Réaliser des capacités de manipulation habile au niveau humain est l'un des défis fondamentaux de longue date en robotique.
Bien que les mains robotiques multi-doigts aient un potentiel similaire aux mains humaines sur le plan matériel, en raison du coût élevé d'acquisition de données d'action robotique de haute qualité, les modèles vision-langage-action (VLA) existants sont largement inférieurs aux grands modèles de langage (LLM) et aux modèles vision-langage (VLM) en termes d'échelle et de diversité des données, et peinent à répondre aux exigences des tâches complexes du monde réel.
Une nouvelle étude du Microsoft Research Asia (MSRA) en collaboration avec l'Université Tsinghua, intitulée "Scalable Vision-Language-Action Model Pretraining for Robotic Manipulation with Real-Life Human Activity Videos", propose un cadre de pré-entraînement innovant, VITRA, pour résoudre ce problème clé.

La contribution principale de cette recherche réside dans la proposition d'une solution entièrement automatisée pour transformer des volumes massifs de vidéos non annotées d'activités humaines réelles en données parfaitement alignées avec le format des données d'entraînement V-L-A robotiques existantes.
En extrayant les trajectoires de mouvement 3D des mains des vidéos, en effectuant une segmentation d'actions atomiques et en générant automatiquement des instructions langagières, l'équipe de recherche a construit un jeu de données V-L-A pour les mains à très grande échelle, contenant 1 million de clips et 26 millions d'images.
Après un pré-entraînement exclusivement sur des données vidéo humaines, le modèle a démontré de puissantes capacités de prédiction d'actions manuelles en zéro-shot (Zero-Shot) dans des environnements réels totalement inédits.
Avec seulement un léger finetuning utilisant peu de données robotiques réelles, le modèle a pu réaliser des manipulations habiles avec un taux de réussite élevé sur un vrai robot, montrant une capacité de généralisation extrêmement forte face à de nouveaux objets et environnements.
Voici plus de détails.
Établir le lien de transformation des vidéos humaines aux données robotiques
Le problème central de l'article est de savoir comment surmonter l'énorme écart entre les vidéos humaines non structurées et les données robotiques structurées, afin d'en extraire des étiquettes d'action et des instructions langagières de haute qualité utilisables pour le pré-entraînement de modèles VLA.
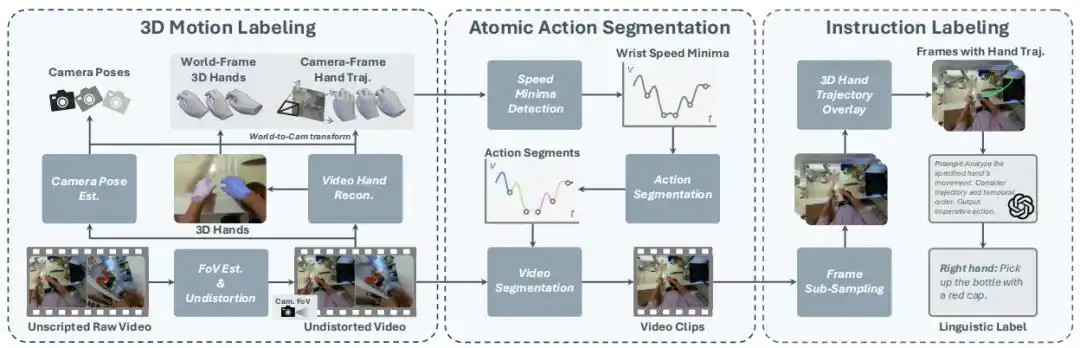
Cette étude a construit un système complet composé de trois technologies clés, réalisant une transformation transparente des vidéos brutes aux données V-L-A.
△
Annotation de mouvement 3D : Restauration précise des trajectoires de la main et de la caméra
Restaurer un mouvement précis de la main en 3D à partir de vidéos monoculaires, non calibrées et potentiellement mobiles est une tâche extrêmement difficile.
L'étude propose une méthode de suivi de pose de la caméra et de la main monoculaire basée sur les dernières technologies de vision 3D :
Tout d'abord, l'état de la caméra est déterminé par le flux optique de fond, et ses paramètres intrinsèques sont estimés.
Ensuite, la pose de la caméra est suivie à l'aide d'un SLAM visuel profond et d'un modèle d'estimation de la profondeur, et un modèle de reconstruction de la main est utilisé pour extraire la pose 3D de la main dans l'espace de la caméra pour chaque image (incluant la pose 6D du poignet et les angles de toutes les articulations).
Enfin, ces informations sont combinées pour obtenir la trajectoire de mouvement 3D de la main dans l'espace mondial.
Cette méthode fournit non seulement des étiquettes d'action de haute précision, mais jette également les bases de la segmentation d'actions et de l'annotation d'instructions ultérieures.
Segmentation d'actions atomiques : Découpage naturel basé sur les minima de vitesse
Les données V-L-A robotiques existantes sont généralement composées de tâches atomiques simples et à courte portée. Comment segmenter précisément ces actions atomiques à partir de longues vidéos est un défi.
L'équipe de recherche s'est inspirée du rythme naturel des actions humaines, proposant un algorithme de segmentation simple et efficace : découpage basé sur les minima de vitesse de déplacement de la main dans l'espace 3D.
Lors des transitions d'action, la main humaine présente généralement des changements de vitesse, les minima de vitesse marquant souvent le changement d'action.
En détectant les minima de vitesse de la trajectoire 3D du poignet dans l'espace mondial, cette méthode peut découper efficacement de longues vidéos en courts clips contenant une seule action atomique, sans nécessiter aucune annotation manuelle ou inférence de modèle supplémentaire.


Annotation d'instructions : Description d'action précise combinant la trajectoire 3D
Pour générer des instructions langagières précises pour les clips vidéo segmentés, l'équipe de recherche a habilement combiné un modèle vision-langage (VLM) et la trajectoire 3D de la main.
Pour chaque clip vidéo, le système échantillonne uniformément 8 images et projette/superpose la trajectoire 3D de la paume sur ces images.
Ensuite, ces images avec la trajectoire mise en évidence sont fournies à GPT-4, avec l'invite de décrire l'action de la main spécifiée sous forme de phrase impérative, en combinant le contenu de l'image et les informations de trajectoire.
L'expérience prouve que fournir des clips vidéo atomiques avec la trajectoire 3D de la main superposée améliore significativement la précision des descriptions d'action générées par GPT.
Réaliser une puissante prédiction en zéro-shot et une généralisation au monde réel
Basé sur l'ensemble de données V-L-A pour les mains humaines à très grande échelle construit automatiquement ci-dessus, l'équipe de recherche a conçu et entraîné un modèle VLA spécialement conçu pour la manipulation habile.
△
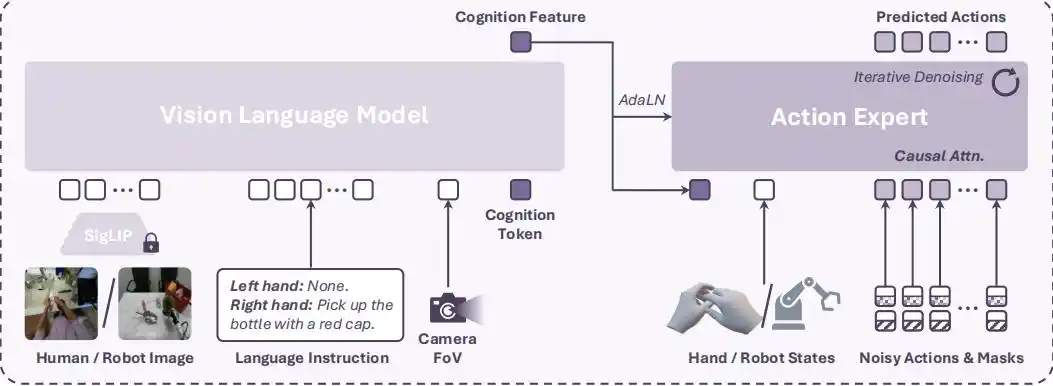
1. Architecture du modèle combinant VLM et expert en actions par diffusion
Ce modèle VLA est composé d'un réseau de base VLM (PaliGemma-2) et d'un expert en actions par diffusion (Diffusion Transformer, DiT).
Le VLM reçoit l'observation visuelle, l'instruction langagière et l'information sur l'angle de champ de vision (FoV) de la caméra, et émet une "fonction cognitive" (Cognition Feature).
L'expert en actions par diffusion reçoit cette fonction cognitive, l'état actuel de la main et un bloc de bruit d'actions avec masque, et prédit la séquence future d'actions de la main via un débruitage itératif.
Pour traiter les actions rapides de la main humaine et s'adapter aux données de clips courts, le modèle utilise un mécanisme d'attention causale (Causal Attention) pour le débruitage des actions, garantissant que la prédiction de chaque étape d'action ne dépend que des actions précédentes, évitant ainsi efficacement l'impact négatif du remplissage par des zéros.
2. Prédiction d'actions manuelles en zéro-shot : Capacités impressionnantes dans des environnements inédits
Dans des environnements de vie réelle totalement inédits, le modèle pré-entraîné a démontré une puissante capacité de prédiction d'actions manuelles en zéro-shot.
△
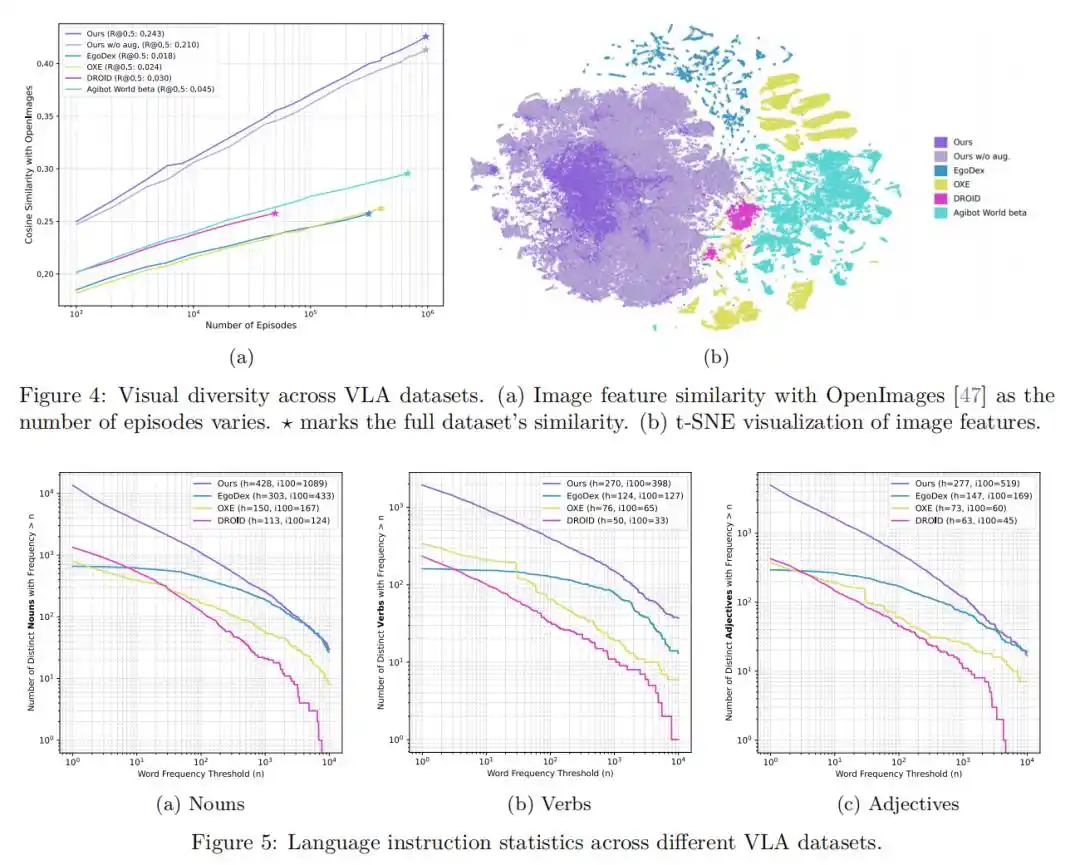
Dans les évaluations des tâches de préhension et des tâches générales de prédiction d'actions, ce modèle surpasse significativement les modèles entraînés sur des données collectées en environnement de laboratoire (comme EgoDex), ainsi que les modèles entraînés avec des données humaines annotées brutes.
Cela prouve amplement que le pré-entraînement sur des vidéos de vie réelle massives et diversifiées peut considérablement améliorer la capacité de généralisation du modèle face à des environnements complexes et des objets inconnus.
3. Manipulation habile sur robot réel : Déploiement efficace avec peu de données de finetuning
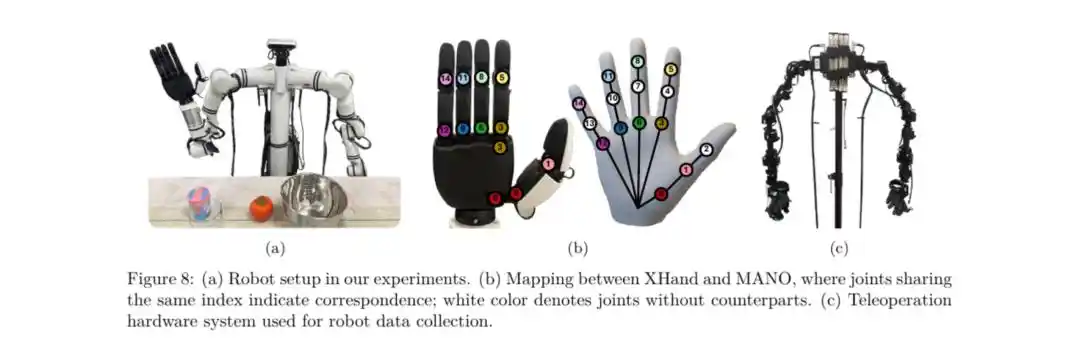
Pour le déploiement sur un robot réel, l'équipe de recherche a aligné l'espace d'actions de la main humaine avec celui de la main robotique habile (comme le Realman équipé de la XHAND1 de XingDong).
△
Seul un léger finetuning du modèle pré-entraîné avec peu de données de téléopération robotique réelle (environ 1,2K échantillons) est nécessaire pour exécuter dans le monde réel diverses tâches de manipulation habile, incluant la saisie, le placement, le versement et le balayage.
Les résultats expérimentaux montrent que, comparée aux modèles non pré-entraînés sur des données VLA humaines ou pré-entraînés sur d'autres jeux de données (comme OXE, EgoDex), cette méthode obtient une amélioration significative du taux de réussite des tâches, démontrant notamment une robustesse exceptionnelle face à des objets et arrière-plans jamais vus.
Le support matériel clé du déploiement de VITRA dans le monde réel
Si le cadre VITRA peut réaliser une capacité de généralisation impressionnante sur un robot réel, cela est dû non seulement à l'innovation algorithmique, mais aussi au soutien puissant du matériel sous-jacent —
La XHAND1 de XingDong, première main habile à cinq doigts à entraînement direct (full direct-drive) développée en interne en Chine.
Ce cadre et les caractéristiques matérielles de la XHAND1 de XingDong forment une parfaite "synergie logiciel-matériel", présentant des avantages de déploiement irremplaçables dans les scénarios d'application réels.
△
URDF haute précision et connexion transparente avec l'espace d'actions de la main humaine
La percée principale du cadre VITRA réside dans l'alignement de l'espace d'actions de la main humaine avec celui de la main robotique habile.

La XHAND1 de XingDong fournit officiellement un modèle URDF de très haute précision, décrivant non seulement avec précision les paramètres de mouvement et de dynamique, mais mappant également parfaitement la distribution spatiale des articulations de la main humaine.
Ce support de modèle de niveau "jumeau numérique" permet à VITRA, lors de la phase de finetuning, de mapper avec précision les angles des articulations humaines vers les articulations correspondantes de la XHAND1, réduisant ainsi considérablement le fossé entre la vidéo humaine et le matériel réel, et garantissant un déploiement efficace de la stratégie pré-entraînée sur le matériel réel.
Architecture à entraînement direct et réponse haute fréquence : Exécution parfaite d'opérations habiles complexes
Pour exécuter des tâches de manipulation habile complexes comme le versement ou le balayage, le robot doit posséder une capacité de réponse dynamique extrêmement élevée.
L'architecture à moteurs à entraînement direct (Direct-Drive) adoptée par la XHAND1 de XingDong fournit la base matérielle idéale pour cet algorithme.
La conception à entraînement direct élimine fondamentalement les frottements importants, la latence et les interférences non linéaires induits par les réducteurs traditionnels, conférant à la main habile une capacité de réponse dynamique ultra-sensible. Cela permet à la XHAND1 d'exécuter instantanément et avec précision les instructions d'action émises par le modèle VITRA, et de manipuler en toute sécurité divers objets inconnus.
Réseau de capteurs riche : Réserver de l'espace pour la perception multimodale future
Bien que le modèle VITRA actuel s'appuie principalement sur l'entrée visuelle, le riche réseau de capteurs de la XHAND1 de XingDong (comme les réseaux tactiles haute résolution) réserve un espace important pour la perception multimodale future.
Combinée aux puissantes capacités de perception matérielle de la XHAND1, les futurs modèles VLA pourront potentiellement intégrer davantage de retours tactiles pour traiter des tâches plus fines et complexes de "déplacement des doigts (Finger Gaits)".
La loi d'échelle de la taille des données
Cette étude explore également en profondeur l'impact de l'échelle des données de pré-entraînement sur les performances du modèle.
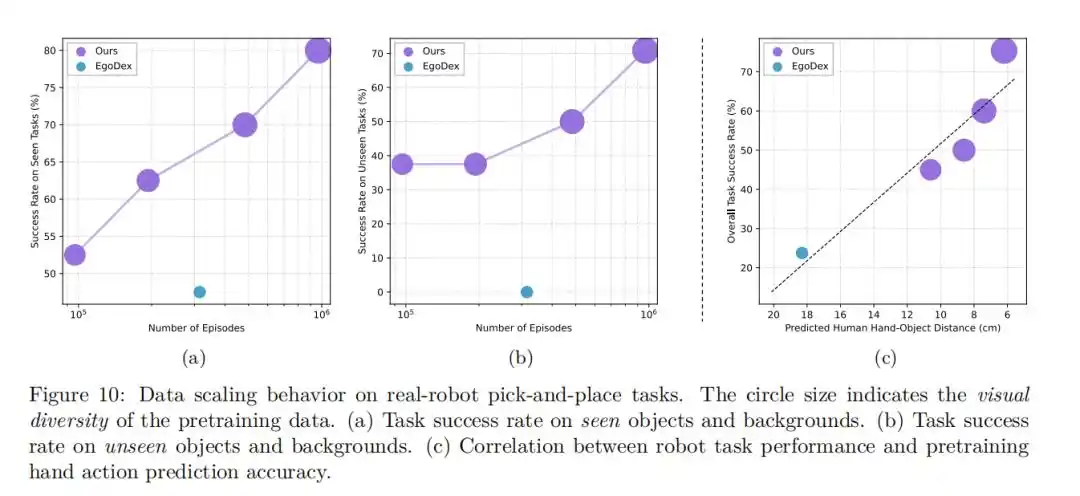
△
L'expérience a révélé qu'avec l'augmentation du volume de données de pré-entraînement, l'erreur du modèle dans les tâches de prédiction d'actions manuelles en zéro-shot diminue régulièrement, et son taux de réussite dans les tâches de manipulation robotique réelle augmente continuellement.
Ce comportement d'échelle évident (Scaling Behavior) indique qu'en augmentant davantage l'échelle des données vidéo humaines, il est possible d'améliorer continuellement les performances des modèles VLA.
Ce résultat marque une percée clé dans l'utilisation de vidéos humaines non structurées pour le pré-entraînement de modèles VLA robotiques.
En fournissant une solution de transformation de données entièrement automatisée, cette étude réduit considérablement le seuil d'obtention de données d'entraînement robotique de haute qualité, ouvrant la voie à l'application des mains habiles multi-doigts dans un éventail plus large de scénarios complexes réels, et établissant une base solide pour progresser vers une intelligence incarnée véritablement généralisée.
Lien vers l'article : https://arxiv.org/abs/2510.21571
Cet article provient du compte WeChat "量子位" (Quantum Bit), auteur : L'équipe VITRA






