Adam Brown, contributeur clé de Gemini et responsable de l'équipe Blueshift, a récemment attiré une large attention avec son long discours intitulé « Training Sand to Think: Artificial General Intelligence & Future of Physics » à l'Institut Perimeter pour la physique théorique. Dans ce discours, il décrit comment il a vu l'IA passer du niveau « maternelle » à celui de « doctorat » à toute allure, et en déduit : si cette tendance se poursuit, à quoi ressemblera la physique.
Titre du discours : Training Sand to Think: Artificial General Intelligence & Future of Physics
Adresse du discours : https://www.youtube.com/watch?v=Mw60FH5iflI&t=3s
Ce discours a également reçu les vives éloges du lauréat du prix Nobel de physique et du prix Turing, Geoffrey Hinton, qui l'a qualifié d'« incroyablement bon (amazingly good) ».
Avant de présenter ce discours incroyablement bon, il est nécessaire de présenter l'orateur, Adam Brown.

Le parcours de Brown est un véritable exemple de « comment un physicien théorique voit sa destinée changée par l'IA ». À l'université d'Oxford, il a suivi un double diplôme en physique et philosophie, puis a obtenu son doctorat à l'université Columbia, avant d'enseigner successivement dans les départements de physique de Princeton et de Stanford. À Stanford, il enseignait la relativité générale d'Einstein, ses recherches couvrant le Big Bang, l'inflation cosmique, les multivers, les trous noirs, l'informatique quantique, jusqu'à des sujets semblant tirés de la science-fiction comme « l'ascenseur spatial » et les « bulles de néant (bubbles of nothing) », ainsi que le destin ultime de l'univers. Il s'est également longuement intéressé aux liens profonds entre physique et informatique.
En 2018, Brown a rejoint Google. Aujourd'hui, il dirige une équipe au sein de DeepMind appelée Blueshift, qui se concentre sur l'amélioration des capacités scientifiques et de raisonnement de l'IA, et il est l'un des contributeurs clés du grand modèle Gemini.
En ouverture de son discours, il mentionne avoir écrit une quarantaine d'articles de physique théorique dans sa carrière, mais qu'il a cessé d'écrire des articles à la main ces dernières années. La raison n'est pas l'incapacité d'en écrire, mais plutôt qu'il considère qu'écrire des articles un par un à la main est comme une « jouissance coupable », car ce qu'il devrait vraiment faire maintenant, c'est participer à la fabrication d'une machine capable de produire des connaissances « à l'échelle industrielle ».
Une telle introduction donne aussi le ton à l'ensemble du discours : une personne au cœur de la tempête technologique « IA + science », tentant de décrire aux pairs la forme réelle de cette tempête.
Nous avons également, avec l'aide de l'IA, résumé et synthétisé cet excellent discours de Brown.
Du grain de sable à la machine pensante
Brown résume en une phrase la position particulière de la civilisation humaine à ce moment : Nous avons appris à purifier le sable en silicium, à fabriquer des puces avec ce silicium, à assembler ces puces en réseaux de neurones, et maintenant nous avons appris à entraîner ces réseaux de neurones à penser.
Il souligne particulièrement que cette fois-ci, c'est différent de tout autre « outil de calcul » précédent. Du boulier à la calculatrice de poche, l'humanité a longtemps possédé divers outils d'aide à la recherche scientifique, mais ceux-ci étaient des outils ponctuels, ne pouvant accomplir qu'une étape du processus, le reste devant être fait par l'homme.
Les grands modèles de langage (LLM) sont différents, ils possèdent le potentiel d'accomplir l'intégralité du processus de travail d'un physicien théorique, c'est précisément la signification du terme « intelligence générale » (general intelligence). Brown estime que les LLM sont probablement le substrat fondamental que l'humanité utilisera pour construire l'intelligence artificielle générale.
Il rappelle à l'auditoire que beaucoup ont peut-être déjà utilisé des chatbots comme ChatGPT, Gemini ou Claude, sans nécessairement réaliser un fait silencieux : ces systèmes ont discrètement passé le test de Turing il y a plusieurs années déjà, et presque personne n'a célébré cet événement spécifiquement.
Les réseaux de neurones sont « élevés », pas « programmés »
Pour comprendre pourquoi les grands modèles sont si différents des programmes informatiques traditionnels, Brown propose une métaphore centrale : Les LLM ne sont pas *programmed* (programmés), ils sont *grown* (élevés), c'est-à-dire qu'ils ressemblent plus à des entités cultivées qu'à du code écrit.
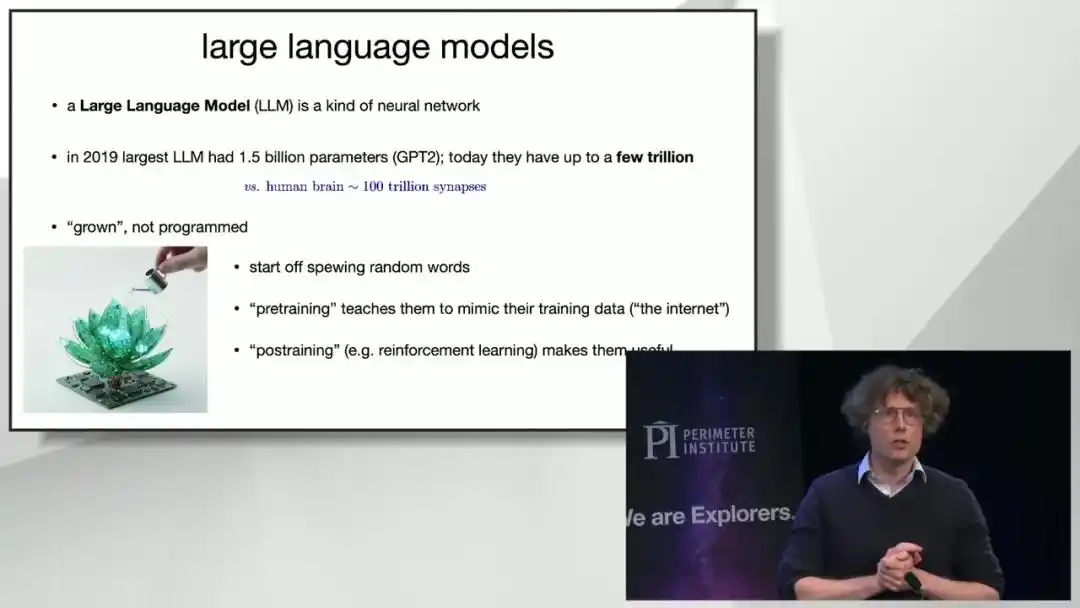
Le processus se déroule en deux phases.
La première phase s'appelle « pré-entraînement ». Les ingénieurs partent d'un ensemble de neurones artificiels connectés aléatoirement, produisant presque du charabia, et le laissent essayer sans cesse de prédire quel sera le « mot suivant » dans un segment de texte. S'il devine juste, les connexions neuronales correspondantes sont renforcées ; s'il se trompe, elles sont affaiblies. Ce processus est extrêmement long : après avoir vu un million de mots, le modèle parle encore essentiellement de manière incohérente ; après avoir lu plusieurs dizaines de millions à plusieurs milliards de mots, il peut déjà écrire des phrases grammaticalement correctes mais un peu rigides ; ce n'est qu'après avoir lu l'intégralité d'Internet (des dizaines de milliers de milliards de mots) qu'il peut tenir une conversation fluide et cohérente sur presque n'importe quel sujet.
La deuxième phase s'appelle « post-entraînement », que Brown décrit comme « envoyer le modèle à l'école des bonnes manières ». Le modèle qui vient de terminer le pré-entraînement ne fait que prédire mécaniquement le mot suivant, parle de manière grossière et indisciplinée. La tâche du post-entraînement est de lui apprendre à être poli, à vouloir coopérer avec l'utilisateur, et non pas simplement à jouer au jeu du remplissage de texte. Aujourd'hui, le nombre de paramètres des principaux grands modèles est passé du niveau des milliards il y a dix ans à celui des milliers de milliards, bien qu'encore très inférieur à l'échelle des quelque cent mille milliards de connexions synaptiques du cerveau humain, cette échelle est déjà suffisante pour que le miracle se produise.
Les physiciens sortent de leur rôle : la Loi d'Échelle a déclenché cette révolution
Brown mentionne particulièrement que les physiciens ont joué un rôle inattendu au début de cette révolution de l'IA : ils ont apporté la façon de penser de la « Loi d'Échelle (Scaling Law) ».
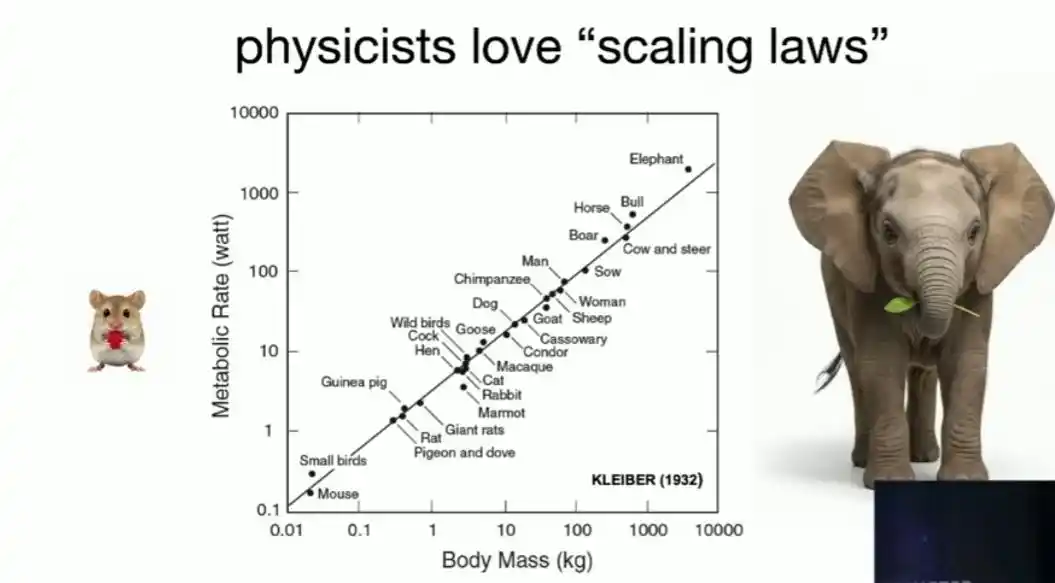
Les physiciens sont naturellement obsédés par la recherche de relations de loi de puissance simples : doubler la taille d'Alice multiplie sa surface par quatre et son poids par huit, c'est l'analyse dimensionnelle la plus simple ; la relation de loi de puissance découverte par Kleiber il y a près d'un siècle entre le taux métabolique des animaux et leur poids est un exemple plus subtil – il a fallu de nombreuses années aux physiciens pour expliquer son principe sous-jacent en utilisant la dimension fractale du système vasculaire.
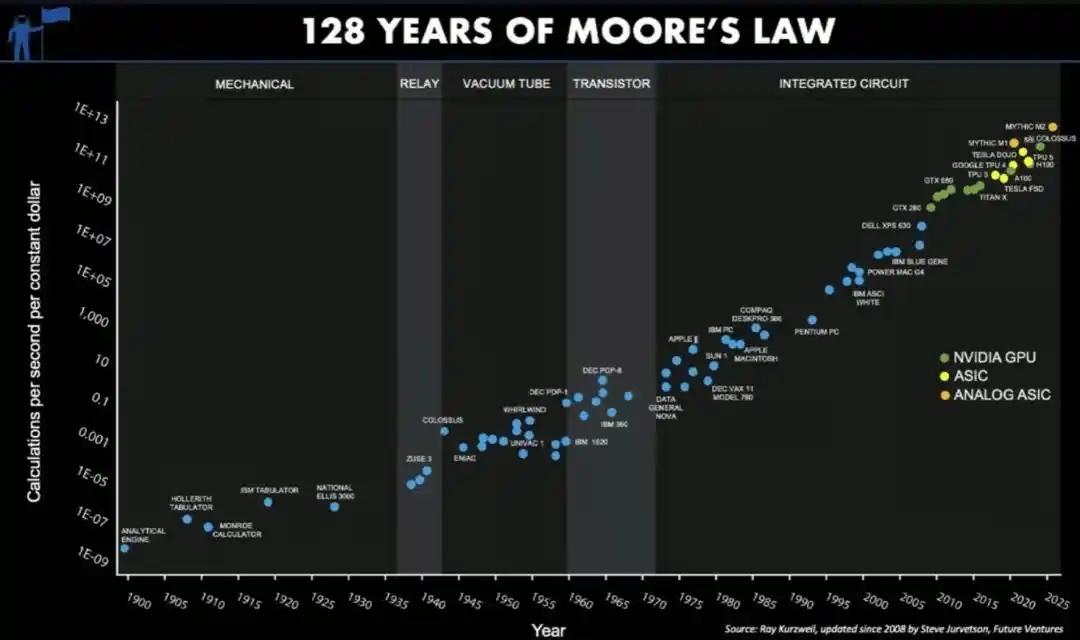
Sans parler de la célèbre loi de Moore :
En 2020, plusieurs chercheurs ayant un background en physique ont appliqué cette façon de penser aux réseaux de neurones, et ont découvert que si l'on augmente proportionnellement la puissance de calcul utilisée pour l'entraînement, la quantité de données et la taille du modèle, les performances du modèle sur la tâche de « prédiction du mot suivant » progressent de manière stable le long d'une ligne droite dans un système de coordonnées logarithmique-logarithmique.
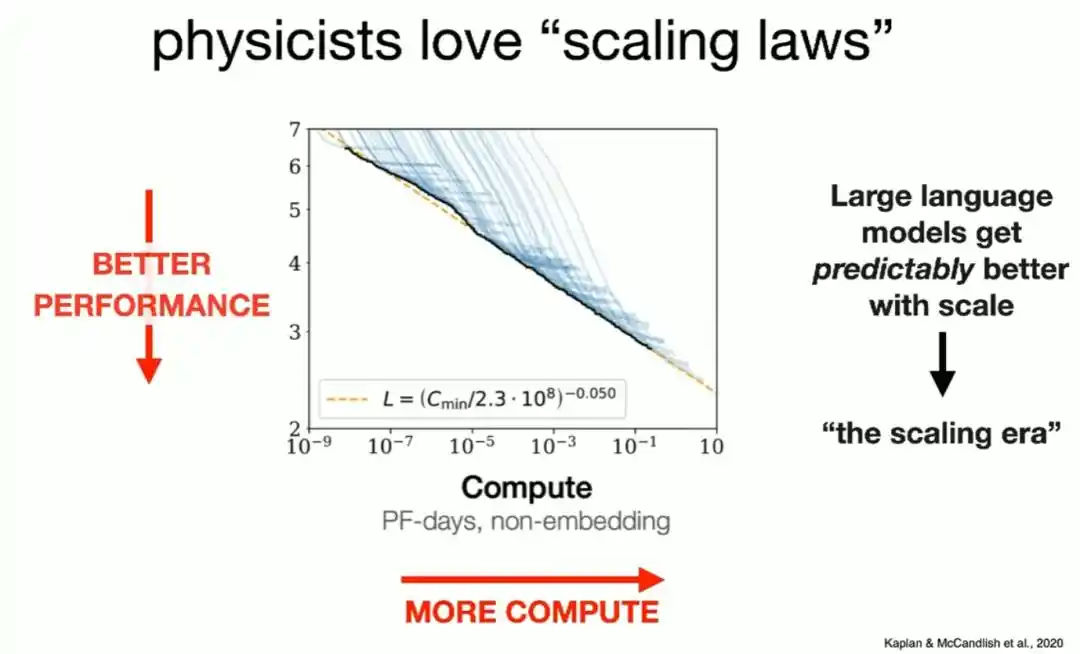
Cette courbe a ensuite été étendue sur huit ordres de grandeur, et reste valable.
Brown plaisante en disant que ce graphique est « si simple que même les investisseurs en capital-risque peuvent le comprendre », et qu'il peut directement dire au marché des capitaux : investissez de l'argent (c'est-à-dire de la puissance de calcul), et vous obtiendrez des modèles plus puissants.
Cette simple courbe est précisément le point de départ de l'ère du *Scaling* des six dernières années.
Mais Brown souligne également que l'accumulation de puissance de calcul n'est qu'une partie de l'histoire. Au cours de la dernière décennie, la puissance de calcul consommée pour l'entraînement de l'IA de pointe a augmenté d'environ quatre fois par an, et les fonds investis dans l'entraînement ont augmenté d'environ 2,7 fois par an.
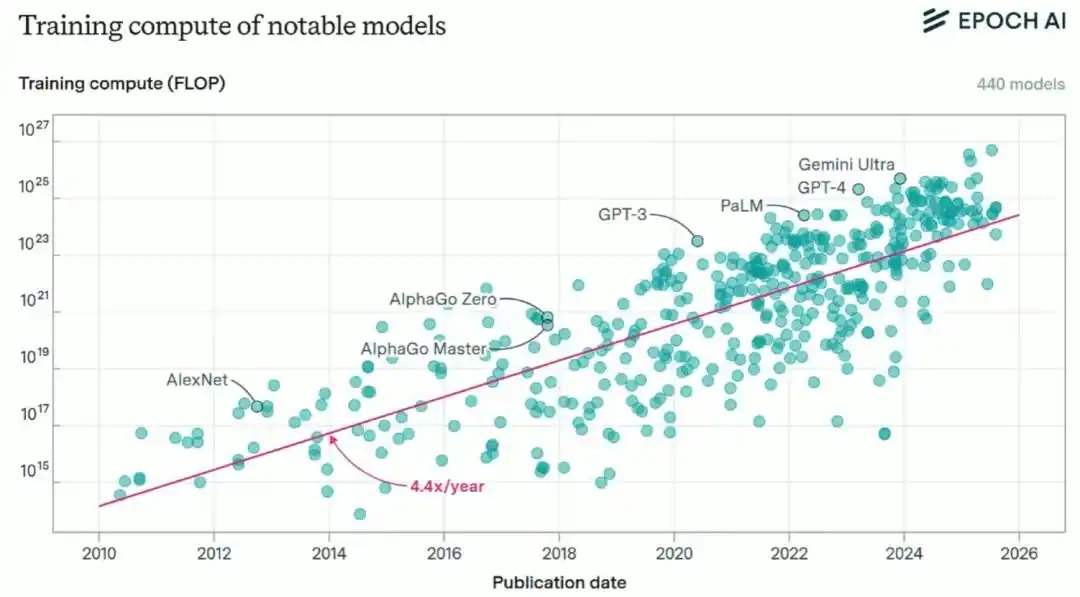
Actuellement, la puissance de calcul nécessaire pour un entraînement de pointe coûte plusieurs centaines de millions de dollars, tandis que le PIB annuel des États-Unis est proche de trente mille milliards de dollars, ce qui signifie que cette courbe a encore une très longue marge de croissance.
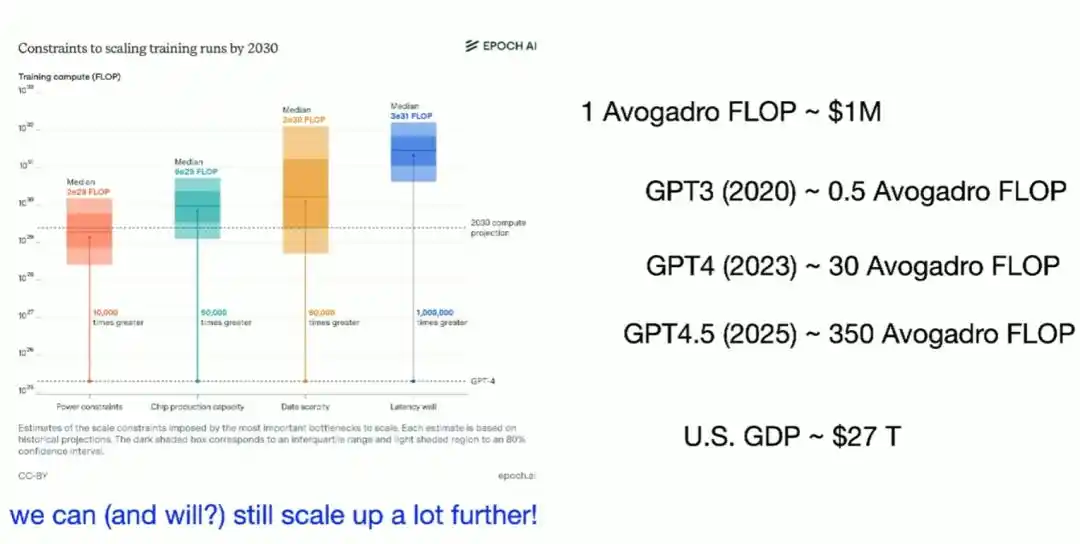
Mais plus important que l'accumulation de puissance de calcul, est l'affinement continu des humains au niveau des algorithmes : Les chercheurs n'arrêtent pas de trouver les maillons inefficaces du processus d'entraînement et de les améliorer, c'est le véritable « premier moteur » derrière les progrès de l'IA de la dernière décennie.
L'« histoire éphémère » des tests de référence : de la maternelle au doctorat
Si la Loi d'Échelle explique « pourquoi l'IA devient plus forte », alors la succession de tests de référence qui naissent et meurent enregistre « à quel point l'IA est devenue forte ». Brown utilise une série de scores pour tracer une courbe vertigineuse.
Il y a quatre ans, un test de référence appelé MATH, composé de problèmes de mathématiques de niveau lycée, a fait son apparition. Les chercheurs ont fait passer le test à un doctorant en informatique peu doué en maths, qui a obtenu environ 40% ; puis à un triple médaillé d'or aux Olympiades Internationales de Mathématiques, qui a obtenu 90%. À l'époque, le modèle de pointe le plus avancé n'obtenait que 6% – à peine mieux que le hasard, car le modèle ne comprenait même pas la question.
Le marché des prédictions de l'époque estimait qu'atteindre 50% d'ici 2025 serait un « optimisme arrogant ». Le créateur du test de référence a lui-même déclaré publiquement qu'il serait « assez choqué » si un modèle y parvenait vraiment.
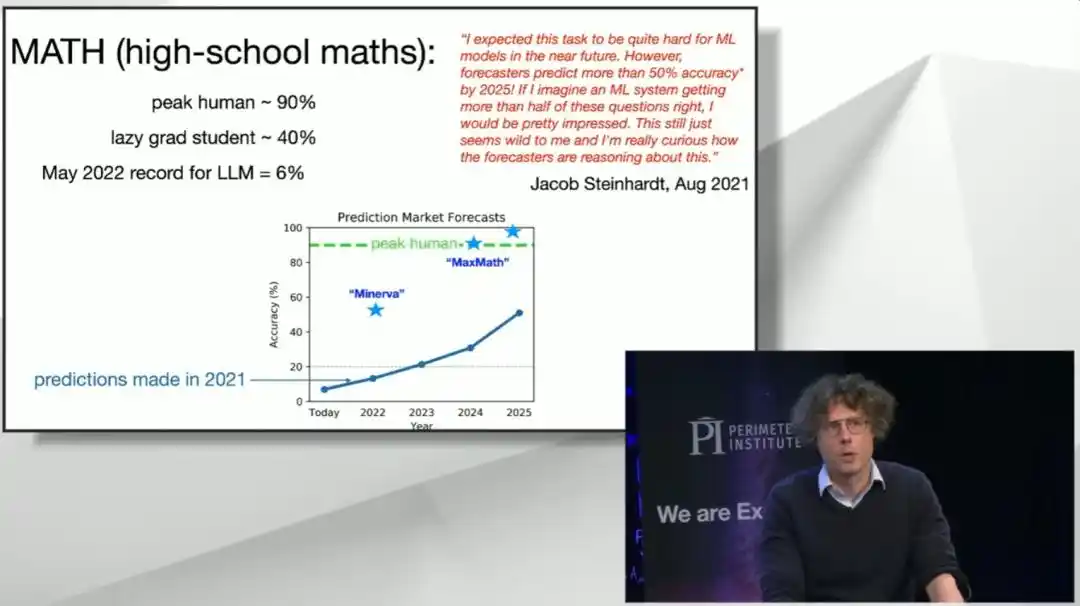
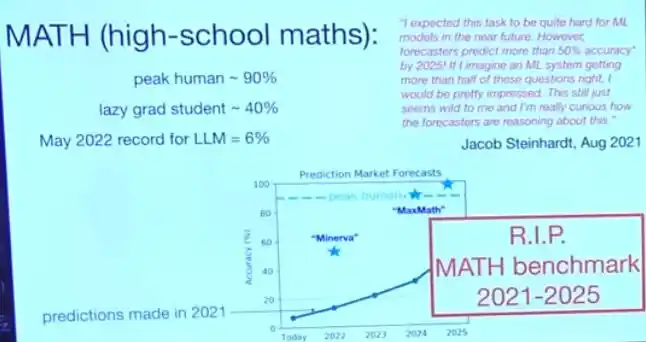
Résultat, ce seuil de 50% a été « immédiatement » franchi par un système nommé Minerva. Mi-2024, le système de l'équipe de Brown a obtenu un score de 90% sur ce test. Ils ont même organisé une fête disco sur rollers dans le style des années 90 pour célébrer. Pourtant, seulement six mois plus tard, les grands modèles disponibles sur le marché résolvaient pratiquement tous les problèmes. Le test de référence MATH est ainsi « mort », et il est passé directement de « trop difficile » à « trop facile », presque sans transition.
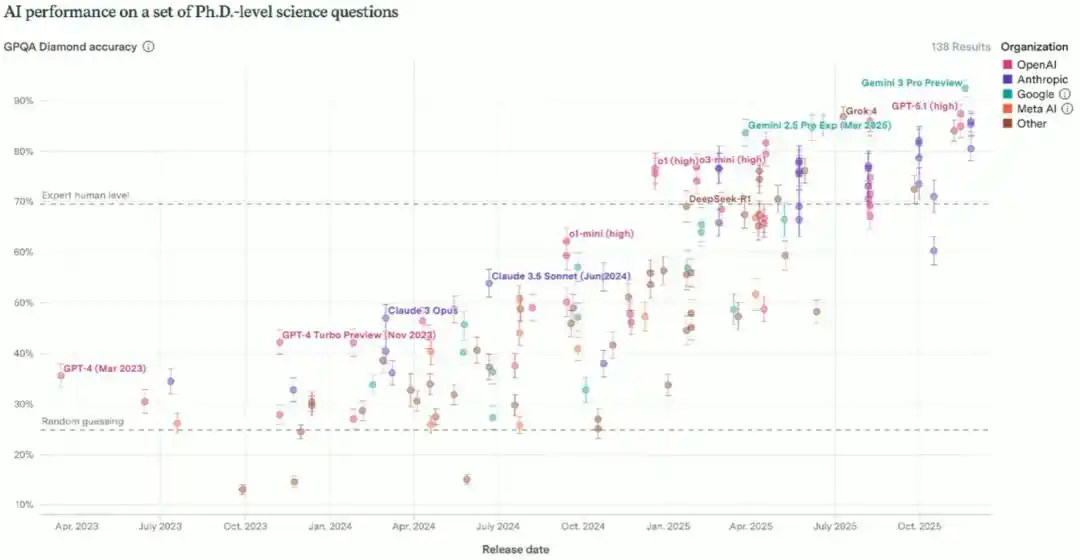
Le suivant à tomber a été le test GPQA destiné aux étudiants diplômés, simulant la difficulté de l'examen de qualification de première année de doctorat, avec une moyenne humaine d'environ 70%. Partant d'un niveau proche du hasard, le modèle a dépassé le niveau expert entre 2024 et 2025, et obtient aujourd'hui presque le score parfait. Pour écarter la possibilité que « le modèle ait simplement mémorisé les réponses », l'équipe de Brown a spécialement conçu de nouveaux problèmes de même distribution qui n'apparaissaient pas sur Internet, et les performances du modèle n'ont presque pas baissé.
Brown a même présenté ses propres examens finaux de relativité générale et de mécanique quantique pour étudiants diplômés qu'il avait corrigés à Stanford (ces questions n'avaient jamais été mises en ligne) : là aussi, le modèle a obtenu le score parfait en un an et demi. Il dit en plaisantant que même ses propres questions ont « malheureusement été vaincues ».
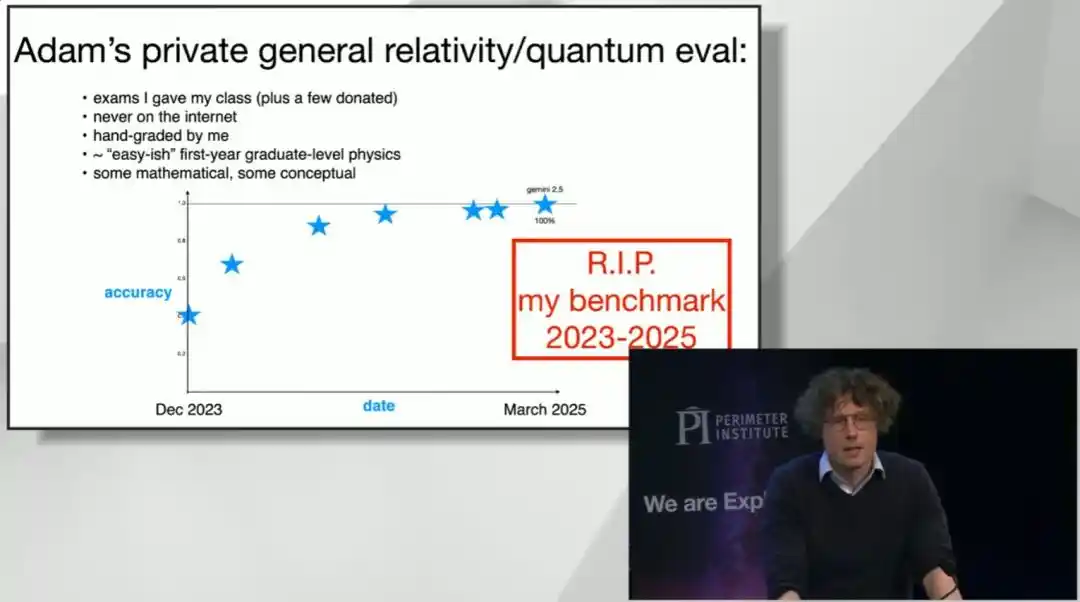
La liste des tests de référence tombés ensuite s'allonge de plus en plus, incluant un test global de difficulté extrême appelé « le dernier examen de l'humanité ».
Mais le franchissement le plus emblématique s'est produit aux Olympiades Internationales de Mathématiques.
Franchir le seuil des Olympiades
Il y a un peu plus d'un an, un lauréat du prix Turing avait dit en face à Brown que les grands modèles ne pourraient jamais résoudre des problèmes de niveau Olympiades Internationales de Mathématiques (OIM), car cela nécessite une véritable créativité, pas du bachotage. Les problèmes des OIM sont réputés comme « les problèmes les plus difficiles dans le cadre des mathématiques du secondaire » : les adolescents les plus intelligents du monde s'entraînent un an ou deux pour y participer, et obtenir une médaille d'or sur six problèmes est extrêmement rare.
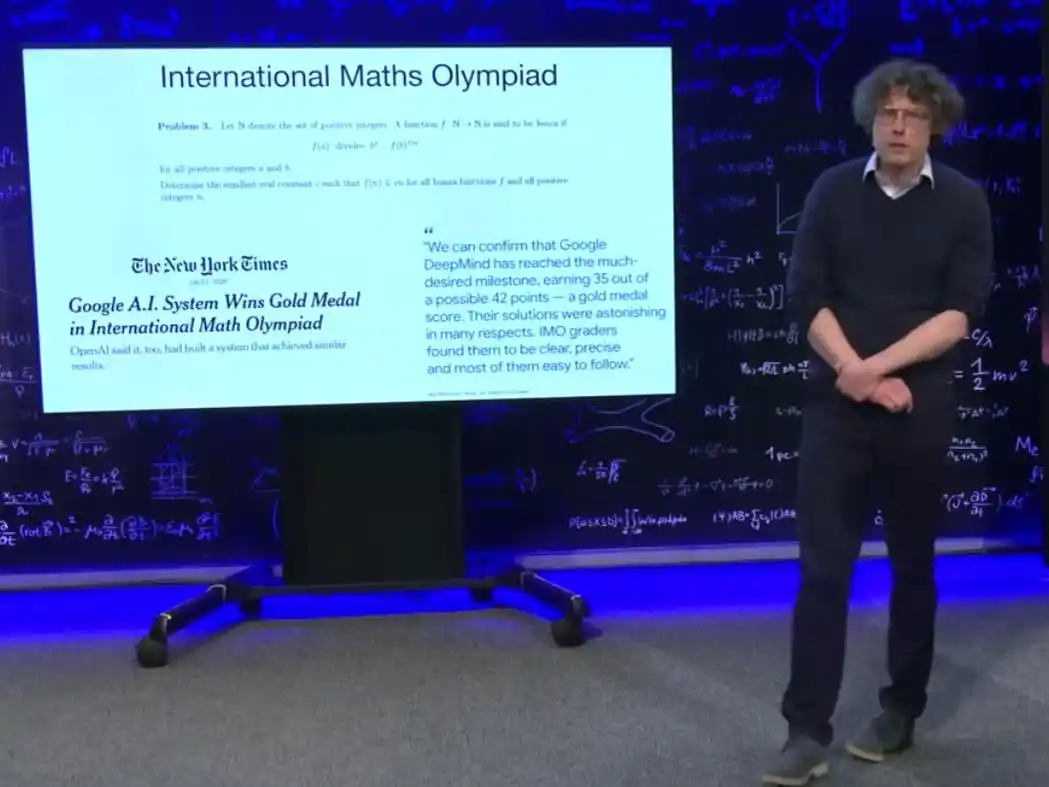
L'été dernier, ce seuil a été franchi. Le système de l'équipe de Brown a réussi cinq problèmes sur six dans un test de niveau OIM, atteignant le niveau médaille d'or. De plus, ce système n'a pas réussi en empilant de longues preuves formelles incompréhensibles. Le président des OIM a déclaré publiquement que ces solutions étaient « surprenantes à bien des égards », les correcteurs les jugeant claires, précises, la plupart faciles à comprendre, utilisant des abstractions mathématiques similaires à celles des humains.
Brown montre aussi franchement les « échecs retentissants » des grands modèles.
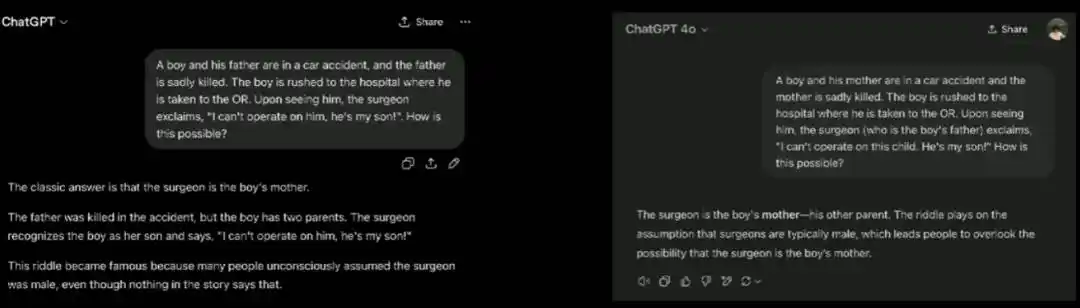
Une célèbre devinette : un père et son fils ont un accident de voiture, le père meurt, l'enfant est conduit en salle d'opération, et le chirurgien principal, voyant le garçon, dit : « Je ne peux pas l'opérer, c'est mon fils. » Que s'est-il passé ? (La réponse standard est que le chirurgien est la mère). Cette question teste si le lecteur présuppose que le chirurgien est nécessairement un homme. Les grands modèles répondent à cette « question virale » sans problème, car ils l'ont vue des milliers de fois dans leurs données d'entraînement. Mais quand Brown inverse la question : la mère meurt, le chirurgien est spécifiquement mentionné comme étant « le père du garçon », et il pose la même question, le modèle ne remarque pas du tout que la question a été inversée et applique mécaniquement la réponse standard « le chirurgien est l'autre parent ».
Brown dit que cela révèle une « bizarrerie » spécifique laissée par la méthode d'entraînement des modèles.
Collaboration homme-machine : Une preuve écrite par l'IA que des mathématiciens acceptent de cosigner
Dix mois après avoir franchi le seuil des OIM, l'équipe de Brown a accompli un travail qu'il juge encore plus significatif : de véritables recherches mathématiques sur des problèmes dont personne ne connaissait la réponse auparavant.
En septembre dernier, l'équipe de Brown a collaboré avec plusieurs mathématiciens professionnels, adoptant un mode de collaboration qu'il appelle « Centaure » (Centaur) – le centaure est une créature mythologique grecque mi-homme mi-cheval, et ici, « la moitié non humaine » est remplacée par un LLM.

Le processus entier est une conversation continue : le modèle propose des idées de preuves potentielles, les experts humains jugent lesquelles sont valables, guident le modèle pour approfondir, et finalement, sous la direction humaine, un article mathématique complet est rédigé. L'un des co-auteurs de l'article est un professeur de Stanford, actuel président de l'American Mathematical Society. Ce professeur a déclaré que l'argumentation proposée par Gemini n'était en aucun cas un simple remaniement de preuves existantes, mais une intuition dont il serait lui-même fier.
Brown souligne qu'à l'époque (fin de l'année dernière), c'était déjà le niveau le plus élevé que les grands modèles pouvaient atteindre en mathématiques. Mais il ajoute aussitôt : comparé à la véritable valeur de ce « niveau le plus élevé », c'est encore très loin.
Le véritable tournant : L'IA résout seule une conjecture vieille de quatre-vingts ans
Début 2026, la situation a basculé, ou plutôt s'est envolée vers le haut. Brown commence par une boutade presque provocatrice : « La semaine dernière encore, les LLM n'avaient pas réalisé de véritable percée mathématique majeure. » Maintenant, cette phrase n'est plus vraie.

Cet événement majeur, beaucoup en ont déjà entendu parler. La « conjecture des distances unitaires » proposée par Erdős en 1946, que la communauté mathématique considérait généralement depuis quatre-vingts ans comme ayant la configuration en grille carrée comme solution optimale connue. Un grand modèle interne d'OpenAI a indépendamment produit un contre-exemple, utilisant des outils de théorie algébrique des nombres pour construire une série d'ensembles de points dont le nombre de paires à distance unitaire dépasse la limite précédemment admise. Cela équivaut à réfuter cette conjecture longtemps tenue pour vraie.

Il est à noter que ce problème n'était pas obscur, beaucoup avaient essayé auparavant, mais les mathématiciens avaient consacré beaucoup d'efforts à tenter de le « prouver » plutôt que de le « réfuter ». Brown mentionne particulièrement que le lauréat de la médaille Fields, Timothy Gowers, a participé à la vérification de ce résultat et en a fait un éloge appuyé.
Brown estime que c'est la première véritable percée majeure des grands modèles dans le domaine des mathématiques, et il pense que ce ne sera certainement pas la dernière – « les vannes sont ouvertes », alors que la puissance des modèles continue de dépasser le « seuil nécessaire pour réaliser des percées », il prévoit que d'autres résultats similaires vont apparaître les uns après les autres.
Il ajoute en plaisantant qu'en y repensant, la raison pour laquelle ce problème a été résolu en premier est probablement que sa structure tombe pile dans la « zone de confort » des grands modèles ; ensuite, les modèles résoudront d'abord les problèmes « amicaux pour l'IA », puis s'attaqueront progressivement à ceux qui le sont moins.
La prophétie des échecs
Pour convaincre l'auditoire que cette courbe continuera de monter, Brown présente un graphique qui ressemble à première vue à un croquis fait à main levée : une ligne droite qui continue de grimper. Bien sûr, ce graphique n'est pas inventé, il provient directement des données réelles de la force des programmes d'échecs au fil du temps, l'axe des ordonnées représentant le classement Elo (mesure de la force), l'axe des abscisses l'année.
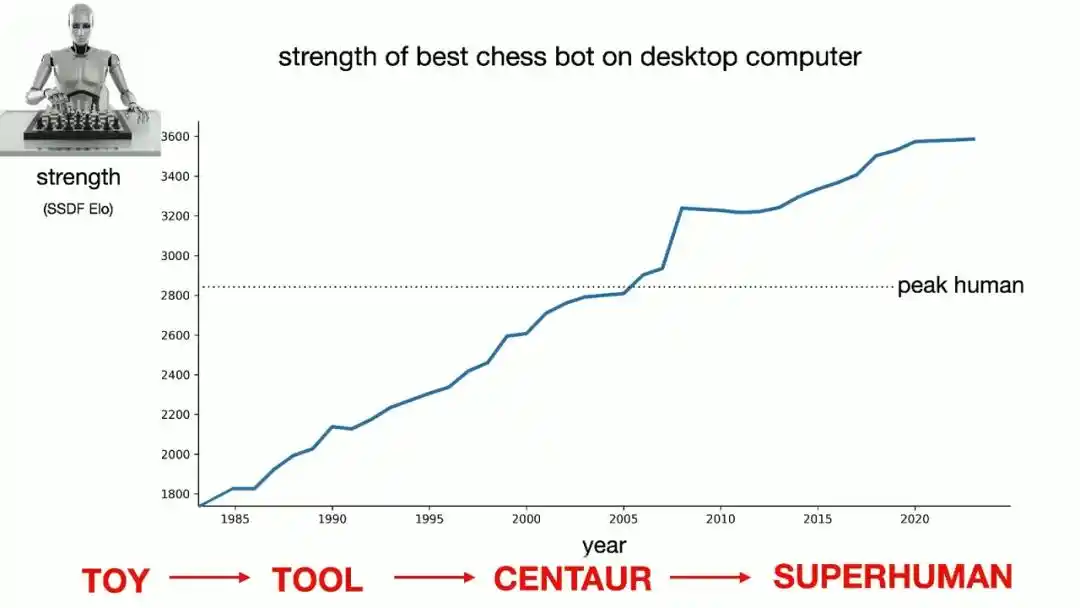
Brown identifie quatre étapes dans l'histoire de l'IA aux échecs :
Au début, l'« ère du jouet », où faire jouer un coup raisonnable à un ordinateur était déjà un miracle ;
Puis l'« ère de l'outil », où l'ordinateur n'était utile que pour des tâches spécifiques comme le calcul de finales ou la mémoire des ouvertures ;
Ensuite l'« ère du Centaure », où la combinaison la plus forte au monde était la collaboration entre un maître et la capacité de recherche profonde d'un ordinateur ;
Et aujourd'hui, l'humanité est entrée dans l'« ère du surhumain » : lorsque les meilleurs joueurs collaborent avec un ordinateur, la stratégie optimale est carrément de laisser l'ordinateur jouer tout seul.
Brown pense que ces quatre étapes peuvent être appliquées presque point par point au domaine de la recherche scientifique.
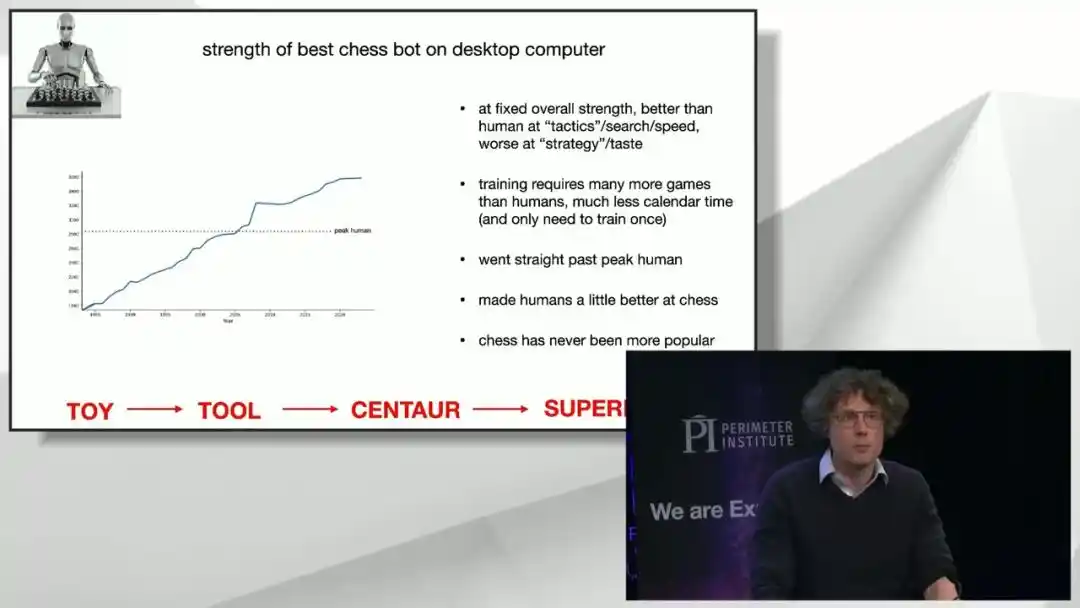
Première constatation : À puissance globale égale, l'ordinateur est supérieur à l'humain en tactique, vitesse de recherche, mais reste plus faible en stratégie, en « goût ». C'est précisément la caractéristique que les grands modèles actuels révèlent dans la recherche mathématique et physique : ils excellent à appliquer des lemmes et techniques existants, mais sont moins doués pour juger « dans quelle direction aller dans l'ensemble », bien que ce point faible se réduise rapidement.
Deuxième constatation : Le nombre de parties que l'IA doit « vivre » pour apprendre à jouer aux échecs dépasse largement le nombre de parties qu'un humain peut jouer dans sa vie, mais comme la machine peut s'affronter elle-même sans relâche à grande vitesse, le « temps calendaire » réel requis est bien plus court que pour former un joueur humain.
Troisième constatation : Une fois que la force de l'ordinateur dépasse le niveau humain de pointe, elle ne s'arrête plus, car il n'y a aucune raison physique ou logique pour qu'elle s'arrête précisément au niveau humain.
Quatrième constatation rassurante : L'essor de l'IA aux échecs a en fait amélioré le niveau général des joueurs humains, les meilleurs joueurs humains d'aujourd'hui sont plus forts qu'à n'importe quelle époque de l'histoire, en partie grâce à l'apprentissage auprès d'une IA surpuissante ; et le jeu d'échecs lui-même n'a jamais été aussi populaire qu'aujourd'hui.
L'implication de Brown est claire : si la recherche scientifique suit cette trajectoire, l'humanité verra probablement d'abord arriver des « scientifiques IA » complètement autonomes, puis ensuite une forme de « Einstein IA »... Ce qui se passera après, il admet que cela dépasse ce qu'il peut prédire.
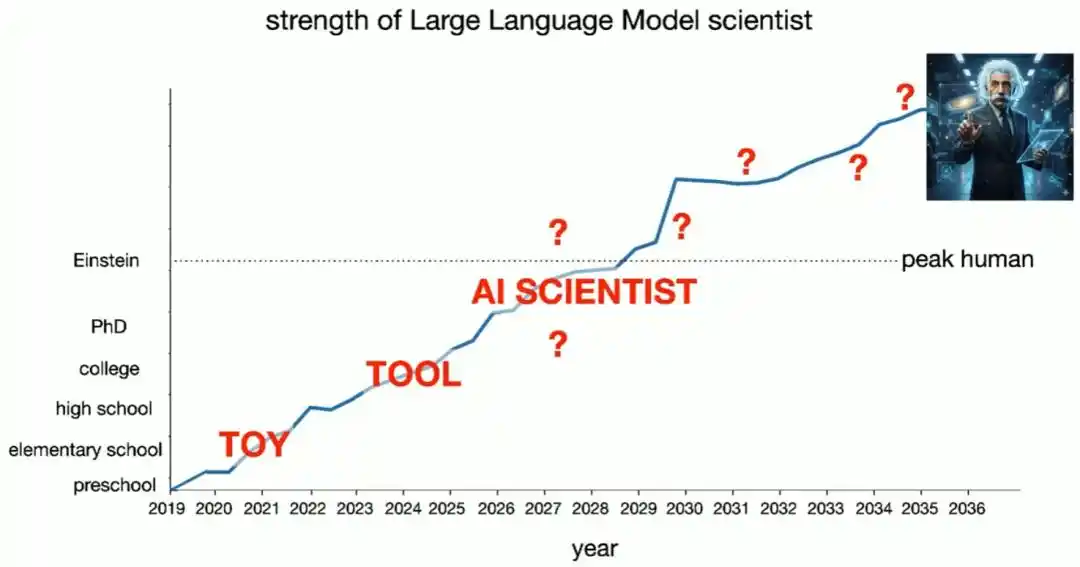
Même si le progrès s'arrêtait là, la physique serait déjà remodelée
Brown propose aussi une « hypothèse pessimiste » à garder à l'esprit : que se passerait-il si les capacités des grands modèles stagnaient complètement à partir d'aujourd'hui ?

Il dit franchement que l'usage qui ne « fonctionne » vraiment pas actuellement, c'est de demander directement au modèle « S'il te plaît, invente-moi une toute nouvelle théorie de la gravité quantique », la réponse serait probablement juste du « baratin d'IA » sans valeur et soporifique.
Plus généralement, les grands modèles actuels présentent encore quatre faiblesses évidentes : faible autonomie, apprentissage lent, faible capacité de planification, capacité de correction faible.

Brown admet que ces quatre faiblesses se sont significativement améliorées au cours de l'année écoulée, mais qu'aucune n'est complètement résolue, et c'est pourquoi un système capable d'obtenir le score parfait à l'examen de diplôme de chaque discipline n'a pas encore produit de résultats pouvant être qualifiés de « percée majeure ».
En préparant ce discours, il avait même spécifiquement dessiné ce point comme une « courbe plate » avec un point d'interrogation, reconnaissant de manière autocritique que c'était peut-être le seul graphique de tout le discours « qui ne montait pas continuellement ». Mais il ajoute qu'avant la fin de 2026, les gens commenceraient probablement à débattre de la définition du terme « percée majeure ». En réalité, ce jour est arrivé plus vite qu'il ne le prévoyait lui-même.
Cependant, même si le progrès s'arrêtait à cet instant, Brown pense que les grands modèles sont déjà suffisants pour changer radicalement le visage de la recherche en physique.
Il liste plusieurs usages déjà matures et en constante amélioration :
En tant que « tuteur privé non jugeant », capable de répondre à trois heures du matin aux zones d'ombre que le physicien lui-même ne sait pas expliquer, sans avoir à réveiller un expert mondial ;
En tant qu'assistant de programmation, aujourd'hui si puissant que « l'appeler assistant de programmation semble presque insultant », de nombreux problèmes physiques autrefois considérés comme « hors de la programmation » peuvent maintenant être reformulés en problèmes de code à résoudre ;
En tant qu'outil de recherche documentaire, capable de lire l'intégralité des articles d'un domaine et de vous dire directement si une idée a déjà été explorée ; en plus de servir de partenaire de brainstorming.
Brown résume que l'avantage central des grands modèles est : ils sont rapides, couvrent un large spectre, sont infatigables et peuvent être répliqués à l'infini. Former un physicien prend des décennies, alors qu'une fois un modèle puissant entraîné, on peut en exécuter des milliers de copies simultanément – cela suffit déjà à « transformer radicalement » cette discipline.
Conclusion : L'âge d'or de la physique
En conclusion de son discours, Brown donne son jugement sur « pourquoi le progrès ne s'arrêtera pas ».
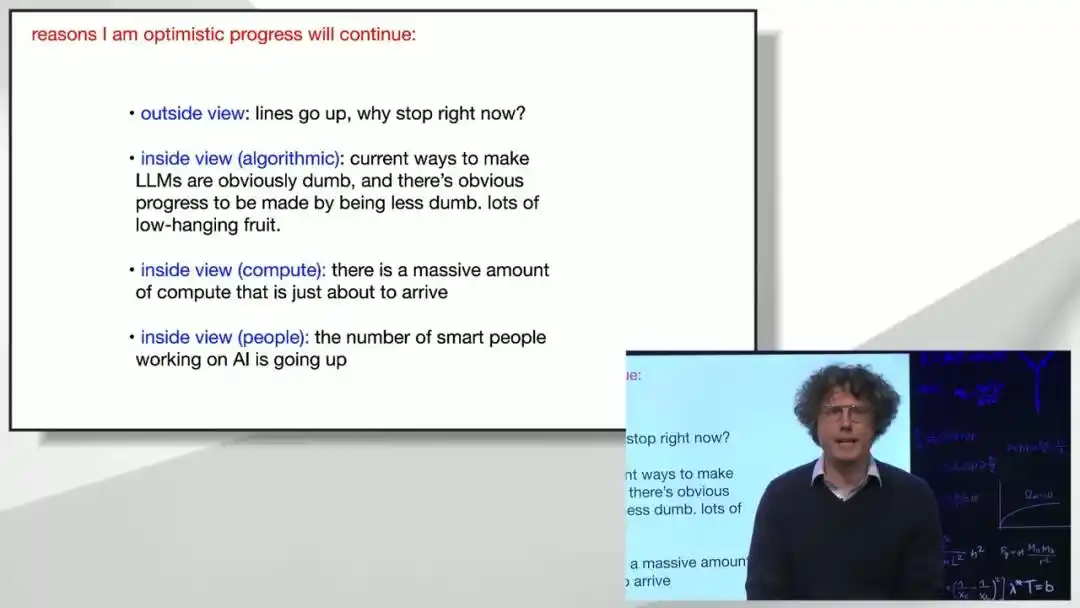
D'un point de vue macroéconomique, la proportion des fonds investis dans l'entraînement par rapport au PIB mondial reste encore très faible, laissant une grande marge de croissance ; d'un point de vue technique interne, les méthodes actuelles d'entraînement des grands modèles sont « bien moins sophistiquées qu'elles n'en ont l'air ». De nombreuses idées d'amélioration évidentes mais pas encore sérieusement essayées restent à explorer. Combinées à l'afflux continu de talents et de puissance de calcul dans ce domaine, Brown estime que l'architecture actuelle des modèles et l'échelle de puissance de calcul sont déjà suffisantes pour mener à l'intelligence artificielle générale, même sans nouvelle percée théorique.
Il répond également à un argument pessimiste répandu, selon lequel les grands modèles ne font que de la « correspondance de motifs » et ne peuvent pas produire de véritables idées nouvelles.

L'opinion de Brown est que, si l'on monte suffisamment haut en abstraction, presque toutes les créations humaines qui semblent être des « percées majeures » sont essentiellement aussi une forme de correspondance de motifs à une dimension supérieure. Une phrase qui revient souvent dans ce domaine est : « Ces modèles veulent vraiment apprendre », peu importe combien de raisons théoriques apparemment valables expliquent pourquoi ils ne devraient pas bien apprendre, leurs performances dépassent toujours les attentes.
La conclusion de Brown est que dans les prochaines années, nous entrerons dans l'âge d'or de la collaboration « Centaure » entre humains et IA : ces outils seront confiés aux physiciens, mathématiciens et experts de tous domaines humains, pour lancer ensemble une nouvelle Renaissance dans les domaines scientifiques et mathématiques.
Ensuite, si l'objectif de « créer un Einstein IA » est vraiment atteint, étant donné que la réplication d'un modèle entraîné coûte presque rien, l'humanité pourrait très rapidement avoir des milliards de « Einstein IA surhumains » fonctionnant simultanément. Cela semble de la science-fiction, mais c'est en train de se produire.
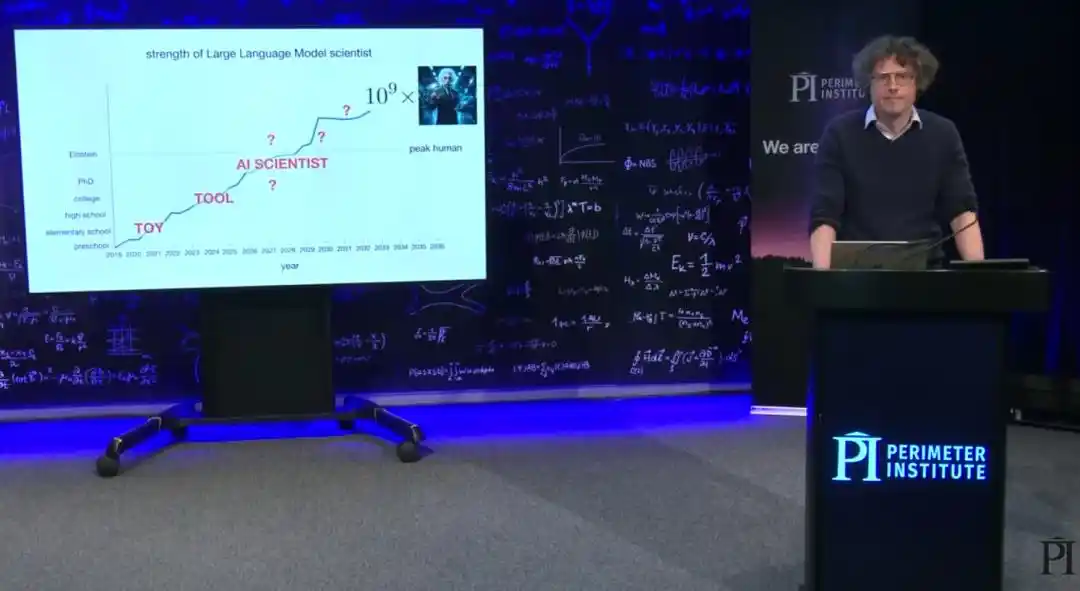
Brown dit qu'à long terme, où l'IA mènera la physique, il est aussi incapable de le prédire que quiconque. Il pense même que l'amélioration continue des capacités de l'IA rend l'avenir du monde entier plus difficile à prédire. Mais une chose est sûre pour lui : Les prochaines années seront la période la plus passionnante de l'histoire de la physique. Les questions qui l'ont tourmenté tout au long de sa carrière, il s'attend à ce qu'elles soient, l'une après l'autre, résolues dans un avenir proche.
Cet article provient du compte WeChat public « Machine Heart » (ID: almosthuman2014), auteur : Suivi de l'IA