Note de la rédaction : Beaucoup de personnes utilisant Claude Code ont l'impression que les Tokens sont consommés trop vite et que les longues sessions épuisent facilement le quota. Mais du point de vue d'un ingénieur d'Anthropic, ce qui impacte réellement le coût, ce n'est pas tant la quantité de code écrite, mais plutôt la réutilisation continue du contexte déjà traité.
L'essentiel de cet article est d'expliquer comment économiser des Tokens via un mécanisme de cache. L'auteur a réutilisé plus de 300 millions de Tokens en une semaine grâce au cache, avec un pic quotidien de 91 millions. Le coût d'un Token en cache n'étant que de 10% de celui d'un Token d'entrée classique, 91 millions de Tokens en cache équivalent en facturation à environ 9 millions de Tokens normaux. Si les longues sessions de Claude Code semblent plus "économes", ce n'est pas parce que le modèle travaille gratuitement, mais parce qu'une grande partie du contexte répétitif est réutilisée avec succès.
La clé du "Prompt caching" est de "ne pas interrompre le cache". Claude Code met en cache de manière hiérarchique l'invite système, les définitions d'outils, CLAUDE.md, les règles du projet et l'historique de la conversation ; tant que le préfixe des requêtes suivantes reste cohérent, Claude peut lire directement depuis le cache au lieu de retraiter tout le contexte. Anthropic surveille également en interne le taux de réutilisation du cache de prompts, car cela affecte non seulement le quota utilisateur, mais aussi directement le coût du service de modèle et son efficacité opérationnelle.
Pour l'utilisateur lambda, il n'est pas nécessaire de comprendre tous les détails techniques, mais plutôt d'adopter quelques bonnes pratiques clés : ne pas laisser une session inactive plus d'une heure ; effectuer un transfert de session propre lors d'un changement de tâche ; éviter de changer fréquemment de modèle ; et privilégier l'ajout de grands documents dans les "Projects" plutôt que de les coller à plusieurs reprises dans la conversation.
Cet article ne se contente pas de donner une astuce pour économiser des Tokens, il propose plutôt une méthode d'utilisation de Claude Code plus proche de la pensée ingénieur : considérer le contexte comme un actif à gérer, permettant une réutilisation continue du cache et évitant aux longues sessions de refaire des calculs redondants.
Voici l'article original :
J'ai économisé 300 millions de Tokens cette semaine, dont 91 millions en une seule journée, soit plus de 300 millions sur la semaine.
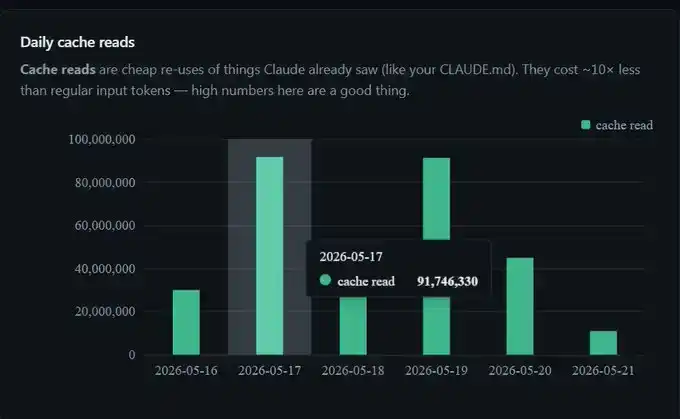
Je n'ai modifié aucun paramètre. C'est simplement le "prompt caching" qui fonctionne normalement en arrière-plan.
Mais une fois que j'ai vraiment compris ce qu'est le cache et comment éviter de l'"interrompre", avec le même quota d'utilisation, mes sessions ont pu durer plus longtemps. Voici donc un guide d'introduction 80/20 sur le prompt caching de Claude Code, sans entrer dans les détails profonds de l'API.
TL;DR
Le coût d'un Token en cache est seulement 10% de celui d'un Token d'entrée normal. 91 millions de Tokens en cache équivalent en facturation à environ 9 millions de Tokens.
Le TTL (durée de vie) du cache pour l'abonnement Claude Code est de 1 heure ; par défaut 5 minutes pour l'API ; et toujours 5 minutes pour les Sub-agents.
Le cache est divisé en trois couches : système, projet, conversation.
Changer de modèle en cours de conversation détruit le cache, y compris l'activation du mode "opus plan".
Comment le cache est-il facturé exactement ?
Chaque Token mis en cache coûte 10% du prix d'un Token d'entrée normal.

Ainsi, lorsque mon tableau de bord montre qu'un jour donné, 91 millions de Tokens ont été servis depuis le cache, la facturation réelle équivaut environ au traitement de 9 millions de Tokens. C'est pourquoi, comparé à une utilisation sans cache, l'utilisation prolongée de Claude Code donne l'impression que les sessions s'allongent presque "gratuitement".
Deux chiffres dans le tableau de bord méritent une attention particulière :
Cache create (Création de cache) : Coût ponctuel généré lors de l'écriture du contenu dans le cache. Il commence à porter ses fruits lors du tour de conversation suivant.
Cache read (Lecture du cache) : Tokens que Claude réutilise depuis le cache, comme votre CLAUDE.md, les définitions d'outils, les messages précédents, etc. C'est 10 fois moins cher que de les retraiter comme nouvelle entrée.

Si votre chiffre "Cache read" est élevé, cela signifie que vous utilisez efficacement le cache ; s'il est bas, vous payez à plusieurs reprises pour le même contexte.
Thariq d'Anthropic a fait une remarque qui m'a marqué : "Nous surveillons en fait le taux d'utilisation du prompt cache. S'il devient trop bas, cela déclenche une alerte, voire un incident de niveau SEV."
Il a également écrit un excellent article sur X. Lorsque le taux d'utilisation du cache est élevé, quatre choses se produisent simultanément : Claude Code semble plus rapide, le coût du service d'Anthropic diminue, votre quota d'abonnement semble plus durable, et les longues sessions de codage deviennent plus réalistes.
Mais si le taux d'utilisation est faible, tout le monde y perd.

Ainsi, l'intérêt des deux parties est aligné : Anthropic souhaite que votre taux d'utilisation du cache soit élevé, et vous aussi. Ce qui vous freine réellement, ce sont quelques habitudes anodines en apparence, mais qui réinitialisent silencieusement le cache.
Comment le cache se développe-t-il à chaque tour de conversation ?
Le cache repose sur le "prefix matching" ou "correspondance de préfixe".
Sans entrer dans des détails techniques trop profonds, il suffit de comprendre ceci : tant que le contenu précédant une certaine position est exactement le même que celui déjà mis en cache, Claude peut réutiliser ces Tokens du cache.
Une session complètement nouvelle se déroule à peu près ainsi :
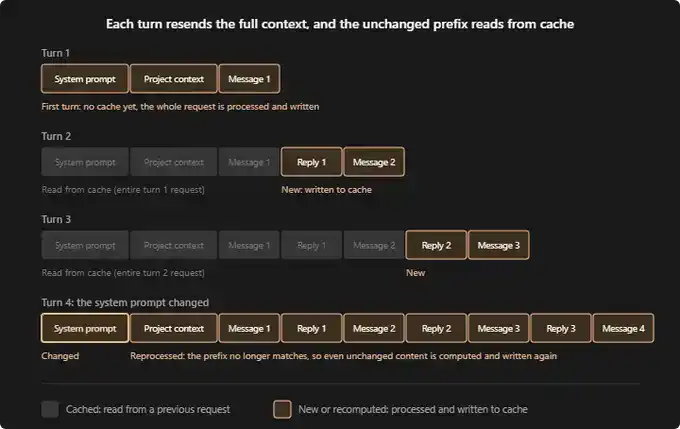
D'après la documentation de Claude Code, une session entièrement nouvelle s'exécute typiquement ainsi :
Premier tour de conversation : Pas encore de cache. L'invite système, le contexte de votre projet (comme CLAUDE.md, la mémoire, les règles), ainsi que votre premier message sont tous retraités et écrits dans le cache.
Deuxième tour de conversation : Tout le contenu du premier tour est maintenant en cache. Claude n'a qu'à traiter votre nouvelle réponse et le message suivant. Le coût de ce tour est bien plus bas.
Troisième tour de conversation : Même logique. Les tours de conversation précédents restent dans le cache, seul le dernier échange doit être retraité.
Le cache lui-même peut être divisé en trois couches :

D'après l'article de Thariq sur X :
Couche système (System layer) : Inclut les instructions de base, les définitions d'outils (read, write, bash, grep, glob) et le style de sortie. Cette couche est mise en cache globalement.
Couche projet (Project layer) : Inclut CLAUDE.md, la mémoire, les règles du projet. Cette couche est mise en cache par projet.
Couche conversation (Conversation) : Inclut les réponses et les messages, et s'étend à chaque tour de conversation.
Si, en cours de session, un élément de la couche système ou projet change, tout doit être remis en cache depuis le début. C'est l'opération la plus "coûteuse". Imaginez : vous en êtes au 16e message, vous modifiez soudain l'invite système, ou vous faites une pause d'une heure, alors tous les Tokens depuis le premier message devront être retraités.
La confusion entre 1 heure et 5 minutes
C'est le point le plus facilement mal compris.
Abonnement Claude Code : TTL par défaut de 1 heure.
API Claude : TTL par défaut de 5 minutes. Vous pouvez payer plus pour le porter à 1 heure.
Sub-agent (quel que soit le plan) : Toujours 5 minutes.
Chat web Claude.ai : Pas de documentation officielle claire. Probablement identique à l'abonnement, mais je n'ai pas pu le confirmer.
Il y a quelques mois, beaucoup se plaignaient que le quota Claude s'épuisait trop vite. Certains pensaient qu'Anthropic avait discrètement réduit le TTL de 1 heure à 5 minutes sans avertir les utilisateurs. Mais ce n'était pas le cas, le TTL de Claude Code reste de 1 heure.
Le problème vient du fait que la documentation de Claude Code et celle de l'API sont séparées, et qu'il s'agit de choses complètement différentes, ce qui a créé pas mal de confusion.
Si vous exécutez massivement des workflows de Sub-agents, ou utilisez directement l'API, le chiffre de 5 minutes est important. Mais pour 95% des utilisateurs de Claude Code, ce qu'il faut vraiment retenir, c'est cette fenêtre d'1 heure.
Trois habitudes pour couvrir 95% des utilisateurs
Voici ce que je trouve vraiment utile dans l'usage quotidien.
Ne pas faire de pause trop longue
Si vous êtes inactif depuis plus d'une heure, le contenu précédent a essentiellement expiré du cache. Votre prochain message reconstruira le cache. Dans ce cas, plutôt que de reprendre une ancienne session "refroidie", il est souvent plus économique de faire une transition claire, puis de démarrer une nouvelle session.
Lors d'un changement de tâche, recommencez directement
/compact ou /clear détruisent déjà le cache, donc autant profiter de ce moment pour vraiment réinitialiser.
J'ai créé une compétence "session handoff" (transfert de session) pour remplacer /compact. Elle résume ce que nous avons accompli, les décisions en suspens, les fichiers les plus importants, et par où reprendre. Ensuite, j'exécute /clear, je colle ce résumé, et je peux continuer comme si rien ne s'était interrompu.
La commande compact peut parfois être lente. Alors que cette compétence handoff se termine généralement en moins d'une minute.
Dans le chat Claude, placez les grands documents dans Projects
Le mécanisme de cache sur Claude.ai n'est pas officiellement très détaillé, mais il est évident que les Projects sont optimisés différemment des fils de conversation normaux. Donc, si vous devez coller de gros documents, mieux vaut les placer dans un Project plutôt que de les insérer directement dans la conversation.
Quelles actions détruisent silencieusement le cache ?
Certaines choses réinitialisent complètement le cache sans avertissement évident.
Changer de modèle : Parce que le cache dépend de la correspondance de préfixe, et chaque modèle a son propre cache. Dès que vous changez de modèle, la prochaine requête relira l'historique complet sans aucun accès au cache.
Mode "Opus plan" : Ce paramètre utilise Opus pour la phase de planification et Sonnet pour l'exécution. Je l'ai recommandé dans certaines vidéos d'optimisation de tokens, pour une bonne raison. Mais il faut comprendre que chaque activation de "plan" est essentiellement un changement de modèle, ce qui signifie reconstruire le cache. À long terme, cela aide toujours à prolonger le quota de session, mais vous devez savoir ce qui se passe en arrière-plan.
Modifier CLAUDE.md en cours de session est possible : Cette modification ne prend pas effet immédiatement, mais seulement au prochain redémarrage. Ainsi, le cache actuellement en cours n'est pas affecté.
Mon tableau de bord gratuit des Tokens
Les captures d'écran que j'ai montrées précédemment proviennent d'un tableau de bord de tokens.
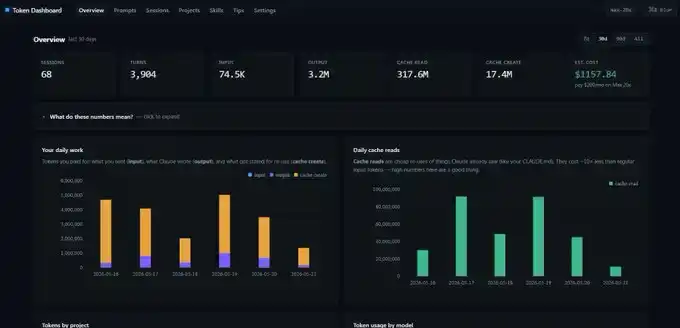
C'est un dépôt GitHub très simple. Vous donnez le lien à Claude Code, vous lui demandez de le déployer en local sur localhost, et il lira l'historique de toutes vos sessions passées au lieu de démarrer les statistiques à zéro. Vous verrez immédiatement les données quotidiennes d'input, output, cache create et cache read.
Une mise en garde cependant : ce tableau de bord comptabilise les données de Token sur votre appareil local. Si vous passez d'un ordinateur de bureau à un ordinateur portable, les chiffres ne seront pas exactement les mêmes. Chaque appareil a sa propre vue statistique.
Conclusion
Le Prompt caching est un sujet qui peut être approfondi. L'article de Thariq est plus complet que celui-ci, si vous voulez une vue d'ensemble, cela vaut la peine de le lire.
Mais vous n'avez pas besoin de comprendre tous les détails pour en bénéficier. Il vous suffit de maîtriser l'essentiel 80/20 : un Token en cache coûte 10 fois moins cher qu'un Token normal ; le TTL de Claude Code est d'1 heure ; changer de modèle détruit le cache ; faire des transitions claires entre les tâches est souvent plus économique que de tenter de réutiliser une ancienne session devenue "obsolète".






