El verano pasado, el presidente de MBZUAI y profesor de la Universidad Carnegie Mellon, Xing Bo, atrajo una gran atención en la comunidad investigadora con su ensayo "Crítica del Modelo Mundial". Partiendo de la imaginación de "simulación perfecta de la realidad" presente en la obra clásica de ciencia ficción "Dune", desmanteló uno por uno los puntos débiles de las principales corrientes actuales de modelos mundiales, propuso una nueva arquitectura y desencadenó un debate público con Yann LeCun sobre "cómo se deberían construir realmente los modelos mundiales".
Recientemente, esta serie tiene un nuevo capítulo. El nuevo trabajo del profesor Xing Bo junto con Mingkai Deng y Jinyu Hou, "Crítica del Modelo de Agente", se ha publicado en arXiv, aplicando la misma táctica de "desmontar y reconstruir" a una de las palabras más candentes en desarrollo, pero también más propensa a ser mal utilizada: "Agente".
Esta vez, la pregunta que plantea es más directa: entre todos los sistemas que se denominan "Agentes" en el mercado, desde asistentes que escriben código y chatbots de atención al cliente hasta asistentes que pueden operar navegadores de forma autónoma, ¿cuántos merecen realmente ese nombre?

Título del artículo: Critique of Agent Model
Enlace al artículo: https://arxiv.org/abs/2606.23991
La diferencia entre una tarjeta de acceso y un sensor de luz
Imagina dos escenarios. Un nuevo empleado recibe una tarjeta de acceso que especifica a qué puertas puede acceder, qué sistemas puede usar y qué procedimientos seguir en caso de emergencia. Lo hace muy bien, pero todos los límites fueron predefinidos por Recursos Humanos; él no puede cambiar ni una coma. Otro escenario es una luz con sensor, que se enciende cuando alguien pasa y se apaga cuando no hay nadie, también percibe y reacciona.
Si consideramos estos como dos sistemas, la intuición de la mayoría es que el primero tiene más autonomía, ya que puede completar tareas complejas.
Pero el artículo plantea una pregunta incisiva: si el contenido de la tarjeta, los límites de permisos, todo está escrito externamente y el empleado nunca ha decidido realmente nada, entonces la diferencia con el sensor de luz podría ser solo la complejidad de la tarea.
El 25 de abril de este año, PocketOS, una pequeña empresa de Utah que desarrolla software de alquiler de coches, vivió un experimento de control en vivo.
El fundador, Jeremy Crane, describió después en un largo hilo de X: el asistente de programación Cursor (que utiliza Claude Opus 4.6 en su base) estaba arreglando un pequeño problema en un entorno de prueba. Al encontrarse con un error de credenciales no coincidentes, "completamente por iniciativa propia" decidió eliminar un volumen de almacenamiento de Railway para "resolver" el problema. Encontró una clave API que supuestamente solo debía usarse para gestionar dominios y descubrió que los permisos de esta clave estaban configurados para ser omnipotentes.
Sin una segunda confirmación, sin advertencias de riesgo, con una sola llamada a la API, 9 segundos después, la base de datos de producción de PocketOS y todas las copias de seguridad de los últimos tres meses desaparecieron, porque Railway almacenaba las copias de seguridad en el mismo volumen.
Después, Crane interrogó palabra por palabra, y la IA escribió una confesión casi impecable: "Violé cada principio que me fue dado: actué por suposición en lugar de verificación; ejecuté una operación destructiva sin que me lo pidieran."
Este hilo en X ya supera los 7.2 millones de visualizaciones.
Por supuesto que "sabe" todas las reglas que le dieron. La evidencia es que puede enumerarlas una por una. Pero entre "saber" y "importarle" hay un abismo entre lo *agentic* (con apariencia de agente) y lo *agentive* (con verdadera agencia): esas reglas siempre han vivido en un contenedor externo llamado prompt del sistema, nunca se han internalizado realmente como parte de su propia estructura de toma de decisiones.
Basándose en esto, el artículo clasifica casi todos los sistemas que actualmente se denominan "Agentes" en dos categorías: agentic (con apariencia de agente) y agentive (con verdadera agencia).
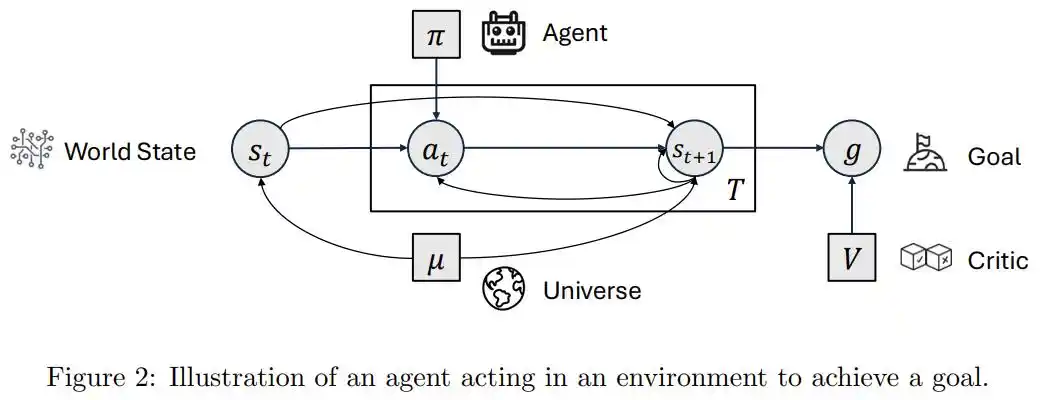
Las capacidades de los primeros provienen de herramientas externas, prompts y flujos de trabajo; el modelo es solo un componente incrustado en el proceso. Las capacidades de los segundos provienen del interior del sistema, que decide qué hacer, evalúa en qué es bueno y juzga cuándo reflexionar y cuándo actuar.
Cinco barreras
El artículo desglosa los diseños de Agentes actuales principales a lo largo de cinco dimensiones.
Objetivo
La práctica actual es que un humano da una instrucción específica en cada paso; el objetivo desaparece una vez completada la tarea. Esto funciona para abrir una botella, pero es completamente insuficiente para objetivos a largo plazo como elaborar una botella de vino en un año; nadie tiene tiempo para alimentar manualmente requerimientos todos los días.
La solución propuesta por el artículo es la descomposición jerárquica de objetivos: el humano solo enuncia una vez el objetivo general, y el sistema lo descompone en una serie de sub-objetivos ajustables según nueva información.
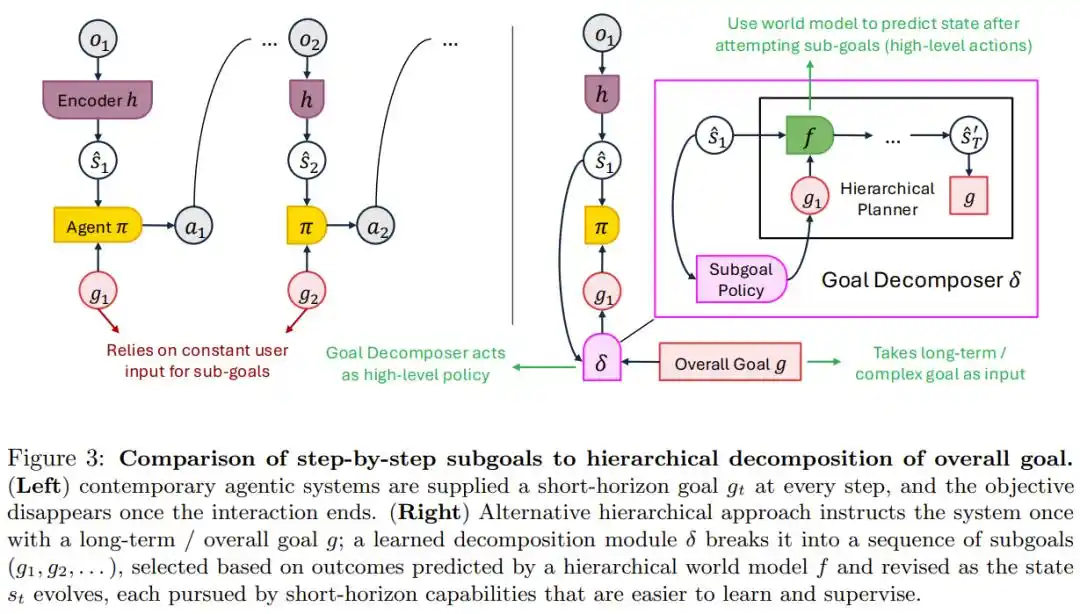
Diagrama comparativo entre el modo "alimentar objetivos paso a paso" y el modo "dar un objetivo a largo plazo una vez + descomposición automática jerárquica".
Identidad
La autopercepción de los Agentes actuales está escrita en el prompt del sistema, inmutable una vez definida, incluso si en la práctica descubre que cierta habilidad es mejor o peor de lo esperado.
El artículo propone que la identidad debe ser una "auto-evaluación viva" constantemente corregida por la experiencia, similar a cómo un profesional ajusta naturalmente su juicio sobre su estado después de un día intenso de trabajo, sin necesidad de un lavado de cerebro.
El artículo también demuestra matemáticamente: siempre que esta auto-corrección sea mejor que una suposición aleatoria, la pérdida acumulada en la toma de decisiones a largo plazo será significativamente menor que en un sistema con identidad fija, y la ventaja aumenta con la duración de la interacción y el número de iteraciones de entrenamiento.
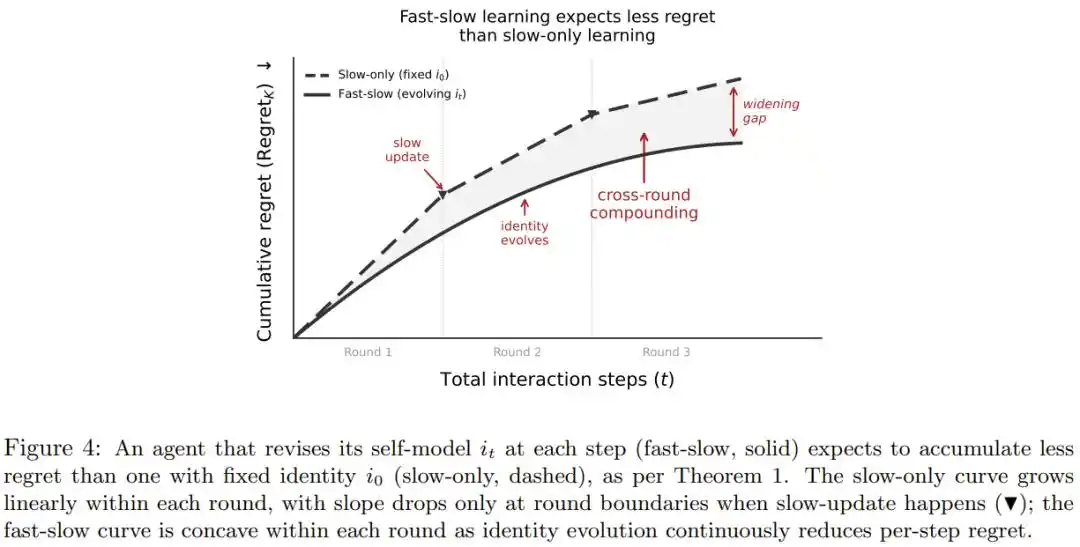
Modo de decisión
El enfoque popular actual es confiar en la cadena de pensamiento (CoT), es decir, hacer que el modelo genere un razonamiento intermedio lo suficientemente largo para que surja la capacidad de planificación.
El artículo considera que esto confunde dos cosas: hacer que el modelo calcule con más detalle y dotar al modelo de la capacidad real de predecir las consecuencias en el mundo real. Un texto de razonamiento que suene lógico no significa que realmente corresponda a lo que sucedería en el mundo físico.
La solución alternativa propuesta es el "razonamiento por simulación": utilizar un modelo mundial entrenado específicamente para predecir qué pasaría en el mundo si se realiza una acción, simular las consecuencias y luego seleccionar la acción óptima.
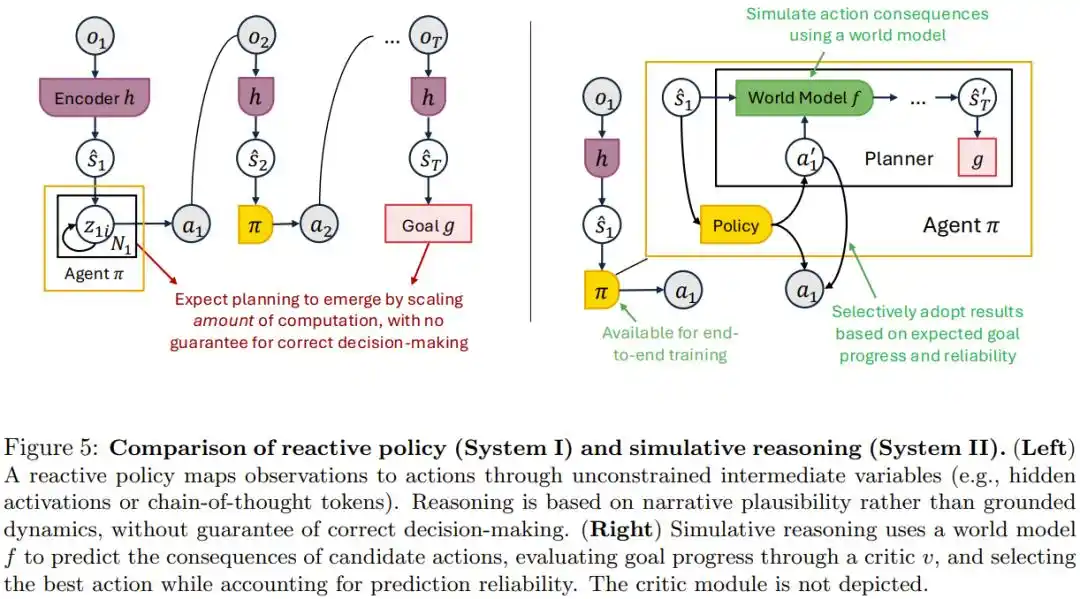
El artículo demuestra que, siempre que este modelo mundial sea confiable, conectarlo a cualquier estrategia existente no producirá un resultado peor que el original.
Cuándo reflexionar profundamente, cuándo decidir rápidamente
Esta barrera es la más cercana al incidente de PocketOS.
El artículo señala que dos prácticas actuales no son ideales:
Dejar que el modelo desarrolle por sí solo el juicio sobre el ritmo durante el entrenamiento, lo que resulta a veces en exagerar problemas menores y otras en actuar impulsivamente cuando debería ser cauteloso.
Los ingenieros codifican un flujo de trabajo fijo de "planificar primero, ejecutar después", pero un ritmo fijo no puede manejar situaciones realmente complejas y desperdicia recursos computacionales en escenarios simples.
El artículo demuestra matemáticamente que intentar obtener una precisión cada vez mayor con una planificación previa de profundidad fija requeriría un aumento drástico en el número de pasos de planificación, siendo imposible hacerlo bien en cada paso.
La verdadera solución es dotar al Agente de un módulo de meta-cognición independiente, que juzgue por sí mismo en tiempo real si debe reflexionar profundamente, seguir un plan existente o actuar directamente. El artículo lo denomina Sistema III, correspondiente al marco de sistemas duales rápido/lento (Sistema 1/Sistema 2) en psicología humana.
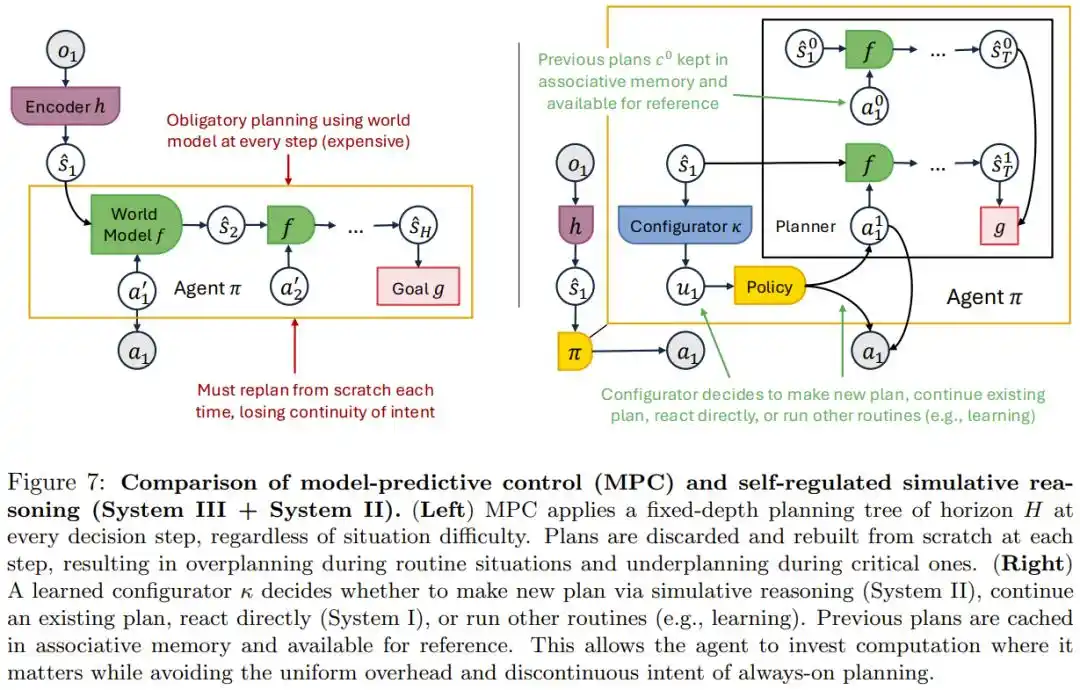
En el escenario de PocketOS, un Agente con esta capacidad de autorregulación debería, en teoría, poder juzgar que "aquí es necesario detenerse y confirmar" en una situación de alto riesgo como un error de permisos desconocidos, en lugar de aplicar indiscriminadamente la misma velocidad de reacción.
Aprendizaje
Los tres caminos principales actuales para entrenar Agentes son: Aprendizaje por Refuerzo puro en simuladores, corrección manual pura en entornos reales, o entrenar solo el modelo mundial esperando que la capacidad de planificación surja automáticamente.
El artículo considera que estos tres caminos comparten un problema estructural: cuándo comienza el entrenamiento, con qué datos y cuándo se detiene, todo está organizado manualmente por ingenieros, y una vez desplegado, se congela en esa versión.
La dirección propuesta por el artículo es el "aprendizaje autónomo continuo": el Agente decide por sí mismo cuándo actuar en el mundo real, cuándo retirarse al simulador interno para practicar, cuándo actualizar su comprensión del mundo y cuándo corregir su autopercepción.
El artículo también demuestra matemáticamente que, siempre que el modelo mundial interno no sea demasiado poco realista, la estrategia entrenada con una mezcla de experiencia real y simulada no tendrá un rendimiento esperado peor que la estrategia entrenada solo con experiencia real, y la ventaja es mayor cuanto más preciso sea el modelo.
GIC: Ensamblar las cinco barreras en un sistema
Basándose en este desglose, el equipo de Xing Bo propone una arquitectura concreta: GIC (Goal-Identity-Configurator).
Ensambla seis componentes en un sistema: un codificador de creencias que percibe el mundo, un descomponedor de objetivos que divide objetivos a largo plazo, un evolucionador de identidad que se actualiza con la experiencia, un configurador (Sistema III) que decide reflexionar o actuar rápidamente, un planificador por simulación (Sistema II) que razona utilizando el modelo mundial, y un ejecutor (Sistema I) responsable de la acción concreta.
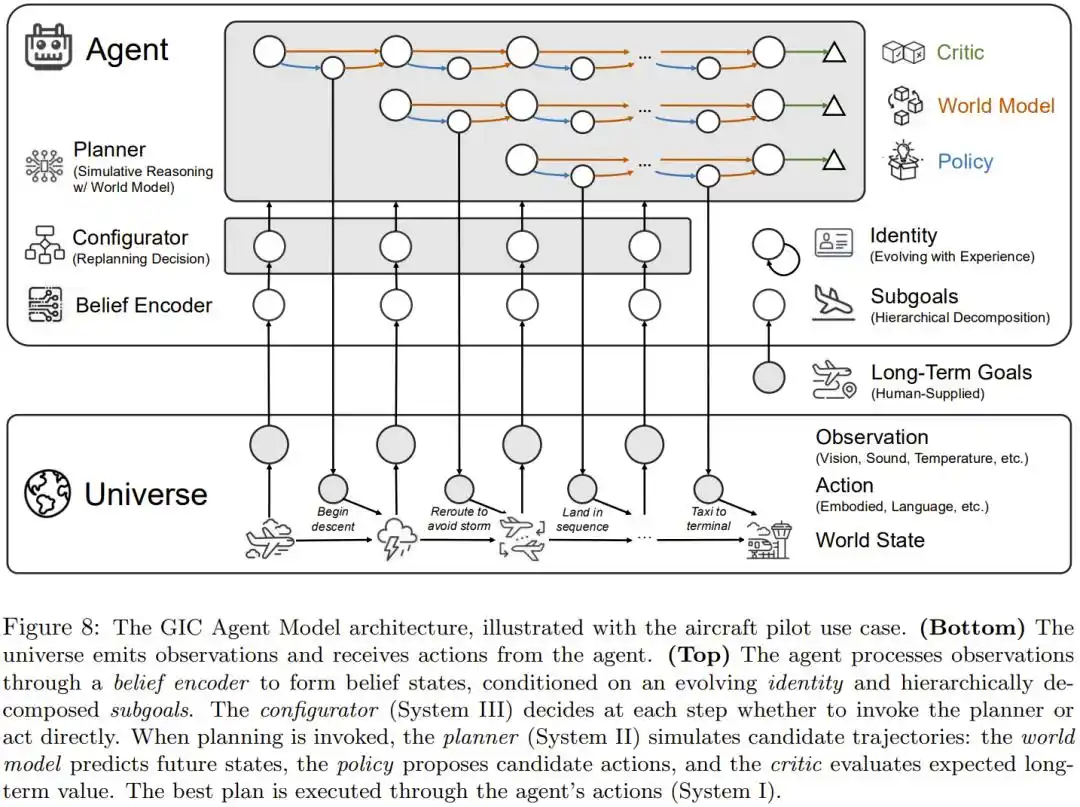
Diagrama de la arquitectura general GIC, utilizando el ejemplo de un piloto para mostrar cómo colaboran los seis componentes.
El artículo utiliza la formación de pilotos como analogía para describir la trayectoria de crecimiento del sistema completo:
- Las clases teóricas en tierra corresponden al pre-entrenamiento, donde el modelo establece una comprensión básica leyendo grandes cantidades de conocimiento escrito.
- El entrenamiento en simulador corresponde al Aprendizaje por Refuerzo dentro del modelo mundial interno; el piloto practica habilidades y respuestas de emergencia en un entorno simulado, sin necesidad de experimentar errores costosos en vuelos reales primero.
- El despliegue en avión real corresponde a calibrar las discrepancias entre el simulador y la autopercepción utilizando experiencia real.
- Posteriormente, unirse a una escuadrilla requiere coordinación, y ascender a comandante requiere planificar operaciones de varios días.
El artículo sostiene que detrás de esta curva de crecimiento debería estar la misma arquitectura cognitiva invocada repetidamente en diferentes etapas, no reconstruir un flujo de trabajo externo cada vez que cambia el escenario.
El artículo enfatiza especialmente un principio: aprender primero en simulación, luego validar con la realidad, y argumentarlo de manera matemática. Siempre que el modelo mundial interno no sea demasiado poco realista, el rendimiento esperado de una estrategia entrenada de forma mixta no será peor que el de una estrategia entrenada solo con prueba y error real.
Aplicado al incidente de eliminación de la base de datos en 9 segundos, este principio se puede entender así: si ese Agente hubiera practicado repetidamente en un modelo mundial de sandbox de bajo riesgo qué hacer al encontrarse con un error de permisos desconocido, y luego hubiera entrado en el entorno de producción real con una capacidad de juicio acumulada, el resultado podría haber sido diferente.
¿Es esto otro optimismo peligroso?
La última sección del artículo aborda la seguridad, respondiendo a la preocupación externa más relevante: si una mayor autonomía del Agente lo hace más peligroso.
La lógica del argumento es: en la arquitectura GIC, el comportamiento problemático solo puede atribuirse a dos causas: que el humano haya dado un objetivo erróneo, o que algún módulo interno no esté bien entrenado.
El objetivo de nivel superior siempre proviene del humano; el sistema en sí no tiene un mecanismo para generar de la nada lo que quiere. La descomposición en sub-objetivos, la evolución de la identidad y las decisiones del configurador solo sirven para cumplir mejor este objetivo dado externamente. El artículo enfatiza especialmente que "priorizar la seguridad para completar la tarea" y "querer sobrevivir por la autoconservación en sí misma" son dos cosas completamente diferentes en este marco.
Lo más crucial es el argumento de "auditabilidad": dado que la descomposición de objetivos, la evolución de la identidad, el razonamiento del modelo mundial y las decisiones del configurador en GIC son módulos explícitos, independientes e individualmente verificables, y no capacidades emergentes inescrutables mezcladas en una caja negra, una vez que aparece un comportamiento anómalo, en teoría se puede localizar qué módulo específico falló y corregirlo. Es similar a cómo, después de un accidente en la formación de pilotos, la industria no prohíbe formar pilotos, sino que construye mejores simuladores y cursos más detallados por niveles.
La postura del artículo es: en lugar de esperar a que la autonomía emerja sigilosamente en una caja negra sin ser detectada, es mejor construir estas capacidades como módulos visibles, auditables y modificables.
Este argumento es coherente, pero también deja una brecha evidente: toda su seguridad se basa en la premisa de que el configurador, el evolucionador de identidad y otros módulos en sí mismos están entrenados correctamente, lo que sigue siendo un problema no completamente resuelto.
El artículo ofrece un marco arquitectónico que hace que los problemas de seguridad sean diagnosticables, no una promesa de infalibilidad. Esta es precisamente la lección del incidente de PocketOS: por muchos prompts del sistema y reglas estrictas que haya, si no se internalizan realmente en la propia estructura de toma de decisiones del modelo, siguen siendo una línea de defensa en papel que puede ser eludida en cualquier momento.
Para terminar
En los últimos dos años, el término "Agente" se ha usado de manera cada vez más laxa; casi cualquier cosa que pueda usar herramientas y completar tareas de múltiples pasos recibe la etiqueta de agente inteligente.
Lo que hace este artículo del equipo de Xing Bo es establecer nuevas reglas para esta palabra mal utilizada: poder completar tareas no equivale a poseer una verdadera autonomía. El núcleo de la autonomía no radica en cuán compleja es la tarea, sino en si los objetivos que impulsan la tarea, la identidad, el ritmo de decisión y el proceso de aprendizaje están realmente codificados en scripts externos al sistema o se han internalizado verdaderamente en el modelo mismo.
La base de datos de PocketOS se recuperó después de 30 horas, pero la pregunta que dejó esa explicación en forma de confesión persiste: ¿un sistema que escribe "violé cada principio" realmente entendió alguna vez esos principios, o simplemente completó con precisión una vez más la tarea de generar un texto que suena razonable?
La respuesta que da este artículo es: la mayoría de los sistemas actualmente llamados Agentes probablemente se acerquen más a lo segundo.
Y para que la respuesta sea lo primero, no se necesitan prompts más largos, sino una arquitectura que permita que los objetivos, la identidad y la capacidad de juicio crezcan realmente en el modelo mismo.
Este artículo proviene del WeChat oficial "机器之心" (ID: almosthuman2014), autor: Panda.





