Imaginez une telle scène :
Une personne âgée vivant seule glisse et tombe dans son salon, la douleur l'empêchant de crier à l'aide. À cet instant, son dispositif intelligent ou la caméra de sa maison "voit" l'anomalie, et l'IA, sans attendre d'ordre vocal, émet activement une alerte, contactant rapidement la famille ou les urgences.
Ou bien, vous regardez un match de football intense, et au moment crucial où un but est marqué, vous n'avez pas le temps de revenir en arrière ou de poser une question ; les lunettes intelligentes à IA vous fournissent automatiquement une analyse au ralenti et une interprétation tactique.
Ces scénarios ne sont plus une fantaisie futuriste, mais de vrais problèmes que le premier modèle d'interaction vision-langage entièrement open source au monde — JoyAI-VL-Interaction, vient d'être publié par JD.com (Jingdong) tente de résoudre.

Ces deux dernières années, les capacités des grands modèles n'ont cessé de s'étendre, mais l'interaction principale reste basée sur la logique du "tour par tour" : "l'utilisateur pose une question, le modèle répond". C'est efficace, mais dans de nombreux cas, ce n'est pas pertinent. Beaucoup d'événements importants se produisent trop vite pour que l'utilisateur puisse poser une question ; dans de nombreuses situations, il n'y a tout simplement pas d'ordre vocal.
Cette année, un constat devient un consensus dans le secteur : l'IA passe de la "prédiction du prochain token" à la "prédiction du prochain état physique". Cela signifie aussi que l'IA doit évoluer d'un processeur d'information passif à un participant actif.
C'est précisément à ce moment que JD.com publie en open source JoyAI-VL-Interaction, le premier modèle d'interaction vision-langage en temps réel entièrement open source au monde, capable de juger de manière autonome dans un flux vidéo continu quand répondre, quand garder le silence, quand confier des tâches complexes aux modèles backend.
JoyAI-VL-Interaction veut démontrer qu'une IA qui pénètre vraiment le monde physique ne devrait pas toujours attendre d'être interrogée ; elle devrait apprendre à voir, à juger activement, et à offrir de l'aide au bon moment.
C'est aussi un signal plus large envoyé par l'IA de JD.com : des capacités du modèle aux scénarios industriels, la concurrence en IA passe des questions-réponses à l'écran vers le monde réel.
Pourquoi l'interaction vision-langage ?
Dans le monde physique réel, une quantité énorme d'informations cruciales survient à des moments où l'utilisateur n'a pas le temps de poser une question. Ce sentiment de "trop tard" est parfois un problème d'expérience, mais le plus souvent, c'est une question de limites de capacités imposées par le paradigme.
Le secteur n'est pas inconscient de cette limite.
Au premier semestre 2026, l'interaction en temps réel est devenue le mot-clé le plus chaud en IA multimodale. L'industrie avance globalement selon deux voies : l'une consiste à rendre les dialogues au tour par tour plus rapides, l'autre à rendre les appels vocaux plus naturels.
La première met l'accent sur une faible latence ou des entrées/sorties arbitraires, mais le noyau reste "il ne répond que si vous demandez" ; la seconde permet au modèle d'écouter et de parler simultanément, d'être interrompu à tout moment, offrant une expérience plus proche d'un appel réel, mais l'accent reste sur les scénarios vocaux.
Le problème est que de nombreux changements dans le monde réel ne se transforment pas d'abord en une phrase. Un début d'incendie, une chute, l'approche d'un véhicule, un changement à l'écran, une anomalie sur une ligne de production : l'image précède toujours le langage. Si l'IA ne peut qu'attendre que l'on s'exprime, elle aura du mal à être vraiment "présente".
La seule entité à avoir fait le même constat en même temps que JD.com est Thinking Machines Lab, fondé par Mira Murati. Le 11 mai, cette entreprise a présenté le concept d'"interaction models" (modèles d'interaction) et a publié des aperçus de recherche, soulignant que le paradigme de réponse autonome des modèles d'interaction offre un espace d'imagination plus large pour la collaboration Homme-IA par rapport au paradigme traditionnel question-réponse.
Le fait que deux équipes convergent au même moment vers la même idée est en soi un signal : faire de l'interactivité une capacité propre du modèle à grande échelle est une direction incontournable pour l'industrie dans les années à venir.
La différence est que JD.com place la vision-langage dans une position plus centrale, en extrayant la voix en tant qu'entrée/sortie (I/O) amovible, faisant de la vision-langage la "modalité de pilotage de premier ordre" pour les décisions autonomes du modèle.
En d'autres termes, dès l'instant où la caméra s'allume, JoyAI-VL-Interaction "regarde" continuellement les changements visuels du monde physique et juge de manière autonome s'il faut intervenir, quoi dire, s'il faut déléguer la tâche.
C'est aussi là que réside le potentiel de l'interaction visuelle : elle peut être utilisée pour la surveillance des personnes âgées et des enfants, l'assistance aux malvoyants, les lunettes intelligentes, le commentaire sportif, l'inspection en magasin, la logistique d'entrepôt, la collaboration avec les robots, etc. L'utilisateur n'a pas besoin de formuler d'abord sa question en une phrase ; l'IA peut capter le besoin à partir des changements environnementaux.
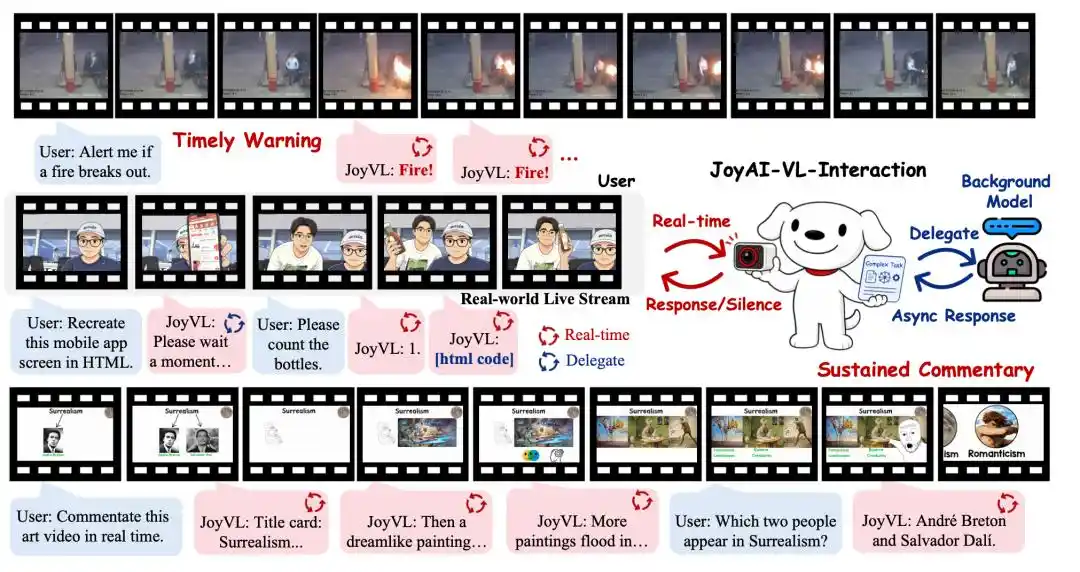
Ainsi, la vision n'est pas seulement un autre mode d'entrée, mais un canal de perception indispensable pour que l'IA progresse vers la "prédiction du prochain état physique".
Le rapport technique de JoyAI-VL-Interaction de JD.com renforce également ce point, montrant que dans six scénarios réels de flux, JoyAI-VL-Interaction atteint un taux de victoire de 77,6 % contre les principaux modèles chinois et de 87,9 % contre les modèles étrangers ; dans le scénario de surveillance et d'alerte, le plus exigeant en termes de détection d'événements, le taux de victoire atteint 100 %. Le rapport indique que l'écart ne réside pas seulement dans la qualité des réponses, mais dans la capacité à agir au bon moment.
Simplement, réaliser une interaction visuelle active est effectivement plus difficile.
L'acquisition de données pour l'interaction vocale est relativement directe ; de nombreux jeux de données de commandes vocales permettent au modèle d'apprendre quand les humains parlent, comment interrompre, comment répondre. Les données nécessaires à l'interaction visuelle sont complètement différentes. Le modèle doit apprendre, dans un flux d'images en évolution continue, quels signaux méritent une réponse et lesquels doivent être ignorés.
Une barrière plus profonde est la capacité à définir les scénarios. Dans l'interaction vocale, il existe une limite de déclenchement naturelle : l'utilisateur qui parle marque le début de l'interaction. L'interaction visuelle n'a pas de début ni de fin clairs ; le modèle doit lui-même juger des limites dans un flux d'informations sans frontières.
C'est là que réside la particularité de JD.com : cette entreprise ne cherche pas ses scénarios dans un laboratoire abstrait, mais opère naturellement au sein de réseaux commerciaux réels comme la vente au détail, la logistique, la santé, l'industrie, etc.
Cela signifie que l'IA de JD.com n'est pas confrontée à une seule interface de discussion, mais à une multitude de tâches réelles : comment les marchandises circulent, comment les équipements collaborent, comment les robots interagissent avec les humains, comment les anomalies sont détectées à l'avance. Le modèle peut apprendre à partir de besoins réels et s'améliorer grâce à des retours concrets.
Bien qu'il y ait des compromis dans les approches techniques, la forme d'interaction de l'AGI général futur sera nécessairement une intelligence active ; l'agent intelligent doit posséder un cycle complet de perception de l'environnement, de prise de décision autonome et de réponse en temps réel. Par conséquent, de nombreuses entreprises ne refusent pas de développer des grands modèles d'interaction visuelle, mais manquent actuellement du terreau nécessaire pour les faire émerger. C'est aussi pourquoi les capitaux et la puissance de calcul affluent d'abord vers la piste de l'interaction vocale.
Ainsi, le choix de JD.com de partir de la vision n'est pas seulement un choix technique, mais aussi une conséquence de sa position stratégique. Par rapport à de nombreux acteurs des grands modèles, JD.com est plus proche du terrain opérationnel du monde physique et a aussi plus besoin d'une IA capable de perception active et de réponse en temps réel.
Pour que ce jour arrive plus vite, il faut que quelqu'un parte plus tôt.
Léger, Open Source, Déployable
Que signifie le premier projet entièrement open source au monde ?
Redéfinir un paradigme d'interaction semble grandiose, mais lorsqu'il s'agit de l'appliquer, le premier obstacle est très simple : l'IA ne doit pas toujours déranger les gens, ni rester silencieuse quand elle devrait alerter.
On s'attend généralement à ce que l'IA parle le plus possible, mais dans les scénarios d'interaction visuelle en temps réel, un modèle qui interrompt constamment n'est pas intelligent. La vraie capacité de valeur est d'apparaître activement au moment crucial et de rester silencieux quand cela n'a pas d'importance.
C'est pourquoi JoyAI-VL-Interaction a entraîné le "silence" en tant que compétence. Le modèle doit maîtriser trois niveaux de jugement : dans quel scénario il doit répondre activement, dans quel scénario il doit garder le silence, et dans quel scénario il doit déléguer la tâche à d'autres modèles.
Si cette capacité reste limitée aux articles de recherche, sa valeur est limitée. L'accent mis par JD.com sur "entièrement open source" réside dans le fait d'ouvrir ensemble le modèle, le système d'inférence et les chemins de développement d'applications, permettant aux développeurs de vraiment les exécuter, les modifier et les utiliser.
JD.com a choisi une approche technique plus propice à la diffusion : un modèle de 8 milliards de paramètres, qu'une seule carte graphique 3090 peut déployer. Avec cette taille, les développeurs individuels peuvent l'exécuter, le matériel grand public peut le supporter, et les dispositifs en périphérie peuvent l'intégrer.
Pour l'interaction visuelle en temps réel, cette légèreté ne signifie pas une réduction des capacités, mais une répartition des rôles plus claire.
JoyAI-VL-Interaction ressemble plus à une couche d'interaction frontale, responsable de voir l'environnement, de juger du moment opportun, d'accomplir une communication brève. Lorsqu'elle rencontre des tâches complexes nécessitant un raisonnement approfondi, elle les délègue automatiquement à des agents backend choisis par l'utilisateur comme OpenClaw, Codex, Claude Code, etc. Un modèle de 8B est donc suffisant.
Par exemple, le modèle peut d'abord dire à l'utilisateur "Je vais y réfléchir", puis confier le problème difficile au backend, tout en restant présent ; une fois le résultat renvoyé par le backend, il transmet la réponse à l'utilisateur. Pendant ce temps, il peut continuer à aider l'utilisateur avec d'autres interactions immédiates.
JD.com a également opté pour une conception légère au niveau du système sous-jacent : grâce au codage vidéo, à la mémoire à long terme et à la compression de contexte, le modèle peut observer en continu de longs flux vidéo à un coût relativement faible et maintenir une latence de bout en bout inférieure à la seconde. Pour le lecteur ordinaire, l'important n'est pas ces termes techniques, mais le résultat : l'IA peut rester plus longtemps et avec un seuil d'entrée plus bas dans les scénarios réels.
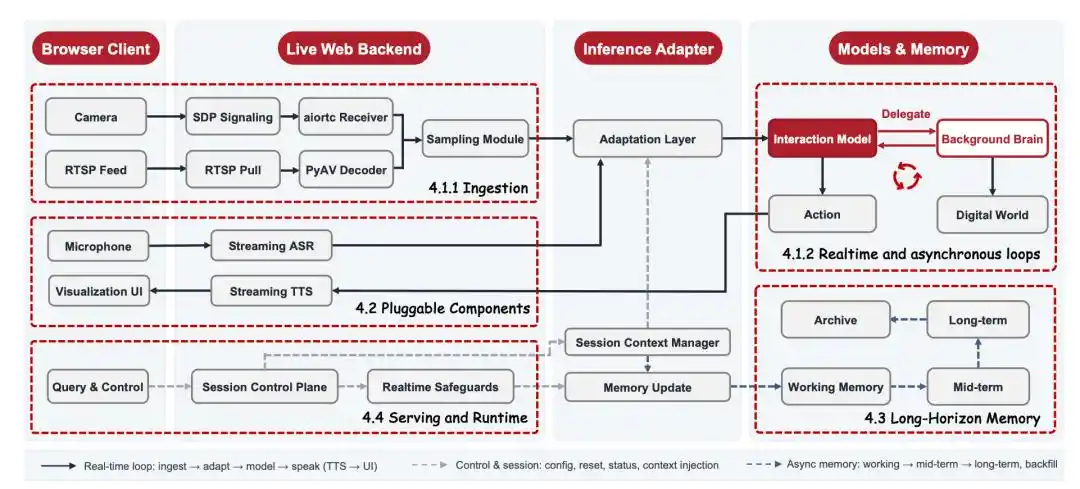
Le choix d'une solution rentable et déployable conduit également directement à la stratégie open source de JD.com. Ce n'est que si le modèle est suffisamment léger, le système suffisamment complet et le seuil de déploiement suffisamment bas que l'interaction visuelle en temps réel peut passer de l'expérience de quelques équipes à un écosystème d'applications exploré conjointement par davantage de développeurs et d'entreprises.
JD.com a déjà publié en open source ce système d'inférence, avec un objectif clair : permettre à toute personne disposant d'une carte graphique 3090 (ou supérieure) et d'une caméra de construire rapidement sa propre application d'interaction visuelle en temps réel.
JoyAI-VL-Interaction bénéficie du support day-0 de vLLM-Omni et a été intégré nativement dans la branche principale de vLLM-Omni.
Ramener l'IA dans le monde physique
L'objectif de l'open source est de confier le potentiel d'application à un marché plus large. Car la valeur d'une percée technique doit finalement être validée par le monde réel.
Les premières idées d'application pour JoyAI-VL-Interaction sont déjà très claires : dans les diffusions sportives, l'IA peut commenter automatiquement les buts cruciaux ou les dernières secondes ; en surveillance boursière, elle peut observer continuellement les changements à l'écran et signaler les anomalies ; dans la surveillance à domicile, elle peut alerter activement en cas de chute d'une personne âgée ou d'approche d'une zone dangereuse par un enfant ; couplée à des lunettes intelligentes, elle peut aider l'utilisateur à reconnaître la route, les produits, les écrans et l'environnement ; en assistant les malvoyants, elle peut transformer les informations visuelles en aides en temps réel.
Pour JD.com, on espère surtout qu'elle pourra être intégrée aux robots : un modèle qui sait quand parler, quand se taire, quand demander de l'aide au système backend peut rendre les robots plus efficaces et plus proches de l'assistant intelligent "sachant se tenir à sa place" que les gens attendent.
La raison fondamentale pour laquelle JD.com ose "bousculer" ce domaine à ce moment est qu'il détient un actif que les autres acteurs des grands modèles ne possèdent pas : des données du monde physique.
Placé dans le contexte sectoriel de 2026, le poids des actifs de données du monde physique est particulièrement important.
2026 est qualifiée par le secteur d'"année de naissance des données pour l'intelligence incarnée". Dans ce contexte grandiose, une contradiction aiguë se fait jour : les données de qualité sur l'interaction physique sont extrêmement rares, loin de satisfaire les besoins d'entraînement à grande échelle, et le goulot d'étranglement de l'itération algorithmique se déplace massivement du côté des modèles vers celui des données.
C'est à ce moment précis que JD.com annonce son intention d'accumuler 10 millions d'heures de données vidéo de haute qualité provenant de scénarios réels en deux ans, mobilisant 600 000 personnes pour la collecte.
JD.com dispose de plus de 3 000 scénarios commerciaux réels, couvrant la vente au détail, la logistique, la santé, l'industrie, etc. Cette année, il a également innové à Suqian avec un modèle de collecte communautaire par maillage, déployant en masse son terminal JoyEgoCam et mobilisant les petites et moyennes entreprises ainsi que les résidents locaux pour collecter dans des scénarios opérationnels réels.
La vitesse de déploiement est rapide. En mars, JD.com annonce la construction à Suqian du premier centre de collecte de données pour l'intelligence incarnée au monde ; en avril, il publie la première infrastructure de données pour l'intelligence incarnée couvrant toute la chaîne collecte, stockage, annotation, entraînement, évaluation, simulation, test ; en mai, la production en série de JoyEgoCam commence, permettant une collecte continue de données en vue à la première personne.
Ces données constituent le carburant le plus rare pour entraîner les modèles d'intelligence incarnée et d'interaction visuelle. À mesure que les données d'incarnation intègrent l'entraînement, la valeur de JoyAI-VL-Interaction évoluera également d'"un modèle capable de voir activement" vers les robots, les véhicules autonomes, les entrepôts, les magasins et les foyers, c'est-à-dire des espaces physiques plus concrets.
Entre le modèle et l'application, JoyAI-Echo, également publié en open source par JD.com le 3 juin, joue un rôle clé. Echo excelle dans la génération en temps réel de longues vidéos, tandis qu'Interaction excelle dans la compréhension et l'interaction en temps réel. La publication en open source de deux modèles en un mois signifie que JD.com a connecté les deux extrémités (entrée et sortie) du multimodal vidéo et place l'avancée de l'IA dans le monde physique dans une perspective à plus long terme.
Lors de la conférence de lancement du 618 cette année, JD.com a déclaré vouloir devenir "le plus grand centre opérationnel du monde physique au monde".
À l'ère de l'interaction homme-machine, le secteur s'intéresse de plus en plus à la manière dont l'IA comprend le monde physique, mais la logique de résolution de JD.com diffère de celle de la plupart des acteurs des grands modèles : cette entreprise opère déjà dans le monde physique.
Les entrepôts, la livraison, la vente au détail, la santé, l'industrie sont autant de terrains d'entraînement et d'expérimentation pour l'IA et l'intelligence incarnée. Rien que pour la logistique de JD.com, 3 millions de robots, 1 million de véhicules autonomes et 100 000 drones sont prévus dans les cinq prochaines années ; ces équipements deviendront également un terrain d'application pour JoyAI-VL-Interaction.
Qu'elle soit vocale ou visuelle, les modèles d'interaction existent essentiellement pour connecter le monde physique et le monde numérique, comprendre le monde physique et orchestrer le monde numérique.
L'open source est la première fenêtre que JD.com ouvre vers l'extérieur. Sur cette piste où les besoins poussent la technologie, JD.com publie le modèle, les données d'entraînement et le système complet, en pariant sur quelque chose de plus lointain : faire de l'interaction active, actuellement un choix de quelques équipes, un canal principal pour l'avancée de l'IA vers le monde physique.
Vous pouvez démarrer le service en un clic sur vLLM-Omni ou lancer l'application en un clic depuis le dépôt :
Adresse du code : https://github.com/jd-opensource/JoyAI-VL-Interaction
Adresse du modèle : https://huggingface.co/jdopensource/JoyAI-VL-Interaction-Preview
Adresse du jeu de données : https://huggingface.co/datasets/jdopensource/JoyAI-VL-Interaction
Adresse du rapport technique : https://huggingface.co/papers/2606.14777






