Catatan Redaksi: Anthropic merilis Claude Opus 4.8, meraih peringkat pertama pada lima dari enam tolok ukur inti, dengan harga yang tetap tidak berubah; Claude Code menambahkan alur kerja dinamis, dan model tingkat Mythos generasi berikutnya juga telah memasuki ekspektasi pasar.
Dibandingkan sekadar peningkatan kinerja, yang lebih patut diperhatikan dalam rilis ini adalah Anthropic mulai membentuk 'keandalan' sebagai inti penjualan model mutakhir.
Dalam tes kejujuran kode, tingkat kesalahan di mana Opus 4.8 tidak melaporkan kesalahan dirinya sendiri turun drastis; dalam Claude Code, ia dapat mengelola beberapa sub-Agent, dan memasukkan pemeriksaan diri yang bersifat adversarial sebelum hasil diserahkan. Perubahan-perubahan ini bersama-sama mengarah pada masalah nyata: ketika AI berpindah dari jendela obrolan ke alur kerja nyata, yang paling dikhawatirkan pengguna seringkali bukan ketidakmampuan model menyelesaikan tugas, melainkan kemampuannya memberikan jawaban yang tampak lengkap, lancar, dan konsisten bahkan ketika ia keliru.
Oleh karena itu, arti Opus 4.8 tidak hanya sekadar peningkatan model, tetapi juga mengirimkan sinyal industri yang jelas: persaingan model mutakhir sedang beralih dari sekadar mengejar angka benchmark, menuju perebutan keandalan, kemampuan verifikasi, dan kemampuan mengungkap kesalahan. Bagi perusahaan dan pengguna profesional, ambang batas inti AI pada tahap selanjutnya akan semakin bergantung pada apakah model tersebut layak untuk didelegasikan.
Ini juga merupakan prasyarat agar Agent benar-benar dapat digunakan. Model perlu menyelesaikan lebih banyak tugas, dan juga perlu membuat orang berani menyerahkan tugas yang lebih penting dan kompleks kepadanya.
Berikut adalah teks asli:
Hari ini Anthropic merilis Claude Opus 4.8. Dari enam tes benchmark yang tercantum di kartu rilis, ia meraih peringkat pertama pada lima di antaranya.
Perubahan kunci yang paling saya perhatikan adalah: dalam tes kejujuran ringkasan kode Anthropic, Opus 4.7 tidak menandai kesalahannya sendiri dalam 19.7% kasus; sedangkan pada Opus 4.8, proporsi ini turun menjadi 3.7%. Untuk tugas yang sama, kemampuannya mengenali kesalahan dalam pekerjaannya sendiri meningkat sekitar lima kali lipat. Anthropic menyimpulkannya sebagai '4 kali lipat' dalam pengumuman. Bagaimanapun dihitung, inilah kunci yang menentukan apakah Anda dapat menyerahkan pekerjaan nyata ke model ini, lalu pergi dengan tenang, dan ini lebih penting daripada skor benchmark mana pun di kartu rilis.

Apa yang Sebenarnya Dirilis
Pertama versi singkat, lalu masuk ke angka-angka spesifik:
Keandalan benar-benar meningkat. Selain data kejujuran kode yang disebutkan di atas, Opus 4.8 juga merupakan model Claude pertama yang mendapatkan 'nol secara harfiah' dalam dua tes due diligence: ia menurunkan frekuensi 'melaporkan hasil yang cacat secara keliru' dari 0.25 menjadi 0.00, dan menurunkan tingkat kejadian 'penyelidikan yang malas' dari 25% menjadi 0%. Jawaban keliru yang terlalu percaya diri turun sekitar 11 kali lipat. Kecenderungannya untuk memihak pekerjaannya sendiri, yaitu bias yang dapat diukur di 4.7, telah hilang.
Claude Code menambahkan alur kerja dinamis, saat ini dalam versi pratinjau penelitian. Claude sekarang akan menulis skrip pengaturan sendiri, menjadwalkan puluhan hingga ratusan sub-Agent secara paralel dalam satu sesi, dan menjalankan Agen adversarial independen yang mencoba menyangkal hasil tersebut sebelum disajikan kepada Anda. Ini adalah ide 'tim Agent' yang diusulkan di Opus 4.6, yang kini menjadi kemampuan otomatis.
Ia memimpin di kartu rilisnya sendiri, tetapi tidak sepenuhnya memimpin. Menang di lima dari enam tes. GPT-5.5 masih memimpin dalam tugas operasi terminal. Dan di kartu sistem, tersembunyi beberapa kemunduran kejujuran yang tidak ditampilkan Anthropic di slide presentasi, akan dibahas di bawah.
Harga tidak berubah. Masih $5 per juta token input dan $25 per juta token output, sama dengan 4.7. Namun, mode cepat sekarang tiga kali lebih murah dari sebelumnya, meskipun masih termasuk dalam kategori premium, dengan harga $10 / $50.
Mythos akan datang. Anthropic secara eksplisit menyatakan bahwa model tingkat Mythos yang sangat kuat dengan akses terbatas akan datang dalam beberapa minggu ke depan. Opus 4.8 adalah pintu masuk publik menujunya.
Kartu Rilis Resmi: Gambaran Benchmark
Di bawah ini adalah kartu rilis resmi, disajikan dengan skema warna kami.
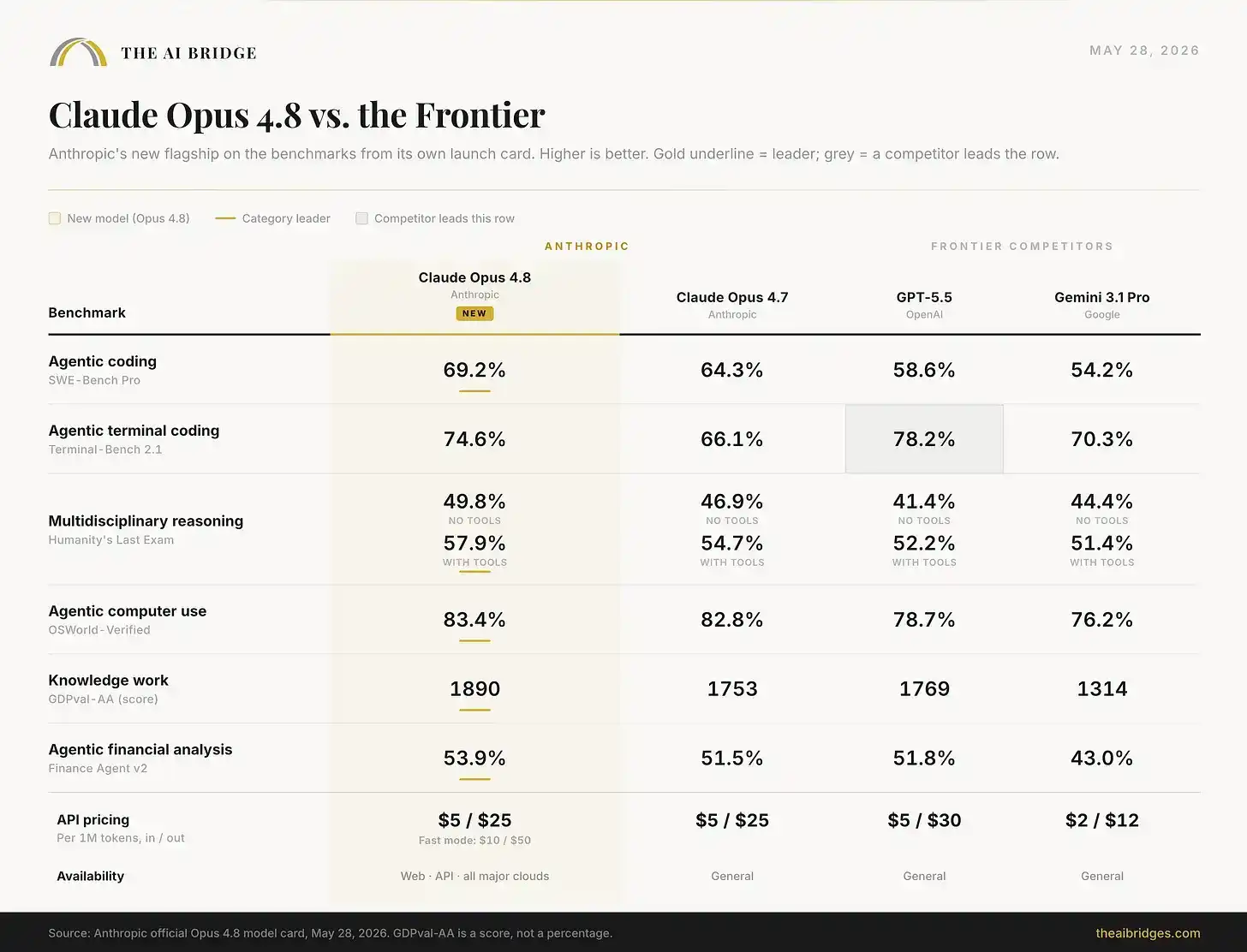
Ada satu tes yang memecahkan sapuan bersih, dan tes ini penting. Pada Terminal-Bench 2.1, yaitu benchmark yang menguji kemampuan model menyelesaikan tugas Agent jarak jauh melalui terminal, GPT-5.5 masih memimpin dengan 78.2% dibandingkan 74.6% Opus 4.8. Anthropic menempatkan kekalahan ini di kartu rilisnya sendiri, alih-alih menyembunyikannya. Pembagian 'Agent vs Pengrajin' yang kami sebutkan saat rilis GPT-5.5 belum sepenuhnya tertutup: GPT-5.5 masih lebih kuat sebagai operator terminal murni, sedangkan Opus 4.8 lebih seperti insinyur yang lebih kuat dalam pekerjaan yang benar-benar diperhatikan pengguna profesional, seperti pengkodean dunia nyata, penalaran ahli, penggunaan komputer, dan pekerjaan pengetahuan.
Di Luar Kartu Rilis
Kartu rilis hanya menunjukkan enam benchmark. Laporan kartu sistem 244 halaman melaporkan lebih dari 40 tes, dan hasil paling menarik tidak ada di slide. Beberapa hal berikut patut dicatat:
Kemampuan matematika meningkat 27 poin persentase. Pada USAMO 2026, yaitu Olimpiade Matematika Amerika yang diadakan Maret lalu, Opus 4.8 meraih 96.7%, sedangkan 4.7 adalah 69.3%. Karena kompetisi ini terjadi setelah waktu potong pelatihan Opus 4.8, tidak ada masalah kontaminasi data. Ini adalah lompatan generasi terbesar di seluruh kartu.
Keunggulan melebar dalam konteks panjang. Dalam satu tes penalaran grafis dengan satu juta token, Opus 4.8 mencetak 68.1, sedangkan 4.7 adalah 40.3, dan GPT-5.5 adalah 45.4. Semakin panjang konteks dan semakin sulit tugasnya, semakin jelas margin keunggulannya.
Multi-Agent-lah tempat ia benar-benar mencapai puncak. Agent tunggal Opus 4.8 tertinggal dari Gemini dalam tugas penelitian web, masing-masing 84.3 dan 85.9. Namun, jika sebuah pengatur menjadwalkan sekelompok sub-Agent, skornya dapat mencapai 88.5%, menjadi skor tertinggi yang dilaporkan; tim lima Agent bahkan dapat mencapai kinerja terbaik Agent tunggal dalam seperlima waktu. Inilah wujud kemampuan alur kerja dinamis dalam tes benchmark.
Efisiensi token mengalami perubahan kualitatif. Dalam tes pengkodean tersulit, Opus 4.8, dengan pengaturan upaya terendah, dapat mencapai kinerja Opus 4.7 dengan pengaturan upaya tertinggi. Artinya, Anda bisa mendapatkan kinerja puncak sebelumnya dengan biaya token yang lebih sedikit.
Ia melampaui ambang batas yang sebelumnya tidak dilampaui model mana pun. Pada Harvey's Legal Agent Benchmark, suatu tugas dianggap berhasil hanya jika setiap kriteria penilaian dalam tugas tersebut sepenuhnya lulus. Opus 4.8 adalah model pertama yang menduduki peringkat pertama dalam standar 'lulus semua' ini. Ia lulus 89% dari kriteria individual, tetapi tingkat kelulusan tugas lengkap hanya 9.6%, yang juga menunjukkan betapa ketatnya persyaratan pekerjaan hukum nyata.
Ada juga kemunduran yang disajikan dengan jujur. Tiga hal memang lebih buruk daripada 4.7, dan Anthropic mengakuinya dalam kartu sistem. GPQA Diamond, yaitu tes sains ahli, turun dari 94.2 ke 93.6. Kemampuan untuk menolak menjawab dalam skenario penggunaan komputer dan kemampuan menahan injeksi prompt mengalami kemunduran, sehingga 4.8 lebih mudah dimanipulasi dalam skenario Agent. Selain itu, dalam simulasi bisnis selama satu tahun, sisa uang tunainya hanya sepertiga dari 4.7. Ini tidak muncul di kartu rilis, dan justru karena itulah, lebih pantas untuk disebutkan.
Dibandingkan dengan Model Berat Sumber Terbuka, Di Mana Posisinya
Kartu rilis hanya membandingkan Opus 4.8 dengan model mutakhir sumber tertutup lainnya. Jika memperluas pandangan ke model berat sumber terbuka murah yang sedang diuji banyak tim saat ini, gambaran tersebut hampir merupakan cerminan industri AI tahun 2026: Opus 4.8 memimpin dalam kemampuan, tetapi kesenjangannya dengan model sumber terbuka gratis yang dapat di-hosting sendiri hanya tersisa beberapa poin persentase, sementara perbedaan harganya sangat besar.
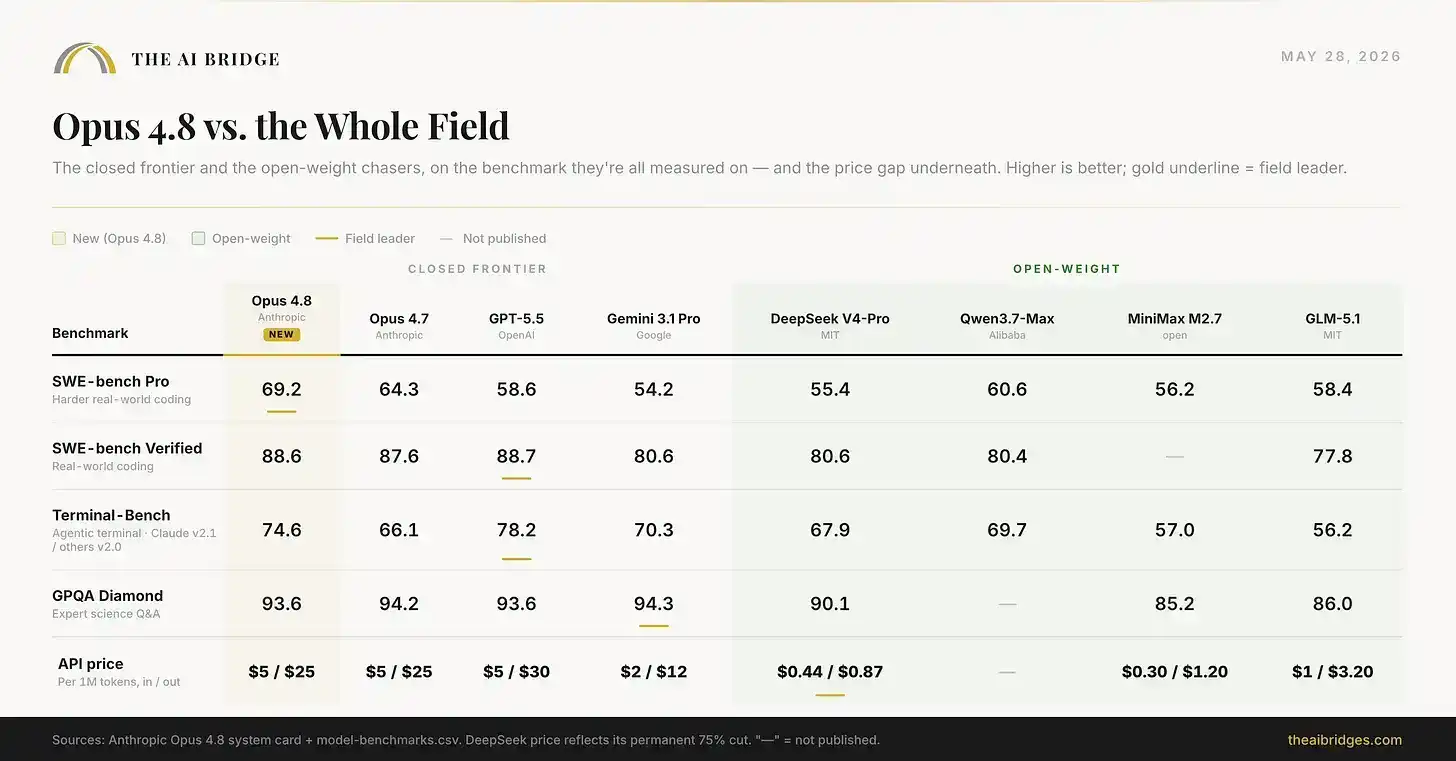
Grafik di atas mencakup perbandingan lengkap delapan model. Harga DeepSeek mencerminkan penurunan harga permanen 75%; harga Qwen Max belum diumumkan.
Opus 4.8 langsung menang dalam benchmark pengkodean. Tetapi Qwen3.7-Max, model sumber terbuka yang dapat Anda jalankan sendiri, mencetak 60.6, hanya tertinggal sekitar 9 poin. DeepSeek V4-Pro mencetak 55.4, dengan harga outputnya sekitar sepertiga puluh dari Opus. Untuk tugas rekayasa berisiko tertinggi, perbedaan $25 per juta token output layak dibayar. Untuk banyak pekerjaan sehari-hari, perbedaan ini semakin tidak sepadan. Dan inilah perhitungan yang sekarang dilakukan setiap tim serius.
Apa Artinya Ini bagi Anda
Jika Anda sedang menggunakan Opus 4.7, maka ini adalah peningkatan gratis. Harga tidak berubah, data lebih baik, penilaian atas outputnya sendiri juga jelas lebih andal. Beralih saja.
Pertanyaan yang lebih menarik adalah: pekerjaan apa yang sekarang Anda bersedia serahkan kepadanya? Setiap pembaca memiliki garis batas dalam pikiran, memisahkan 'tugas yang bisa saya serahkan ke AI' dan 'tugas yang harus saya lakukan sendiri, karena saya belum bisa mempercayakan penyerahannya'. Peningkatan keandalan 4.8 berarti Anda dapat mendorong garis ini selangkah ke depan. Model lebih ahli menandai ketidakpastiannya sendiri, ini mengurangi biaya 'penyerahan kesalahan diam-diam', dan memperluas rentang tugas yang layak didelegasikan ke model. Inilah arti data kejujuran dalam penggunaan praktis, lebih penting daripada skor individu mana pun.
Ini juga sesuai dengan yang kami tulis pekan lalu. Studi Kefasihan AI Anthropic sendiri menemukan bahwa ketika keluaran model terlihat sangat rapi dan lengkap, orang akan jauh lebih sulit memperhatikan konteks yang hilang. Jawabannya tampak sudah selesai, jadi kami berhenti memeriksa. Opus 4.8 menyerang mode kegagalan ini dari sisi model: ia lebih ahli memberi tahu Anda di mana kelemahan mungkin masih ada dalam jawaban yang tampak bersih dan lengkap. Ia tidak dapat menggantikan penilaian Anda, tetapi ia dapat memberikan pegangan untuk penilaian Anda.
Jika Anda menggunakan Claude Code, cobalah alur kerja dinamis minggu ini dengan tugas besar yang benar-benar nyata, seperti migrasi satu kali, atau pemeriksaan komprehensif sejumlah besar file, sambil memperhatikan penghitung token. Kemampuan ini nyata, dan pemeriksaan diri yang bersifat adversarial juga kunci untuk membuat output lebih terpercaya. Namun, biayanya juga nyata. Ini adalah alat yang disiapkan untuk tugas besar yang sulit diselesaikan oleh Agent tunggal, dan tidak seharusnya menjadi opsi default harian Anda.
Selanjutnya: Mythos, Akan Datang dalam Beberapa Minggu
Pernyataan paling visioner dalam rilis ini sebenarnya tidak tentang 4.8. Anthropic menyatakan bahwa model tingkat Mythos akan datang dalam beberapa minggu ke depan, dan memposisikan Opus 4.8 sebagai langkah publik menujunya.
Anda perlu memahami apa artinya ini. Mythos adalah model mutakhir terbatas yang terus-menerus diuji benchmark di internal Anthropic, melampaui Opus 4.8 yang telah dirilis di hampir semua metrik: mencapai 93.9% pada SWE-bench Verified; dalam tes keamanan siber, ia dapat menghasilkan eksploitasi kerentanan yang dapat dijalankan untuk sebagian besar target di browser saat ini, sedangkan tingkat keberhasilan Opus 4.8 kurang dari 10%. Sebelumnya, Mythos hanya terbuka untuk sekitar 52 lembaga yang diaudit, dengan harga lima kali lipat dari Opus standar, diperlakukan sebagai infrastruktur, bukan produk biasa.
Oleh karena itu, ketika model tingkat Mythos yang lebih kuat diluncurkan dalam beberapa minggu ke depan, pahami dengan kerangka 'dua jenis pasar': satu adalah lapisan komoditas, yaitu Opus 4.8, terbuka luas, harga tetap, semakin dikejar oleh model sumber terbuka gratis; yang lain adalah lapisan mutakhir terkendali, yaitu Mythos, mahal, akses terbatas. Keduanya bukanlah produk yang terpisah, tetapi tingkat berbeda dalam garis kemampuan kontinu yang sama. Pekerjaan keandalan dalam 4.8 adalah hal yang harus Anda bangun sebelum tujuan sebenarnya 'menjalankan model dengan pengawasan lebih sedikit'. Dan tujuan itu sekarang bukan berjarak beberapa kuartal dari kita, tetapi beberapa minggu.
Latar Belakang: Bagaimana Garis Ini Sampai di Sini
Jika Anda sudah kehilangan irama empat bulan terakhir, pahami seperti ini: Opus 4.6 pada Februari membawa tim Agent, Sonnet 4.6 membawa keruntuhan harga, Opus 4.7 pada April membawa lompatan penalaran, dan Mythos adalah langit-langit terbatas yang samar-samar terlihat di samping. Opus 4.8 menyambungkan dua petunjuk ini: ia melanjutkan narasi pengaturan dari 4.6, sekaligus menjadi pintu masuk menuju Mythos.
Ritme rilis ini sendiri adalah fakta kunci yang tersembunyi di bawah semua perubahan permukaan. Model unggulan bergerak dari 4.5, 4.6, 4.7 ke 4.8 dalam beberapa bulan, dan model yang Anda adopsi untuk standardisasi tim hari ini, mungkin pada musim gugur bukan lagi model yang sebenarnya Anda jalankan. Inilah mengapa, daripada berinvestasi dalam keterampilan penggunaan model tertentu, lebih baik berinvestasi pada kemampuan yang dapat ditransfer lintas model, seperti pendelegasian yang jelas dan verifikasi yang ketat.
Sapuan bersih dalam benchmark akan mendapatkan penyebaran tangkapan layar. Tetapi tempat yang benar-benar berubah lebih kecil, dan lebih penting: ini adalah versi Claude pertama yang inti penjualannya bukan lagi sekadar 'lebih pintar', tetapi 'Anda dapat mempercayakan lebih banyak hal padanya'. Sebelum Agent benar-benar menjadi berguna, seluruh industri harus bergerak ke arah ini; dan bagian kemampuan ini, juga paling sulit dimasukkan ke dalam sebuah grafik.
Di mana garis batas Anda sekarang? Pekerjaan apa yang Anda berserah serahkan ke model, dan apa yang masih harus Anda lakukan sendiri? Dan apa yang perlu terjadi, agar Anda bersedia mendorong garis ini selangkah lagi ke depan?





