Édité par|Panda
Ces derniers jours, Google a perdu coup sur coup deux de ses talents.
Le 18 juin, Noam Shazeer, l'un des co-auteurs du papier sur le Transformer, a annoncé sur X qu'il quittait l'entreprise pour rejoindre OpenAI. Deux jours plus tard, le lauréat du prix Nobel de chimie 2024 et responsable de l'équipe AlphaFold, John Jumper, a également annoncé son départ de Google DeepMind, pour se rendre chez Anthropic.
Ces deux annonces successives ont eu un impact considérable sur les marchés financiers : l'action d'Alphabet, la maison-mère de Google, a chuté de plus de 7% à un moment donné, effaçant plus de 300 milliards de dollars de capitalisation boursière. Plusieurs analystes ont attribué cette vente massive à la « fuite des cerveaux ». Gil Luria, analyste chez D.A. Davidson, a déclaré sans ambages que le départ de Shazeer pour OpenAI et de Jumper pour Anthropic, l'un après l'autre, inquiétait désormais les marchés quant à la capacité de Google à conserver ses talents dans la bataille pour l'IA.

Le départ de Shazeer est particulièrement intéressant – c'est déjà la deuxième fois qu'il quitte Google.
En 2021, mécontent du refus de la société de publier publiquement le chatbot qu'il avait dirigé, il était parti fonder Character.AI ; en août 2024, Google a dépensé environ 2,7 milliards de dollars pour acheter une licence technologique à Character.AI, le ramenant ainsi chez DeepMind en tant que vice-président ingénierie du projet Gemini, qu'il co-dirigeait avec Jeff Dean. Moins de deux ans plus tard, il est à nouveau parti, cette fois pour le rival acharné OpenAI.
Ainsi, les huit co-auteurs du papier publié il y a neuf ans, « Attention Is All You Need », ont désormais tous quitté Google.
L'utilisateur de X, Tyler Maran, a créé une infographie illustrant leurs destinations respectives, qui a été largement partagée sur les réseaux sociaux.

Cependant, cette image pourrait rapidement devenir obsolète. Ces deux derniers jours, des rumeurs ont circulé selon lesquelles Nvidia recruterait discrètement l'équipe principale d'Essential AI, qui inclut Ashish Vaswani, co-auteur du papier sur le Transformer et co-fondateur/PDG d'Essential AI. Au moment de la rédaction, ni Nvidia ni Essential AI n'ont officiellement répondu à ces informations.
Saisissons cette occasion pour faire un bilan complet des parcours de ces huit personnes, surnommées les « pères du Transformer », au cours des neuf dernières années, et de leurs destinations actuelles.
Il est important de préciser que l'ordre des auteurs dans le papier « Attention Is All You Need » est aléatoire. La note en bas de page le mentionne clairement : Tous les auteurs ont contribué de manière égale, l'ordre des noms est aléatoire. Il n'y a donc pas de « premier auteur » ou d'« auteur correspondant » désigné. Cet article suit l'ordre de signature original du papier pour présenter ces huit personnes.
« L'origine de tout » : huit employés de Google peu conventionnels
Pour comprendre leurs trajectoires actuelles, il faut revenir en 2017. À cette époque, l'approche dominante en traduction automatique était les réseaux de neurones récurrents (RNN). Les modèles devaient traiter les phrases mot par mot, de manière séquentielle, comme une file d'attente sur une voie unique, incapable de calculs parallèles, ce qui rendait l'entraînement lent et coûteux.
Huit personnes de Google Brain ont décidé d'essayer une idée presque téméraire : abandonner complètement la structure récurrente, ne garder que le mécanisme d'« attention », et laisser le modèle voir la phrase entière d'un coup, décidant lui-même quel mot mérite plus d'attention. Le titre du papier, « Attention Is All You Need », est un détournement de la chanson des Beatles « All You Need Is Love », et a depuis inspiré de nombreuses imitations pour des titres de papiers de recherche.

La section sur les contributions des auteurs, succincte, décrit ce que chacun a fait :

Jakob Uszkoreit a été le premier à proposer de remplacer les structures récurrentes par l'auto-attention, et a dirigé la validation précoce de cette idée ;
Ashish Vaswani, avec Illia Polosukhin, a conçu et implémenté le modèle Transformer initial, participant à presque tous les aspects du projet ;
Noam Shazeer a proposé l'attention à produit scalaire réduit (scaled dot-product attention), le mécanisme d'attention multi-têtes et la représentation de position sans paramètres, une autre personne impliquée dans presque tous les détails ;
Niki Parmar a conçu, implémenté et débogué d'innombrables variantes du modèle dans la base de code initiale et plus tard dans le framework tensor2tensor ;
Llion Jones a également testé de nombreuses variantes du modèle et s'est occupé de la base de code initiale, de l'optimisation de l'efficacité de l'inférence et de la visualisation ;
Łukasz Kaiser et Aidan N. Gomez ont passé d'innombrables nuits à construire les divers modules de tensor2tensor, remplaçant la base de code initiale et améliorant considérablement les résultats expérimentaux et l'efficacité de la recherche.
Cette description révèle indirectement un détail : bien que l'ordre des auteurs soit aléatoire, Uszkoreit, Vaswani, Polosukhin et Shazeer ont clairement assumé des rôles plus centraux au niveau de l'architecture, tandis que Parmar, Jones, Kaiser et Gomez ont porté le poids de l'implémentation et de la construction du système – une préfiguration des différences de personnalité et d'expertise qui ont orienté leurs chemins distincts par la suite.
Le nom « Transformer » lui-même a une anecdote. Uszkoreit aimait la sonorité du mot, alors l'équipe s'est surnommée « Team Transformer », et les premières conceptions documentaires arboraient une illustration des six personnages des dessins animés Transformers.
Depuis sa publication, le papier a été cité plus de 260 000 fois, l'un des articles les plus cités du 21e siècle.

Ashish Vaswani

Vaswani est né en 1986 en Inde. Il a obtenu une licence en informatique à l'Institut de technologie de Birla Mesra (BIT Mesra) en 2002, avant de partir aux États-Unis pour un doctorat à l'Université de Californie du Sud sous la direction de David Chiang, travaillant sur la traduction automatique statistique et la modélisation linguistique par réseaux de neurones. Après son doctorat, il a été informaticien à l'USC Information Sciences Institute pendant deux ans, puis a officiellement rejoint Google Brain en 2016 en tant que chercheur scientifique, y restant jusqu'en 2021.
Selon la description des contributions, Vaswani a conçu et implémenté le modèle Transformer initial avec Illia Polosukhin, l'un des acteurs centraux « impliqué dans presque tous les aspects du projet ».
Après avoir quitté Google, Vaswani a cofondé Adept AI en 2021 avec Niki Parmar, l'ancien vice-président ingénierie d'OpenAI David Luan et d'autres, en tant que Chief Scientist. L'objectif était de créer des « modèles d'action » capables d'effectuer des opérations de manière autonome dans n'importe quel logiciel.
Adept a levé plus de 400 millions de dollars, atteignant une valorisation d'environ 1 milliard de dollars, mais le produit tardait à arriver sur le marché et des divergences internes sont apparues. Vaswani et Parmar ont choisi de partir tôt – son mandat de Chief Scientist chez Adept a pris fin en novembre 2022.
Début 2023, Vaswani et Parmar se sont à nouveau associés pour fonder Essential AI, dont il est devenu PDG. La société a successivement obtenu des investissements stratégiques de Google, Nvidia et AMD : un tour d'amorçage de 8,3 millions de dollars mené par Thrive Capital, un tour A de 56,5 millions de dollars fin 2023 mené par March Capital, avec la participation de Google, Nvidia, AMD, KB Investment, Franklin Templeton, etc. Début 2026, la société a bouclé un tour B de 175 millions de dollars mené par Lightspeed Venture Partners, avec la participation de Thrive Capital, atteignant une valorisation de 1 milliard de dollars et devenant officiellement une licorne.
Fin 2025, la société a publié sa première série de modèles open source, Rnj-1 (d'après le mathématicien indien Ramanujan).
Mais ces deux derniers jours, la situation a changé. Selon des rapports, Nvidia recruterait l'équipe principale d'Essential AI, Vaswani lui-même étant inclus, pour travailler sur le développement du modèle open source de Nvidia, Nemotron.
Des sources indiquent que la raison est assez pragmatique : le financement d'Essential AI rencontre des difficultés, et attirer Vaswani et son équipe du camp du concurrent AMD (qui a été un investisseur stratégique précoce d'Essential AI, l'entreprise dépendant longtemps des GPU AMD) représente une bonne affaire. Plusieurs chercheurs d'Essential AI (dont Alok Tripathy, Saurabh Srivastava) ont déjà mis à jour leur profil LinkedIn pour indiquer qu'ils ont rejoint Nvidia. Cependant, à ce jour, ni Nvidia ni Essential AI n'ont officiellement confirmé ces informations.
Noam Shazeer

Shazeer est né en 1976 à Philadelphie, dans une famille juive orthodoxe ; son père, Dov Shazeer, était ingénieur, ancien professeur de mathématiques, et sa sœur a été ordonnée rabbin par le Hebrew College. Il a montré des talents précoces, remportant une médaille d'or avec score parfait aux Olympiades Internationales de Mathématiques en 1994 en tant que membre de l'équipe américaine. Il a ensuite étudié les mathématiques et l'informatique à l'Université Duke, bénéficiaire de la bourse Angier B. Duke Memorial, et a été lauréat du concours de mathématiques Putnam.
En 2000, Shazeer a rejoint Google, se faisant connaître tôt en corrigeant la fonction de correction orthographique de la recherche Google.
Selon la description des contributions du papier Transformer, il a proposé l'attention à produit scalaire réduit, l'attention multi-têtes et la représentation de position sans paramètres, une autre personne « impliquée dans presque tous les détails » avec Vaswani et Polosukhin.
Après avoir co-écrit le papier Transformer en 2017, lui et son collègue Daniel De Freitas ont créé le chatbot Meena, mais Google a choisi de ne pas le publier par prudence. Les deux ont quitté l'entreprise en 2021 pour fonder Character.AI, levant plus de 150 millions de dollars auprès d'a16z et d'autres, créant une application de chat de rôle-play populaire.

En août 2024, un tournant s'est produit : Google a conclu un accord de licence avec Character.AI, d'un montant rapporté d'environ 2,7 milliards de dollars, et Shazeer et De Freitas sont retournés chez Google DeepMind avec une petite équipe. Il a été nommé vice-président ingénierie, co-dirigeant le projet Gemini avec Jeff Dean et Oriol Vinyals. Détenant environ 30 à 40% des actions de Character.AI, cette transaction lui aurait rapporté personnellement entre 750 millions et 1 milliard de dollars. En 2026, il a été élu membre de l'Académie nationale d'ingénierie des États-Unis, sa carrière semblant alors à son apogée.
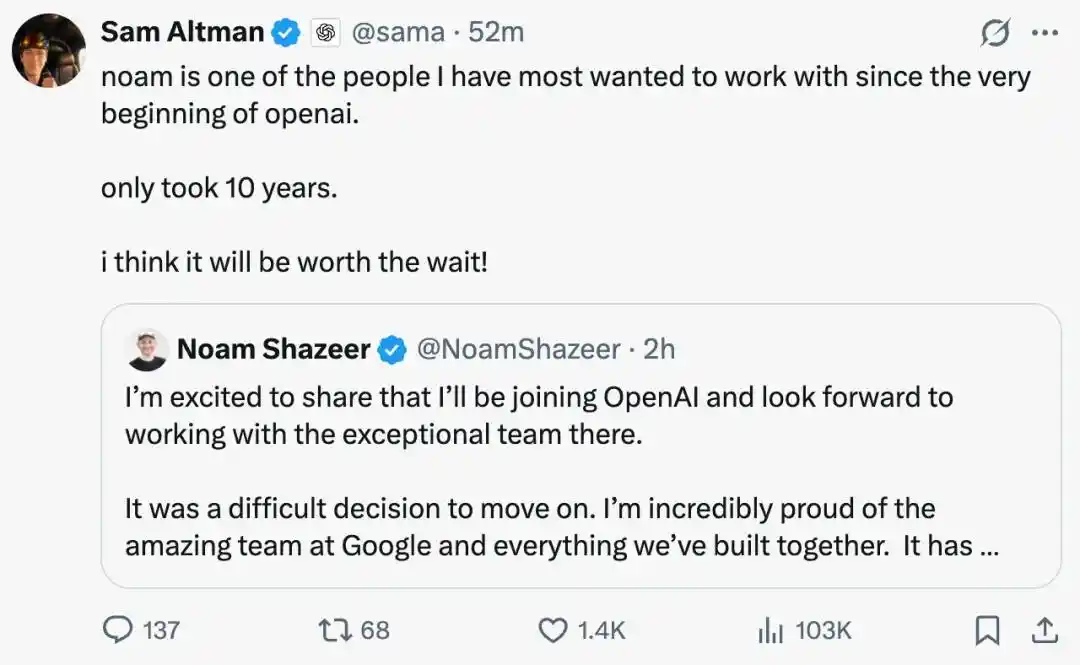
Mais seulement quelques mois plus tard, il a à nouveau choisi de partir, cette fois pour OpenAI, où il serait responsable d'une direction appelée « Architecture Research », arrivant pile pendant la période où OpenAI renforce ses troupes pour son introduction en bourse (la société a déposé confidentiellement le formulaire S-1 auprès de la SEC le 8 juin, avec une valorisation potentielle rapportée de 852 milliards de dollars).
Le PDG d'OpenAI, Sam Altman, a rarement fait une déclaration publique : « Depuis le premier jour de la fondation d'OpenAI, il a été l'une des personnes avec qui je voulais le plus collaborer », ajoutant que ce recrutement « mijotait depuis dix ans ».
Pour Google, c'est un « rachat raté » coûteux : la personne qu'ils ont ramenée il y a deux ans avec 2,7 milliards de dollars rejoint maintenant le principal concurrent, l'une des raisons directes de la chute des actions de Google cette semaine.
Niki Parmar

Parmar est née à Pune, en Inde. Elle a obtenu sa licence à l'Institut de technologie informatique de Pune (Pune Institute of Computer Technology) en technologies de l'information. Pendant ses études, elle s'est intéressée à l'intelligence artificielle et au machine learning via les cours en ligne d'Andrew Ng et Peter Norvig, puis est partie aux États-Unis pour un master en informatique à l'Université de Californie du Sud, travaillant avec le professeur Morteza Dehghani sur des problèmes de sciences sociales via le machine learning.
En 2015, Parmar a rejoint Google Research en tant qu'ingénieure logicielle, puis a intégré Google Brain en 2017 en tant qu'ingénieure logicielle de recherche – elle était alors, selon les rapports, la plus jeune et la seule chercheuse sans doctorat dans l'équipe Google Brain.
Selon la description des contributions, elle a conçu, implémenté et débogué d'innombrables variantes du modèle dans la base de code initiale et plus tard dans le framework tensor2tensor. Après la publication, elle a continué à étendre le Transformer au-delà du langage, participant à des recherches appliquant l'auto-attention à la génération d'images et à la vision par ordinateur.
En 2021, Parmar a quitté Google pour cofonder Adept AI avec Ashish Vaswani, David Luan et d'autres, en tant que Chief Technology Officer. Comme Vaswani, elle a quitté Adept tôt, et début 2023, elle a à nouveau cofondé Essential AI avec Vaswani.
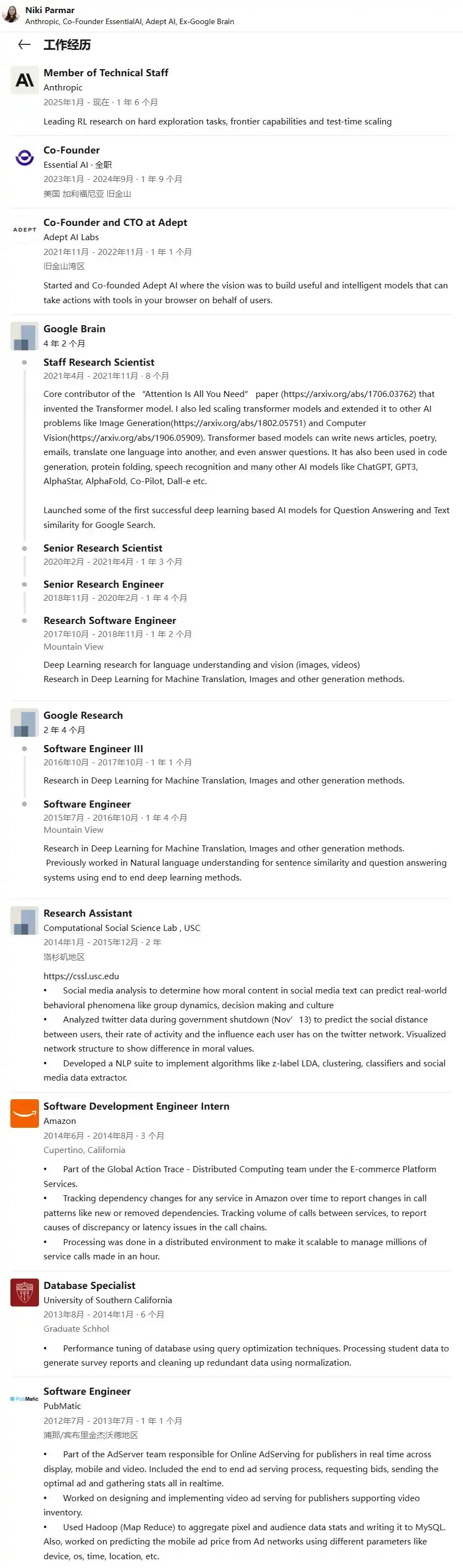
Mais elle n'a pas attendu le tour B et le statut de licorne d'Essential AI. Fin 2024, Parmar a discrètement quitté Essential AI pour rejoindre Anthropic, annonçant publiquement cette décision en février 2025. Elle a écrit sur X : « Aujourd'hui est aussi bon qu'un autre jour pour partager : j'ai rejoint Anthropic en décembre dernier. »
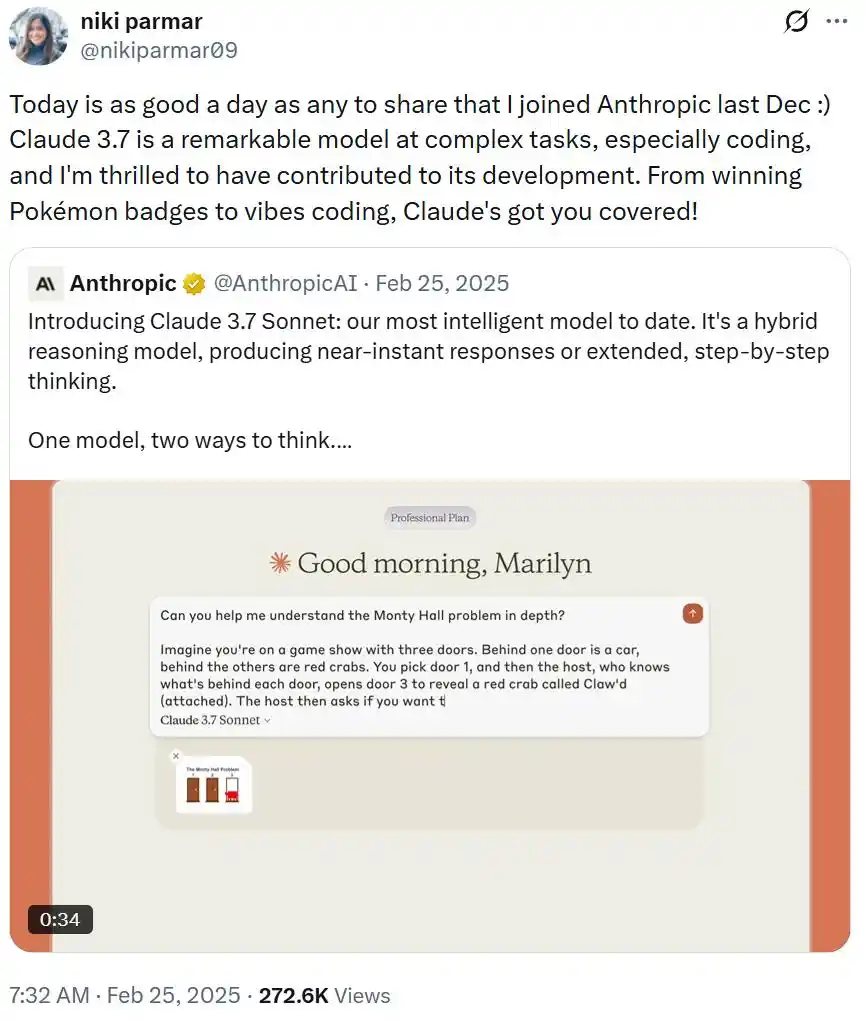
Elle a ensuite participé au développement de Claude 3.7 Sonnet – l'une des versions de modèle les plus importantes de l'histoire d'Anthropic. Elle est aujourd'hui membre de l'équipe technique (Member of Technical Staff) d'Anthropic, se concentrant sur la recherche de capacités de pointe et le reinforcement learning.
Deux co-auteurs autrefois inséparables, partenaires de deux startups, ont finalement pris des chemins très différents : Parmar s'est retirée discrètement plus d'un an à l'avance, s'intégrant tranquillement dans un laboratoire de premier plan ; tandis que Vaswani a choisi de continuer à pousser Essential AI, jusqu'à ce qu'il soit récupéré cette semaine par la main tendue d'un concurrent.
Jakob Uszkoreit

Uszkoreit est né dans une famille de linguistes. Son père, Hans Uszkoreit, est un linguiste informatique renommé. Lorsque son fils a proposé l'hypothèse que « le seul mécanisme d'attention suffisait », même son père était sceptique. Uszkoreit a obtenu son doctorat à l'Université technique de Berlin et a atteint le niveau de « Distinguished Scientist » chez Google Brain.
Selon la description des contributions, c'est Uszkoreit qui a le premier proposé de remplacer les réseaux de neurones récurrents par l'auto-attention et a dirigé la validation précoce de cette idée – les graines de cette hypothèse étaient déjà présentes dans un article de 2016 qu'il a co-écrit avec Ankur Parikh, Oscar Täckström et Dipanjan Das sur le « modèle d'attention décomposable ».

Le nom « Transformer » a également été choisi parce qu'il aimait la sonorité du mot ; l'équipe interne s'appelait « Team Transformer », et la couverture des premiers documents de conception montrait les six personnages des dessins animés Transformers.
Fin 2020, AlphaFold2 de DeepMind a prouvé que des modèles de type Transformer pouvaient résoudre des problèmes de l'ampleur du « Saint Graal de la biologie » qu'est le repliement des protéines. Il a également réalisé de plus en plus clairement que ce qui manquait à l'apprentissage profond pour vraiment transformer la biologie, ce n'était pas l'algorithme, mais les données. « C'est presque devenu une obligation morale », a-t-il rappelé plus tard.
Ainsi, en 2021, il a cofondé Inceptive avec Rhiju Das, professeur de biochimie à Stanford et créateur du célèbre jeu de conception d'ARN, Eterna. L'entreprise a son siège à Berkeley, mais l'équipe de recherche reste à Berlin – lui-même y vit, et les employés sont répartis à Zurich, Londres, Vancouver et sur la côte est des États-Unis. L'idée centrale est d'inverser l'expérimentation : ne pas entraîner le modèle sur des données existantes, mais générer massivement de nouvelles données expérimentales sur l'ARN via des robots et du travail humain, pour nourrir ensuite le modèle.
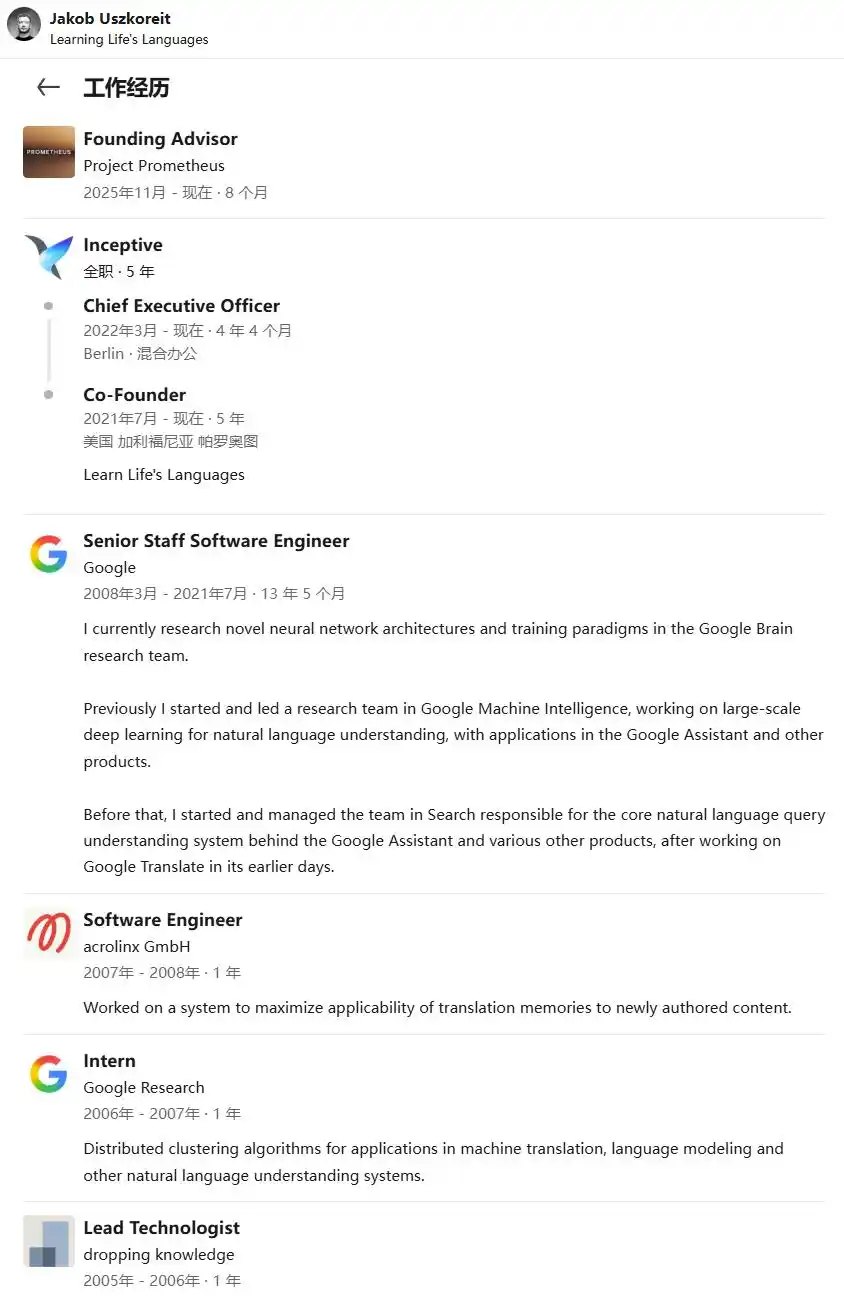
Inceptive a levé environ 120 millions de dollars auprès de Nvidia, a16z, Obvious Ventures, Section 32, etc. Les derniers développements ont eu lieu ce mois-ci : début juin, le pionnier des thérapies par interférence ARN, Alnylam Pharmaceuticals, a signé un partenariat stratégique avec Inceptive pour accélérer la conception de candidats-médicaments siRNA grâce au modèle de base d'Inceptive, avec un paiement initial de 30 millions de dollars et un montant potentiel total de l'accord d'environ 2 milliards de dollars. Uszkoreit a déclaré : « La plupart de la conception de médicaments repose encore sur des essais et erreurs – tester des milliers de molécules en espérant qu'une fonctionne. Inceptive part d'un point de vue différent : la vie suit des règles extrêmement complexes que seul l'IA peut apprendre. »
Parmi les huit auteurs, il est le seul à avoir complètement changé de voie pour se lancer dans la biotechnologie, ce qui confirme une prédiction laissée par ce papier il y a neuf ans : le potentiel du mécanisme d'attention va bien au-delà de la traduction automatique.
Llion Jones

Jones est Gallois, diplômé de l'Université de Birmingham. Il a rejoint Google en 2011 en tant qu'ingénieur logiciel, y restant plus de dix ans, l'un des rares parmi les huit auteurs à ne pas avoir de doctorat, ayant trouvé son chemin par intuition d'ingénieur.
Selon la description des contributions, il a testé de nombreuses variantes du modèle et s'est occupé de la base de code initiale, de l'optimisation de l'efficacité de l'inférence et de la visualisation.
Il s'est rappelé plus tard de ce moment décisif : « Nous commencions juste à essayer de supprimer certaines parties du modèle, juste pour voir à quel point les performances se dégraderaient. À notre surprise, elles se sont améliorées. » C'était la première validation de l'hypothèse que la « structure récurrente était superflue ».
En 2023, Jones a cofondé Sakana AI à Tokyo avec David Ha, également ancien de Google. « Sakana » signifie « poisson » en japonais. Ha est PDG, Jones est directeur de la technologie (CTO), et un autre cofondateur, Ren Ito, est directeur des opérations (COO).
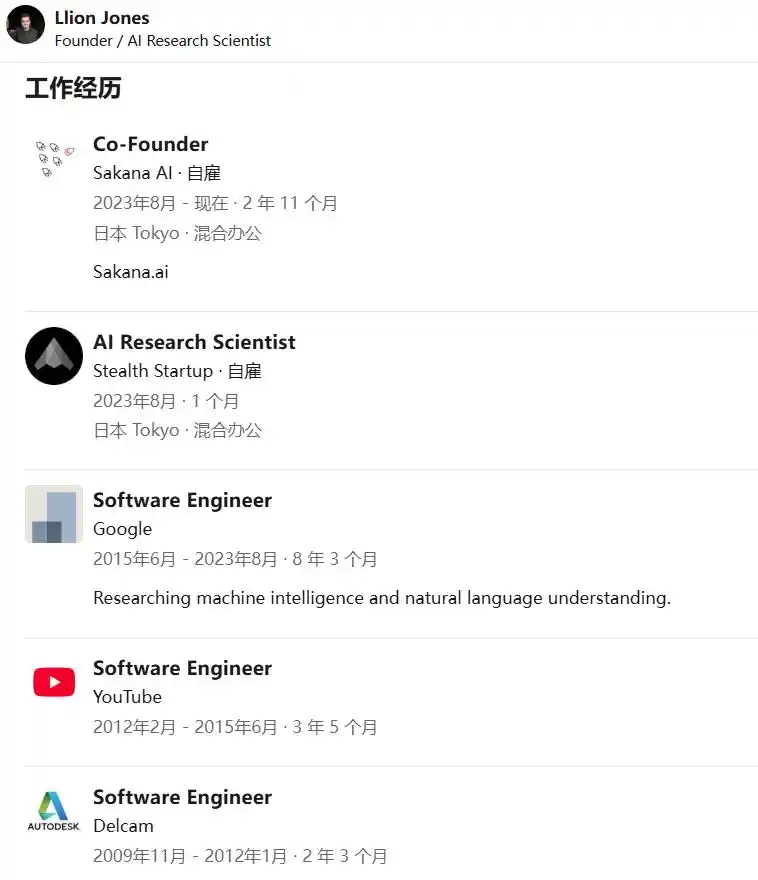
Jones réside désormais à Tokyo, se décrivant sur les réseaux sociaux comme un « chercheur en IA gallois vivant à Tokyo ». La recherche de cette entreprise a une teinte résolument contre-courant : plutôt que d'accumuler simplement de la puissance de calcul et des paramètres, elle s'inspire de la logique de l'évolution naturelle, faisant collaborer des modèles plus petits comme un banc de poissons. Ses résultats représentatifs incluent la « Continuous Thought Machine » et le projet « AI Scientist » capable de mener des recherches de bout en bout de manière autonome. Récemment, l'entreprise a publié le modèle Sakana Fugu, aux performances de pointe.
Sakana AI a levé un total de 379 millions de dollars, y compris un tour B en mars 2026. Mitsubishi Electric est également l'un de ses investisseurs. En mars 2026, l'entreprise a également conclu un accord de coopération pluriannuel avec le groupe financier Mitsubishi UFJ (MUFG). Ce dernier prévoit d'utiliser la technologie de Sakana pour transformer ses systèmes bancaires, un partenariat qui permettrait à cette entreprise valorisée à environ 1,5 milliard de dollars de devenir rentable en un an, selon les rapports.
Jones lui-même a exprimé ses doutes sur le simple « scaling » à plusieurs occasions. En mars 2026, lors d'un événement interne bancaire, il a déclaré que la recherche en IA actuelle faisait face à une réalité paradoxale : des investissements et des talents massifs affluaient, ce qui devrait en théorie générer plus de percées, mais l'effet réel pouvait être exactement inverse. Les investisseurs poussent pour des résultats, la concurrence pousse pour des lancements précoces, et l'espace pour « explorer librement » se réduit. Il a mentionné que Sakana conservait une petite part de liberté de recherche « sans KPI », car la prochaine percée viendrait forcément de ce type d'investissement à long terme sans considération de résultats immédiats – c'était précisément l'approche qui avait fait naître le Transformer dans les bureaux de Google Brain à l'époque.
Il a également prononcé une phrase souvent citée : pour qu'une nouvelle architecture remplace vraiment le Transformer, il ne suffit pas qu'elle soit « meilleure », elle doit être « nettement, indubitablement meilleure ».
Aidan N. Gomez

Gomez est le plus jeune des huit auteurs. L'année de la publication du papier, il n'était qu'un stagiaire de licence de 20 ans chez Google Brain, étudiant un double diplôme en informatique et mathématiques à l'Université de Toronto.
Selon la description des contributions, lui et Łukasz Kaiser ont passé d'innombrables nuits à construire les modules du framework tensor2tensor, remplaçant la base de code initiale et améliorant considérablement les résultats expérimentaux et l'efficacité de la recherche. « Je voulais juste comprendre comment fonctionnait le mécanisme d'attention », a-t-il rappelé plus tard, « Je n'avais aucune idée que cela deviendrait l'« architecture de tout ». » Après le papier, il est parti faire un doctorat à l'Université d'Oxford, interrompu pour créer une entreprise, obtenant finalement son doctorat en 2024 – on peut dire qu'il a complété son diplôme tout en créant son entreprise.
En 2019, Gomez a cofondé Cohere avec Ivan Zhang et Nick Frosst, positionnant l'entreprise comme un fournisseur d'IA pour les entreprises, évitant délibérément la course coûteuse aux chatbots grand public, se concentrant sur la confidentialité des données, le déploiement local et les capacités multilingues, avec des clients principalement de grandes entreprises et gouvernements. En 2023, Gomez a été sélectionné parmi les 100 personnes les plus influentes en IA par le Time, et lui et ses cofondateurs ont été en tête du classement des pionniers des tendances en IA par le magazine Maclean's la même année ; en avril 2025, il a été élu au conseil d'administration de l'entreprise de véhicules électriques Rivian.
Cette approche relativement « moins sexy » a permis à l'entreprise d'obtenir de bonnes performances financières : mi-2026, les revenus récurrents annualisés de Cohere dépassaient 200 millions de dollars, ayant été multipliés par 6 sur un an, avec une marge brute d'environ 70%, un financement cumulé proche de 1,7 milliard de dollars et une valorisation d'environ 7 milliards de dollars ; l'entreprise a engagé en août 2025 Francois Chadwick, qui avait participé à l'introduction en bourse d'Uber, comme premier directeur financieur (CFO), une fenêtre pour la vente d'actions secondaires par les employés a été ouverte, et Gomez a déclaré à plusieurs reprises que l'introduction en bourse était « proche », mais à ce jour, l'entreprise n'a pas encore déposé de prospectus auprès des régulateurs.
Ces dernières années, Gomez est de plus en plus perçu comme un porte-parole géopolitique de l'IA. Cette semaine, il a écrit dans Fortune, appelant les pays à faire face au problème de la « souveraineté numérique ». L'article mentionne directement le récent resserrement de l'accès aux modèles d'Anthropic, avertissant que les pays ne peuvent pas « louer » leur avenir à quelques géants technologiques centralisés, et propose de construire un écosystème véritablement diversifié, permettant aux pays de s'appuyer sur différents fournisseurs d'IA tout en préservant leurs propres valeurs, langues et systèmes juridiques.
Il a également déclaré publiquement que les craintes concernant les risques existentiels de type « fin du monde par l'IA » étaient exagérées, et qu'il s'inquiétait davantage des risques réels de désinformation amplifiée automatiquement sur les réseaux sociaux. Gomez ne parle plus seulement des modèles eux-mêmes, mais de qui a le droit de décider quel type d'IA le monde utilisera.
Łukasz Kaiser

Kaiser est Polonais. Sa formation académique initiale était en informatique théorique : logique, théorie des automates, théorie des modèles algorithmiques et théorie des jeux. Il a obtenu un double master en mathématiques et informatique à l'Université de Wrocław, puis un doctorat à l'Université technique de Rhénanie-Westphalie d'Aix-la-Chapelle en Allemagne. Il a ensuite occupé un poste de chercheur permanent au CNRS et à l'Université Paris Diderot (Paris 7), se concentrant sur la recherche pure en logique et théorie des automates. Plus tard, il s'est tourné vers les applications, travaillant chez Google Brain pendant près de huit ans, étant également co-auteur de TensorFlow, et ayant collaboré avec Samy Bengio sur un article précoce « La mémoire active peut-elle remplacer l'attention ? », et avec Ilya Sutskever sur un article « Neural GPU Learning Algorithm ».
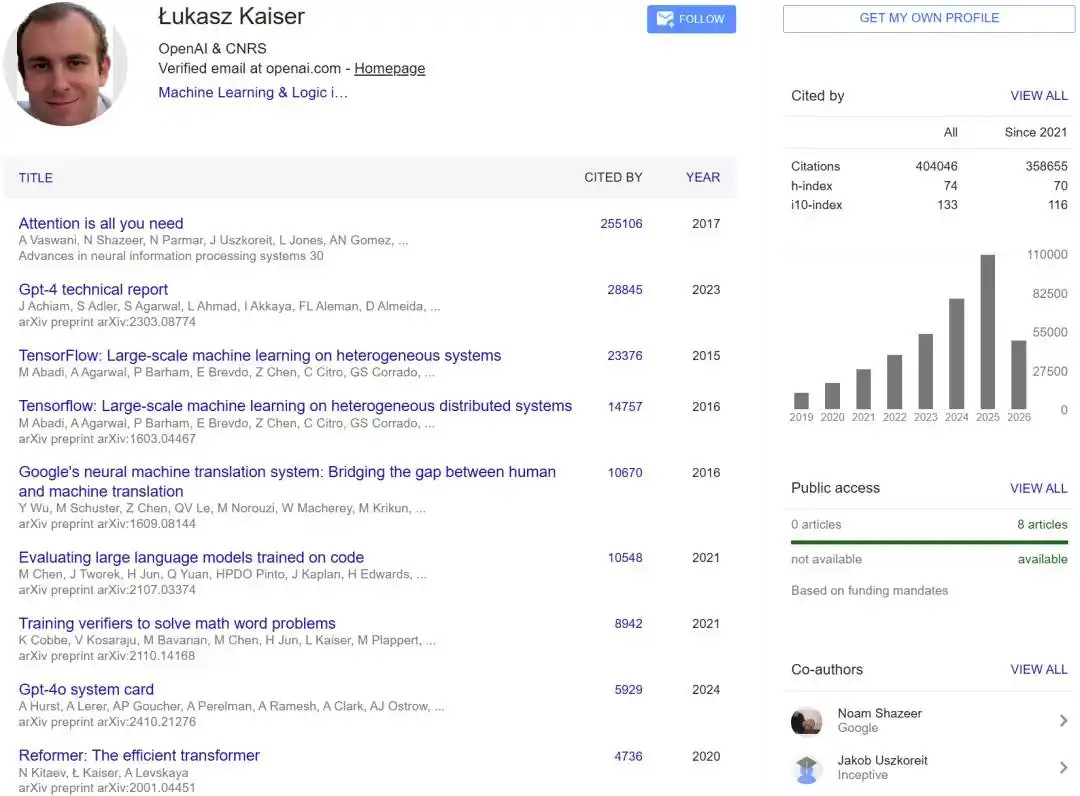
Selon la description des contributions, lui et Aidan N. Gomez ont passé d'innombrables nuits à construire le framework tensor2tensor, améliorant considérablement les résultats et l'efficacité de la recherche.
<Parmi les huit auteurs, il est le seul à ne pas avoir créé d'entreprise, restant toujours dans de grands laboratoires pour faire de la recherche pure.Il a rejoint OpenAI en 2021, avant même que ChatGPT ne sorte. Chez OpenAI, il a participé au développement de Codex (devenu la base technique de GitHub Copilot) et au benchmark de programmation HumanEval qui l'accompagnait, ainsi qu'aux recherches sur l'ensemble de données de problèmes mathématiques GSM8K. Ce travail a montré tôt que « laisser le modèle raisonner un peu plus longtemps, échantillonner plus de fois » pouvait significativement améliorer la précision – c'était l'embryon du paradigme des modèles de raisonnement (reasoning models).
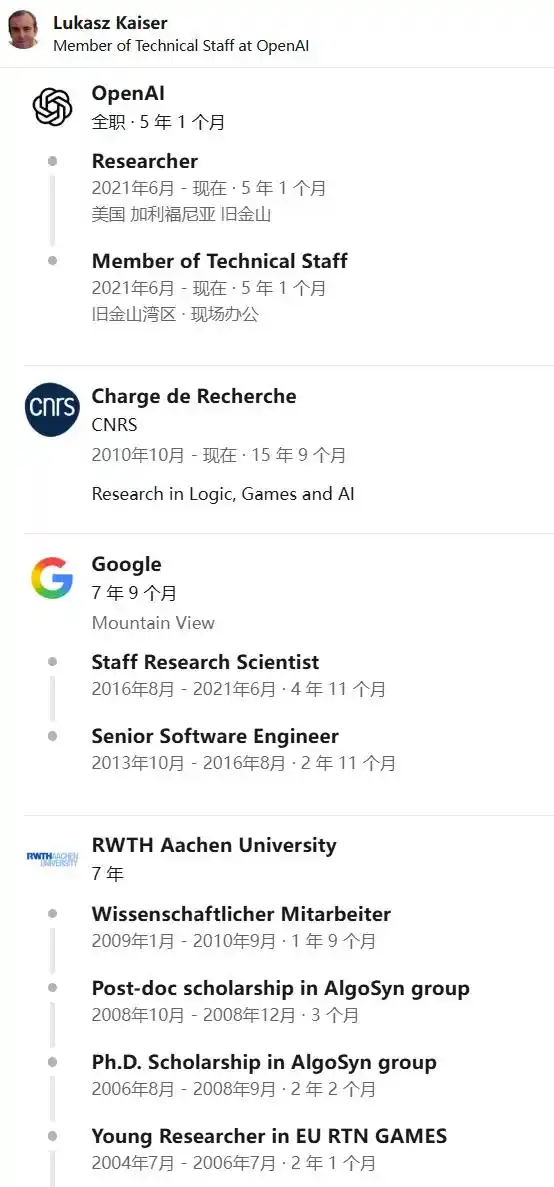
Il est également l'un des auteurs signataires du rapport technique de GPT-4, puis est devenu un contributeur clé du premier modèle de raisonnement d'OpenAI, o1 (publié en septembre 2024), considéré comme un rôle de « lead researcher », poursuivant jusqu'aux modèles o3 et aux paradigmes de raisonnement plus récents, jusqu'à la série actuelle GPT-5.
Il a récemment déclaré sur le MAD Podcast de Matt Turck que le Transformer avait été prouvé mathématiquement capable de résoudre n'importe quel problème, à condition de permettre au modèle de générer suffisamment d'étapes de raisonnement intermédiaires. D'une certaine manière, c'est une annotation tardive et plus précise de ce papier vieux de neuf ans.
Illia Polosukhin

Polosukhin est originaire de Kharkiv, en Ukraine. Il a étudié les mathématiques appliquées en licence et était également champion des compétitions internationales de programmation pour étudiants (ICPC). Selon lui, après avoir vu « Matrix » à dix ans, il a développé un intérêt quasi-obsessionnel pour l'intelligence artificielle. En 2014, il a rejoint Google, participant à des recherches liées à TensorFlow, et travaillant également sur la compréhension en lecture automatique et les systèmes de questions-réponses.
Selon la description des contributions, il a conçu et implémenté le modèle Transformer initial avec Ashish Vaswani, sa partie consistant principalement à valider l'efficacité de cette architecture sur les tâches de traduction automatique.
Après la publication, il a quitté Google en 2017 pour cofonder une entreprise d'IA initialement appelée NEAR.AI avec Alexander Skidanov. Mais ils ont rapidement réalisé que créer des infrastructures décentralisées pourrait être plus intéressant que de créer des modèles, et l'entreprise s'est transformée en projet blockchain NEAR Protocol vers 2018.
NEAR utilise une technologie de sharding appelée Nightshade et fournit un réseau de deuxième couche compatible Ethereum via Aurora. Le réseau principal a été lancé en 2020, et à ce jour, l'entreprise a levé plus de 530 millions de dollars auprès d'a16z, Coinbase, Tiger Global, Hashed, Dragonfly Capital, etc.
Polosukhin tente aujourd'hui de réunir ses deux identités initiales : en mars 2026, il a déclaré aux médias que « les futurs utilisateurs de la blockchain seront des agents IA, pas des humains », positionnant NEAR comme la « couche de règlement » de l'économie des agents. En avril de la même année, il a publiquement appelé à des cadres réglementaires plus complets pour faire face aux agents IA autonomes ; il estime que les institutions et systèmes existants ne sont pas prêts à gérer les problèmes de responsabilité et de risques systémiques posés par ces systèmes, et appelle à des mécanismes de responsabilité plus clairs et une supervision de type « humain dans la boucle ».
Il réside actuellement au Portugal. Être à la fois « l'auteur d'un papier fondateur sur les LLM » et « à la tête d'une entreprise blockchain valorisée des milliards de dollars » est une combinaison que peu de gens au monde peuvent revendiquer.
Huit chemins, l'exploration continue
En mars 2024, lors de la conférence GTC de Nvidia, sept des huit auteurs (Niki Parmar absente pour cause) sont apparus ensemble pour la première fois en tant que groupe, interviewés par Jensen Huang.

Huang a déclaré : « Tout ce dont nous jouissons aujourd'hui remonte à ce moment. »
À la fin de l'entretien, il a offert à chacun une plaque commémorative signée du supercalculateur DGX-1 de Nvidia gravée des mots « Vous avez transformé le monde (You transformed the world) ». En novembre de la même année, la Fondation NEC C&C du Japon a décerné le prix C&C de l'année à cette équipe de huit personnes, les « Transformer Team ». Ils ont partagé la scène avec trois ingénieurs seniors ayant étudié la technologie de transmission par câbles sous-marins transocéaniques. Deux types de bâtisseurs d'infrastructures fondamentales dans des domaines totalement différents, réunis dans un même prix.
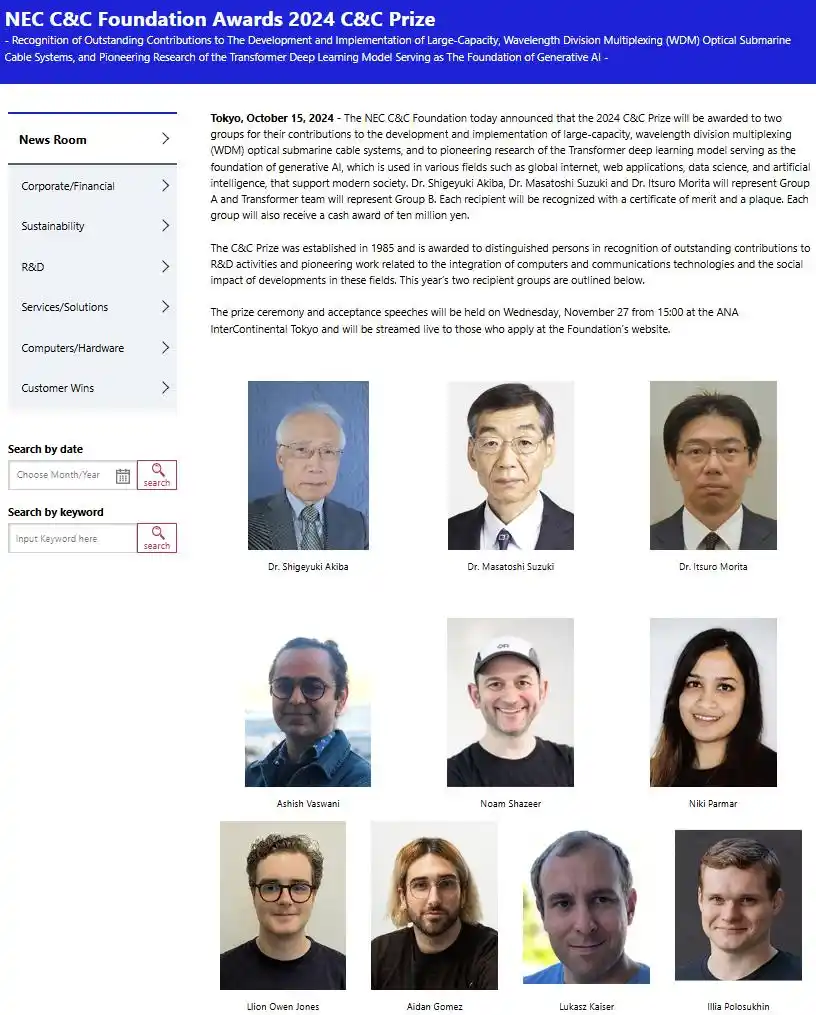
Neuf ans plus tard, ces huit trajectoires de vie se sont dispersées vers des endroits qui ne se croiseront probablement plus : le secteur des services aux entreprises de la Silicon Valley, le laboratoire d'algorithmes évolutionnaires de Tokyo, l'entreprise de biologie moléculaire de Berlin, le protocole blockchain du Portugal, et les laboratoires d'IA de pointe qui se réorganisent encore cette semaine.
Mais si l'on rassemble leurs déclarations au fil des ans, un jugement commun revient : personne ne croit vraiment que le Transformer sera le point final.
Aidan N. Gomez dit que le monde a besoin de quelque chose de mieux que le Transformer ; Llion Jones dit que la prochaine architecture doit être « nettement, indubitablement meilleure » pour le remplacer ; Łukasz Kaiser continue d'utiliser le langage mathématique pour tenter d'expliquer jusqu'où cette architecture vieille de neuf ans peut encore mener l'humanité.
C'est peut-être l'héritage le plus durable de ce papier : ses huit auteurs sont dispersés aux quatre coins du monde, mais aucun n'a cessé de chercher la réponse suivante.
Liens de référence
https://www.wired.com/story/eight-google-employees-invented-modern-ai-transformers-paper/
https://x.com/TylerMaran/status/2067772926695522454
https://www.nvidia.com/zh-tw/on-demand/session/gtc24-s63046/
Cet article provient du compte officiel WeChat « Machine Heart » (ID: almosthuman2014), auteur : Follow AI.