Artículo | Xiang Xianzhi
Luo Fuli publicó un mensaje en X, para poner punto final a la controversia por la reducción de precios del Xiaomi MiMo.
El 26 de mayo, la cuenta oficial de Xiaomi MiMo en X publicó un anuncio: La serie MiMo-V2.5 reduce permanentemente el precio de sus APIs, con una reducción máxima del 99%. Todos los contextos de longitud tienen un precio fijo, y los paquetes de Tokens se actualizan de 5 a 8 veces.
Este anuncio inundó el círculo de IA en China durante toda una semana. La reacción inicial de la industria se dividió en varias facciones. La más grande dijo que se trataba de "otra ronda de guerra de precios": en los últimos dos años, desde Zhipu, DeepSeek, Byte's Doubao hasta Alibaba's Tongyi, los grandes modelos chinos se han estado reduciendo de precio, todos están en la carrera.
Otro grupo lo vio con pesimismo: Xiaomi acaba de anunciar que este año sus ganancias se reducirán a la mitad, y en este momento aún gasta 600 mil millones en IA y recorta las APIs un noventa por ciento: un típico caso de "capturar mercado perdiendo dinero". Otros creen que es el efecto DeepSeek que continúa: este último ha arrastrado el precio de referencia de toda la industria al suelo, quien no lo siga, queda fuera.
Por eso, como responsable de MiMo, Luo Fili publicó anoche directamente un blog técnico de 5000 palabras, haciendo públicos para todos los detalles técnicos y de costos de la reducción de precios.
"Miren, esto es capacidad de ingeniería real, no una estrategia de marketing".
Para entender lo que dice Luo Fuli, primero hay que comprender exactamente en qué consiste esa reducción del 99%.
No es una reducción del precio de todo el modelo. El descuento del 99% está dirigido específicamente a una categoría de precios llamada Input (Cache Hit): es decir, la parte en la que "el usuario vuelve a leer el contexto histórico en una conversación larga". La reducción para las nuevas entradas ordinarias (No Cache Hit) es mucho menor, y la reducción para la salida del modelo (Output) es la más pequeña.
Si imaginamos el modelo como una cafetería, es más fácil de entender.
Pides un café con leche semidesnatado. La cafetería tiene dos formas de hacerlo: cada vez muele granos, mide el jarabe, añade leche, pagando por ingredientes y mano de obra cada vez; pero el modelo sabe que esta semana quieres el mismo café con leche semidesnatado todos los días, así que prepara una gran jarra y la guarda en la nevera, para la próxima vez servir una taza. Lo que hace MiMo es esto último: convierte la parte que el usuario vuelve a leer de "calcular en el momento" a "recuperar del almacenamiento", por lo que el costo real de esta parte se acerca a 0, naturalmente puede ofrecer un descuento del 99%.
Para lograr "recuperar del almacenamiento", el blog técnico habla de seis trabajos de ingeniería, cada uno indispensable. Vamos a desglosarlos uno por uno.
Trabajo de ingeniería uno: Comprimir la "memoria" del modelo a 1/7
Cuando el modelo dialoga contigo, cada token necesita calcular un "estado intermedio" y almacenarlo para el siguiente paso. Esto se llama KVCache: se puede entender como el "cuaderno de notas de memoria a corto plazo" del modelo. Cada vez que se dice una frase, el modelo anota un resumen en el cuaderno, la próxima vez simplemente revisa las notas, sin necesidad de escuchar todo lo dicho desde el principio.
Los modelos tradicionales en cada capa realizan "Full Attention": es decir, cada token debe observar todos los tokens del diálogo completo, el cuaderno de notas se vuelve cada vez más grueso. MiMo-V2.5-Pro cambia la arquitectura: de las 70 capas, 60 solo observan los últimos 128 tokens (SWA, Sliding Window Attention), y solo 10 capas de "archivistas" observan todo.
El resultado es que el volumen de KVCache se comprime directamente a 1/7 del Full Attention, y la cantidad de cálculo también es 1/7.
Esta es la primera base para reducir costos. Pongamos un ejemplo: originalmente la empresa requería que cada empleado recordara todas las actas de las reuniones, resultado: el cerebro de cada uno no daba abasto y la eficiencia era baja. El nuevo reglamento reduce la carga mental de 60 empleados a 1/7, dejando solo 10 archivistas a cargo de toda la historia: la capacidad de memoria general de la empresa no disminuye, pero la eficiencia aumenta 7 veces.
Trabajo de ingeniería dos: Hacer que el espacio ahorrado por SWA realmente se pueda usar
El primer paso es comprimir el cuaderno a 1/7 a nivel de arquitectura, pero para convertir el "1/7 teórico" en el "1/7 real", hay un obstáculo más.
Los sistemas tradicionales de KVCache asignan memoria de video (VRAM) de manera uniforme a todas las capas según el "uso máximo posible". Esto significa: aunque las 60 capas de SWA solo necesitan un cuaderno pequeño, el sistema también asigna a todas las capas según el "cuaderno grande del archivista": el espacio ahorrado por SWA se reserva inútilmente, es como si no se hubiera ahorrado.
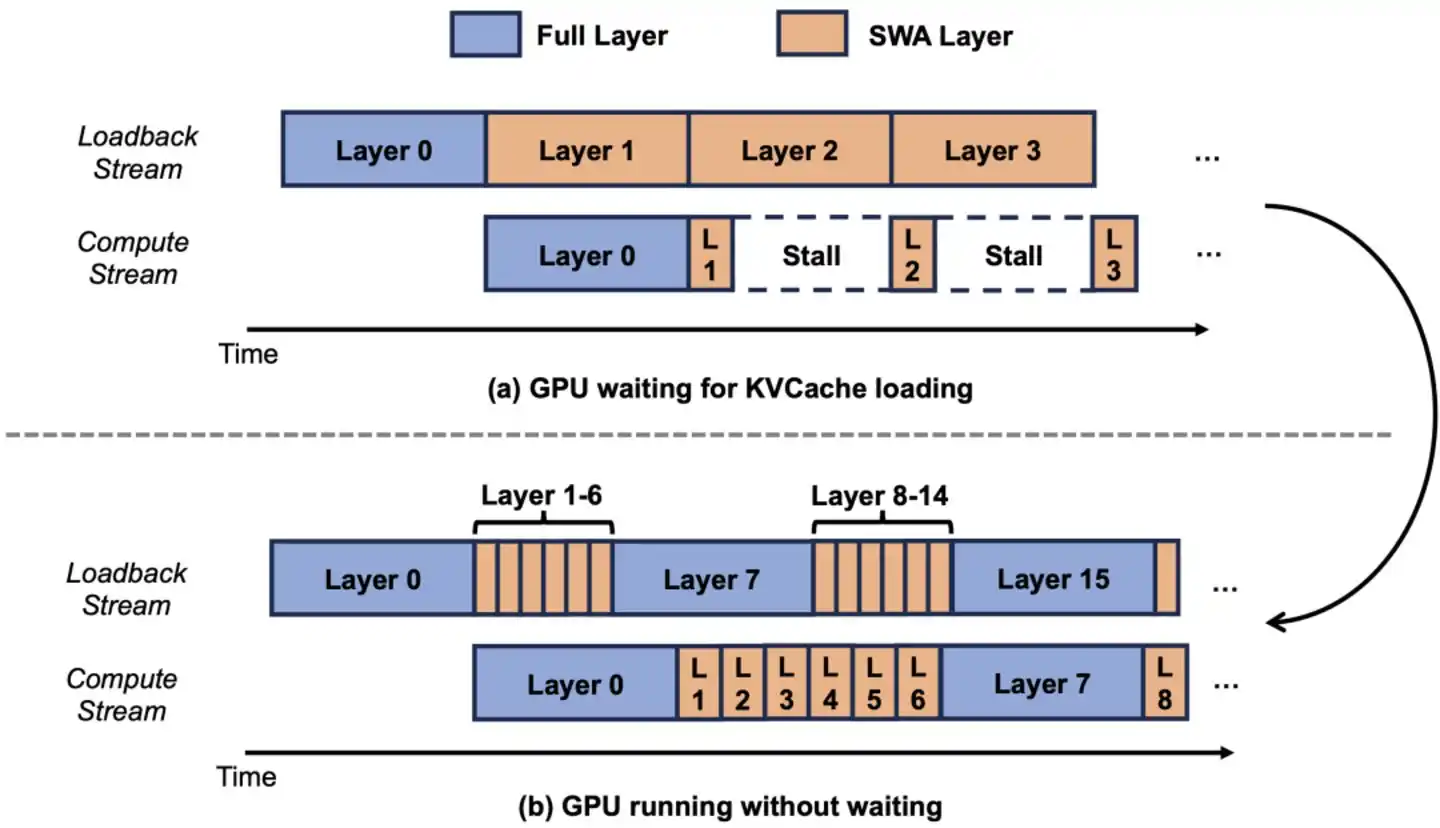
Lo que hace el equipo de Luo Fuli es dividir el KVCache en dos grupos independientes. Las 10 capas de Full Attention van al "grupo grande", asignado según la longitud completa; las 60 capas de SWA van al "grupo pequeño", asignado solo según la ventana de 128 tokens.
Pongamos un ejemplo: originalmente la empresa le daba a cada empleado un "archivador capaz de contener documentos de 100 años", pero 60 empleados en realidad solo necesitaban un "pequeño archivador para una semana de documentos", el 99% del espacio en esos grandes archivadores estaba vacío. El nuevo método es asignar archivadores según las necesidades reales. El resultado es que toda la oficina puede acomodar 5 veces más compañeros para trabajar: la misma GPU puede servir a 5 veces más usuarios concurrentes.
Este paso parece simple, pero sin él, la ventaja del diseño arquitectónico SWA anterior equivaldría a nada.
Trabajo de ingeniería tres: Hacer que la "relectura de usuarios antiguos" realmente pueda acertar en la caché
El cuaderno comprimido a 1/7 + el espacio realmente utilizable, el siguiente paso es resolver un viejo problema: la tasa de acierto del caché de prefijos.
Muchos diálogos de usuarios tienen el mismo inicio: el mismo system prompt, la misma base de código, el mismo documento largo. El sistema almacena estos resultados ya calculados, y la próxima vez que coincidan se reutilizan directamente. Este mecanismo se llama caché de prefijos.
Pero en el modo SWA aparece un problema: que dos solicitudes tengan los mismos tokens, no significa que el KV todavía esté ahí. Es posible que el prefijo se haya calculado, pero la parte fuera de la ventana SWA ya haya sido eliminada. Si el sistema sigue la antigua regla de "si los tokens son iguales, se acierta" para reutilizar, se leerán datos inválidos o sobrescritos, y el efecto del modelo colapsará directamente.
El equipo de Luo Fuli actualizó la regla a "longitud segura de ventana": solo garantiza "la parte que puedes obtener completa".
Pongamos un ejemplo: la biblioteca tiene 1 millón de libros, quieres pedir prestada la trilogía completa de "El problema de los tres cuerpos". La arquitectura original te diría "el libro está aquí", vas y descubres que en el estante solo queda la portada y el primer libro, los otros dos ya están prestados. Este "falso acierto" te hace ir en vano y además tienes que volver a pedir prestado. El nuevo sistema cambia la regla para solo garantizar la parte que puedes obtener completa: primero te da el primer libro, y luego te trae los otros dos.
Parece más estricto, la tasa de acierto debería bajar. Pero en realidad es al revés: porque SWA reduce el volumen de KVCache a 1/7, el mismo espacio de almacenamiento puede contener varios veces más contenido, la tasa de acierto real aumenta considerablemente.
En el blog, Luo Fuli da cifras de pruebas en línea reales: en el marco harness principal, la tasa de acierto de caché en el servidor es en promedio del 93%, y para usuarios de alta frecuencia y ciclo largo puede superar el 95%.
Traduciendo el significado de esta cifra: el 95% de las solicitudes de "relectura" no necesitan cálculo de GPU, se obtienen directamente de la caché. Esta es la base física del descuento del 99%.
Trabajo de ingeniería cuatro: Meter la "caché" en el SSD incorporado de la GPU
Subida la tasa de acierto, el siguiente problema es: dónde almacenar esta caché.
La memoria de video (memoria HBM en la GPU) es cara y limitada: una máquina con 8 tarjetas H100 tiene solo 640 GB de VRAM, pero el KVCache que MiMo necesita almacenar puede ser del orden de decenas de TB. Por lo tanto, debe ser jerárquico: lo usado recientemente se pone en VRAM (L1), lo un poco más antiguo en memoria RAM de la CPU (L2), y los datos fríos en caché distribuida (L3).
Es igual que administrar dinero. El efectivo en la cartera es la VRAM: se usa al momento pero no cabe mucho. El saldo de la tarjeta bancaria es la RAM de la CPU: tomar una vez tarda 30 segundos pero puede guardar mucho. El depósito a plazo fijo es la caché distribuida L3: tomar una vez tarda 2 minutos pero es mucho más barato.
La práctica común de la industria es construir un clúster de almacenamiento separado para L3, con máquinas dedicadas, centros de datos dedicados, pagando alquiler mensualmente.
El equipo de almacenamiento de Xiaomi hace algo diferente. Desarrollaron internamente un sistema de caché distribuida llamado GCache, desplegado directamente en los SSD incorporados en las máquinas con GPU: conviviendo en la misma máquina con las tareas de entrenamiento y de inferencia.
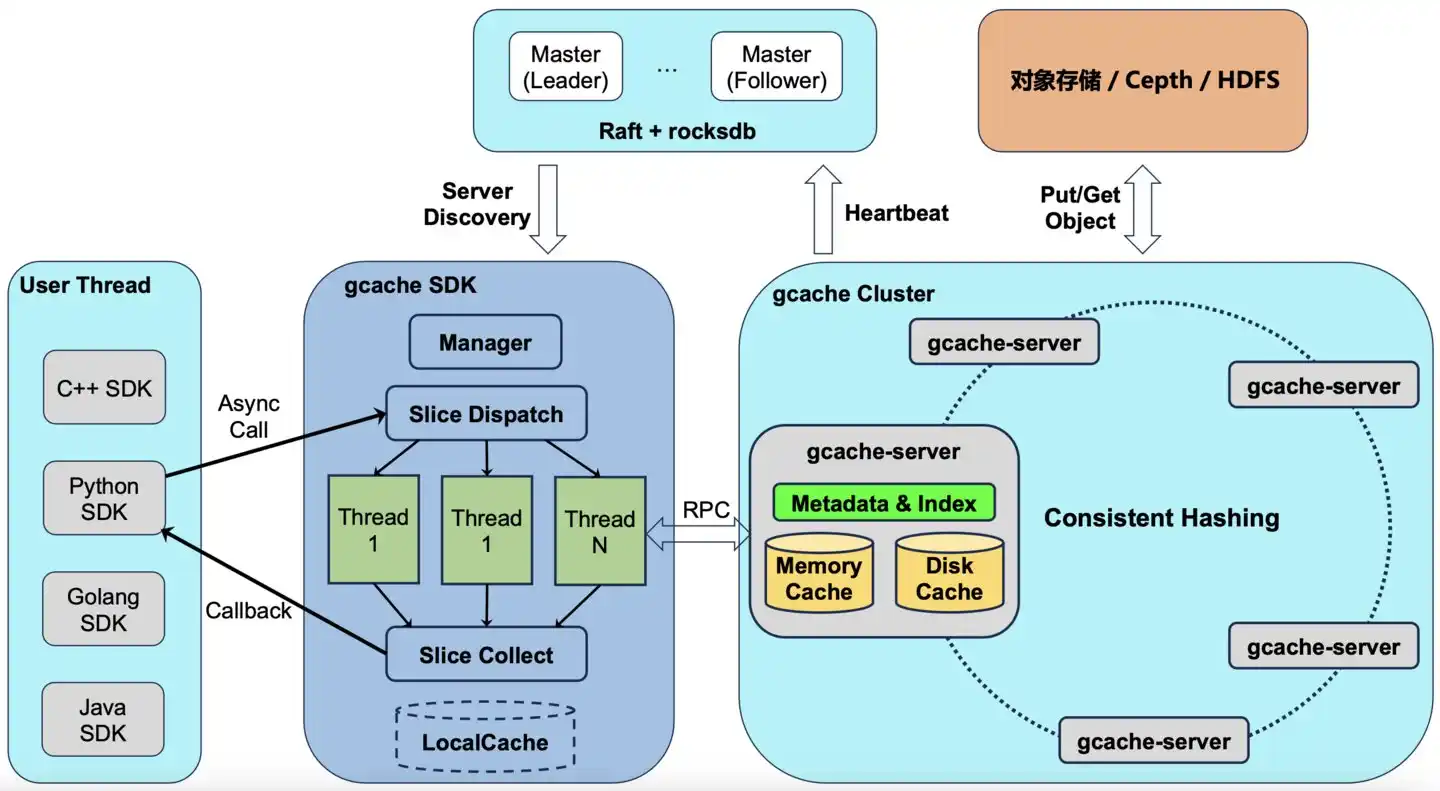
Traducción sencilla: otros alquilan un almacén especial para guardar grandes cantidades de datos; Xiaomi descubrió que el garaje de las máquinas con GPU en realidad está vacío, y guarda los datos directamente ahí. Se ahorra el alquiler mensual.
La cita literal del blog técnico es: "El costo de almacenamiento adicional es 0."
El impacto de esto es mayor de lo que parece. En la "cuenta de capacidad de cálculo" convencional de una empresa de IA, el costo de almacenamiento es un gasto fijo: cuanto más grande es tu modelo y más usuarios tienes, más larga es la factura de almacenamiento. El método GCache elimina directamente este ítem. Combinado con el pequeño volumen de SWA + tasa de acierto del 93-95%, el tiempo de vida (TTL) del KVCache en L3 se extiende de minutos a horas o incluso días: cuanto más largo sea el TTL, más amplia será la ventana de acierto posible para el contexto histórico, mayor será la tasa de acierto de la caché, y más sólido será el descuento del 99%.
Trabajo de ingeniería cinco: Hacer que las solicitudes que aciertan en la caché tomen el camino más corto
La caché se puede guardar, se puede consultar y es barata. El último paso es: cómo enrutar la solicitud correcta a la máquina correcta.
Xiaomi desarrolló su propio sistema de programación llamado LLM-Router, que hace tres cosas:
Primero, programación de afinidad. Las solicitudes con el mismo prefijo se enrutan a la misma máquina, maximizando la reutilización de la caché.
Segundo, agrupación por longitud. Divide las solicitudes cortas (0-64K), medianas (64K-256K) y largas (256K-1M) en diferentes canales de procesamiento, evitando que las solicitudes cortas se vean perjudicadas por las largas.
Tercero, optimización de TTFT. En la cola de espera para inferencia, prioriza la programación de solicitudes con poco cálculo real (es decir, aquellas que aciertan mucho en la caché): evitando que sean bloqueadas por solicitudes de "entrada completamente nueva" que requieren mucho cálculo.
Por ejemplo, en la programación habitual de un aeropuerto, todos los pasajeros con el mismo destino se concentran en la misma sala de espera, compartiendo el proceso de recogida de equipaje: esto es programación de afinidad. Los que llevan equipaje de mano y los que llevan 3 maletas grandes facturadas pasan por dos canales de seguridad diferentes, los rápidos no se ven retrasados por los lentos: esto es agrupación por longitud. Al embarcar, se prioriza a quienes solo llevan equipaje de mano, suben rápido, permitiendo que el avión despegue antes: esto es optimización de TTFT.
Esta estrategia de programación elevó en las pruebas reales la tasa de acierto de caché L2 en un 25%, aumentó el rendimiento de entrada por máquina en un 30% y redujo la latencia P90 de las solicitudes largas en un 30%.
Tradución: la misma GPU puede servir a más usuarios. La otra mitad de la lógica de la reducción de precios está aquí: la producción efectiva por unidad de capacidad de cálculo es mayor, el costo por usuario es menor.
Trabajo de ingeniería seis: Hacer que el modelo "escriba" también más rápido
Las cinco cosas anteriores optimizan el lado de "lectura": reducir el costo de que el usuario relea el contexto histórico a casi 0. La sexta cosa es optimizar el lado de "escritura": es decir, el proceso en que el modelo genera el siguiente token.
Los modelos tradicionales solo pueden generar 1 token a la vez. MiMo soporta de forma nativa 3 capas de MTP (Multi-Token Prediction): predice los siguientes 3 tokens de una vez, si la predicción intermedia es correcta, salta directamente el cálculo intermedio.
Pongamos un ejemplo: la escritura tradicional es escribir letra por letra: quieres escribir "hoy hace buen tiempo", debes presionar 4 teclas. MTP es como tener un autocompletado que adivina cuáles serán tus próximas 1-2 palabras: si acierta, no necesitas presionar esas dos teclas.
Las pruebas de MTP de MiMo en escenarios de agentes: los primeros 128 tokens de decodificación se aceleran 2.3 veces, los tokens 128-256 se aceleran 1.5 veces.
El significado de esto es que el descuento del 99% está dirigido específicamente a Input (Cache Hit), pero cuando el modelo realmente sirve a un usuario, input y output ocurren en la misma solicitud: si output no se ahorra, el costo total de la solicitud solo se ahorra a la mitad. MTP hace que la mitad de output también baje, y así el modelo de rentabilidad de toda la reducción de precios se cierra.
Uniendo las seis cosas en una cadena de reducción de costos:
Arquitectura SWA → KVCache 1/7 → doble grupo libera realmente capacidad → la misma GPU puede albergar 5+ veces concurrencia → tasa de acierto de caché de prefijos 93-95% → 95% de solicitudes casi sin cálculo → GCache hace que costo de almacenamiento sea cero → programación prioriza solicitudes que aciertan → MTP hace que generación también ahorre → tiempo de GPU por solicitud baja un orden de magnitud → costo unitario baja 95%+ → precio baja 99%, margen bruto aún positivo.
Falta cualquier eslabón y esta cadena se rompe en algún punto. La reducción del 99% no es un número de marketing, es el efecto acumulativo de seis pilares de ingeniería superpuestos + verificado en línea real.
Mirando atrás a las interpretaciones iniciales de la industria, cada una tiene parte de razón. La guerra de precios entre las empresas de grandes modelos chinos en estos dos años es real; que Xiaomi reduzca sus ganancias a la mitad y aún apueste por la IA es real; que DeepSeek arrastre los precios de referencia de la industria al suelo también es real.
Pero Luo Fili esta vez hizo público el blog técnico y desglosó detalladamente los detalles técnicos, sin duda esperando responder a las afirmaciones sobre la guerra de precios, para que "los problemas técnicos vuelvan a la técnica, los problemas de marketing vuelvan al marketing".
Escribe en su blog que la eficiencia de inferencia de la serie de modelos MiMo-V2.5 no proviene de un único avance en un eslabón, sino del resultado de una optimización coordinada multidimensional. Hybrid SWA beneficia simultáneamente a prefill y decode, pero una implementación de KVCache no suficientemente optimizada, por el contrario, aumentaría los costos en cada eslabón. En torno a este objetivo, el equipo de MiMo reconstruyó sistemáticamente la gestión de KVCache, la caché jerárquica, el árbol de caché de prefijos, resolvió el problema central de SWA KVCache, optimizó las estrategias de programación y la cadena de Prefill/Decode, y tras ser probado en escenarios reales en línea, finalmente convirtió su ventaja de eficiencia teórica en ventaja real en el entorno de producción. Solo así Hybrid SWA pudo desplegar su ventaja arquitectónica combinando fuerza y eficiencia en el razonamiento de textos largos. Combinado con la configuración MoE y diversas optimizaciones de razonamiento multimodal, mejoró enormemente el rendimiento del servicio de inferencia en línea.
Este es un enfoque sistemático de ingeniería de IA, y también un medio de reducción de costos que vale la pena que la industria considere y tome como referencia.
La guerra de precios no necesita escribir blogs, el cumplimiento de la ingeniería sí.





