Auteur : Matt White, CTO mondial de l'IA, Linux Foundation
Traduction : Felix, PANews

Wang Xingxing (PDO d'Unitree) avec Matt White
Il y a quelques semaines à Shanghai, un ami avec qui je voyageais (quelqu'un d'intelligent, qui suit l'actualité et observe le monde, mais qui ne connaît pas vraiment la robotique) m'a posé, pendant le dîner, la question qui mûrissait depuis le début du voyage.
"Ces robots-chiens que l'on voit courir partout, ces robots humanoïdes qui font des démonstrations de kung-fu sur scène au bureau d'Unitree, et ces bras robotiques qui plient des vêtements. Comment font-ils ? Sont-ils pilotés par des grands modèles de langage (LLM) ? Comment cela fonctionne-t-il exactement ? Y a-t-il une sorte de modèle de langage qui contrôle leurs mouvements ?"
C'est une excellente question, et pour être franc : en un sens, oui, mais la vraie histoire est bien plus intéressante. Les robots que vous voyez sur les réseaux sociaux ne sont pas des ChatGPT dans une carrosserie métallique. Ils exécutent une pile technologique (plusieurs couches d'IA travaillant ensemble). Cette pile a plus changé au cours des trois dernières années que pendant les trente années précédentes. Les modèles de langage en font partie. Les modèles visuels, les modèles d'action, les arbres de comportement, les boucles de contrôle classiques, ainsi qu'une nouvelle famille de systèmes appelés "modèles du monde" le sont également. Et les "modèles du monde" sont peut-être le développement le plus important de tous.
Ceci est un long article. Il partira du début, puis expliquera chaque changement majeur, pour finalement arriver à l'étape actuelle : les robots peuvent non seulement réagir au monde, mais aussi l'imaginer.
I : L'ère pré-LLM : quand les robots n'étaient que des logiciels
Pendant des décennies, construire un robot signifiait écrire beaucoup de code, et presque tout ce code n'avait pas besoin d'apprendre.
Les robots industriels classiques étaient des tours soigneusement conçues de modules empilés. Pensez aux bras orange des années 90 qui soudaient les châssis Toyota, ou au BigDog de Boston Dynamics au début des années 2000.
- Perception : Filtrer les flux de caméra, détecter les contours, utiliser la correspondance géométrique pour identifier la position des pièces.
- Estimation d'état : Combiner codeurs de roues, gyroscopes et accéléromètres (fusion de capteurs) pour déterminer la position et la vitesse du robot.
- Planification : Étant donné une posture cible, calculer un chemin sans collision dans une carte connue en utilisant des algorithmes comme A* ou RRT.
- Contrôle : Au niveau le plus bas, les contrôleurs PID ajustent le couple des moteurs des centaines ou milliers de fois par seconde pour suivre ce chemin.
Ces couches étaient généralement écrites par différentes personnes dans différents laboratoires, puis minutieusement assemblées. Les comportements (par exemple "si la tasse est rouge, la saisir, sinon attendre") étaient codés sous forme de machines à états ou d'arbres de comportement : des organigrammes que le robot exécutait étape par étape.
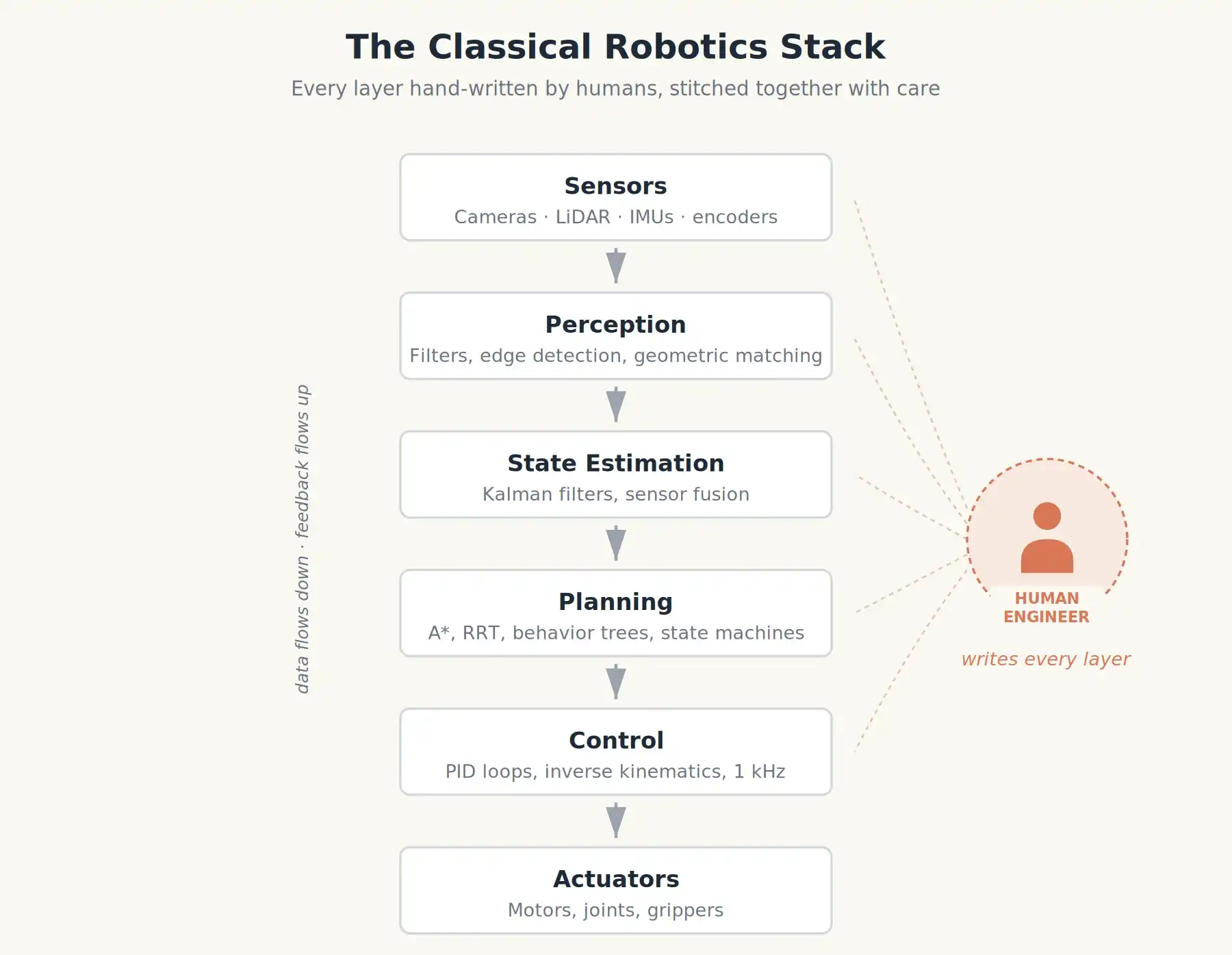
Les avantages de cette approche sont évidents. Elle est prévisible, conforme aux normes de sécurité. C'est pourquoi votre voiture a un système ABS efficace.
Les inconvénients sont tout aussi évidents. Un tel robot n'était intelligent que dans les scénarios imaginés par l'ingénieur. Placez-le dans une nouvelle usine, sous un nouvel éclairage, ou avec une nouvelle couleur de tasse, et il échouait. Sa capacité de généralisation était quasi nulle.
II : L'apprentissage automatique s'immisce discrètement
Dans les années 2010, l'apprentissage profond a commencé à s'attaquer à la couche de perception. Les réseaux de neurones convolutifs (CNN) qui battaient les humains au classement d'images ImageNet pouvaient être recyclés pour détecter des points de préhension sur des objets, segmenter des meubles dans une pièce, ou reconnaître la posture d'une personne. Soudain, la couche "Perception" en haut de la pile n'avait plus besoin d'être conçue à la main, on pouvait simplement l'entraîner.
Puis, l'apprentissage s'est propagé à la couche de "Contrôle". Des chercheurs de Berkeley, DeepMind et OpenAI ont montré que l'apprentissage par renforcement (laisser un agent robotique essayer des millions de fois dans une simulation et renforcer les comportements efficaces) pouvait produire des démarches étonnamment habiles, des manipulations d'objets à la main (le cube Rubik's résolu à une main par OpenAI en 2019 a été une étape importante), et des stratégies de locomotion adaptées à différents terrains.
Un autre axe de recherche parallèle était l'apprentissage par imitation, souvent appelé clonage comportemental : enregistrer des centaines d'essais où un humain télé-opère un robot pour accomplir une tâche, puis entraîner un réseau de neurones à prédire quelle action l'humain prendrait compte tenu de ce que le robot a observé.
Le point clé dans tout cela : chaque politique apprise était trop étroite. Entraînez un réseau à ramasser un cube rouge, il ne sait pas quoi faire d'une tasse jaune. Entraînez-le à marcher sur de l'herbe, il chute sur du carrelage. La généralisation restait le grand problème non résolu.
Notons qu'une infrastructure de base est apparue à cette époque et soutient encore aujourd'hui presque tout : ROS, le système d'exploitation pour robots (première version en novembre 2007). ROS n'est pas un système d'exploitation au sens de Windows ou Linux, mais un cadre middleware, un système de pipeline générique pour robots. Il permet aux "nœuds caméra", "nœuds de navigation", "nœuds contrôleurs de bras robotique" et des dizaines d'autres de publier et s'abonner à des messages via un bus partagé.
La version actuelle, ROS2, fonctionne en sous-couche de la grande majorité des robots de recherche et commerciaux dans le monde, des laboratoires de Stanford aux startups chinoises de robots humanoïdes. Lorsque les gens parlent du "système d'exploitation" d'un robot, ils font presque toujours référence à ROS2 plus les différents paquets logiciels de perception, planification et contrôle qui tournent dessus.
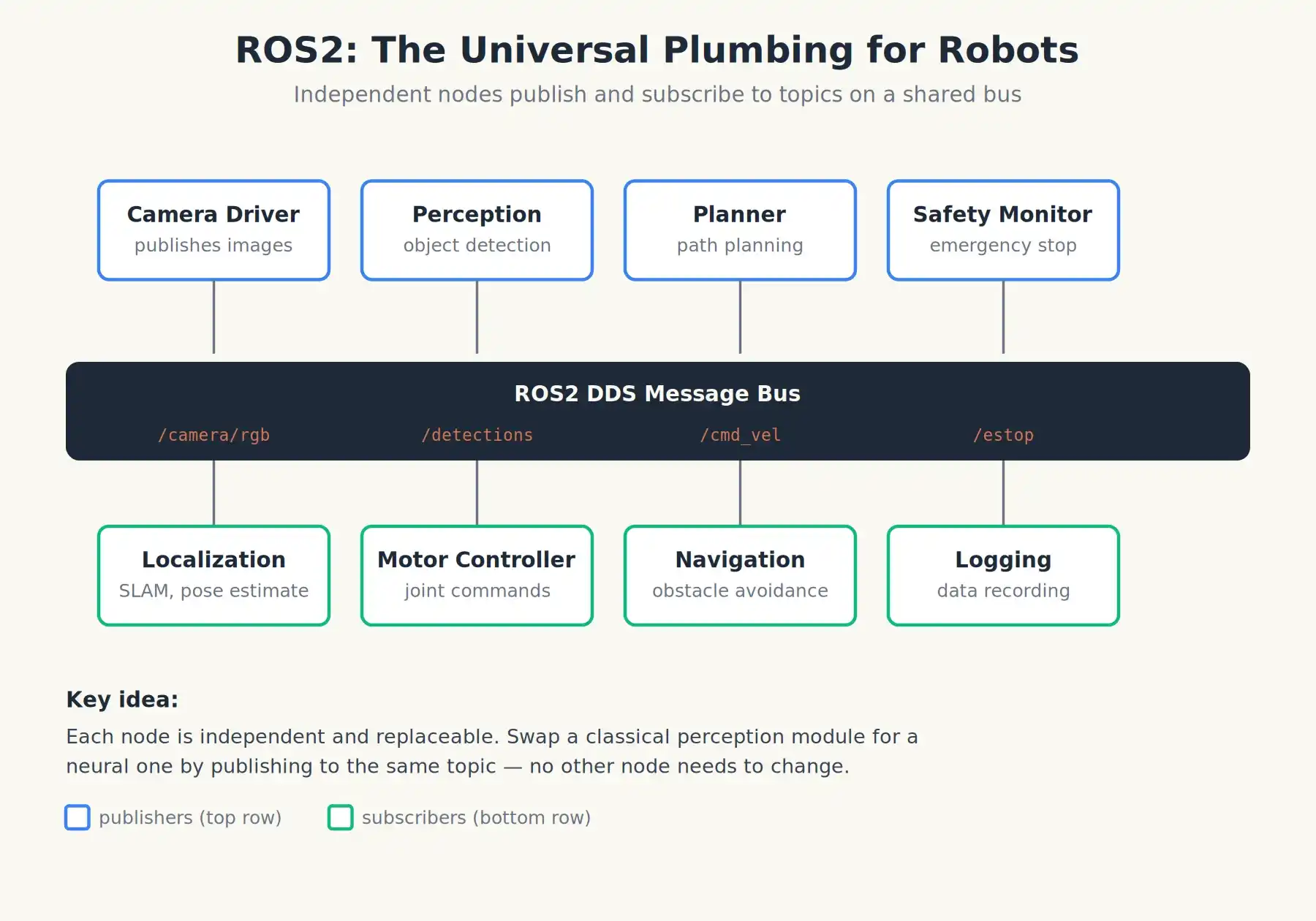
ROS2 : ce n'est pas un système d'exploitation, mais le pipeline universel permettant aux logiciels robotiques indépendants de communiquer entre eux
III : Les LLM arrivent dans la robotique
Puis ChatGPT est arrivé.
Soudain, il y avait cette chose : le LLM. Il pouvait lire des instructions simples en anglais, faire un raisonnement en plusieurs étapes, écrire du code et appeler des fonctions. Les roboticiennes et roboticiens ont presque immédiatement réalisé que c'était la pièce manquante qu'ils essayaient de résoudre depuis des années. Le plus difficile pour qu'un robot accomplisse des tâches utiles dans une maison ou un bureau, ce n'était généralement pas le contrôle des moteurs, mais l'interaction : comment l'humain dit au robot quoi faire, et comment le robot décompose cet objectif en actions atomiques qu'il sait déjà exécuter ?
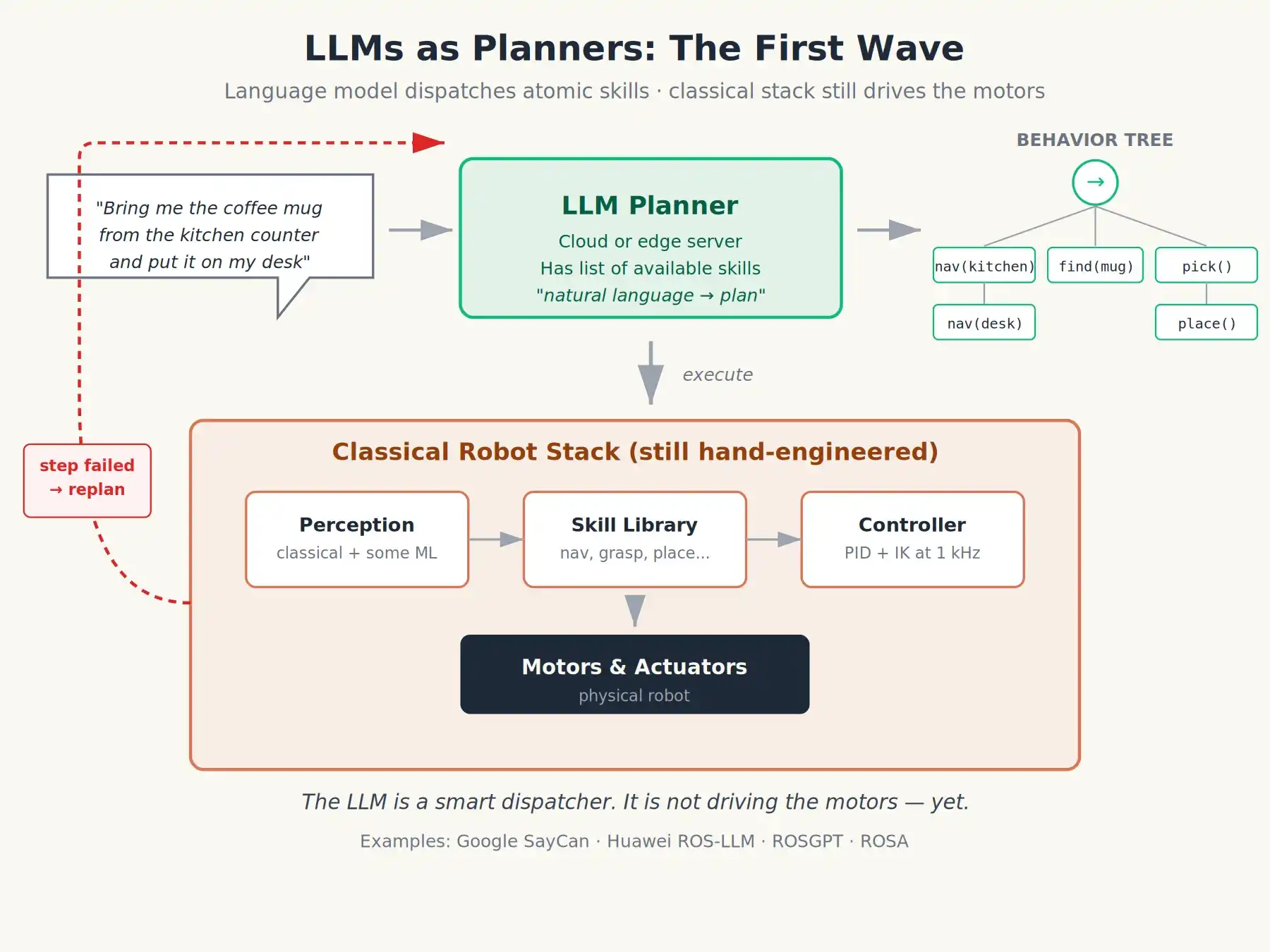
La première vague de travaux appliquant les LLM aux robots consistait à considérer le modèle de langage comme un compilateur en langage naturel s'exécutant au-dessus de ROS. Le schéma était le suivant :
-
L'utilisateur dit en anglais : "Apporte-moi la tasse de café sur le plan de travail et pose-la sur mon bureau."
-
Le LLM génère un plan basé sur la liste des compétences atomiques disponibles pour le robot : cela peut être une séquence d'appels de fonctions, une machine à états, ou un arbre de comportement écrit en XML.
-
Les nœuds ROS2 exécutent ce plan étape par étape. Si une étape échoue, l'échec est signalé au LLM pour qu'il puisse replanifier.
Le projet SayCan de Google en 2022 était une version très élégante de cette idée : le LLM propose des compétences, un modèle "d'affordance" indépendant évalue la probabilité de succès actuelle de chaque compétence, et le robot choisit la combinaison avec le score combiné le plus élevé. Des cadres ouverts comme ROS-LLM, ROSGPT et ROSA (menés par le laboratoire de recherche de Huawei) ont popularisé ce schéma.
C'était effectivement un bond en avant significatif. Soudain, vous pouviez dire au robot "nettoie la table, mets les recyclables dans la poubelle bleue", et il essayait une séquence d'actions raisonnable. Mais remarquez ceci : le modèle de langage reste encore au niveau de la planification. Les commandes d'action réelles sont toujours générées par les contrôleurs sous-jacents, soigneusement conçus ou entraînés de manière spécialisée. Le modèle de langage n'est qu'un planificateur intelligent, il ne conduit pas.
IV : Les modèles Vision-Langage-Action (VLA), quand le cerveau commence à piloter le robot

Le robot Keenon XMAN-R1 prélève des médicaments sur des étagères dans la pharmacie automatisée de Galbot à Pékin. Pour seulement 100 000 dollars.
Le prochain bond a été plus difficile et plus important. Les chercheurs se sont posé une question plus ambitieuse : Et si le modèle pouvait non seulement planifier, mais aussi générer directement les commandes d'action ? Et si on mettait directement l'image de la caméra et l'instruction langagière dans un réseau de neurones, et qu'on obtenait le mouvement des articulations pour la milliseconde suivante ?
C'est cela, le modèle Vision-Langage-Action (VLA). C'est aujourd'hui le paradigme dominant dans le domaine des robots humanoïdes et quadrupèdes.
Le premier robot visio-langagier largement connu a été RT-2 de Google DeepMind en 2023. L'astuce était : utiliser un grand modèle visio-langagier (déjà entraîné pour décrire des images et répondre à des questions), et continuer à l'entraîner avec des données de démonstration robotiques, mais en traitant les actions du robot comme un autre type de jeton à prédire. Le même réseau neuronal qui pouvait produire "le chat est assis sur le tapis" pouvait maintenant produire une série de jetons codant "déplace la patte avant droite de 3 cm, referme la pince, lève de 5 cm". Le raisonnement et l'action étaient dans le même modèle.
Puis, mi-2024, une équipe menée par Stanford a publié OpenVLA, un modèle VLA open source à 7 milliards de paramètres, entraîné sur le jeu de données Open X-Embodiment. Ce dernier regroupe plus d'un million de segments d'entraînement provenant de 21 laboratoires de recherche différents, couvrant 22 corps robotiques différents. C'était la première fois que quelqu'un en dehors de Google pouvait télécharger un modèle robotique généraliste et commencer à le modifier. Cela a changé le domaine du jour au lendemain.
Aujourd'hui, les VLA leaders sont peu nombreux mais évoluent rapidement :
- π0 et π0.5 de Physical Intelligence : excellente adaptation aux tâches.
- NVIDIA Isaac GR00T N1.7 : poids ouverts, licence commerciale, conçu pour les humanoïdes, c'est le modèle que la plupart des entreprises de matériel chinoises affinent actuellement avec leurs propres données.
- Helix et le plus récent Helix-02 de Figure AI : propriétaire, mais très important architecturalement.
- Genie Envisioner d'AgiBot : une plateforme basée sur un modèle du monde chinois.
- SmolVLA, NORA, ACoT-VLA, CogACT : une myriade de VLA académiques émergeant, explorant différentes directions de conception.
Comment fonctionne un VLA (sans mathématiques)
Imaginez un VLA comme fusionnant trois flux d'entrée en un seul flux de sortie.
Le premier flux de données est la vision. Une caméra RVB (parfois un capteur de profondeur ou un lidar), parfois des capteurs tactiles sur les bouts des doigts, traités par un encodeur visuel (généralement un modèle Transformer comme DINOv2 ou SigLIP) qui compresse chaque image en quelques centaines de "jetons visuels", résumant ce que le robot voit.
Le deuxième flux est le langage. Votre instruction ("passe-moi le tournevis") est convertie en jetons comme dans ChatGPT.
Ces deux flux sont concaténés et introduits dans un "tronc" Transformer (souvent un petit modèle de langage open source comme Qwen3 ou Llama). Ce tronc fait le raisonnement, combinant ce qu'il voit avec ce qu'on lui demande.
Le troisième flux : l'action, sort de l'autre côté. C'est là que les choix architecturaux divergent :
- Jetons d'action discrets : le modèle génère directement des jetons décodables en angles d'articulation ou positions de l'effecteur terminal, comme ChatGPT génère des mots. Simple, mais peut être saccadé à haute fréquence.
- Tête d'action par diffusion ou appariement de flux (flow-matching) : un petit réseau indépendant prend la sortie du tronc et débruite pour produire une trajectoire lisse de positions articulaires, comme un modèle de diffusion d'images, sauf qu'il génère du mouvement. C'est ce que fait π0, produisant des actions plus fluides et naturelles.
- Chunking d'actions : au lieu de prédire la prochaine commande unique, prédire un bloc de commandes pour la prochaine demi-seconde, lissant ainsi les saccades.
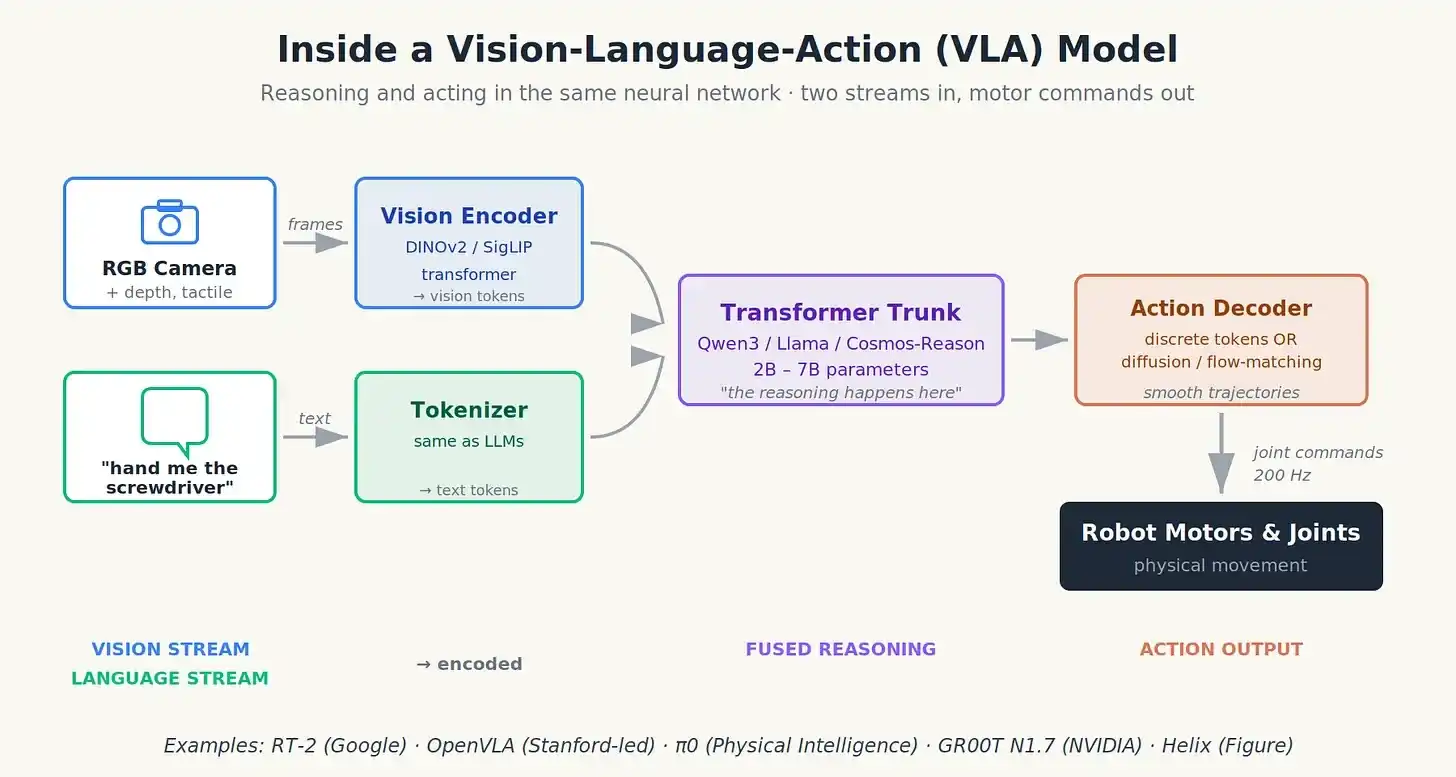
Dans un modèle VLA : deux flux d'entrée, instructions de mouvement en sortie, raisonnement et action fusionnés dans un réseau.
C'est le changement architectural crucial : le raisonnement et l'action ne sont plus séparés. Apprendre au réseau neuronal à reconnaître une tasse lui apprend aussi comment la saisir. C'est ce couplage qui permet aux VLA de généraliser là où leurs prédécesseurs ne le pouvaient pas.
V : La stratégie du double cerveau : comment LLM et VLA travaillent ensemble
Voici un détail rarement expliqué clairement dans le marketing. Les robots humanoïdes les plus performants aujourd'hui ne font pas tourner un seul système VLA, mais deux modèles à des vitesses différentes, qui se parlent. Cela est parfois appelé architecture à double système ou Système 1 / Système 2, empruntant au cadre psychologique de Daniel Kahneman qui postule que les humains ont un cerveau intuitif rapide et un cerveau réfléchi lent.
Helix de Figure AI a rendu cette conception classique, et maintenant elle (et ses variantes) est copiée presque partout. De façon particulièrement importante, le GR00T N1.7 de NVIDIA utilise ce design, et la plupart des robots humanoïdes chinois également. La structure est la suivante :
- Système 2 (S2) : le cerveau lent réfléchi. Un modèle visio-langagier à 7 milliards de paramètres, fonctionnant à environ 7–9 Hz (c'est-à-dire 7 à 9 fois par seconde). Son travail est d'observer la scène, d'analyser l'instruction, de faire un raisonnement en plusieurs étapes (par exemple, "le bol est derrière la boîte de céréales ; je dois d'abord déplacer la boîte"), et d'émettre une intention de haut niveau – généralement un ensemble de vecteurs internes compacts, pas des mots.
- Système 1 (S1) : le cerveau réactif rapide. Une politique visuo-motrice beaucoup plus petite (environ 80 millions de paramètres), fonctionnant à 200 Hz. Elle prend le vecteur d'intention du S2 plus les dernières données des capteurs, et produit des commandes articulaires continues. Elle ne "pense" pas vraiment, elle réagit.
Récemment, Helix-02 de Figure a ajouté un Système 0. Il se trouve sous le double cerveau, c'est une couche réflexe, pas une troisième couche cognitive. C'est un réseau de 10 millions de paramètres fonctionnant à 1 kHz, qui gère l'équilibre basique et la coordination corporelle, remplaçant plus de 100 000 lignes de code C++ de contrôle du mouvement écrit à la main. Vous pouvez voir le S0 comme une moelle épinière apprise : il ne raisonne ni ne planifie, il maintient juste le corps debout et coordonné, tandis que la réflexion est faite par le double cerveau au-dessus.
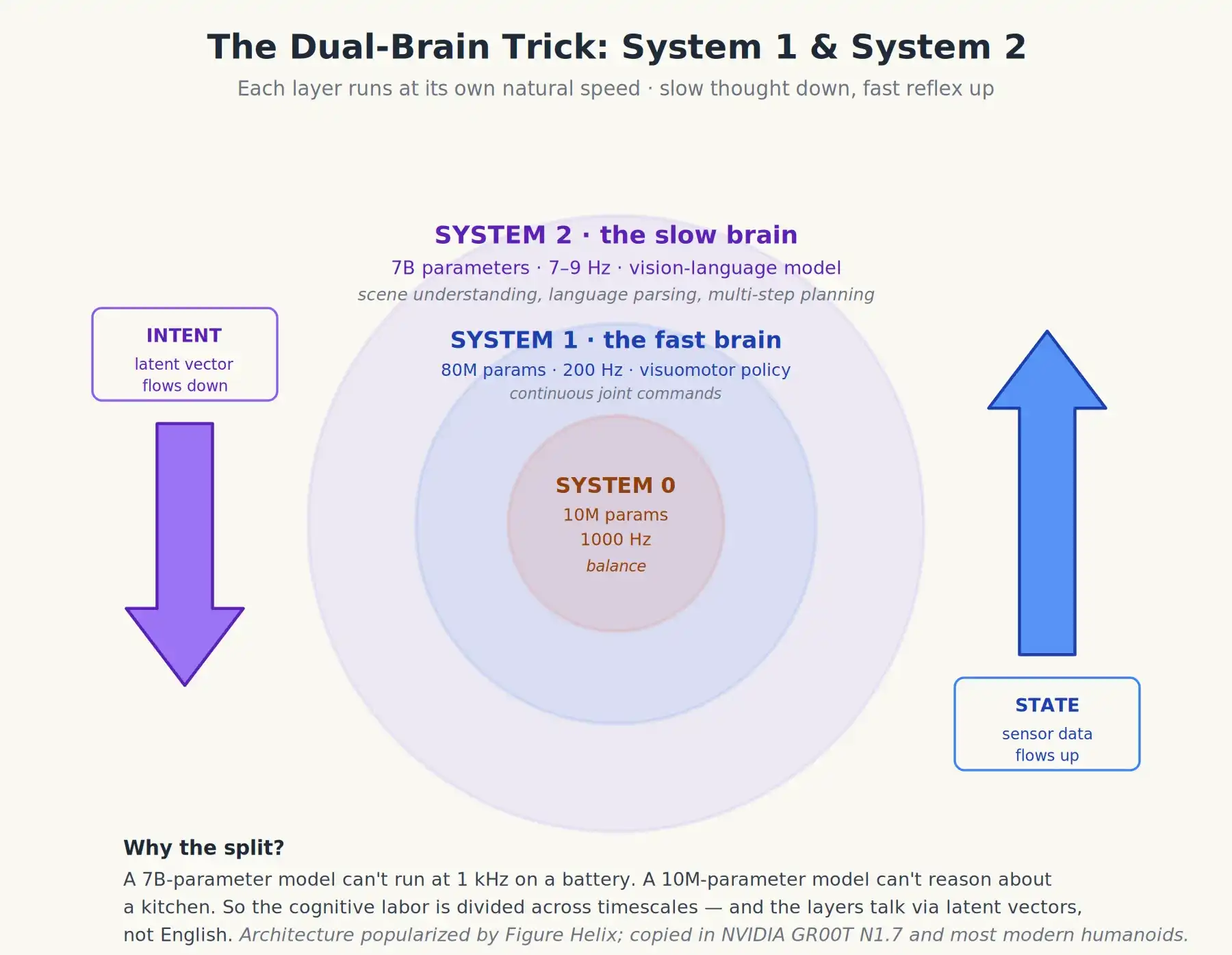
L'architecture du double cerveau d'un robot humanoïde moderne : le Système 2 pense lentement, le Système 1 réagit vite – et en dessous, un Système 0 réflexe pour l'équilibre, le contact tactile et la coordination corporelle
Cette division vient des contraintes de la physique. Si on émet une commande de mouvement seulement toutes les 200 millisecondes (la vitesse d'un grand VLA), le robot se déplace comme sous l'eau. Les commandes de mouvement doivent être mises à jour plus vite que l'oscillation naturelle des articulations qu'elles contrôlent, ce qui signifie des centaines ou milliers d'updates par seconde. Aucun Transformer à 7 milliards de paramètres ne peut tourner aussi vite sur un robot alimenté par batterie.
Ainsi, la charge cognitive est divisée : le gros modèle lent pense ; le petit modèle rapide agit. Ils ne communiquent pas en anglais, mais via des vecteurs latents appris : le modèle lent émet un objectif abstrait, et le modèle rapide sait comment l'interpréter.
VI : Le cloud, le edge computing et la question de l'emplacement du "cerveau"
Où se fait réellement tout ce calcul ?
Il y a aujourd'hui un quasi-consensus fort, presque idéologique, parmi les équipes robotiques : les boucles de contrôle critiques pour la sécurité doivent fonctionner localement. Deux raisons :
La latence. Le temps d'aller-retour en WiFi ou réseau cellulaire est de 30-80 ms même dans les meilleurs cas. Les commandes d'action ont besoin d'être mises à jour toutes les 1-5 ms. Une boucle réseau ne peut tout simplement pas fonctionner.
La fiabilité. Les robots fonctionnent dans des usines, entrepôts, cuisines, hôpitaux. Le réseau peut tomber à tout moment. Si le robot s'arrête dès que le Wi-Fi est coupé, c'est un danger.
Ainsi, la division moderne est grossièrement la suivante :
Embarqué (local), fonctionnant sur un module comme NVIDIA Jetson Thor ou AGX Thor (environ 2 000 TFLOPS, 128 Go de RAM, 40–130 W de consommation) :
- Tout S0/S1 : équilibre, locomotion, contrôle des mouvements fins.
- Le VLA lui-même (Système 2), de plus en plus quantifié en FP8 ou FP4 pour tenir dans les contraintes matérielles. Les modèles de 2 à 7 milliards de paramètres peuvent tourner sur l'appareil aujourd'hui.
- La perception, la fusion de capteurs, et tout programme de surveillance de sécurité couvrant le reste.
Cloud ou serveur distant (si présent) :
- Interface conversationnelle ("Hé robot, qu'est-ce que je devrais préparer pour le dîner ?") : celles-ci peuvent tolérer la latence.
- Apprentissage en essaim : des milliers de robots envoient des données de télé-opération à un serveur pour être agrégées dans la version suivante du modèle.
- Planification à long terme à grande échelle, peut-être avec des modèles à l'état de l'art.
- Tableau de bord et monitoring de l'opérateur.
Il y a aussi une couche intermédiaire grandissante : des serveurs edge locaux dans l'usine ou l'entrepôt, parlant au cluster de robots via un réseau local avec une latence à un chiffre de ms. Des LLM plus grands pourraient vivre à ce niveau, faisant de la planification de haut niveau que chaque robot n'a pas besoin de gérer seul.
C'est sur cette hypothèse que la vague chinoise de robots humanoïdes est construite : Unitree, AgiBot, XPeng IRON, Fourier, EngineAI. Leurs robots embarquent du calcul (souvent Jetson, parfois des puces chinoises comme Huawei Ascend), le cloud étant utilisé pour l'apprentissage en essaim et l'interface conversationnelle, pas pour la boucle de contrôle.
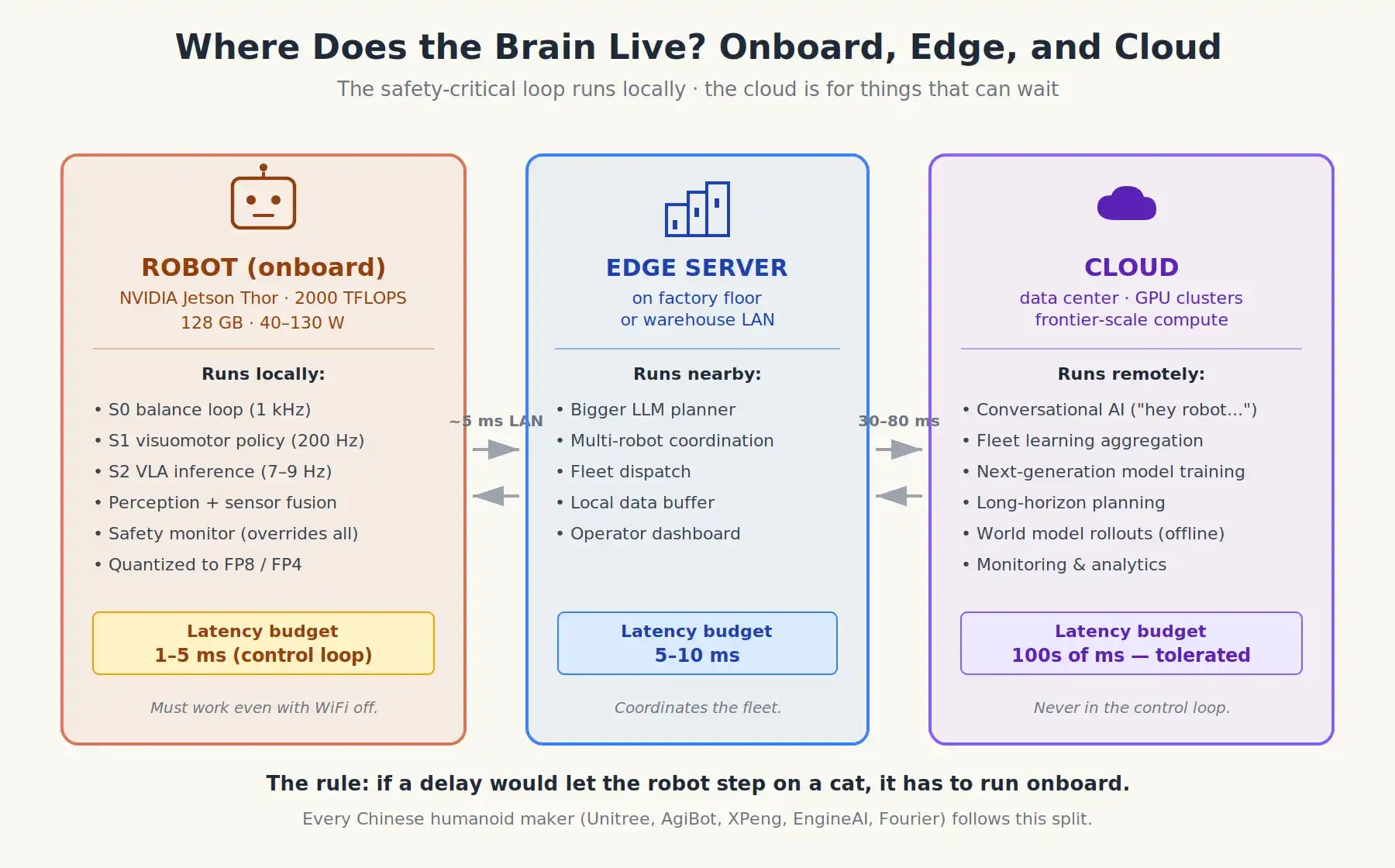
Où le cerveau du robot fonctionne réellement : les boucles critiques pour la sécurité fonctionnent localement, le cloud pour ce qui peut attendre
VII : Pourquoi les modèles open source deviennent discrètement le point central
Si vous ne regardez que les démos, vous pourriez penser que le domaine est dominé par quelques entreprises américaines bien financées. Mais la réalité est plus complexe. La vitesse de développement de l'IA physique est en grande partie déterminée par des modèles open source dont les poids peuvent être téléchargés et affinés par n'importe qui.
La liste qui suit n'est pas longue, mais significative :
- OpenVLA (Stanford) : le premier modèle robotique généraliste open source à 7B.
- NVIDIA Isaac GR00T (N1, N1.5, N1.7) : les poids ouverts sont à venir, licence commerciale à venir, formé sur des dizaines de milliers d'heures de vidéo à la première personne humaine. GR00T N1.7 est sorti en mars 2026, permettant à tout utilisateur avec un humanoïde d'utiliser son architecture à double système gratuitement.
- π0 de Physical Intelligence : poids publiés pour la recherche.
- NVIDIA Cosmos : un modèle de base du monde ouvert.
- AgiBot World : un immense jeu de données open source d'une startup de Shanghai, contenant des démonstrations de télé-opération de robots humanoïdes.
- LeRobot de Hugging Face : une librairie ouverte, devenue le point de convergence de toutes les plateformes ci-dessus.
- mimic-video de Mimic robotics : un modèle vidéo-action open source, 10 fois plus efficace en échantillons que les VLA traditionnels.
C'est important pour deux raisons. D'abord, une startup en robotique n'a pas à dépenser des dizaines de millions pour pré-entraîner un modèle de base : elle peut prendre GR00T ou π0, et l'affiner avec les données de son propre robot. C'est ce que font Unitree, EngineAI, Booster, Galbot, et des dizaines de petites entreprises chinoises. C'est pourquoi une entreprise de quelques centaines d'employés peut produire un humanoïde qui marche, parle et plie du linge : elle se tient sur les épaules d'une pile technologique open source.
Ensuite, les modèles open source sont le seul moyen réaliste de résoudre les problèmes de sécurité. Si un modèle complètement fermé fonctionne dans un robot sur un sol d'usine, sans aucune visibilité sur sa logique de raisonnement, c'est un cauchemar réglementaire. Les modèles ouverts permettent aux auditeurs, chercheurs et opérateurs d'inspecter réellement ce sur quoi le robot a été entraîné.
VIII : Quels problèmes ne sont toujours pas résolus
Si vous avez vu assez de vidéos de démonstration de robots, vous en avez aussi vu beaucoup d'échecs. La génération actuelle de robots LLM+VLA est impressionnante, mais présente clairement des limites. Voici ses problèmes :
- La récupération en cours de tâche. Les VLA sont meilleurs que toute technologie précédente pour gérer les changements inattendus. Mais quand les choses tournent vraiment mal (saisie ratée, objet qui roule, quelqu'un qui entre dans la zone de travail), retrouver le bon chemin reste un point faible. Le robot répète bêtement l'action qui a échoué.
- L'efficacité en échantillons. Former un VLA de zéro nécessite des dizaines de milliers d'heures de données de télé-opération. Un humain apprend à utiliser un nouvel outil en quelques minutes. L'écart d'efficacité est énorme.
- La généralisation inter-entités. Un modèle entraîné sur un bras Franka au labo de Stanford ne transfère pas parfaitement à un robot humanoïde Unitree dans un entrepôt de Shenzhen. Les corps sont physiquement différents.
- Les tâches longues. Tout comportement cohérent sur plus de 30-60 secondes, avec de multiples sous-objectifs, a tendance à dériver. "Prépare-moi le petit-déjeuner" reste hors de portée.
- Le bon sens physique. Les VLA sont entraînés par imitation, pas par compréhension. Ils ne comprennent pas réellement que l'eau se renverse si on heurte un verre. Ils ont juste vu des exemples et prédisent ce qui vient ensuite par correspondance de motifs.
- Le raisonnement spatial. Bien que multimodaux, ils sont étonnamment faibles pour des tâches comme "contourner l'obstacle plutôt que de passer à travers" ou "empiler ces choses sans qu'elles tombent".
Cette dernière série de faiblesses est ce qui pousse le domaine à parier sur un type de modèle radicalement différent.
IX : Les modèles du monde
Imaginons : et si au lieu d'entraîner un robot à prédire une action, on l'entraînait à prédire les conséquences d'une action ?
Un modèle du monde (World Model) est un réseau neuronal qui prédit à quoi ressemblera le monde ensuite, étant donné son état actuel (généralement une vidéo ou une séquence de trames) et une action proposée. En termes simples, voyez-le comme un prédicteur vidéo apprenant avec un volant. Vous lui donnez la dernière seconde de flux de caméra, et dites-lui "le robot bouge son bras de 10 cm vers l'avant", et il génère une vidéo réaliste prédisant la seconde suivante.
Pourquoi est-ce important ?
Parce qu'avec un modèle du monde, un robot peut penser avant d'agir. Il peut imaginer trois ou quatre actions candidates différentes, prédire leurs résultats, les noter, et choisir la meilleure. Tout cela avant que le moteur ne bouge. C'est exactement comment fonctionne un moteur d'échecs : il ne mémorise pas les coups, il simule le futur. Nous n'avons jamais eu cette capacité en robotique physique auparavant, parce que nous n'avions jamais eu de modèle assez précis pour simuler la complexité du monde réel.
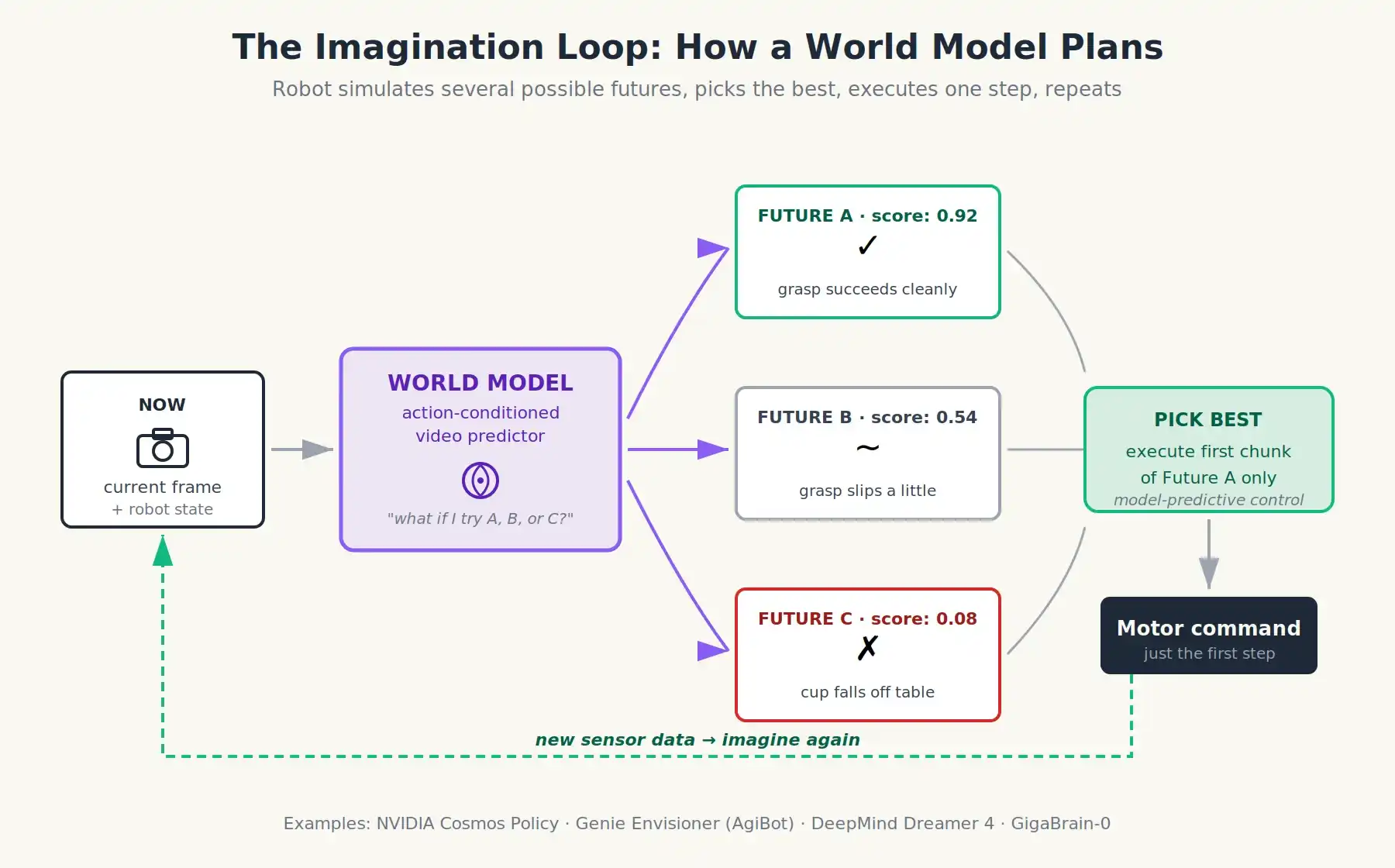
Les modèles du monde permettent aux robots de simuler plusieurs futurs possibles, de les noter, et de choisir le meilleur avant que le moindre moteur ne démarre
À quoi ressemblent les modèles du monde en 2026 ?
L'état de l'art actuel est varié mais évolue rapidement. Voici quelques modèles :
- NVIDIA Cosmos : une famille de modèles de base du monde ouvert, incluant Cosmos Predict 2.5 (génératif), Cosmos Transfer 2.5 (simulation contrôlable), Cosmos Reason 2 (raisonneur visio-langagier pour robots) et le plus récent Cosmos Policy. Cosmos Policy va plus loin en affinant un modèle du monde pour sortir directement des actions pour le contrôle. Cosmos est entraîné sur des dizaines de milliers d'heures GPU de données vidéo (Cosmos Predict 2.5 est le modèle du monde dans la famille).
- DeepMind Genie 3 : un modèle du monde interactif qui peut générer des environnements entièrement navigables à partir d'indications textuelles, à 24 ips, et rester stable pendant des minutes. Conçu initialement pour les jeux.
- Meta V-JEPA 2 : pré-entraîné sur plus d'un million d'heures de vidéos web, puis conditionné avec seulement 62 heures de vidéos robotiques. Atteint 80% de taux de succès en ramassage-dépose zero-shot sur de vrais bras robotiques dans différents labos. L'approche "JEPA" est architecturalement différente des autres.
- DeepMind Dreamer 4 : a appris à collecter des diamants dans Minecraft (une tâche de 20k pas) en utilisant uniquement des données hors ligne, sans aucune interaction avec l'environnement. Preuve qu'un vrai apprentissage par renforcement est possible dans un monde virtuel.
- Genie Envisioner d'AgiBot : une plateforme de modèle du monde unifié chinoise, entraînée sur plus de 3000 heures de vidéos de télé-opération de robots humanoïdes réels. Elle peut générer à la fois des trajectoires prédites et des trajectoires d'action exécutables. AgiBot utilise NVIDIA Cosmos Predict 2 comme tronc, affiné avec ses propres données. C'est exactement le schéma "pile open source + données propres" décrit précédemment.
- Le modèle du monde de Toyota Research basé sur Cosmos : pour l'augmentation de données de télé-opération et la navigation.
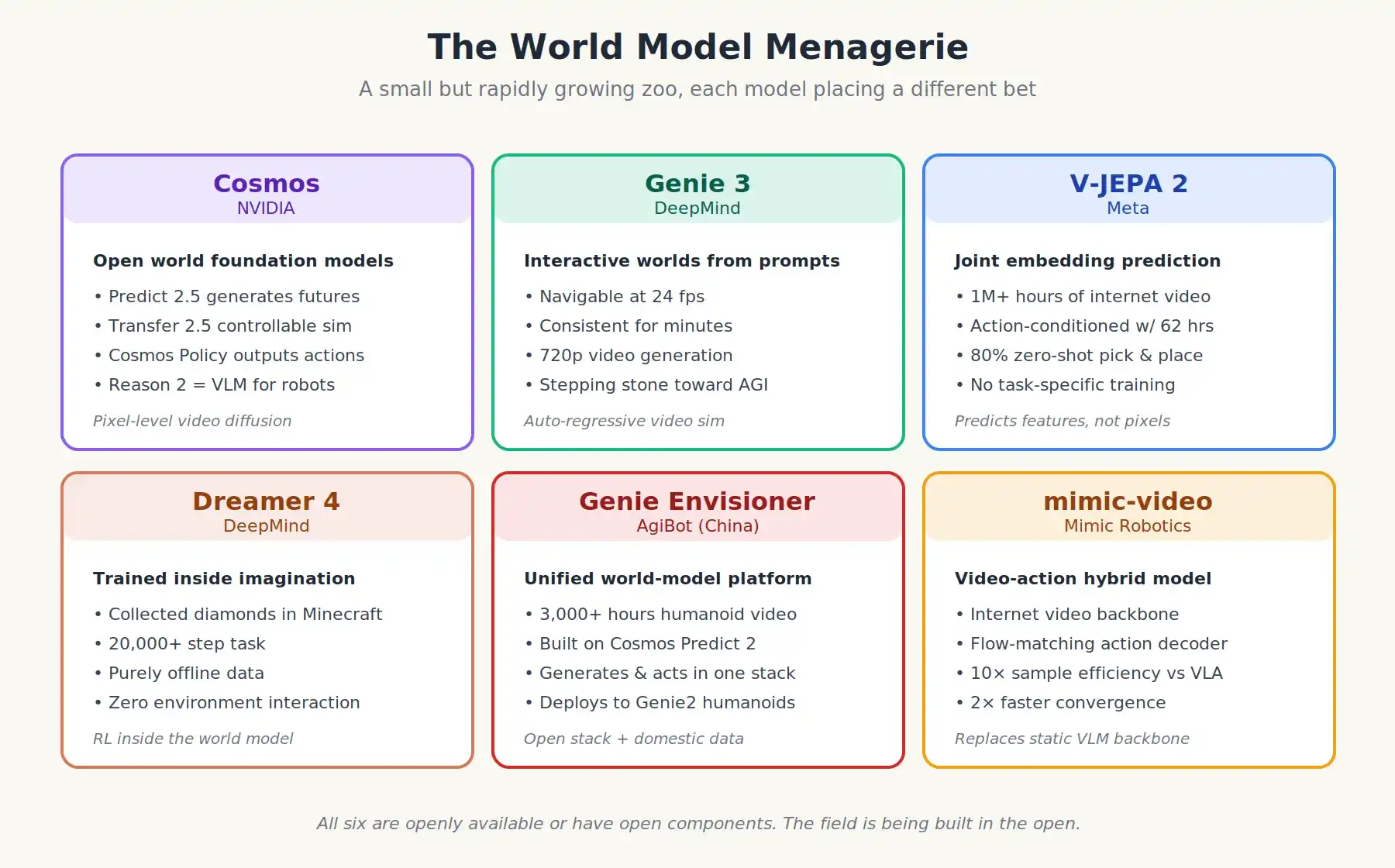
Les six modèles du monde les plus importants de 2025-2026, chacun proposant une vision différente de comment une machine devrait apprendre la physique.
X : Architectures alternatives, car le domaine n'est pas encore tranché
Il n'y a pas de manière standard de construire un modèle du monde. Le débat architectural est l'une des discussions les plus intéressantes en IA aujourd'hui, et il affecte directement ce que les robots pourront faire à l'avenir. Trois écoles méritent d'être suivies :
Diffusion vidéo au niveau pixel (école Cosmos/Sora) : Utilise un modèle de diffusion pour prédire les pixels réels des futures trames. Avantage : peut servir de générateur de données synthétiques, peut rendre de nouvelles démonstrations robotiques qui ne se sont jamais produites. Inconvénient : coûteux, parfois enfreint la physique, et prédire des pixels qu'on ne verra jamais est un gaspillage.
Architecture de prédiction d'embedding conjoint, ou JEPA (école LeCun) : Ne prédit pas les pixels, prédit l'embedding abstrait de la trame suivante. Rejette les détails texturés, ne garde que l'essence sémantique de ce qu'il y a dans la scène. Avantage : efficace, se concentre sur ce qui importe pour l'action. Inconvénient : difficile à utiliser. V-JEPA, V-JEPA 2 et de nouveaux modèles hybrides JEPA-VLA explorent cet espace.
Modèles du monde à action latente (école Genie/Dreamer) : Apprend à compresser des vidéos entières dans un "langage d'action" latent qui capture la structure du comportement, puis entraîne un modèle du monde à prédire le prochain état latent étant donné la prochaine action latente. Avantage : permet d'utiliser des vidéos web sans action pour l'entraînement, puis d'ajouter un peu de données robotiques réelles. Inconvénient : les actions latentes ne sont pas interprétables par les humains, l'analyse de sécurité devient complexe.

Diffusion de pixels, JEPA et action latente : même objectif, des façons radicalement différentes de construire un modèle du monde
XI : L'application pratique des robots basés sur un modèle du monde
Si on avance de quelques années, l'architecture d'un robot humanoïde de pointe pourrait ressembler à ceci :
Un VLA avec un modèle du monde au-dessus. Quand le robot rencontre une nouvelle situation, il exécute quelque chose comme ceci :
- Le VLA propose quelques actions candidates possibles (il reste la politique).
- Le modèle du monde prend chaque action candidate et simule 1-3 secondes de vidéo hypothétique.
- Un évaluateur de valeur note les résultats imaginés : la tasse a-t-elle été saisie ? Quelque chose est-il tombé ? Une personne a-t-elle été touchée ?
- Le robot choisit l'action avec le score le plus élevé et n'exécute que sa première partie.
- Les données réelles des capteurs reviennent ; la boucle se répète.
C'est le contrôle prédictif par modèle, une technique utilisée pendant des années pour stabiliser des fusées et des quadricoptères, mais en remplaçant les équations physiques dérivées à la main par un modèle du monde appris. Son évolutivité vient du fait que le modèle du monde est pré-entraîné sur des millions d'heures de vidéo, et non parce que quelqu'un a écrit les équations de Navier-Stokes pour une cuisine.
Les bénéfices s'empilent :
- Meilleure récupération. Si une saisie échoue, le modèle du monde peut imaginer plusieurs chemins de correction et choisir le plus prometteur.
- Meilleure généralisation. Un modèle du monde entraîné sur des vidéos web a vu plus de "phénomènes physiques" que n'importe quel jeu de données de télé-opération robotique, par plusieurs ordres de grandeur.
- Planification à long terme viable. Planifier dans l'imagination, pas dans la réalité.
- Réduction du fossé simulation-réalité. Avant, il fallait s'entraîner dans son propre simulateur (par exemple Isaac Sim, Newton Physics Engine) et espérer que cela se transfère. Maintenant, on peut s'entraîner dans un simulateur qui a appris à correspondre à de vraies vidéos. Le fossé est donc plus petit.
- Explosion des données synthétiques. Un modèle du monde peut générer des millions de trajectoires robotiques différentes, avec différents éclairages, matériaux et configurations d'objets, pratiquement gratuitement. Cela résout l'un des plus grands goulots d'étranglement du domaine.
Il a aussi un avantage de sécurité important. Un robot capable de simuler les conséquences d'une action peut refuser d'exécuter une action dangereuse : pas à cause d'une règle codée en dur, mais parce qu'il a prévu que quelqu'un pourrait être blessé dans le futur.
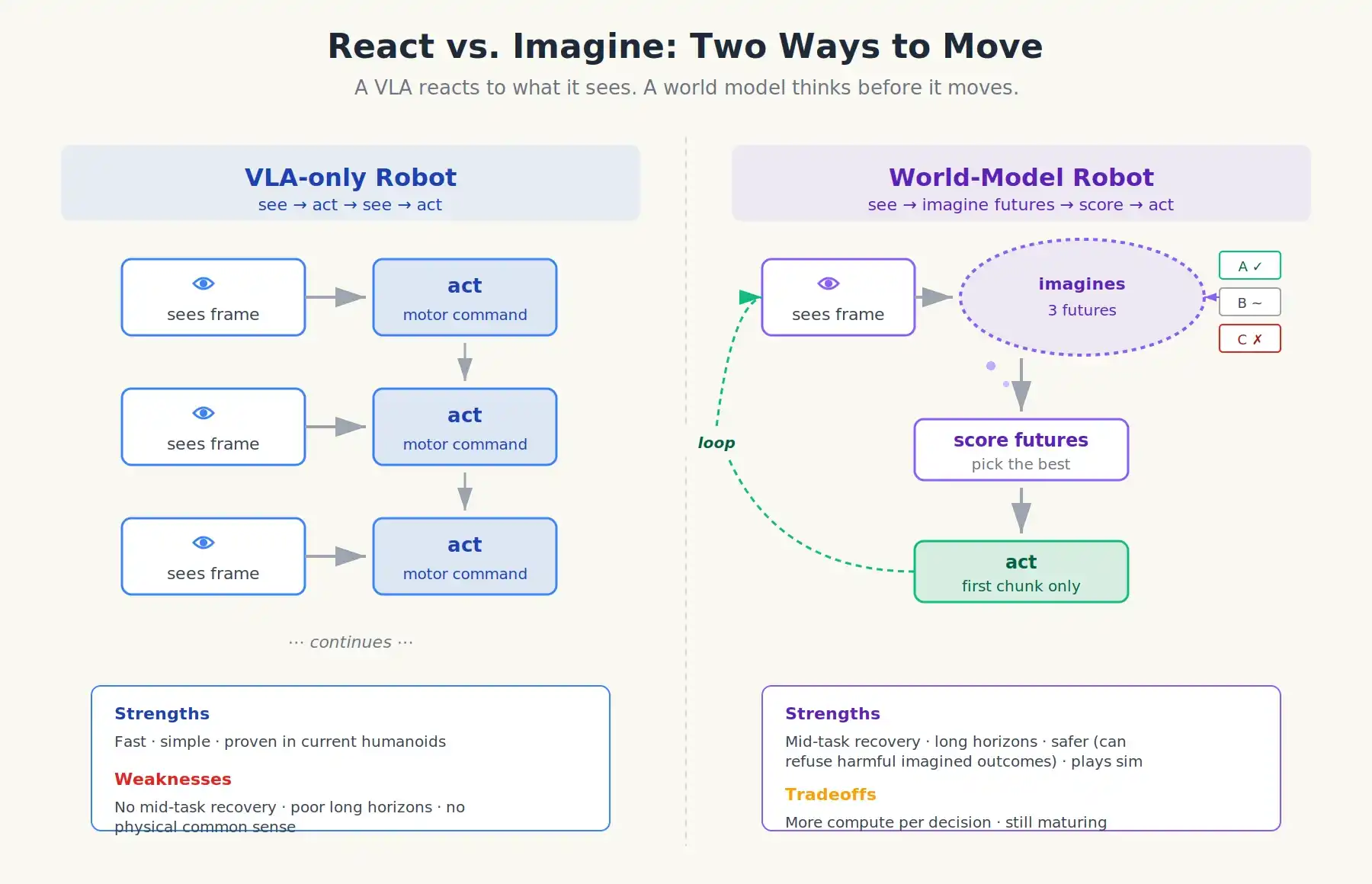
Deux façons de se déplacer : le VLA réagit à ce qu'il voit ; le robot avec modèle du monde pense avant de bouger
XII : Ce qu'il faut aussi savoir
Le problème des données est le vrai problème central : Toutes les innovations architecturales du monde ne servent à rien si vous ne pouvez pas alimenter le modèle. Actuellement, la télé-opération (un humain portant un casque VR contrôlant le robot comme une marionnette) est le principal goulot d'étranglement technique. Le fossé concurrentiel d'une entreprise robotique dépend de plus en plus de son pipeline d'acquisition de données, pas du modèle lui-même. AgiBot a construit des entrepôts remplis d'opérateurs. La loi d'échelle de dextérité du NVIDIA GR00T N1.7 montre que plus de vidéos à la première personne humaine améliore directement et prédictiblement la dextérité du robot. C'est aussi une zone où la Chine a un avantage structurel : coût de la main-d'œuvre pour la collecte de données plus faible, environnement de déploiement plus permissif, et l'État coordonnant activement la chaîne d'approvisionnement.
La simulation est un univers parallèle. Isaac Sim de NVIDIA, le nouveau moteur physique open source Newton (la version 1.0 sortira officiellement en avril 2026), et la plateforme Omniverse, permettent aux entreprises d'entraîner des robots dans des millions d'environnements simulés en parallèle sans les déployer dans le monde réel. La plupart de ce qui semble être de "l'intelligence robotique" est en fait cultivé en simulation puis transféré sur le matériel.
L'économie commence à apparaître. Unitree a livré environ 5500 robots humanoïdes en 2025 et prévoit 10k à 20k en 2026. Le prix moyen est passé de 85k à 25k USD en deux ans. L'Unitree R1 se vend 5900 USD. Le Noetix Bumi est lancé à 1400 USD. Le matériel des robots humanoïdes s'approche des prix de l'électronique grand public, tandis que l'IA à l'intérieur est encore en retard sur les démos. Cet écart va se combler, et lorsque cela arrivera, l'effet d'échelle du marché sera prononcé.
Les modes de défaillance sont étranges. Lorsque les robots basés sur des LLM échouent, ils le font souvent d'une manière que les robots traditionnels ne pouvaient pas. Par exemple, faire confiance en faisant une erreur, percevoir "hallucinatoirement" une fonctionnalité, s'enfermer dans une boucle de conversation avec son propre planificateur. Le monde de la robotique traditionnelle est assez sceptique, avec raison, insistant sur le fait que les systèmes apprenants doivent être surveillés par la sécurité et contraints par le comportement. Les robots déployés les plus fiables aujourd'hui sont hybrides : un cerveau VLA placé dans une cage de sécurité conçue à la main.
Le récit du "moment ChatGPT" est une métaphore utile mais trompeuse : Jensen Huang a dit à tout le monde que le moment ChatGPT pour les robots est arrivé. Il le dit parce que NVIDIA vend des pelles et des pioches. La version plus honnête est : Nous en sommes à peu près à l'ère GPT-2 de l'IA physique. C'est puissant, ça peut vous impressionner ; mais pas assez pour être déployé sans surveillance. Ça évolue rapidement, mais ce n'est pas encore un point d'inflexion viral, c'est une trajectoire ascendante lente et régulière.
Conclusion

L'évolution des quadrupèdes Unitree (de droite à gauche)
Dans la démonstration vue au bureau d'Unitree, cinq robots humanoïdes G1 exécutaient des arts martiaux, leurs mouvements chorégraphiés, leur contrôleur de type VLA embarqué ajustant finement, un opérateur de télé-opération s'assurant que tout se passe bien. Il n'était pas fondamentalement autonome. Mais l'ensemble du pipeline : perception, planification, contrôle du mouvement, était remplacé par des réseaux neuronaux. Deux ans plus tard, le même robot fera le même mouvement sans chorégraphie, parce qu'il aura pré-imaginé le mouvement entier et choisi la meilleure version.
Tout le développement décrit ici : des contrôleurs écrits à la main, à la perception par apprentissage automatique, au planificateur LLM, au VLA, à l'architecture à double système, et enfin au modèle du monde, est en fait un lent déplacement de l'endroit où se trouve l'intelligence robotique. Cela a commencé dans l'esprit de l'ingénieur, puis est devenu du code écrit à la main, puis est passé dans la couche de perception, dans le planificateur, dans la politique. Et maintenant, il se dirige enfin vers des modèles qui apprennent le monde lui-même.
Chaque transition a rendu les robots plus généraux, plus adaptables, plus utiles. Si la transition vers les modèles du monde fonctionne, elle donnera vraiment aux robots des capacités profondes : assez profondes pour que la question ne soit plus "Que peuvent faire les robots ?", mais "Que devrions-nous les laisser faire ?"
Lecture connexe : Un inventaire de plus de 30 entreprises de robots humanoïdes : Qui l'emportera en 2026 ?