Viện Nghiên cứu Google gần đây đã công bố một bài báo, quan điểm cốt lõi có thể được tóm gọn trong một câu: Thay vì vật lộn một cách mù quáng để“khiến AI toàn tri toàn năng”, hãy dạy nó học cách nói “Tôi không chắc chắn”.
Bài báo có tiêu đề "Hallucinations Undermine Trust; Metacognition is a Way Forward" được hoàn thành bởi Viện Nghiên cứu Google phối hợp với Đại học Tel Aviv và đã được chấp nhận tại ICML 2026 Position Track. Bài báo đề xuất rằng hướng đi chính thống hiện tại của toàn ngành AI trong việc chống lại "ảo giác" có thể đã đi sai đường ngay từ gốc rễ - mọi người đang bận rộn nhồi nhét thêm kiến thức cho mô hình, nhưng lại bỏ qua một khả năng quan trọng hơn và bị đánh giá thấp hơn: cho phép AI cảm nhận và thể hiện mức độ tự tin của nó đối với từng câu trả lời.
(Địa chỉ bài báo: [2605.01428] Hallucinations Undermine Trust; Metacognition is a Way Forward)
Thuế thực dụng: Cái giá thực sự của việc xóa bỏ ảo giác
Trước tiên, hãy bắt đầu từ một tình huống mà ai cũng từng gặp.
Bạn hỏi trợ lý AI một câu hỏi, nó trả lời bằng một giọng điệu vô cùng quả quyết, với từ ngữ chặt chẽ, logic hoàn chỉnh, trông có vẻ hoàn hảo. Sau đó, khi bạn kiểm tra, câu trả lời đó hoàn toàn bịa đặt. Điều gây bực bội hơn là, khi nói ra, nó không hề do dự, như thể đã tận mắt chứng kiến.
Đây chính là "ảo giác" của AI - mô hình đưa ra nội dung sai lệch về mặt sự thật, nhưng lại trình bày cho người dùng theo một cách không thể nghi ngờ. Vấn đề này đặc biệt nguy hiểm trong các ngữ cảnh rủi ro cao như y tế, pháp lý, nghiên cứu khoa học.
Lối tư duy của ngành công nghiệp để đối phó với ảo giác, về bản chất, có hai con đường. Con đường thứ nhất: Làm cho AI biết nhiều hơn, thông qua mở rộng dữ liệu huấn luyện, tăng tham số mô hình để bao phủ nhiều sự thật hơn. Con đường thứ hai: Khiến AI im lặng khi không chắc chắn, gặp câu hỏi không nắm rõ thì trực tiếp từ chối trả lời.
Cả hai con đường đều có điểm yếu rõ ràng. Sự thật trên thế giới là vô hạn, mô hình không thể nhớ hết mọi thứ, vì vậy con đường thứ nhất luôn có những góc chết không thể bao phủ. Vấn đề của con đường thứ hai là, một khi AI bắt đầu từ chối trả lời trên quy mô lớn, nó sẽ từ "trợ lý hữu ích" biến thành "thứ vô dụng không dám nói gì" - người dùng hỏi mười câu, tám câu bị từ chối, trải nghiệm cực kỳ tệ.
Bài báo đã đặt cho cái giá của con đường thứ hai một cái tên chính xác: "Thuế thực dụng" (utility tax) - để giảm tỷ lệ ảo giác, bạn phải hy sinh một lượng lớn thông tin vốn có thể trả lời đúng.
Tại sao loại thuế này lại nặng đến vậy? Nguồn gốc nằm ở việc AI thiếu một khả năng then chốt. Để chiến lược "từ chối trả lời" phát huy hiệu quả chính xác, mô hình cần phân biệt chính xác giữa "câu này tôi trả lời đúng" và "câu này tôi trả lời sai" - chỉ từ chối cái sai, giữ lại cái đúng. Nhưng thực tế là, mô hình không thể thực hiện sự phân biệt chính xác này. Bài báo phân biệt hai khái niệm dễ gây nhầm lẫn nhưng mang ý nghĩa hoàn toàn khác biệt để minh họa vấn đề này.
Hiệu chỉnh (calibration) đo lường mức độ tự tin tổng thể của AI có khớp với tỷ lệ chính xác tổng thể hay không. Ví dụ, AI trả lời 100 câu hỏi, lần nào cũng nói "Tôi có 60% chắc chắn", và trong 100 câu đó đúng 60 câu, đó chính là hiệu chỉnh hoàn hảo.
Khả năng phân biệt (discrimination) đo lường AI có thể phân biệt chính xác giữa "tôi đúng" và "tôi sai" ở mỗi câu hỏi cụ thể hay không. Một AI cho tất cả câu hỏi mức độ chắc chắn 60%, tỷ lệ chính xác tổng thể đúng 60%, hiệu chỉnh có thể nói là hoàn hảo, nhưng khả năng phân biệt bằng 0 - nó hoàn toàn không thể phân biệt câu nào nên tin, câu nào nên đề phòng. Hiệu chỉnh tốt không đồng nghĩa với khả năng phân biệt mạnh, đây chính là điểm mấu chốt của vấn đề.
Bài báo đã rà soát lượng lớn tài liệu và phát hiện ra rằng, các mô hình lớn chính thống hiện tại trong các nhiệm vụ hỏi đáp kiến thức thực tế có chỉ số khả năng phân biệt AUROC tập trung trong khoảng 0.70 đến 0.85. Con số này nghe có vẻ ổn, nhưng thực tế là chưa đủ dùng. Bài báo sử dụng AUROC=0.71 làm tham số để thực hiện một nhóm tính toán mô phỏng, kết quả đáng kinh ngạc: Giả sử tỷ lệ sai lầm cơ bản của AI là 25%, để giảm tỷ lệ sai sót xuống còn 5%, AI phải từ chối trả lời hơn 52% câu hỏi đúng. Ngay cả khi nâng khả năng phân biệt lên mức 0.85, gần với giới hạn trên trong tài liệu, vẫn cần từ bỏ 28% câu trả lời đúng. Chỉ khi khả năng phân biệt đạt trên 0.95, cái giá mới có thể bỏ qua - và hiện tại không có bất kỳ phương pháp nào trong nhiệm vụ đòi hỏi kiến thức cao tiếp cận được con số này.
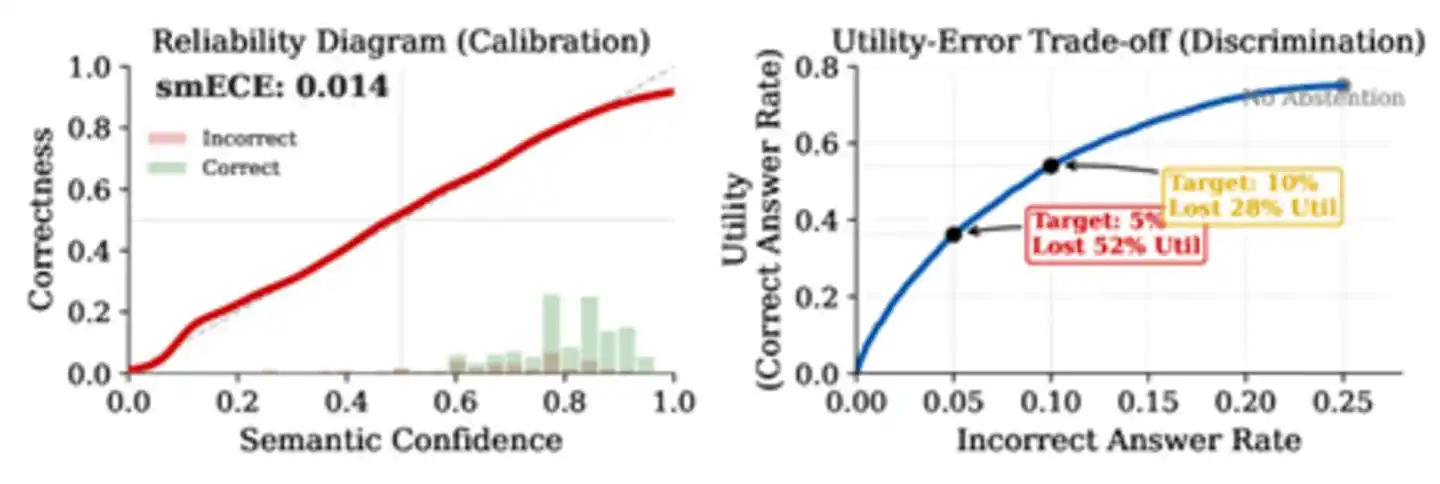
Hình: Sự khác biệt giữa hiệu chỉnh và khả năng phân biệt. Biểu đồ bên trái cho thấy mô hình được hiệu chỉnh tốt (đường đỏ gần với đường chéo), biểu đồ bên phải tiết lộ thực tế khắc nghiệt - ngay cả khi hiệu chỉnh hoàn hảo, để giảm tỷ lệ sai sót từ 25% xuống 5%, phải hy sinh 52% câu trả lời đúng.
Dữ liệu thực tế xác nhận nhận định này. Bài báo phân tích biểu hiện của các mô hình tiên phong trên bài kiểm tra chuẩn SimpleQA Verified, kết quả rõ ràng đến mức hơi tàn nhẫn: Phần lớn các mô hình phân bố dọc theo đường chéo "trả lời càng nhiều, sai càng nhiều", một số ít mô hình theo đuổi độ chính xác cao thông qua việc từ chối trả lời nhiều để đổi lấy độ chính xác trên từng câu hỏi cao hơn, nhưng lại phải trả giá thực dụng khổng lồ. Khu vực lý tưởng "góc trên bên phải" - vừa trả lời nhiều vừa ít sai - hiện tại chẳng có ai. Khoảng trống này chính là "khoảng cách khả năng phân biệt" mà bài báo đề cập.
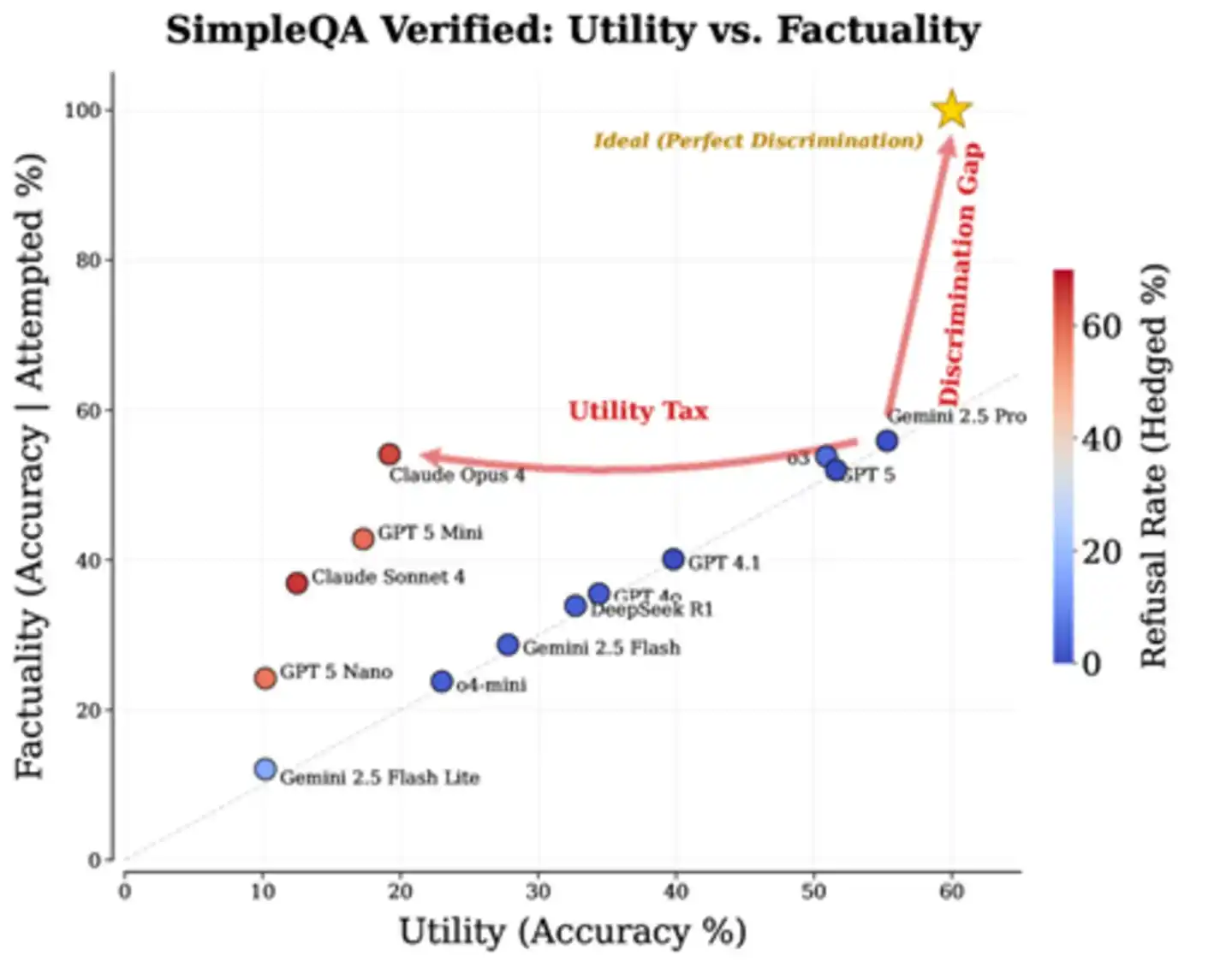
Hình: Biểu hiện thực tế của các mô hình chính thống trên SimpleQA Verified. Ngôi sao năm cánh ở góc trên bên phải là mục tiêu lý tưởng, "Discrimination Gap" đánh dấu khoảng cách giữa các mô hình hiện có với lý tưởng, "Utility Tax" đánh dấu cái giá thực dụng mà Claude Opus 4 phải trả để đổi lấy độ chính xác cao.
Vì "nhồi nhét nhiều kiến thức" có góc chết, "không chắc chắn thì im lặng" lại quá đắt đỏ, liệu có con đường thứ ba không?
Định nghĩa lại ảo giác: Không phải "nói sai", mà là "không đủ tư cách xác định nhưng lại khẳng định chắc chắn"
Đóng góp cốt lõi của bài báo không nằm ở việc chẩn đoán vấn đề, mà ở việc định nghĩa lại bản chất của vấn đề.
Trong một thời gian dài, ngành công nghiệp định nghĩa "ảo giác" là "AI xuất ra thông tin sai", điều này hàm chứa một tiền đề: xóa bỏ ảo giác = xóa bỏ tất cả sai lầm. Nhưng bài báo đề xuất, thử nhìn từ một góc độ khác - ảo giác không phải là "AI nói sai", mà là "AI không đủ tư cách xác định, nhưng lại dùng giọng điệu xác định để đưa ra thông tin sai".
Sự phân biệt này có vẻ tinh tế, nhưng thực tế ảnh hưởng sâu rộng. Ví dụ: Bác sĩ xem xong kết quả kiểm tra và nói "Bạn mắc bệnh X", nếu thực tế anh ta chỉ đoán mò dựa trên trực giác, thì đây là hành vi không có trách nhiệm. Nhưng nếu anh ta nói "Hiện tại các triệu chứng nghiêng về bệnh X, nhưng cần kiểm tra thêm để xác nhận", dù nhận định ban đầu có chệch hướng, cách diễn đạt này bản thân nó đã là trung thực - anh ta đang nói với bệnh nhân rằng "Hãy thận trọng với nhận định này". Sai lầm không phải là không thể chấp nhận, điều không thể chấp nhận là rõ ràng không chắc chắn nhưng lại giả vờ chắc chắn.
Dựa trên định nghĩa mới này, con đường thứ ba xuất hiện: Sự không chắc chắn trung thực (faithful uncertainty) - khiến AI ở cấp độ ngôn ngữ thể hiện mức độ tự tin, tương ứng trung thực với mức độ tự tin của trạng thái nội bộ của nó.
Cụ thể, "sự không chắc chắn nội bộ" của AI có thể được đo lường khách quan thông qua lấy mẫu lặp lại: hỏi cùng một câu hỏi một trăm lần, mỗi lần đều đưa ra câu trả lời giống nhau, điều này cho thấy nội tâm quả quyết; câu trả lời đủ kiểu đủ loại, cho thấy nội bộ thực sự dao động. "Sự không chắc chắn ngôn ngữ" là cảm giác chắc chắn thể hiện trong cách diễn đạt của AI - "Ngày 4 tháng 8 năm 1961" và "Hình như tôi nhớ là năm 1961, nhưng không hoàn toàn chắc chắn", tín hiệu đưa đến cho người đọc hoàn toàn khác nhau.
Sự không chắc chắn trung thực yêu cầu cả hai phải thẳng hàng: khi nội tâm dao động thì ngôn từ để lại khoảng trống, chỉ khi nội tâm quả quyết mới dùng giọng điệu xác định. Bài báo nhấn mạnh rằng mục tiêu này khả thi hơn "xóa bỏ tất cả sai lầm". Lý do là, sự không chắc chắn trung thực chỉ yêu cầu đầu ra ngôn ngữ của AI tương ứng với trạng thái nội bộ của chính nó - đây là một vấn đề khép kín, tín hiệu nằm ngay trong mô hình nội bộ, không phụ thuộc vào sự thật bên ngoài. Trong khi việc xóa bỏ sai lầm đòi hỏi đầu ra của AI phải hoàn toàn tương ứng với sự thật của thế giới bên ngoài, lý thuyết tính toán được bài báo trích dẫn chỉ ra rằng điều này có những hạn chế cơ bản về mặt lý thuyết.
Bài báo tổng kết khả năng này thành một khái niệm ở cấp độ cao hơn: Siêu nhận thức (metacognition) - AI vừa có thể cảm nhận sự không chắc chắn của chính mình, vừa có thể điều chỉnh hành vi dựa trên cảm nhận đó. Khái niệm này mượn từ tâm lý học, vốn có nghĩa là "nhận thức về quá trình nhận thức của chính mình", đặt trong ngữ cảnh AI, chính là việc AI có nhận thức rõ ràng về những gì mình biết và những gì mình không biết.
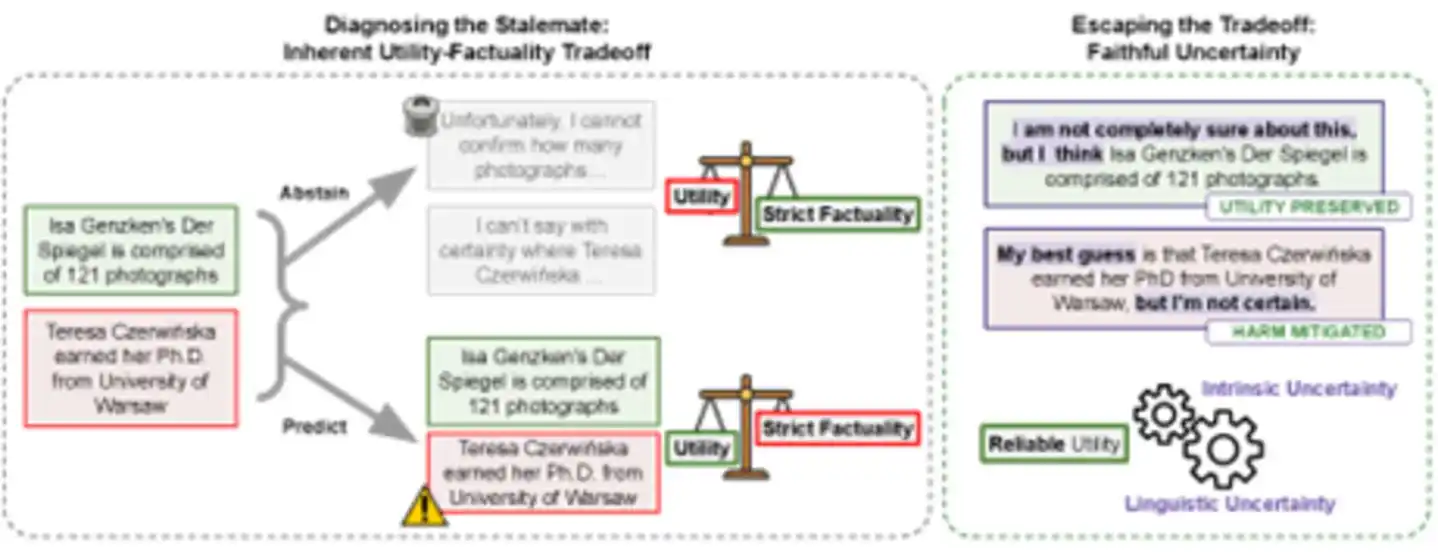
Hình: Bên trái là tình thế tiến thoái lưỡng nan truyền thống - "trả lời" có rủi ro ảo giác, "từ chối trả lời" có cái giá thực dụng. Bên phải là con đường mới - thông qua việc thể hiện trung thực sự không chắc chắn, vừa giữ lại thông tin hữu ích, vừa giảm thiểu tác hại của thông tin sai lệch, đạt được "tính thực dụng đáng tin cậy".
Thời đại đại lý AI: Agent không có siêu nhận thức chính là "bay mù"
Giá trị của siêu nhận thức không chỉ giới hạn ở các tình huống hội thoại. Trong thời đại Đại lý AI (Agent), nó trở nên càng quan trọng hơn.
Về mặt bề ngoài, chỉ cần trang bị công cụ tìm kiếm cho AI là có thể giải quyết vấn đề thiếu kiến thức - không biết thì tra cứu, còn sợ gì ảo giác? Nhưng bài báo chỉ ra rằng, việc đưa công cụ vào không phải là một "giải pháp lưu trữ", mà là một "vấn đề kiểm soát".
Sau khi có công cụ, AI phải đối mặt với một loạt quyết định mới: Câu hỏi này tôi tự biết không, có cần tìm kiếm không? Thông tin tìm kiếm ra có đáng tin không? Nếu kết quả tìm kiếm mâu thuẫn với thông tin tôi nắm giữ, nên nghe theo ai? Tìm kiếm đến khi nào thì nên dừng lại?
Tất cả những quyết định này đều dựa vào cảm nhận chính xác của AI về mức độ tự tin nội bộ của chính nó. Một Đại lý AI không có khả năng siêu nhận thức, giống như một phi công không có bảng điều khiển - động cơ đang báo động, anh ta vẫn tăng tốc.
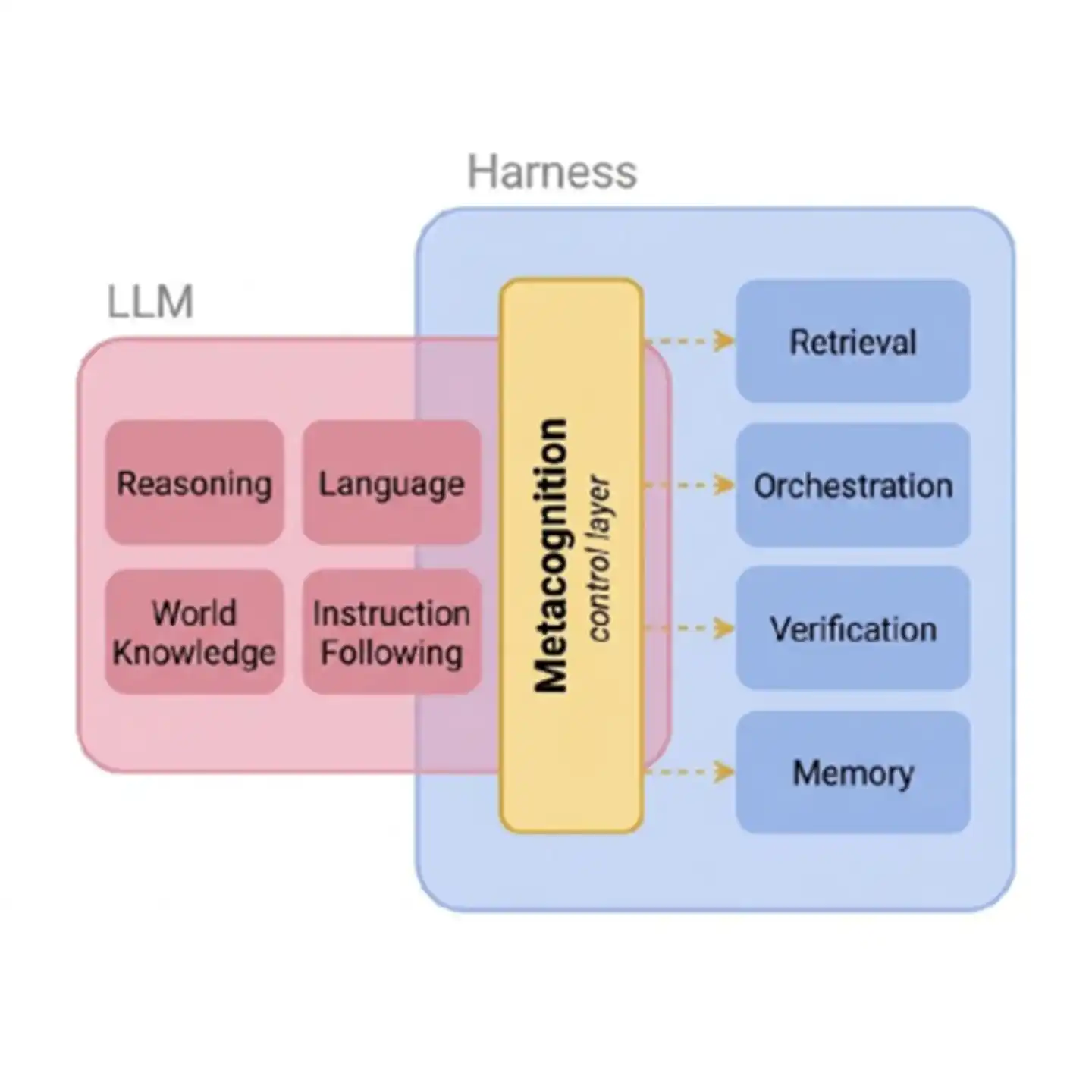
Hình: Tầng kiểm soát siêu nhận thức đóng vai trò cầu nối giữa khả năng cơ bản của AI và hệ thống công cụ bên ngoài. Không có tầng này, việc điều phối công cụ bên ngoài của Agent giống như "bay mù" - không biết có nên tìm kiếm không, tìm rồi có nên tin không, tin thì tin đến mức độ nào.
Nghiên cứu được bài báo trích dẫn chỉ ra rằng, các Đại lý AI tăng cường tìm kiếm hiện tại phổ biến tồn tại vấn đề lạm dụng công cụ - đối với những vấn đề hoàn toàn không cần tìm kiếm cũng đi tìm, hiệu quả thấp và đưa thêm nhiễu không cần thiết. Lý do rất đơn giản: AI không có siêu nhận thức hoàn toàn không thể đánh giá "tôi có cần thêm thông tin hay không".
Trên con đường hướng tới siêu nhận thức, vẫn còn vài khó khăn nan giải
Bài báo cũng thẳng thắn chỉ ra những thách thức then chốt trên con đường thực hiện.
"Nghịch lý tự khởi động" (Bootstrap Paradox): Dạy AI thể hiện sự không chắc chắn cần dữ liệu huấn luyện mẫu để làm mẫu "khi nào nên do dự", nhưng ranh giới kiến thức của AI là động và thay đổi. Một mẫu dữ liệu được gắn nhãn "Tôi không chắc chắn", sau khi mô hình tiến hóa, có thể biến thành nội dung mà nó biết chắc chắn. Sử dụng dữ liệu tĩnh để dạy khả năng động sẽ huấn luyện ra AI "giả vờ không chắc chắn". Điều này cần phát triển cơ sở hạ tầng dữ liệu động có thể phản ánh ranh giới kiến thức hiện tại của mô hình.
"Tín hiệu phá hủy sự căn chỉnh" (Alignment Breaking Signal): Nghiên cứu phát hiện, AI sau khi được huấn luyện trước thực sự đã có tín hiệu không chắc chắn nội bộ khá tốt - trạng thái nội bộ của nó có thể phân biệt giữa "câu này tương đối có chắc chắn" và "câu này không chắc lắm". Nhưng quá trình huấn luyện căn chỉnh như RLHF sẽ làm mờ tín hiệu này. Lý do là, sở thích của con người nghiêng về những câu trả lời có giọng điệu xác định, điều này buộc AI học được rằng bất kể nội tâm dao động thế nào, đối ngoại đều thể hiện ra vẻ đầy tự tin.
"Đánh giá tính nhân quả" (Causal Evaluation): Vấn đề nan giải ở tầng sâu hơn là, làm thế nào để đảm bảo AI thực sự đang đọc tín hiệu nội bộ, chứ không phải học được cái vỏ bề mặt "gặp từ lạ thì nói tôi không chắc chắn"? Phân biệt giữa "siêu nhận thức thực sự" và "biểu diễn siêu nhận thức", là một vấn đề đánh giá khoa học cơ bản.
Bài báo cũng đưa ra đề xuất cụ thể với cộng đồng nghiên cứu: Đừng chỉ sử dụng một con số tỷ lệ chính xác duy nhất để đánh giá các phương pháp chống ảo giác, mà nên hiển thị hóa toàn bộ "đường cong đánh đổi tính thực dụng - tỷ lệ sai sót", xem rõ một phương pháp có thực sự nâng cao khả năng phân biệt ở tầng đáy hay không, hay chỉ đơn thuần là điều chỉnh ngưỡng từ chối trả lời trên cùng một đường cong. Đồng thời nên kiểm tra "thiệt hại kèm theo" - để giảm tỷ lệ sai sót trong hỏi đáp kiến thức, có phải đã phải trả giá ngoài ý muốn trên các nhiệm vụ suy luận, lập trình, viết lách hay không.
Suy cho cùng, thông điệp cốt lõi mà bài báo muốn truyền tải là: AI có thể không toàn tri toàn năng, nhưng nó phải có nhận thức trung thực về những gì mình biết và những gì mình không biết, và truyền đạt nhận thức đó cho người dùng.
Chúng ta tin tưởng các chuyên gia, không phải vì họ không bao giờ phạm sai lầm, mà vì họ có thể trung thực phân biệt giữa "tôi chắc chắn" và "tôi đoán mò" - chính sự phân biệt này đã tạo nên khoảng cách giữa chuyên nghiệp và không chuyên nghiệp. AI cũng nên đi theo con đường này. Thay vì đuổi theo không ngừng một ảo ảnh hoàn hảo không sai sót, hãy để AI học một việc thực tế hơn: Biết mình đang nói nhảm khi nào, và thành thật nói với người dùng. (Bài viết lần đầu được đăng trên Titanium Media APP, tác giả | 硅谷Tech_news, biên tập viên | 焦燕)