Judul Asli: DeepSeek's 10 trillion USD grand strategy
Penulis Asli: @bookwormengr
Kompilasi Asli: Peggy,BlockBeats
Catatan Redaksi: Selama setahun terakhir, sebagian besar diskusi tentang DeepSeek berfokus pada kinerja model, strategi open source, dan perang harga. Namun, jika DeepSeek hanya dipahami dari segi "jual langganan atau tidak", "ada multimodalitas atau tidak", "bisa jadi coding agent atau tidak", mungkin kita meremehkan hal yang benar-benar ingin diubahnya.
Artikel ini mengajukan penilaian yang lebih radikal: Tujuan DeepSeek mungkin bukan monetisasi jangka pendek di lapisan aplikasi, melainkan serangkaian inovasi arsitektur dasar untuk membentuk kembali struktur biaya pelatihan dan inferensi AI, dan secara tidak langsung mendorong terbentuknya ekosistem perangkat keras baru. Dari MoE, MLA ke DSA, CSA, mHC, Engram, lalu Dual Path dan TileLang, garis teknologi DeepSeek selalu berpusat pada satu masalah inti: Dalam situasi di mana HBM, teknologi proses canggih, kemasan (packaging), dan ekosistem CUDA terbatas, bagaimana menjalankan model yang lebih kuat dengan komputasi canggih yang lebih sedikit.
Yang paling patut diperhatikan dalam artikel ini, bukanlah "apakah DeepSeek bisa mendapatkan pendapatan miliaran dolar AS melalui API atau langganan", melainkan apakah ia sedang mengikat kemampuan model, sistem memori, dan ekosistem perangkat keras domestik menjadi satu. Kompresi KV Cache mengurangi ketergantungan pada HBM, NAND dan SSD dapat menampung cache jangka panjang, LPDDR dapat digunakan untuk streaming loading bobot dan penyimpanan Engram, sementara TileLang berusaha melemahkan benteng CUDA. Jika inovasi-inovasi ini terus menyebar, yang diuntungkan bukan hanya DeepSeek sendiri, tetapi juga penyimpanan, ASIC, GPU, chip jaringan, dan seluruh rantai infrastruktur AI.
Tentu saja, penilaian dalam artikel tentang "ekosistem industri 10 triliun dolar AS" dan "valuasi 1 triliun dolar AS" masih mengandung spekulasi yang kuat. Namun, artikel ini memberikan jalan penting untuk memahami DeepSeek: Open source tidak selalu berarti meninggalkan komersialisasi, harga murah juga tidak selalu sekadar subsidi pasar. Bagi DeepSeek, bisnis sebenarnya mungkin tidak berada di lapisan aplikasi, melainkan dalam membantu lebih banyak perangkat keras menjadi dapat digunakan, membuat pasokan AI berbiaya lebih rendah menjadi mungkin. Dengan kata lain, yang dijual mungkin bukan model itu sendiri, melainkan kelayakan infrastruktur AI generasi berikutnya.
Berikut adalah teks aslinya:

Pernahkah Anda bertanya-tanya, bagaimana DeepSeek benar-benar akan menghasilkan uang, dan mungkin banyak uang?
Ia tidak meluncurkan skema langganan pemrograman yang kompetitif seperti GLM, MoonShot, dan MiniMax; juga tidak memiliki model multimodal, audio, video. Sampai saat ini, ia bahkan belum memiliki harness-nya sendiri, yaitu kerangka kerja eksekusi lapisan luar untuk pemanggilan model, akses alat, dan eksekusi tugas—meskipun mereka baru-baru ini mulai merekrut untuk posisi terkait, mempersiapkan pembangunan sistem ini.
Sementara itu, DeepSeek tampaknya juga berdiri tegas di pihak open source untuk jangka panjang, bahkan sangat senang berbagi "rahasianya". Bukankah ini gila? Bukankah ini membakar uang sia-sia? Apakah investor yang bersiap menginvestasikan 100 miliar dolar AS padanya sedang membuang uang ke selokan?
Menurut saya pribadi, jawabannya justru sebaliknya.
Selanjutnya, saya akan mengajukan beberapa observasi berdasarkan hal-hal yang telah dilakukan DeepSeek sejauh ini, dan menganalisis strategi yang tampaknya sedang diikutinya. Target CEO DeepSeek Liang Wenfeng mungkin jauh melampaui persaingan model saat ini. Sasaran yang dia bidik mungkin adalah hadiah yang lebih besar: DeepSeek berpeluang mengejar valuasi 1 triliun dolar AS, sambil mendorong terbentuknya industri baru senilai 10 triliun dolar AS.

Laporan TechInAsia tentang putaran pendanaan terbaru DeepSeek
Mengunjungi Kembali "Perjalanan Sang Pahlawan" DeepSeek
DeepSeek selalu berjalan melawan arus. Ia tidak memilih terus-menerus meluncurkan model yang sedikit lebih kuat, lalu terburu-buru mengemasnya menjadi aplikasi yang bisa langsung dimonetisasi, seperti skema langganan pemrograman. Pada 27 Januari 2025, saya pernah memposting tweet yang tersebar luas, menceritakan "perjalanan sang pahlawan" DeepSeek menurut saya. Sekarang, kisah ini menjadi lebih menarik.
Saat orang lain masih mencoba membangun model padat (dense), DeepSeek memilih model campuran ahli (Mixture of Experts, MoE) yang lebih sulit dilatih.
Mereka menggunakan metode "prinsip pertama" (first principles), menemukan algoritma GRPO baru, untuk menggantikan algoritma pembelajaran penguatan (Reinforcement Learning) PPO yang lebih mahal saat itu.
Mereka menemukan bahwa pembelajaran penguatan berbasis reward yang dapat diverifikasi (Reinforcement Learning from Verified Rewards, RLVR), adalah strategi kunci untuk meningkatkan kemampuan penalaran model.
Mereka juga mengusulkan strategi decoding spekulatif sederhana melalui "prediksi multi-token" (Multi Token Prediction), sekaligus membuat sinyal pelatihan menjadi lebih padat.
Mereka menyempurnakan pipeline "zero bubble", untuk meningkatkan efisiensi pemanfaatan sumber daya GPU yang terbatas.
Mereka merilis load balancer ahli (expert), membuat semua orang lebih mudah menggunakan model MoE. Terutama melalui strategi "Wide Expert Parallel", model dapat disajikan dengan batch yang lebih besar, sehingga secara drastis menurunkan biaya inferensi.
Mereka menciptakan mekanisme MLA, DSA, CSA, HCA, untuk mengurangi kebutuhan KV Cache, dan membuat kebutuhan komputasi yang bertambah seiring panjang konteks sedapat mungkin tetap mendekati konstan.
Mereka menciptakan Engram, mempertukarkan memori dengan efisiensi komputasi.
Mereka juga menciptakan mHC, memungkinkan pelatihan stabil ketika skala model diperbesar. Masih banyak contoh serupa lainnya.
Dalam struktur narasi paling umum "perjalanan sang pahlawan", sang pahlawan tidak pernah memutuskan sejak awal ke mana perjalanannya benar-benar menuju. Dia belajar sepanjang jalan, secara bertahap menemukan misinya yang benar-benar besar, dan menyelesaikannya di bawah berbagai rintangan. Dia akan bertemu banyak orang yang meragukannya, tetapi dia memilih mengabaikan mereka. Dia juga akan bertemu banyak pelaku jahat. Dia memiliki kelemahan atau kekurangan yang jelas, tetapi akhirnya mengatasi masalah ini, menyelesaikan misinya. Dia menghadapi tantangan yang tampak mustahil untuk dilewati, tetapi bisa menemukan cara untuk bersekutu, dan belajar bagaimana menggunakan sumber daya yang terbatas dan berharga dengan bijak. Inilah yang membuat penonton ingin menyemangati sang pahlawan. Inilah juga alasan DeepSeek mendapatkan pengikut, rasa hormat global, serta penentang.
Seperti yang akan saya jelaskan secara rinci nanti, DeepSeek telah menempuh jalan ini cukup lama, dan secara bertahap menemukan takdir terakhirnya: Tujuannya bukan menjual skema langganan pemrograman, melainkan mendorong ekosistem perangkat keras AI Tiongkok senilai 10 triliun dolar AS, dan membuat dirinya sendiri mencapai valuasi 1 triliun dolar AS. Dalam proses ini, ia juga akan menciptakan peluang bagi banyak pemain baru dalam ekosistem perangkat keras Barat.

Mari Mulai dengan Beberapa Perhitungan KV Cache yang Menarik
Lihat tweet @SemiAnalysis_ yang sangat tepat waktu ini:
DeepSeek telah menyelesaikan masalah ini lebih baik daripada siapa pun!
Mari kita lakukan beberapa perhitungan KV Cache yang menarik. Jangan khawatir, meskipun Anda tidak suka matematika. Kami akan menggunakan kalkulator KV Cache yang baru dirilis, untuk melihat berapa banyak penghematan KV Cache yang dapat dibawa oleh DeepSeek V4 Pro, dan membandingkannya dengan model GLM dan Qwen terbaru.
Di sini saya menghitung dengan panjang konteks 1 juta, mengasumsikan presisi KV 8 bit, presisi indekser 16 bit. Anda juga bisa mencobanya sendiri dengan membuka kalkulator ini: https://kvcache.ai/tools/kv-cache-calculator/
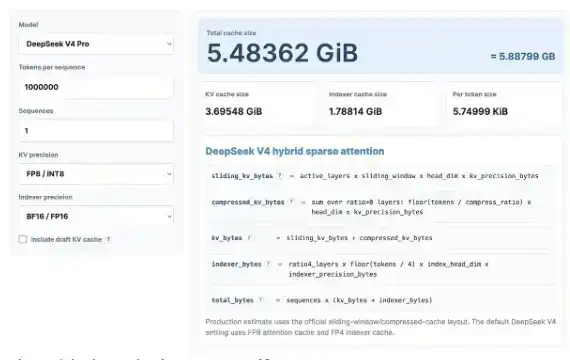
Anda juga bisa mencobanya sendiri dengan membuka kalkulator!
Pada panjang konteks 1 juta:
· DeepSeek V4 hanya membutuhkan 5.48GB HBM;
· GLM-5 membutuhkan 60GB HBM;
· Qwen3-235B-A22B bahkan membutuhkan HBM setinggi 89GB.
Perlu diperhatikan:
· DeepSeek adalah model dengan 1,6 triliun parameter;
· GLM-5 sekitar 700 miliar parameter, dan sudah menggunakan MLA dan DSA milik DeepSeek, meskipun belum menggunakan mekanisme perhatian terkompresi terbaru;
· Qwen3-235B-A22B sekitar 235 miliar parameter, menggunakan mekanisme perhatian GQA.
DeepSeek telah memberikan kontribusi mendasar dalam meredakan tekanan memori. Jika inovasi semacam ini diadopsi secara luas, akan secara signifikan menurunkan biaya operasi agen siklus panjang, dan membuka kunci batch aplikasi baru berikutnya.
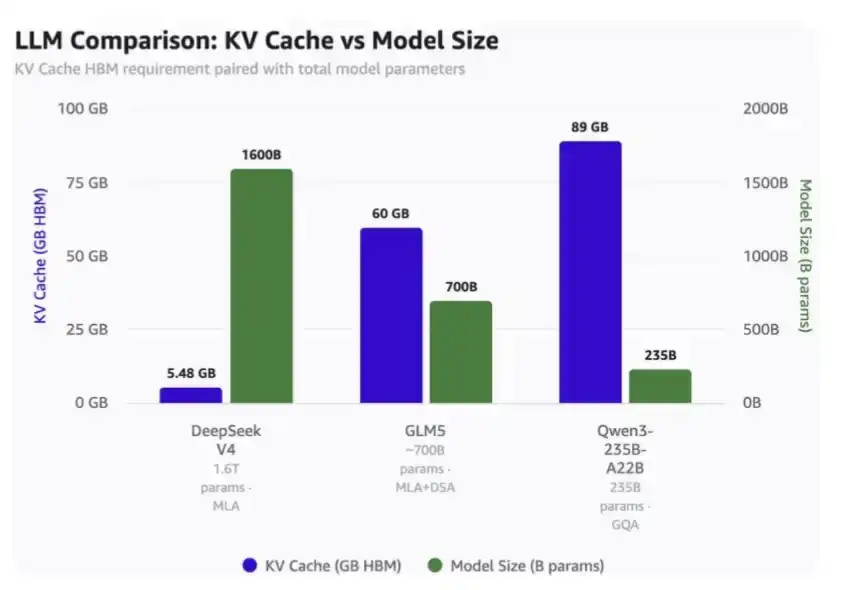
Perbandingan penggunaan KV Cache pada konteks 1 juta Token dengan skala model
Metodologi di Balik "Kegilaan"
Alasan ukuran KV Cache bisa menjadi sangat kecil, sekaligus tidak mengorbankan kualitas model, adalah alasan DeepSeek dapat menyediakan cache jangka panjang dengan harga yang sangat rendah—harganya bahkan kurang dari 3% dari harga cache hit Sonnet 4.6, dan DeepSeek dapat menyimpan cache selama berjam-jam.
Untuk tugas siklus panjang, KV Cache yang lebih kecil berarti dapat dibongkar ke SSD dengan lebih ekonomis, dan dimuat ulang saat diperlukan. Dengan demikian, ketergantungan pada HBM dapat dikurangi. Dari perspektif industri perangkat keras AI Tiongkok, HBM tidak hanya pasokan ketat, tetapi juga tipe memori yang paling sulit diproduksi.
Selain itu, DeepSeek juga mengembangkan teknologi untuk memuat KV Cache dari SSD lebih cepat, yang telah dijelaskan dalam makalah Dual Path mereka.
Kompresi KV Cache pada DeepSeek V4 sangat besar, sehingga langkah ini bahkan mungkin tidak lagi diperlukan.
Lalu, siapa penerima manfaat langsung dari kompresi KV Cache?
Siapa yang memasok SSD dalam skala besar? Jangan lupa, YMTC (Yangtze Memory Technologies Co., Ltd.) sedang tumbuh menjadi raksasa di bidang 3D NAND. NAND dapat membantu DeepSeek menghindari komputasi ulang KV. Sebaliknya, DeepSeek juga menciptakan pasar besar untuk NAND dan SSD—ini tidak hanya menguntungkan YMTC, tetapi juga produsen terkait lainnya.

Namun, ini tidak hanya tentang NAND dan SSD.
Memori LPDDR juga memiliki potensi besar. Ia dapat berfungsi sebagai tempat penyimpanan bobot model, dan melakukan streaming bobot tersebut ke HBM saat diperlukan, sehingga meredakan tekanan kebutuhan HBM. Tim SGLang pernah mempublikasikan blog yang bagus tentang ini. Gambar di bawah ini menunjukkan cara kerja skema ini.
Meskipun DeepSeek tidak merancang secara khusus untuk skema ini, arsitektur MoE-nya, model ahli yang banyak, dan karakteristik bobot 4 bit, semuanya membuat skema ini lebih mudah diimplementasikan.
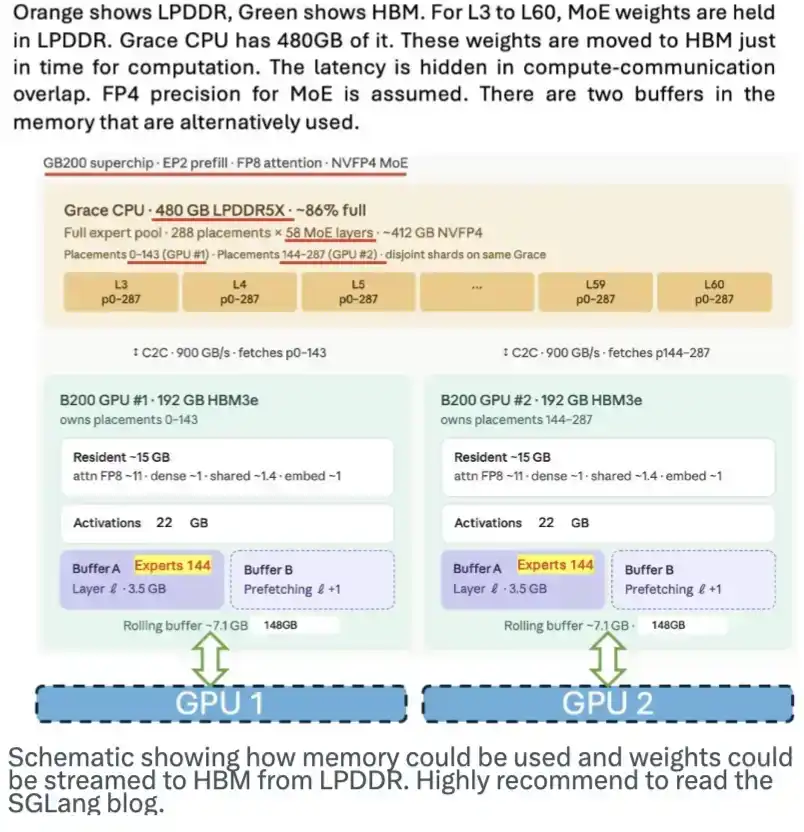
Diagram skematis ini menunjukkan bagaimana memori mungkin digunakan, dan bagaimana bobot model di-streaming dari LPDDR ke HBM. Sangat disarankan untuk membaca blog SGLang tersebut.
Inovasi ini, jika digabungkan dengan KV Cache yang sangat kompak dan lossless, akan secara signifikan mengurangi kebutuhan HBM.
Lalu, siapa di Tiongkok yang memproduksi LPDDR? Jawabannya adalah CXMT, atau ChangXin Memory Technologies. Mereka hanya tertinggal sekitar setengah generasi dalam kecepatan LPDDR, dan satu generasi dalam kepadatan, tidak terlalu jauh.
Selain pasokan NAND yang cukup, ekosistem AI Tiongkok dalam waktu dekat juga akan memiliki pasokan LPDDR yang cukup. Apakah ini dapat meredakan tekanan komputasi? Jawabannya: Ya. Mari lanjutkan.

Penggunaan Memori yang Cerdas Juga Dapat Meredakan Tekanan GPU / ASIC
Fungsi menggunakan NAND untuk menyimpan KV Cache sebenarnya mudah dipahami: Ia dapat mempertahankan KV Cache lebih lama, mengurangi tekanan pada HBM, sekaligus menghindari komputasi ulang KV Cache, sehingga meringankan beban komputasi GPU dan ASIC.
Lalu, apakah LPDDR juga dapat berfungsi dengan cara serupa? Selain sebagai lokasi penyimpanan yang dapat "streaming on-demand" bobot ke HBM, apakah ia dapat lebih jauh mengurangi tekanan komputasi?
Jawabannya: Ya.
LPDDR dapat digunakan untuk menyimpan sejumlah besar konten yang disebut Engram. Dalam makalah Engram DeepSeek, mereka menunjukkan bahwa MoE dapat memperluas kapasitas model melalui komputasi bersyarat, tetapi Transformer sendiri kekurangan mekanisme "pencarian pengetahuan" asli. Oleh karena itu, Transformer sering kali terpaksa mensimulasikan proses pengambilan (retrieval) secara tidak efisien melalui komputasi.
Untuk mengatasi masalah ini, DeepSeek mengusulkan modul Engram. Ia memodernisasi embedding N-gram klasik, mengubahnya menjadi mekanisme pencarian berbasis hash O(1), sehingga menciptakan jalur pensparsian pelengkap, yang mereka sebut memori bersyarat (conditional memory).
Cara ini dapat menghemat komputasi, tetapi juga membutuhkan memori untuk membawa tabel embedding, dan tabel itu sendiri bisa sangat besar.
Pada dasarnya, ini adalah skema tipikal "mempertukarkan memori dengan komputasi". Namun, wawasan utamanya adalah: Dari biaya pembacaan per bit data, sisi "memori" jauh lebih murah—satu pencarian LPDDR, jauh lebih murah daripada membiarkan data melewati penuh beberapa lapisan Transformer untuk satu kali komputasi maju (forward). Oleh karena itu, dalam skala besar, ini adalah pertukaran yang sangat menguntungkan.
Ini adalah cara DeepSeek mengorbankan sebagian memori, untuk mendapatkan penghematan komputasi.
Pertukaran yang Layak Dilakukan
Karena tidak memiliki kepadatan transistor chip yang setara, juga tidak memiliki EUV, GPU dan ASIC Tiongkok dalam FLOPs mentah, kemungkinan akan tertinggal dari GPU Barat dalam jangka panjang. Mereka juga masih memiliki kesenjangan yang jelas dalam kemasan canggih (advanced packaging). Oleh karena itu, pertukaran semacam ini sangat layak dilakukan, terutama mengingat Tiongkok dapat memproduksi memori NAND dan LPDDR dalam jumlah besar.
Mengulas Strategi Jangka Panjang DeepSeek
Dari inovasi-inovasi ini, tujuan DeepSeek tampaknya bukan menghasilkan keuntungan beberapa miliar dolar AS saat ini. Banyak pilihan yang dibuatnya di masa lalu menunjukkan hal ini: Sampai sekarang belum memiliki multimodalitas, belum memiliki model suara, apalagi model video.
Ia benar-benar terlibat dalam permainan jangka panjang yang sabar, dengan skala mungkin mencapai 10 triliun dolar AS: Mendorong pembentukan ekosistem perangkat keras AI alternatif.
Ini bukan hanya agar produsen memori Tiongkok menjadi pemain kunci di pasar perangkat keras AI domestik dan global, tetapi lebih untuk secara fundamental mengurangi kebutuhan sumber daya, membuat pelatihan dan penyajian model AI menjadi lebih efisien biaya. Dengan demikian, banyak produsen GPU, ASIC, serta produsen chip jaringan, memiliki peluang menjadi pilihan yang layak.
Sementara itu, inovasi-inovasi ini juga akan menguntungkan ekosistem open source Barat, serta produsen perangkat keras generasi baru.
Sebenarnya semua tanda-tanda telah muncul. Mari kita tinjau secara rinci inovasi-inovasi yang telah diusulkan DeepSeek hingga saat ini:
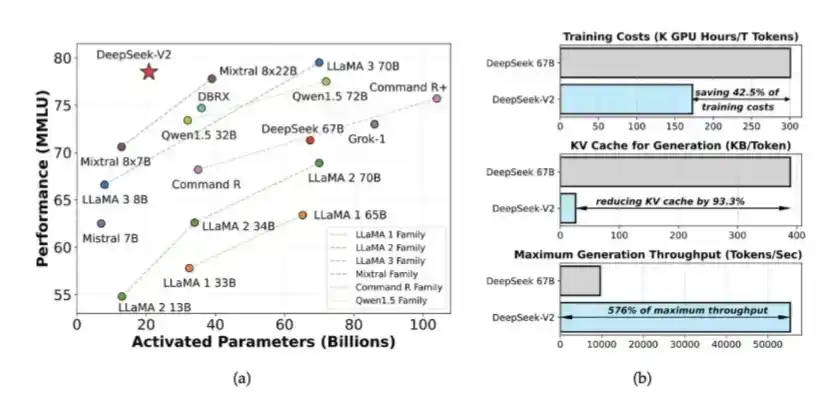
1. Model Campuran Ahli (MoE) dan MLA yang diperkenalkan dalam DeepSeek V2
DeepSeek memperkenalkan MoE dan MLA dalam V2. MoE mengurangi kebutuhan komputasi untuk melatih model kecerdasan tinggi sekitar 40% hingga 50%; MLA mengurangi KV Cache hingga 90%.
Ini membuat pembongkaran KV Cache ke SSD menjadi cukup efisien.
Ide-ide ini pertama kali muncul dalam makalah DeepSeek V2 yang dirilis DeepSeek pada Mei 2024. Kemudian, mereka juga menjadi dasar pelatihan DeepSeek V3. Saat itu, DeepSeek hanya menggunakan 2048 GPU H800 yang performanya dilemahkan, untuk melatih sistem dengan kinerja mendekati level model closed-source.
2. DSA: Diperkenalkan dalam DeepSeek V3.2 Exp, untuk mengurangi overhead komputasi dalam skenario konteks panjang, sekaligus meredakan tekanan bandwidth HBM.
Fungsi inti DSA adalah memastikan volume komputasi tidak terus bertambah seiring peningkatan panjang konteks. Lihat grafik di bawah: Seiring bertambahnya panjang konteks, waktu pemrosesan DeepSeek-V3.2 tetap stabil.
3. mHC: Diusulkan DeepSeek pada Desember 2025 dalam makalah "mHC: Manifold-Constrained Hyper-Connections".
mHC adalah inovasi arsitektur makro DeepSeek, yang mendesain ulang cara aliran informasi antar lapisan Transformer.
Di masa lalu, sejak ResNet, model biasanya menggunakan koneksi residual standar, yaitu x + F(x). Sedangkan mHC memperluas aliran residual menjadi beberapa saluran informasi paralel, dan memungkinkan model untuk melakukan pencampuran yang dapat dipelajari di antara saluran-saluran ini. Kuncinya adalah, ia akan membatasi matriks pencampuran menjadi matriks bistokastik, yaitu membatasinya pada politop Birkhoff melalui proyeksi Sinkhorn-Knopp. Dengan cara ini, secara matematis dapat dijamin bahwa amplitudo sinyal dapat tetap stabil, berapa pun dalamnya model ditumpuk.
Ini memecahkan masalah ketidakstabilan katastropik yang dihadapi oleh Hyper-Connections tanpa kendala. Hyper-Connections awalnya diusulkan oleh ByteDance, tetapi tanpa kendala, amplifikasi sinyal akan meledak hingga 3000 kali pada skala 27 miliar parameter, akhirnya menyebabkan pelatihan benar-benar gagal.
Biaya komputasi mHC rendah: Ia hanya membawa overhead waktu pelatihan aktual sekitar 6,7%, karena tidak mengubah FLOPs lapisan perhatian atau FFN, hanya mengubah cara keluaran lapisan-lapisan ini dirutekan antar lapisan.
Namun peningkatan kinerjanya cukup signifikan: Pada skala 27 miliar parameter, mHC meningkatkan skor 7,2 poin pada tugas penalaran BIG-Bench Hard, 3,2 poin pada DROP, 2,8 poin pada tugas matematika GSM8K, dan 1,4 poin pada tugas pengetahuan umum MMLU. Dan peningkatan ini dicapai pada skala model yang sama, dengan anggaran komputasi yang hampir sama.
Pada dasarnya, mHC menyediakan topologi perutean informasi antar lapisan yang lebih kaya dan lebih ekspresif untuk jaringan, mencapai kecerdasan per parameter yang lebih tinggi dengan hampir tidak ada tambahan FLOPs.
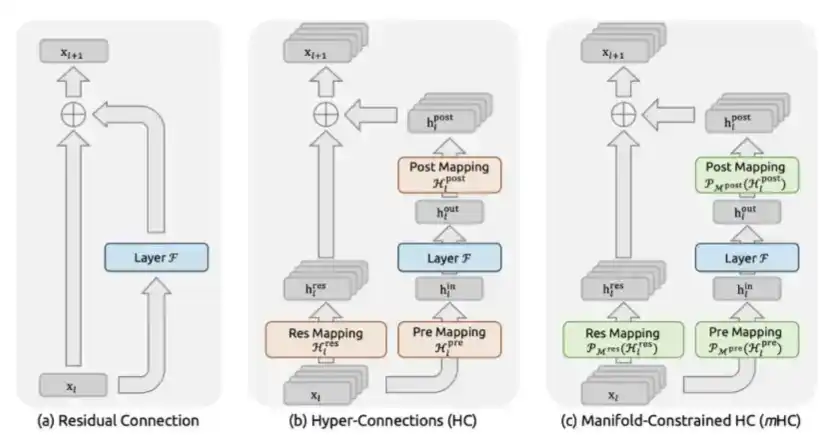
mHC adalah desain arsitektur yang kompleks, tetapi ia dapat membawa proses pelatihan yang lebih stabil, dan kecerdasan per parameter yang lebih tinggi.
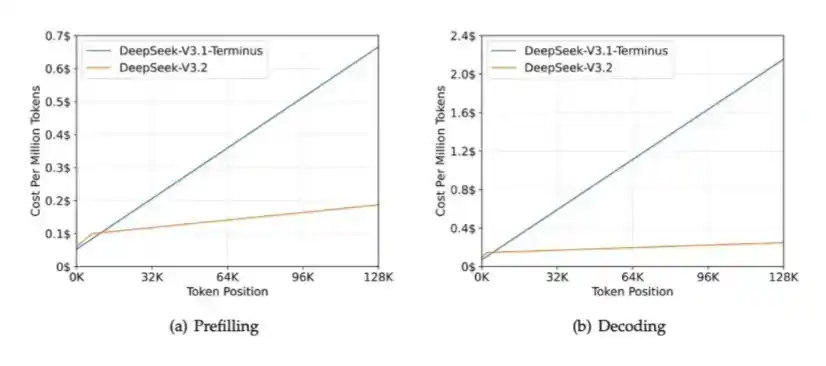
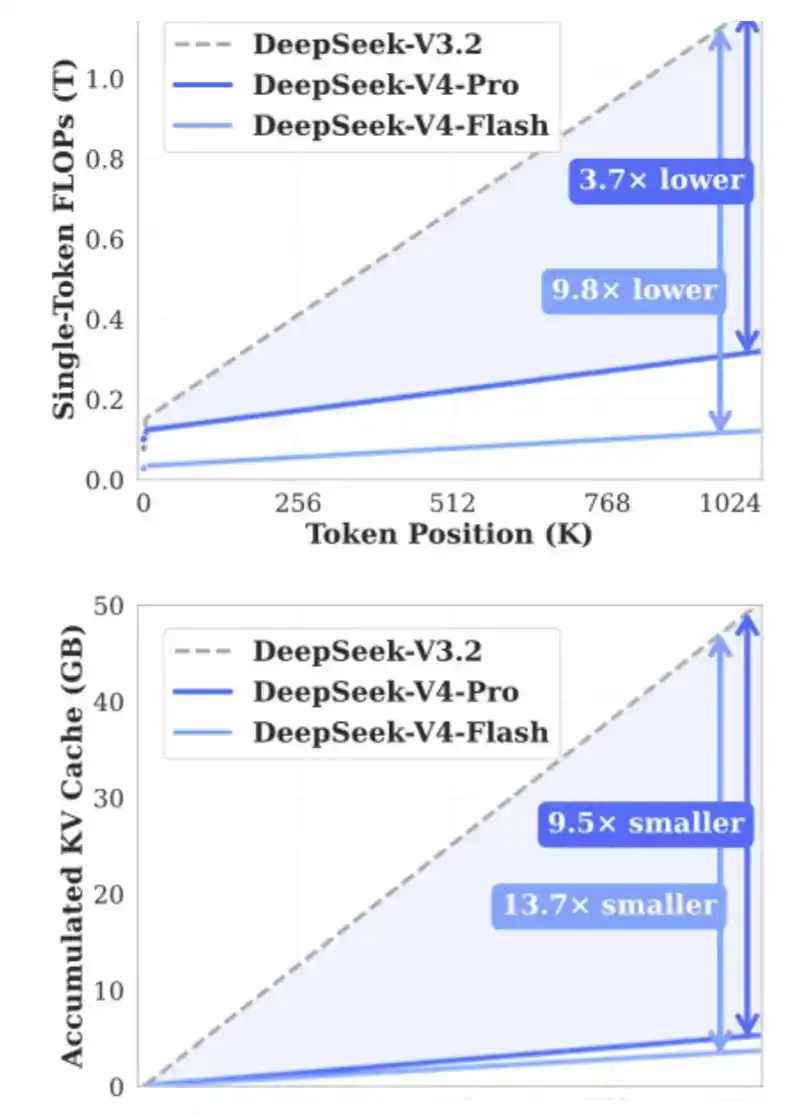
4. CSA, HSA: Diperkenalkan DeepSeek pada April 2026 dalam V4.
Tujuan CSA dan HSA adalah dengan mengompresi Token KV, mengurangi kebutuhan KV Cache hingga 90% lagi, sekaligus secara signifikan mengurangi FLOPs yang dibutuhkan, sehingga secara bersamaan meredakan tekanan pada HBM serta GPU / ASIC.
5. Engram: Diperkenalkan DeepSeek pada kuartal pertama 2026, pada dasarnya dalam beberapa hal mempertukarkan memori, yaitu memori LPDDR, dengan efisiensi komputasi.
Seperti ditunjukkan oleh grafik rinci di bawah ini, dengan anggaran parameter total yang sama, Engram membawa peningkatan kinerja yang nyata.
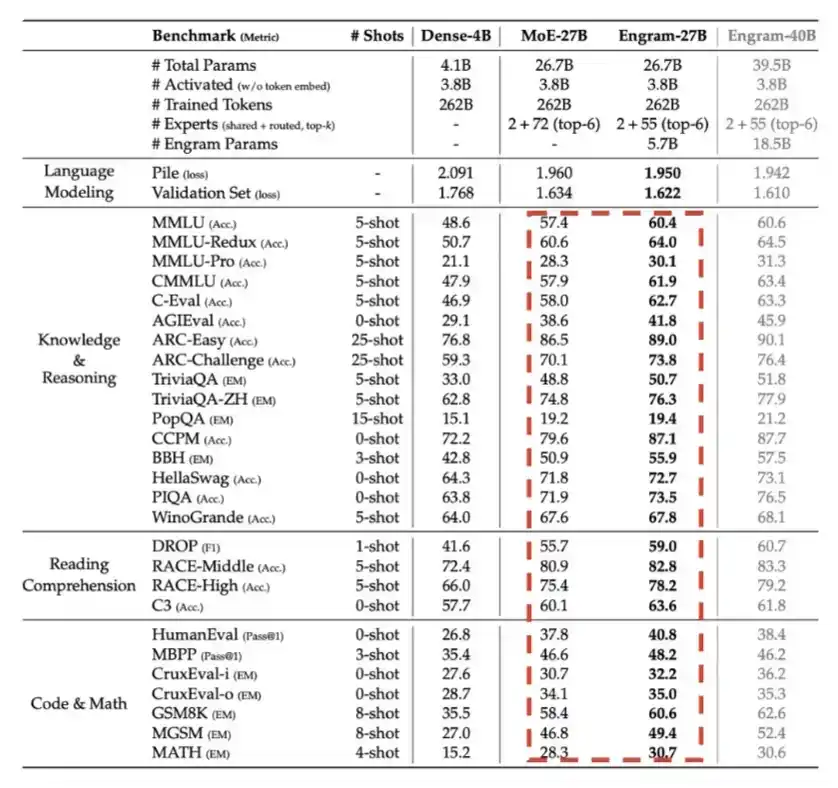
6. Engram: Diperkenalkan DeepSeek pada kuartal pertama 2026, pada dasarnya dalam beberapa hal mempertukarkan memori, yaitu memori LPDDR, dengan efisiensi komputasi.
Seperti ditunjukkan oleh grafik rinci di bawah ini, dengan anggaran parameter total yang sama, Engram membawa peningkatan kinerja yang nyata.

Ini adalah saran yang dibagikan DeepSeek kepada produsen perangkat keras dalam makalah V4. Saya yakin, dalam diskusi offline, umpan balik yang mereka berikan hanya akan lebih banyak.
7. Investasi pada TileLang juga mengarah ke arah yang sama: DeepSeek tidak hanya menyelesaikan bottleneck komputasinya sendiri, tetapi mendorong ekosistem perangkat keras Tiongkok memiliki kemampuan bersaing dengan ekosistem Barat.
Dengan TileLang, pengembang dapat hanya menulis kernel sekali, yaitu kode dasar untuk komputasi, lalu membuatnya berjalan sukses di beberapa platform perangkat keras, asalkan platform tersebut telah memiliki dukungan backend TileLang yang sesuai.
Saya memperkirakan, laboratorium AI Tiongkok lainnya juga akan bergabung satu per satu. Ini akan membantu produsen perangkat keras Tiongkok menghadapi apa yang disebut "benteng CUDA" dengan cara tidak langsung. Bersamaan dengan itu, ia juga akan melepaskan potensi lebih banyak perangkat keras Barat, seperti AMD.
Perlu dijelaskan: Banyak platform perangkat keras AI Tiongkok telah menyediakan kemampuan kompatibilitas CUDA, atau lapisan penerjemah CUDA. Misalnya, Moore Threads, MetaX (Muxi), Biren Technology, dan Iluvatar CoreX (Tianshu Zhixin), adalah produsen chip Tiongkok dengan kompatibilitas CUDA yang cukup tinggi melalui lapisan penerjemah. Oleh karena itu secara teori, mereka tidak selalu membutuhkan TileLang.

Pembelajaran Penguatan Skala Besar dan RSI
Seiring DeepSeek mendapatkan lebih banyak sumber komputasi, yaitu pilihan perangkat keras yang lebih banyak, sekaligus kebutuhan model itu sendiri akan sumber daya komputasi menurun, ia akan dapat memajukan proyek pelatihan yang lebih ambisius, terutama pasca-pelatihan pembelajaran penguatan (reinforcement learning).
Pembelajaran penguatan membutuhkan pembuatan banyak lintasan (trajectory), yaitu menghasilkan triliunan Token. Proses ini dengan cepat menjadi sangat mahal. Lebih lanjut, jika ingin melatih model dengan panjang konteks 1 juta, perlu menghasilkan lintasan dengan panjang yang sama. Hanya dengan melatih model pada lintasan super panjang inilah, tugas siklus panjang benar-benar dapat didukung.
Selain itu, karena pilihan perangkat keras bertambah, sumber daya perangkat keras yang dapat dipanggil DeepSeek juga akan lebih banyak, ini akan mendorong penelitian otomatis, yaitu RSI. RSI mengacu pada AI yang merancang dan melaksanakan eksperimen sendiri. Metode ini melibatkan banyak trial and error, dan biayanya juga akan meningkat pesat. Namun RSI sangat penting untuk mengeksplorasi ruang desain model secara lengkap. Sebelum menuju AGI, dan kemudian menuju ASI, DeepSeek harus memiliki kemampuan RSI.
Apa yang Dilakukan DeepSeek Hari Ini, Seluruh Industri Akan Ikut Besok
Inovasi DeepSeek di sekitar model campuran ahli, MLA, DSA, dll., telah diadopsi satu per satu oleh laboratorium AI lain di seluruh dunia dan di Tiongkok.
Misalnya, ZAI, pengembang seri model GLM, menggunakan MLA dan DSA. Kimi, alias Moonshot, juga menggunakan MLA, dan tanpa ragu menyatakan bahwa arsitekturnya didesain berdasarkan arsitektur DeepSeek. Sebaliknya, DeepSeek juga menggunakan optimizer Muon, sedangkan Muon pertama kali digunakan dalam pelatihan skala besar oleh Kimi (Moonshot).
Perlu dijelaskan:
MoE pertama kali diusulkan oleh Google pada 2017, penulis kuncinya adalah Noam Shazeer. Kontribusi DeepSeek adalah menerapkan MoE dalam skala besar, dan menemukan trik pendampingnya sendiri.
Muon, atau optimizer MomentUm Orthogonalized by Newton-Schulz, diusulkan oleh peneliti machine learning Keller Jordan pada akhir 2024. Tim Kimi (Moonshot) adalah tim pertama yang menggunakannya untuk pelatihan skala besar.
Bagaimana dengan Masalah Menghasilkan Uang?
Kita bisa melihat contoh menarik OpenAI.
OpenAI menerima warrant / opsi untuk membeli saham AMD dan Cerebras dengan harga yang lebih rendah, hak-hak ini terkait dengan pencapaian tonggak konsumsi komputasinya. Bagi AMD dan Cerebras, ini adalah transaksi yang sangat menguntungkan. Karena begitu OpenAI berkomitmen menggunakan perangkat keras mereka, kemungkinan kesuksesan jangka panjang mereka akan meningkat pesat.
Ada pernyataan seperti ini dalam pengumuman AMD:
"Sebagai bagian dari kesepakatan, untuk lebih menyelaraskan kepentingan strategis kedua belah pihak, AMD menerbitkan warrant kepada OpenAI yang dapat digunakan untuk membeli hingga 160 juta saham biasa AMD, dan akan vested secara bertahap sesuai pencapaian tonggak tertentu. Batch pertama akan vested ketika penyebaran awal 1 gigawatt selesai, batch berikutnya akan vested bertahap seiring pembelian diperluas hingga 6 gigawatt. Syarat vested juga dikaitkan dengan AMD mencapai target harga saham tertentu, serta OpenAI mencapai tonggak teknologi dan komersial yang diperlukan AMD untuk penyebaran skala besar."

Saya memperkirakan, DeepSeek juga akan mencapai kesepakatan serupa dengan beberapa produsen teknologi memori, ASIC, CPU, dan jaringan Tiongkok, dan bekerja sama secara mendalam dengan mereka, membuat tumpukan perangkat keras produsen-produsen ini mampu menangani beban kerja AI terdepan.
Mengingat total kapitalisasi pasar saham AI Barat, termasuk sekutu Asia Timur, telah jauh melampaui 10 triliun dolar AS, cara "mendapatkan imbalan ekuitas melalui kerja sama" ini akan memberi DeepSeek peluang membantu Tiongkok membangun industri yang sama besarnya, dan mendapatkan kue sendiri di dalamnya, akhirnya mencapai valuasi 1 triliun dolar AS.
Ini tidak hanya akan membuat DeepSeek menghasilkan uang jauh melampaui bisnis langganan aplikasi tradisional, tetapi juga dapat mencapai target yang dikatakannya "membuat AGI bermanfaat bagi setiap orang". Liang Wenfeng adalah penggemar setia Jim Simons, dan juga pemain modal yang cukup pintar, dia tidak mungkin melewatkan hal ini.
Jika Anda melihat kembali semua yang telah dilakukan DeepSeek hingga saat ini, hanya penjelasan inilah yang paling masuk akal.
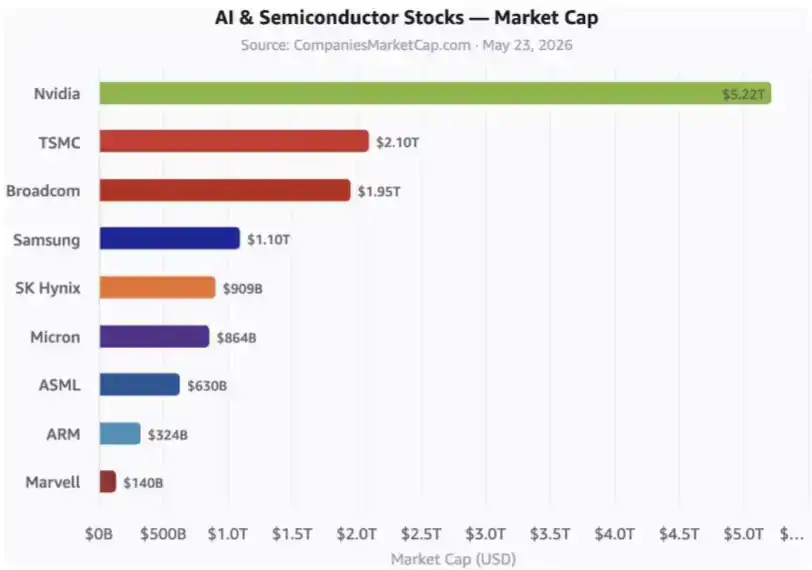
Ini adalah saham-saham AI kunci. Grafik ini belum termasuk hyperscalers, serta banyak perusahaan terkait lainnya.
Tautan Asli







