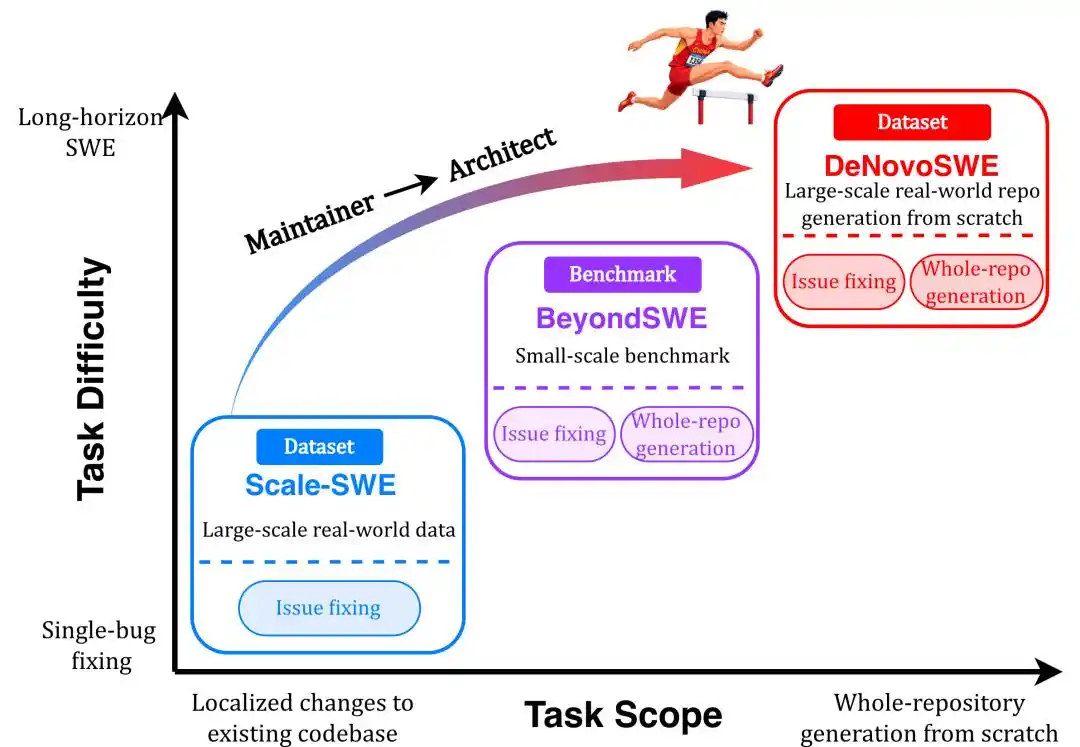
Avec l'amélioration continue des capacités des agents de code LLM, de plus en plus de chercheurs estiment qu'il est temps de passer à l'étape suivante : des tâches de longue portée plus proches des besoins réels. Ainsi, des benchmarks d'évaluation pour les tâches de longue portée ont émergé, tels que NL2RepoBench et BeyondSWE. L'attente envers le rôle des agents de code a évolué de celui de mainteneurs de dépôts vers celui d'architectes, capables de planifier et d'exécuter des tâches de longue portée pour générer des codes complets de dépôts.
Récemment, l'École d'Intelligence Artificielle Gaoling de l'Université Renmin de Chine a terminé une recherche connexe et a publié de manière significative l'ensemble de données DeNovoSWE, axé sur les tâches de génie logiciel de longue portée, en particulier les tâches de génération de code au niveau du dépôt à partir de zéro.

Lien de l'article : https://arxiv.org/pdf/2606.10728
Lien du dépôt : https://github.com/AweAI-Team/DeNovoSWE
Lien des données : https://huggingface.co/collections/AweAI-Team/denovoswe
En utilisant les mécanismes Diviser pour régner et Critiquer et réparer pour construire un ensemble de données de haute qualité, et en réussissant à mettre à l'échelle les tâches de génie logiciel de longue portée, un ensemble de données de tâches de génie logiciel de longue portée de haute qualité et ouvert, contenant 4 818 données réelles, a été construit — ce résultat fournit des données à grande échelle pour l'entraînement des capacités de longue portée des agents de code, améliorant considérablement leurs capacités pour les tâches de longue portée.
L'article propose également des méthodes de filtrage basées sur la notation de difficulté des problèmes, permettant d'atténuer efficacement le compromis entre la proportion de problèmes difficiles et la qualité des trajectoires.
Les expériences montrent que Qwen3-30B-A3B-Instruct, entraîné sur DeNovoSWE, passe de 5,8 % à 47,2 % sur BeyondSWE-Doc2Repo, et de 4,3 % à 23,0 % sur NL2RepoBench, démontrant une amélioration significative de la capacité de génération de code au niveau du dépôt grâce aux données de longue portée.
Reconstruire un dépôt entier à partir d'un document
Au cours de l'année dernière, avec la mise à l'échelle de grandes quantités de données de génie logiciel comme Scale-SWE, les agents de code ont progressé rapidement sur des tâches réelles de génie logiciel telles que SWE-bench. Cependant, alors que les modèles deviennent de plus en plus compétents pour "corriger un problème" ou "modifier quelques bugs", une question plus critique émerge : Les agents possèdent-ils réellement des capacités de génie logiciel de longue portée ? D'après les performances des modèles avancés sur BeyondSWE-Doc2Repo et NL2RepoBench, les résultats ne sont pas idéaux.
Dans le monde réel, le développement de logiciels ne consiste souvent pas à modifier une fonction ou à ajouter une condition, mais à comprendre les besoins, planifier l'architecture, créer des fichiers, concevoir des API, gérer les dépendances, connecter des modules, et finalement faire fonctionner l'ensemble du dépôt lors des tests.
En d'autres termes, la difficulté réside dans la génération au niveau du dépôt à long horizon : partir d'un document de tâche pour générer un dépôt logiciel complet, exécutable et vérifiable. C'est précisément ce que DeNovoSWE cherche à résoudre.
Documents de tâche de haute qualité pour « générer un dépôt à partir de zéro »
Dans la génération document-vers-dépôt, le document n'est pas seulement un README, ni une simple liste d'API. Il est essentiellement la seule entrée de tâche permettant à l'agent de reconstruire l'ensemble du dépôt.
Un document de tâche de haute qualité doit répondre à au moins deux critères fondamentaux.
Premièrement, il doit être bien organisé.
Les tâches au niveau du dépôt sont naturellement complexes, impliquant plusieurs modules, interfaces, configurations, structures de données et flux d'interaction. Si le document se contente d'empiler des descriptions de fonctions, l'agent peut facilement se perdre dans des informations fragmentées. Par conséquent, le document doit d'abord fournir une vue d'ensemble claire du dépôt, puis diviser les chapitres par capacités ou flux de travail, afin que chaque section corresponde à des limites fonctionnelles claires.
Deuxièmement, il doit partir d'une perspective d'évaluation fiable.
Le document ne doit pas être trop court, sinon la tâche devient un problème mal défini, forçant potentiellement le modèle à deviner sans orientation pour réussir l'évaluation ; il ne doit pas non plus être trop long, sinon il révèlerait directement des détails d'implémentation, faisant perdre tout défi à la tâche.
Un document véritablement de haute qualité devrait décrire les comportements clés sur lesquels repose l'évaluation : y compris les chemins d'import, les API publiques, les entrées/sorties, les paramètres par défaut, les comportements d'exception, les options de configuration, les chaînes de motifs, les champs de retour, etc., tout en décrivant les fonctionnalités générales à accomplir. En d'autres termes, le document doit être suffisant pour permettre à l'agent de reproduire des comportements testables, mais sans devenir une copie du code d'implémentation.
C'est aussi l'idée centrale de DeNovoSWE : rendre le document à la fois lisible, implémentable et vérifiable.
Méthode DeNovoSWE
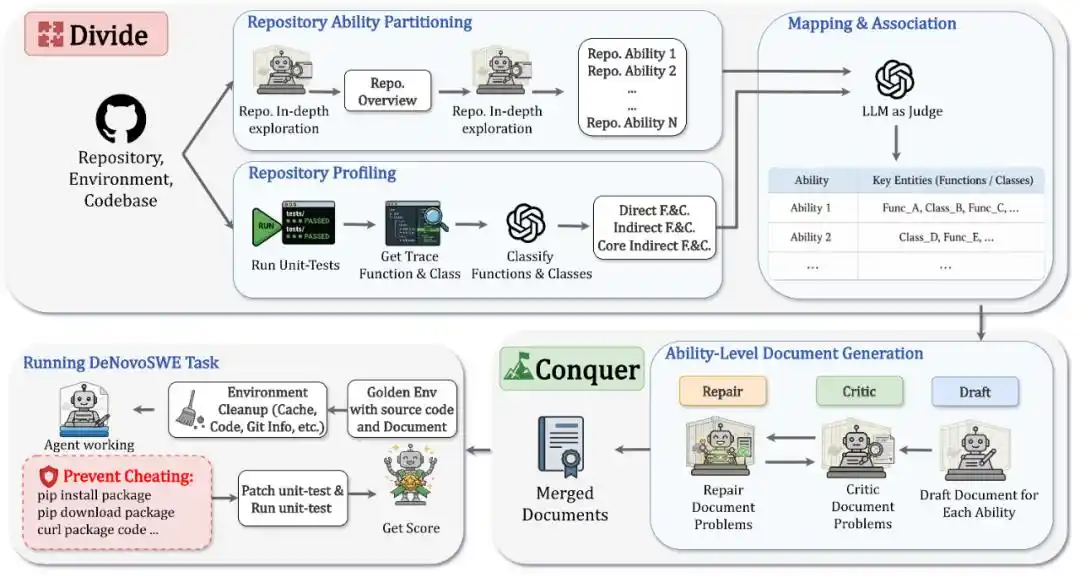
DeNovoSWE structure la "génération d'un dépôt complet à partir d'un document" en une tâche de génie logiciel de longue portée à grande échelle et vérifiable. Il ne s'agit pas d'écrire des documents manuellement, mais de construire automatiquement des instances de haute qualité via un workflow multi-agent en sandbox. L'ensemble de la méthode peut se résumer en deux étapes : Diviser et Conquérir.
Dans l'étape de division, le système analyse d'abord le dépôt cible, le décomposant en plusieurs capacités de dépôt.
Chaque capacité correspond à une fonctionnalité ou un flux de travail central dans le dépôt, par exemple l'authentification et la connexion, la lecture/écriture de données, le traitement par lots, les processus d'exportation, etc. Ainsi, le problème initialement complexe de génération de dépôt est divisé en plusieurs chapitres de document structurés clairement.
Simultanément, DeNovoSWE exécute les tests unitaires originaux et collecte les traces d'exécution pour identifier quelles fonctions, classes et interfaces affectent réellement l'évaluation, distinguant ainsi les composants directs, les composants indirects centraux et les composants indirects non centraux : les interfaces appelées directement par les tests doivent être documentées en détail ; les composants indirects centraux qui affectent le comportement observable doivent également être couverts ; tandis que les implémentations internes non centrales peuvent être laissées à la libre créativité de l'agent.
Dans l'étape de conquête, DeNovoSWE utilise un mécanisme de Brouillon-Critique-Réparation pour générer des documents capacité par capacité. L'agent Brouillon rédige d'abord une première version ; l'agent Critique vérifie si le document omet des API clés, des contrats de comportement ou des informations structurelles ; l'agent Réparation corrige ensuite le document en fonction des retours. Ce cycle s'itère jusqu'à ce que chaque chapitre de capacité soit suffisamment clair, complet et aligné sur l'évaluation.
Finalement, les documents des différentes capacités sont fusionnés en un document de tâche complet, servant de seule référence pour que l'agent génère le dépôt à partir de zéro.
Difficulté : Pourquoi s'agit-il d'une tâche de longue portée ?
La difficulté des tâches DeNovoSWE provient d'un changement fondamental : il ne s'agit plus de corriger des problèmes ponctuels, mais de générer un dépôt entier.
Dans les tâches traditionnelles de génie logiciel, l'agent fait généralement face à un dépôt existant, ne nécessitant que de localiser un bug, modifier du code local et passer les tests.
Dans DeNovoSWE, l'agent est confronté à un environnement nettoyé : le code source original et les tests sont supprimés, l'historique git est réinitialisé, et les canaux de fuite potentiels tels que les caches, les résidus de site-packages, les wheels pip, les artefacts de compilation temporaires, etc., sont également supprimés. Cela signifie que l'agent doit véritablement s'appuyer sur le document pour reconstruire l'ensemble du dépôt. Il doit planifier la structure du projet, créer des fichiers de modules, définir des interfaces publiques, implémenter des interactions inter-fichiers, gérer les dépendances et configurations, et corriger continuellement les erreurs au fil des cycles d'édition et de retours de test.
La moindre déviation dans une signature d'API, un champ de retour, un type d'exception ou un comportement par défaut peut entraîner un échec des tests. Les erreurs peuvent également s'accumuler sur le long terme : un module mal conçu au début peut affecter plusieurs fichiers et chaînes d'appel par la suite.
Pour mieux gérer les différences de difficulté entre les dépôts, DeNovoSWE propose également un filtrage des trajectoires basé sur la difficulté. En termes simples, les tâches faciles devraient exiger un taux de réussite plus élevé, tandis que les tâches difficiles ne devraient pas être entièrement éliminées simplement parce qu'elles n'atteignent pas un score parfait. DeNovoSWE définit différents seuils de filtrage pour différentes plages de difficulté, en fonction de la complexité structurelle et de l'évaluation de difficulté par un LLM, permettant ainsi un équilibre entre qualité et diversité.
Ceci est particulièrement important pour les tâches de longue portée : plus un dépôt est complexe, plus il est difficile de passer tous les tests du premier coup, mais les trajectoires difficiles, à faible score ou partiellement réussies contiennent toujours des capacités précieuses de planification et d'implémentation à long terme.
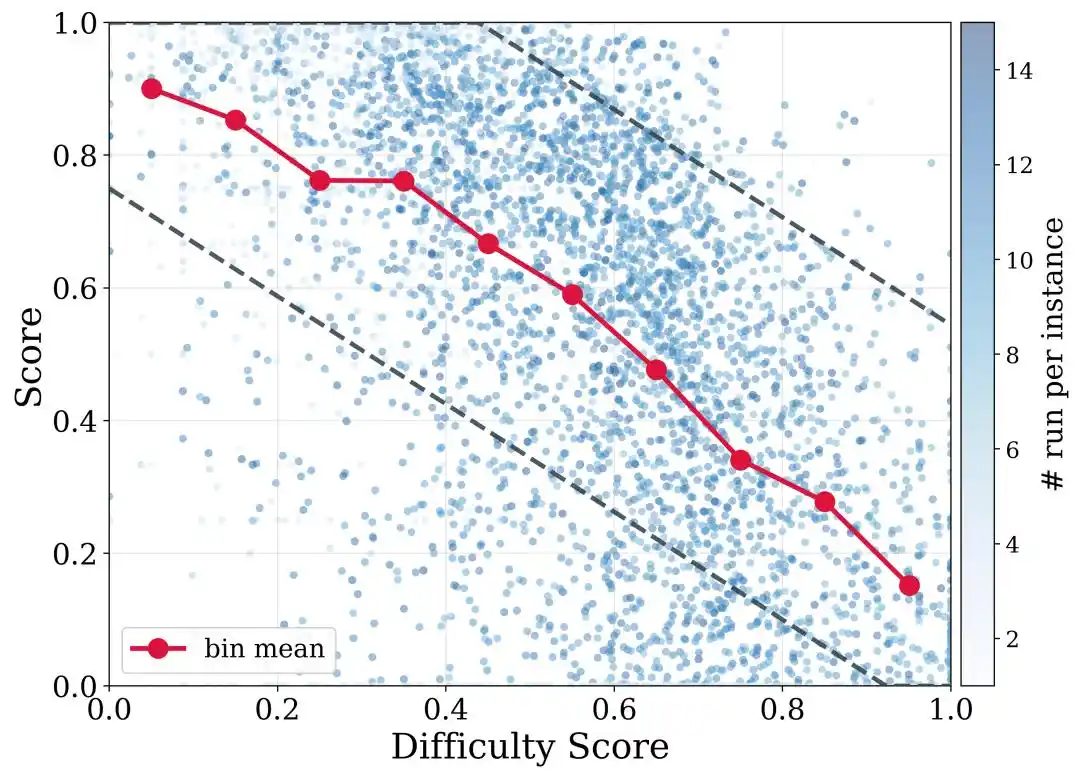
Résultats expérimentaux
DeNovoSWE a finalement construit 4818 instances de tâches document-vers-dépôt de haute qualité. C'est un environnement de génie logiciel de longue portée exécutable, évaluable et entraînable.
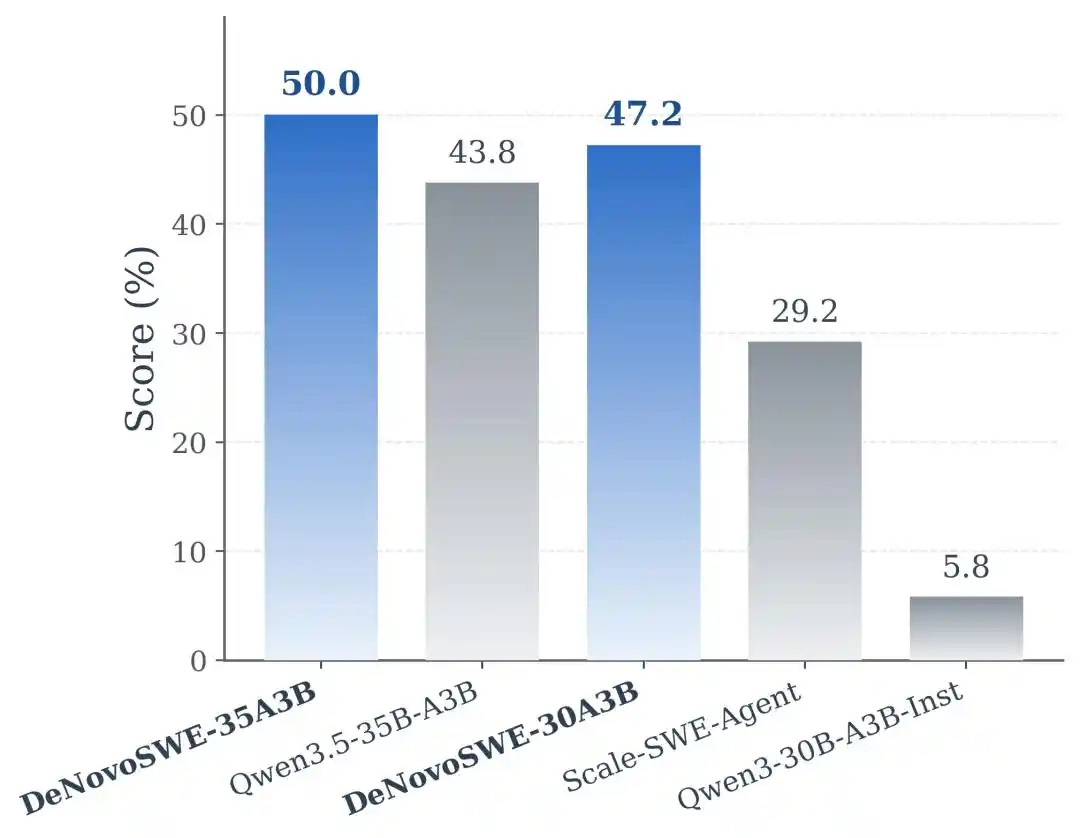
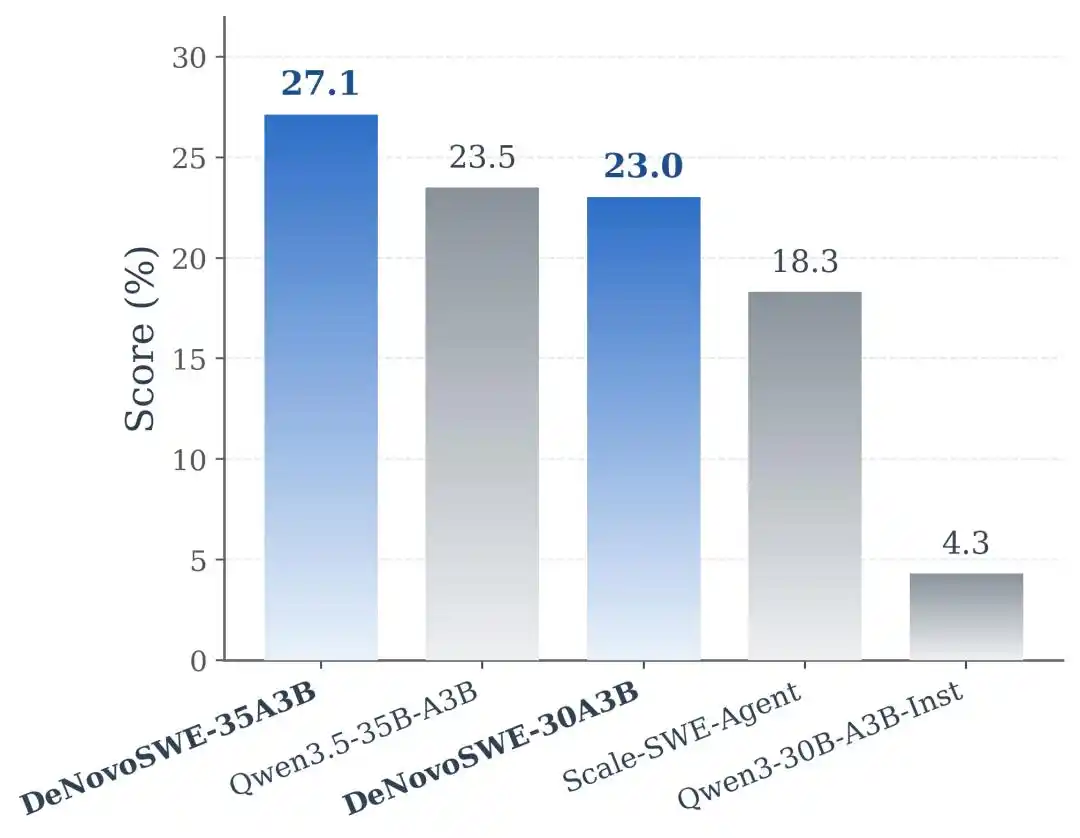
Les résultats expérimentaux montrent que DeNovoSWE apporte une amélioration significative de la capacité de génération de dépôts de longue portée des modèles. Sur Qwen3-30B-A3B-Instruct, le modèle original n'atteignait que 5,8 % sur BeyondSWE-Doc2Repo et 4,3 % sur NL2RepoBench. L'agent Scale-SWE-Agent, entraîné sur des données de génie logiciel classiques au niveau des problèmes, peut améliorer ces scores à 29,2 % et 18,3 %, indiquant que les données de génie logiciel standard ont bien un effet de transfert. Cependant, lorsque le modèle est entraîné avec DeNovoSWE, les performances montent encore à 47,2 % et 23,0 %.
Cela montre que les données axées sur la "correction de bugs" ne peuvent pas complètement remplacer les données de longue portée axées sur la "génération de dépôts complets". Pour que les agents apprennent véritablement l'ingénierie au niveau du dépôt, il est nécessaire de construire des environnements d'entraînement spécifiquement conçus pour les tâches de longue portée.
Sur l'architecture plus puissante Qwen3.5-35B-A3B, DeNovoSWE apporte également des gains stables : BeyondSWE-Doc2Repo passe de 43,8 % à 50,0 %, et NL2RepoBench de 23,5 % à 27,1 %. Cela démontre davantage que les bénéfices de DeNovoSWE ne sont pas dus à une adaptation accidentelle à un modèle particulier, mais proviennent bien des données de longue portée de haute qualité elles-mêmes.
Conclusion
La prochaine étape des agents de code ne consiste pas seulement à corriger des problèmes individuels plus rapidement, mais à pouvoir comprendre des documents, planifier des architectures, organiser des modules, implémenter des interfaces, et finalement générer un dépôt logiciel complet et fonctionnel.
DeNovoSWE a systématiquement transformé cet objectif en un ensemble de données entraînable, vérifiable et extensible. Il répond à une question clé : quelles données peuvent réellement entraîner des agents possédant des capacités de génie logiciel de longue portée ?
La réponse n'est pas plus de codes fragmentés, ni des problèmes plus simples, mais des tâches de génération de dépôts entiers de haute qualité, structurées, alignées sur l'évaluation et résistantes aux fuites.
Partir d'un document pour reconstruire un dépôt entier. C'est le seuil que les agents de code de longue portée doivent franchir.
Références : https://arxiv.org/pdf/2606.10728
Cet article provient du compte officiel WeChat "New Zhiyuan", éditeur : LRST






