Note de la rédaction : En janvier 2026, les critiques d'Andrej Karpathy sur la programmation par Claude ont mis en lumière un fichier apparemment insignifiant mais crucial dans le flux de travail de programmation IA : CLAUDE.md. Forrest Chang a ensuite synthétisé ces problèmes en 4 règles de comportement, cherchant à corriger les erreurs courantes de Claude lors de l'écriture de code : hypothèses implicites, sur-ingénierie, modifications involontaires de code non concerné et manque de critères de réussite clairs.
Mais quelques mois plus tard, le champ d'application de Claude Code n'était plus limité à « faire écrire un bout de code par le modèle ». Avec l'avènement des Agents multi-étapes, des chaînes de déclenchement de hooks, des conflits de chargement de skills et des collaborations multi-dépôts devenant la norme, de nouveaux modes d'échec sont apparus : perte de contrôle du modèle dans les tâches longues, tests réussis mais sans validation de la logique réelle, migrations terminées mais échouant silencieusement, mélanges erronés de styles de code différents.
En 6 semaines, l'auteur de cet article a testé 30 dépôts de code et a ajouté 8 nouvelles règles aux 4 originales de Karpathy, cherchant à couvrir les nouveaux problèmes de la programmation IA évoluant de la complétion ponctuelle vers la collaboration agentisée.
Voici l'article original :
Fin janvier 2026, Andrej Karpathy a publié un fil sur X, critiquant la façon dont Claude écrit du code. Il a relevé trois types de problèmes typiques : faire des hypothèses erronées sans les expliquer, sur-complexifier, et causer des dommages collatéraux inutiles à du code qui n'aurait pas dû être modifié.
Forrest Chang a vu ce fil et a synthétisé ces plaintes en 4 règles de comportement, les écrivant dans un fichier séparé CLAUDE.md, puis l'a publié sur GitHub. Ce projet a atteint 5,828 étoiles le premier jour, 60,000 favoris en deux semaines, et compte aujourd'hui 120,000 étoiles, devenant le dépôt à fichier unique à la croissance la plus rapide en 2026.

Par la suite, j'ai testé cela pendant 6 semaines sur 30 dépôts de code.
Ces 4 règles sont efficaces. Les erreurs qui survenaient avec une probabilité d'environ 40% sont tombées à moins de 3% pour les tâches où ces règles s'appliquaient. Le problème est que ce modèle a été créé initialement pour résoudre les erreurs de programmation de Claude observées en janvier.
En mai 2026, l'écosystème Claude Code fait face à des problèmes différents : conflits entre Agents, déclenchements en chaîne de hooks, conflits de chargement de skills, et interruptions de flux de travail multi-étapes entre sessions.
J'ai donc ajouté 8 règles supplémentaires. Voici la version complète à 12 règles de CLAUDE.md : pourquoi chacune mérite d'être incluse, et où le modèle original de Karpathy échouera silencieusement sur 4 points.
Si vous souhaitez passer les explications et l'utiliser directement, le fichier complet est à la fin de l'article.
Pourquoi c'est important
Le fichier CLAUDE.md de Claude Code est le plus sous-estimé de toute la stack technologique de programmation IA. La plupart des développeurs font trois types d'erreurs :
Premièrement, le traiter comme une poubelle à préférences, y entasser toutes leurs habitudes, le faire gonfler à plus de 4000 tokens, avec un taux de respect des règles tombant à 30%.
Deuxièmement, ne pas l'utiliser du tout et réécrire les prompts à chaque fois. Cela gaspille 5 fois plus de tokens et crée un manque de cohérence entre les sessions.
Troisièmement, copier un modèle et ne plus jamais y toucher. Il peut être efficace deux semaines, mais il deviendra obsolète à votre insu à mesure que le code évolue.
La documentation officielle d'Anthropic est claire : CLAUDE.md est essentiellement suggestif. Claude le suivra environ 80% du temps. Au-delà de 200 lignes, le taux de respect chute notablement car les règles importantes sont noyées dans le bruit.
Le modèle de Karpathy résout ce problème : un fichier, 65 lignes, 4 règles. C'est la base minimale.
Mais on peut aller plus haut. En ajoutant les 8 règles suivantes, il couvrira non seulement les problèmes d'écriture de code dont Karpathy se plaignait en janvier 2026, mais aussi les problèmes d'orchestration d'Agents apparus en mai 2026 – problèmes qui n'existaient pas lorsque le modèle original a été écrit.
Les 4 règles originales
Si vous n'avez pas encore vu le dépôt de Forrest Chang, voici la version de base :
Règle 1 : Pensez avant de coder.
Ne faites pas d'hypothèses silencieuses. Explicitez vos hypothèses, exposez les compromis. Posez des questions avant de deviner. Opposez-vous activement lorsqu'une solution plus simple existe.
Règle 2 : La simplicité d'abord.
Utilisez le code minimal qui résout le problème. N'ajoutez pas de fonctionnalités imaginaires. Ne créez pas d'abstractions pour du code à usage unique. Si un ingénieur senior le jugerait excessivement complexe, simplifiez.
Règle 3 : Modifications chirurgicales.
Ne modifiez que ce qui doit l'être. N'« optimisez » pas au passage le code adjacent, les commentaires ou le formatage. Ne refactorisez pas ce qui n'est pas cassé. Respectez le style existant.
Règle 4 : Exécution orientée objectif.
Définissez d'abord les critères de réussite, puis itérez jusqu'à validation. Ne dites pas à Claude chaque étape, dites-lui à quoi doit ressembler le résultat final et laissez-le itérer.
Ces 4 règles résolvent environ 40% des modes d'échec que j'observe dans les sessions Claude Code non supervisées. Les 60% restants se cachent dans les zones grises suivantes.
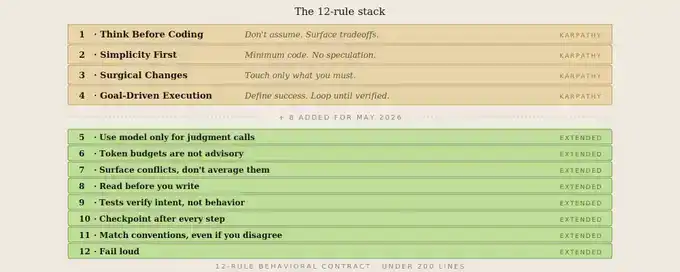
Mes 8 nouvelles règles, et pourquoi
Chaque règle provient d'un moment réel où les 4 règles originales de Karpathy ne suffisaient plus. Je décrirai d'abord le contexte, puis donnerai la règle correspondante.
Règle 5 : Ne laissez pas le modèle faire un travail non linguistique
La règle de Karpathy ne couvrait pas cela. Le modèle a donc commencé à décider de problèmes qui devraient être traités par du code déterministe : faut-il retenter un appel API, comment router un message, quand escalader. Résultat : la décision changeait chaque semaine. Vous obtenez une instable conditionnelle facturée 0,003 $ par token.
Le moment clé : un code appelait Claude pour « décider s'il fallait réessayer en cas d'erreur 503 ». Ça a bien fonctionné deux semaines, puis c'est devenu instable car le modèle a commencé à inclure le corps de la requête dans son contexte de décision. La stratégie de réessai est devenue aléatoire car le prompt lui-même était aléatoire.
Règle 6 : Fixez un budget token strict, sans exception
Un CLAUDE.md sans contrainte budgétaire, c'est un chèque en blanc. Chaque itération peut déraper en un déversement contextuel de 50,000 tokens. Le modèle ne s'arrête pas de lui-même.
Le moment clé : une session de débogage a duré 90 minutes. Le modèle itérait sans cesse autour du même message d'erreur de 8 Ko, oubliant progressivement les correctifs déjà tentés. À la fin, il proposait des solutions rejetées 40 messages auparavant. Avec un budget token, le processus aurait dû être arrêté à la 12ème minute.
Règle 7 : Exposez les conflits, ne faites pas de compromis moyens
Lorsque deux parties du code sont en contradiction, Claude essaie de plaire aux deux et produit un code incohérent.
Le moment clé : un dépôt avait deux modèles de gestion d'erreurs, un avec async/await et try/catch explicite, l'autre avec des frontières d'erreur globales. Le nouveau code écrit par Claude utilisait les deux. L'erreur était donc gérée deux fois. J'ai mis 30 minutes à comprendre pourquoi les erreurs étaient ignorées deux fois.
Règle 8 : Lisez d'abord, écrivez ensuite
La règle de Karpathy « Modifications chirurgicales » dit à Claude de ne pas modifier le code adjacent. Mais elle ne lui dit pas : comprenez d'abord le code adjacent. Sans cela, Claude écrira du nouveau code en conflit avec du code existant situé 30 lignes plus loin.
Le moment clé : Claude a ajouté une nouvelle fonction, identique à une fonction existante, parce qu'il n'avait pas d'abord lu la fonction originale. Les deux font la même chose. Mais à cause de l'ordre d'import, la nouvelle a écrasé l'ancienne, qui était la référence standard de fait depuis 6 mois.
Règle 9 : Les tests ne sont pas optionnels, mais les tests eux-mêmes ne sont pas l'objectif
La règle de Karpathy « Exécution orientée objectif » suggère que les tests peuvent être un critère de réussite. En pratique, Claude prend « les tests passent » comme seul objectif et écrit du code qui passe des tests superficiels mais casse autre chose.
Le moment clé : Claude a écrit 12 tests pour une fonction d'authentification, tous passés. Mais la logique d'authentification en production était cassée. Les tests vérifiaient seulement que la fonction « retournait quelque chose », pas la bonne chose. Elle passait les tests parce qu'elle retournait une constante.
Règle 10 : Les opérations longues nécessitent des points de contrôle
Le modèle de Karpathy suppose une interaction ponctuelle. Mais le vrai travail Claude Code est souvent multi-étapes : refactorisation sur 20 fichiers, construction d'une fonctionnalité en une session, débogage sur plusieurs commits. Sans point de contrôle, une erreur à une étape peut faire perdre toute la progression.
Le moment clé : une tâche de refactorisation en 6 étapes a échoué à l'étape 4. Quand je l'ai découvert, Claude avait déjà terminé les étapes 5 et 6 sur l'état erroné. Défaire et réparer a pris plus de temps que refaire toute la tâche. Avec des points de contrôle, l'erreur de l'étape 4 aurait été détectée.
Règle 11 : Les conventions priment sur la nouveauté
Dans un dépôt avec des modèles établis, Claude aime introduire ses propres façons de faire. Même si elles sont « meilleures », introduire un second modèle est pire que n'importe quel modèle unique.
Le moment clé : Claude a introduit des hooks dans un code React basé sur des class components. Ça fonctionnait. Mais cela cassait aussi le modèle de test existant du dépôt, car ces tests dépendaient de componentDidMount. Il a fallu une demi-journée pour tout supprimer et réécrire.
Règle 12 : Échouez explicitement, pas silencieusement
Les échecs les plus coûteux de Claude sont ceux qui ressemblent à des succès. Une fonction « s'exécute » mais retourne des données erronées ; une migration « terminée » mais ayant ignoré 30 enregistrements ; un test « réussi » mais seulement parce que l'assertion elle-même est fausse.
Le moment clé : Claude a signalé qu'une migration de base de données était « terminée avec succès ». En réalité, elle avait ignoré silencieusement 14% des enregistrements provoquant des conflits de contraintes. Ce comportement était logué mais n'était pas explicitement exposé. 11 jours plus tard, lorsque les données des rapports sont devenues aberrantes, nous avons découvert le problème.
Résultats des données
Pendant 6 semaines, j'ai suivi le même ensemble de 50 tâches représentatives, couvrant 30 dépôts, en testant trois configurations.
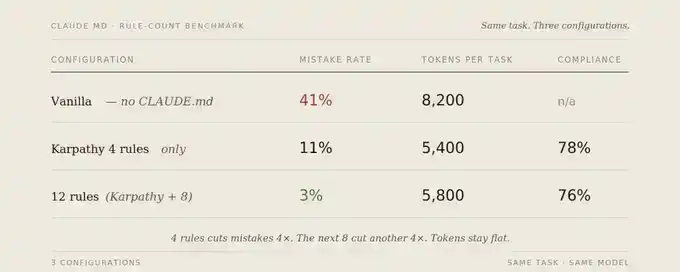
Le taux d'erreur correspond aux tâches nécessitant une correction ou une réécriture pour correspondre à l'intention initiale. Sont comptabilisées : hypothèses erronées silencieuses, sur-ingénierie, dommages collatéraux, échecs silencieux, violations de conventions, compromis conflictuels, points de contrôle manqués.
Le taux de respect correspond à la probabilité que Claude applique explicitement une règle lorsqu'elle est applicable.
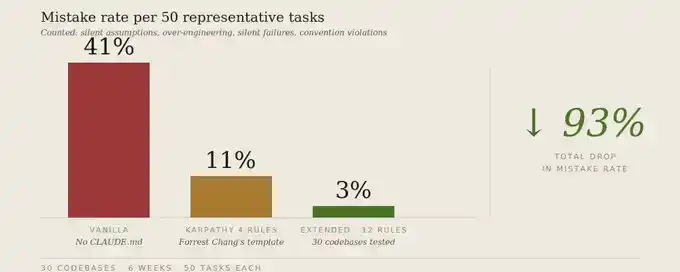
Le résultat intéressant n'est pas seulement la baisse du taux d'erreur de 41% à 3%. C'est surtout que l'extension de 4 à 12 règles a à peine augmenté la charge de respect, passant de 78% à 76%, mais a réduit le taux d'erreur de 8 points supplémentaires. Les nouvelles règles couvrent des modes d'échec que les 4 règles originales ne traitaient pas ; elles ne se font pas concurrence pour le même budget d'attention.
Où le modèle de Karpathy échoue silencieusement
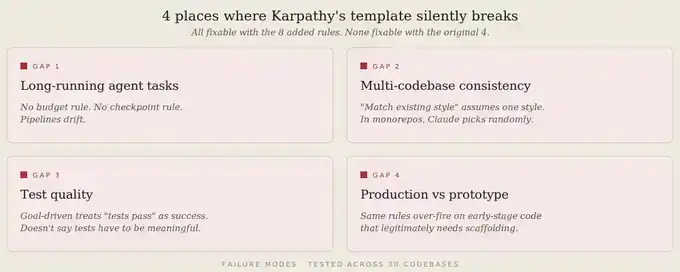
Même sans ajouter de nouvelles règles, le modèle original à 4 règles est insuffisant dans au moins 4 situations.
Premièrement, les tâches longues d'Agent.
Les règles de Karpathy ciblent principalement le moment où Claude écrit du code. Mais que se passe-t-il quand Claude exécute un pipeline multi-étapes ? Le modèle original n'a pas de règle de budget, de point de contrôle, ni de règle « échouer bruyamment ». Le pipeline dérive alors progressivement.
Deuxièmement, la cohérence multi-dépôts.
« Respecter le style existant » suppose un seul style. Mais dans un monorepo de 12 services, Claude doit choisir quel style respecter. Les règles originales ne lui disent pas comment choisir. Il choisit alors au hasard ou mélange les styles.
Troisièmement, la qualité des tests.
« Exécution orientée objectif » considère « les tests passent » comme une réussite, mais ne précise pas que les tests doivent être significatifs. Résultat : Claude écrit des tests qui ne vérifient presque rien, mais qui le font croire qu'il est sûr de lui.
Quatrièmement, la différence entre production et prototypage.
Les mêmes 4 règles peuvent empêcher la sur-ingénierie en production, mais aussi ralentir le prototypage. Car une phase de prototypage a parfois besoin de 100 lignes d'échafaudage exploratoire pour trouver la direction. La règle « Simplicité d'abord » de Karpathy se déclenche trop facilement sur du code précoce.
Ces 8 nouvelles règles ne remplacent pas les 4 règles originales de Karpathy, elles comblent leurs lacunes : le modèle original correspond au scénario d'écriture de code par complétion de janvier 2026 ; en mai 2026, Claude Code évolue dans un environnement multi-étapes, multi-dépôts, piloté par des Agents, et les problèmes ne sont pas les mêmes.
Ce qui n'a pas fonctionné
Avant de finaliser ces 12 règles, j'ai aussi essayé d'autres approches.
Ajouter des règles vues sur Reddit / X.
La plupart répétaient simplement sous une autre forme les 4 règles de Karpathy, ou étaient des règles spécifiques à un domaine non généralisables, comme « utilisez toujours les classes Tailwind ». Elles ont été supprimées.
Dépasser 12 règles.
J'ai testé jusqu'à 18 règles. Au-delà de 14, le taux de respect est tombé de 76% à 52%. La limite des 200 lignes est réelle. Au-delà, Claude commence à faire du pattern matching sur « il y a des règles ici » au lieu de les lire réellement.
Règles dépendant d'outils spécifiques.
Par exemple « utilisez toujours eslint » : si eslint n'est pas installé, la règle échoue silencieusement. Je l'ai reformulée de manière indépendante, par exemple « suivez les styles déjà appliqués de force dans le dépôt ».
Mettre des exemples plutôt que des règles dans CLAUDE.md.
Les exemples consomment plus de contexte. Trois exemples utilisent autant de contexte qu'environ 10 règles, et Claude a tendance à surajuster sur les exemples. Les règles sont abstraites, les exemples sont concrets. Utilisez donc des règles.
« Soyez prudent », « Réfléchissez bien », « Concentrez-vous ».
Ce sont du bruit. Le taux de respect de ces instructions tombe à environ 30% car elles ne sont pas vérifiables. Je les ai remplacées par des règles impératives plus concrètes, comme « explicitez les hypothèses ».
Dire à Claude d'agir comme un « ingénieur senior ».
Ça ne fonctionne pas. Claude se considère déjà comme un ingénieur senior. Le vrai problème n'est pas ce qu'il pense, mais ce qu'il exécute. Les règles impératives réduisent cet écart, les prompts d'identité non.
Version complète à 12 règles de CLAUDE.md
Voici la version complète prête à être copiée-collée.
Temporairement impossible d'afficher ce contenu hors du document Lark
Sauvegardez-le en tant que CLAUDE.md à la racine de votre dépôt. Sous ces 12 règles, ajoutez les règles spécifiques à votre projet, comme la stack technique, les commandes de test, les modes d'erreur, etc. Ne dépassez pas 200 lignes au total, sinon le taux de respect chutera.
Comment l'installer
Deux étapes :
1. Ajoutez les 4 règles de base de Karpathy à votre CLAUDE.md
curl https://raw.githubusercontent.com/forrestchang/andrej-karpathy-skills/main/CLAUDE.md >> CLAUDE.md
2. Collez les règles 5–12 de cet article ci-dessous
Sauvegardez le fichier à la racine du dépôt. Le >> est important, il ajoute au CLAUDE.md existant au lieu d'écraser vos règles projet déjà écrites.
Modèle mental
CLAUDE.md n'est pas une liste de souhaits, mais un contrat de comportement pour bloquer des modes d'échec concrets que vous avez observés.
Chaque règle devrait répondre à : quelle erreur empêche-t-elle ?
Les 4 règles de Karpathy empêchent les modes d'échec qu'il a vus en janvier 2026 : hypothèses silencieuses, sur-ingénierie, dommages collatéraux, critères de réussite faibles. C'est la base, ne la sautez pas.
Mes 8 nouvelles règles empêchent les nouveaux modes d'échec apparus après mai 2026 : boucles d'Agent sans contrainte budgétaire, tâches multi-étapes sans points de contrôle, tests semblant vérifier mais ne testant pas la logique cruciale, et problèmes d'échecs silencieux présentés comme des succès. Ce sont des correctifs incrémentaux.
Bien sûr, l'effet varie. Si vous n'exécutez pas de pipelines multi-étapes, la règle 10 est moins importante. Si votre dépôt a un style unifié et appliqué par un linter, la règle 11 est redondante. Après avoir lu ces 12 règles, gardez celles qui correspondent à des erreurs que vous avez réellement commises, supprimez le reste.
Un CLAUDE.md personnalisé à 6 règles ciblant vos vrais modes d'échec vaut mieux qu'une version à 12 règles dont 6 ne vous serviront jamais.
Conclusion
Le post X de Karpathy en janvier 2026 était essentiellement une plainte. Forrest Chang en a fait 4 règles. Finalement, 120 000 développeurs ont mis une étoile à ce résultat. Et la plupart d'entre eux n'utilisent encore que ces 4 règles.
Le modèle a progressé, l'écosystème a changé. Agents multi-étapes, déclenchements en chaîne de hooks, chargement de skills, collaboration multi-dépôts – tout cela n'existait pas lorsque Karpathy a écrit ce post. Les 4 règles originales ne résolvent pas ces problèmes. Elles ne sont pas fausses, elles sont incomplètes.
Ajoutez 8 règles. 6 semaines de tests couvrant 30 dépôts. Taux d'erreur réduit de 41% à 3%.
Mettez cet article en favori ce soir, collez ces 12 règles dans votre CLAUDE.md. S'il vous évite une semaine de détours avec Claude, partagez-le.







