Jusqu'où peut-on compresser une image ?
En février 2025, le Joint Photographic Experts Group (JPEG) a annoncé un événement discrètement célébré dans l'industrie : JPEG AI, le premier standard international de codage d'images par apprentissage de bout en bout, tant attendu et développé pendant des années, était officiellement publié.

La nouvelle s'est répandue, de nombreux chercheurs la partageant sur les réseaux sociaux avec des commentaires comme « L'IA fait enfin son entrée dans les standards ».
La norme JPEG est née en 1992 et, depuis plus de trente ans, elle constitue l'un des langages fondamentaux des images numériques humaines. Aujourd'hui, l'intelligence artificielle commence à reprendre l'écriture de la grammaire de ce langage.
Derrière les célébrations, une réalité subtile persiste : même JPEG AI reste encore assez éloigné d'une véritable compression « perceptuelle ».
Les ingénieurs savent que les métriques traditionnelles de qualité de compression comme le rapport signal sur bruit de crête (PSNR) n'ont pas grand-chose à voir avec ce que l'œil humain perçoit comme « beau ». Une image peut obtenir un score PSNR élevé tout en paraissant fade à l'œil humain ; une autre avec un PSNR plus faible peut sembler riche en détails et réaliste. Optimiser une métrique mathématique et optimiser la perception humaine sont deux choses très différentes.
Pendant des décennies, du JPEG au VVC en passant par JPEG AI, la logique de conception de presque tous les codecs est restée enfermée dans le cadre des métriques mathématiques. La compression perceptuelle (optimisation directe pour l'expérience visuelle) est longtemps restée un objectif lointain dans les articles académiques, plutôt qu'une réalité technique pouvant être intégrée dans un téléphone.
C'est à ce moment précis qu'une équipe d'ingénieurs d'Apple a discrètement publié un article présentant leur réponse, nom de code : PICO.

Titre de l'article : What Matters in Practical Learned Image Compression
Adresse de l'article : https://arxiv.org/pdf/2605.05148
Pourquoi « paraître mieux » est-il bien plus difficile qu'« avoir un score plus élevé » ?
Pour comprendre PICO, il faut d'abord comprendre ce que fait réellement la compression d'image.
Enregistrer une photo sous forme de fichiel est essentiellement un compromis entre « quoi oublier, quoi retenir ». L'espace de stockage étant limité, il faut nécessairement jeter une partie de l'information, tout en faisant en sorte que l'observateur ne le remarque pas trop. Différents codecs suivent différentes « méthodes de suppression ».
Les codecs traditionnels comme JPEG, AV1, VVC sont des systèmes de règles conçus manuellement par des ingénieurs. Ils découpent l'image en blocs, la transforment, la quantifient, l'encodent entropiquement, chaque étape représentant des décennies d'expérience humaine. Ces systèmes peuvent exceller sur des métriques mathématiques comme le PSNR, mais leur conception est intrinsèquement orientée vers la « réduction de l'erreur pixel », et non vers la « réduction de l'inconfort visuel ».
Le problème est que l'œil humain n'est pas un compteur d'erreur pixel. Sa sensibilité aux textures, au texte, aux détails est bien plus complexe qu'une formule mathématique. Lorsque vous compressez fortement une photo de rue, le PSNR peut rester correct, mais vous verrez les bords des bâtiments flous, les textes des panneaux déformés — or, ce sont précisément les choses que l'œil humain remarque en premier.
L'émergence des codecs par apprentissage a théoriquement ouvert une nouvelle porte : les réseaux neuronaux peuvent être entraînés de bout en bout directement pour la perception humaine, et non pour une formule mathématique. Mais avant PICO, les codecs par apprentissage perceptuel existants étaient soit trop lents pour être pratiques, soit manquaient de compatibilité multi-appareils, soit ne permettaient pas un contrôle flexible du débit binaire, les rendant impossibles à intégrer dans un produit grand public.
Trois problèmes clés, trois solutions
PICO signifie Perceptual Image Codec (Codec d'Image Perceptuel). Ce nom indique clairement son objectif : satisfaire l'œil humain.
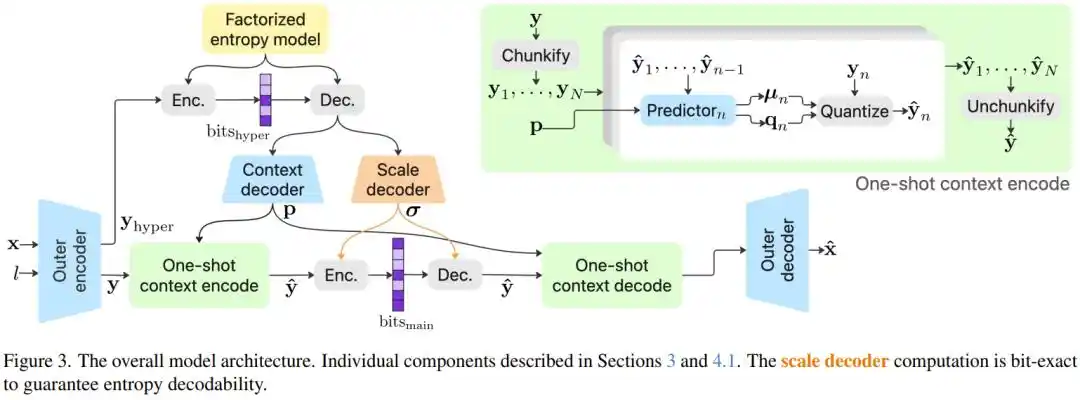
L'équipe de recherche a exploré systématiquement des millions de configurations de modèles et a introduit plusieurs innovations technologiques clés.
Premier problème : L'encodage entropique est lent, que faire ?
La compression d'image comporte une difficulté : pour compresser davantage, un codec a besoin d'un « modèle entropique » pour estimer précisément la quantité d'information de chaque pixel. La méthode la plus précise est l'encodage autorégressif : pour compresser chaque pixel, il faut d'abord regarder les pixels déjà compressés autour, pour prédire séquentiellement. C'est comme un chef qui, pour chaque ingrédient ajouté, doit regarder l'état de la casserole avant de décider de la suite. Précis, mais extrêmement lent.
La solution de PICO est le « Modèle de contexte en une passe » (One-shot Context Model) : le paramètre « d'échelle », crucial dans l'encodage entropique, est extrait et calculé entièrement en une seule passe avant, sans attendre les allers-retours ; les autres paramètres peuvent être calculés en parallèle, préservant la précision autorégressive tout en contournant son goulot d'étranglement de vitesse. Résultat : sans ce module, les performances du modèle chutent de 10,28 % ; avec lui, la vitesse est presque inchangée.
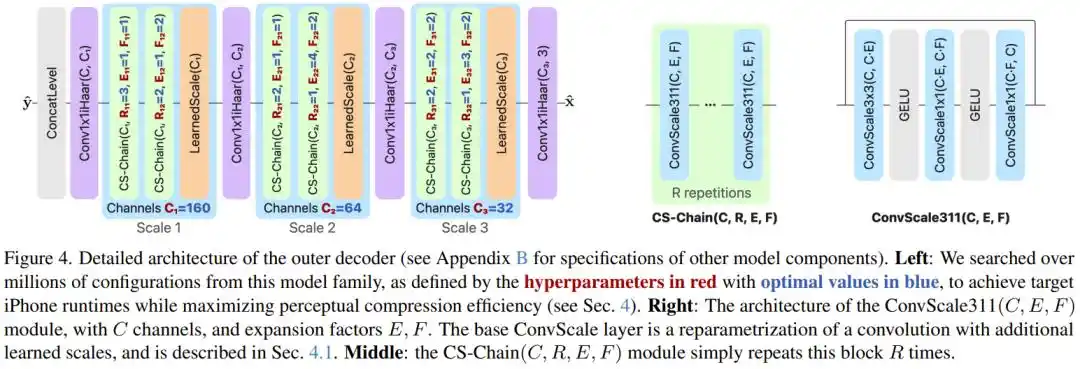
Deuxième problème : L'entraînement perceptuel génère des hallucinations, que faire ?
Les images générées par des GAN (Réseaux Antagonistes Génératifs) semblent souvent « réalistes », mais ce réalisme peut être inventé — des mèches de cheveux deviennent des motifs inexistants, des surfaces lisses acquièrent des textures artificielles. Pire, l'œil humain est extrêmement sensible au texte : même une légère déformation d'une lettre est immédiatement perçue.
PICO a conçu spécifiquement pour le texte la TextFidelityLoss : en utilisant un détecteur de texte existant, il identifie automatiquement les zones de texte dans l'image, et impose dans ces zones une contrainte stricte de fidélité pixel, tout en réprimant la « créativité » du GAN dans ces régions. Les expériences montrent qu'avec cette fonction de perte, l'erreur absolue dans les zones de texte est réduite de moitié.
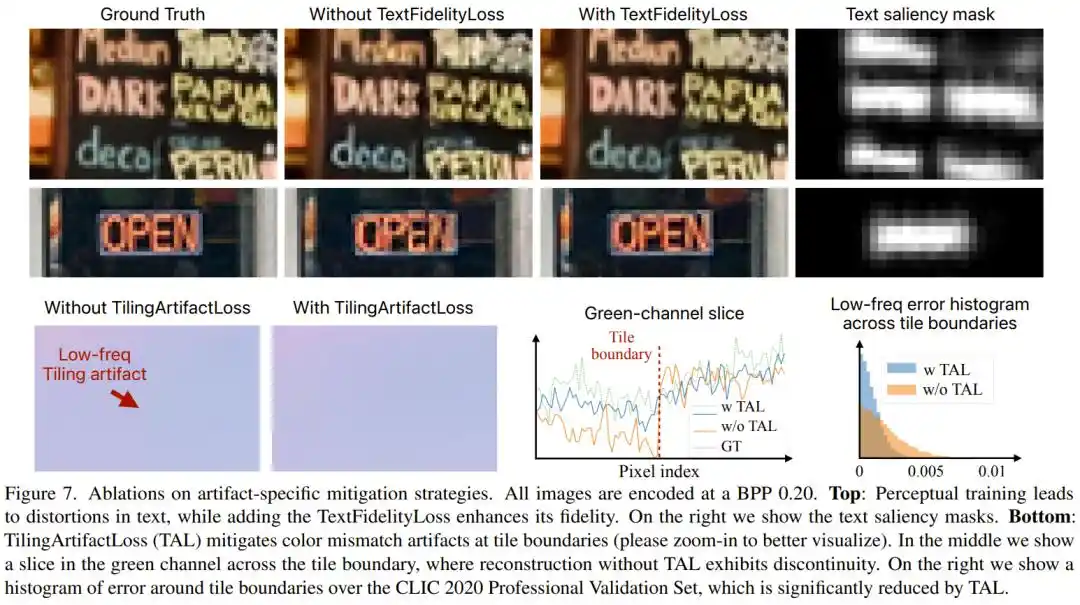
Troisième problème : Le traitement par blocs laisse des bordures de couleur, que faire ?
Pour fonctionner rapidement sur les puces des téléphones, PICO découpe l'image en tuiles de 504×504 pixels, traite chacune séparément, puis les réassemble. Mais le GAN, lors de l'entraînement, a tendance à ignorer les couleurs basse fréquence, ce qui entraîne souvent des différences de couleur visibles entre tuiles adjacentes, comme une sensation de « mauvaise assemblage » lors du retouche photo. L'équipe de recherche a introduit spécifiquement la TilingArtifactLoss, une perte L1 multi-résolution, forçant le modèle à maintenir la cohérence des couleurs à plusieurs fréquences spatiales. Cette mesure a réduit l'erreur aux bordures des tuiles de plus de moitié.
Résultats expérimentaux
L'équipe d'Apple ne s'est pas contentée des métriques de référence. Elle a mandaté une plateforme tierce, Mabyduck, pour organiser une vaste évaluation subjective humaine.
L'évaluation utilisait une comparaison par paires en aveugle : 610 évaluateurs sélectionnés (après test de daltonisme et de détection d'artefacts de compression) comparaient les résultats de reconstruction d'une même image par différents codecs, par paires. Les résultats ont été agrégés en un score Bayesian ELO. Au total, 74 925 comparaisons par paires ont été collectées.

Les chiffres finaux parlent d'eux-mêmes : À qualité visuelle identique, la taille de fichier de PICO n'est qu'un tiers à la moitié de celle d'AV1, AV2, VVC, ECM et JPEG AI — en d'autres termes, pour stocker la même image, il ne nécessite que 30% à 43% des bits de ces standards. Comparé aux codecs par apprentissage perceptuel les plus performants actuels (HiFiC, MRIC, etc.), PICO économise également 20% à 40% de la taille de fichier.
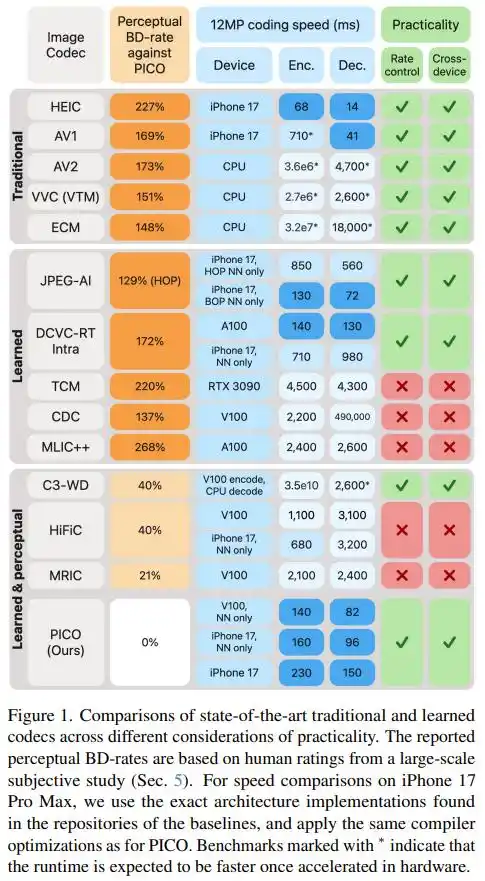
En termes de vitesse, sur l'iPhone 17 Pro Max, PICO encode une photo de 12 MP en seulement 230 millisecondes, et la décode en 150 ms. La plupart des codecs ML de pointe, exécutés sur des serveurs avec des cartes graphiques NVIDIA V100, sont plus lents que cela.
Il est à noter que l'article enregistre également un « contre-exemple » : sur la métrique traditionnelle du PSNR, PICO affiche des performances moyennes, voire inférieures à DCVC-RT et VVC. Cela confirme précisément le constat de base de l'équipe : optimiser la qualité perceptuelle et optimiser les métriques mathématiques sont deux directions fondamentalement différentes, et on ne peut pas avoir le beurre et l'argent du beurre.
Un jalon d'époque, pas un point final
PICO a bien sûr ses limites. L'article reconnaît que pour les images synthétiques hautement structurées comme les dessins animés ou les schémas, l'efficacité de compression de PICO est inférieure à celle des codecs traditionnels, car ce type de contenu se prête naturellement à une modélisation autorégressive guidée par des règles, plutôt qu'à une génération perceptuelle.
Mais ces limites n'obscurcissent pas la signification de ce travail.
Ces trente dernières années, les progrès techniques en compression d'image se sont presque tous produits sur la piste « faire paraître les chiffres meilleurs ». Du JPEG au HEVC en passant par VVC, les ingénieurs ont optimisé génération après génération des métriques comme le PSNR ou le SSIM. La perception humaine est toujours restée un « problème difficile » contourné.
PICO est la première fois que quelqu'un s'attaque systématiquement de front à ce problème : de l'exploration d'architecture et de la conception des fonctions de perte, à l'évaluation subjective humaine à grande échelle, pour finalement aboutir à un codec capable de fonctionner en temps réel sur un téléphone.
La prochaine fois que vous partagerez une photo depuis un appareil Apple, vous ne ressentirez peut-être aucune différence. Mais peut-être que dans ce processus de compression silencieux, un algorithme conçu sur mesure pour la perception humaine décidera quelles informations méritent d'être conservées, et lesquelles peuvent être discrètement oubliées.
L'équipe : De WaveOne à Apple
L'auteur correspondant de cet article est Oren Rippel, chercheur chez Apple, une figure familière du domaine de la compression.
Son nom est apparu pour la première fois à grande échelle en 2017. Il travaillait alors pour la startup WaveOne et a publié un article intitulé « Real-Time Adaptive Image Compression », utilisant un réseau neuronal pour surpasser tous les codecs grand public de l'époque, tout en maintenant une vitesse d'exécution en temps réel. Cet article a fait des vagues dans le milieu universitaire et a établi la réputation de Rippel dans le domaine de la compression par apprentissage.

Par la suite, le même noyau dur de personnes a continué à approfondir ses travaux chez WaveOne, présentant ELF-VC pour la compression vidéo, réalisant sur le jeu de tests vidéo UVG une économie de débit binaire de 44% par rapport au H.264, tout en étant cinq fois plus rapide que les autres codecs ML comparables.
Cette équipe de WaveOne a ensuite intégré Apple dans son ensemble. Et PICO est leur première réponse systématique, avec les ressources de calcul et de plateforme d'Apple, à la question de la compression d'image perceptuelle.
Cet article provient du compte WeChat « Machine Heart » (ID : almosthuman2014), auteur : Compression is Intelligence.






