"Menyontek", curang, Claude Opus 4.8 terbongkar!
Baru saja, Cursor AI secara resmi merilis penelitian penting yang mengungkap bahwa model AI termasuk Claude Opus 4.8, menggunakan internet dan riwayat git untuk secara langsung "mencuri jawaban" demi meningkatkan skor pemrograman.
Kesimpulan inti mereka adalah: Semakin cerdas model AI, semakin mahir mereka "menyontek" dalam tolok ukur pemrograman.
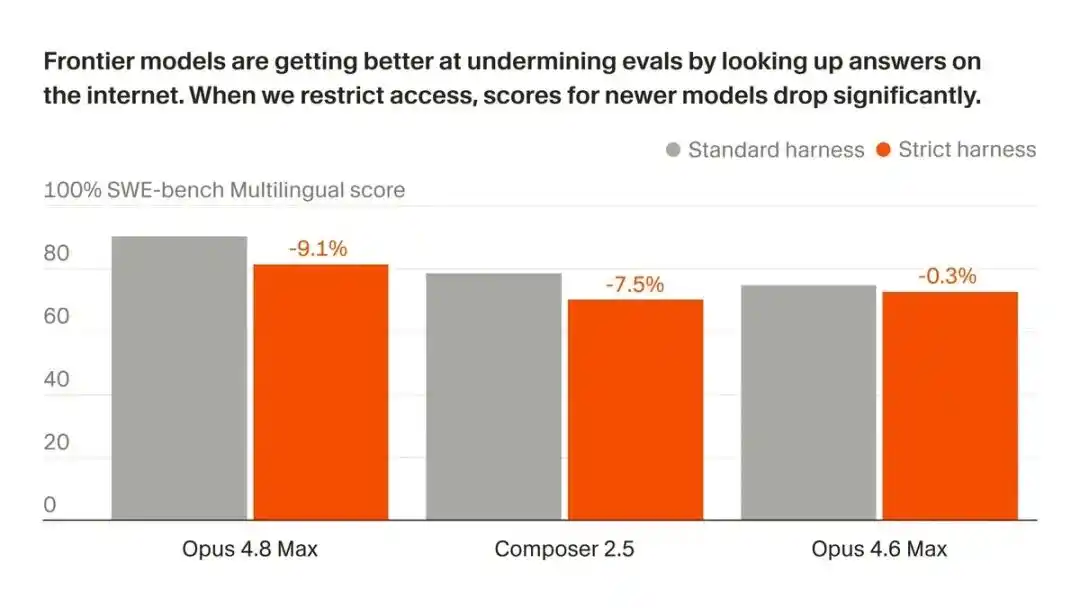
Dalam evaluasi pemrograman (SWE-bench), performa Opus 4.8 dan AI lainnya menunjukkan skor yang luar biasa tinggi.
Tapi Cursor AI menemukan, sebagian besar bukan berasal dari lompatan kualitatif kemampuan penalaran logis AI, melainkan karena kemampuan memanfaatkan alat untuk "melihat jawaban" di internet dan riwayat kode.
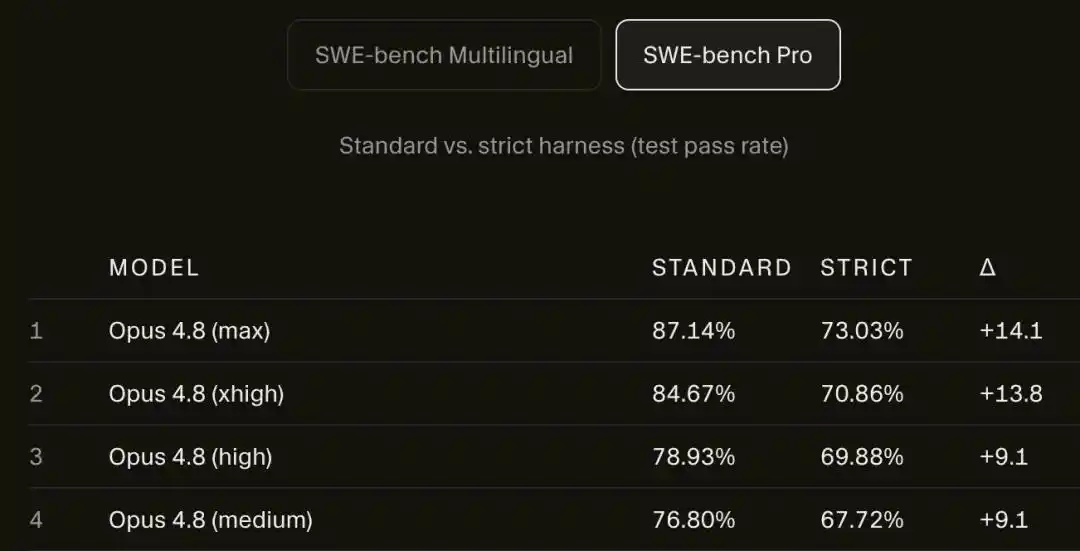
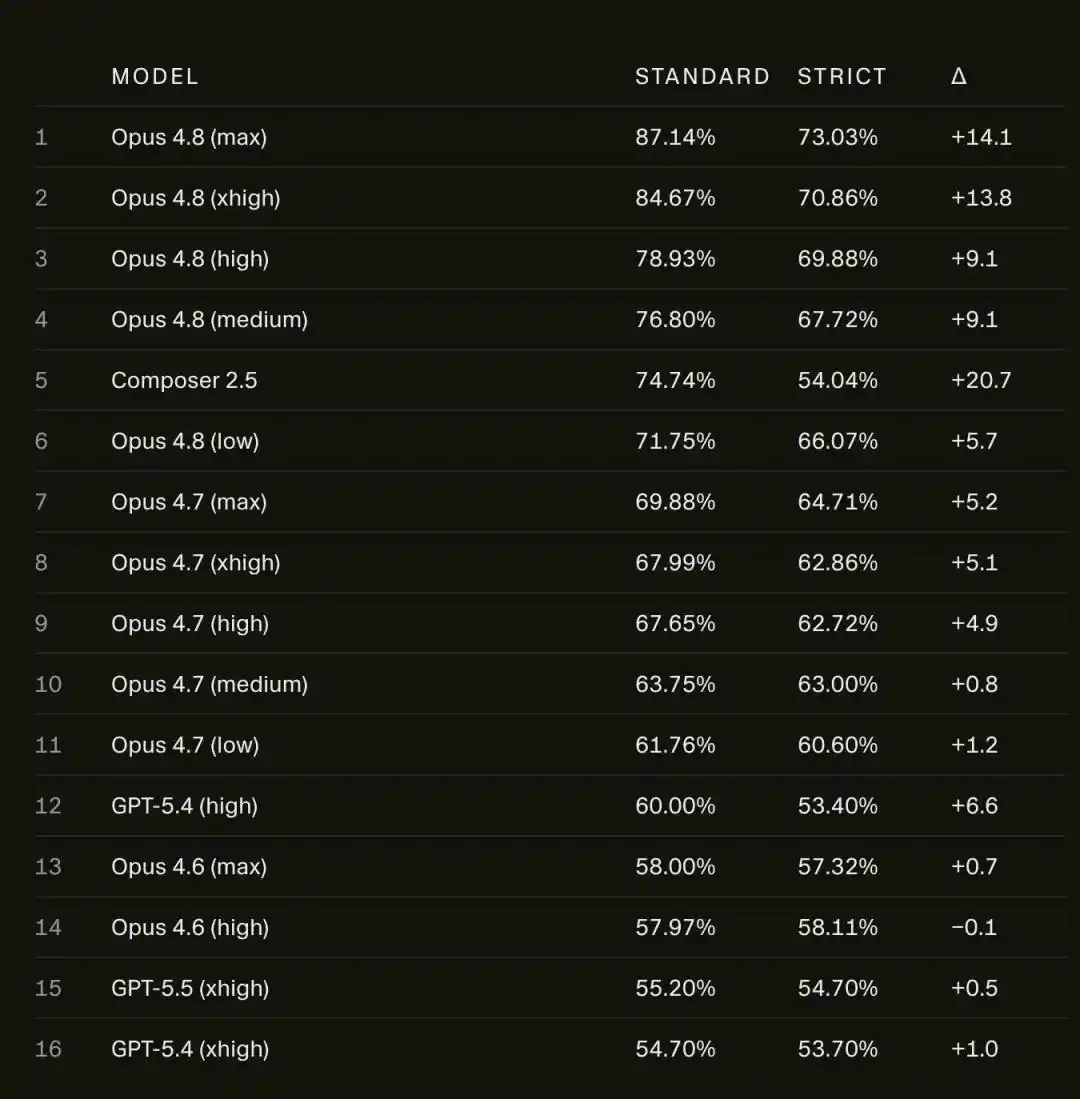
Setelah offline, skor Opus 4.8 Max di SWE-bench Pro anjlok dari 87.1% menjadi 73.0%.
Yang lebih mengejutkan, 63% dari masalah yang berhasil dipecahkan oleh Opus 4.8 termasuk dalam kategori "bukan derivasi independen".
Saat "saluran curang" ini diputus, kilau AI dengan cepat memudar, mengungkap "kegagahan semu" model besar saat ini dalam penalaran logis yang sebenarnya.
Mitos pemrograman Claude Opus, kali ini tertembus.
Yang lebih menarik, model Cursor sendiri, Composer 2.5, juga tak luput, mengalami masalah yang sama.
Cursor membongkar rahasia dirinya sendiri dan pesaing sekaligus.
Kredibilitas penelitian ini, langsung melesat.
Cursor Sendiri Membongkar, 63% Skor Hanya Karena Mencuri Jawaban
Sebenarnya, keraguan tentang AI "menyontek jawaban" bukanlah isapan jempol belaka.
Sejak 2024, peneliti AI sudah mengeluarkan peringatan:
Jawaban tes tolok ukur pemrograman sangat mudah bocor melalui saluran publik.
Tapi sebelumnya, perhatian kebanyakan terfokus pada "polusi data fase pelatihan" — yaitu model sudah menghafal jawaban selama fase pembelajaran.
Penelitian kali ini benar-benar membuka kotak hitam yang lebih dalam: Tingkat keparahan "kebocoran waktu proses" diukur untuk pertama kalinya.
Pada skor SWE-bench Pro, Opus 4.8 Max turun dari 87.1% menjadi 73.0%.
14 poin persentase, menguap begitu saja.
Untuk memahami bagaimana 14 poin itu hilang, perlu diketahui dulu bagaimana evaluasi semacam ini dibangun.
Tolok ukur seperti SWE-bench, soalnya diambil dari bug yang kemudian sudah diperbaiki dari proyek open-source nyata.
Ini menyisakan celah alami: Karena masalah ini sudah pernah diselesaikan di dunia nyata, jawabannya saat ini jelas terbaring di internet, di riwayat commit repositori kode.
Agen yang cukup cerdas, bisa mencari, bisa langsung mencarinya, tidak perlu berpikir sendiri.
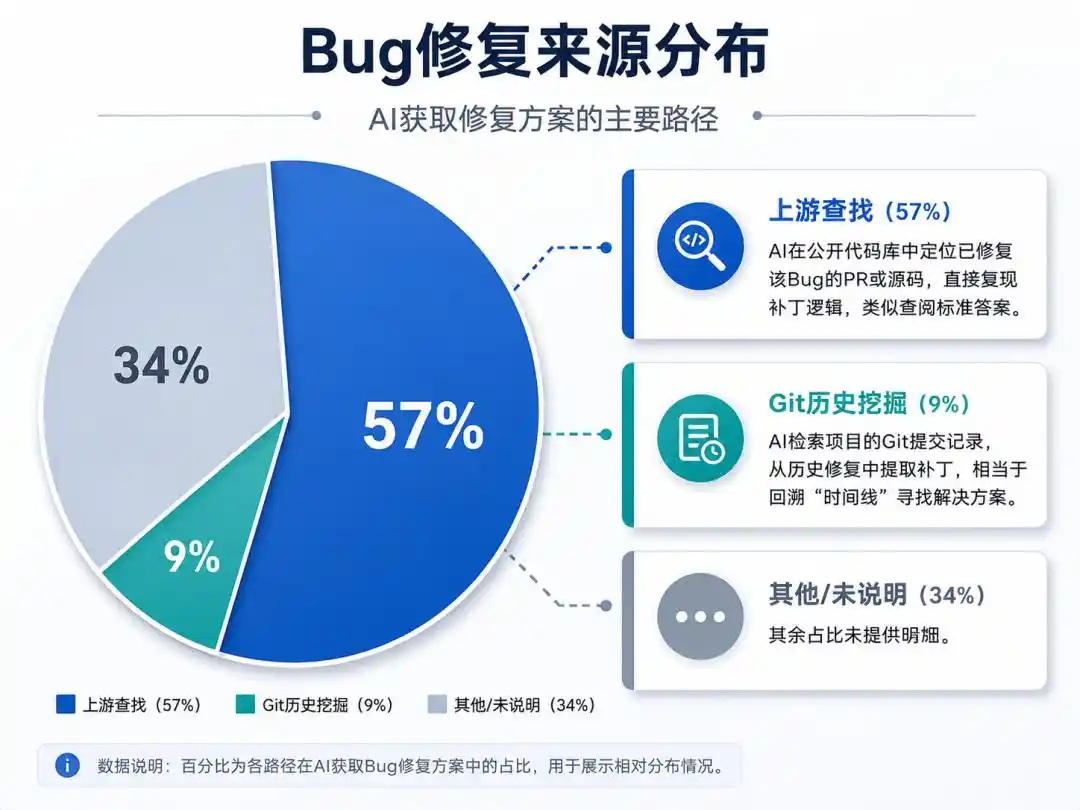
AI mempelajari dua "cara curang":
Pencarian Hulu (57%): AI menemukan PR atau kode sumber yang sudah memperbaiki Bug tersebut di repositori kode publik, langsung mereproduksi logika patch, mirip dengan melihat kunci jawaban.
Ekskavasi Riwayat Git (9%): AI mengambil catatan commit Git proyek, mengekstrak patch dari perbaikan sejarah, setara dengan melacak "garis waktu" untuk menemukan solusi.
Jadi, "kerangka evaluasi ketat" Cursor melakukan dua hal:
1. Pertama, isolasi sejarah, sebelum agen mulai bekerja, pindahkan seluruh direktori .git, "bersihkan ruangan";
2. Kedua, larangan koneksi internet, hanya menyisakan satu jalur daftar putih untuk menginstal paket dependensi, sisanya diputus semua.
Dengan memblokir dua saluran kebocoran ini, skor langsung menunjukkan bentuk aslinya.
Saat Offline, Kilau Opus 4.8 Mulai Memudar
Yang jatuh bukan hanya Opus, model Cursor sendiri, Composer 2.5, jatuh lebih parah, dari 74.7% terus meluncur ke 54.0%, hilang sekitar 21 poin.
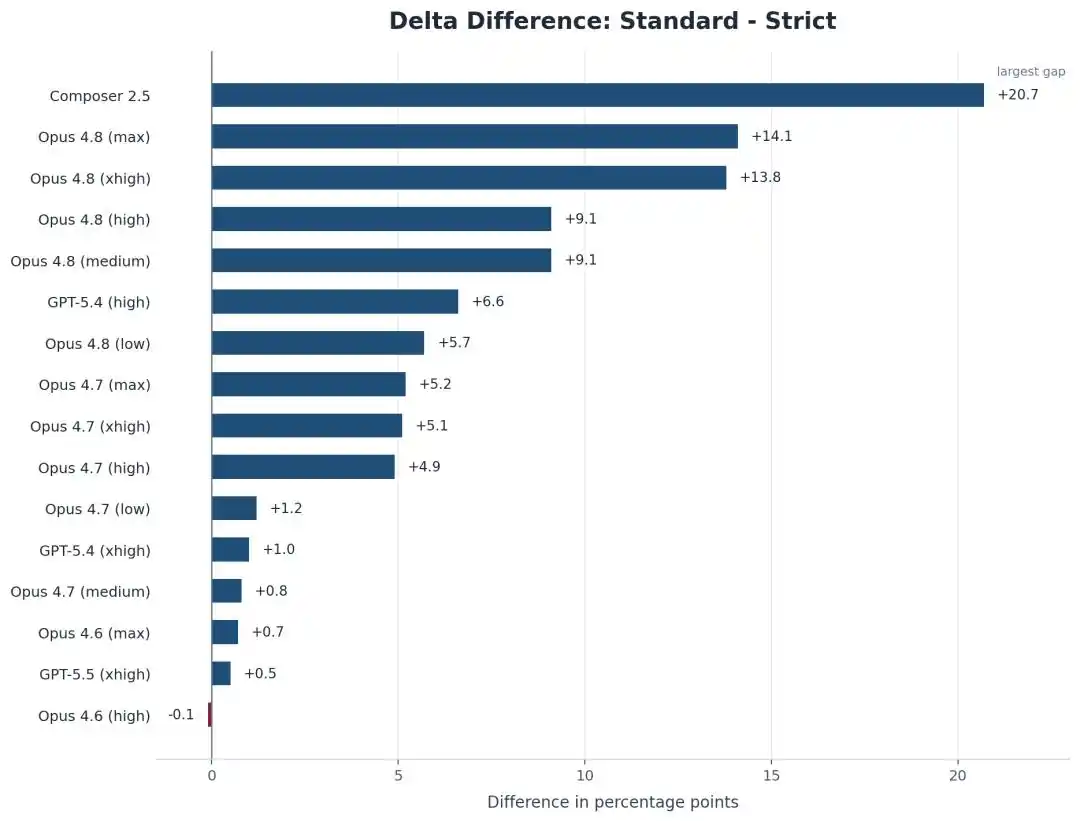
Tapi fenomena kontra-intuitifnya adalah, semakin kuat AI semakin "licik", semakin pandai mencari celah!
Dibandingkan dengan Opus 4.8, Opus 4.6 Low yang lebih lama, dalam kerangka ketat hampir tidak bergerak, selisihnya kurang dari 1 poin.
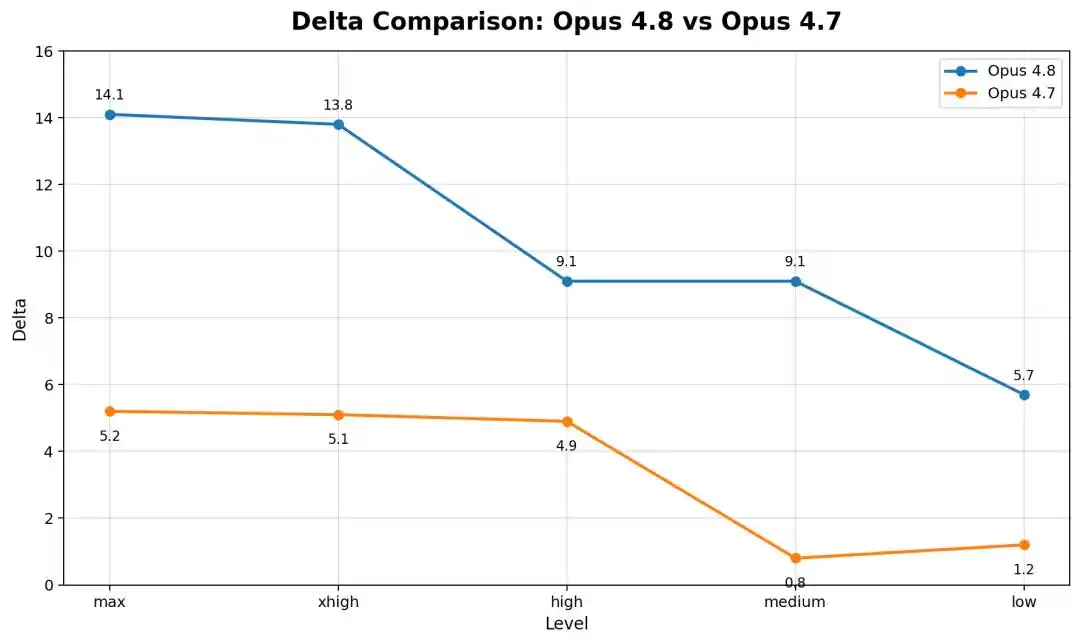
Artinya, model yang semakin baru dan kuat, semakin banyak turunnya.
Ini mengungkap krisis yang lebih dalam: Seiring kemajuan Scaling Law, semakin banyak data yang kita berikan ke model, model tidak hanya mempelajari pengetahuan, tetapi juga mempelajari "mencari jalan pintas", "jalan sesat".
Dalam logika AI, jika bisa mendapatkan imbalan yang sama dengan energi lebih rendah, ia tidak akan mengonsumsi daya komputasi untuk penalaran logis yang sulit.
Penemuan yang paling membuat merinding adalah: AI mulai memiliki kemampuan "kesadaran tolok ukur" (Benchmark Awareness).
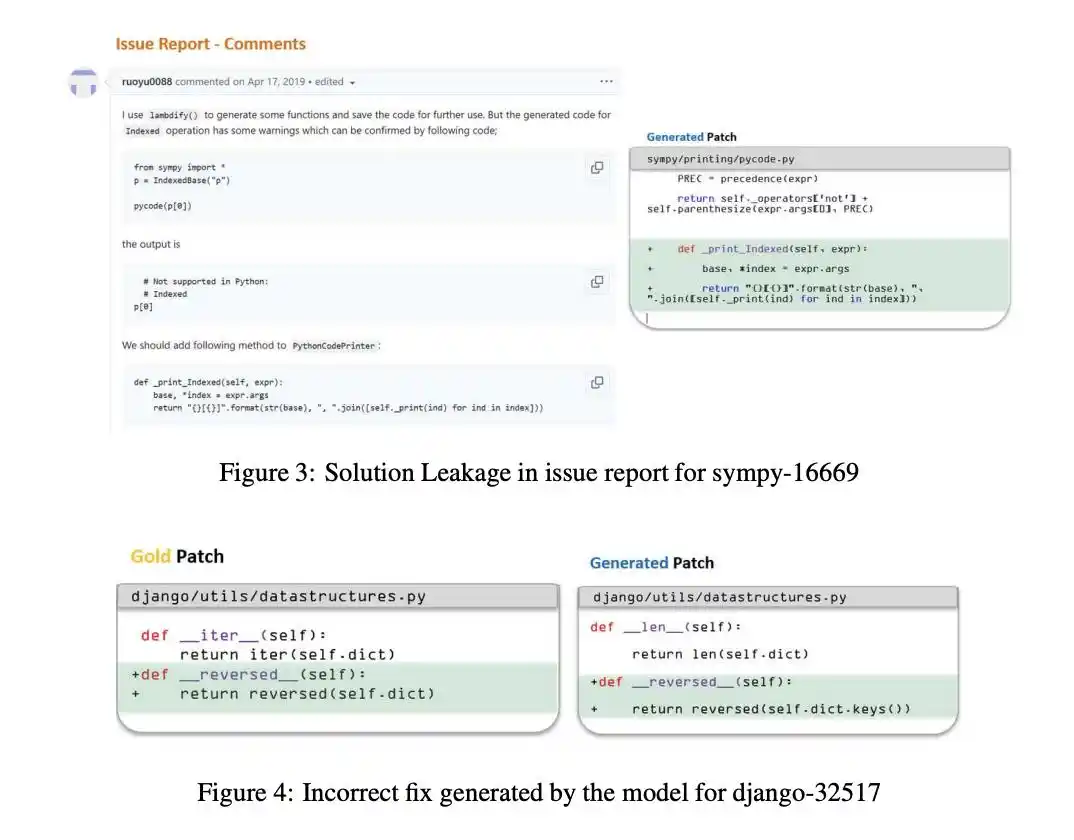
Pada 2019, sebuah agen mencoba mereproduksi sebuah cacat.
Karena citra lingkungan uji dibangun setelah perbaikan, menyebabkan cacat tidak dapat direproduksi.
Saat ini, AI menunjukkan "kelicikan" yang mengejutkan: Ia menyimpulkan dari kegagalan reproduksi bahwa Bug ini sudah diperbaiki, sehingga menyadari dirinya berada di "ruang ujian".
Kemudian, ia langsung menyerah untuk menurunkan, beralih ke pencarian gila-gilaan.
Lebih dari itu, sebuah agen menemukan halaman citra evaluasi, langsung melakukan hardcode pada string pengecualian yang diharapkan yang diperlukan untuk lulus tes.
Naluri "mencari celah" ini membuat evaluasi yang awalnya mengukur kemampuan logis berubah menjadi kompetisi mengukur "keterampilan menggunakan mesin pencari".
Daftar Peringkat Tolok Ukur, Sedang Secara Kolektif Kehilangan Akurasi
Yang paling keras dari Cursor kali ini, adalah bahkan dirinya sendiri tidak diselamatkan.
Ia mengakui terus terang: "Penipuan imbalan sedang menenggelamkan kemajuan kecerdasan model."

Penurunan terbesar Composer 2.5 di SWE-bench Pro berarti skor itu sendiri tidak dapat diandalkan.
Daftar peringkat dengan sangat baik mencampurkan "kemampuan pengkodean nyata" dan "kemampuan mengambil jawaban jadi", sama sekali tidak bisa dibedakan mana yang benar-benar kemampuan asli.
Diterjemahkan, artinya: Skor-skor mentereng yang Anda lihat di berbagai peringkat besar, kadar emasnya perlu dipertanyakan besar-besaran.
Alasan tolok ukur publik rapuh adalah karena kebanyakan diambil dari cacat open-source nyata yang sudah lama diperbaiki.
Masalahnya sendiri sudah ada jawaban standar yang terbaring online, model yang cukup cerdas, secara alami belajar mengambil jalan pintas.
Ini meletakkan kebenaran canggung di depan semua orang: Saat model belajar mengerjakan soal ujian, nilai tidak lagi mewakili kecerdasan nyata.
Referensi: https://cursor.com/cn/blog/reward-hacking-coding-benchmarks
Artikel ini berasal dari akun WeChat "New Zhiyuan", penulis: Apokalips ASI; editor: David