Penulis: AI Product Aying
Saya membaca sebuah blog yang ditulis tim Anthropic berjudul "Lessons from building Claude Code: How we use skills". Ini mungkin adalah ringkasan praktis paling mendalam tentang Skill yang pernah saya lihat sejauh ini.
Skill sebenarnya tidak rumit, tetapi menurut saya, untuk benar-benar melakukannya dengan baik juga tidak mudah.
Saya ingat saat Skill baru populer, semua orang sangat suka membuat berbagai Skill gaya penulisan, Skill menulis. Sepertinya hanya dengan memasukkan gaya penulisan kita ke dalamnya, model akan dapat menghasilkan output dengan gaya itu secara stabil.
Tetapi kemudian saya mencobanya sendiri dan menemukan bahwa seringkali itu tidak berhasil.
Karena sebuah Skill gaya penulisan mungkin diisi dengan ribuan kata, bahkan puluhan ribu kata. Setelah Skill dimuat, konteksnya memakan sebagian besar ruang. Semakin berat konteksnya, kemampuan berpikir model justru mudah menurun.
Akhirnya sering muncul situasi seperti ini: gayanya memang berhasil dipelajari, tetapi kontennya menjadi dangkal, kemampuan analisisnya juga melemah.
Ada juga situasi umum lainnya.
Banyak orang saat menulis Skill, suka memasukkan berbagai instruksi operasional. Langkah pertama melakukan apa, langkah kedua apa, langkah ketiga apa. Hasilnya, saat dijalankan, akan ditemukan bahwa eksekusi model tidak stabil.
Kemudian saya baru perlahan memahami, banyak pekerjaan berulang seperti ini sebenarnya lebih cocok diendapkan menjadi Script, bukan ditulis sebagai Instructions yang panjang.
Setelah membaca artikel Anthropic ini, kesan terbesar saya adalah, banyak orang mungkin menggunakan Skill, tetapi belum tentu benar-benar memahami Skill.
Pada dasarnya, Skill adalah tentang Context Engineering. Kapan seharusnya pengetahuan dimasukkan ke dalam Skill, kapan harus dipecah menjadi References, kapan harus ditulis sebagai Script, kapan harus menggunakan Gotchas untuk membatasi model, sebenarnya ada banyak pengalaman di sini.
Setelah memahami prinsip kerja Skill, jika kita melihat kembali Skill-skill yang bagus, akan ditemukan bahwa mereka tidak pernah menyelesaikan masalah prompt, tetapi menyelesaikan masalah konteks, pengendapan pengalaman, dan penggunaan kembali kemampuan.
Jika Anda ingin mempelajari Skill secara mendalam, sangat disarankan untuk membaca dua artikel ini:
https://claude.com/blog/lessons-from-building-claude-code-how-we-use-skills
https://research.perplexity.ai/articles/designing-refining-and-maintaining-agent-skills-at-perplexity
#01 Jangan Menulis Omong Kosong
Pada dasarnya, Skill mengendapkan "pengetahuan implisit" dalam organisasi. Oleh karena itu, jangan ulangi pengetahuan umum yang sudah diketahui di dalam Skill. Yang benar-benar berharga adalah informasi yang bahkan tidak diketahui model.
Di internal Anthropic sering ditekankan, yang sebenarnya harus ditulis dalam Skill adalah Gotchas, yaitu kesalahan yang sering terjadi.
Misalnya:
1. Tabel ini tidak bisa diurutkan berdasarkan created_at
2. Staging mengembalikan 200 tidak berarti berhasil
3. request_id dan trace_id adalah hal yang sama
Karena informasi ini seringkali ada dalam pengalaman karyawan. Jadi, harus diingat apa esensi Skill sebenarnya.
Skill = Menuliskan pengalaman master (senior).
Melalui Skill, pengalaman yang tadinya tersebar di pikiran orang yang berbeda-beda dapat diendapkan.
#02 Skill Sebenarnya Adalah Context Engineering
Ini mungkin salah satu pandangan Anthropic yang paling mendalam.
Skill bukan sebuah file markdown, melainkan sebuah folder. Bagi yang pernah menggunakan Skill, pernyataan ini terdengar seperti omong kosong.
Tetapi beberapa hari ini saya merenungkannya berulang kali, perlahan menyadari: mereka ingin menggunakan bentuk folder ini untuk mengungkapkan konsep Context Engineering.
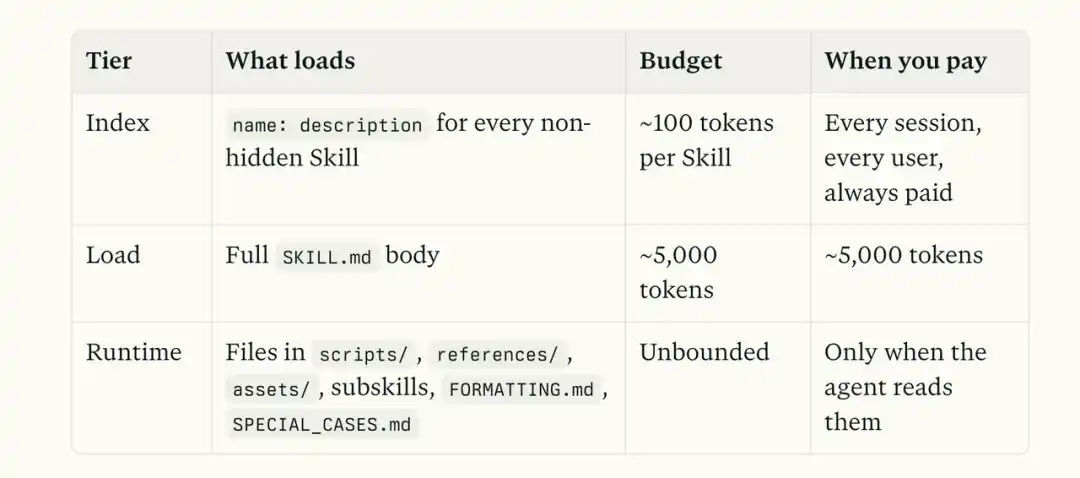
Mari kita lihat kembali struktur Skill yang khas:
skill/ ├── SKILL.md ├── references/ menyimpan penjelasan rinci, referensi API, kondisi batas ├── scripts/ menyimpan skrip yang dapat dieksekusi ├── examples/ menyimpan contoh ├── assets/ menyimpan template, gambar, materi tetap
Saat suatu Skill dipanggil, model pertama-tama membaca SKILL.md. Jika kita memasukkan semua informasi ke dalam file ini, konteks akan meledak dengan cepat.
Misalkan ini adalah Skill troubleshooting pembayaran, di dalamnya ada penjelasan kode error Stripe, kasus kegagalan historis, skrip pemeriksaan, dan template laporan akhir.
Jika semua konten ini ditumpuk ke dalam SKILL.md, setiap kali Skill dipanggil, Claude harus membacanya kembali dari awal.
Bahkan jika pengguna hanya ingin mengonfirmasi arti sebuah kode error, atau hanya ingin melihat mengapa status pembayaran tertentu tidak diperbarui. Banyak informasi yang tidak berguna akan ikut dimasukkan ke dalam konteks.
Sedangkan pendekatan Anthropic sangat berbeda.
SKILL.md lebih mirip halaman navigasi. Tugasnya adalah memberi tahu model, saat menemui error Stripe, carilah penjelasan yang sesuai di references.
Saat perlu merujuk kasus historis, periksa masalah serupa di examples. Saat perlu benar-benar melakukan tindakan pemeriksaan, jalankan skrip di scripts. Terakhir, saat membuat laporan troubleshooting, gunakan template di assets.
Seluruh proses ini adalah paparan yang bertahap.
Gambar di bawah ini, sangat disarankan untuk disimpan.
#03 Gunakan Skrip Sebisa Mungkin
Jangan biarkan model menghabiskan konteks dan kemampuan penalaran terbatasnya untuk pekerjaan berulang. Serahkan hal-hal ini pada skrip.
Misalnya. Banyak orang saat menulis Skill, akan menulis seperti ini:
1. Kueri data registrasi; 2. Kueri data pembayaran; 3. Hitung tingkat konversi; 4. Analisis penyebab anomali.
Cara penulisan seperti ini tentu tidak masalah. Model juga bisa menyelesaikannya. Tetapi setiap kali dieksekusi, ia harus mengulang seluruh alur analisis dari awal.
Mengkueri data, mengatur data, menangani berbagai kondisi batas, semua pekerjaan ini sebenarnya berulang.
Karena kemampuan ini sudah diuji berulang kali. Mengapa harus membuat model menemukannya kembali? Lebih baik langsung berikan skrip yang spesifik.
Dan dengan cara skrip, eksekusi Skill juga akan lebih akurat, dan lebih hemat Token.
Dari sudut pandang ini, Scripts di dalam Skill sebenarnya mengendapkan kemampuan organisasi. Di balik setiap skrip, sering kali adalah praktik terbaik yang disimpulkan tim setelah mengalami banyak masalah.
Setelah kemampuan ini dikokohkan. Claude setiap kali dapat bekerja berdasarkan pengalaman ini, bukan dari nol berulang kali.
Jadi saya semakin merasa, dalam Skill, Instructions dan Scripts menyelesaikan masalah di tingkat yang berbeda.
Instructions memberikan pengalaman dan penilaian, Scripts memberikan kemampuan dan eksekusi.
Misalnya, dalam Skill troubleshooting pembayaran mungkin ada pernyataan seperti ini:
Jika Stripe mengembalikan 200, jangan langsung menganggap pembayaran berhasil, perlu memeriksa tabel payment_events lebih lanjut.
Ini termasuk Instructions. Karena ini adalah pengalaman, sedangkan check_payment_events() termasuk Script, karena ini adalah kemampuan eksekusi.
Jika hanya ada Script, model tahu cara memeriksa, tetapi belum tentu tahu mengapa harus memeriksa.
Jika hanya ada Instructions, model tahu harus memeriksa. Tetapi setiap kali harus mengimplementasikannya kembali. Keduanya tidak dapat dipisahkan.
#04 Description Lebih Mirip Aturan Routing
Cara banyak orang menulis Description Skill secara alami sudah salah.
Karena orang terbiasa menulisnya sebagai pengenalan fungsi. Misalnya: PR Management Skill membantu pengguna memantau status PR, menangani masalah CI, secara otomatis menyelesaikan Merge.
Tetapi masalahnya adalah, model tidak mencari Skill berdasarkan fungsi. Saat Claude Code dijalankan, ia akan memindai semua nama dan Description Skill terlebih dahulu.
Kemudian berdasarkan masalah pengguna saat ini, menilai Skill mana yang harus dimuat.
Jadi informasi terpenting dalam Description bukanlah apa yang bisa dilakukan Skill ini, melainkan dalam situasi apa Skill ini harus dimuat.
Description sebenarnya menanggung tugas routing seluruh Skill.
Di dunia nyata, jarang ada orang yang mengatakan bantu saya memanggil alat manajemen PR. Orang lebih mungkin mengatakan: bantu awasi PR ini, CI rusak lagi, dan sebagainya.
Jadi Description yang baik seharusnya sebisa mungkin menggambarkan niat pengguna, bukan hanya mencantumkan fungsi.
Saya bahkan merasa bisa menggunakan metode yang sangat sederhana untuk memeriksa.
Setelah menulis Description, hapus seluruh Skill, hanya simpan Description satu baris ini. Kemudian tanya diri sendiri: setelah model melihat masalah pengguna, apakah ia tahu kapan harus memuat Skill ini.
Jika tidak bisa, kemungkinan besar masih harus diperbaiki.
#05 Manajemen dan Distribusi Skill
Ada satu lagi tentang manajemen Skill.
Saat satu orang menggunakan Skill, masalah ini sebenarnya sederhana. Tulis beberapa Skill sendiri, kelola sendiri, tingkatkan sendiri. Tetapi saya yakin kebanyakan tim nantinya akan menghadapi masalah yang sama.
Saat Skill berkembang dari beberapa menjadi puluhan, bahkan ratusan, bagaimana Skill-skill ini harus dikelola? Bagaimana cara meningkatkannya? Bagaimana mendistribusikannya kepada anggota tim?
Pengalaman Anthropic dalam hal ini, menurut saya cukup layak dijadikan referensi.
Saat skala tim masih kecil, Skill langsung mengikuti repositori kode. Cukup letakkan di direktori .claude/skills dalam proyek. Semua orang berbagi set Skill yang sama, juga berbagi metode kerja yang sama.
Tetapi seiring bertambahnya jumlah Skill, muncul masalah baru.
Saat Claude Code dijalankan, ia akan memindai semua nama dan Description Skill, kemudian menilai Skill mana yang harus dipanggil untuk tugas saat ini. Semakin banyak Skill, biaya routing semakin tinggi.
Ini juga mengapa Anthropic kemudian mulai membuat Marketplace. Tetapi yang lebih menarik adalah cara mereka mengelola Marketplace.
Banyak perusahaan saat menghadapi masalah seperti ini, reaksi pertama sering kali adalah membangun alur persetujuan. Siapa pun yang menulis Skill, ajukan aplikasi terlebih dahulu; setelah disetujui, baru masuk ke perpustakaan Skill resmi. Kami di internal juga pernah melakukan ini sebelumnya, tetapi sangat berat. Hanya untuk mengelola.
Saya menemukan organisasi Anthropic sangat ringan.
Biarkan Skill baru menyebar dalam lingkup kecil terlebih dahulu, biarkan rekan kerja sendiri yang menginstal dan mencoba.
Jika semakin banyak orang mulai menggunakannya, itu berarti Skill ini benar-benar menyelesaikan suatu masalah nyata. Pada tahap ini, penulis baru mengirimkannya ke Marketplace resmi.
Jadi mereka tidak membahas apakah Skill berharga terlebih dahulu, melainkan membiarkannya diuji dalam penggunaan nyata. Semakin banyak yang menggunakannya, secara alami akan masuk ke sistem resmi. Skill yang tertinggal seperti ini, pada dasarnya adalah Skill yang benar-benar dibutuhkan tim.





