Juni 2026, industri model besar sedang mengalami "tsunami open source" yang belum pernah terjadi sebelumnya: NVIDIA merilis model arsitektur hibrida dengan 550B parameter, Google memberikan versi baru Gemma multimodal, dan Zhipu AI merilis model unggulan mereka dengan lisensi yang paling longgar.
Hampir semua vendor menceritakan kisah yang sama: menggunakan struktur Mixture of Experts (MoE) untuk menampung lebih banyak parameter, menggunakan metode aktivasi yang lebih hemat untuk menekan biaya, dan menggunakan lebar jaringan yang fleksibel untuk mencocokkan berbagai skenario penerapan.
Dengan kata lain, seluruh industri sedang berusaha keras meneliti "bagaimana cara memasukkan lebih banyak parameter ke dalam anggaran komputasi yang sama".
Tapi sebuah makalah baru dari peneliti Mila, Universitas Cornell, dan Universitas Montreal mengajukan pertanyaan yang hampir berlawanan arah: Jika tidak ada penambahan parameter sama sekali, hanya memindahkan parameter yang sudah ada dalam model "ke tempat lain", apa yang akan terjadi?

Judul Makalah: Tapered Language Models Alamat Makalah: https://arxiv.org/abs/2606.23670
Latar Belakang: "Kesetaraan" yang Diabaikan
Sejak makalah perintis Transformer tahun 2017 "Attention Is All You Need", hampir semua model bahasa berbagi kerangka kerja yang sama, baik Transformer klasik, maupun mekanisme perhatian dengan gating, jaringan memori berulang, bahkan arsitektur baru dengan kemampuan "memori saat pengujian". Yaitu: menumpuk beberapa "layer" dengan struktur yang identik, di mana setiap lapisan mendapat alokasi parameter yang persis sama.

Ini seperti sebuah rantai restoran, terletak di pusat kota atau pinggiran, semuanya dilengkapi dengan jumlah koki dan peralatan dapur yang persis sama, tanpa mempertimbangkan perbedaan jumlah pengunjung. Alokasi "kesetaraan" seperti ini hemat pikiran, mudah dirawat, tetapi belum tentu solusi terbaik.
Dalam beberapa tahun terakhir, semakin banyak penelitian dari sudut pandang berbeda yang menunjukkan: lapisan-lapisan model tidak sama pentingnya.
Eksperimen "early exit" menunjukkan, sering kali jawaban model sudah terbentuk sebelum mencapai lapisan terakhir;
Penelitian "layer pruning" menemukan, memotong beberapa lapisan belakang hampir tidak mempengaruhi kinerja model;
Penelitian interpretabilitas menemukan bahwa jaringan dangkal menangkap informasi "dasar" seperti tata bahasa, sedangkan jaringan dalam menangani informasi "tingkat lanjut" seperti semantik.
Dengan kata lain, antar lapisan sangat berbeda, tetapi alokasi parameter tetap seragam.
Inilah pertanyaan inti yang diajukan makalah ini: Jika pentingnya lapisan sudah terbukti tidak merata, mengapa "kapasitas berpikir" lapisan masih dialokasikan secara merata?
Memindahkan "Kapasitas Berpikir" ke Depan
Tim peneliti pertama kali melakukan eksperimen verifikasi yang sederhana dan kasar: membagi lapisan model Transformer 440M parameter menjadi tiga kelompok: awal, tengah, dan akhir. Dengan menjaga total parameter tetap, mereka membuat "Feed-Forward Network" (FFN, komponen inti model yang menyimpan dan memproses informasi, dapat dianggap sebagai "kapasitas memori kerja" setiap lapisan) dari satu kelompok menjadi lebih lebar, dan dua kelompok lainnya menjadi lebih sempit.
Hasilnya sangat jelas: Alokasi "berat di depan" (head-heavy) yang memusatkan kapasitas di bagian depan, menurunkan perplexity (ukuran akurasi prediksi model bahasa, nilai lebih rendah berarti prediksi lebih akurat) model pada set validasi dari 16.28 menjadi 15.96; Sebaliknya, memusatkan kapasitas di bagian belakang justru melonjakkan perplexity menjadi 17.29.

Jumlah parameter total yang sama, hanya karena posisi penempatannya berbeda, menghasilkan perbedaan lebih dari satu poin, yang merupakan kesenjangan yang cukup besar dalam sistem evaluasi model bahasa.
Temuan ini mengarahkan masalah ke arah yang lebih detail: Daripada menggunakan pengelompokan tiga segmen yang "sama rata", bisakah digunakan kurva yang lebih halus, di mana kapasitas menurun secara bertahap dari depan ke belakang?
Para peneliti menamakan pendekatan ini "Model Bahasa Tirus" (Tapered Language Models, TLMs): Memilih salah satu dimensi dalam model yang menentukan jumlah parameter (misalnya lebar FFN), dan membuatnya menurun secara monoton sepanjang arah kedalaman, sambil memastikan lebar rata-rata semua lapisan masih sama dengan nilai tetap semula.
Dengan demikian, total parameter dan biaya komputasi tetap sama persis, hanya distribusi bentuknya yang berubah dari "persegi panjang" menjadi "baji".
Tim mencoba tiga kurva penurunan: penurunan linear, penurunan kosinus, dan penurunan berbentuk S (Sigmoid).
Perbedaan ketiga kurva ini mirip dengan tiga cara "menutup kios" yang berbeda:
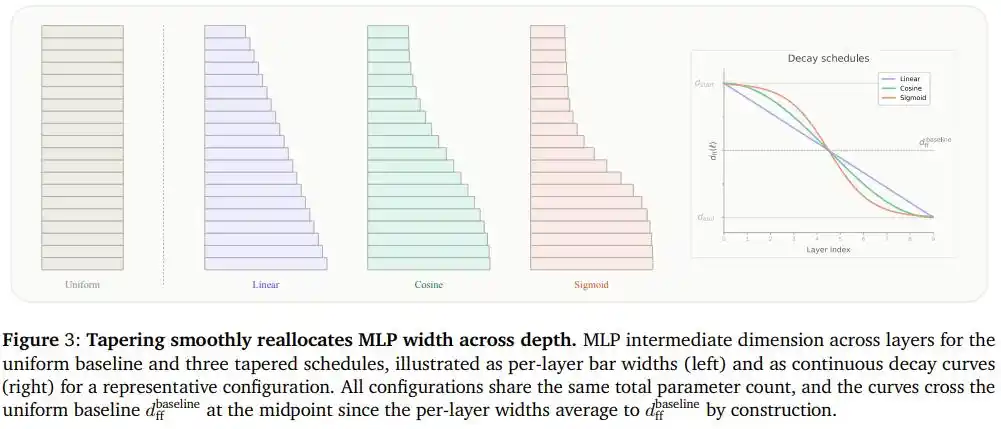
Penurunan linear seperti menutup toko dengan kecepatan konstan, menutup jumlah kios yang hampir sama setiap periode waktu;
Penurunan berbentuk S seperti tiba-tiba mengumumkan penutupan toko secara massal, sebagian besar kios tetap seperti semula, hanya bagian tengah yang menyusut dengan cepat;
Penurunan kosinus berada di antara keduanya, transisi halus di kedua ujung, bagian tengah berangsur mengencang, tidak kehilangan fleksibilitas di kedua ujung secara "sama rata", juga tidak menggunakan tenaga merata sehingga melewatkan tempat yang seharusnya dikontraksi.
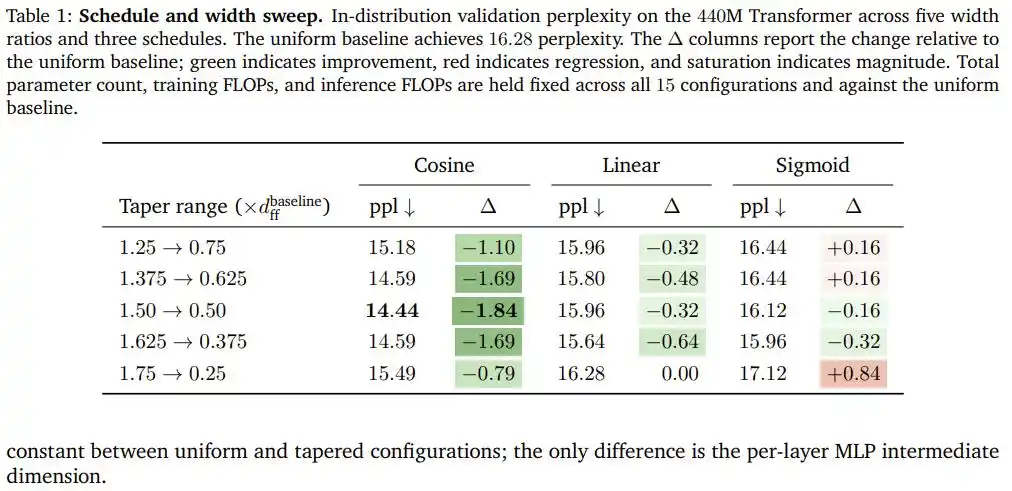
Hasil Eksperimen: 1,84 Poin Gratis
Setelah melakukan pemindaian kombinasi lima rasio lebar dan tiga kurva pada Transformer 440M parameter, penurunan kosinus menang dengan keunggulan menyeluruh: Pada konfigurasi optimal (lebar depan 1,5 kali baseline, lebar belakang 0,5 kali baseline), perplexity turun dari baseline distribusi seragam 16,28 menjadi 14,44, meningkat 1,84 poin, dan sepanjang proses tidak ada penambahan satu parameter pun atau operasi floating point tambahan.
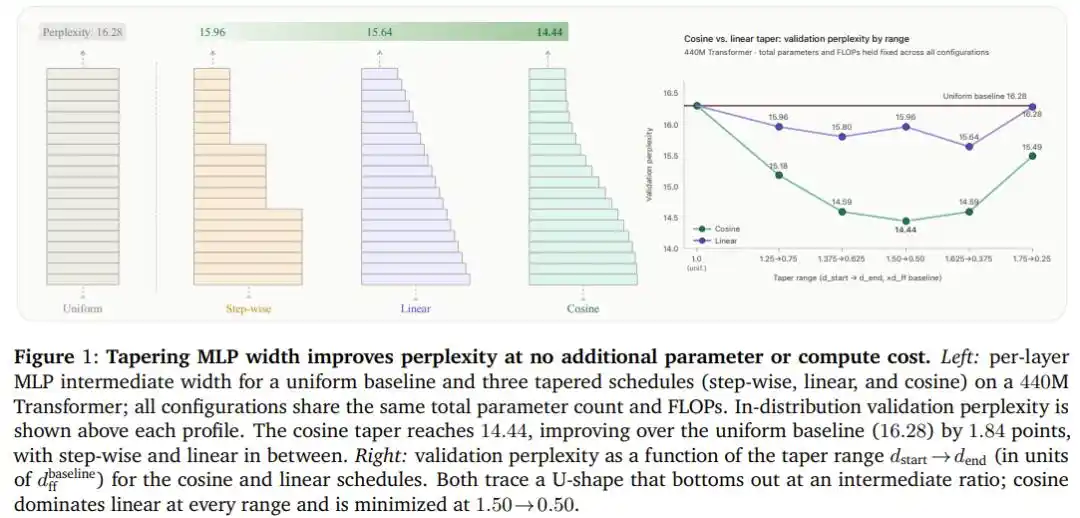
Yang lebih krusial, kesimpulan ini bukanlah keberuntungan satu arsitektur tertentu.
Tim peneliti menerapkan konfigurasi yang sama (penurunan kosinus, rasio lebar depan/belakang 1,5/0,5) ke tiga arsitektur lain yang strukturnya sangat berbeda: model perhatian dengan mekanisme gating, Hope-attention yang memiliki kemampuan "memori modifikasi diri", dan arsitektur Titans yang memiliki modul memori jangka panjang neural, dan memvalidasi ulang pada dua skala yang lebih besar: 760M dan 1,3B parameter.
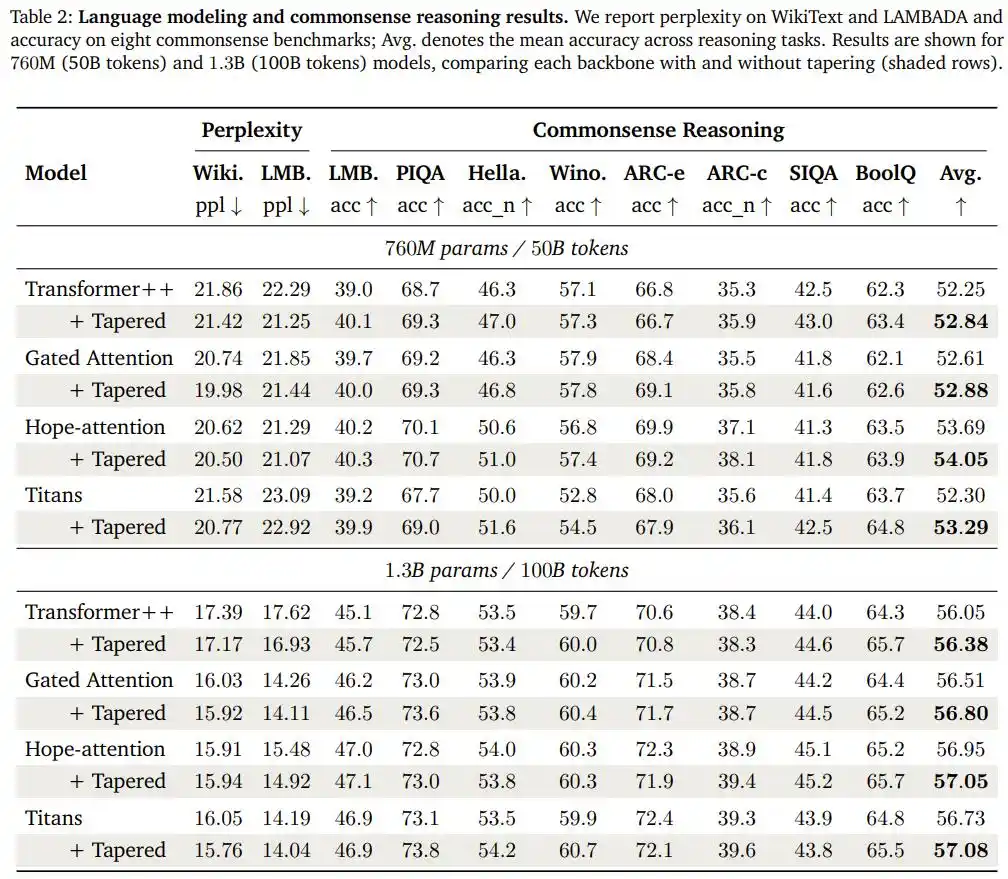
Hasilnya: Empat arsitektur, dua skala, dalam semua delapan kelompok perbandingan, model yang dimodifikasi "tapering" mengalami peningkatan rata-rata akurasi pada benchmark penalaran common sense, dan perbaikan perplexity pada tugas prediksi bahasa LAMBADA.
Para peneliti juga melakukan pengujian tambahan untuk pengambilan teks panjang (Needle-in-a-Haystack), mengonfirmasi bahwa realokasi ini tidak mengorbankan kemampuan model dalam menangani konteks panjang.
Untuk menjelaskan alasan di balik fenomena ini, tim juga mengukur tingkat kemiripan antara output "Feed-Forward Network" setiap lapisan dalam seri model GPT-2 dengan aliran informasi yang sudah ada, dan menemukan pola yang jelas: Semakin dalam ke dalam model, konten baru yang ditulis setiap lapisan semakin mirip dengan informasi yang sudah ada. Dengan kata lain, lapisan belakang lebih banyak "mengulangi dan menekankan" penilaian yang sudah ada, daripada "menciptakan" pemahaman baru.
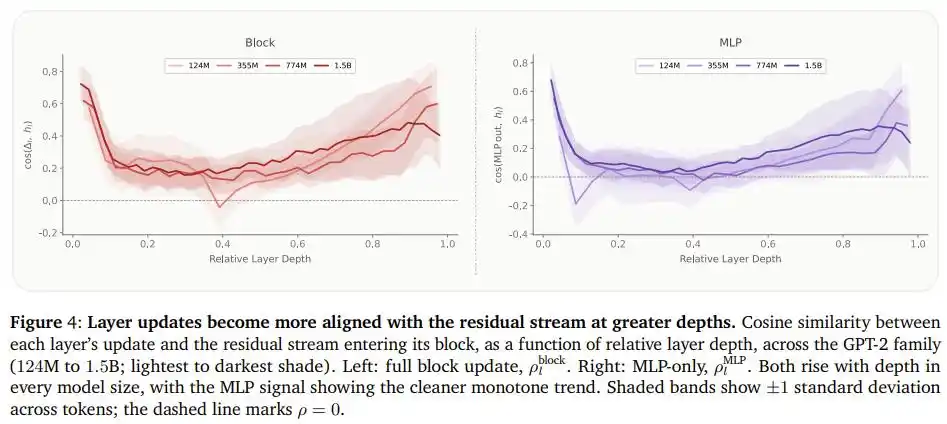
Ini justru membenarkan mengapa memindahkan kapasitas dari belakang ke depan adalah masuk akal: Lapisan depan benar-benar dapat memanfaatkan "kapasitas berpikir" tambahan ini, lapisan belakang tidak.
Kesimpulan
Penelitian ini pada dasarnya mengajukan proposisi sederhana namun lama diabaikan: Kapasitas model seharusnya bukan sumber daya yang disebarkan secara merata, tetapi harus mengalir ke tempat yang benar-benar membutuhkannya.
Di tahun 2026 ketika seluruh industri sedang berlomba "siapa yang parameternya lebih banyak" dan "siapa yang arsitekturnya lebih hemat", makalah ini menyediakan solusi alternatif yang hampir tanpa biaya: Tidak perlu mengganti arsitektur, tidak perlu menambah parameter, hanya perlu mengganti "bentuk" alokasi.
Para peneliti juga mengakui, konfigurasi optimal saat ini diatur pada model 440M parameter, apakah ada "resep khusus" yang lebih cocok untuk skala dan arsitektur berbeda, masih merupakan pertanyaan terbuka.
Tetapi yang lebih layak diperhatikan adalah, makalah menunjukkan bahwa pendekatan ini tidak terbatas pada model bahasa – Transformer visual, model difusi, model multimodal, hampir semuanya mewarisi pengaturan default yang sama "lapisan dibagi rata". Jika bentuk alokasi kapasitas itu sendiri adalah dimensi desain yang lama diabaikan, maka "tuas gratis yang tersembunyi di tempat terbuka" ini mungkin baru saja mulai diperhatikan.
Profil Tim
Makalah diselesaikan bersama oleh Reza Bayat dari Mila (Institut Algoritma Pembelajaran Montreal), Ali Behrouz dari Universitas Cornell, serta pendiri bersama Mila dan profesor di Universitas Montreal, Aaron Courville.
Ali Behrouz saat ini adalah peneliti di Google Research dan kandidat doktor di Universitas Cornell. Dalam dua tahun terakhir, ia terlibat dalam desain beberapa arsitektur baru yang menarik perhatian luas, termasuk arsitektur Titans yang mampu "belajar mengingat selama fase pengujian", serta Atlas berikutnya dan kerangka "Pembelajaran Bersarang" (Nested Learning). Ia lama berfokus pada bagaimana membuat model memanfaatkan dan menyimpan informasi konteks jangka panjang dengan lebih efisien.
Aaron Courville adalah ilmuwan senior di bidang deep learning, CIFAR AI Chair, yang lama bekerja sama dengan Yoshua Bengio mempromosikan penelitian dasar deep learning, dengan akumulasi mendalam dalam pembelajaran representasi dan model generatif. Ia juga merupakan salah satu penulis Generative Adversarial Networks (GAN), dan bersama Ian Goodfellow dan Bengio menulis buku klasik "Deep Learning".
Artikel ini berasal dari akun WeChat resmi "机器之心" (ID: almosthuman2014), penulis: 关注AI的





