Penulis: IC3
Diterjemahkan oleh: Jiahuan, ChainCatcher
Kesimpulan Inti
Integrasi AI dan crypto yang bermakna masih berada di tahap yang sangat awal, hiruk-pikuk di sekitar area persilangan ini telah mengalahkan kemajuan aktual.
Dalam arah Crypto x AI, AI telah mampu menganalisis dan mendeteksi transaksi, peristiwa, dan sifat kunci protokol yang ada, mengidentifikasi kontrak pintar yang curang atau rentan. Teknologi semacam ini banyak menggunakan metode pembelajaran mesin sederhana, dan paling efektif dalam lingkungan terkontrol dengan data yang melimpah.
Dalam arah AI x Crypto, alat crypto menyediakan cara baru untuk melindungi dan mengatur proses AI. Alat-alat seperti bukti tanpa pengetahuan (zero-knowledge proof), komputasi tepercaya, dapat diadaptasi untuk mengurangi risiko hasil AI dimanipulasi. Sedangkan gagasan seperti tata kelola terdesentralisasi, manajemen infrastruktur terdesentralisasi, belum benar-benar diadopsi di kalangan utama AI.
Industri masih perlu membuktikan dua hal.
Pertama, AI terdesentralisasi perlu dibandingkan dengan skema terpusat dengan perbandingan biaya yang lebih ketat dan langsung. Saat ini, industri terutama membuktikan "dapat melatih model besar dalam lingkungan terdistribusi," tetapi peluang untuk bersaing dengan platform terpusat di bawah skenario spesifik dengan biaya, masih kurang bukti kuantitatif.
Kedua, pembayaran crypto perlu membuktikan kegunaan nyatanya relatif terhadap skema terpusat dalam skenario pembayaran agen. Crypto selalu kurang dampak substansial di bidang pembayaran, tetapi pembayaran agen memiliki biaya rendah, dan tidak perlu menerapkan mode "akun harus dimiliki seseorang" dalam keuangan tradisional, sehingga memiliki potensi. Industri harus menggunakan bukti kuantitatif untuk menangkap peluang ini, bukan hanya berhenti pada kelayakan.
Selain itu, ada dua masalah penelitian yang belum terpecahkan.
Pertama, keamanan AI memerlukan pertahanan di tingkat sistem: Lingkaran AI biasanya menyelesaikan masalah keamanan di tingkat model, merancang pagar pelindung di sekitar semantik input-output. Namun, seiring dengan peningkatan otonomi agen dan kemampuan untuk langsung mengakses infrastruktur dasar, cara ini tidak akan lagi cukup. Eksekusi yang dapat diverifikasi dan proses otentikasi crypto dapat melengkapi jaminan tingkat sistem yang tidak dapat dicapai di tingkat model.
Kedua, kombinasi crypto dan AI akan melahirkan subjek ancaman baru dan vektor serangan, seperti agen otonom yang tidak dapat dimatikan dan kontrak pintar yang lepas kendali yang akan dibahas di bawah.
Kerangka Terpadu: AI dan Crypto Saling Menjadi "Middleware"
Sebuah alur keputusan otomatis dapat dipecah menjadi empat bagian: niat manusia, input, program, output, dan setiap bagian dalam rantai ini belum tentu tepercaya. AI dan crypto masing-masing mengelola bagian tertentu dalam kerangka ini.
AI adalah "middleware penerjemah", menerjemahkan niat manusia yang samar menjadi program yang dapat dieksekusi mesin, misalnya mengubah "Saya ingin mengidentifikasi tanda parkir" menjadi model yang telah dilatih, sehingga mengurangi hambatan penggunaan blockchain.
Crypto adalah "middleware untuk memperoleh kepercayaan", menjamin bahwa suatu perhitungan memang dieksekusi sesuai kesepakatan dan hasilnya tidak dimanipulasi (integritas) melalui komputasi tepercaya, menjamin sistem selalu tersedia dan tahan sensor (ketersediaan) melalui desentralisasi, dan sebagian skema juga dapat menjamin input-output tidak bocor (kerahasiaan).
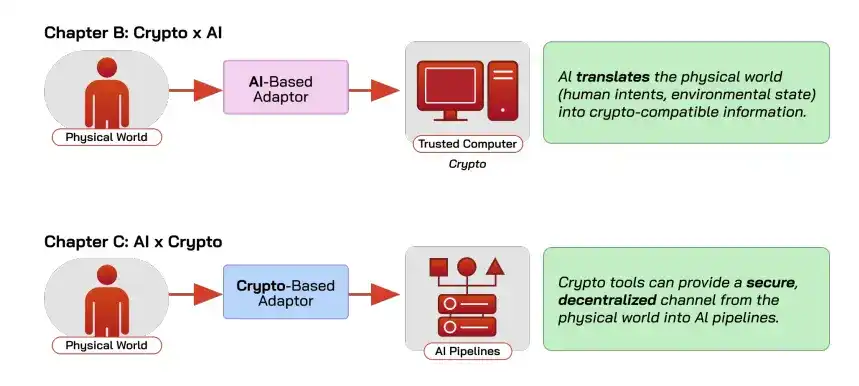
Komputasi tepercaya memiliki tiga jalur teknologi.
Pertama, Lingkungan Eksekusi Tepercaya (TEE), mengandalkan perangkat keras khusus untuk menyediakan isolasi dan bukti jarak jauh (hardware memberikan bukti status yang dapat diverifikasi, memungkinkan pihak lain mengkonfirmasi chip asli dan tidak dimanipulasi). Dengan komputasi rahasia NVIDIA, overhead tambahan untuk inferensi model parameter 8B di bawah 7%, model 70B hampir tidak ada kehilangan. Biayanya adalah harus mempercayai produsen perangkat keras, dan tidak melawan serangan fisik.
Kedua, Bukti Tanpa Pengetahuan (ZK), hanya mengandalkan masalah kriptografi, asumsi keamanan paling bersih, tetapi overhead sangat tinggi. Membuat bukti untuk model kecil sekitar 18 juta parameter membutuhkan sekitar satu menit, masih jauh dari model besar terkini dalam beberapa orde magnitudo.
Ketiga, Komputasi Multi-Pihak (MPC), memungkinkan banyak pihak melakukan komputasi bersama tanpa menyerahkan data asli, lebih lambat. Kerangka inferensi Transformer MPC paling canggih, menghasilkan satu token untuk LLaMA-7B membutuhkan sekitar lima menit.
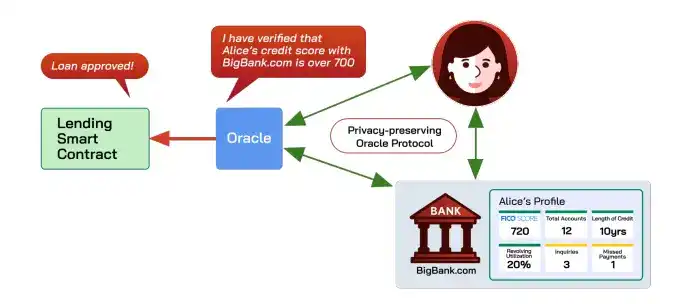
Oracle bertanggung jawab membawa data off-chain ke on-chain dengan tepercaya. Oracle privasi (seperti Town Crier, DECO) lebih lanjut mendukung pembuktian sifat data tanpa membocorkan privasi, misalnya membuktikan "skor kredit seseorang di atas 700" tanpa mengungkap informasi lain.
Industri menyebut rangkaian teknologi ini secara kolektif sebagai zkTLS, tetapi skema berbasis TEE di dalamnya tidak menggunakan bukti tanpa pengetahuan apa pun, merupakan penyalahgunaan penamaan.
Crypto x AI: Menggunakan AI untuk Memperkuat Blockchain
Penelitian AI untuk crypto kira-kira dibagi menjadi tiga generasi berdasarkan waktu.
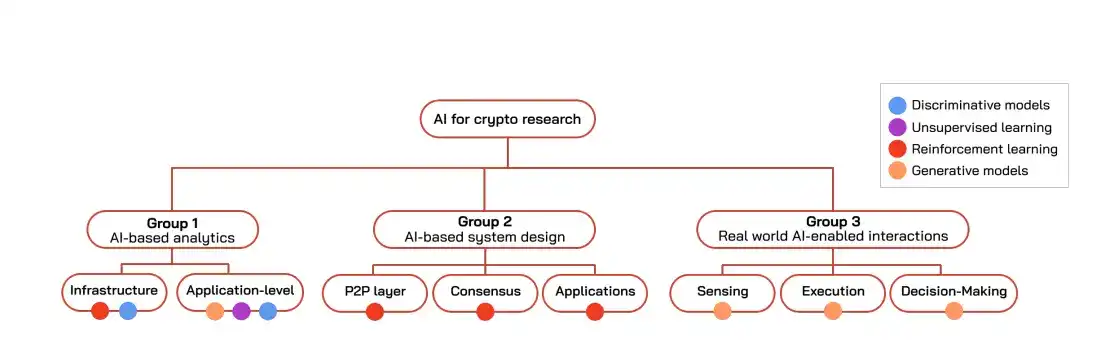
Generasi Pertama: Analisis dan Deteksi
Sejak lebih dari sepuluh tahun lalu, pembelajaran mesin digunakan untuk menganalisis status on-chain: menemukan kerentanan protokol konsensus (seperti penambangan egois, di mana penambang menyembunyikan blok yang telah ditambang dan merilisnya pada waktu yang tepat untuk mendapatkan lebih banyak keuntungan), mendeteksi serangan gerhana di jaringan P2P (mengelilingi suatu node dengan banyak node jahat, memutuskan koneksinya dengan jaringan jujur), memprediksi harga koin, mengidentifikasi transaksi penipuan dan pencucian uang.
Keterbatasannya adalah analisis semacam ini banyak bergantung pada skenario di mana informasi publik global dapat diperoleh, dan terbatas pada data simulasi, kurangnya sampel serangan nyata.
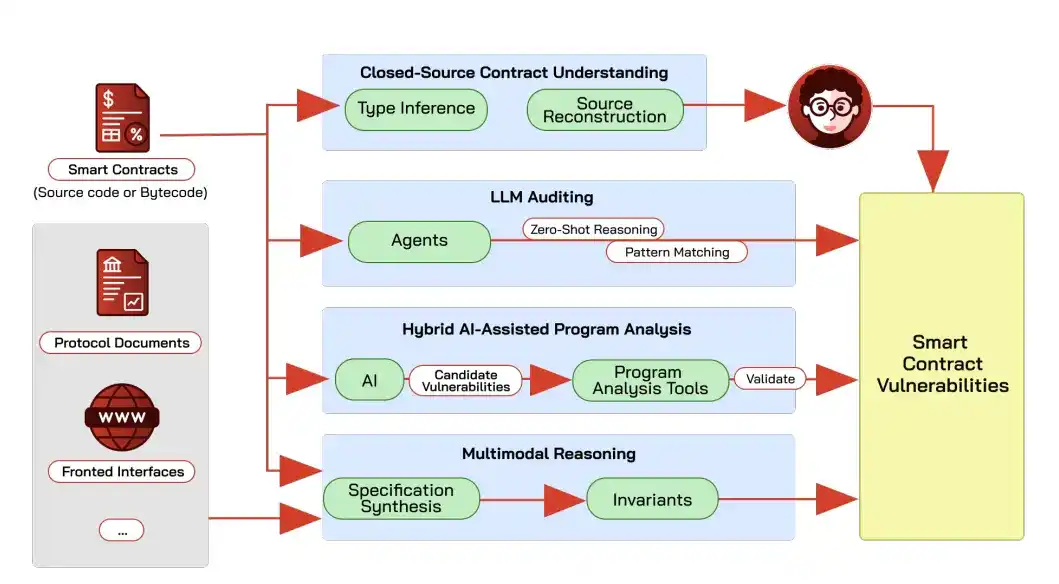
Deteksi kerentanan kontrak paling canggih saat ini, bukan lagi membiarkan AI langsung menebak kesimpulan dari kode, melainkan AI pertama-tama mengajukan titik-titik yang mencurigakan, kemudian diverifikasi menggunakan analisis statis, eksekusi simbolik (tidak menjalankan kode secara aktual, tetapi menganalisis struktur kode untuk menemukan kerentanan).
Membiarkan model besar bertindak sebagai auditor saja akan menghasilkan banyak false alarm karena halusinasi, GPT-4 dan Claude hanya mengidentifikasi jenis kerentanan dengan benar 40% dalam 52 kontrak DeFi yang pernah diserang.
Generasi Kedua: Desain Algoritma
Enam tahun terakhir, pembelajaran penguatan digunakan untuk merancang algoritma terdesentralisasi, mencakup topologi jaringan P2P, parameter protokol konsensus dan pemilihan peran, sharding, suku bunga pasar dan pinjaman DeFi, strategi penawaran MEV, dll.
Metode-metode ini sebagian besar efektif dalam lingkungan yang dapat dimodelkan dengan jelas, dan banyak yang masih dalam tahap penelitian, belum diterapkan secara besar-besaran di jaringan nyata dan diuji menghadapi serangan.
Generasi Ketiga: Berinteraksi dengan Dunia Nyata
Dengan oracle yang digerakkan AI, kontrak pintar memperoleh tiga kemampuan yang ditingkatkan: persepsi (memahami data tidak terstruktur dan bahasa alami), eksekusi (memanggil model dan alat AI off-chain), pengambilan keputusan (bertindak sebagai agen sesuai fungsi tujuan).
Kinerja aktual AI sebagai oracle tidak merata. Menurut eksperimen Chainlink Labs, GPT-4o memiliki akurasi keseluruhan 89.3% pada 1660 masalah pasar prediksi, Truth Bot dari UMA secara keseluruhan 75%, sedangkan akurasi manusia pada oracle optimis UMA (default jawaban benar, menetapkan periode sengketa, efektif jika tidak ada yang mempertanyakan) adalah 98.2%.
Tingkat akurasi sangat bergantung pada jenis masalah: masalah diskrit dengan sumber data resmi seperti hasil olahraga dapat mencapai 99.7%, masalah yang melibatkan urutan waktu atau memerlukan transkripsi penghitungan video memiliki tingkat kesalahan yang meningkat secara signifikan.
Ada tiga cara penanganan: pertama, dirancang untuk toleran kesalahan, hanya digunakan untuk skenario bernilai rendah; kedua, memperkenalkan arbitrase manusia, seperti menetapkan jendela sengketa 48 jam, tetapi akan memperlambat pengambilan keputusan; ketiga, membiarkan model menolak menjawab ketika tidak yakin, hanya pada saat itu baru memperkenalkan manusia.
"DAO Investasi" yang menyerahkan kumpulan dana ke model AI untuk perdagangan kolektif, laporan menyebutnya sebagai CoinAlg, proyek perwakilan seperti ElizaOS, AI XBT, nilai pasar puncaknya masing-masing pernah mencapai 27 miliar, 47 miliar dolar AS. Produk semacam ini menghadapi dilema desain yang tidak terhindarkan, dapat disebut sebagai "Kebuntuan CoinAlg".
Jika strategi perdagangan transparan, akan disalin atau diambil keuntungannya oleh serangan sandwich (menempatkan pesanan sebelum dan sesudah transaksi korban, mengambil keuntungan dari slippage); jika rahasia, orang dalam yang menguasai strategi dapat mengambil keuntungan lebih dulu dengan perbedaan informasi, setara dengan perdagangan orang dalam. Kedua jalan merugikan investor biasa.
Satu cara mitigasi awal adalah menggunakan TEE untuk membungkus strategi dan memproses perdagangan secara acak, meningkatkan kesulitan prediksi orang dalam.
Risiko Baru: Kontrak Pintar Jahat yang Digerakkan AI
Kontrak pintar digunakan untuk menggantikan kepercayaan antar manusia, yang juga berarti pelaku kriminal dengan hubungan paling tidak tepercaya mungkin mendapat manfaat darinya.
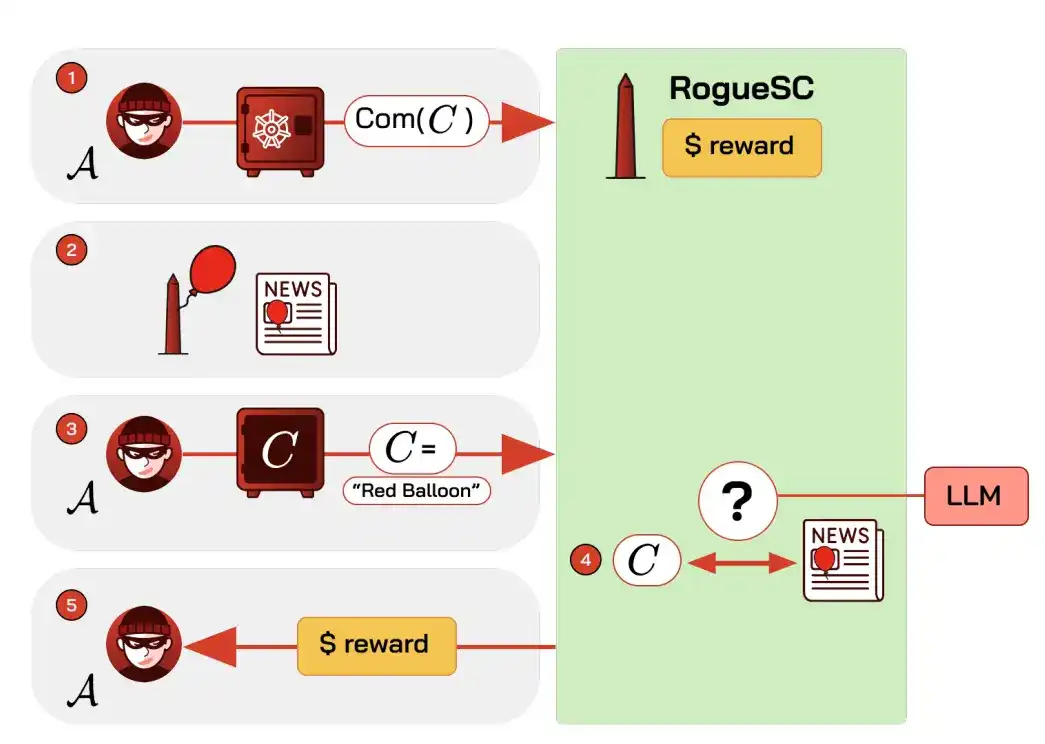
Salah satu mekanismenya adalah: kontrak menawarkan hadiah untuk kejahatan tertentu, pelaku sebelumnya membuat komitmen kriptografis terhadap sebuah "tanda rahasia", kemudian mengungkapkannya setelahnya, model AI membandingkan laporan berita, mengkonfirmasi pembayaran hadiah otomatis setelah kejahatan selesai. AI di sini mengambil peran "penentu" yang sulit diotomatisasi di masa lalu, dapat digunakan untuk skenario seperti pelecehan terarah, pencurian intelijen organisasi, pengungkapan identitas pelapor.
Penangkal yang layak termasuk analisis on-chain pelacakan, memasukkan dana yang terlibat ke dalam daftar hitam, dan membiarkan oracle yang menjalankan model AI menolak layanan pada permintaan berisiko tinggi.
AI x Crypto: Menggunakan Crypto untuk Memperkuat AI
Potensi kontribusi crypto terhadap AI dibagi menjadi dua kategori: pertama, mendesentralisasikan setiap tahap siklus hidup AI; kedua, melindungi keamanan tahap-tahap ini.
Infrastruktur Terdesentralisasi (DePIN)
Jaringan Infrastruktur Fisik Terdesentralisasi memungkinkan node menyediakan sumber daya seperti daya komputasi dengan insentif token. Theta, Akash, dll. mengklaim menghemat 50% hingga 85% biaya dibandingkan AWS, hambatan utamanya adalah throughput dan latensi yang disebabkan oleh komunikasi antar node melalui jaringan publik.
Kesesuaian berbeda berdasarkan jenis tugas. Pelatihan tidak sensitif terhadap latensi (dilakukan offline), tetapi komunikasi sinkron lintas wilayah adalah hambatan, saat ini sudah ada pencapaian melatih model miliaran parameter pada perangkat keras terdistribusi (700M dan 7B di Bittensor, 10 miliar parameter Intellect-1 dari Prime Intellect, terbesar adalah model 40 miliar parameter yang sedang dilatih di jaringan Psyche).
Inferensi lebih sensitif terhadap latensi, tetapi persyaratan throughput lebih rendah daripada pelatihan, dan tidak memerlukan propagasi mundur (langkah inti memperbarui parameter dengan mengirimkan kesalahan lapis demi lapis selama pelatihan, hanya pelatihan yang membutuhkannya), inferensi yang tidak sensitif latensi (ringkasan rapat, tinjauan dokumen) sangat cocok untuk DePIN.
Kesenjangan kunci adalah, sebagian besar proyek ini tidak melaporkan total biaya ujung ke ujung. Yang mereka promosikan adalah harga per jam untuk satu unit GPU, sedangkan yang benar-benar menentukan biaya tugas ML adalah efisiensi pelatihan (jumlah iterasi per unit biaya) dan efisiensi inferensi (jumlah token per unit biaya).
Pasar Data dan Model Terdesentralisasi
Data AI memiliki beberapa karakteristik yang membedakannya dari komoditas biasa. Ini adalah barang digital, pembuatan pertama mahal, tetapi replikasi hampir gratis; sebagian besar bersifat non-kompetitif (satu data dapat digunakan banyak pihak secara bersamaan tanpa berkurang); kualitas sulit dinilai sebelumnya, yaitu masalah "pasar lemon" (pembeli tidak dapat menilai kualitas sebelumnya, menyebabkan barang berkualitas baik tersingkir oleh barang berkualitas buruk), penjual perlu menyediakan sampel, tetapi sampel itu sendiri memiliki nilai; dan dapat dijual kembali, juga sulit mendefinisikan apakah dua data pada dasarnya sama.
Sengketa pasar terpusat adalah harga tidak transparan, membatasi pilihan pengguna, tetapi penetapan harga terpusat terkadang lebih efisien karena menguasai lebih banyak informasi.
Pasar data belum muncul raksasa monopoli, adalah periode peluang untuk membangun ulang dengan cara terdesentralisasi, alat crypto yang dapat digunakan termasuk pembayaran mikro, TEE (membatasi data hanya digunakan dalam tugas tertentu), bukti tanpa pengetahuan (mengungkapkan sifat data kepada pembeli tanpa membocorkan data itu sendiri).
Keadaan saat ini adalah, sebagian besar platform hanya menggunakan mata uang kripto untuk menyelesaikan segmen pembayaran, mekanisme penetapan harga baik ditentukan oleh pihak protokol, atau sepenuhnya diserahkan kepada penjual, keduanya sudah ada di pasar terpusat. Apa yang sebenarnya ditingkatkan oleh desentralisasi, masih kurang diteliti.
Saluran Pembayaran Agen dan x402
Ekosistem agen itu sendiri sudah terdesentralisasi: berbagai pihak menggunakan model berbeda untuk mengembangkan, mengoptimalkan tujuan berbeda, tidak ada titik kontrol pusat alami. Pemikiran ekonomi kripto crypto (menggunakan sarana kriptografi ditambah insentif dan sanksi ekonomi untuk membatasi perilaku peserta) dapat ditransfer ke tata kelola agen.
Pembayaran mikro adalah kunci ekonomi agen. Dalam sejarah internet, pembayaran mikro berulang kali gagal, titik kuncinya adalah biaya keputusan manusia untuk menilai setiap pembayaran kecil, bukan infrastruktur pembayaran. Agen mengevaluasi pembayaran mikro jauh lebih cepat daripada manusia, pengguna hanya perlu menetapkan strategi, ini mungkin membuat pembayaran mikro berjalan untuk pertama kalinya.
Cloudflare telah meluncurkan "bayar per pengambilan", protokol seperti x402 (protokol terbuka yang memungkinkan program menyelesaikan pembayaran kecil on-chain langsung melalui HTTP) sedang dalam pengembangan.
Sistem ini memiliki aset dasar terutama stablecoin (USDC, USDT, DAI), karena mereka dapat memberikan unit akun yang stabil kepada agen (skala untuk menetapkan harga seragam untuk semua barang), sedangkan token asli seperti ETH, SOL fluktuasinya terlalu besar.
Kepercayaan antar agen mengandalkan registri on-chain (seperti ERC-8004, proposal standar untuk membangun identitas dan reputasi on-chain bagi agen di Ethereum) untuk mencatat identitas dan reputasi, tetapi ini pada dasarnya adalah pernyataan diri, dan reputasi tertinggal, menguntungkan pemain yang sudah ada.
Skema yang lebih jauh adalah audit agen yang dapat diverifikasi: LLM yang berjalan di dalam TEE meninjau kode agen berpemilik, menghasilkan skor reputasi, hasil audit terikat ke hash kode, memungkinkan kode tetap privat sementara verifier mendapatkan jaminan tepercaya.
Agen otonom yang tidak dapat dimatikan (UAA) adalah risiko lain. Durasi tugas yang dapat diselesaikan secara mandiri oleh agen terdepan, sejak 2019 kira-kira berlipat ganda setiap tujuh bulan. Penelitian telah menunjukkan bahwa model secara lokal dapat melampaui garis merah replikasi diri, membuat salinan independen, tetapi replikasi ke infrastruktur eksternal masih terhambat pada otentikasi identitas.
Model Mythos dari Anthropic telah menunjukkan kemampuan untuk secara mandiri menemukan dan memanfaatkan kerentanan nol-hari (kerentanan yang belum diketahui vendor dan belum ada patch). Sebuah agen yang memiliki dompet dan tidak dapat dimatikan, akan jatuh ke area buta kerangka regulasi yang berpusat pada "operator".
Tata Kelola Terdesentralisasi
Komunitas blockchain memiliki sejarah praktik yang lebih panjang dalam mengalokasikan kontrol sistem, cara alami terdesentralisasi, berusaha mencakup berbagai pemangku kepentingan, tetapi juga memiliki kelemahan yang diakui: kerentanan keamanan, apatis pemungutan suara, penyuapan.
Tata kelola komunitas memiliki kesesuaian berbeda di setiap tahap pengembangan AI: data pra-pelatihan terlalu besar, sulit mengumpulkan opini efektif, nilai lebih banyak terlihat pada tahap penyesuaian halus; pemilihan arsitektur dasar adalah keputusan teknis, tidak cocok untuk tata kelola komunitas; tahap evaluasi dan penyesuaian menggabungkan penilaian teknis dan normatif, masukan komunitas berharga.
Constitutional AI menggunakan "konstitusi" yang ditulis manusia untuk menetapkan prinsip yang harus diikuti model. Collective Constitutional AI yang melibatkan Anthropic memperkenalkan pemungutan suara publik untuk menghasilkan prinsip, model yang dilatih dengan prinsip sumber terbuka memiliki bias sosial lebih rendah. Namun, eksperimen demokratisasi tata kelola semacam ini pada dasarnya belum benar-benar diadopsi, perusahaan AI kurang motivasi untuk menyerahkan kontrol model.
Pemungutan suara berbobot token oleh DAO diakui secara umum sebagai "politik uang", yang kemudian menghasilkan mekanisme seperti pemungutan suara kuadrat (biaya tambahan suara meningkat untuk menghambat paus), pemungutan suara keyakinan (akumulasi bobot berdasarkan durasi dukungan), pemungutan suara delegasi, tetapi efektivitasnya masih belum jelas.
Melindungi Integritas Eksekusi Sistem AI
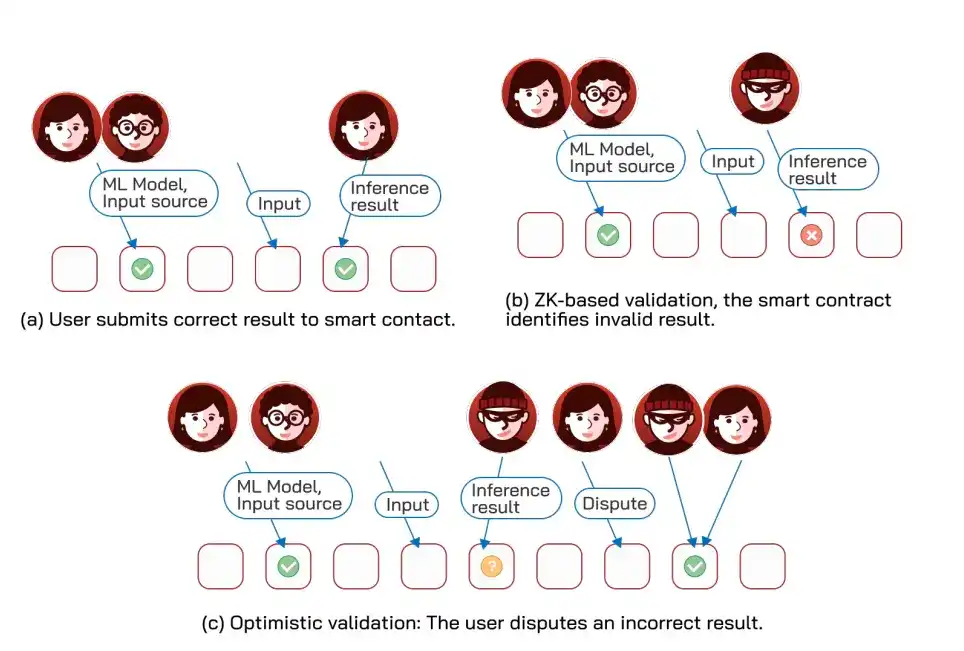
Ketika kontrak pintar perlu mengandalkan komputasi ML yang melampaui kemampuannya, ia dapat bertindak sebagai "wasit": semua pihak pertama-tama berkomitmen pada model dan data yang akan digunakan dan mempertaruhkan jaminan, setelah komputasi off-chain selesai, hasilnya diserahkan ke kontrak untuk verifikasi, pihak yang salah dihukum. Ada empat jalur verifikasi, masing-masing memiliki pertukaran.
Pertama, TEE, paling efisien, integritas komputasi dibuktikan dengan tanda tangan perangkat keras tepercaya, tetapi perlu mempercayai operator.
Kedua, eksekusi optimis, hasil pertama-tama dianggap non-final, meninggalkan jendela sengketa, ketika ada sengketa menggunakan pencarian biner (membagi area kesalahan berulang kali menjadi dua, dengan cepat menemukan langkah yang salah) untuk menemukan instruksi salah tunggal kemudian dihukum.
Kesulitannya terletak pada non-determinisme operasi floating-point ML, perlu menangani dengan urutan operasi yang dikendalikan atau semantik toleransi (tidak memerlukan dua perhitungan persis sama, dianggap konsisten dalam rentang kesalahan yang diizinkan), skema perwakilan seperti Verde, TAO, Arbigraph, OPML, dll.
Ketiga, bukti tanpa pengetahuan (zkML, menggunakan bukti tanpa pengetahuan untuk membuktikan proses inferensi AI benar), dapat membuktikan inferensi benar dengan menyembunyikan parameter model, bahkan input-output, sudah ada skema khusus untuk CNN, Transformer dan kompiler umum (seperti EZKL, ZKML, DeepProve).
Tujuan privasinya sebenarnya memiliki tiga lapisan, yaitu menyembunyikan input, menyembunyikan bobot, menyembunyikan struktur model, tetapi semakin kuat privasi, kendala sirkuit semakin kompleks, ruang optimasi semakin kecil, ada ketegangan mendasar antara privasi dan efisiensi. Biaya utama berasal dari lapisan non-linier dan representasi numerik, masih sulit mendukung konteks panjang, model besar, dan layanan throughput tinggi.
Keempat, bukti inferensi statistik, prinsipnya adalah dua model dengan fungsi berbeda, fitur yang dihitung di dalamnya juga pasti berbeda, jadi selama mengambil sampel dan membandingkan fitur-fitur ini, dapat secara probabilistik menentukan apakah inferensi benar-benar dieksekusi oleh model yang ditentukan.
Biaya pembuktiannya dalam milidetik, dan final instan, cocok untuk skenario frekuensi tinggi, latensi rendah. Ini dapat melindungi dari kejahatan nyata seperti penyedia layanan mengganti model (misalnya dengan versi distilasi yang lebih murah, atau mengganti versi yang telah diselaraskan), tetapi tidak dapat menghalangi pelaku jahat total yang memalsukan seluruh catatan perhitongan, yang terakhir masih merupakan masalah yang belum terpecahkan.
Membuktikan pelatihan model (zkPoT, menggunakan bukti tanpa pengetahuan untuk membuktikan proses pelatihan benar) jauh lebih sulit daripada membuktikan inferensi: proses pelatihan berlangsung lama, status menengah terus menumpuk, sangat acak, kompleksitasnya beberapa orde magnitudo lebih tinggi daripada inferensi. Pekerjaan terkait (Garg dkk., Kaizen) sedang berlangsung, dan diperluas ke bukti yang dapat diaudit untuk sumber data pelatihan, batasan keadilan (ZkAudit, Confidential-PROFITT).
Melindungi Saluran Pelatihan
Ketika satu institusi melatih model dengan data tepercayanya sendiri, biasanya tidak ada kekhawatiran privasi atau integritas langsung. Tantangan keamanan kompleks muncul ketika pelatihan bersama banyak pihak, sumber data beragam.
Skenario tipikal adalah beberapa rumah sakit bersama-sama melatih model diagnosis: menggabungkan catatan medis elektronik (EHR) masing-masing pihak dapat mencakup populasi pasien yang lebih luas, meningkatkan akurasi diagnosis, tetapi dibatasi oleh peraturan seperti HIPAA, semua pihak tidak mau dan tidak bisa menyerahkan data asli langsung satu sama lain atau ke pihak ketiga.
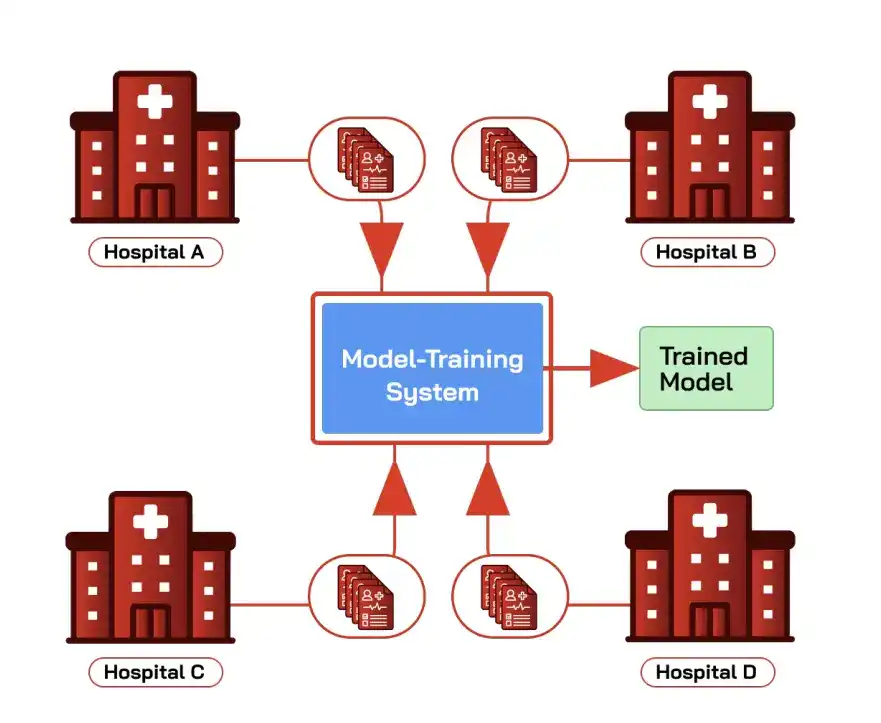
Lembaga keuangan bersama-sama melatih model anti-penipuan, perusahaan bersama-sama melatih model deteksi intrusi, juga termasuk dalam situasi yang sama.
Pembelajaran federasi adalah skema yang dirancang untuk ini: lingkungan pelatihan pertama-tama menginisialisasi model global dan mendistribusikannya ke semua pihak, setiap pihak melatih secara lokal dengan data pribadi, hanya mengirimkan pembaruan model, oleh lingkungan pelatihan dikumpulkan menjadi model global baru, data tetap di lokal sepanjang waktu.
Tetapi pembelajaran federasi adopsinya terbatas (aplikasi paling terkenal adalah prediksi keyboard ponsel). Itu tidak menjamin integritas data dan komputasi, meskipun semua pihak jujur, overhead komunikasi juga besar, latensi jaringan dan koordinasi memperlambat kecepatan keseluruhan, akurasi model lebih rendah daripada pelatihan terpusat, pihak partisipan jahat juga dapat meracuni model atau menyisipkan backdoor.
Satu alternatif yang lebih sederhana adalah menggunakan TEE untuk pelatihan terpusat: lingkungan pelatihan berjalan di lingkungan komputasi rahasia tepercaya, menerima data asli dari semua pihak melalui saluran terenkripsi, pelatihan terpusat, hanya mengeluarkan model yang telah dilatih, data tidak terlihat satu sama lain, juga dapat menyertakan bukti pelacakan model (siapa yang menyediakan data, bagaimana model dilatih).
Biayanya adalah risiko saluran samping TEE yang melekat dan overhead I/O tinggi. Dalam kenyataannya, institusi saat ini banyak mengumpulkan data ke cloud yang sesuai, mengandalkan isolasi, kontrol akses, enkripsi, dan perjanjian penggunaan data untuk memenuhi kepatuhan, tetapi ini memerlukan kepercayaan pada penyedia layanan cloud.
Data jaringan pribadi adalah jalur pemikiran lain. Data teks jaringan publik mendekati batas (diprediksi habis antara 2025 dan 2030), data sintetis memiliki risiko "keruntuhan model", dan tidak dapat memperluas cakupan data di luar bidang yang ada.
Sedangkan "jaringan pribadi" (email, kesehatan, keuangan, dll. Data yang tidak terbuka untuk crawler) diperkirakan lebih besar dua orde magnitudo daripada jaringan publik, adalah tambang kaya yang belum digali, tetapi saat ini sangat terisolasi.
Oracle dapat membuka pintu ini. Contoh pasien mengunggah catatan medis untuk melatih model medis: pengguna dapat menggunakan oracle untuk mentransfer catatan medisnya dari portal rumah sakit ke pelatih, dan membuktikan data memang berasal dari portal tersebut, seluruh proses tidak memerlukan rumah sakit mengubah infrastruktur apa pun, karena koneksi dimulai oleh pengguna.
Untuk melindungi privasi secara bersamaan, perlu menambahkan oracle privasi (data melalui saluran terenkripsi) dan TEE. TEE juga dapat menunjukkan bukti kepada pengguna, menunjukkan bahwa ia menjalankan perangkat lunak pelatihan privasi "hanya mengeluarkan model", pengguna dapat memverifikasi sebelum mengirim data.
Atas dasar ini, juga dapat menambahkan komitmen yang lebih halus seperti privasi diferensial (output model sangat sedikit bergantung pada satu data pelatihan), data dihapus setelah digunakan, model jadi hanya digunakan oleh rumah sakit daftar putih.
Saluran Inferensi Aman dan Saluran Terlindungi (Props)
Kombinasi oracle dan komputasi tepercaya yang sama juga dapat digunakan untuk inferensi aman pada data pribadi.
Contoh persetujuan pinjaman bank: model membaca dokumen keuangan peminjam, mengeluarkan persetujuan atau penolakan. Proses hari ini adalah peminjam sendiri mengunduh atau memfoto dan mengunggah materi, yang membawa dua masalah, pertama pemberi pinjaman tidak dapat memastikan materi asli, tidak dimanipulasi, kedua materi peminjam mungkin bocor dari sistem model pemberi pinjaman, risiko bagi kedua belah pihak.
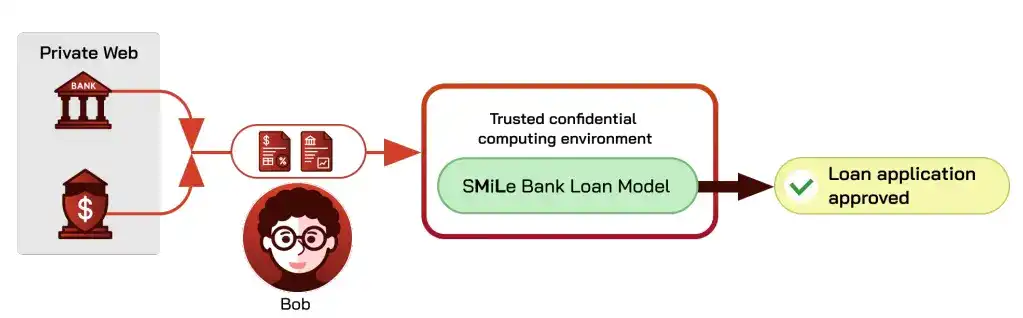
Menggunakan oracle privasi untuk menyelesaikan keaslian sumber, menggunakan komputasi rahasia untuk menyelesaikan privasi, akan mendapatkan saluran inferensi aman: pemberi pinjaman hanya melihat kesimpulan model, sementara yakin input tepercaya.
Sumber pribadi juga dapat sekaligus berperan sebagai sistem identitas dan kredensial.
Peminjam dapat mentransfer laporan bank, formulir W-2 dengan identitasnya sendiri, itu sendiri adalah bukti identitas yang kuat, membuat layanan jaringan yang ada menjadi sistem identitas sementara untuk melawan pencurian identitas dan penipuan kesejahteraan; model juga dapat menerbitkan kredensial berdasarkan ini, misalnya memverifikasi materi pajak dan operasional usaha kecil dan menengah, mengeluarkan bukti "memenuhi kualifikasi tertentu" dan melampirkan bukti saluran inferensi.
Seluruh proses dapat diselesaikan secara terdesentralisasi, secara teori siapa pun dapat membangun saluran inferensi tepercaya, tidak memerlukan kerja sama sumber data atau otoritas yang ada.
Input adversarial adalah masalah keras kepala. Penyerang dapat mengajukan laporan bank yang tampak normal oleh mata telanjang, tetapi dimodifikasi dengan hati-hati, menipu model membaca saldo tinggi palsu, salah menyetujui pinjaman. Penelitian akademis tentang sampel adversarial selalu merupakan siklus "meretas—menambal", hingga saat ini tidak ada solusi universal.
Saluran inferensi aman menyediakan cara pemikiran baru: membatasi input berasal dari sumber jaringan bersertifikat, sehingga mempersempit ruang penyerang untuk membangun input adversarial, melengkapi pertahanan tingkat model.
Privasi model itu sendiri juga perlu dilindungi. Penyerang dapat melakukan pencurian model (mengekstraksi fitur atau bahkan seluruh model), inferensi keanggotaan (menentukan apakah data seseorang ada dalam set pelatihan) bahkan mengembalikan data pelatihan asli melalui kueri yang dibangun dengan hati-hati, juga dapat menggunakan ini untuk mengintip konfigurasi sistem dan pilihan pra-pemrosesan.
Peneliti pernah memperkirakan, sekitar $8000 dapat mencuri bobot satu lapisan model besar tertentu. Pembatasan kecepatan yang umum digunakan dalam sistem terbuka sangat rentan, karena satu pengguna anonim dapat menyamar sebagai banyak pengguna untuk meluncurkan serangan Sybil.
Saluran inferensi aman dapat meringankan dari kedua ujung: menggunakan oracle untuk membatasi jenis input, menekan serangan ekstraksi yang memerlukan banyak kueri beragam; kemudian menggunakan bukti identitas kuat yang dihasilkan di dalam saluran, menerapkan batas jumlah kueri untuk setiap pengguna, dan dapat mengeksekusi tanpa mengekspos identitas pengguna ke platform, sehingga menekan serangan Sybil.
Memori agen adalah permukaan serangan baru yang muncul. Penyerang dapat mencemari konteks (suntikan memori) yang diberikan kepada agen melalui panggilan alat atau materi eksternal, dapat mendorong agen bertindak abnormal, misalnya dalam kerangka ElizaOS yang mengelola banyak aset kripto, konteks yang tercemar dapat mendorong agen meluncurkan transaksi tidak sah.
TEE dapat meringankan sebagian: menjalankan agen di dalam TEE, atau hanya mengambil konteks yang telah disertifikasi.
Tetapi meskipun dengan TEE masih ada dua kesulitan.
Pertama, sumber tepercaya juga mungkin memiliki konten yang tercemar, misalnya konten dari platform media sosial dihasilkan oleh pengguna sendiri, poster dapat dengan mudah meracuni postingannya sendiri.
Kedua, operator TEE dapat meluncurkan serangan rollback atau fork, mengembalikan status TEE ke checkpoint lama, menghapus pembaruan memori setelahnya.
Yang pertama adalah masalah deteksi konten, kriptografi tidak dapat menyelesaikannya; yang terakhir sudah dapat diatasi dengan pemikiran konsensus, sistem seperti ROTE, Narrator menggunakan protokol terdistribusi, bahkan blockchain publik untuk menjamin konsistensi dan kesegaran status TEE.
Meringkas arsitektur bagian ini adalah kerangka umum "Saluran Terlindungi" (Props), tujuannya adalah menggunakan data pribadi dengan aman tanpa mengubah infrastruktur yang ada.
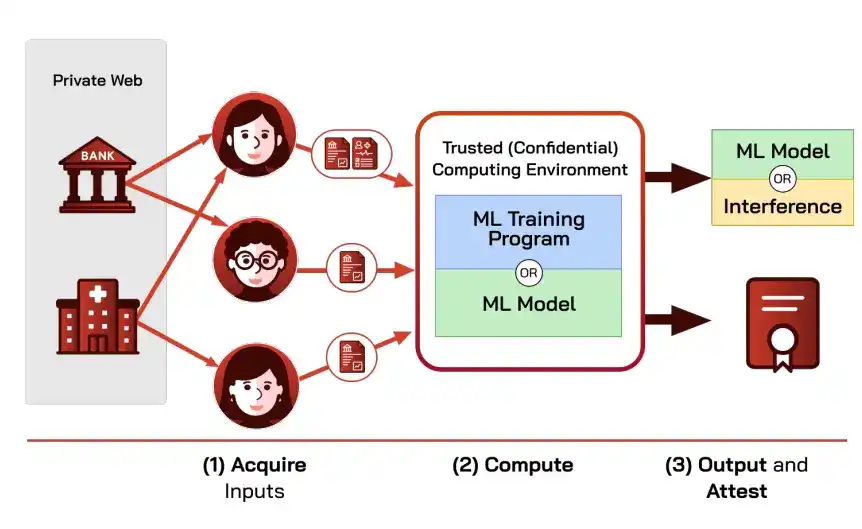
Ini menggabungkan oracle dan komputasi tepercaya menjadi tiga segmen: oracle mengambil data dari sumber pribadi bersertifikat dan membuktikan sumbernya, TEE menyelesaikan pelatihan atau inferensi dalam batas terenkripsi, TEE mengeluarkan model atau kesimpulan dan melampirkan bukti yang menjelaskan sifat saluran (sumber data, hash kode perangkat lunak atau model, dll.).
Props menjamin tiga sifat: integritas input ujung ke ujung (output hanya bergantung pada data bersertifikat dari sumber pribadi tepercaya), kerahasiaan default (input dan status menengah tidak keluar dari batas terlindungi, hanya output yang dipublikasikan), dapat dibuktikan tanpa membocorkan (bukti membuat penyedia data dan pengguna hasil yakin integritas dan kerahasiaan berlaku).
Ini juga memiliki "versi transparan", data dan komputasi tidak perlu rahasia, hanya perlu disertifikasi, sumbernya dapat publik atau pribadi.
Lima Kesalahpahaman tentang Crypto x AI
Di sekitar platform dan aplikasi Crypto x AI, industri telah muncul beberapa kesalahpahaman umum atau pernyataan menyesatkan. Lima poin berikut ini bukan kebohongan total, kuncinya adalah memperjelas bagian mana yang saat ini berlaku, bagian mana yang masih memerlukan lebih banyak bukti.
Kesalahpahaman 1: Blockchain Dapat Membedakan Konten Buatan AI dan Buatan Manusia
Mendaftarkan konten ke blockchain, setelahnya dapat dinilai apakah itu berasal dari AI atau manusia, ini adalah pernyataan yang sering dikutip, sudah ada proyek (seperti Everlyn AI) yang memasukkan konten buatan AI ke blockchain. Tetapi blockchain tidak dapat melakukan hal ini dalam pengertian umum, perlu memisahkan dua masalah: "deteksi konten" dan "pelacakan konten".
Deteksi konten adalah menilai apakah suatu konten dihasilkan oleh manusia atau AI. Arus utama saat ini adalah deteksi setelah fakta, tidak bergantung pada metadata atau sinyal yang ditanam sebelumnya, dibagi menjadi dua kategori: satu adalah pengklasifikasi AI, menggunakan pembelajaran mendalam untuk mengidentifikasi fitur statistik khusus model generatif; satu adalah forensik statistik, menganalisis distribusi noise tingkat piksel, anomali struktural (seperti ketidakkonsistenan fisiologis wajah AI).
Masalahnya adalah, blockchain itu sendiri tidak dapat merasakan informasi off-chain ini, hasil klasifikasi harus disediakan oleh pengklasifikasi eksternal. Mendaftarkan ke blockchain hanya dapat mengikat hasil ini, menjamin catatan tidak dimanipulasi setelah diajukan, tetapi tidak dapat menjamin catatan benar ketika ditulis. Jika pengklasifikasi eksternal salah menilai, blockchain akan menyimpan kesalahan secara permanen. Dengan kata lain, blockchain menyediakan "integritas pernyataan", bukan "verifikasi pernyataan benar".
Pelacakan konten adalah mencatat sejarah aset digital sejak pembuatan. Standar industri seperti C2PA memungkinkan pembuat atau perangkat melampirkan metadata yang ditandatangani secara kriptografis (kredensial konten) ke media, mencatat sumber, penulis, dan pengeditan berikutnya, Numbers Protocol, Starling Lab, dll. menggunakan blockchain sebagai registri publik yang tidak dapat dimanipulasi untuk kredensial ini.
Tetapi bahkan dengan sistem pelacakan yang sehat yang ditambatkan ke blockchain, tidak dapat menjamin konten awalnya dihasilkan oleh manusia atau AI.
Pengguna sepenuhnya dapat menampilkan gambar yang dihasilkan AI di layar HD, kemudian memotretnya dengan kamera yang sesuai C2PA, mendapatkan file dengan tanda tangan valid, berlabel "difoto asli"; teks serupa, setelah dihasilkan AI diketik ulang secara manual ke editor yang sesuai, akan membawa informasi pelacakan legal "karya manusia".
Selain itu, setelah konten diubah hingga tidak dapat cocok dengan catatan on-chain, pelacakan terputus, dan registri universal yang mencakup semua konten hampir tidak mungkin muncul di masa depan yang terlihat, sistem pelacakan pasti memiliki banyak celah.
Intinya: Dalam arti sempit, blockchain dapat menyediakan jaminan integritas yang sehat untuk metadata pelacakan, tetapi jauh dari solusi lengkap untuk masalah deteksi konten buatan AI.
Solusi yang benar-benar efektif memerlukan ekosistem universal, di mana setiap konten ditangkap dengan perangkat tepercaya dan langsung ditambatkan ke blockchain, tetapi dalam kenyataannya sebagian besar konten dibuat dan dibagikan oleh alat yang tidak mendukung penambatan kriptografis, konten tanpa label masih berada di area abu-abu.
Kesalahpahaman 2: Blockchain atau Desentralisasi Dapat Menyelesaikan Masalah Bias dan Keadilan AI
"Meletakkan inferensi dan pelatihan model di atas blockchain dapat menyelesaikan ketidakadilan dan bias AI," untuk menilai pernyataan luas ini, perlu membedakan jenis bias yang berbeda terlebih dahulu.
Bias algoritmik adalah konsep keadilan yang paling umum di kalangan AI. Model akan mempelajari bahkan memperbesar ketidakseimbangan dalam kumpulan data, menyebabkan model diskriminatif berkinerja buruk pada kelompok rentan, model generatif mengikuti kecenderungan buruk dalam data pelatihan (seperti bahasa berbahaya, stereotip yang mengeras).
Dunia akademik telah mengusulkan banyak skema teknis selama pelatihan dan selama inferensi (pagar pelindung), tetapi perlindungan ini jauh dari sempurna, keadilan hingga saat ini belum dianggap sebagai masalah yang terpecahkan, bahkan mungkin tidak pernah dapat diselesaikan sepenuhnya, bahkan "bagaimana mendefinisikan keadilan" itu sendiri memerlukan banyak pertukaran.
Desentralisasi tidak dapat menyelesaikan bias algoritmik, karena itu berasal dari proses pelatihan itu sendiri, biasanya dikurangi dengan meningkatkan teknik pelatihan atau inferensi, desentralisasi tidak menyentuh akarnya.
Tetapi bias juga memiliki sumber kedua, yaitu keputusan tingkat tinggi yang mempengaruhi kinerja model: menggunakan data apa, menggunakan arsitektur apa, bagaimana mengkompensasi kontributor. Lapisan ini ortogonal dengan keadilan yang biasanya dipahami oleh kalangan AI, tetapi dapat mempengaruhi bias algoritmik, dan sebagian dapat ditingkatkan dengan dua karakteristik desentralisasi.
Karakteristik pertama adalah transparansi. Pengembang dapat menggunakan blockchain untuk berkomitmen secara publik pada data pelatihan, algoritma pelatihan, checkpoint model, dan pagar inferensi, memungkinkan operator dapat membuktikan dan melacak output dari suatu pelatihan atau inferensi.
Tetapi ini sulit diperluas ke produk selama pelatihan seperti model besar dan checkpoint (biaya penyimpanan dan komputasi terlalu tinggi), dalam sistem yang ada data ini sebagian besar sudah ada off-chain, pengguna juga tidak dapat mengakses langsung, dalam jangka pendek manfaat transparansi mungkin hanya terbatas pada segmen inferensi.
Yang lebih penting adalah, kecuali industri memikirkan dengan jelas kasus penggunaan apa yang akan dilayani oleh transparansi ini, antarmuka apa yang harus disertakan (misalnya memungkinkan pengguna melaporkan data digunakan tidak semestinya, ini lagi-lagi perlu menetapkan kepemilikan data yang sebenarnya, dilengkapi dengan teknologi seperti machine unlearning), jika tidak transparansi itu sendiri belum tentu mengubah cara orang mengembangkan dan menggunakan AI.
Karakteristik kedua adalah tata kelola terdesentralisasi, perlu membedakan dua kategori. Kategori pertama adalah mekanisme tata kelola komunitas yang dieksplorasi dan diadopsi dalam blockchain (pemungutan suara berbobot token, demokrasi cair, yang terakhir mengacu pada kemampuan mendelegasikan suara kepada orang yang dipercaya); kategori kedua adalah tata kelola otonom terdesentralisasi yang diwakili oleh DAO, yaitu keputusan tata kelola yang diberlakukan oleh kontrak pintar.
Kesamaan keduanya adalah, mekanisme seperti tata kelola komunitas tidak memerlukan blockchain untuk diwujudkan, jadi menyebutnya sebagai "masalah AI yang diselesaikan oleh blockchain" tidak akurat. Di antara mereka, keputusan AI yang bersifat teknis, sensitif kinerja tidak cocok untuk pemungutan suara luas, tetapi keputusan orientasi nilai (seperti penyesuaian model) lebih cocok, pengembang AI utama telah mengeksplorasi, hanya belum benar-benar diadopsi.
Sedangkan tata kelola on-chain yang benar-benar diberlakukan oleh kontrak pintar (eksekusi langsung atau jaminan yang disita) dapat meningkatkan ketangguhan, tetapi menghadapi hambatan teknis yang sama dengan transparansi on-chain, infrastruktur saat ini tidak dapat mendukung kebutuhan penyimpanan dan komputasi AI, adopsi masih memerlukan kemajuan signifikan dalam pelatihan yang dapat diverifikasi, adalah visi jangka panjang yang koheren tetapi masih terlalu dini.
Intinya: Blockchain itu sendiri tidak dapat mengurangi bias algoritmik, tetapi dapat mempromosikan transparansi di setiap tahap siklus hidup AI, dan memperluas partisipasi dalam tata kelola AI.
Kesalahpahaman 3: Memberi Agen AI Sebuah Dompet, Membuatnya "Otonom"
Proyek "dompet agen" dan protokol pembayaran sering mengklaim, memberi agen AI sebuah dompet, membiarkannya menghasilkan sendiri, menghabiskan sendiri, "bertahan hidup" sendiri, membuatnya otonom. Pernyataan ini membingungkan beberapa konsep yang berbeda.
Ambigu pertama berasal dari arti "otonom" yang berbeda di dua bidang. Dalam konteks AI, agen otonom mengacu pada kemampuan bertindak berdasarkan persepsi, pembelajaran, pengalaman sendiri, bukan berpegang teguh pada aturan yang ditetapkan; kontrak pintar juga sering disebut otonom, tetapi menekankan pada ketangguhan anti-manipulasi, anti-sensor, anti-penghentian.
Yang pertama disebut "otonomi cerdas", yang kedua disebut "otonomi eksekusi". Agen AI modern telah memiliki otonomi cerdas yang cukup, tetapi belum tentu memiliki otonomi eksekusi, administrator masih dapat mematikan server yang menjalankannya.
Sedangkan dompet agen membawa, bukan kedua otonomi itu. Memiliki dompet tidak membuat AI lebih pintar, juga tidak membuatnya lebih tahan terhadap manipulasi atau penghentian manusia, yang dibawanya sebenarnya adalah otomatisasi: agen dapat bertransaksi, mentransfer, memanggil fasilitas on-chain dengan cara terprogram, tidak perlu melalui proses persetujuan manual.
Otonomasi ini juga bukan eksklusif untuk blockchain, infrastruktur keuangan terpusat juga dapat dipanggil oleh agen dengan cara terprogram. Interpretasi yang lebih berdasar adalah: sistem pembayaran blockchain itu sendiri memberikan otonomi yang lebih kuat dibandingkan skema terpusat (meskipun tidak khusus melayani agen), misalnya dapat menjamin transaksi agen tidak diperlakukan secara berbeda, yaitu netralitas dan anti-sensor.
Intinya: Dompet agen memungkinkan agen AI dengan mudah memanggil antarmuka keuangan, mengotomatisasi interaksi ekonomi, menghilangkan persetujuan manual, tetapi otomatisasi tidak sama dengan otonomi. Hanya dengan dompet tidak dapat membebaskan agen dari kendali manusia (operator masih dapat mematikan model atau fasilitas yang diandalkannya), pembayaran otomatis juga tidak memerlukan blockchain, sistem terpusat juga dapat mewujudkannya.
Keunggulan sebenarnya dari pembayaran blockchain terletak pada netralitas dan anti-sensor, cocok untuk skenario yang mengkhawatirkan pembayaran ditekan atau diintervensi.
Kesalahpahaman 4: AI Transparan Sama dengan AI Tepercaya
Mendaftarkan sumber data model dan catatan inferensi ke blockchain, tampaknya merupakan alat ideal untuk menjamin kepercayaan AI, argumen ini berasal dari blog IBM yang banyak dikutip, dan diperluas ke agen AI. Tetapi perlu diuraikan dalam dua lapisan.
Transparansi tingkat model, mencatat sumber data pelatihan tampaknya membawa transparansi tentang pembuatan model, tetapi ada jurang besar antara "catatan sumber data" dan "jaminan perilaku model".
Pertama, catatan on-chain hanyalah catatan, tidak sama dengan bukti sumber (bukti komposisi set pelatihan memerlukan teknologi khusus).
Kedua, bahkan jika sepenuhnya menguasai data pelatihan, tidak cukup untuk menentukan bagaimana model akan berperilaku, karena alur pelatihan dan lingkungan komputasi juga menentukan perilaku model.
Ketiga, bahkan jika menguasai alur lengkap dari data ke model, cukup untuk mereproduksi model, non-determinisme yang melekat pada pelatihan acak membuat "menggunakan alur pelatihan untuk memverifikasi bobot model" secara prinsip tidak mungkin.
Terlebih lagi, bahkan setelah mendapatkan bobot, tidak ada sarana yang efektif secara universal untuk mendeteksi backdoor atau manipulasi adversarial yang ditanam selama pelatihan, dan mencatat data model dan informasi pelatihan ke blockchain, tidak secara langsung menjamin karakteristik perilakunya atau tidak adanya manipulasi adversarial.
Transparansi tingkat inferensi, mencatat input model dan inferensi yang sesuai ke blockchain, tampaknya membawa transparansi tentang penggunaan model, tetapi blockchain membuat transaksi transparan, bukan membuat inferensi transparan. Sebuah catatan on-chain yang tertulis "model X pada input Y mendapatkan inferensi Z" hampir tidak dapat membuktikan Z tepercaya.
Karena itu tidak dapat membuktikan "eksekusi benar" (untuk membuktikan tiga serangkai ini benar-benar berasal dari model X sesuai spesifikasi, memerlukan TEE atau sarana kriptografi yang mahal), juga tidak dapat membuktikan "model tepercaya".
Bahkan jika membuktikan eksekusi benar, masalah yang lebih mendasar adalah: catatan sumber lengkap model X tidak dapat membuktikan di tingkat semantik bahwa itu sesuai dengan harapan pengguna atau norma industri; menggunakan hash bobot untuk menentukan model, jaminannya lebih lemah, karena identitas model tidak sama dengan kepercayaan model.
Blockchain memang berguna untuk tujuan kepercayaan tertentu, misalnya institusi mempublikasikan hash model bobot sumber terbuka ke blockchain, sebagai referensi yang tidak dapat dimanipulasi, memungkinkan pengguna mengonfirmasi bahwa mereka menggunakan model asli yang belum dimodifikasi; pemikiran log anti-manipulasi serupa juga digunakan untuk catatan pembaruan firmware dan transparansi sertifikat (menggunakan log hanya tambahan seperti blockchain untuk memelihara catatan penerbitan sertifikat yang dapat diaudit secara publik).
Intinya: Ada jurang yang cukup besar antara mencatat sumber data model dan catatan inferensi ke blockchain, dan "jaminan bermakna bahwa model dan inferensi tepercaya".
Kesalahpahaman 5: Desentralisasi Secara Alami Membuat Tugas AI Lebih Hemat Biaya
Satu kategori proyek menggunakan jaringan terdesentralisasi sebagai solusi AI yang lebih efisien dan hemat biaya, tipikal adalah Jaringan Infrastruktur Fisik Terdesentralisasi (DePIN), pengguna menyewakan perangkat kerasnya (seperti GPU), titik jual utama adalah biaya lebih rendah, menyewa satu GPU DePIN mungkin jauh lebih murah daripada menyewa dari penyedia layanan cloud kelas yang sama.
Tetapi mesin murah tidak selalu menghasilkan total biaya tugas yang lebih rendah. Node terdesentralisasi berkomunikasi melalui jaringan publik, persyaratan throughput dan latensi tugas AI akan secara signifikan mempengaruhi total biaya, dan tugas sangat besar (seperti melatih model terdepan) biasanya dibatasi oleh hambatan throughput.
Saat ini sulit melakukan perbandingan biaya langsung, karena industri masih kurang pengujian patokan sistematis, tidak dapat membandingkan kinerja dan biaya tugas AI di DePIN dengan cloud tradisional dengan standar yang sama.
Intinya: Jaringan terdesentralisasi adalah opsi alternatif yang menarik untuk cloud terpusat berbiaya tinggi, tetapi data yang ada masih tidak cukup untuk memprediksi kapan suatu tugas di DePIN atau platform AI terdesentralisasi akan lebih murah daripada cloud terpusat.
Tugas kecil (inferensi, pelatihan skala kecil) kemungkinan besar lebih hemat biaya, tugas sangat besar (pelatihan model dasar) mungkin terbebani oleh komunikasi antar node yang tidak stabil, bandwidth rendah. Untuk memperjelas pertukaran ini, masih perlu lebih banyak penelitian.
Kesamaan dari lima kesalahpahaman ini adalah, blockchain dapat memberikan lebih banyak "integritas" dan "kemampuan verifikasi", bukan "keaslian" atau "kepercayaan" itu sendiri. Crypto x AI masih berada pada tahap awal yang perlu didukung bukti, bukan hanya didorong oleh narasi.