Oleh | AIDeepDive
Hari ini, saham Zhipu AI (02513.HK), yang dijuluki "Saham Model Besar Pertama di Dunia", kembali melonjak tajam.
Lonjakan harga sahamnya di sesi intraday sempat menembus 30%. Pada penutupan perdagangan, harganya mencapai HK$1282, dengan kenaikan harian melebihi 26%, dan kapitalisasi pasarnya mencapai HK$571,57 miliar, sekali lagi mencetak rekor tertinggi sepanjang masa.
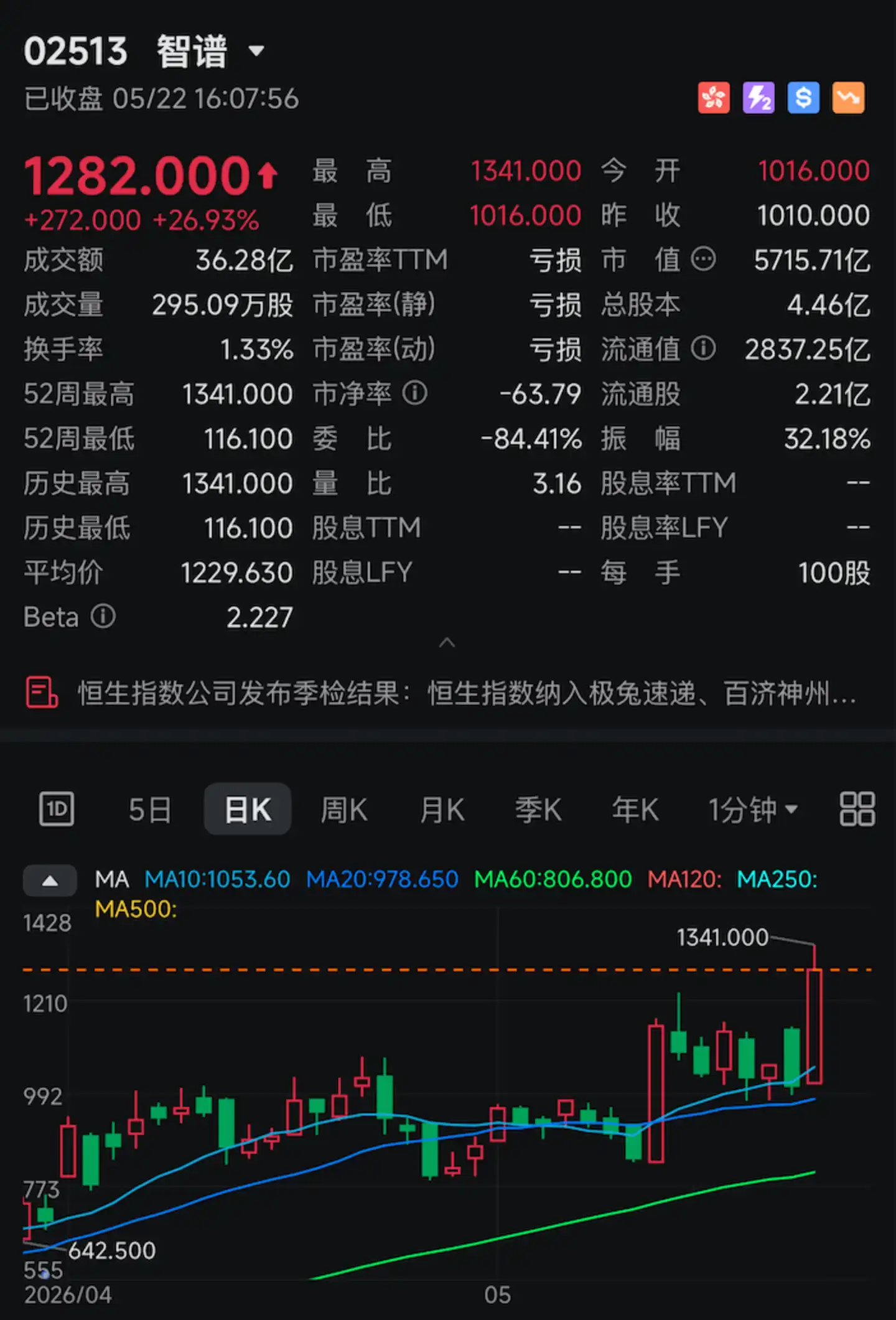
Pemicu lonjakan tajam ini adalah satu indikator teknis spesifik: 400 tokens/detik.
Pada 22 Mei, Zhipu secara resmi membuka API (GLM-5.1-highspeed) versi berkecepatan tinggi GLM-5.1 untuk klien perusahaan. Parameter inti yang paling krusial hanya satu: kecepatan keluaran model mencapai 400 token per detik, memecahkan batas atas kecepatan API dari vendor model besar global.
Awalnya saya mengira ini hanya kemasan PR dari model besar China lagi, namun setelah melihat detail teknismya dengan teliti, akhirnya saya memahami logika di balik respons pasar modal.
Apa artinya 400 tokens/detik?
Model mampu menghasilkan sekitar 200 karakter China per detik, setara dengan output intensif satu menit dari seorang penulis profesional, yang dipadatkan menjadi satu detik.
Volume teks yang membutuhkan waktu berhari-hari bagi seorang kreator untuk menulisnya, dapat diselesaikan oleh GLM-5.1 versi berkecepatan tinggi dalam 1 menit; tugas rekonstruksi sistem yang membutuhkan waktu 3 hari bagi seorang insinyur, dapat diselesaikannya dalam waktu minum secangkir kopi.
01 Kecepatan, Lebih Penting dari yang Anda Bayangkan
Kecepatan selalu menjadi dimensi yang paling mudah diabaikan dalam persaingan model AI.
Selama tiga tahun terakhir, perlombaan senjata model besar terkonsentrasi pada dua jalur: skala parameter (model yang lebih besar dan lebih pintar) dan perang harga (Token yang lebih murah dan lebih inklusif). "Cepat", tidak pernah menjadi pemeran utama.
Hal ini karena "cepat" di masa lalu biasanya dicapai dengan mengecilkan parameter model. Untuk mempercepat, harus menggunakan model yang lebih kecil dan lebih ringkas, dengan konsekuensi kemampuan yang menyusut.
Signifikansi GLM-5.1 versi berkecepatan tinggi kali ini terletak pada kemampuannya mempertahankan kemampuan basis berukuran penuh kelas flagship, sambil mendorong kecepatannya hingga 400 tokens/detik.
Baik dari sisi model domestik maupun skala internasional, untuk pertama kalinya "kemampuan flagship" dan "latensi sangat rendah yang ekstrem" berhasil dicapai tanpa kompromi.

Mengapa kecepatan begitu krusial? Karena medan perang utama AI sedang mengalami pergeseran fundamental.
Saat AI berpindah dari era ChatBot ke era Agent, tanya jawab bukan lagi skenario utama AI. Untuk menyelesaikan satu tugas, Agent seringkali membutuhkan model untuk melakukan panggilan mandiri puluhan bahkan ratusan putaran: menulis kode, menyesuaikan antarmuka, mencari informasi, memanggil alat...
Dalam mode kerja ini, jeda antara setiap putaran panggilan akan diakumulasi dan diperbesar tanpa ampun. Untuk tugas yang membutuhkan 50 putaran panggilan, jika setiap putaran menghemat 1 detik, seluruh tugas menjadi lebih cepat hampir 1 menit. Untuk asisten pemrograman AI, interaksi suara, sistem pengambilan keputusan bisnis, perbedaan seperti ini dapat menentukan hidup mati.
Dari tingkat yang lebih dalam, dalam anggaran waktu yang tetap, inferensi yang lebih cepat berarti model dapat menyelesaikan jalur penalaran yang lebih dalam, lebih banyak putaran verifikasi mandiri. Kecepatan, sedang berubah dari indikator sistem menjadi batas atas kecerdasan itu sendiri.
02 Seberapa Sulitkah Mencapai Kecepatan Ini?
Lalu, kira-kira seperti apa tingkat kecepatan di industri saat ini?
Di antara vendor terkemuka, GPT-4o dari OpenAI berkisar 100–150 tokens/detik, seri Claude Sonnet dari Anthropic sekitar 80–120 tokens/detik, API model flagship utama di dalam negeri sebagian besar berada di kisaran 50–100 tokens/detik. 400 tokens/detik kira-kira 3 hingga 5 kali lipat dari tingkat rata-rata industri.
Yang lebih krusial lagi, kesenjangan ini bukan sesuatu yang bisa ditutupi hanya dengan menambah daya komputasi.
Secara teoretis, satu server yang dilengkapi dengan 8 kartu grafis H200 mampu memindahkan data hingga 38TB per detik. Untuk GLM-5.1, menghasilkan satu token hanya membutuhkan pembacaan sekitar 42GB parameter aktivasi. Secara teori murni, seharusnya mendekati 1000 tokens/detik.
Tapi sistem di dunia nyata seringkali hanya dapat menghasilkan puluhan tokens/detik.
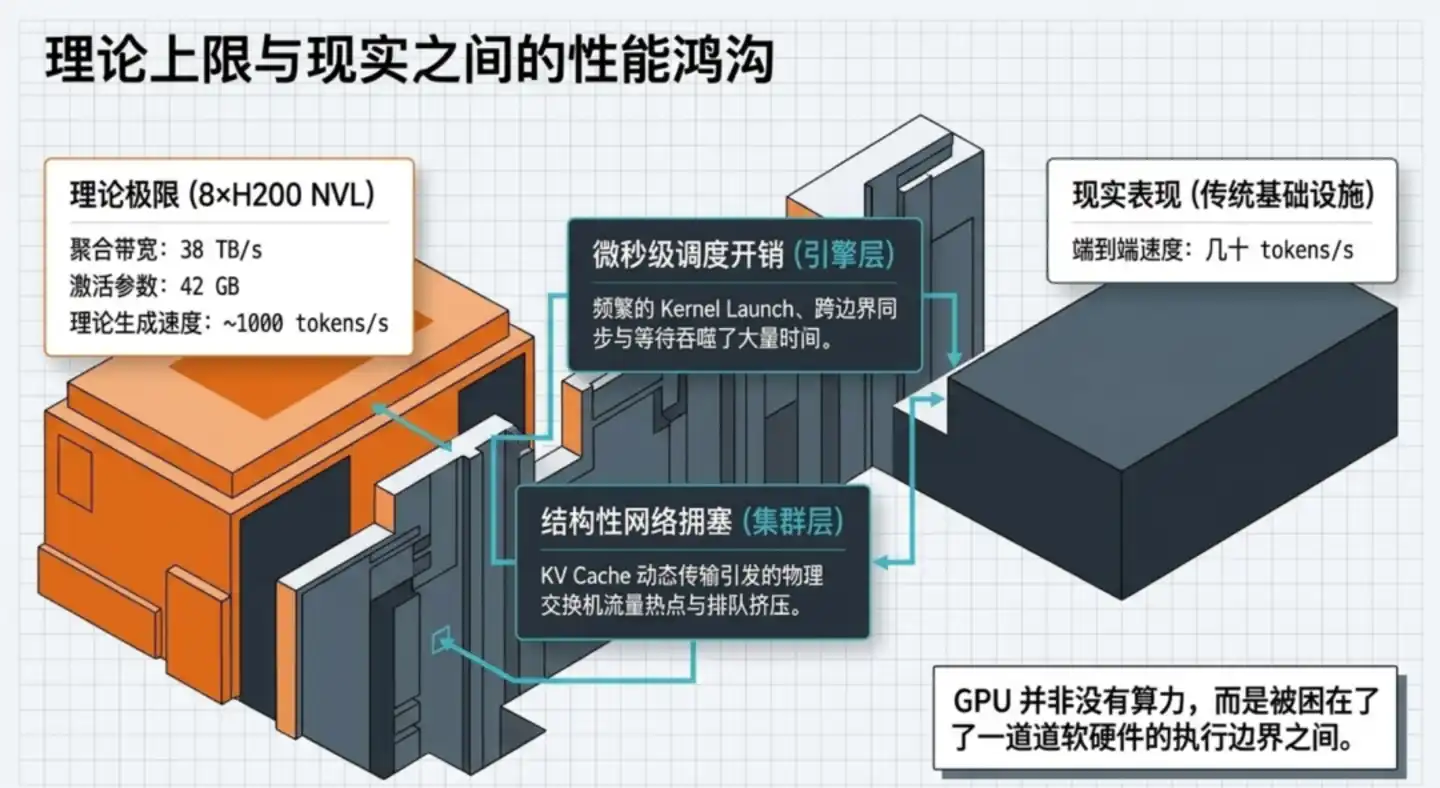
Ini adalah jurang yang sangat besar. GPU tidak cukup cepat? Bukan, melainkan banyak waktu yang terbuang untuk menunggu, menganggur, dan penjadwalan yang tidak efektif.
Zhipu kali ini berhasil mencapai terobosan kecepatan akhir melalui inovasi simultan di tiga lapisan: mesin inferensi, strategi paralel, dan arsitektur jaringan.
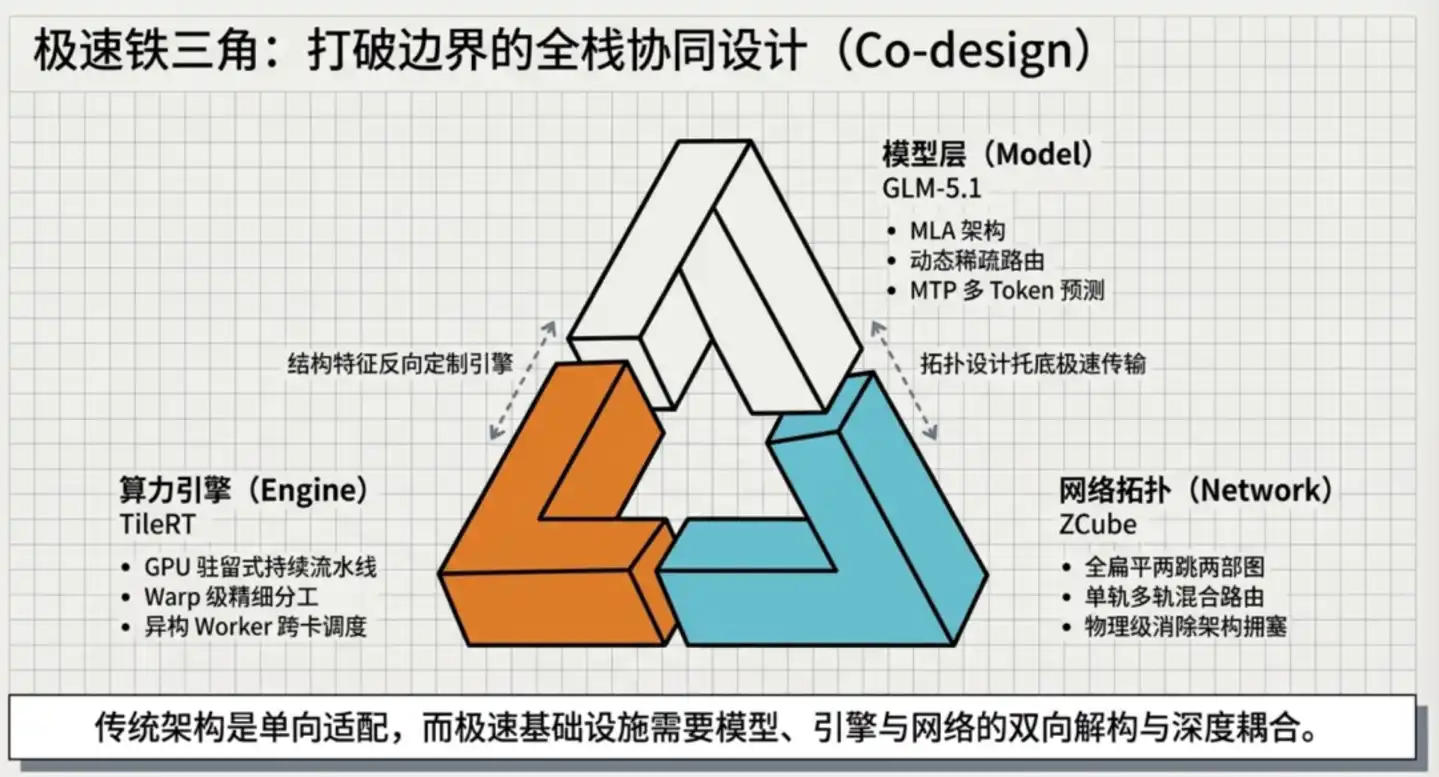
03 Tumpukan Teknologi Tiga Lapis, Mendekati Batas Fisik Perangkat Keras
Model besar awalnya beroperasi seperti ini: model besar dipecah menjadi operator independen satu per satu, setiap operator meluncurkan satu inti komputasi (kernel) secara terpisah, berhenti setelah selesai menghitung, menunggu sinkronisasi, lalu meluncurkan yang berikutnya.
Pada fase pelatihan, setiap perhitungan membutuhkan waktu beberapa detik hingga beberapa menit, overhead peluncuran dan penungguan ini sepenuhnya dapat diabaikan. Namun saat inferensi, untuk menghasilkan satu token, langkah kunci tertentu mungkin hanya membutuhkan puluhan mikrodetik, sehingga overhead peluncuran dan penungguan menjadi relatif signifikan.
Pemikiran inti TileRT: mengompilasi seluruh model menjadi satu mesin yang berjalan terus-menerus, diluncurkan sekali, tidak pernah berhenti.
TileRT pada fase kompilasi kode membuka logika komputasi seluruh model secara statis menjadi satu jalur pipa kontinu. Saat berjalan, GPU tetap beroperasi pada kecepatan tinggi, komputasi, pemindahan data, dan komunikasi berjalan paralel, hasil antara sebisa mungkin tetap berada dalam cache berkecepatan tinggi internal GPU, tidak lagi berulang kali ditulis kembali ke memori video yang lambat lalu dibaca ulang.
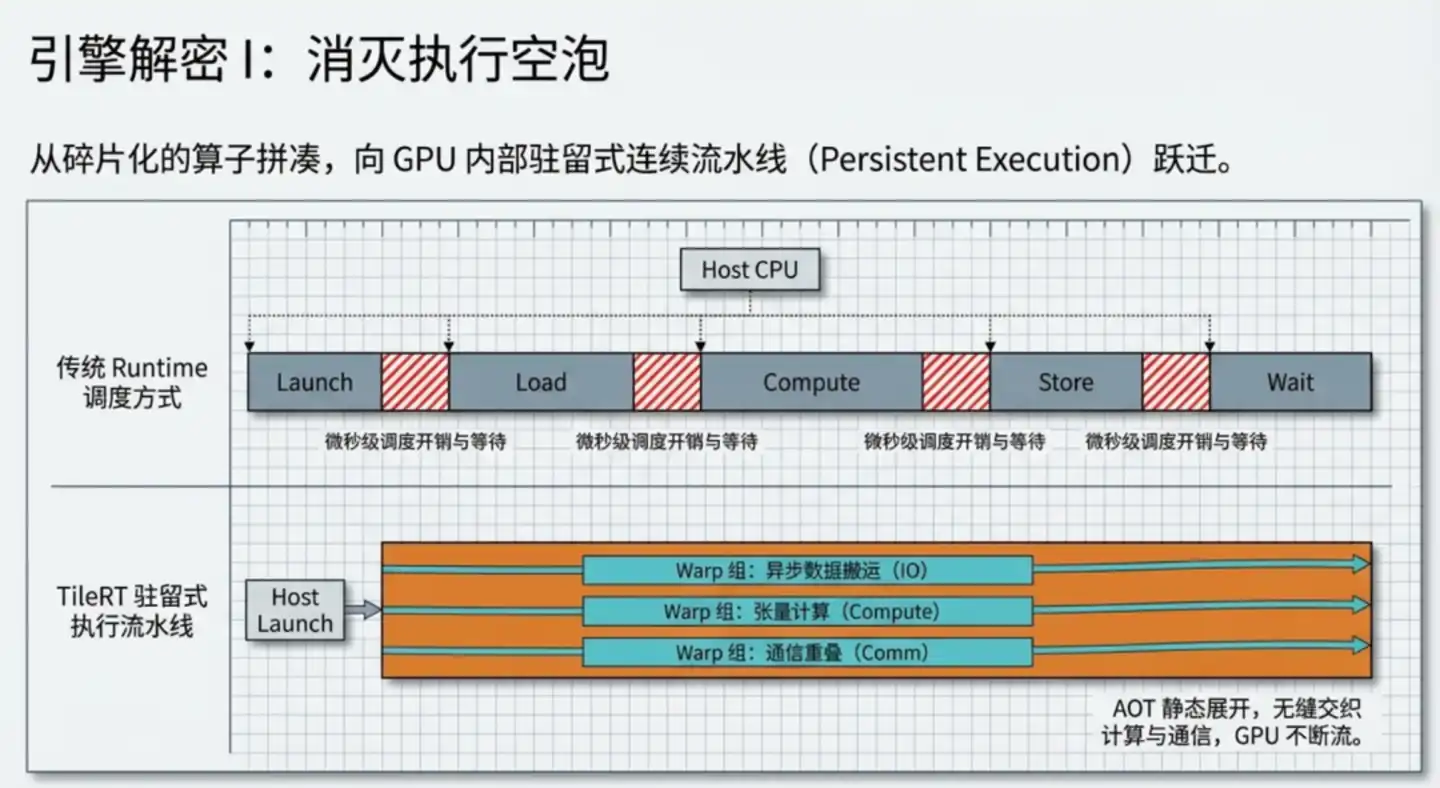
Ada satu detail desain kunci di sini: Spesialisasi Warp.
Memahami Warp, perlu memahami cara kerja GPU terlebih dahulu. Perbedaan terbesar GPU dengan CPU adalah bahwa GPU memiliki ribuan unit komputasi yang relatif sederhana di dalamnya. Unit-unit ini dibundel menjadi kelompok 32 unit, kelompok ini disebut Warp.
32 unit dalam Warp yang sama harus selalu bertindak serempak, menjalankan instruksi yang sama, seperti satu regu dalam tentara, komandan regu memberi perintah semua orang melakukan gerakan yang sama secara bersamaan.
Dalam kerangka kerja tradisional, semua Warp menjalankan urutan instruksi yang sama; TileRT membuat kelompok Warp yang berbeda menangani tanggung jawab berbeda: satu bagian khusus bertanggung jawab memindahkan data batch berikutnya terlebih dahulu, satu bagian khusus bertanggung jawab komputasi matematika, satu bagian khusus bertanggung jawab komunikasi dengan GPU lain. Tiga kelompok bekerja bersamaan, pipa berkoordinasi, saling tidak menunggu.
Seperti analogi dari "satu pekerja memindahkan batu bata, memasang dinding, memeriksa secara serial", berubah menjadi "kelompok pemindah batu bata, kelompok pemasang dinding, kelompok pemeriksa berputar bersamaan".
Efisiensi internal satu kartu terselesaikan, paralel multi-kartu menghadapi tantangan baru.
Praktik umum industri adalah Paralel Tensor (Tensor Parallel): Membagi matriks bobot model menjadi beberapa bagian, setiap GPU bertanggung jawab atas satu bagian, setelah masing-masing selesai menghitung, hasilnya dikumpulkan melalui interkoneksi berkecepatan tinggi (NVLink).
Skema ini efektif untuk komputasi padat yang teratur seperti perkalian matriks, dan merupakan skema multi-kartu standar untuk hampir semua kerangka kerja inferensi model besar saat ini.
GLM-5.1 mengadopsi MLA (Multi-head Latent Attention, Atensi Potensial Multi-kepala), ini adalah mekanisme atensi yang diusulkan oleh DeepSeek.
Mekanisme atensi tradisional perlu menyimpan banyak data antara (KV Cache) dari setiap langkah perhitungan secara lengkap untuk digunakan nanti, sangat boros memori video; Cara MLA adalah mengompresi data antara ini menjadi "vektor potensial" yang kompak terlebih dahulu, lalu menyimpannya, saat digunakan baru dibuka dan dikembalikan, kebutuhan memori video turun drastis, efisiensi inferensi lebih tinggi.
Tapi ada satu bagian khusus dalam alur komputasi MLA: perlu melakukan pengindeksan jarang (sparse indexing) dari sejumlah besar informasi historis: mirip dengan dengan cepat mencari beberapa buku yang paling relevan di perpustakaan besar terlebih dahulu, baru membaca buku-buku itu dengan teliti.
Langkah "mencari buku" ini bergantung pada informasi global, tidak cocok untuk dibagi rata ke beberapa kartu; "Membaca teliti" adalah komputasi padat yang cocok untuk paralel multi-kartu. Jika memaksa semua 8 GPU berpartisipasi dalam "mencari buku", banyak waktu akan terbuang untuk komunikasi sinkron antar GPU.
Solusi TileRT adalah menjalankan GPU secara heterogen: GPU 0 khusus berperan sebagai "petugas pencarian perpustakaan", bertanggung jawab atas pengindeksan jarang dan keputusan perutean; GPU 1–7 berperan sebagai "analis pembaca teliti", bertanggung jawab atas komputasi atensi dan operasi matriks yang padat. Dua jenis pekerja bekerja sama dengan strategi paralel yang paling sesuai untuk masing-masing untuk menyelesaikan seluruh lapisan komputasi.
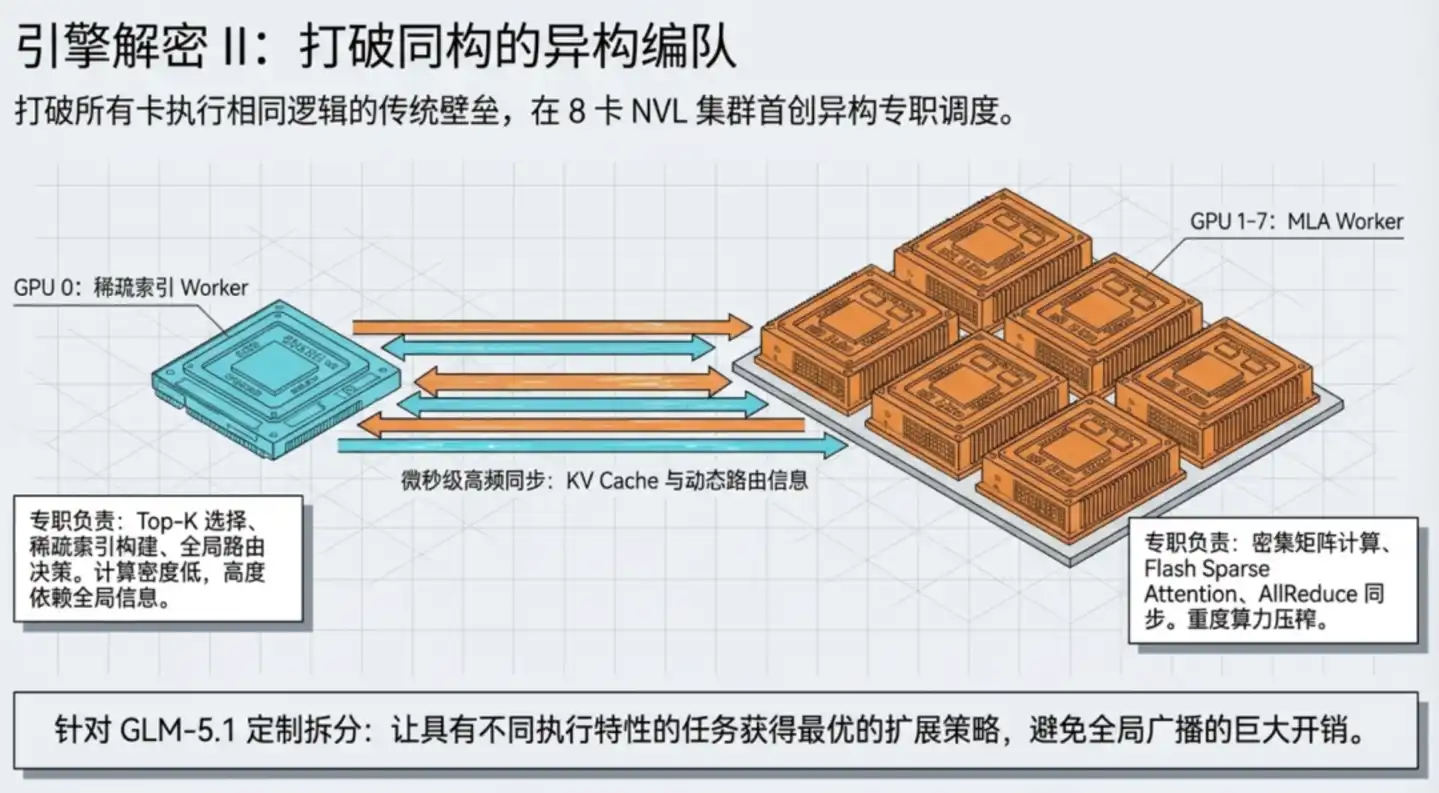
Selanjutnya, TileRT menanamkan operasi komunikasi antar GPU langsung ke dalam jalur pipa eksekusi, tidak lagi sebagai langkah independen. Dari luar, seluruh sistem 8 kartu menyelesaikan komputasi satu lapisan atensi hanya membutuhkan satu peluncuran kernel, komunikasi dan komputasi internal semuanya diselesaikan secara mulus di dalam pipa kontinu.
Dua lapisan di atas menyelesaikan masalah dalam lingkup satu mesin. Ketika klaster diperluas ke ratusan bahkan ribuan GPU, transmisi data antar GPU itu sendiri menjadi langit-langit baru.
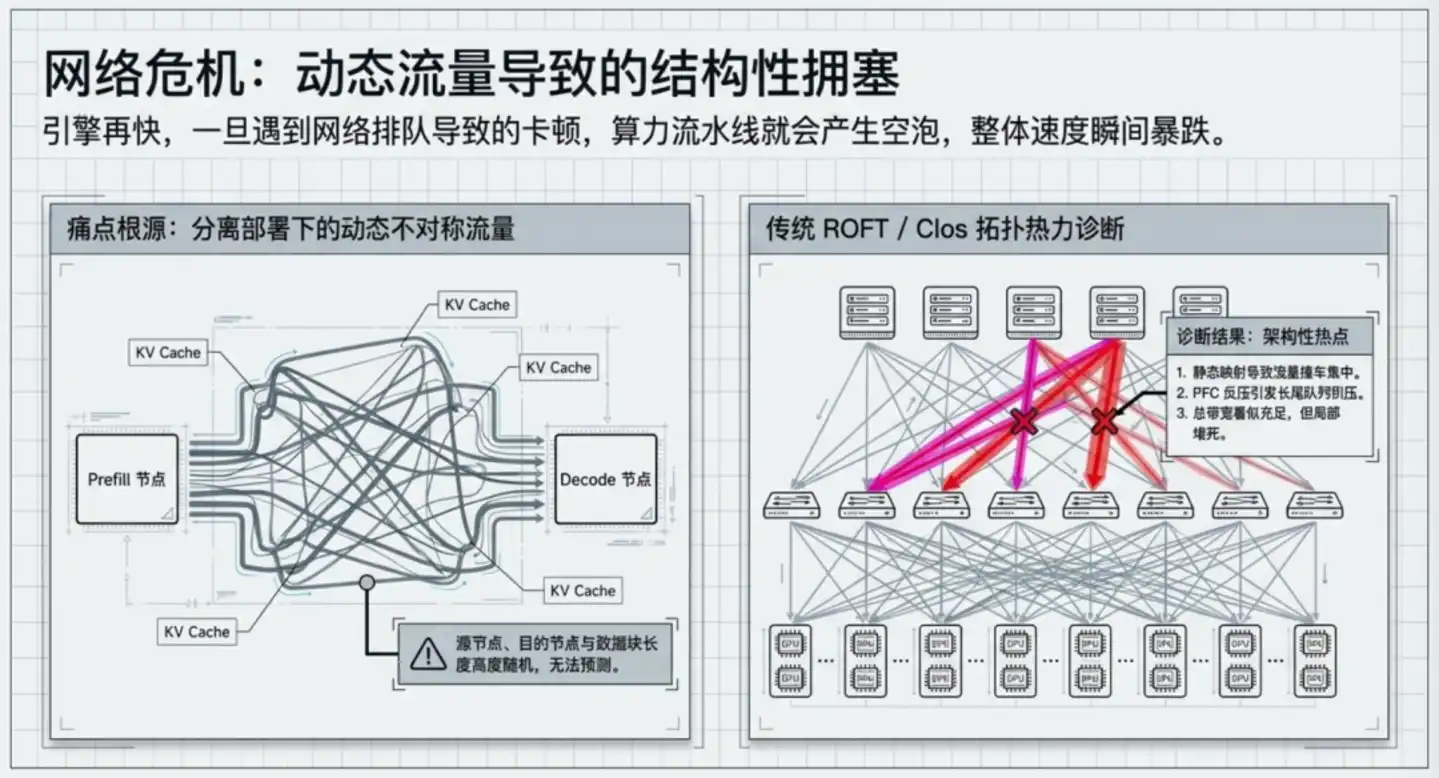
Praktik umum industri adalah ROFT (Rail-Optimized Fat-Tree), ini adalah skema yang direkomendasikan resmi oleh NVIDIA, standar absolut industri.
Strukturnya seperti pohon: server terhubung ke switch Leaf (lapisan akses, langsung menghadap server), Leaf kemudian terhubung ke atas ke switch Spine (lapisan tulang punggung, bertanggung jawab atas interkoneksi antar Leaf, seperti hub jalan raya). Data yang ditransmisikan antara dua GPU, harus "naik ke Spine terlebih dahulu, lalu turun ke Leaf target", setidaknya melewati 3 hop.
Untuk menghindari lalu lintas terkonsentrasi di beberapa jalur, arsitektur ini bergantung pada algoritma ECMP untuk mendistribusikan data di antara beberapa jalur, berjalan baik dengan asumsi lalu lintas internet "statistik seragam".
Tapi lalu lintas skenario inferensi tidak seragam sama sekali. Panjang konteks permintaan yang berbeda dapat mencapai puluhan kali lipat, arah transmisi KV Cache antar GPU hampir acak, beberapa switch Leaf akan secara berkala menjadi hotspot, memicu mekanisme backpressure, menyebarkan kemacetan dari lokal ke seluruh tautan. Kemacetan ini bukan sesuatu yang bisa diselesaikan dengan penyesuaian parameter protokol, itu adalah produk dari struktur topologi itu sendiri.
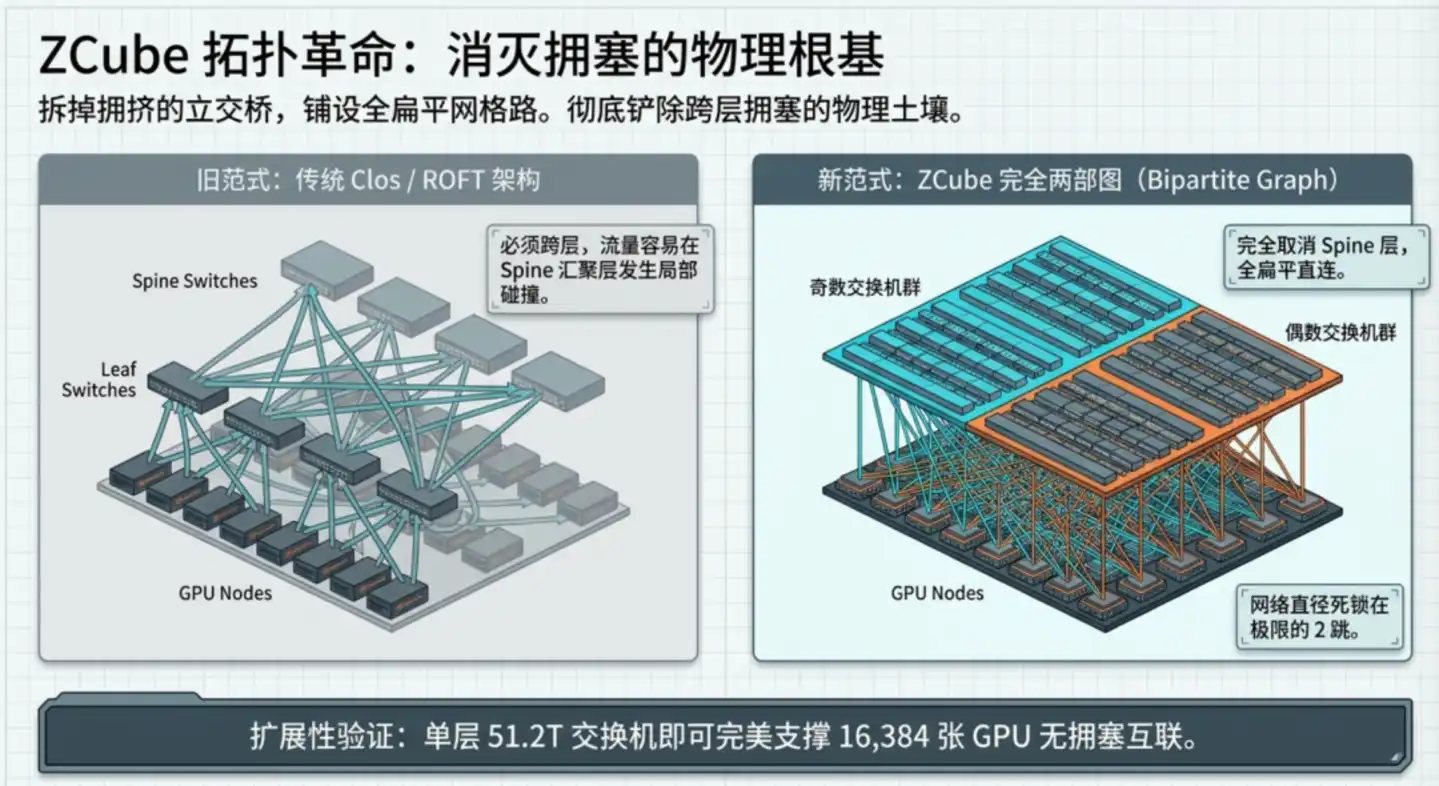
Terobosan mendasar ZCube: Dari tingkat arsitektur membuat kemacetan seperti ini secara fisik tidak mungkin terjadi.
Desain inti dibagi dua langkah:
Langkah pertama, menghapus lapisan tulang punggung Spine, meratakan seluruh jaringan. Membagi semua switch Leaf menjadi dua kelompok berdasarkan penomoran ganjil-genap, dua kelompok tersebut saling terhubung sepenuhnya, switch ganjil mana pun terhubung ke semua switch genap, begitu pula sebaliknya. Setiap dua GPU dapat saling mencapai melalui maksimal dua switch, hop berkurang dari 3 hop menjadi 2 hop.
Langkah kedua, juga yang paling cerdik: Kartu jaringan setiap GPU menggunakan dua cara yang sangat berbeda untuk terhubung ke dua kelompok switch secara terpisah. Topologi khusus ini membawa satu sifat matematika kunci: Di seluruh jaringan, antara setiap dua GPU, ada satu dan hanya satu jalur optimal.
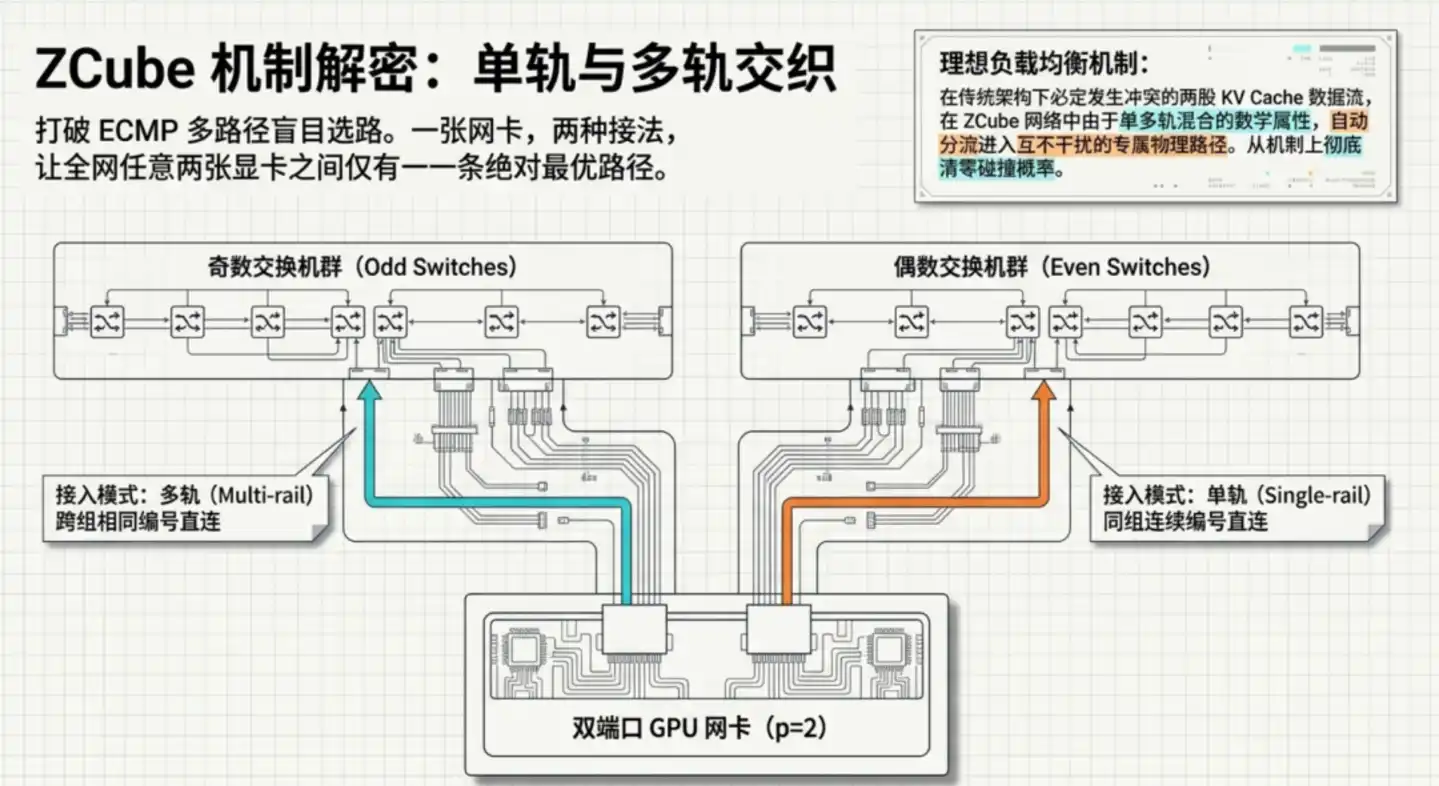
"Jalur tunggal" langsung menghilangkan akar penyebab kemacetan. Arsitektur tradisional mudah menjadi hotspot, justru karena ada banyak jalur yang dapat dipilih, algoritma penyeimbang beban jika salah memilih akan menyebabkan lalu lintas terkonsentrasi. ZCube dalam desainnya menghilangkan "pemilihan" itu sendiri: tidak perlu penyeimbangan, karena tidak ada persimpangan jalan sama sekali.
04 Dengan Kondisi Perangkat Keras yang Sama, Bagaimana Perhitungannya?
Setelah meningkatkan klaster produksi GLM-5.1 dari ROFT tradisional ke ZCube, Zhipu mendapatkan tiga angka:
Ringkasnya, dengan investasi GPU yang sama, klaster dapat melayani lebih banyak pengguna; dengan persyaratan pengalaman pengguna yang sama, klaster dapat membeli sepertiga lebih sedikit perangkat jaringan. Efisiensi dan biaya meningkat dua arah.
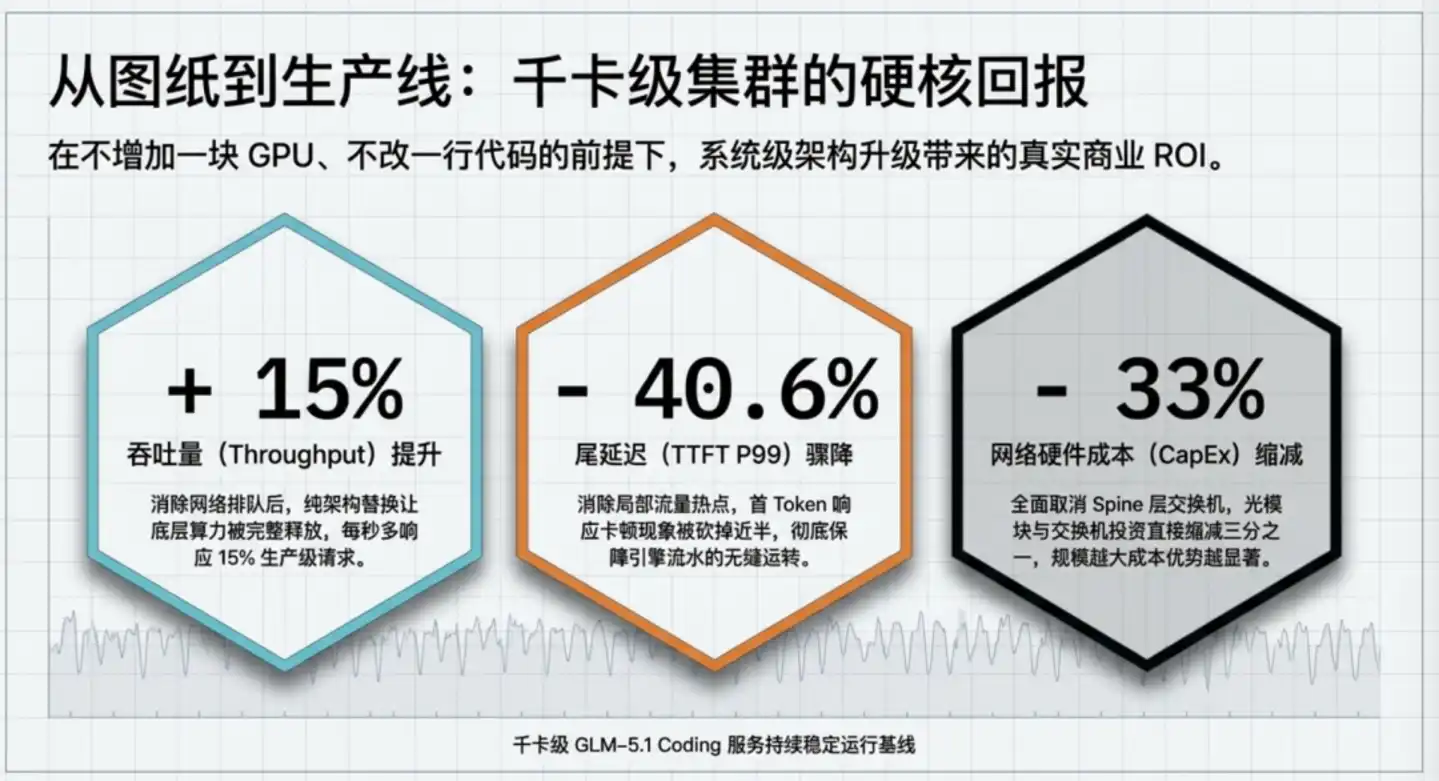
Secara spesifik, throughput meningkat 15%, setara dengan mendapatkan tambahan daya komputasi 15% secara gratis. Dengan jumlah GPU yang tidak berubah, throughput bertambah 15%, setara dengan biaya perangkat keras per token turun sekitar 13%, atau dengan biaya yang sama dapat melayani 15% lebih banyak pengguna.
Jika sebuah klaster memiliki 1000 GPU, peningkatan ini setara dengan mendapatkan tambahan kapasitas 150 kartu secara cuma-cuma. Berdasarkan harga pasar kartu inferensi kelas atas saat ini, ini adalah nilai daya komputasi miliaran yuan.
Penurunan latensi ekor 40,6%, menyelesaikan masalah stabilitas bukan kecepatan rata-rata. Sebuah tugas Agent yang membutuhkan 50 putaran panggilan, jika latensi ekor berkurang 1 detik setiap kali, waktu penyelesaian terburuk seluruh tugas dikompresi hampir 1 menit.
Pengurangan biaya sepertiga, adalah penghematan langsung di tingkat pembangunan. ZCube menghapus lapisan Spine, dalam skala klaster yang sama, jumlah switch dan modul optik yang dibutuhkan langsung berkurang sepertiga. Menurut perhitungan Zhipu, dalam klaster skala sepuluh ribu kartu, hanya item ini saja dapat menghemat sekitar 2,1 hingga 6,4 miliar yuan.
Dari perspektif jangka panjang, seiring dengan meningkatnya skala klaster secara eksponensial, kompleksitas komunikasi antar GPU bertambah berkali-kali lipat, kemungkinan dan dampak kemacetan juga meningkat. Ini berarti nilai inovasi tingkat arsitektur seperti ZCube akan semakin terlihat dengan ekspansi berkelanjutan klaster inferensi. Besok, keuntungan klaster level sepuluh ribu kartu mungkin lebih dari 15% hari ini.
05 Penutup
Setelah membaca laporan teknis Zhipu, saya berpikir, apakah ini akan seperti kemunculan mendadak DeepSeek, membawa badai bagi industri?
Setelah dipikir-pikir, pengaruh keduanya sepertinya berada di aspek yang berbeda. Saat DeepSeek muncul, yang dibuktikannya adalah, kecerdasan yang sama, dapat diwujudkan dengan daya komputasi yang jauh lebih sedikit. Pasar khawatir "GPU yang dibutuhkan menjadi lebih sedikit", sehingga kapitalisasi pasar NVIDIA hari itu menguap hampir 600 miliar dolar AS.
Tapi teknologi Zhipu hari ini membuktikan: dengan daya komputasi yang sama, dapat menghasilkan lebih banyak. Ini merekonstruksi "seperti apa seharusnya infrastruktur lain di luar GPU".
Dalam jangka pendek, NVIDIA tidak akan terpengaruh, tetapi dalam jangka panjang, parit pertahanan GPU + interkoneksi NVLink + jaringan InfiniBand + ekosistem perangkat lunak CUDA sedang "dilonggarkan", terutama InfiniBand yang dibeli NVIDIA dengan akuisisi Mellanox senilai 6,9 miliar dolar AS pada tahun 2019, premium sisi jaringan NVIDIA akan sangat terkikis.
Selain itu, ZCube menghapus lapisan Spine, tetapi justru menuntut kepadatan port switch Leaf yang lebih tinggi. Yang diuntungkan adalah vendor yang mampu membuat switch Leaf berdensitas tinggi, port besar (Ruijie, Arista, chip switch Broadcom), yang dirugikan adalah vendor yang terutama mengandalkan switch kelas atas lapisan Spine untuk mendapatkan premium.
Pada tahun 2025, Celestica dan NVIDIA bersama-sama menguasai sekitar 50% pangsa pasar switch jaringan backend AI, pola ini akan menghadapi perombakan ulang setelah paradigma ZCube menyebar.
Modul optik adalah arah yang paling langsung diuntungkan dalam perubahan rantai industri kali ini, logikanya sangat jelas. Bagi produsen modul optik domestik (seperti InnoLight, TFC, dll.), ini adalah dorongan struktural: tidak hanya total volume meningkat, tetapi juga permintaan modul optik berkecepatan tinggi (800G, 1.6T) dalam paradigma ZCube lebih terkonsentrasi dan mendesak dibandingkan arsitektur tradisional.
Baik arsitektur TileRT maupun ZCube, ini adalah set mesin inferensi perangkat lunak murni yang berjalan di atas GPU standar, tidak bergantung pada fitur perangkat keras NVIDIA yang bersifat pribadi, secara teori dapat dipindahkan ke chip domestik seperti Huawei Ascend. Arah ini jika dapat diwujudkan, akan secara signifikan menurunkan ambang batas tumpukan perangkat lunak chip AI domestik dalam skenario inferensi.
Ini mungkin makna yang lebih besar di balik inovasi teknologi ini.







