Oleh | Sun Yongjie
Memasuki tahun 2026, jendela peluncuran DeepSeek V4 berulang kali ditunda, namun justru secara tak terduga memicu diskusi global di kalangan AI tentang "de-CUDA-fikasi". Dari pemberitaan berbagai media, model open-source multimodal yang diperkirakan memiliki skala parameter triliunan dan mendukung konteks token hingga jutaan ini, sedang berusaha keras untuk beradaptasi dengan chip Ascend milik Huawei, serta menulis ulang kode intinya melalui framework CANN.
Jika hal ini akhirnya menjadi kenyataan, ini akan menjadi pertama kalinya sistem AI China secara sistematis mengeksplorasi kemungkinan membawa kemampuan model inti pada platform non-CUDA dalam lingkungan produksi nyata. Dengan kata lain, ini bukan hanya peluncuran sebuah model, tetapi lebih seperti "uji tekanan" terhadap jalur teknologi dasar.
Namun, seperti ditekankan oleh pendiri DeepSeek, Liang Wenfeng, dalam komunikasi internal, ini hanyalah "langkah pertama dari perjalanan sepuluh ribu li". Risiko dan peluang ada di masa depan, keseimbangan, bahkan pilihan, antara kompatibilitas dan kemandirian, akan menentukan apakah AI China benar-benar dapat menemukan jalur perkembangan sendiri.
Penundaan DeepSeek V4, Biaya Pasti dari Konversi Platform Komputasi AI Dasar
Seperti disebutkan sebelumnya, V4 yang rencananya dirilis pada Tahun Baru Imlek atau Februari-Maret tahun ini, berulang kali melewatkan jendela peluncuran, hingga awal April media terkait mengonfirmasi "akan dirilis dalam beberapa minggu". Alasan utamanya adalah adaptasi mendalam antara sisi inferensi dan penggunaan chip Ascend Huawei. Namun masalahnya, jalur ini jauh lebih rumit dari yang dibayangkan. Untuk memahami kompleksitas ini, pertama-tama kita perlu kembali ke karakteristik teknis DeepSeek V4 itu sendiri.
Seperti diketahui, memasuki tahun 2026, skala parameter model besar telah melampaui ambang batas "triliunan", menuju level puluhan triliun. Dalam konteks ini, meskipun V4 menggunakan arsitektur MoE (Mixture of Experts) yang lebih agresif, yang secara teoritis mengurangi beban komputasi inferensi tunggal dengan "mengaktivasi pakar sesuai kebutuhan", imbalannya adalah tuntutan yang lebih ekstrem terhadap kemampuan sistem termasuk bandwidth memori, interkoneksi antar chip (Interconnect), serta manajemen KV Cache.
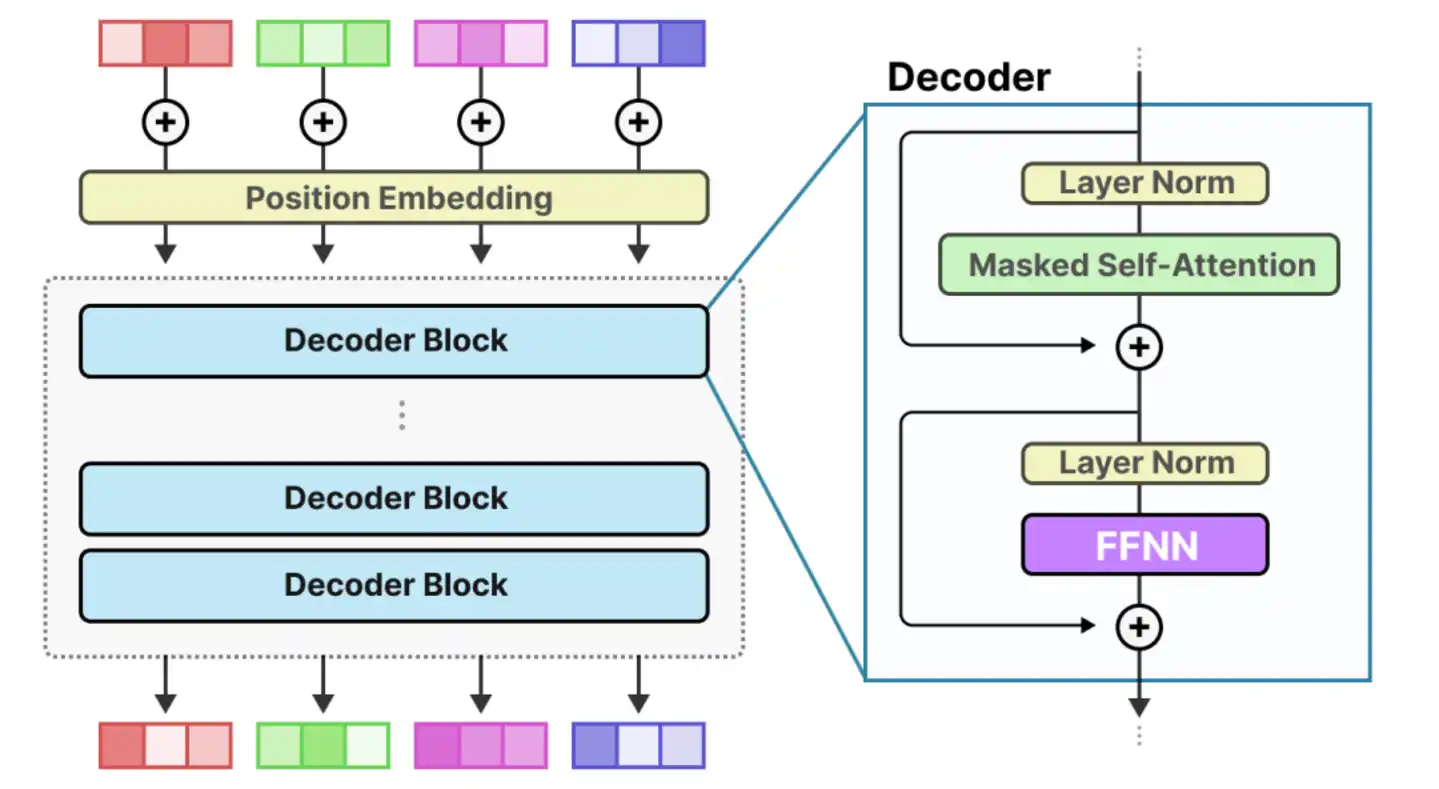
Dengan kata lain, tekanan komputasi bergeser dari "komputasi murni" ke "penjadwalan dan komunikasi sistem". Dan dalam ekosistem NVIDIA, masalah ini memiliki solusi yang relatif matang.
Misalnya, berdasarkan H100 atau B200, melalui interkoneksi bandwidth tinggi yang dibangun dengan NVLink dan NVSwitch, bandwidth antar GPU dalam satu node dapat mencapai level TB/s, membentuk jaringan komputasi yang hampir "terhubung penuh", di mana data mengalir antar chip seperti jalan tol, dengan latency dan biaya sinkronisasi yang sangat terkompresi. Namun ketika DeepSeek mencoba memigrasi sistem yang presisi ini ke platform Ascend Huawei, yang dihadapi adalah topologi hardware yang sangat berbeda.
Tidak dapat disangkal, chip Ascend telah menunjukkan kemajuan signifikan dalam beberapa tahun terakhir, tetapi dalam hal "kemampuan konektivitas penuh" dari cluster berskala sangat besar, masih terdapat kesenjangan fisik dengan NVIDIA. Misalnya, dibatasi oleh kemampuan proses manufaktur dan IP SerDes, Ascend lebih bergantung pada modul optik untuk ekspansi antar node. Skema "mengorbankan ruang untuk bandwidth" ini meskipun可行 (feesible), juga memperkenalkan jalur fisik yang lebih panjang, sehingga membawa kompleksitas seperti latency sinyal, overhead sinkronisasi, serta manajemen daya dan pendinginan.
Sementara itu, kesenjangan di tingkat perangkat lunak juga tidak dapat diabaikan. Framework CANN milik Ascend dalam hal cakupan operator, paralelisme otomatis, fusi kernel, serta penjadwalan komunikasi terdistribusi, secara keseluruhan kematangannya masih tertinggal dibandingkan ekosistem CUDA. Ini berarti, tim teknikal DeepSeek perlu melakukan optimasi spesifik dalam banyak detail底层 (bottom-layer), bahkan menulis ulang secara manual operator kunci.
Yang lebih rumit lagi, ketertinggalan ini seringkali bukan linier, tetapi sistematis. Secara konkret terlihat sebagai penurunan kinerja satu operator dapat mempengaruhi seluruh rantai komputasi; penurunan efisiensi komunikasi sekali dapat menyebabkan fluktuasi besar dalam throughput keseluruhan. Hasil akhirnya mungkin model masih dapat berjalan, tetapi masih jauh dari stabil, efisien, dan dapat diskalakan.
Dari sudut pandang ini, penundaan DeepSeek V4 bukanlah masalah sederhana tentang irama produk, tetapi merupakan biaya pasti dari磨合 (break-in) mendalam antara tim algoritma terkemuka China dan sistem chip domestik. Meskipun prosesnya sulit, sangatlah penting.
Yang lebih penting, proses ini melepaskan sinyal yang jelas, yaitu persaingan AI, sedang beralih dari "perbandingan kemampuan model", ke "perbandingan kemampuan rekayasa sistem". Dan pada tahap ini, siapa yang dapat lebih cepat "menjalankan, menstabilkan, dan menjalankan dengan biaya lebih murah" sebuah model, dialah yang benar-benar mendekati keunggulan tingkat industri.
Monopoli CUDA Sulit Dipatahkan, CANN Terpaksa Berkompromi
Jika kesulitan adaptasi sisi inferensi DeepSeek V4 di atas mengungkapkan hambatan realitas di tingkat rekayasa, maka dengan menelusuri pertanyaan ini lebih jauh, pertanyaan yang lebih mendasar muncul: Mengapa hanya memindahkan model dari satu platform komputasi ke platform lain menjadi begitu sulit?
Melihat kembali aliansi Wintel di era PC, Microsoft dan Intel meskipun memonopoli bersama, tetapi ada persaingan kepentingan antara kedua perusahaan, yang memberikan ruang bagi kebangkitan Linux, AMD, dan bahkan sistem Apple di kemudian hari. Namun, NVIDIA membangun semacam "monopoli vertikal tunggal" di bidang AI, yaitu gabungan Microsoft dan Intel.
Secara konkret diwujudkan sebagai, pada tingkat perangkat keras, NVIDIA mendefinisikan struktur fisik SM (Streaming Multiprocessor) dan logika komputasi Tensor Core; pada tingkat perangkat lunak, CUDA menyediakan cuBLAS, cuDNN dan library tertutup lainnya yang sesuai sempurna 1:1. Keduanya bertumpuk menyebabkan realitas yang sangat menakutkan: lebih dari 6 juta+ pengembang global mengoptimalkan algoritma, framework (PyTorch, TensorFlow) mengutamakan implementasi CUDA di sekitar cuBLAS, cuDNN, NVLink/NVSwitch, bahkan cluster heterogen anti-NVIDIA seperti AWS Trainium+Cerebras WSE, saat migrasi cache KV masih memerlukan perangkat lunak NVIDIA NIXL dan AWS EFA.
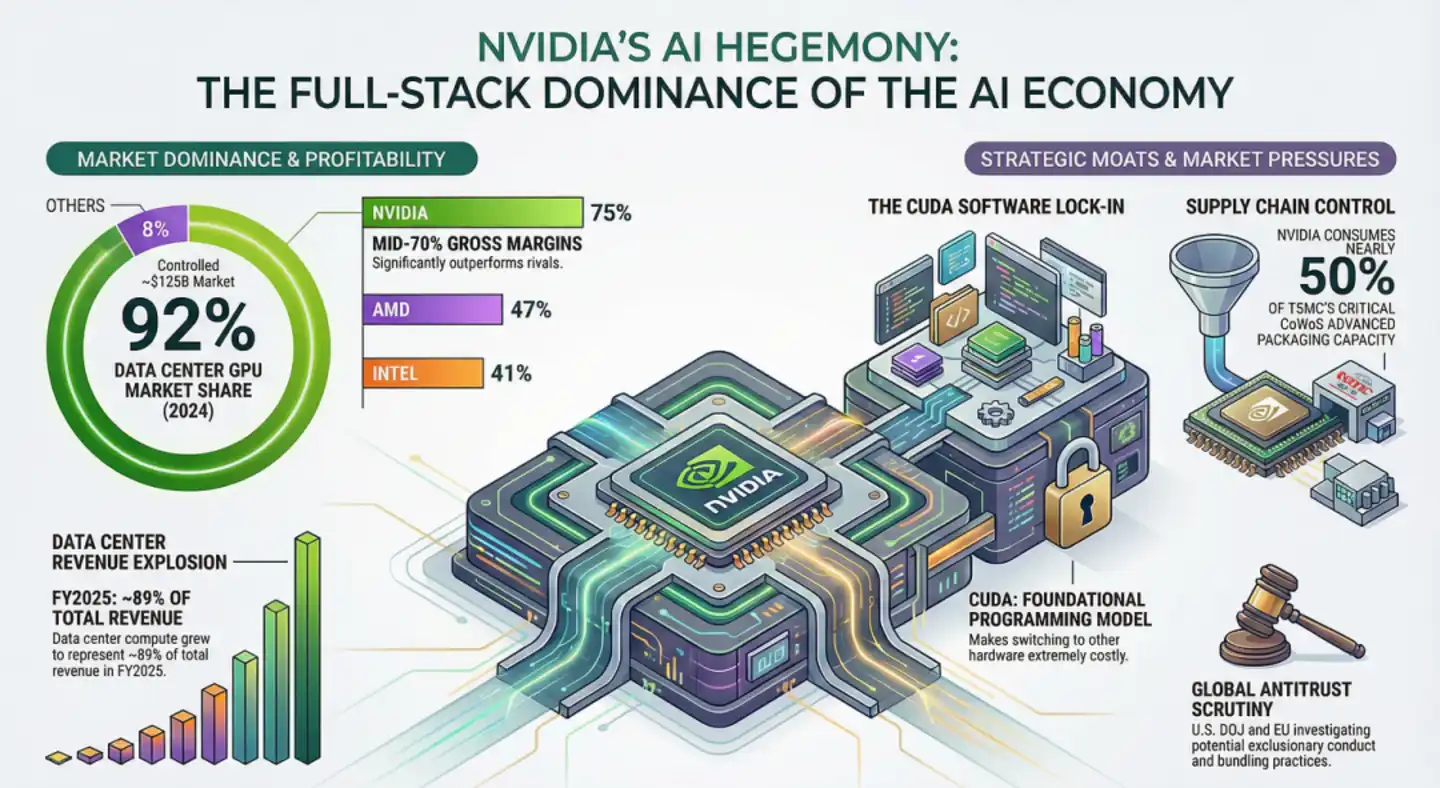
Dari sini terlihat, ini bukan lagi detail teknis titik tunggal, ini adalah penguncian ekosistem, yaitu sebelum portabilitas model gagal, pengembang "berpikir dengan bahasa fitur perangkat keras NVIDIA" telah menjadi惯性 (inertia). Dan正是 (justru)惯性 (inertia) ekosistem inilah yang membuat NVIDIA seperti lubang hitam raksasa, menyerap lebih dari 90% keuntungan inovasi global.
Dalam latar belakang di atas, sebagai pesaing terkuatnya, CANN Huawei awalnya memang mencoba menempuh jalur yang relatif independen, tetapi dengan datangnya era model besar, jalur ini secara bertahap menunjukkan masalah, misalnya pengembang tidak mau bermigrasi, perusahaan tidak berani mengambil risiko, pertumbuhan ekosistem lambat. Ditambah tekanan waktu (misalnya iterasi cepat model besar), jalur yang sepenuhnya mandiri mulai menjadi tidak realistis.
Berdasarkan ini, CANN secara bertahap memperkenalkan desain lapisan abstraksi yang mirip CUDA, misalnya dalam CANN Next mencoba menyamakan antarmuka cuBLAS, cuDNN, mencapai kompatibilitas tinggi, sehingga biaya migrasi model terkompresi dari "minggu bahkan bulan" menjadi "tingkat jam"; pada tingkat arsitektur, arsitektur heterogen 950PR (Pre-fill/Decode Decouple) yang baru dirilis juga sengaja meniru layanan decouple NVIDIA, bukan jalur heterogen彻底 (sepenuhnya) seperti TPU Google.
Kita harus mengakui, strategi yang hampir seperti "kompatibilitas diutamakan" ini dalam jangka pendek berhasil,降低了门槛 (menurunkan ambang batas), membuat Ascend cepat mendapatkan basis aplikasi di pasar domestik, dan memungkinkan perusahaan seperti DeepSeek, Tencent, ByteDance dan lainnya mencoba komputasi domestik dengan门槛 (ambang batas) yang lebih rendah. Misalnya CANN Next melalui model pemrograman SIMT mencapai kompatibilitas CUDA di atas 95%, telah membantu banyak perusahaan mempersingkat waktu migrasi secara signifikan hingga tingkat jam, mempercepat implementasi实际 (nyata).
Namun tantangan yang menyertainya adalah, begitu menyentuh inovasi terdepan, lapisan kompatibilitas akan menjadi "langit-langit".
Misalnya, ketika pengembang benar-benar menggunakan platform Ascend secara mendalam, mereka akan menemukan bahwa meskipun jalur umum telah dipermudah, begitu menyangkut beberapa operator底层 (bottom-layer) yang jarang digunakan atau inovatif, dukungan CANN akan menurun, kinerja berfluktuasi剧烈 (drastis). Dan kesulitan yang dihadapi DeepSeek V4 selama adaptasi, seperti ketika mencoba memperkenalkan arsitektur hybrid struktur non-Transformer seperti SSM (State Space Model) atau Mamba, menemukan bahwa optimasi底层 (bottom-layer) CANN masih terutama condong ke perkalian matriks (GEMM),很大程度上 (sebagian besar)是因为 (karena) ketika mencoba beberapa optimasi algoritma yang melampaui常规 (konvensional), mereka menabrak "batas" lapisan kompatibilitas CANN.
Dan masalah yang lebih dalam adalah,一旦 (sekali) memilih kompatibel, berarti默认 (default) CUDA仍然是 (tetap menjadi) standar tersembunyi, Anda dapat mengganti perangkat keras, tetapi dalam semantik perangkat lunak dan paradigma pengembangan,仍然 (tetap) menggunakan aturan yang ditentukan oleh pihak lain. Ini既是 (sekaligus) jalan pintas,也是 (juga) batasan.
Kompatibilitas Menyimpan Tantangan Risiko, Peluang Masa Depan Masih Perlu Kemandirian Sejati
Seperti disebutkan sebelumnya, dalam realitas dimana ekosistem CUDA telah membentuk standar de facto, pilihan Huawei pada jalur "seperti kompatibel" hampir merupakan hasil yang tak terelakkan, tetapi juga mendorong seluruh industri AI China ke titik pilihan kritis: melanjutkan kompatibilitas dengan CUDA, atau secara bertahap menuju sistem ekosistem yang benar-benar independen?
Dalam jangka pendek, jawabannya hampir tidak ada keraguan,那就是 (yaitu) harus kompatibel, ini adalah pilihan efisiensi dan realitas. Tetapi dalam jangka panjang, jalur ini menyembunyikan risiko yang tidak boleh diabaikan.
Seperti diketahui, ketika sebuah sistem (seperti CANN) dirancang untuk kompatibel dengan sistem lain (seperti CUDA), ia tidak dapat menghindari untuk mewarisi keterbatasan pihak lain.
Faktanya adalah, saat ini sebagian besar algoritma open-source global dikembangkan sekitar arsitektur NVIDIA, jika untuk memanfaatkan aset存量 (existing) ini hanya mengejar kompatibilitas 1:1, maka kita akan terjebak dalam "perangkap peniru" dalam desain perangkat keras, dan memanifestasikan sebagai一旦 (sekali) arsitektur perangkat keras NVIDIA di masa depan menghadapi transformasi paradigma, misalnya dari Transformer ke beberapa arsitektur baru yang tidak memerlukan perkalian matriks skala besar, tetapi lebih bergantung pada logika asynchronous, maka tumpukan komputasi domestik yang一直 (selama ini) berada dalam status "bayangan" mungkin akan menghadapi断层 (discontinuity) teknologi secara instan, dan jalan buntu "kompatibilitas Bug ke Bug" ini,无疑 (tidak diragukan lagi) membuat inovasi底层 (bottom-layer) kita始终 (selalu) diselimuti bayangan orang lain.
Dan risiko yang lebih dalam terletak pada "selisih waktu". Menurut data statistik Bernstein dan Epoch AI, meskipun Huawei mengalami peningkatan份额 (share) signifikan di dalam negeri,但在 (tetapi dalam) total komputasi AI global,占比 (proporsi) chip domestik hanya 5%, masih relatif terbatas. Dan正是 (justru) kesenjangan skala absolut ini, yang menyebabkan "gesekan efisiensi R&D" yang serius.
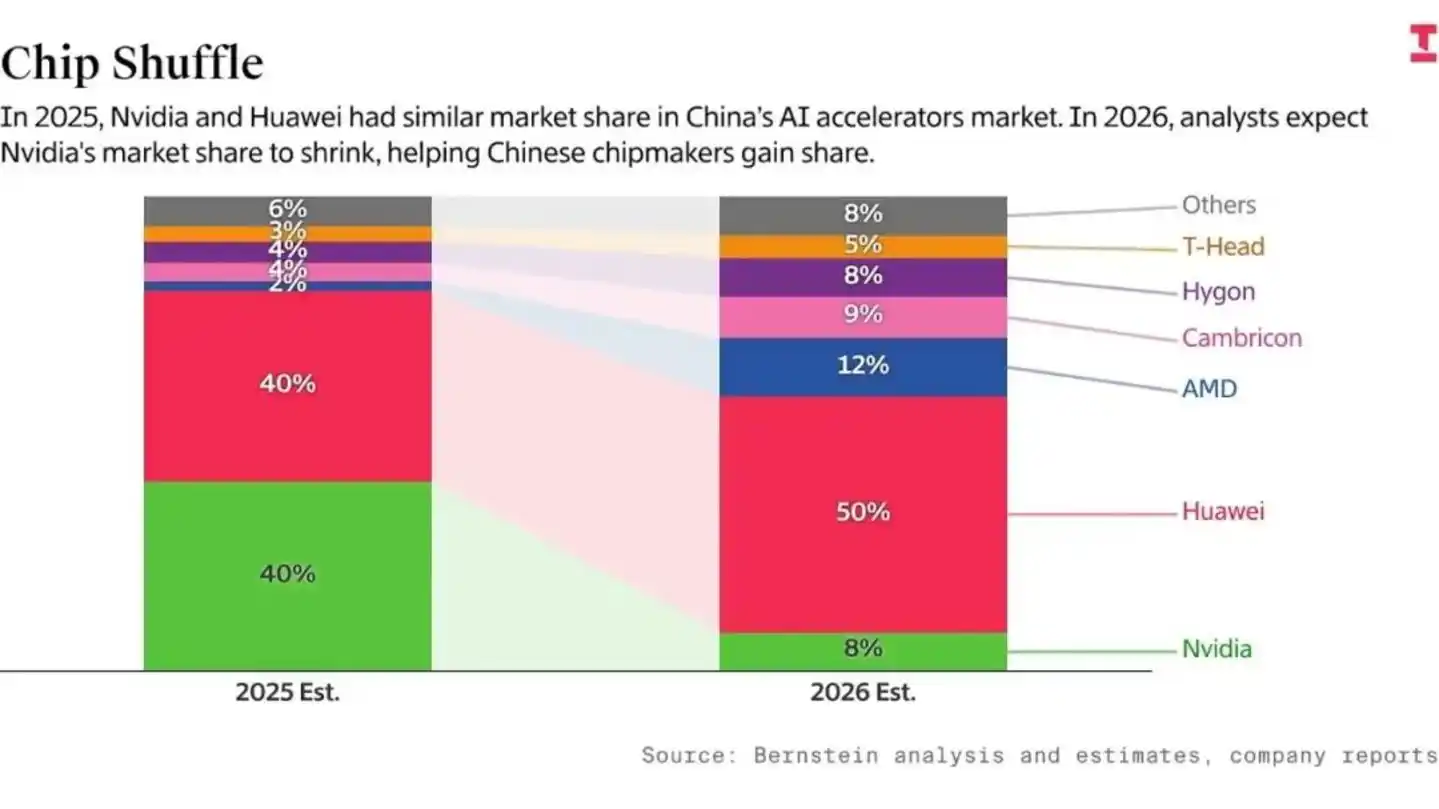
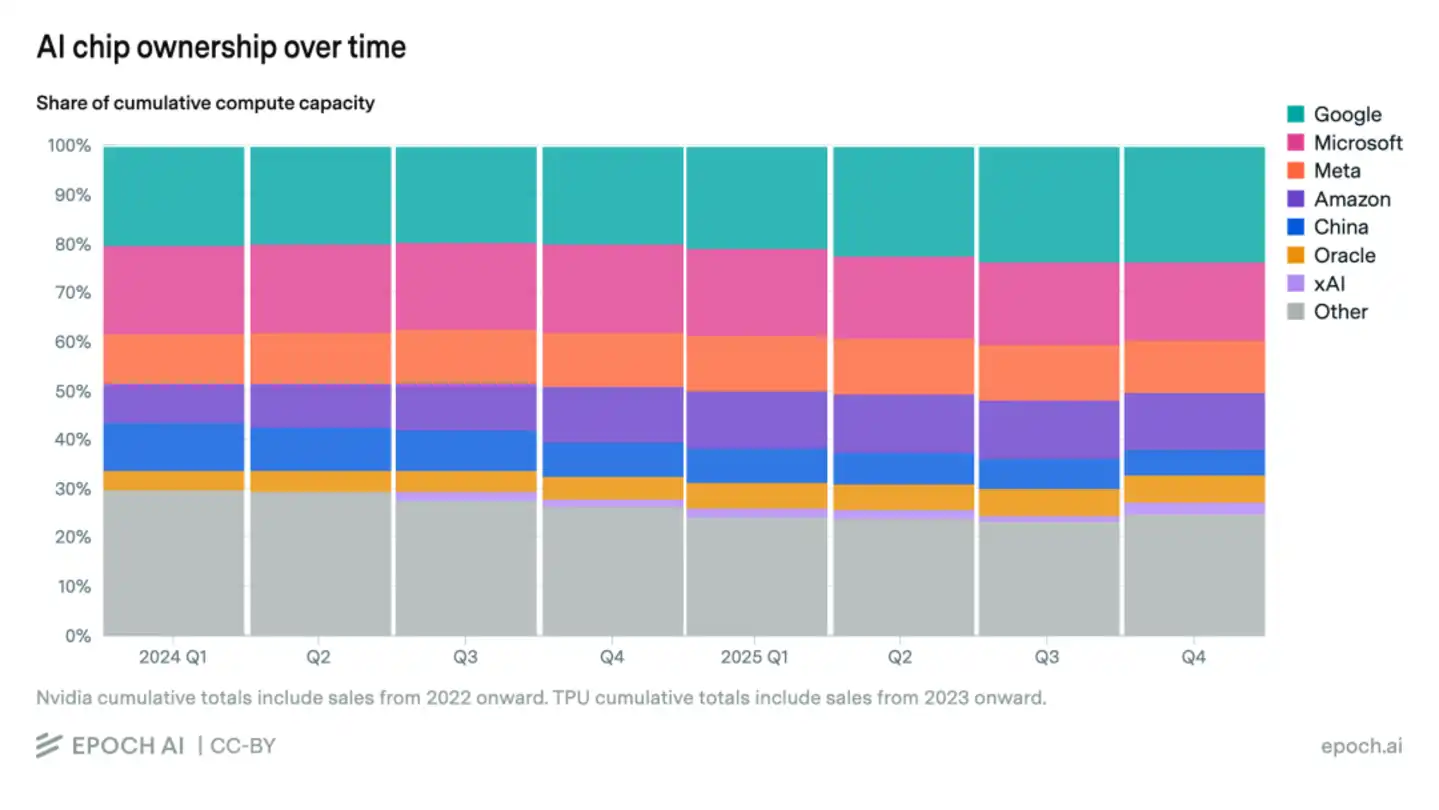
Secara konkret terwujud sebagai, raksasa AI AS dapat memanfaatkan bandwidth komunikasi Blackwell yang kuat, dalam 18 bulan menjalankan Scaling Laws parameter 10T, sedangkan talenta terkemuka China terpaksa menghabiskan lebih dari 50% kapasitas penelitian mereka pada masalah seperti "bagaimana mengatasi atenuasi sinyal chip usang" dan "beradaptasi dengan compiler yang belum matang".
Perlu dijelaskan, ketidaksesuaian waktu di atas, di era AI yang berubah dengan cepat akan diperbesar tanpa batas. Ketika talenta kita masih sibuk "mengisi lubang", lawan mungkin telah menyelesaikan pertumbuhan eksponensial kemampuan model, menyebabkan领先 (keterdepanan) model lawan setahun, berkembang menjadi jurang不止 (tidak hanya) setahun dengan kita setelah kemampuan model, roda data, keselarasan keamanan semuanya tumbuh majemuk secara eksponensial.
Tentu saja, tantangan sering mengandung peluang. Jika DeepSeek V4 berhasil dirilis, akan membuktikan kelayakan "full-stack domestik", mempercepat pematangan ekosistem CANN, menarik lebih banyak pengembang untuk mengikuti, ditambah dengan sentimen global "dunia telah lama menderita karena NVIDIA", dukungan industri terhadap CANN mungkin akan melampaui ekspektasi. Dan chip后续 (penerus) seperti Huawei Ascend jika mencapai 80%—90% kinerja inferensi H100, ditambah dengan红利 (dividen) kompatibilitas CANN Next, skala kritis pasokan AI China有望 (diharapkan) terbentuk dalam 1—2 tahun.
Tetapi需要 (perlu) disadari dengan清醒 (jernih), kompatibilitas hanya dapat menyelesaikan masalah "bertahan hidup", kemandirian sejati,才能 (baru dapat) menentukan "seberapa jauh melangkah". Dan 3-5 tahun ke depan, akan menjadi periode jendela kunci. Jika kita dapat保持 (mempertahankan) kompatibilitas sambil secara bertahap membangun model pemrograman independen, sistem operator, dan arsitektur sistem, ekosistem AI China masih memiliki peluang untuk mencapai lompatan dari mengikuti ke mendefinisikan aturan.否则 (Jika tidak) AI China mungkin akan terjebak dalam rel "kereta replika kasar".
Ditulis di akhir: Penundaan peluncuran DeepSeek V4, yang tampaknya "keterlambatan" yang偶然 (kebetulan), sebenarnya mengungkapkan realitas yang lebih dalam, yaitu persaingan AI早已 (sudah lama) bukan hanya persaingan model, tetapi pertarungan menyeluruh ekosistem底层 (bottom-layer) dan kemampuan sistem. Kompatibilitas dengan CUDA固然 (memang) adalah jalur terpendek menuju realitas, tetapi jika berhenti di sini, juga dapat mengunci langit-langit masa depan.
Jadi tantangan sebenarnya, bukan在于 (terletak pada) apakah dapat mengganti一套 (satu set) teknologi, tetapi在于 (terletak pada) apakah dapat melepaskan ketergantungan pada paradigma yang ada, membangun sistem aturan sendiri. Dan 3-5 tahun ke depan, akan menentukan apakah AI China menjadi kutub penting dalam ekosistem global, atau tetap berada pada posisi "mengikuti tingkat tinggi" dalam jangka panjang. Tentu saja, dalam mengejar kemandirian, juga需要 (perlu) mewaspadai potensi dampak ekosistem tertutup terhadap daya tarik pengembang global, untuk memastikan keterbukaan ekosistem dan daya saing internasional jangka panjang.






