Beberapa waktu lalu, Anthropic menerbitkan sebuah artikel berjudul "When AI Builds Itself" (Ketika AI Membangun Dirinya Sendiri), yang dengan cepat memicu diskusi luas. Artikel tersebut mengungkapkan seperangkat data internal yang mengejutkan: Hingga Mei 2026, lebih dari 80% kode dalam basis kode Anthropic telah ditulis oleh Claude, jumlah kode yang digabungkan oleh insinyur setiap hari adalah 8 kali lipat dari tahun 2024; dalam sebuah tes internal, Claude meningkatkan kecepatan eksekusi sepotong kode pelatihan sekitar 52 kali dari benchmark, sementara seorang peneliti manusia yang berpengalaman biasanya membutuhkan 4 hingga 8 jam untuk mencapai percepatan 4 kali lipat.
Anthropic mengarahkan lintasan ini ke tujuan yang lebih dalam: "Peningkatan Diri Rekursif" — sistem AI merancang, membangun, dan melatih versi penerusnya sendiri secara mandiri, manusia tidak lagi menggerakkan setiap langkah. Patut dicatat, perusahaan tersebut juga menyerukan koordinasi industri, untuk memiliki opsi menunda atau bahkan menghentikan sementara pengembangan AI terdepan saat momen peningkatan diri rekursif tiba. Dan Anthropic sudah melakukannya: membatasi penggunaan Claude Fable 5 terbaru untuk penelitian dan pengembangan AI terdepan.
Dan sekarang, Recursive Superintelligence mengumumkan telah melangkahkan langkah pertama menuju penelitian AI otomatis.
Perusahaan baru yang didirikan bersama oleh Tian Yuandong ini baru saja keluar dari mode siluman hanya sebulan yang lalu, dan kini telah merilis hasil teknis publik pertamanya. Mereka menciptakan sistem penemuan pengetahuan otomatis terbuka, dan mencapai hasil SOTA pada tiga benchmark pengujian. Singkatnya, mereka berhasil membuat AI menjalankan eksperimen untuk Anda.

https://x.com/tydsh/status/2065062838255649082
Hasil Langkah Pertama: Membuat AI Menjalankan Eksperimen untuk Anda
Hasil teknis publik pertama Recursive ini bernama "First Steps Toward Automated AI Research" (Langkah Pertama Menuju Penelitian AI Otomatis).

Tweet: https://x.com/Recursive_SI/status/2064980090702962699
Alamat repositori: https://github.com/recursive-org/first-steps-toward-automated-ai-research
Alamat blog: https://www.recursive.com/articles/first-steps-toward-automated-ai-research
Jika disimpulkan dalam satu kalimat, inti dari pekerjaan ini adalah: membangun sistem yang dapat secara mandiri memajukan siklus penelitian AI, dan memperbarui rekor terbaik pada tiga benchmark pengujian.
Sebelum membongkar hasilnya secara formal, perlu dipahami terlebih dahulu logika desain sistem ini.
Alur penelitian AI tradisional adalah loop "mengusulkan ide — menulis kode — menjalankan eksperimen — menganalisis hasil — mengusulkan ide lagi" yang sangat bergantung pada manusia. Efisiensi bottlenecknya tidak pada komputasi, tapi pada manusia. Peneliti yang dapat merancang alur pelatihan terdepan di seluruh dunia dapat dihitung dengan jari, dan setiap iterasi eksperimen membutuhkan intervensi tinggi dari mereka.
Sistem Recursive mencoba mengotomatisasi loop ini.
Cara kerjanya adalah: Untuk tujuan optimasi yang jelas, sistem secara otomatis mengusulkan ide eksperimen, mengimplementasikan kode, menjalankan verifikasi, belajar darinya, lalu memutuskan langkah pencarian selanjutnya. Beberapa jalur penelitian dapat dilanjutkan secara paralel, temuan yang efektif dapat digunakan kembali lintas tugas, dan mekanisme deteksi kecurangan reward (reward hacking) juga tertanam di seluruh siklus, untuk mencegah sistem "mencari jalan pintas" dengan meningkatkan metrik evaluasi tanpa benar-benar memperbaiki apapun.
Ini bukanlah alat khusus yang disesuaikan untuk satu masalah, melainkan kerangka kerja otomatisasi penelitian umum lintas domain. Recursive membuktikannya dengan tiga skenario pengujian yang sangat berbeda.
Tiga Medan Pertempuran, Tiga Rekor Baru
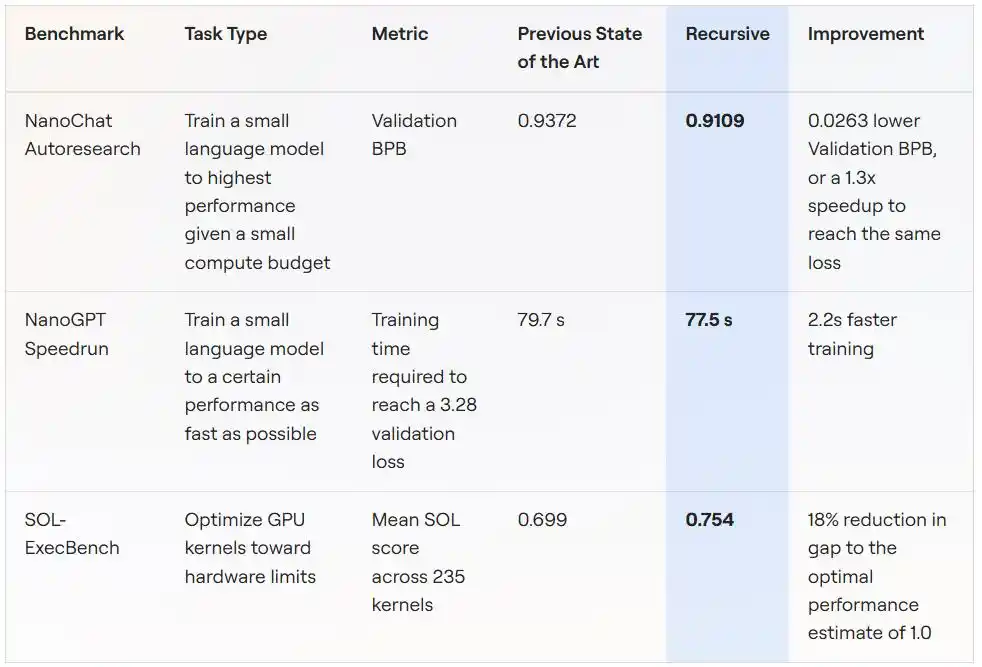
Skenario satu: Pelatihan model kecil dengan anggaran komputasi tetap (NanoChat Autoresearch)
Aturan benchmark ini berasal dari proyek autoresearch yang diluncurkan oleh Andrej Karpathy (penulis GPT-2, mantan co-founder OpenAI): pada satu GPU, dengan anggaran pelatihan tetap lima menit, melatih model bahasa kecil hingga mencapai loss validasi serendah mungkin (diukur dalam BPB, semakin rendah semakin baik).
Skenario ini secara alami cocok untuk penelitian otomatis: siklus eksperimen pendek, varians metrik rendah, perilaku curang relatif mudah dideteksi. Justru karena itu, sebuah proyek komunitas bernama "autoresearch@home" telah berjalan cukup lama pada benchmark ini — puluhan peneliti manusia bersama ratusan agen AI berkolaborasi, terus menekan metrik ke bawah.
Sistem Recursive berangkat dari kode awal yang sama, akhirnya mendorong BPB validasi dari yang terbaik di komunitas 0.9372 menjadi 0.9109, meningkat sebesar 0.0263 BPB. Dengan kata lain: kualitas pelatihan yang sama, solusi Recursive hanya membutuhkan waktu pelatihan 1.3 kali lebih sedikit dari lawan untuk mencapainya.
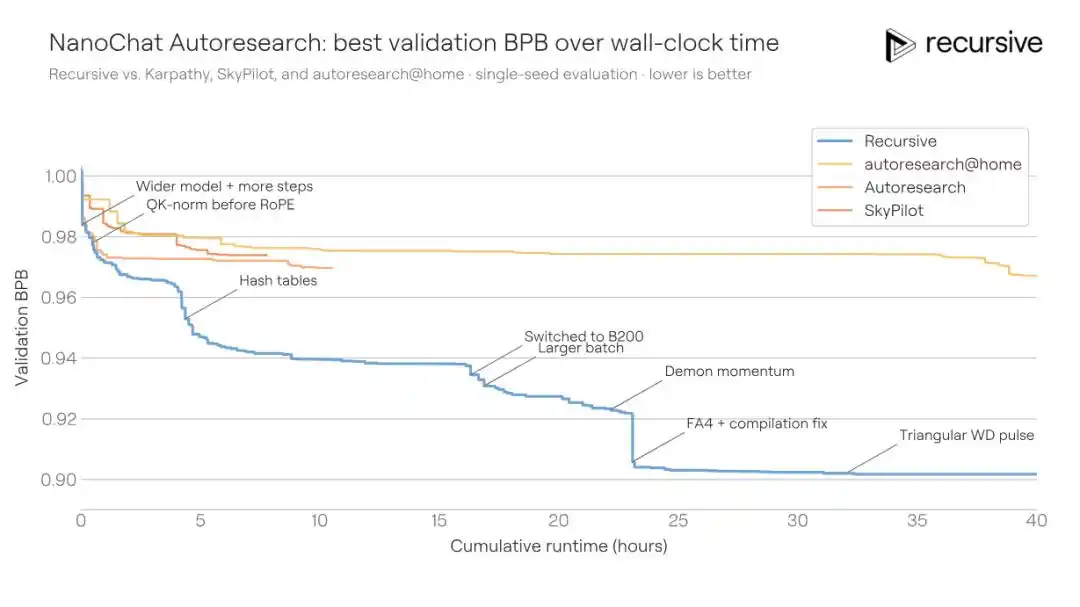
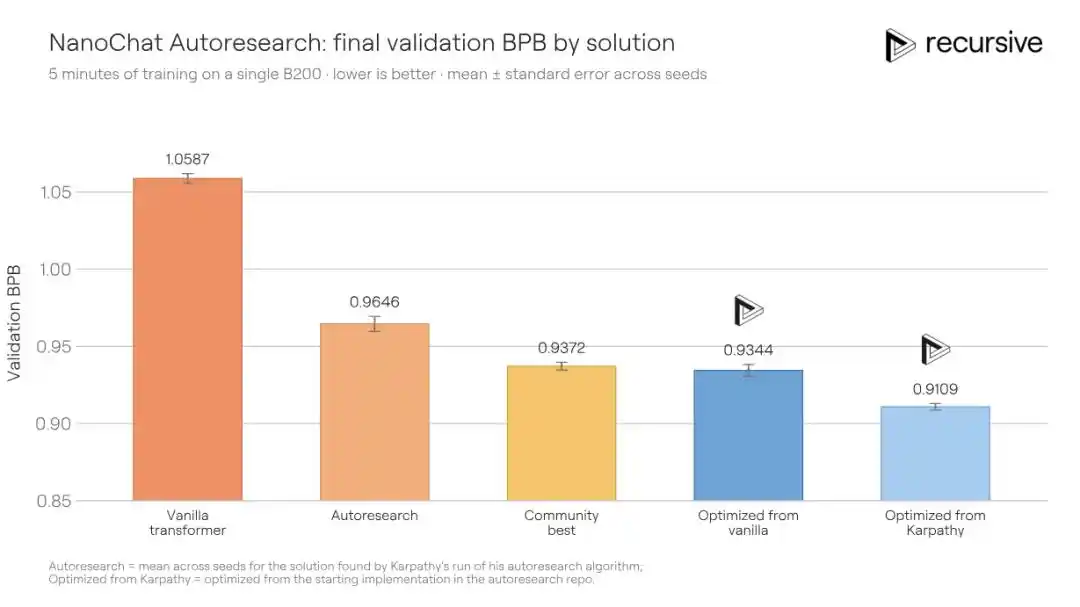
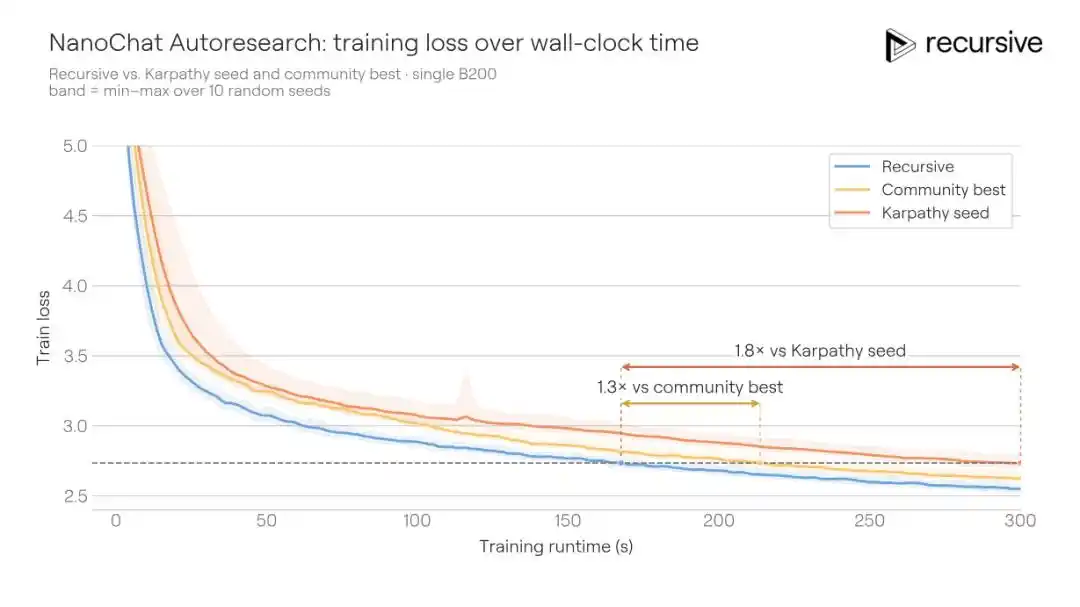
Peningkatan yang ditemukan sistem bukanlah kemenangan satu pukulan. Ia menggabungkan berbagai perubahan seperti penyesuaian arsitektur, loss tambahan, modifikasi mekanisme perhatian, perilaku pengoptimal, penjadwalan weight decay, pengaturan kompiler, dan lainnya. Salah satu penemuan kuncinya adalah mekanisme memori konteks pendek yang lebih kaya: dalam jalur value perhatian, mengembed informasi bigram (pasangan kata berdekatan) dan trigram (tiga serangkai) secara bersamaan melalui tabel hash, dan mencampurnya dengan bobot gating yang dapat dipelajari. Lapisan Transformer yang berbeda menggunakan fungsi hash yang berbeda, sehingga mengurangi kemungkinan tabrakan berulang antar lapisan.
Trik ini terkait secara konseptual dengan karya-karya seperti DeepSeek Engram, tetapi sistem menerapkannya dalam varian spesifik yang belum terlihat dalam literatur publik ke skenario anggaran tetap.
Skenario dua: Balapan kecepatan pelatihan ekstrem (NanoGPT Speedrun)
Jika skenario sebelumnya adalah "satu langkah lebih maju" di atas hasil komunitas yang aktif, skenario ini jauh lebih sulit.
NanoGPT Speedrun adalah benchmark lain yang diluncurkan oleh Karpathy dan telah dioptimalkan oleh komunitas selama lebih dari dua tahun: pada 8 GPU H100, waktu terpendek yang dibutuhkan untuk melatih model GPT hingga mencapai loss validasi 3.28. Sejak pertengahan 2024, komunitas telah memampatkan waktu dari sekitar 45 menit menjadi 79,7 detik melalui 83 kontribusi yang tercatat. Setiap skema baru perlu memeras waktu lagi di atas kode yang sudah sangat teroptimalkan, sulit dibayangkan.
Sistem Recursive berangkat dari solusi optimal yang ada, kembali memampatkan waktu pelatihan menjadi 77,5 detik, menghemat 2,2 detik. Ini setara atau bahkan lebih baik dari peningkatan yang dapat dilakukan oleh kontributor manusia baru-baru ini.
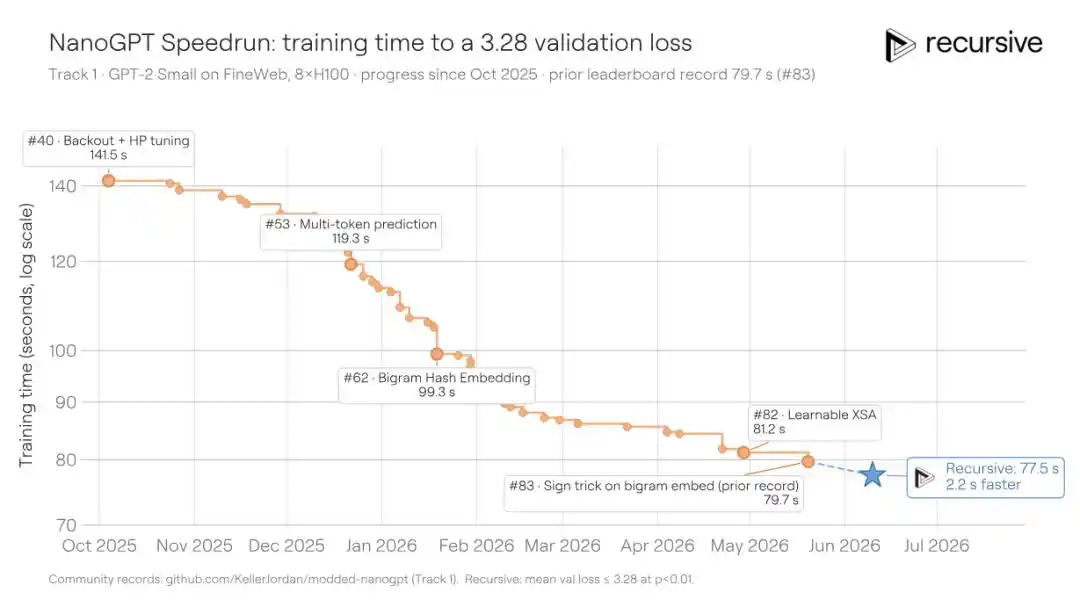
Kunci trik yang ditemukan sistem kali ini termasuk:
Perhitungan perhatian presisi FP8. Skema komunitas hanya menggunakan komputasi FP8 (floating point 8-bit) di lapisan terakhir model (kepala model bahasa), sedangkan sistem memperluas FP8 ke dalam operasi matriks lapisan perhatian, propagasi maju menggunakan FP8 untuk mendapatkan throughput Tensor Core dua kali lipat, propagasi mundur mempertahankan BF16 untuk menjaga stabilitas.
Noise eksplorasi annealing dalam pengoptimal. Sistem menyuntikkan noise Gaussian rata-rata nol ke dalam langkah pembaruan pengoptimal NorMuon, dengan amplitudo noise berkurang secara linear hingga nol seiring kemajuan pelatihan. Ini agak mirip memberi pengoptimal pola perilaku "berani bereksplorasi dulu, lalu konvergen dengan stabil", membantu solusi akhir jatuh pada cekungan loss yang lebih datar.
Kernel MLP fused yang lebih ramping. Sistem menulis ulang sebuah kernel GPU Triton, membuat propagasi maju hanya menyimpan nilai aktivasi setelah ReLU dikuadratkan, dan saat propagasi mundur menghitung ulang hasil antara yang belum dikuadratkan di dalam kernel, menghemat satu kali bolak-balik baca/tulis tensor aktivasi penuh dalam memori bandwidth tinggi — ini adalah percepatan langsung di tingkat perangkat keras.
Tiga peningkatan, masing-masing dari tiga bidang keahlian berbeda: strategi presisi, desain pengoptimal, dan pemrograman kernel GPU. Sistem menemukan ruang lagi di atas hasil optimasi komunitas dua tahun, itu sendiri sudah menjelaskan masalahnya.
Skenario tiga: Optimasi kernel GPU (SOL-ExecBench)
Dua skenario sebelumnya bekerja pada level pelatihan model, skenario ketiga ini masuk lebih dalam: optimasi kernel komputasi GPU.
SOL-ExecBench adalah benchmark yang dikeluarkan oleh NVIDIA, berisi 235 tugas penulisan kernel, mencakup berbagai beban kerja nyata seperti perkalian matriks, reduksi, lapisan normalisasi, komponen perhatian, rutin kuantisasi, blok fused, dan lainnya. Standar penilaian adalah skor SOL: 0,5 sesuai implementasi PyTorch dasar, 1,0 sesuai batas teoretis perangkat keras. Hasil publik terbaik sebelumnya adalah 0,699.
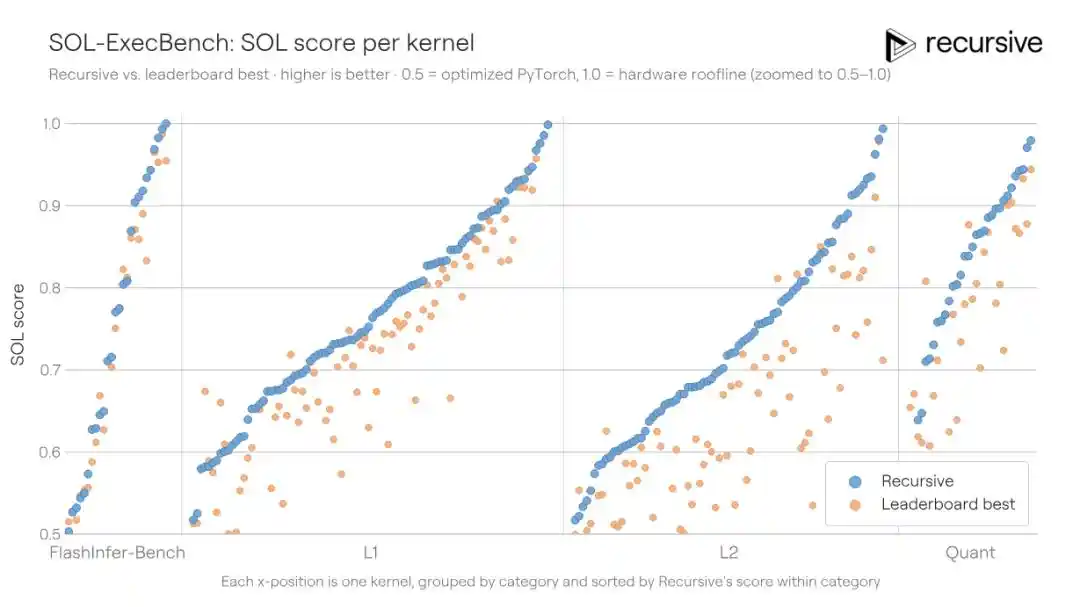
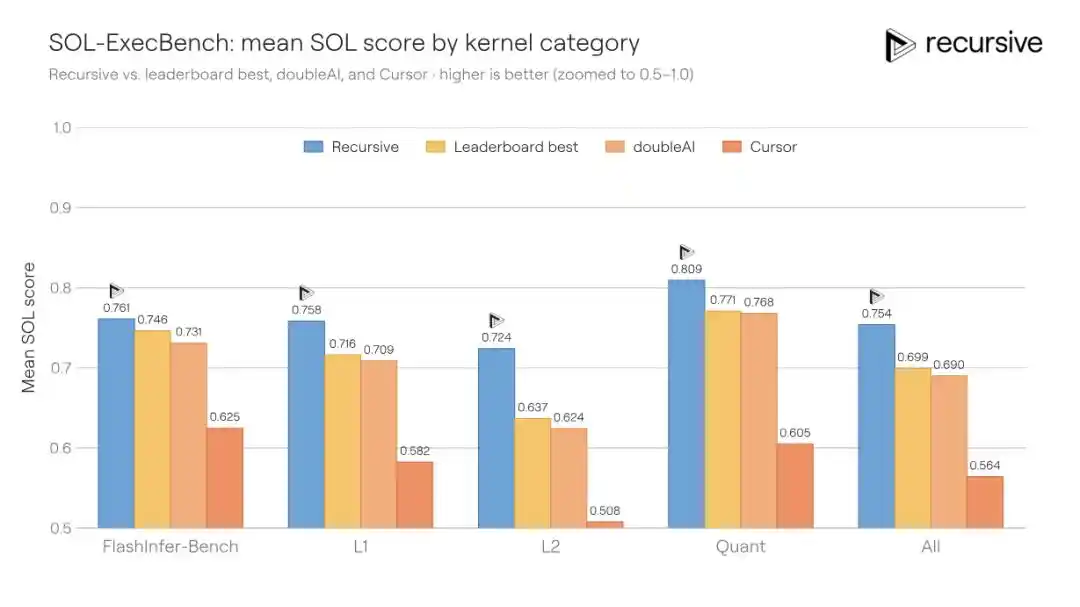
Sistem Recursive dijalankan pada 235 kernel secara keseluruhan, memungkinkan penggunaan kembali pola optimasi yang ditemukan lintas tugas (misalnya strategi pemindahan memori, cara pembagian blok, trik reduksi), skor akhir meningkat menjadi 0,754, mengurangi jarak ke batas perangkat keras sebesar 18%.
Skenario ini istimewa, karena rekayasa kernel adalah bidang yang sangat terspesialisasi — insinyur yang dapat menulis kernel Triton/CUDA efisien juga sangat langka di seluruh dunia. Dan tim Recursive mengakui secara jujur dalam blog mereka, mereka sendiri bukan ahli di bidang kernel, "ide-ide ini berasal dari sistem itu sendiri, bukan dari latar belakang keahlian kami."
Recursive: Menggunakan AI untuk Meningkatkan AI Secara Rekursif
Perusahaan yang merilis hasil ini, Recursive Superintelligence, didirikan pada akhir 2025 hingga awal 2026, baru keluar dari mode siluman bulan lalu. Anggota pendiri selain Tian Yuandong, mantan Direktur Ilmuwan Penelitian FAIR Meta, juga termasuk:
Richard Socher, CEO Recursive, mantan Kepala Ilmuwan Salesforce
Alexey Dosovitskiy, mantan Ilmuwan Penelitian Google DeepMind dan penulis pertama Vision Transformer, kutipan Google Scholar lebih dari 160 ribu
Tim Rocktäschel, mantan Ilmuwan Utama DeepMind dan Profesor AI UCL
Peter Norvig, mantan Direktur Riset Google, bersama Stuart Russell menulis buku teks terkenal di bidang AI "Artificial Intelligence: A Modern Approach"
Caiming Xiong, mantan Wakil Presiden AI Salesforce
Tim Shi, mantan Peneliti OpenAI, Pendiri Bersama dan CTO perusahaan AI perusahaan Cresta
Josh Tobin, CTO Recursive, mantan Kepala Penelitian OpenAI dan Uber ATG
Jeff Clune, mantan Wakil Presiden Penelitian Google DeepMind, Profesor Ilmu Komputer University of British Columbia, Kanada
Dan perusahaan rintisan ini, bahkan sebelum memiliki produk publik, telah memegang pendanaan 6,5 miliar dolar AS, dengan valuasi mencapai 46,5 miliar dolar AS, dipimpin oleh GV (Google Ventures) dan Greycroft, dengan partisipasi NVIDIA dan AMD Ventures.
Proposisi inti perusahaan sesuai langsung dengan namanya: membangun sistem AI yang dapat secara rekursif meningkatkan kemampuan penelitiannya sendiri, melibatkan AI dan mempercepat proses penelitian dan pengembangan AI itu sendiri, akhirnya membentuk loop peningkatan diri yang berkelanjutan.
Untuk detail lebih lanjut, lihat laporan "Setelah Meninggalkan Meta, Tian Yuandong Baru Saja Umumkan Rintisan".
Tentu saja, di tingkat jalur, Recursive tidak sendirian. AMI Labs milik Yann LeCun menyelesaikan pendanaan 10 miliar dolar AS pada Maret tahun ini, Ineffable Intelligence milik David Silver mendapatkan putaran seed 11 miliar dolar AS pada April, semuanya mengarah ke arah yang sama: membuat sistem AI secara mandiri menghasilkan pengetahuan, mengurangi intervensi manusia dalam alur penelitian. Namun dalam hal ritme hasil publik, "Langkah Pertama" Recursive ini sejauh ini adalah salah satu demonstrasi teknis paling konkret dan dapat direproduksi dari perusahaan sejenis.
Fajar Paradigma Rekursif
Hasil yang dirilis Recursive ini, ditempatkan dalam konteks industri yang lebih makro, mewakili penerapan awal dari paradigma penelitian dan pengembangan AI baru: menjadikan sistem AI itu sendiri sebagai peran utama penelitian.
Logika inti "AI rekursif" ini tidak rumit: AI meningkatkan kemampuan penelitian AI, AI yang ditingkatkan kemudian dapat lebih efektif meningkatkan dirinya sendiri, berulang terus. Ia tidak bergantung pada satu terobosan tunggal, melainkan pada sistem yang terus menghasilkan terobosan.
Pemikiran ini memiliki signifikansi ekonomi untuk penelitian AI itu sendiri. Alur pelatihan model terdepan masih sangat bergantung pada sedikit peneliti dengan keterampilan tertentu, dan orang yang mampu melakukan pekerjaan ini di seluruh dunia tidak lebih dari beberapa ribu. Jika sistem penelitian otomatis dapat mengambil alih sebagian dari pekerjaan ini, kurva kecepatan dan biaya kemajuan AI akan berubah.
Penilaian ini juga bergema dengan suara lain yang baru-baru ini muncul dari industri. Misalnya, "When AI Builds Itself" oleh Anthropic yang disebutkan di awal artikel ini, nadanya tidak ringan — ia menyerukan koordinasi industri, untuk memiliki opsi menunda atau bahkan menghentikan sementara pengembangan AI terdepan saat momen peningkatan diri rekursif tiba, untuk memberi waktu agar struktur sosial dan penelitian alignment dapat mengejar. Untuk detail lebih lanjut, lihat "Evolusi Diri AI Terlalu Cepat, Anthropic Serukan Penghentian Global Penelitian dan Pengembangan".

https://www.anthropic.com/institute/recursive-self-improvement
Dua hal terjadi bersamaan, mengundang renungan. Di satu sisi Anthropic mencatat dan memperingatkan arah lintasan ini, di sisi lain tim seperti Recursive, langkah demi langkah membuat lintasan ini menjadi kenyataan.
Tentu saja, Recursive sendiri juga mengakui, ini masih "langkah pertama": sistem saat ini bekerja paling baik pada skenario dengan metrik jelas, umpan balik cepat, dan kecurangan dapat dideteksi, masih cukup jauh dari memajukan masalah ilmiah terbuka secara mandiri. Pencegahan kecurangan reward akan menjadi tantangan inti yang terus dihadapi di jalan menuju skalabilitas.
Tapi sebuah loop telah mulai berputar. Pertanyaan selanjutnya, hanya seberapa cepat ia akan berputar.
Artikel ini dari akun WeChat publik "机器之心" (ID:almosthuman2014), penulis: 递归进化中的机器之心, editor: Panda






