Mencapai kemampuan operasi cekatan setara manusia merupakan salah satu tantangan utama dalam bidang robotika.
Meskipun tangan cekatan multi-jari memiliki potensi seperti manusia secara perangkat keras, karena tingginya biaya untuk memperoleh data aksi robot berkualitas tinggi, model Visi-Bahasa-Aksi (VLA) yang ada saat ini jauh tertinggal dalam hal skala dan keragaman data dibandingkan model bahasa besar (LLM) dan model bahasa-visual (VLM), sehingga sulit memenuhi kebutuhan tugas kompleks di dunia nyata.
Makalah penelitian terbaru dari Microsoft Research Asia (MSRA) bekerja sama dengan Universitas Tsinghua, "Scalable Vision-Language-Action Model Pretraining for Robotic Manipulation with Real-Life Human Activity Videos", mengusulkan kerangka pra-pelatihan inovatif VITRA untuk mengatasi masalah kunci ini.

Kontribusi inti dari penelitian ini adalah mengusulkan solusi yang sepenuhnya otomatis, mengubah sejumlah besar video aktivitas manusia nyata tanpa anotasi menjadi data yang sepenuhnya selaras dengan format data pelatihan V-L-A robot yang ada.
Dengan mengekstrak lintasan gerakan 3D tangan dari video, melakukan segmentasi aksi atomik, dan menghasilkan instruksi bahasa secara otomatis, tim penelitian membangun dataset V-L-A tangan berskala sangat besar yang berisi 1 juta segmen, 26 juta frame.
Setelah menyelesaikan pra-pelatihan pada data video manusia murni, model menunjukkan kemampuan prediksi aksi tangan nol-sampel (Zero-Shot) yang kuat di lingkungan nyata yang benar-benar belum pernah dilihat sebelumnya.
Hanya dengan sedikit data robot nyata untuk fine-tuning, model dapat mencapai operasi cekatan dengan tingkat keberhasilan tinggi pada robot nyata, dan menunjukkan kemampuan generalisasi yang sangat kuat terhadap objek dan lingkungan baru.
Berikut adalah konten lebih detail.
Membuka Jalan Transformasi dari Video Manusia ke Data Robot
Masalah inti dari makalah ini adalah bagaimana mengatasi perbedaan besar antara video manusia yang tidak terstruktur dan data robot yang terstruktur, sehingga dapat mengekstrak label aksi dan instruksi bahasa berkualitas tinggi yang dapat digunakan untuk pra-pelatihan model VLA.
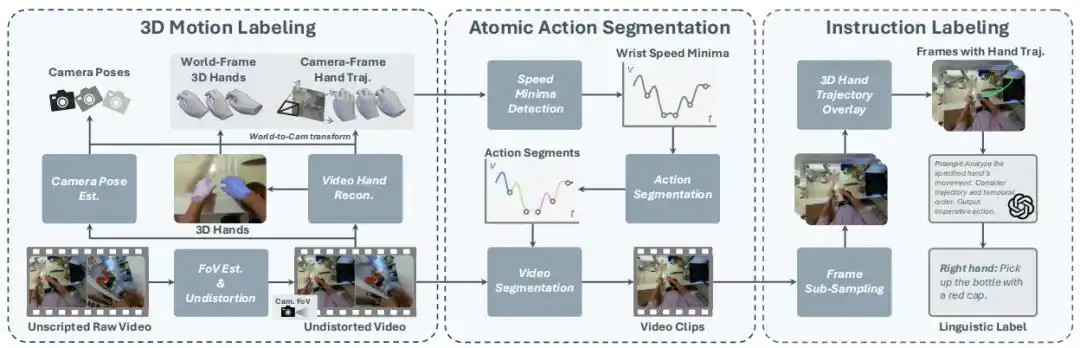
Penelitian ini membangun sistem lengkap yang terdiri dari tiga teknologi inti, mencapai transformasi mulus dari video mentah ke data V-L-A.
△
Anotasi Gerakan 3D: Memulihkan Lintasan Tangan dan Kamera dengan Akurat
Memulihkan gerakan tangan 3D yang akurat dari video kamera monokuler, tidak terkalibrasi, dan mungkin bergerak, adalah tugas yang sangat menantang.
Penelitian ini mengusulkan metode pelacakan pose tangan dan kamera monokuler berdasarkan teknologi visi 3D terkini:
Pertama, menentukan status kamera melalui aliran optik latar belakang, dan memperkirakan parameter intrinsik kamera.
Selanjutnya, menggunakan SLAM visi mendalam dan model estimasi kedalaman untuk melacak pose kamera, dan menggunakan model rekonstruksi tangan untuk mengekstrak pose tangan 3D di ruang kamera setiap frame (termasuk pose 6D pergelangan tangan dan sudut sendi lengkap).
Akhirnya, menggabungkan informasi ini untuk mendapatkan lintasan gerakan tangan 3D di ruang dunia.
Metode ini tidak hanya menyediakan label aksi berpresisi tinggi, tetapi juga meletakkan dasar untuk segmentasi aksi dan anotasi instruksi selanjutnya.
Segmentasi Aksi Atomik: Pembagian Alami Berdasarkan Nilai Minimum Kecepatan
Data V-L-A robot yang ada biasanya terdiri dari tugas atomik sederhana dan jarak pandang pendek. Bagaimana secara akurat memisahkan aksi atom ini dari video panjang adalah sebuah tantangan.
Tim penelitian mengambil inspirasi dari ritme alami gerakan manusia, mengusulkan algoritma segmentasi sederhana dan efisien: memisahkan berdasarkan nilai minimum kecepatan pergerakan tangan di ruang 3D.
Selama transisi aksi, kecepatan tangan manusia biasanya mengalami perubahan, dan nilai minimum kecepatan sering kali menandai pergantian aksi.
Dengan mendeteksi nilai minimum kecepatan dari lintasan pergelangan tangan 3D di ruang dunia, metode ini dapat secara efisien membagi video panjang menjadi segmen pendek yang berisi aksi atom tunggal, tanpa memerlukan anotasi manual tambahan atau inferensi model apa pun.


Anotasi Instruksi: Deskripsi Aksi Akurat dengan Menggabungkan Lintasan 3D
Untuk menghasilkan instruksi bahasa yang akurat untuk segmen video yang telah dipisahkan, tim penelitian secara cerdik menggabungkan Model Bahasa-Visual (VLM) dan lintasan tangan 3D.
Untuk setiap segmen video, sistem mengambil sampel 8 frame gambar secara merata, dan memproyeksikan serta menumpuk lintasan 3D telapak tangan ke dalam gambar.
Kemudian, gambar-gambar dengan sorotan lintasan ini dimasukkan ke GPT-4, dengan prompt untuk menggabungkan konten gambar dan informasi lintasan, dan mendeskripsikan aksi tangan yang ditentukan dalam bentuk kalimat imperatif.
Eksperimen membuktikan bahwa menyediakan segmen video atomik dan menumpukkan lintasan tangan 3D dapat secara signifikan meningkatkan akurasi GPT dalam menghasilkan deskripsi aksi.
Mencapai Prediksi Nol-Sampel yang Kuat dan Generalisasi Dunia Nyata
Berdasarkan dataset V-L-A tangan manusia berskala sangat besar yang dibangun secara otomatis tersebut, tim penelitian merancang dan melatih sebuah model VLA yang dibuat khusus untuk operasi cekatan.
△
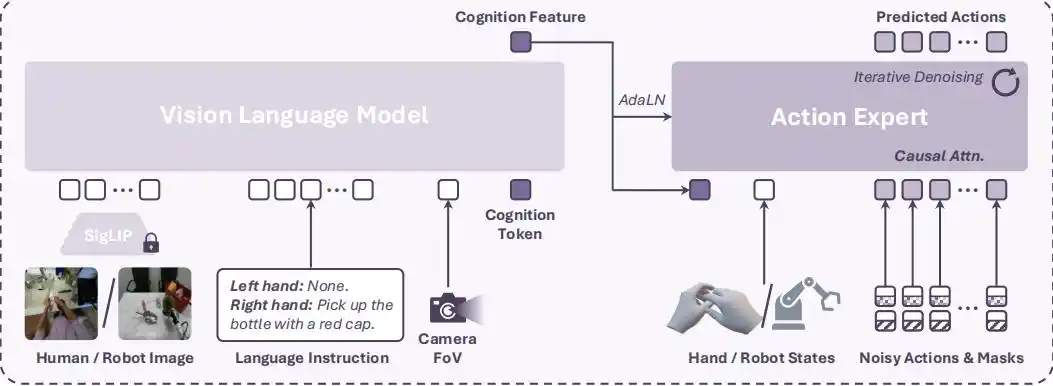
1. Arsitektur Model yang Menggabungkan VLM dan Pakar Aksi Difusi
Model VLA ini terdiri dari jaringan tulang punggung VLM (PaliGemma-2) dan sebuah pakar aksi difusi (Diffusion Transformer, DiT).
VLM menerima observasi visual, instruksi bahasa, dan informasi sudut pandang kamera (FoV), lalu mengeluarkan sebuah "Fitur Kognisi" (Cognition Feature).
Pakar aksi difusi kemudian menerima fitur kognisi tersebut, status tangan saat ini, serta blok aksi berisik yang dimask, dan memprediksi urutan aksi tangan di masa depan melalui denoising iteratif.
Untuk menangani aksi tangan manusia yang bergerak cepat dan beradaptasi dengan data segmen pendek, model menggunakan mekanisme perhatian sebab-akibat (Causal Attention) untuk denoising aksi, memastikan prediksi setiap langkah aksi hanya bergantung pada aksi sebelumnya, sehingga secara efektif menghindari dampak negatif dari zero-padding.
2. Prediksi Aksi Tangan Nol-Sampel: Menunjukkan Kemampuan Luar Biasa di Lingkungan Belum Pernah Dilihat
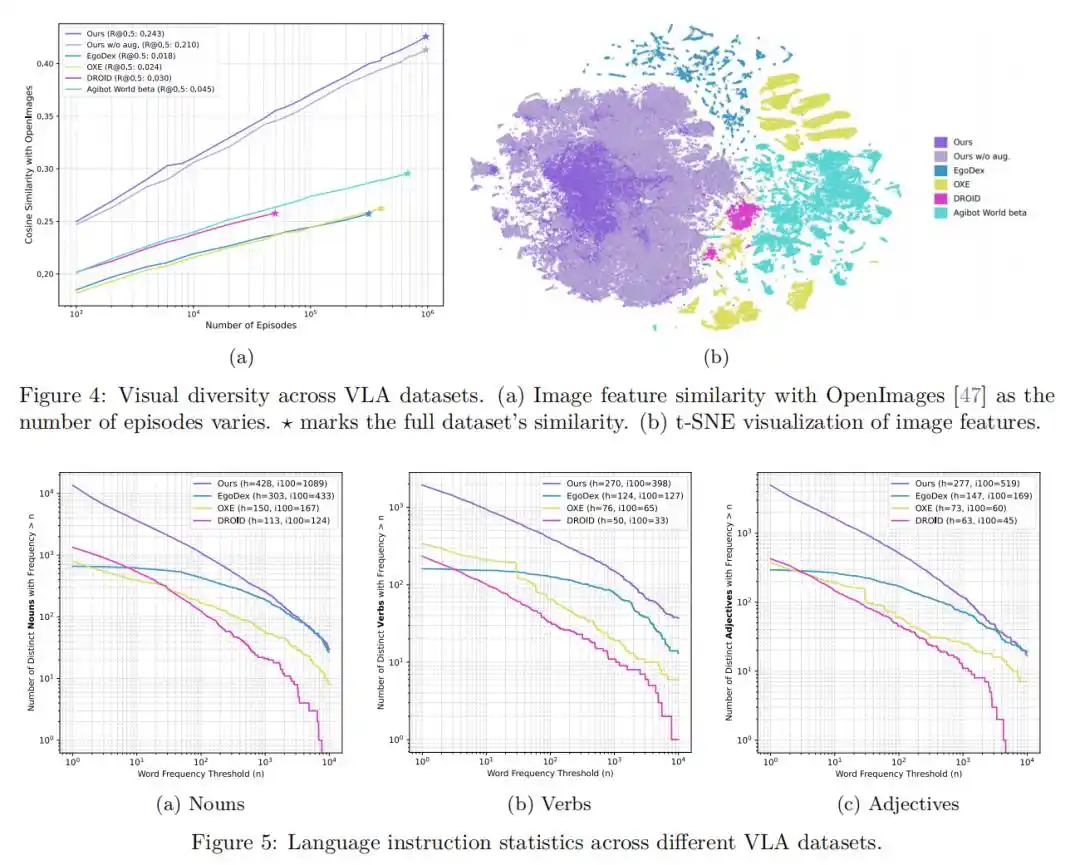
Di lingkungan kehidupan nyata yang benar-benar belum pernah dilihat sebelumnya, model yang telah dipra-pelatih menunjukkan kemampuan prediksi aksi tangan nol-sampel yang kuat.
△
Dalam evaluasi tugas menggenggam dan tugas prediksi aksi umum, model ini secara signifikan mengungguli model yang dilatih pada data yang dikumpulkan di lingkungan laboratorium (seperti EgoDex), serta mengungguli model yang dilatih menggunakan data beranotasi manusia mentah.
Hal ini membuktikan sepenuhnya bahwa menggunakan video kehidupan nyata yang masif dan beragam untuk pra-pelatihan dapat sangat meningkatkan kemampuan generalisasi model terhadap lingkungan kompleks dan objek yang belum dikenal.
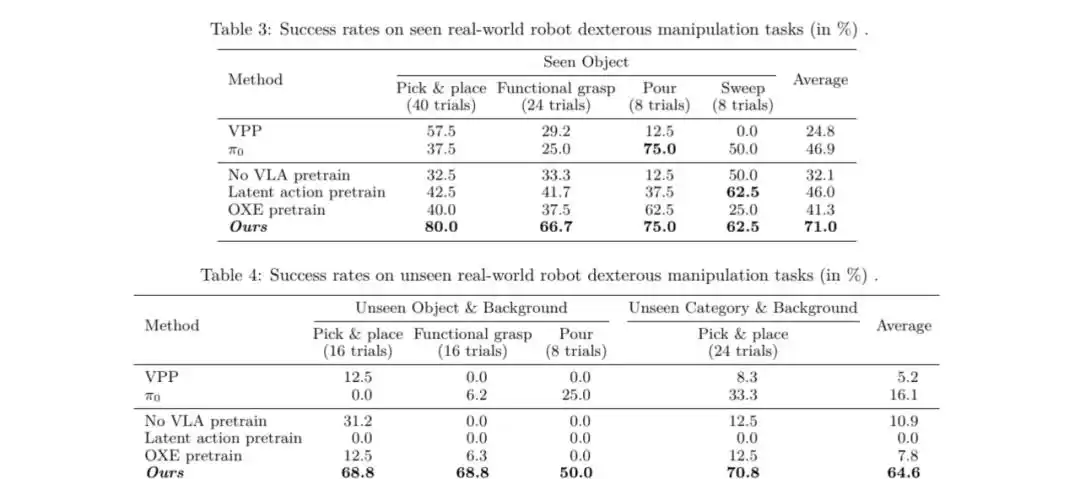
3. Operasi Cekatan Robot Nyata: Penerapan Efisien Hanya dengan Sedikit Data Fine-tuning
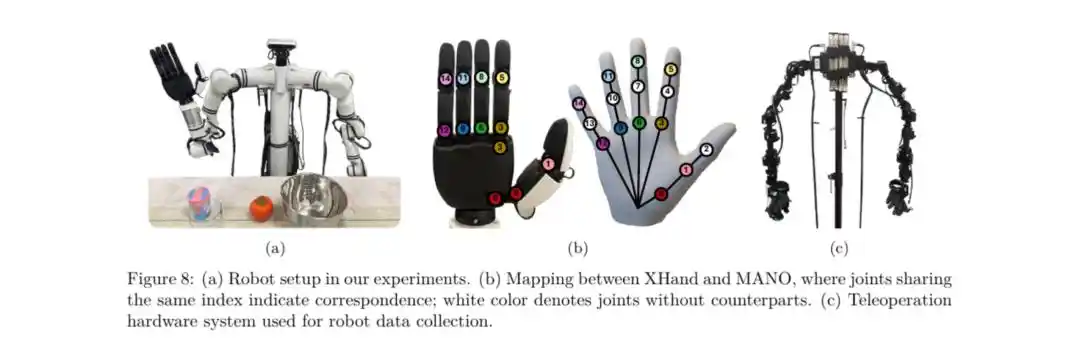
Untuk diterapkan pada robot nyata, tim penelitian menyelaraskan ruang aksi tangan manusia dengan ruang aksi tangan cekatan robot (seperti Realman yang dilengkapi dengan XHAND1 dari StarMove).
△
Hanya dengan menggunakan sedikit (sekitar 1,2 ribu) data teleoperasi robot nyata untuk fine-tuning model yang telah dipra-pelatih, robot dapat melakukan berbagai tugas operasi cekatan termasuk menggenggam, menempatkan, menuang, dan menyapu di dunia nyata.
Hasil eksperimen menunjukkan bahwa dibandingkan dengan model yang tidak dipra-pelatih dengan data VLA manusia atau model yang dipra-pelatih di dataset lain (seperti OXE, EgoDex), metode ini mencapai peningkatan signifikan dalam tingkat keberhasilan tugas, terutama ketika menghadapi objek dan latar belakang yang belum pernah dilihat sebelumnya, menunjukkan ketangguhan yang luar biasa.
Dukungan Inti Perangkat Keras untuk Penerapan VITRA di Dunia Nyata
Alasan kerangka VITRA dapat mencapai kemampuan generalisasi yang menakjubkan pada robot nyata, selain inovasi tingkat algoritma, juga tidak terlepas dari dukungan kuat dari perangkat keras dasar —
tangan cekatan lima jari penggerak langsung mandiri pertama di Tiongkok, XHAND1 dari StarMove.
Kerangka ini dan karakteristik perangkat keras XHAND1 membentuk "kolaborasi lunak-keras" yang sempurna, menunjukkan keunggulan penerapan yang tak tergantikan dalam skenario aplikasi praktis.
△
Sambungan Mulus antara URDF Presisi Tinggi dan Ruang Aksi Tangan Manusia
Terobosan inti dari kerangka VITRA terletak pada penyelarasan ruang aksi tangan manusia dengan ruang aksi tangan cekatan robot.

XHAND1 secara resmi menyediakan model URDF dengan presisi yang sangat tinggi, tidak hanya menggambarkan parameter gerak dan dinamika secara akurat, tetapi juga memetakan distribusi spasial sendi tangan manusia dengan sempurna.
Dukungan model tingkat "digital twin" ini memungkinkan VITRA pada tahap fine-tuning untuk memetakan sudut sendi manusia secara akurat ke sendi yang sesuai di XHAND1, sehingga secara signifikan mengurangi kesenjangan realitas dari video manusia ke perangkat keras nyata, dan memastikan penerapan strategi pra-pelatihan yang efisien pada perangkat keras nyata.
Arsitektur Penggerak Langsung Penuh dan Respons Frekuensi Tinggi: Menjalankan Operasi Cekatan Kompleks dengan Sempurna
Saat menjalankan tugas operasi cekatan kompleks seperti menuang dan menyapu, robot memerlukan kemampuan respons dinamis yang sangat tinggi.
Arsitektur motor penggerak langsung penuh (Direct-Drive) yang diadopsi oleh XHAND1 menyediakan fondasi perangkat keras yang paling ideal untuk algoritma ini.
Desain penggerak langsung penuh pada dasarnya menghilangkan gesekan besar, kelambanan, dan gangguan nonlinier yang disebabkan oleh reduktor tradisional, memberikan kemampuan respons dinamis yang sangat sensitif pada tangan cekatan. Hal ini memungkinkan XHAND1 untuk segera dan akurat menjalankan perintah aksi yang dikeluarkan oleh model VITRA, serta mengoperasikan berbagai objek yang belum dikenal dengan aman.
Array Sensor yang Kaya: Mereservasi Ruang untuk Persepsi Multimodal di Masa Depan
Meskipun model VITRA saat ini terutama bergantung pada input visual, array sensor yang kaya yang dilengkapi pada XHAND1 (seperti array taktil resolusi tinggi) mereservasi ruang yang luas untuk persepsi multimodal di masa depan.
Dengan menggabungkan kemampuan persepsi perangkat keras yang kuat dari XHAND1, model VLA di masa depan diharapkan dapat lebih lanjut menggabungkan umpan balik taktil, menangani tugas "langkah jari (Finger Gaits)" yang lebih halus dan kompleks.
Hukum Skala dari Ukuran Data
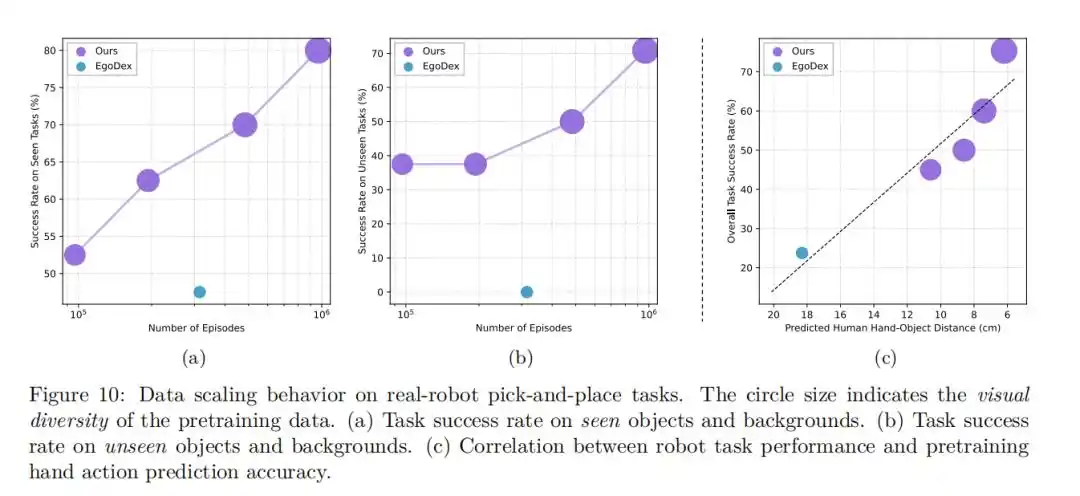
Penelitian ini juga membahas secara mendalam pengaruh skala data pra-pelatihan terhadap kinerja model.
△
Eksperimen menemukan bahwa seiring dengan peningkatan jumlah data pra-pelatihan, kesalahan model dalam tugas prediksi aksi tangan nol-sampel terus menurun, dan tingkat keberhasilan dalam tugas operasi robot nyata terus meningkat.
Perilaku skala (Scaling Behavior) yang jelas ini menunjukkan bahwa dengan lebih memperluas skala data video manusia, diharapkan dapat terus meningkatkan kinerja model VLA.
Pencapaian ini menandai terobosan kunci dalam pemanfaatan video manusia tidak terstruktur untuk pra-pelatihan model VLA robot.
Dengan menyediakan seperangkat solusi transformasi data yang sepenuhnya otomatis, penelitian ini secara signifikan menurunkan ambang batas untuk memperoleh data pelatihan robot berkualitas tinggi, membuka jalan bagi penerapan tangan cekatan multi-jari dalam skenario kompleks nyata yang lebih luas, dan meletakkan dasar yang kuat untuk menuju kecerdasan berwujud (embodied intelligence) yang benar-benar tergeneralisasi.
Tautan makalah: https://arxiv.org/abs/2510.21571
Artikel ini berasal dari akun WeChat publik "量子位", penulis: Tim VITRA






