Keleixi depuis QFeiSI | Compte public QbitAI
Une semaine seulement après son ouverture, DSpark a été adapté aux ordinateurs Apple.
La version adaptée s'appelle mlx-dspark et exécute les modèles Gemma-4 12B et Qwen3-4B.
Après installation, la vitesse de génération de ces deux modèles sur Mac a été augmentée respectivement de 1,6 fois et de 1,4 fois.
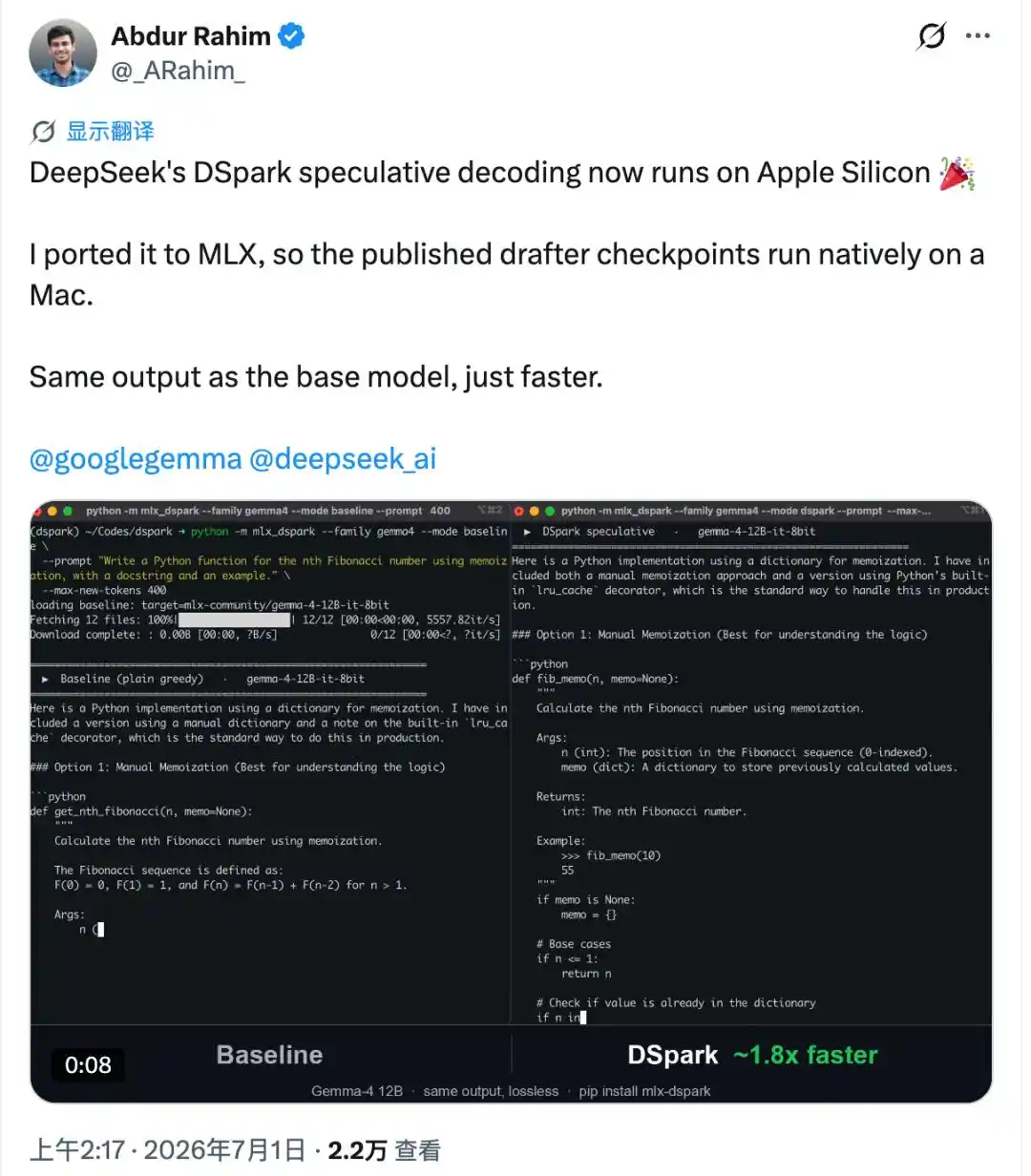
Le plus difficile est qu'il a réussi une chose que la plupart des versions adaptées ne parviennent pas à faire – la sortie est identique octet par octet au modèle original, sans la moindre différence.
En d'autres termes, la vitesse est gagnée sans aucune perte de qualité.
La personne qui s'est attelée à cette tâche est Abdur Rahim, un ingénieur qui bricole des projets open source sur son temps libre. La première version native pour Mac de DSpark depuis son ouverture a été entièrement réalisée par lui seul.
Exécution de grands modèles sur Mac, accélération de 60%
Concernant DSpark, open source de DeepSeek le 27 juin, les chiffres officiels indiquent une accélération de 60% à 85% dans les scénarios côté serveur.
Cependant, cette technologie n'était alors disponible que pour les GPU des centres de données, sans version adaptée aux puces Apple.
mlx-dspark est la première version native pour puces Apple de cette technologie.

L'idée de DSpark est de fournir un modèle plus petit pour assister le modèle cible. Le petit modèle génère d'abord plusieurs candidats d'un coup, puis le modèle cible les vérifie en une seule fois, gardant les bons et renvoyant les mauvais pour une nouvelle tentative.
Le coût de cette étape diffère entre les centres de données et les ordinateurs Apple.
Sur les GPU des centres de données, vérifier un lot de candidats ressemble plus à un forfait, un prix fixe quel que soit le nombre de personnes, le décodage étant déjà un goulot d'étranglement mémoire, vérifier quelques candidats supplémentaires ne prend presque pas plus de temps.
Les puces Apple ressemblent plus à un taxi avec compteur, plus on vérifie de candidats, plus le coût augmente.
Rahim a mesuré que pour Gemma-4 12B, chaque token vérifié en plus coûte environ 14 millisecondes. Il a modélisé ce coût et a conclu que le plafond de vitesse sur puce Apple se situe autour de 2,2 fois.
En bref, Rahim a adapté ce petit modèle assistant à partir du checkpoint HuggingFace et l'a associé aux modèles cibles Gemma-4 12B et Qwen3-4B.
Il a également reconstruit le processus de vérification dans le framework MLX et quantifié les poids en 4-bit.

Résultat, sur M4 Pro, comparé aux outils officiels MLX d'Apple, la vitesse de génération de Gemma-4 12B est passée de 18,4 tok/s à environ 30 tok/s, soit environ 1,6 fois plus rapide ; celle de Qwen3-4B est passée de 52,9 tok/s à environ 73 tok/s, soit environ 1,4 fois plus rapide.
De plus, dans mlx-dspark, Rahim a également accompli quelque chose que la plupart des travaux d'adaptation ne font pas.
Version adaptée, également capable d'une restitution haute précision
La plupart des versions adaptées de grands modèles pour exécution locale ne prennent en charge que le décodage glouton, c'est-à-dire choisir le mot le plus probable à chaque étape.
Dans mlx-dspark, Rahim a également implémenté la méthode d'échantillonnage avec température décrite à l'origine dans le papier DSpark. Le modèle brouillon propose des candidats, la probabilité d'acceptation est min(1, p/q), et les parties non acceptées sont rééchantillonnées à partir du résidu.
Il a vérifié lui-même que la distribution de sortie produite par ce processus est strictement égale à la distribution exacte que le modèle cible donnerait à la même température, ce n'est pas une version approximative dégradée.
La plupart des décodages spéculatifs ne font qu'une version gloutonne car la validation de la version gloutonne est simple, il suffit de comparer mot par mot.
L'étape supplémentaire de Rahim a consisté à vérifier lui-même la distribution de sortie en mode échantillonnage, confirmant qu'elle n'était pas déformée.
La précision à attribuer au modèle cible responsable de la vérification a été un piège qu'il a découvert par essais.
Si le petit modèle est associé à une version de base du modèle cible non affinée par instructions, seulement 47% des candidats proposés passent la vérification ; avec la version affinée par instructions correspondante, ce taux monte à 82%.
Il a également testé de passer le modèle cible en précision bf16, le coût de vérification augmentant plus que le taux d'acceptation, ralentissant même le processus, donc garder le modèle cible par défaut en 8-bit est le plus optimal.
Le petit modèle responsable de proposer les candidats utilise une autre précision.
Le modèle brouillon lui-même a été compressé, après quantification 4-bit il ne fait que 1,8 Go, il rentre sans problème en mémoire et fonctionne toujours de manière non destructive.
Le résultat est que DSpark a non seulement réalisé l'accélération, mais a également bien répliqué sur l'appareil l'augmentation du taux d'acceptation de 16% à 18% mentionnée dans l'article.
DFlash également intégré, les tâches de code plus rapides
Après la publication du tweet, un commentaire est apparu. Jian Chen, l'un des auteurs de l'article DFlash, a demandé s'ils pouvaient essayer le modèle de leur équipe.
DFlash est un autre schéma de décodage spéculatif proposé dans un article publié par z-lab en mai de cette année. Le chef d'équipe des auteurs, Zhijian Liu, est professeur assistant à l'UCSD et également chercheur scientifique chez NVIDIA.
L'approche de DFlash est différente de celle de DSpark. Il utilise une « diffusion de bloc » parallèle pour débruiter un bloc entier de 16 tokens en une fois, au lieu de deviner pas à pas avec des dépendances comme DSpark.
Rahim s'est rapidement mis au travail.
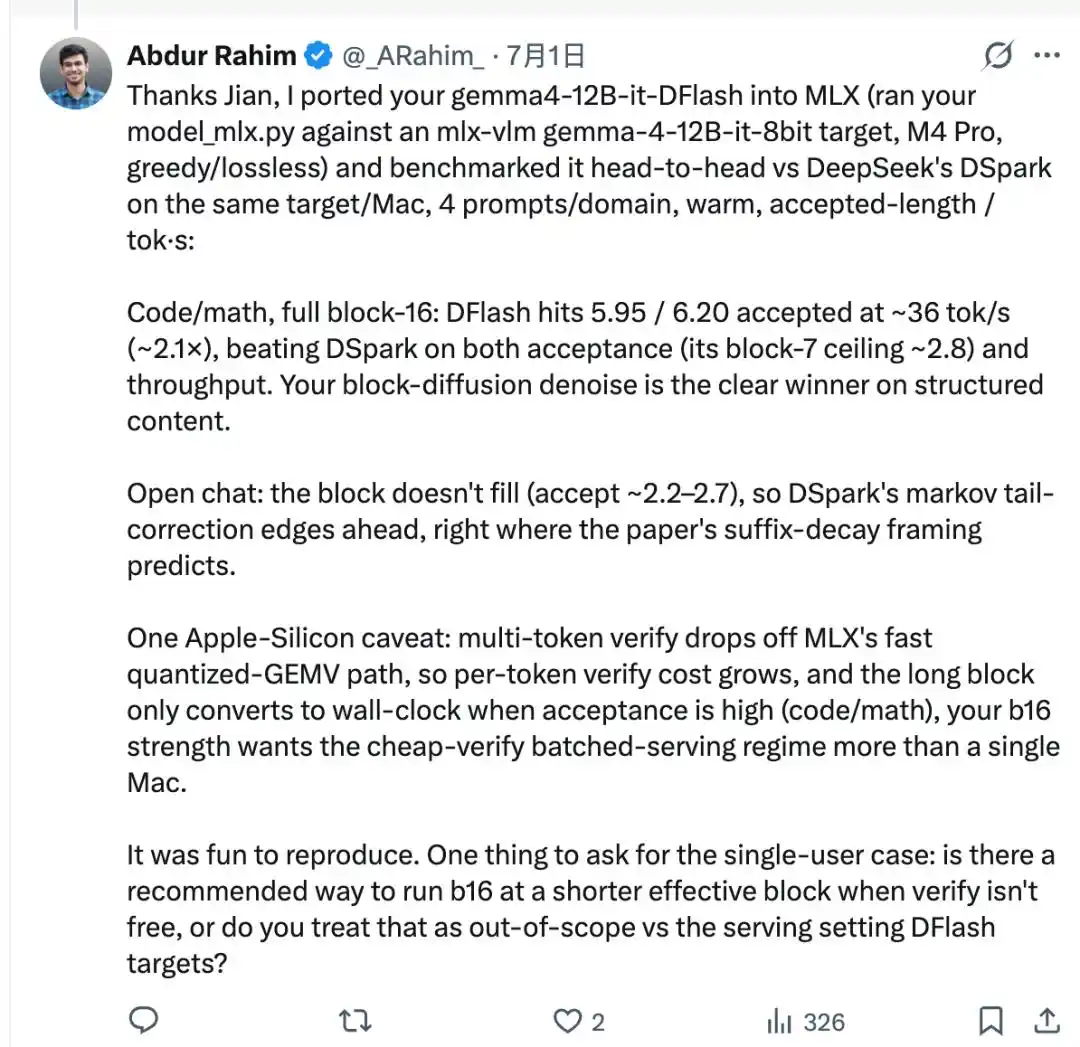
Utilisant le script d'adaptation écrit par Jian lui-même, il a connecté gemma4-12B-it-DFlash publié par z-lab au modèle cible Gemma-4 de mlx-vlm. Sur le même Mac, il a effectué une nouvelle comparaison directe avec DSpark qu'il venait de tester.
Sur les tâches de code et de mathématiques, la longueur d'acceptation du décodage par bloc de DFlash pouvait atteindre 5,95 à 6,20, à une vitesse d'environ 36 tok/s, atteignant environ 2,1 fois, battant ainsi DSpark.
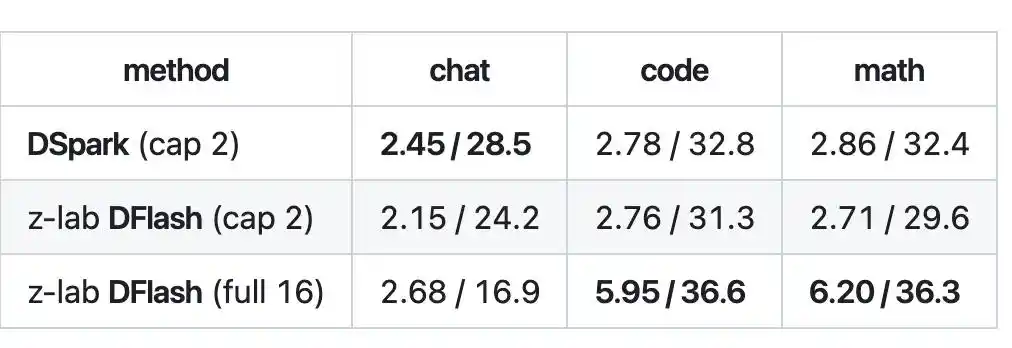
Cependant, DFlash doit générer un bloc entier de 16 tokens en une fois, mais le modèle cible ne les approuve pas nécessairement tous. En réalité, seule une partie passe la vérification. Le secteur appelle cela la « longueur d'acceptation », et il n'est pas toujours possible de remplir les 16 à chaque fois.
Donc, dans des scénarios de conversation ouverte où le contenu est difficile à prédire, la longueur d'acceptation ne monte pas, le bloc n'est pas rempli, et l'avantage de DFlash ne se manifeste pas.
La tête Markov de DSpark existe précisément pour résoudre ce même problème. Générer un bloc entier de mots en parallèle, les positions plus éloignées étant calculées indépendamment, peuvent facilement ne pas s'emboîter. La tête Markov ajoute une couche de dépendance entre ces positions pour corriger ce problème.
Le résultat est que, dans les scénarios de discussion, DSpark est même plus rapide que DFlash.
La version mise à jour ensuite, mlx-dspark v0.0.3, a officiellement intégré la version originale DFlash de z-lab dans le package. Elle a également ajouté un paramètre permettant de raccourcir manuellement la longueur effective du bloc pour DFlash, utilisant des blocs courts pour les scénarios de discussion, et conservant les blocs entiers de 16 pour les scénarios de code et de mathématiques.
Après cela, le même Mac, avec le même package, peut accomplir simultanément les tâches de discussion et celles de code/mathématiques, sans avoir à faire des allers-retours entre les projets DSpark et DFlash.
Rahim a déclaré dans son tweet que la même méthode devrait également fonctionner sur des modèles brouillons plus grands comme Qwen3-8B et 14B.
Liens de référence : [1]https://x.com/_ARahim_/status/2072021710602432577[2]https://github.com/ARahim3/mlx-dspark
Cet article provient du compte public WeChat "Quantum Bit", auteur : Suivi des technologies de pointe.






