Mengonsumsi sebuah SSD 1TB dalam setahun?
Codex, alat pemrograman unggulan OpenAI, sedang menulis data hingga 640TB per tahunnya, mengikis habis masa pakai solid-state drive (SSD) Anda.

Beberapa waktu lalu, seorang pengembang mengajukan sebuah issue di GitHub. Issue GitHub bernomor #28224 yang kini bertanda 'Tertutup' ini, berjudul:
Log umpan balik SQLite Codex dapat menulis 640TB per tahun, dengan cepat menghabiskan masa pakai SSD.
Berdasarkan pengukuran langsung pelapor, SSD utama-nya yang terus menyala selama 21 hari telah mengalami penulisan sebesar 37TB. Dengan proyeksi ini, dalam setahun sekitar 640TB, cukup untuk merusak sebuah hard drive konsumen dengan Total Bytes Written (TBW) 600TB.
Sebagai bukti, dia melampirkan dua tabel.
Dalam bukti 1, database log ini selalu hanya berukuran 1.2GB, secara permukaan terlihat seperti tidak terjadi apa-apa; namun ID baris auto-increment-nya sudah mencapai 5.5 miliar, sementara baris yang benar-benar tersisa hanyalah sedikit di atas 500 ribu, perbedaannya mencapai sepuluh ribu kali lipat.
Kuncinya adalah, keausan hard drive hanya memperhitungkan berapa banyak yang telah ditulis, tidak peduli berapa banyak yang tersisa saat ini: 5.5 miliar baris ini semuanya telah tercatat ke disk, menghapusnya tidak akan mengembalikan penulisan yang sudah terjadi. Jadi Anda selalu hanya melihat 500 ribu baris itu saat memeriksa file, namun hard drive sudah menanggung beban penulisan 5.5 miliar baris.
Bukti 2 mengungkapkan distribusi 5.5 miliar baris ini: lebih dari 90% adalah noise debug yang bahkan pengembangnya sendiri tidak akan melihat kembali, hanya menyalin utuh setiap paket data WebSocket sudah mengambil separuhnya.
Pelakunya adalah satu baris konfigurasi default Level::TRACE, yang memperlakukan masa tulis hard drive Anda seperti kertas coret-coret gratis.
Sebuah komentar bernilai tinggi di Hacker News langsung memberikan cap untuk masalah ini:
Ini adalah salah satu contoh paling terkenal dari "perangkat lunak asal-asalan" (slopware).

Pengguna ini juga dengan putus asa mengeluarkan pernyataan:
Ini benar-benar tragis. Dunia membutuhkan pesaing untuk Anthropic.
Yang lebih memalukan, masalah ini bukan tidak pernah dilaporkan.
Sejak April tahun ini sudah ada umpan balik sporadis, tertunda lebih dari dua bulan, harus menunggu pengguna sendiri yang menghitung, menulis laporan, dan membawanya ke headline Hacker News, baru ditangani secara serius. Meski begitu, putaran ini hanya memotong sekitar 85% penulisan log.
Ada juga yang ingin memperbaikinya sendiri, tetapi menemui jalan buntu: aplikasi desktop dari alat-alat ini bersifat tertutup sumbernya (closed-source).
Ada juga komentar jenius di kolom komentar: Bagaimana proses review tidak menghentikan kesalahan yang begitu jelas? Oh ya... @codex review ini.
640TB, Bagaimana Bisa Terjadi?
Apa artinya 640TB.
SSD konsumen mainstream biasanya memiliki masa pakai penulisan (TBW) sekitar 150 hingga 600 TBW, cukup untuk pengguna biasa digunakan selama belasan hingga dua puluh tahun.
Sedangkan fungsi log Codex yang 'mencatat apa yang dilakukannya' ini, dalam setahun bisa mencapainya.
Ceritanya berawal dari pengguna ini yang memeriksa hard drive-nya. Mesinnya yang terus menyala selama 21 hari, SSD utamanya telah mengalami penulisan 37TB.
Dengan kecepatan ini, setahun sekitar 640TB.
Yang lebih aneh adalah cara penulisannya.
Codex memelihara database SQLite lokal bernama logs_2.sqlite, khusus untuk mencatat log umpan balik. Pengguna ini menangkap selama 15 detik — 36211 baris dimasukkan ke database, sementara jumlah total baris yang dipertahankan, dari awal sampai akhir tetap 681774, tidak bertambah satu pun.
Setiap baris dimasukkan, satu baris dihapus. Jumlah baris selalu tetap, namun disk ditulis dan dihapus berulang kali puluhan ribu kali.
Mekanisme ini memiliki julukan, insert-and-prune: masukkan, lalu segera hapus.
Yang lebih menggelikan adalah hal-hal yang dicatatnya: tumpukan peristiwa inotify sistem file.
ld.so.cache dicatat 128764 kali, locale.alias 37982 kali, passwd 23843 kali.
File yang sama, oleh program yang sama, dicatat berulang-ulang hingga ratusan ribu kali.
ID auto-increment di log telah melebihi 5.5 miliar, sedangkan baris yang benar-benar tersisa hanya sekitar 500 ribu.
Perbedaannya sepuluh ribu kali lipat.
Ini bukan bug, ini seperti alat pemrograman AI yang sedang melafalkan mantra berulang-ulang ke hard drive-nya sendiri.
File Hanya 1GB, Penulisan 640TB
Sambil menulis sambil menghapus, berapa besar file logs_2.sqlite yang tersisa? Sekitar 1GB.
Inilah yang membawa pada poin paling kontra-intuitif dari seluruh peristiwa: masa pakai SSD dilihat dari 'jumlah penulisan' (write amplification), bukan 'ukuran file'. Sebuah file 1GB yang ditulis ulang 640 kali, bagi hard drive sama dengan menulis 640TB.
SQLite menggunakan mekanisme WAL (Write-Ahead Logging), setiap perubahan pertama-tama ditulis ke file -wal, ditumpuk baru kemudian checkpoint kembali ke database utama. Codex setiap 15 detik melakukan puluhan ribu kali insert dan delete, setiap kali harus melalui WAL, pembaruan indeks, checkpoint, area penyimpanan yang sama, dihapus dan ditulis berulang.
Analoginya: sebuah buku catatan 1GB, Anda hapus dan tulis ulang 1750 kali setiap hari, terus menerus selama setahun. Buku catatannya tetap sama, kertasnya sudah bolong.
Ini juga alasan bug ini bisa tersembunyi begitu lama: ia tidak memakan ruang, hanya membakar masa pakai.
Memeriksa ruang disk tersedia tidak menunjukkan anomali, ukuran file selalu tenang, hanya dengan membaca penghitung kesehatan SMART hard drive itu sendiri, baru terlihat jumlah penulisan yang diam-diam menumpuk.
Akar Masalah, Satu Baris RUST_LOG yang Diabaikan
Mengapa mencatat begitu banyak log?
Jawabannya ada di satu baris konfigurasi kode sumber Codex: sink (penampung) log umpan balik SQLite, saat diinisialisasi menggunakan Targets::new().with_default(Level::TRACE).
Satu kalimat, log default diatur ke level TRACE, tingkat tertinggi, paling cerewet, yang mencatat segalanya.
Kerangka kerja log Codex adalah tracing dari ekosistem Rust, praktik standarnya adalah membaca variabel lingkungan RUST_LOG. Pengguna tentu sudah mencoba, mengatur RUST_LOG ke info, warn, bahkan langsung mematikannya.
Tidak berguna.
with_default(Level::TRACE) mengunci default global secara keras di TRACE, RUST_LOG tidak berlaku di jalur ini. Anda pikir sudah mematikan log, ia tetap menulis.
Bug jenis ini paling menjebak karena bukan 'Anda lupa mengonfigurasi', melainkan 'Anda mengonfigurasi, ia berpura-pura tidak mendengar'.
Yang lebih mencolok adalah sebuah proporsi.
Membagi log yang dipertahankan berdasarkan kategori, TRACE mengambil 70.7%, sekitar 732.5 MB. Ditambah dua jalur log telemetri cermin codex_otel (log_only dan trace_safe), mengambil 25.3% lagi.
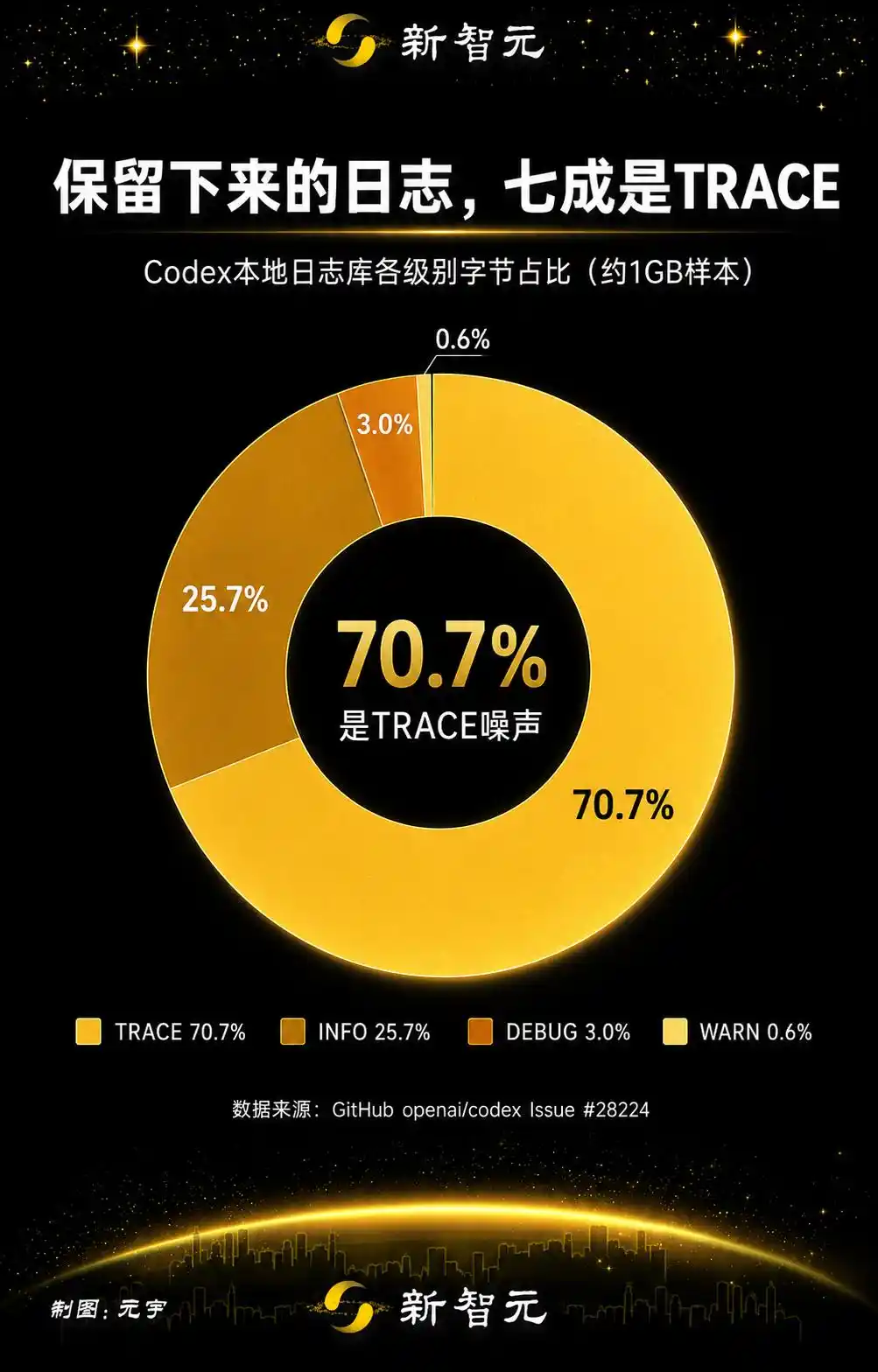
Tujuh puluh persen penulisan adalah noise TRACE, ditambah telemetri cermin, 96% semuanya adalah omong kosong yang tidak akan dilihat siapa pun.
Hanya 4%, adalah konten yang benar-benar bermakna.
Ini Bukan yang Pertama, Setidaknya yang Kesembilan
Pelapor melihat repositori Codex, menemukan Issue jenis 'log tumbuh tak terbatas' ini, setidaknya ada 9.
#17320, WAL menulis gila-gilaan selama respons streaming, akar penyebabnya persis sama dengan kali ini, TRACE mengabaikan RUST_LOG.
#24275, logs_2.sqlite versi desktop melonjak gila-gilaan.
#22444, WAL tumbuh tak terbatas dan mempertahankan ruang tidak dilepaskan.
#26374, menulis 0.75GB per hari, tidak ada rotasi.
#27911, sebuah goals_1.sqlite 4KB, ditulis menjadi 11MB/s.
#20563, proses menganggur juga menulis ke disk dengan gila-gilaan.
#27020, aktivitas disk 100% di Windows.
Sumber paling awal dapat ditelusuri ke #12969, PR inilah yang menghubungkan sink log umpan balik SQLite pada level TRACE.
Sebuah database 4KB ditulis menjadi 11MB per detik, jika dipisahkan sendiri sudah cukup untuk menulis satu artikel. Dan itu dengan yang 640TB, adalah gejala dari produk yang sama, sistem telemetri yang sama.
Ini menunjukkan sistem log dan telemetri Codex, dari awal tidak memiliki konsep 'anggaran sumber daya'.
Seluruh lini produk sedang berkompetisi dalam anggaran token, panjang konteks, kemampuan model.
Tapi hampir tidak ada yang bertanya: seorang Agen yang berjalan di mesin pengguna, beroperasi 7×24 jam, anggaran disk, memori, CPU-nya, siapa yang mengatur?
Diperbaiki, tapi dengan Cara yang Sangat OpenAI
Dilaporkan ke GitHub pada 14 Juni, 23 Juni, pelapor memperbarui: tiga PR telah digabungkan, berdasarkan umpan balik Codex-nya sendiri dapat mengurangi sekitar 85% log, lalu mengumumkan penutupan.
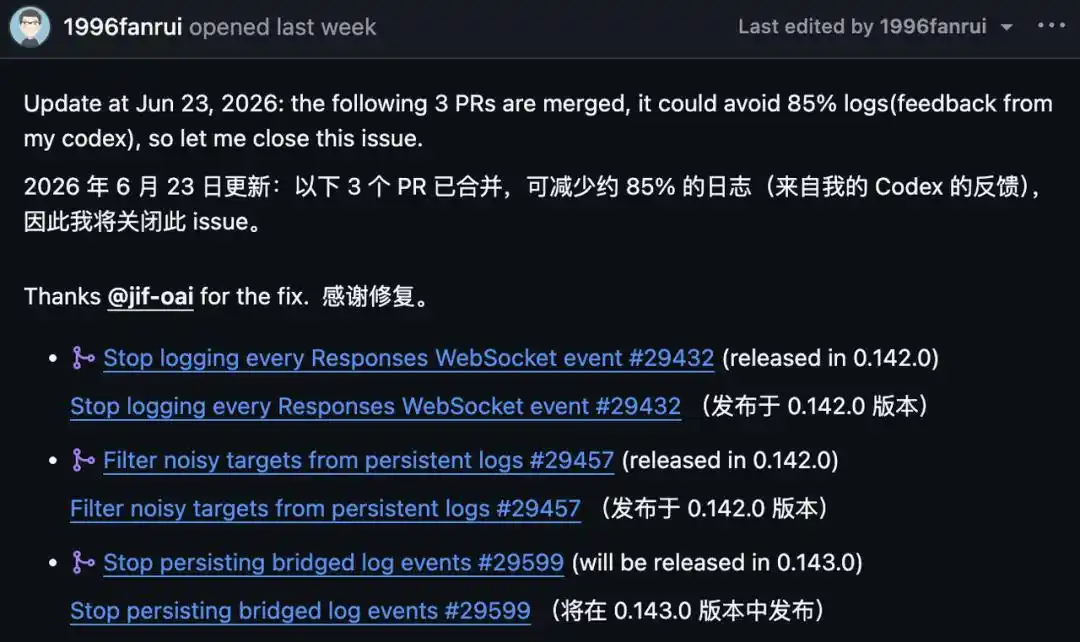
Pertama tentang 85% ini — bukan 100%, dan belum sepenuhnya diterapkan.
Dari tiga perbaikan, #29432, #29457 telah dirilis dengan versi 0.142.0, memotong log WebSocket per baris dan target noise; yang ketiga #29599 menghentikan jenis log redundan lain yang di-bridge, harus menunggu 0.143.0 baru diluncurkan.
Bahkan jika ketiganya sudah diterapkan, sisa sekitar 15%, setahun masih akan menulis sekitar 96TB, hanya dari 'setahun menghabiskan hard drive' turun menjadi 'enam tahun menghabiskan hard drive'.
Ada juga yang membelanya: log trace memang dirancang disimpan untuk debugging, bukan bug, dan memang memudahkan OpenAI melacak edge case.
Tapi masalahnya justru di sini: menggunakan masa pakai SSD pengguna berbayar, sebagai penyimpanan gratis untuk debug vendor, hal ini, apakah disetujui pengguna?
Medan Perang Pemrograman, yang Dihabiskan Bukan Hanya SSD
Yang menarik, yang disebut bukan hanya Codex.
Komentar segera menambahkan: Claude Code juga menulis log debug ke lokal dengan gila-gilaan, ada yang terpaksa membuat symlink direktori log ke RAM disk (tmpfs), untuk memperpanjang usia SSD.
Dua unggulan, melakukan kesalahan jenis yang sama.
Komentar di komunitas, dengan cepat membesar dari satu bug, menjadi masalah kualitas seluruh alat pemrograman AI.
Ada yang mengeluh agen-agen cerdas ini GPU selalu penuh, memori sering 70GB, ada yang memberi nama untuk generasi perangkat lunak ini: perangkat lunak asal-asalan.
Saran pengembang itu sebenarnya sangat sederhana: beri batas untuk aplikasi, jangan melebihi 3GB. Hanya satu batas ini, Codex menunda 9 Issue, berbulan-bulan baru mau menarik garisnya.
Pertanyaannya adalah, sebuah perusahaan yang selalu menyebut 'AGI', mengapa bisa terjatuh pada masalah yang bahkan insinyur magang bisa lihat?
Mengapa cacat ini bisa tersembunyi begitu lama, sebuah komentar juga menyentuh intinya.
Sepuluh tahun lalu, log diatur ke TRACE, program langsung macet, hari itu juga diperbaiki; sekarang CPU cukup cepat, memori cukup besar, disk cukup kuat, cacat kecil ini diam-diam dicerna oleh kinerja perangkat keras, program tetap berjalan, antarmuka normal, pengguna tidak merasakan, sampai suatu hari SSD rusak lebih awal.
Beberapa tahun terakhir, perangkat lunak dipenuhi kode yang dihasilkan AI, fungsi ditumpuk semakin banyak, lapisan abstraksi semakin tebal, konsumsi sumber daya melonjak tak terkendali, hanya mengandalkan produsen perangkat keras yang setiap tahun membuat chip lebih cepat untuk menopang.
Maka terciptalah siklus absurd: perangkat lunak ditulis semakin buruk, perangkat keras dibuat semakin kuat. Pengguna membawa anggapan 'sepertinya tidak melambat' mengeluarkan uang untuk mesin baru, padahal hanya mesin baru yang nyaris menopang perangkat lunak yang lebih buruk.
Satu bug kecil tentu tidak bisa menjatuhkan OpenAI. Tapi persaingan Codex dan Claude Code sudah merambah dari kemampuan model, ke pintu masuk alur kerja pengembang.
Di garis depan ini, membuat perubahan cepat, merespons kebutuhan pengembang bukan lagi nilai tambah, hanya tiket masuk.
Referensi:
https://github.com/openai/codex/issues/28224
https://news.ycombinator.com/item?id=48626930
Artikel ini berasal dari akun WeChat publik "新智元", penulis: ASI启示录






