【Synthèse】 Lors du WWDC qui vient de se terminer, la renaissance de Siri grâce à l'IA a été un mot-clé, et les « modèles embarqués » sont déjà une tendance ! Un peu plus tôt, Andrej Karpathy appelait à extraire les connaissances des modèles pour ne garder que le « noyau cognitif ». Une entreprise chinoise affirme avoir concrétisé cette vision – avec 4B paramètres, elle obtient des résultats équivalents à ceux de modèles massifs de centaines de milliards de paramètres sur des tâches d'intelligence collective. Que peut vraiment changer un modèle cognitif embarqué ?
Hier soir, Siri a été relancée grâce à Gemini, le modèle de Google à 1 200 milliards de paramètres.
Mais parallèlement, Amazon a fermé son controversé classement interne d'IA – les employés utilisaient massivement les outils d'IA, faisant exploser les coûts de calcul au point que la direction a dû intervenir.
Le coût des tokens est devenu l'un des obstacles les plus importants au déploiement à grande échelle de l'IA.
Andrej Karpathy avait indiqué une direction dans une interview : extraire les vastes connaissances du modèle, ne garder qu'un « noyau cognitif » capable de penser, de planifier, de savoir ce qu'il ne sait pas, avec seulement quelques milliards de paramètres.

https://www.youtube.com/watch?v=lXUZvyajciY
Cette direction est en train d'être validée.
Un modèle de 4B paramètres a obtenu des résultats équivalents à ceux de modèles massifs comme GPT-5.4 (centaines de milliards de paramètres) sur des tâches d'intelligence collective, et peut être déployé en embarqué.
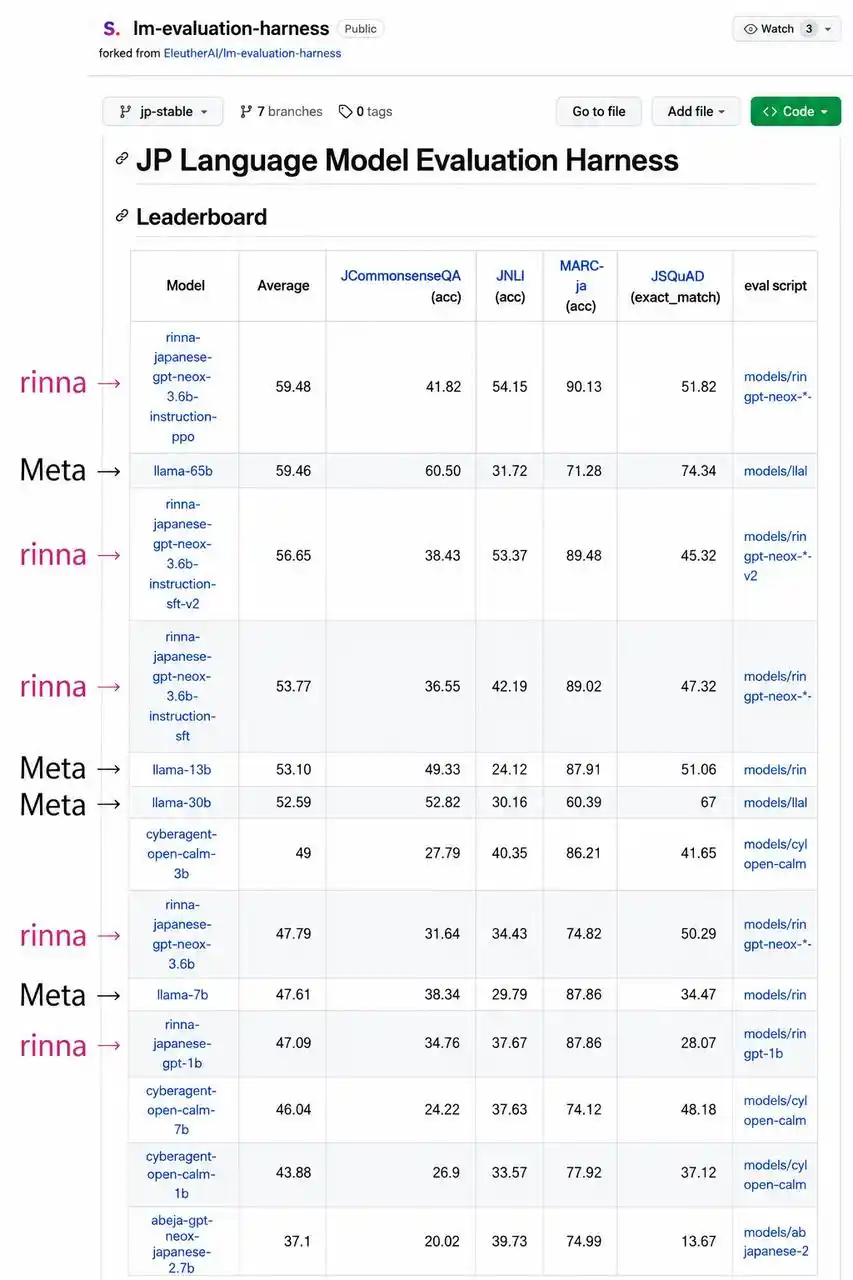
Il provient d'une équipe fondatrice qui avait déjà, avec un modèle de 3.6B paramètres, battu Llama 65B et atteint la première place du classement Hugging Face japonais.
Cette fois, ils ont créé le premier modèle cognitif embarqué du secteur.
La prédiction de Karpathy et la facture du calcul
La pression des coûts de calcul est passée d'un sujet technique à un sujet financier, le cas d'Amazon n'étant qu'un exemple.
Les employés d'Amazon, en utilisant fréquemment les capacités d'inférence des grands modèles via des outils internes d'IA, ont fait grimper les dépenses globales en calcul, forçant la direction à suspendre d'urgence le mécanisme de classement pour limiter l'utilisation.

https://www.ft.com/content/b1a62a7f-6df5-4c90-94ce-64ce9c9961b6?syn-25a6b1a6=1
Le secteur traverse sa première « grande retraite des tokens », la consommation quotidienne de calcul de certaines entreprises ayant déjà atteint un niveau de centaines de millions.
Le modèle économique des grands modèles se heurte à un mur structurel : plus les capacités sont fortes, plus la chaîne de raisonnement est profonde, plus le coût d'un seul appel est élevé.
Le ratio Coût GPU / Revenus (GPU Cost / Revenue) est un indicateur crucial pour toutes les entreprises d'IA, et la tendance à l'expansion continue des paramètres des modèles ne fera qu'aggraver cet indicateur.
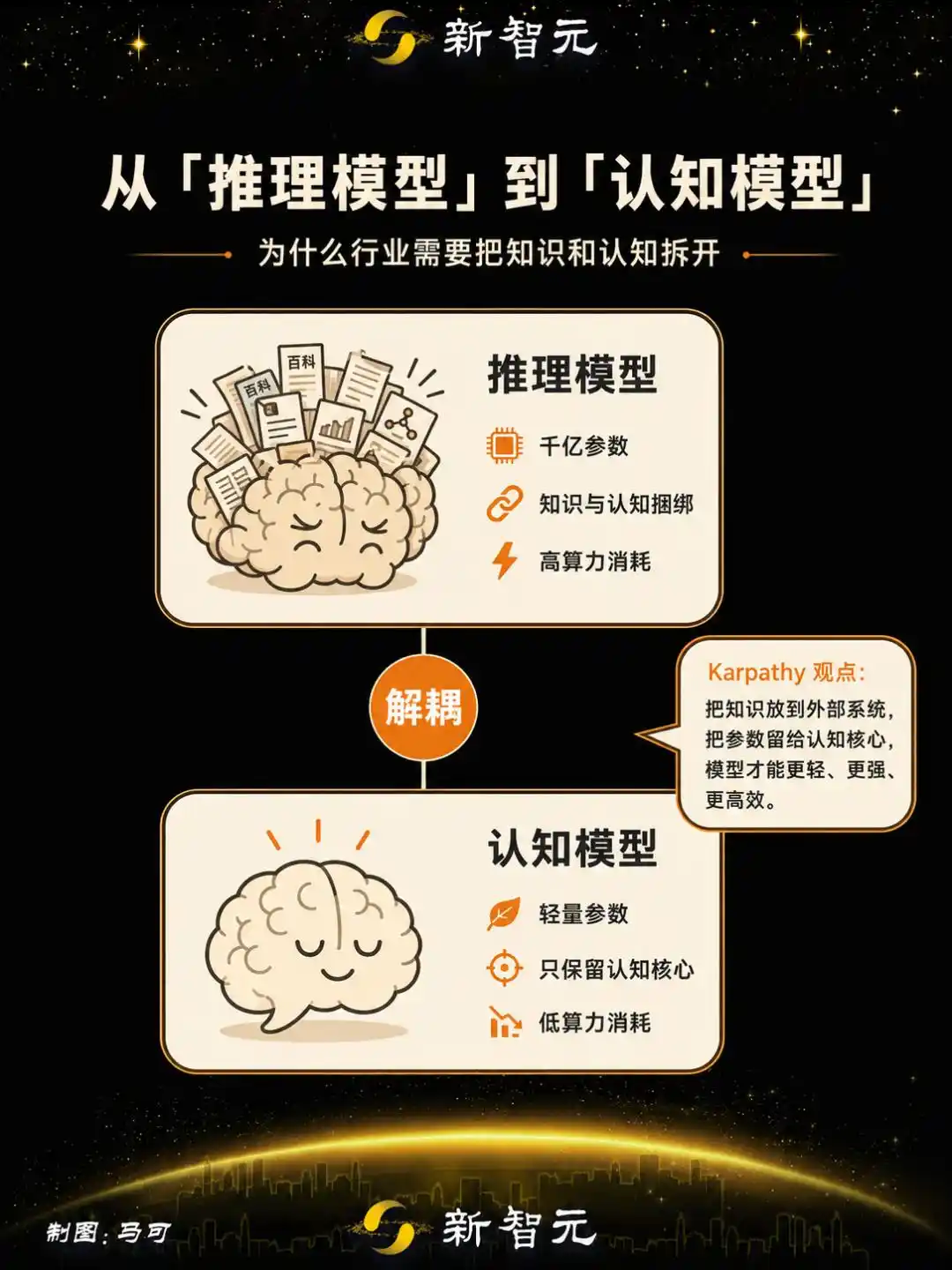
L'approche de Karpathy pointe vers une autre voie : il propose d'extraire la « mémoire / connaissance » du modèle, pour ne conserver ce qu'il appelle le « noyau cognitif » –
une entité dépouillée d'une quantité massive de faits et de connaissances, mais qui conserve l'algorithme de pensée, la magie de l'intelligence, les stratégies de résolution de problèmes.
Il estime qu'avec seulement quelques milliards de paramètres, une réflexion humaine efficace peut être réalisée :
Il penserait comme un humain... Si vous lui posez une question factuelle, il pourrait avoir besoin de consulter – il sait qu'il ne sait pas, et il irait vérifier.
Ces propos ont suscité de vifs débats dans la communauté technique.
Un consensus se forme sur la direction, mais les équipes capables de faire passer le « noyau cognitif » du concept à un produit déployable sont le véritable facteur de changement.
4B rivalise avec des modèles de centaines de milliards : qu'a fait Nextie Alpha ?
Celui qui a fait passer le « noyau cognitif » décrit par Karpathy du concept au produit est Nextie.
Cette entreprise a utilisé l'apprentissage par renforcement pour entraîner des modèles de raisonnement open source, découplant la connaissance de la cognition – en extrayant les connaissances mémorisées du modèle, et en renforçant les capacités de généralisation et de pensée abstraite.
Le modèle produit a été nommé Nextie Alpha, avec une taille de 4B paramètres. Il a terminé son entraînement et a été déployé, c'est le premier produit du secteur à être défini comme un « modèle cognitif ».
Quant à sa méthode d'entraînement, le point de départ est assez inhabituel.
L'équipe de Nextie a compilé des articles académiques humains de 1800 à 2020, couvrant 220 ans, pour tenter de retracer l'évolution de l'intelligence collective et fournir un cadre de référence pour la voie technique.
Sur la base de ces recherches, l'apprentissage par renforcement a été appliqué à des modèles de raisonnement open source, en se concentrant sur l'amélioration des capacités de généralisation et d'abstraction.
Pour donner un exemple concret : après entraînement, le modèle peut transférer les modes de décision d'un joueur de Go à des scènes de la vie quotidienne – ce que Karpathy appelle « conserver l'algorithme de pensée » trouve ici une mise en œuvre technique concrète.
En termes de performance, Nextie Alpha, sur des tâches d'intelligence collective (débat, réflexion, défi, vote, etc.), atteint avec 4B paramètres une qualité de sortie équivalente à celle de grands modèles comme GPT-5.4, avec des avantages significatifs en consommation de calcul et vitesse d'inférence.
Ce qui mérite encore plus d'attention, c'est l'espace de scénarios que ce modèle débloque, avec trois niveaux de signification progressive.
Premier niveau, amélioration de la qualité décisionnelle des systèmes multi-agents.
Dans le cadre de décision Harness, l'utilisation du modèle cognitif donne de meilleurs résultats que le modèle de raisonnement.
Le passage d'un modèle de base de « raisonnement » à « cognitif » apporte un bond qualitatif dans l'ensemble de la chaîne décisionnelle des systèmes de collaboration multi-agents.
Deuxième niveau, réduction drastique des coûts de calcul.
Comparé aux modèles de centaines de milliards de paramètres, les coûts de calcul pour un déploiement cloud sont considérablement réduits avec 4B.
Nextie Alpha supporte également le déploiement embarqué – il peut être exécuté directement sur un MacBook ou des dispositifs d'intelligence incarnée, transformant ainsi les coûts de calcul en coûts électriques.
Cela a une signification particulière pour le domaine de l'intelligence incarnée : utiliser un grand modèle de centaines de milliards de paramètres pour piloter un robot domestique, chaque « réflexion » consomme une grande quantité de tokens, et le coût total pourrait être plus élevé que de faire appel à un humain.
Un déploiement embarqué de 4B recalcule fondamentalement cette équation.
Troisième niveau, déblocage de scénarios proactifs (Proactive).
La grande majorité des produits d'IA actuels fonctionnent en mode réactif (Reactive) – l'utilisateur donne un ordre, le modèle répond.
Le mode Proactive signifie que l'agent intelligent prend des décisions et exécute des tâches de manière autonome, sans attendre de commande. Son échelle commerciale dépasse de loin celle du mode Reactive, mais jusqu'à présent, il était bloqué par les coûts de calcul.
Nextie Alpha permet un fonctionnement 24h/24, à un coût maîtrisé, rendant possibles les agents proactifs qui étaient auparavant mis de côté car trop chers.

Les atouts de l'équipe et le positionnement dans le secteur
Nextie a été fondée par l'équipe fondatrice de Xiaoice de Microsoft.
La marque de fabrique de cette équipe est « battre les grands modèles avec peu de paramètres » – le modèle open source qu'ils avaient précédemment entraîné, rinna (Xiaoice japonais), avec 3.6B paramètres, avait atteint la première place du classement Hugging Face japonais, battant Llama 65B.
Nextie Alpha, avec 4B paramètres, obtenant des résultats équivalents à ceux de modèles de centaines de milliards, perpétue le même héritage technique.
Le secteur sur lequel Nextie mise lourdement est : les systèmes multi-agents collectifs Harness.
Ce secteur est en train d'être validé par les capitaux majeurs – en mars 2026, OpenAI a investi dans la startup Isara, portant directement sa valorisation à 6,5 milliards de dollars. La direction de recherche d'Isara est justement la collaboration multi-agents et l'intelligence collective.

https://www.wsj.com/tech/ai/openai-backs-new-ai-startup-seeking-bot-army-breakthroughs-a0b1fedc
Dans l'évaluation approfondie de l'intelligence (IDI) de ce domaine, les performances globales de Nextie sont significativement supérieures à celles de n'importe quel grand modèle unique.
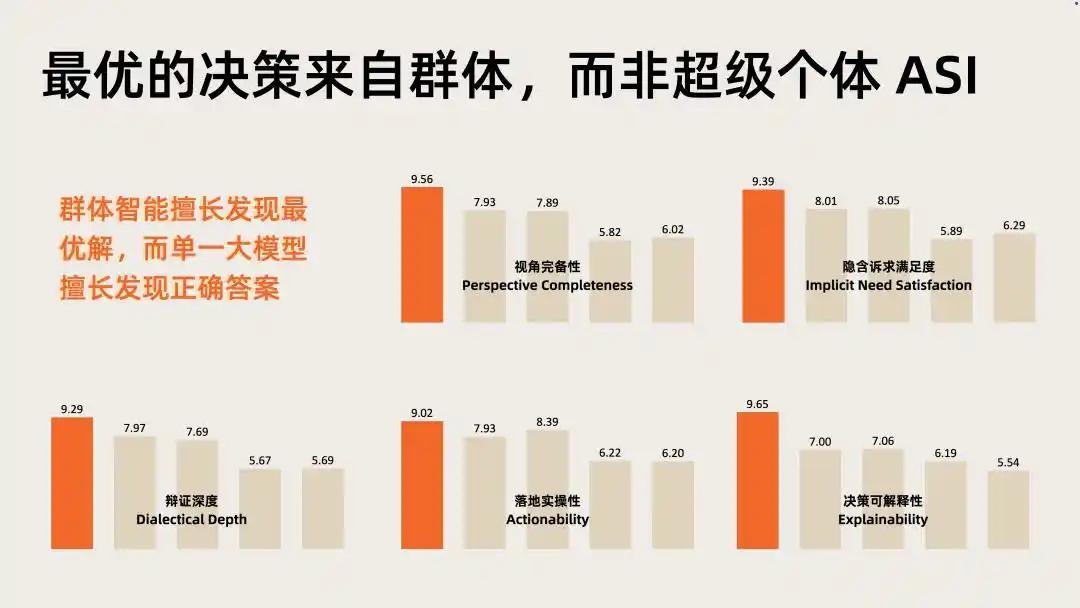
La validation par les capitaux confirme la valeur du secteur, et les données d'évaluation positionnent Nextie à l'intérieur de ce secteur.
La superposition de ces deux signaux pointe vers le même constat : les systèmes multi-agents collectifs sont la prochaine direction à haute valeur ajoutée de la couche applicative de l'IA, et le modèle cognitif est l'infrastructure clé pour les piloter.
Le modèle cognitif change non seulement les paramètres, mais aussi le bilan
Le ratio Coût GPU / Revenus (GPU Cost / Revenue) est une épée de Damoclès suspendue au-dessus de toutes les entreprises d'IA.
La solution proposée par le modèle cognitif vise fondamentalement à restructurer le modèle économique – obtenir avec 4B des résultats qui nécessitaient auparavant des centaines de milliards de paramètres signifie qu'une même qualité de sortie correspond à une structure de coûts totalement différente.
Nextie a révélé en interview que l'équipe était en train d'entraîner un modèle cognitif de 8B paramètres avec une capacité de généralisation encore plus forte.
Si 4B peuvent déjà rivaliser avec GPT-5.4 sur des tâches d'intelligence collective, les limites des capacités de 8B méritent d'être anticipées.
Une question plus profonde est posée à tout le secteur : lorsque le coût d'exécution en continu d'un modèle cognitif en embarqué devient négligeable, tous les produits d'IA conçus aujourd'hui sur le mode réactif (« l'utilisateur donne un ordre, le modèle répond ») devront probablement reconsidérer leur forme.
L'espace d'imagination commerciale des agents proactifs dépasse de loin tout ce qui existe actuellement sous la forme d'agents réactifs.
Cet article provient du compte WeChat public « XinZhiYuan », auteur : ASI启示录







