tahun ini, dia memberikan jawabannya sendiri, model China bukan hanya pengejar, tetapi juga dapat menjadi pendefinisi.
Kompetisi model pemrograman global bukan lagi pertunjukan tunggal Silicon Valley.
Referensi:
https://arena.ai/leaderboard/code/webdev
Artikel ini berasal dari akun WeChat "新智元", penulis: ASI启示录





