Título original: A shallow dive into formal verification
Autor original: Vitalik
Compilación original: Peggy, BlockBeats
Nota del editor: Con la rápida mejora de la capacidad de programación de la IA, la seguridad del software se enfrenta a una nueva paradoja: la IA puede generar código de manera más eficiente, pero también puede encontrar vulnerabilidades de manera más eficiente. Para la industria de la criptografía, este problema es especialmente crítico. Si ocurre algún defecto en contratos inteligentes, pruebas ZK, algoritmos de consenso y sistemas de activos en cadena, las consecuencias a menudo no son simples errores de software, sino pérdidas de fondos irreversibles y el colapso de la confianza.
Lo que Vitalik discute en este artículo es precisamente otro camino para la seguridad del código en la era de la IA: la verificación formal. En pocas palabras, no depende de auditores humanos que revisen línea por línea el código, sino que se escriben las propiedades que el programa debe satisfacer en proposiciones matemáticas y luego se utilizan pruebas verificables por máquina para comprobar si estas propiedades se cumplen. En el pasado, la verificación formal, debido a su alto umbral y proceso tedioso, se ha mantenido en un campo de investigación e ingeniería relativamente nicho; pero a medida que la IA puede ayudar a escribir código y pruebas, este método está adquiriendo nuevamente un significado práctico.
El juicio central del artículo no es que "la verificación formal puede resolver todos los problemas de seguridad". Por el contrario, Vitalik recuerda repetidamente que la llamada "seguridad demostrable" no equivale a una seguridad absoluta: las pruebas pueden omitir supuestos clave, la especificación en sí puede estar mal escrita, el código no verificado, los límites del hardware y los ataques de canales laterales también pueden convertirse en nuevas fuentes de riesgo. Pero aún así, ofrece un paradigma de seguridad más confiable: expresar la intención del desarrollador de múltiples maneras y luego dejar que el sistema verifique automáticamente si estas expresiones son compatibles entre sí.
Esto es especialmente importante para Ethereum. El futuro de Ethereum dependerá cada vez más de componentes complejos de bajo nivel, incluyendo STARK, ZK-EVM, firmas resistentes a la computación cuántica, algoritmos de consenso e implementaciones de EVM de alto rendimiento. La implementación de estos sistemas es extremadamente compleja, pero sus objetivos centrales de seguridad a menudo pueden formalizarse de manera relativamente clara. Y es precisamente en este tipo de escenarios donde la verificación formal asistida por IA puede desempeñar su mayor valor: dejar que la IA se encargue de escribir código eficiente y pruebas, y que los humanos se encarguen de verificar si las proposiciones finalmente demostradas realmente corresponden a los objetivos de seguridad deseados.
Desde una perspectiva más amplia, este artículo también es la respuesta de Vitalik a la seguridad de la red en la era de la IA. Frente a atacantes de IA más poderosos, la respuesta no es abandonar el código abierto, los contratos inteligentes o volver a depender de unas pocas instituciones centralizadas, sino comprimir los sistemas clave en "núcleos de seguridad" más pequeños, más verificables y más confiables. La IA aumentará la cantidad de código deficiente, pero también podría hacer que el código realmente importante sea más seguro que nunca.
A continuación se encuentra el texto original:
Agradecimientos especiales a Yoichi Hirai, Justin Drake, Nadim Kobeissi y Alex Hicks por sus comentarios y revisiones a este artículo.
Durante los últimos meses, un nuevo paradigma de programación ha estado surgiendo rápidamente en los círculos de investigación de vanguardia de Ethereum y en muchos otros rincones del campo de la computación: los desarrolladores escriben código directamente en lenguajes de muy bajo nivel, como el bytecode de EVM, lenguaje ensamblador, o usando Lean, y verifican su corrección mediante pruebas matemáticas verificables automáticamente escritas en Lean.
Si se utiliza correctamente, este método puede generar código extremadamente eficiente y ser mucho más seguro que las formas anteriores de desarrollo de software. Yoichi Hirai lo llama "la forma final del desarrollo de software". Este artículo intentará explicar la lógica básica detrás de este método: qué puede hacer exactamente la verificación formal de software y cuáles son sus limitaciones y fronteras, tanto en el contexto de Ethereum como en el campo más amplio del desarrollo de software.
¿Qué es la verificación formal?
La verificación formal se refiere a escribir pruebas de teoremas matemáticos de una manera que pueda ser verificada automáticamente por una máquina.
Para dar un ejemplo relativamente simple pero aún interesante, podemos ver un teorema básico sobre la secuencia de Fibonacci: cada tres números, uno es par y los otros dos son impares.

Un método de prueba simple es usar inducción matemática, avanzando tres números a la vez.
Primero, el caso base. Sea F1 = F2 = 1, F3 = 2. Por observación directa, se puede ver que la proposición—"cuando i es múltiplo de 3, Fi es par; en otros casos, Fi es impar"—se cumple hasta x = 3.
Luego, el paso inductivo. Supongamos que la proposición se cumple hasta 3k+3, es decir, ya sabemos que F3k+1, F3k+2 y F3k+3 son impar, impar y par, respectivamente. Entonces, podemos calcular la paridad del siguiente grupo de tres números:
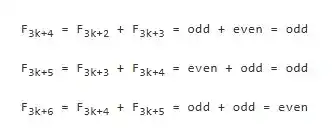
De esta manera, hemos completado la derivación de "saber que la proposición se cumple hasta 3k+3" a "confirmar que la proposición también se cumple hasta 3k+6". Repitiendo este razonamiento, podemos estar seguros de que esta ley se cumple para todos los enteros.
Este argumento es convincente para los humanos. Pero, ¿qué pasa si quieres probar algo cien veces más complejo y realmente quieres asegurarte de no cometer un error? En ese caso, puedes construir una prueba que convenza también a una computadora.
Se vería más o menos así:

Es el mismo razonamiento, pero expresado en Lean. Lean es un lenguaje de programación que a menudo se utiliza para escribir y verificar pruebas matemáticas.
Se ve muy diferente a la prueba "humana" que di anteriormente, y hay buenas razones para ello: lo que es intuitivo para una computadora es muy diferente de lo que es intuitivo para un humano. Aquí, "computadora" se refiere al antiguo sentido de "computadora"—programas "deterministas" compuestos por declaraciones if/then, no modelos de lenguaje grande.
En la prueba anterior, no estás enfatizando el hecho de que fib(3k+4) = fib(3k+3) + fib(3k+2); estás enfatizando que fib(3k+3) + fib(3k+2) es impar, y el omega tactic (táctica omega) en Lean, que tiene un nombre bastante grandioso, combina automáticamente esto con su comprensión de la definición de fib(3k+4).
En pruebas más complejas, a veces debes especificar explícitamente en cada paso qué ley matemática te permite dar ese paso, y a veces estas leyes tienen nombres oscuros, como Prod.mk.inj. Pero, por otro lado, también puedes expandir enormes expresiones polinómicas en un solo paso y completar el argumento escribiendo solo una línea como omega o ring.
Esta falta de intuición y lo tedioso son razones importantes por las cuales las pruebas verificables por máquina, aunque existen desde hace casi 60 años, han permanecido en un campo nicho. Pero, al mismo tiempo, muchas cosas que antes eran casi imposibles ahora se están volviendo rápidamente factibles debido a los rápidos avances en IA.
Verificación de programas de computadora
En este punto, podrías pensar: Bueno, entonces podemos hacer que las computadoras verifiquen pruebas de teoremas matemáticos, así que finalmente podemos determinar cuáles de esos nuevos y locos descubrimientos sobre números primos son reales y cuáles son solo errores ocultos en cientos de páginas de PDFs. ¡Quizás incluso podamos descubrir si la prueba de Shinichi Mochizuki sobre la conjetura ABC es correcta! Pero, aparte de satisfacer la curiosidad, ¿qué importancia práctica tiene esto?
Puede haber muchas respuestas. Y para mí, una respuesta muy importante es: verificar la corrección de los programas de computadora, especialmente aquellos que involucran criptografía o seguridad. Después de todo, un programa de computadora es en sí mismo un objeto matemático. Por lo tanto, probar que un programa de computadora se ejecutará de cierta manera es, en esencia, probar un teorema matemático.
Por ejemplo, supongamos que quieres probar si un software de comunicación encriptado como Signal es realmente seguro. Primero puedes escribir matemáticamente qué significa exactamente "seguro" en este contexto. En resumen, lo que quieres probar es: suponiendo que ciertos supuestos criptográficos sean válidos, solo las personas con la clave privada pueden obtener cualquier información sobre el contenido del mensaje. Por supuesto, en la práctica, hay muchos tipos diferentes de propiedades de seguridad que realmente importan.
Y resulta que ya hay un equipo tratando de descubrir esto. Uno de los teoremas de seguridad que proponen se parece más o menos a esto:

A continuación, se presenta un resumen de Leanstral sobre el significado de este teorema:
El teorema passive_secrecy_le_ddh es una reducción ajustada que muestra que, bajo el modelo de oráculo aleatorio, la confidencialidad pasiva de mensajes de X3DH es al menos tan difícil de romper como la suposición DDH.
En otras palabras, si un atacante puede romper la confidencialidad pasiva de mensajes de X3DH, entonces también puede romper DDH. Dado que DDH generalmente se supone que es un problema difícil, X3DH también puede considerarse resistente a ataques pasivos.
Este teorema demuestra que si un atacante solo puede observar pasivamente los mensajes de intercambio de claves de Signal, no puede distinguir la clave de sesión generada de una clave aleatoria con una ventaja mayor que una probabilidad insignificante.
Si además se combina con una prueba de que el cifrado AES se implementa correctamente, entonces se obtiene una prueba de que el mecanismo de cifrado del protocolo Signal puede resistir a atacantes pasivos.
También existen proyectos de verificación similares que prueban implementaciones seguras de TLS y otros componentes criptográficos dentro del navegador.
Si puedes lograr una verificación formal de extremo a extremo, entonces lo que estás probando no es solo que cierta descripción del protocolo es teóricamente segura, sino que el código específico que los usuarios ejecutan realmente también es seguro en la práctica. Desde la perspectiva del usuario, esto aumenta enormemente el grado de "confianza cero": para confiar completamente en este código, no necesitas revisar línea por línea todo el código base, solo necesitas verificar las afirmaciones que ya han sido probadas.
Por supuesto, hay algunas advertencias muy importantes que deben tenerse en cuenta, especialmente en cuanto a lo que significa exactamente "seguro". Es fácil olvidar probar las afirmaciones que realmente importan; también es fácil encontrarse en una situación en la que la afirmación que necesita ser probada no tiene una descripción más concisa que el código mismo; también es fácil introducir subrepticiamente suposiciones en la prueba que finalmente no se cumplen. También es fácil concluir que solo una parte del sistema realmente necesita una prueba formal, pero luego ser golpeado por una vulnerabilidad crítica en otra parte, o incluso en el nivel de hardware. Incluso la implementación de Lean en sí podría tener errores. Pero antes de discutir estos detalles molestos, veamos primero: si la verificación formal se pudiera realizar de manera ideal y correcta, ¿qué tipo de perspectiva casi utópica podría traer?
Verificación formal orientada a la seguridad
Los errores en el código de computadora ya son preocupantes de por sí.
Cuando pones criptomonedas en contratos inteligentes inmutables en cadena, los errores de código se vuelven aún más aterradores. Porque si el código falla, los hackers norcoreanos podrían transferir automáticamente todo tu dinero, y casi no tendrías ningún recurso.
Cuando todo esto está envuelto en pruebas de conocimiento cero, los errores de código se vuelven aún más aterradores. Porque si alguien logra romper el sistema de pruebas de conocimiento cero, podría retirar todos los fondos, y podríamos no tener idea de qué salió mal, o peor aún, podríamos no saber siquiera que algo ha sucedido.
Cuando tenemos modelos de IA poderosos, los errores de código se vuelven aún más aterradores. Por ejemplo, un modelo como Claude Mythos, después de dos años más de mejoras, podría ser capaz de descubrir automáticamente estas vulnerabilidades.

Algunas personas, enfrentadas a esta realidad, han comenzado a abogar por abandonar la idea básica de los contratos inteligentes, e incluso piensan que el ciberespacio simplemente no puede ser un dominio donde los defensores tengan una ventaja asimétrica sobre los atacantes.
Aquí hay algunas citas:
Para fortalecer un sistema, necesitas gastar más tokens descubriendo vulnerabilidades de los que un atacante gasta explotándolas.
Y también:
Nuestra industria se ha construido alrededor de código determinista. Escribir código, probarlo, lanzarlo y saber que funcionará, pero en mi experiencia, este contrato está fallando. Entre los operadores más avanzados de empresas verdaderamente nativas de IA, las bases de código han comenzado a convertirse en algo "en lo que confías que funcione", y la probabilidad correspondiente a esta confianza ya no puede especificarse con precisión.
Peor aún, algunas personas piensan que la única solución es abandonar el código abierto.
Este sería un futuro sombrío para la seguridad de la red. Especialmente para aquellos que se preocupan por la descentralización y la libertad en Internet, este sería un futuro extremadamente sombrío. Todo el espíritu criptopunk se basa esencialmente en la idea de que en Internet, los defensores tienen ventaja. Construir un "castillo" digital, ya sea en forma de cifrado, firma o prueba, es más fácil que destruirlo. Si perdemos esto, entonces la seguridad de Internet solo podrá provenir de economías de escala, de perseguir a atacantes potenciales en todo el mundo, y más ampliamente, de una elección binaria: dominar todo o perecer.
No estoy de acuerdo con este juicio. Tengo una visión mucho más optimista del futuro de la seguridad de la red.
Creo que el desafío que presenta la capacidad de descubrimiento de vulnerabilidades de IA poderosa es realmente severo, pero es un desafío transitorio. Cuando el polvo se asiente y entremos en un nuevo equilibrio, llegaremos a un estado más favorable para los defensores que en el pasado.
Mozilla también está de acuerdo con esto. Citándolos:
Es posible que necesites reordenar las prioridades de todo lo demás y dedicarte a esta tarea de manera continua y enfocada. Pero hay luz al final del túnel. Estamos muy orgullosos de ver cómo el equipo se ha levantado para enfrentar este desafío, y otros también lo harán. Nuestro trabajo aún no está completo, pero hemos pasado el punto de inflexión y comenzamos a ver un futuro mejor que no es solo "mantenerse al día". Los defensores finalmente tienen la oportunidad de lograr una victoria decisiva.
......
El número de defectos es limitado, y estamos entrando en un mundo donde finalmente podemos encontrarlos todos.
Ahora, si usas Ctrl+F en este artículo de Mozilla para buscar "formal" y "verification", verás que ninguna de las palabras aparece. El futuro positivo de la seguridad de la red no depende estrictamente de la verificación formal, ni de ninguna otra tecnología individual.
¿Entonces de qué depende? Básicamente, de la siguiente imagen:
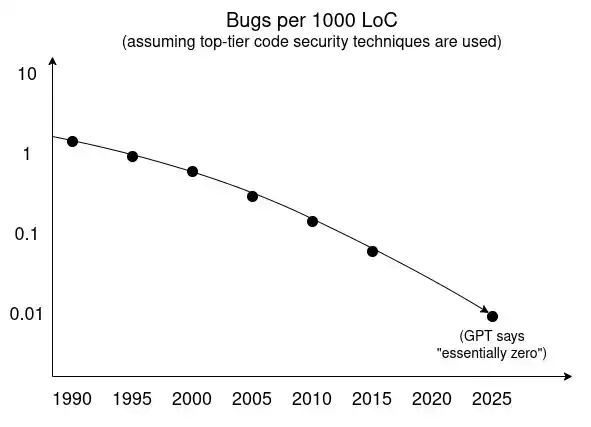
En las últimas décadas, muchas tecnologías han impulsado la tendencia de "disminución del número de vulnerabilidades":
Sistemas de tipos;
Lenguajes con seguridad de memoria;
Mejoras en la arquitectura de software, incluyendo sandboxing, mecanismos de permisos, y más generalmente, la distinción clara entre la "base de computación confiable" (trusted computing base) y el "código restante";
Mejores métodos de prueba;
La acumulación de conocimiento sobre patrones de codificación seguros e inseguros;
Cada vez más bibliotecas de software preescritas y auditadas.
La verificación formal asistida por IA no debe verse como un paradigma completamente nuevo, sino como un potente acelerador: está acelerando una tendencia y un paradigma que ya avanzaban.
La verificación formal no es una panacea. Pero en ciertos escenarios, es especialmente aplicable: cuando el objetivo es mucho más simple que la implementación específica. Esto es particularmente evidente en algunas de las tecnologías más difíciles que necesitan ser implementadas en la próxima gran iteración de Ethereum, como firmas resistentes a la computación cuántica, STARKs, algoritmos de consenso y ZK-EVM.
STARKs son un conjunto de software muy complejo. Pero la propiedad de seguridad central que implementan es fácil de entender y fácil de formalizar: si ves una prueba que apunta al hash H del programa P, la entrada x y la salida y, entonces o el algoritmo de hash utilizado por STARKs está roto, o P(x) = y. Por lo tanto, tenemos el proyecto Arklib, que intenta crear una implementación de STARKs completamente verificada formalmente. Otro proyecto relacionado es VCV-io, que proporciona infraestructura de computación de oráculos básicos que puede usarse para la verificación formal de varios protocolos criptográficos, muchos de los cuales son también componentes de dependencia de STARKs.
Más ambicioso es evm-asm: un proyecto que intenta construir una implementación completa de EVM y verificarla formalmente. Aquí, la propiedad de seguridad no es tan clara. En pocas palabras, su objetivo es demostrar que esta implementación es equivalente a otra implementación de EVM escrita en Lean; esta última puede priorizar la claridad y legibilidad sin preocuparse por la eficiencia de ejecución específica.
Por supuesto, teóricamente aún podría darse el caso de que tengamos diez implementaciones de EVM, todas probadas como equivalentes entre sí, pero que compartan un defecto fatal común que, de alguna manera, permita a un atacante transferir todo el ETH desde una dirección que no controlan. Pero la probabilidad de que esto ocurra es mucho menor que la de que una implementación individual de EVM hoy en día tenga ese defecto. Otra propiedad de seguridad cuya importancia realmente apreciamos después de experiencias dolorosas, la resistencia a DoS, es relativamente fácil de especificar claramente.
Otras dos direcciones importantes son:
Consenso tolerante a fallas bizantinas. En esta dirección, tampoco es fácil definir formalmente todas las propiedades de seguridad deseadas. Pero dado que los errores relacionados han sido muy comunes, vale la pena intentar la verificación formal. Por lo tanto, ya hay trabajos en curso sobre implementaciones de consenso en Lean y sus pruebas.
Lenguajes de programación para contratos inteligentes. Los ejemplos incluyen trabajos de verificación formal en Vyper y Verity.
En todos estos casos, un gran valor agregado de la verificación formal es que estas pruebas son verdaderamente de extremo a extremo. Muchos de los errores más difíciles suelen ser errores de interacción, que ocurren en los límites entre dos subsistemas considerados por separado. Para los humanos, razonar sobre todo el sistema de extremo a extremo es demasiado difícil; pero los sistemas de verificación automática de reglas pueden hacerlo.
Verificación formal orientada a la eficiencia
Volvamos a evm-asm. Es una implementación de EVM.
Pero es una implementación de EVM escrita directamente en lenguaje ensamblador RISC-V.
Literalmente, ensamblador.
Aquí está el opcode ADD:
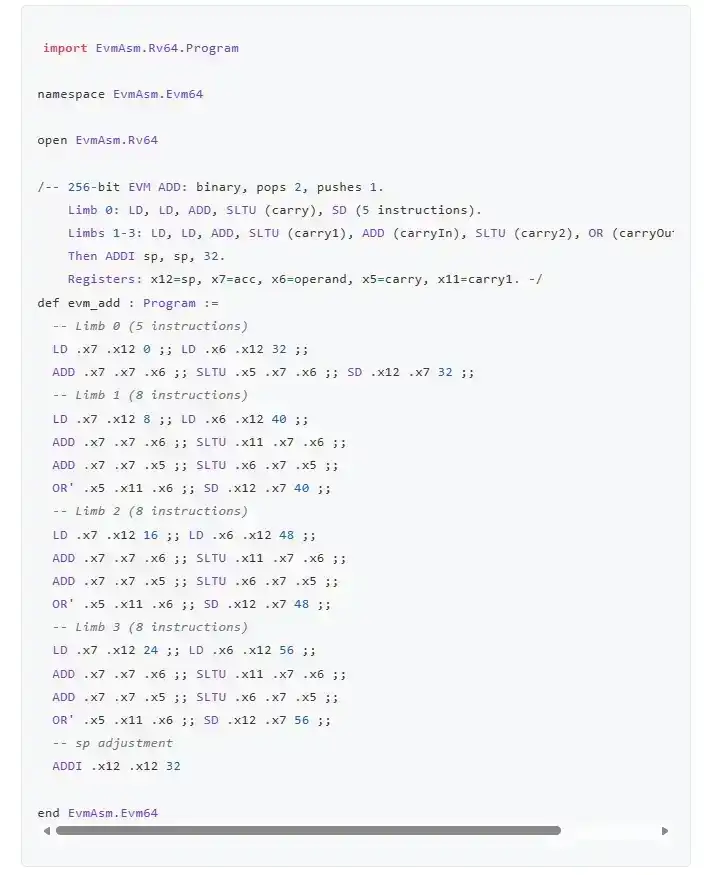
La razón para elegir RISC-V es que los verificadores de ZK-EVM que se están construyendo actualmente suelen funcionar probando RISC-V y compilando clientes de Ethereum en RISC-V. Por lo tanto, si escribes directamente una implementación de EVM en RISC-V, en teoría debería ser la implementación más rápida que puedas obtener. RISC-V también puede ser emulado de manera muy eficiente en computadoras ordinarias, y ya existen computadoras portátiles RISC-V. Por supuesto, para lograr un verdadero extremo a extremo, también debes verificar formalmente la implementación de RISC-V en sí, o la representación aritmetizada del verificador. Pero no te preocupes, ese tipo de trabajo también existe.
Escribir código directamente en ensamblador era algo que hacíamos hace cincuenta años. Desde entonces, hemos pasado gradualmente a escribir código en lenguajes de alto nivel. Los lenguajes de alto nivel sacrifican cierta eficiencia, pero a cambio, permiten escribir código mucho más rápido y, lo que es más importante, también permiten entender el código de otras personas mucho más rápido, lo cual es necesario para la seguridad.
Con la combinación de verificación formal e IA, tenemos la oportunidad de "volver al futuro". Específicamente, dejar que la IA escriba el código ensamblador, y luego escribir pruebas formales para verificar que este código ensamblador tiene las propiedades que queremos. Al menos, esta propiedad objetivo puede ser simplemente: es completamente equivalente a una implementación escrita en un lenguaje de alto nivel amigable para los humanos, optimizada para la legibilidad.
De esta manera, ya no se necesita un solo objeto de código que equilibre legibilidad y eficiencia. Tendríamos dos objetos separados: una implementación en ensamblador, optimizada solo para la eficiencia y adaptada a los requisitos del entorno de ejecución específico; y una afirmación de seguridad, o implementación en lenguaje de alto nivel, optimizada solo para la legibilidad. Luego, usamos una prueba matemática para demostrar la equivalencia entre los dos. Los usuarios pueden verificar automáticamente esta prueba una vez; después de eso, solo necesitan ejecutar la versión rápida.
Esto es muy poderoso. No es sin razón que Yoichi Hirai lo llame "la forma final del desarrollo de software".
La verificación formal no es una panacea
En criptografía y ciencias de la computación, hay una tradición casi tan antigua como los métodos formales mismos: criticar los métodos formales, o más ampliamente, criticar la dependencia en "pruebas". Hay muchos casos prácticos en la literatura. Comencemos con las pruebas escritas a mano más simples de los primeros días de la criptografía. Menezes y Koblitz las criticaron en 2004:
En 1979, Rabin propuso una función de cifrado que era "demostrablemente" segura en cierto sentido, es decir, tenía una propiedad de seguridad de reducción.
La afirmación de seguridad de reducción es: cualquier persona que pueda encontrar el mensaje m del texto cifrado y también debe poder factorizar n.
Poco después de que Rabin propusiera su esquema de cifrado, Rivest señaló que, irónicamente, la misma característica que le daba seguridad adicional también causaría que el sistema colapsara completamente frente a otro tipo de atacante. Este tipo de atacante se conoce como atacante de "texto cifrado elegido". Específicamente, supongamos que un atacante puede engañar a Alice de alguna manera para que descifre un texto cifrado elegido por el atacante. Entonces, el atacante puede factorizar n siguiendo el mismo proceso que usó Sam en el párrafo anterior.
Menezes y Koblitz luego dieron varios ejemplos más. Juntos, muestran un patrón: diseñar protocolos criptográficos en torno a lo que es "más fácil de probar" a menudo hace que los protocolos sean menos "naturales" y más propensos a colapsar en escenarios que el diseñador ni siquiera consideró.
Ahora, volvamos a las pruebas verificables por máquina y al código. Aquí hay un ejemplo de un artículo de 2011, donde los autores encontraron un error en un compilador de C verificado formalmente:
El segundo problema que encontramos en CompCert, que se manifiesta en dos errores, genera código como este: stwu r1, -44432(r1)
Aquí se está asignando un gran marco de pila de PowerPC. El problema es que el campo de desplazamiento de 16 bits desborda. La semántica PPC de CompCert no especifica esta restricción en el ancho del valor inmediato, porque asume que el ensamblador detectará valores fuera de rango.
Otro artículo de 2022:
En CompCert-KVX, el commit e2618b31 corrigió un error: la instrucción "nand" se imprimiría como "and"; y "nand" solo se seleccionaría en el raro modo ~(a & b). Este error se descubrió al compilar programas generados aleatoriamente.
Hoy, en 2026, Nadim Kobeissi, al describir vulnerabilidades en software verificado formalmente en Cryspen, escribió:
En noviembre de 2025, Filippo Valsorda informó de forma independiente que libcrux-ml-dsa v0.0.3 generaba claves públicas y firmas diferentes en diferentes plataformas dadas las mismas entradas deterministas. Este error estaba en el contenedor de la función intrínseca _vxarq_u64, que implementa la operación XAR utilizada en la permutación Keccak-f de SHA-3. La ruta de respaldo pasaba parámetros incorrectos a la operación de desplazamiento, lo que provocaba que los resúmenes SHA-3 se corrompieran en plataformas ARM64 sin soporte de hardware SHA-3. Este es un fracaso de Tipo I: la función intrínseca estaba marcada como verificada, y todo el backend NEON no tenía pruebas de seguridad o corrección en tiempo de ejecución completas.
Y también:
El crate libcrux-psq implementa un protocolo de clave precompartida poscuántica. En el método decrypt_out, la ruta de descifrado AES-GCM 128 llama a .unwrap() en el resultado del descifrado en lugar de continuar transmitiendo el error. Un texto cifrado mal formado puede hacer que el proceso falle.
Estos cuatro problemas pueden clasificarse en dos categorías:
Primera categoría: solo se verifica parte del código, porque verificar el resto es demasiado difícil; y resulta que el código no verificado es más propenso a errores de lo que los autores pensaban, y estos errores a menudo son más críticos.
Segunda categoría: los autores olvidaron especificar claramente una propiedad clave que necesitaba ser probada.
El artículo de Nadim clasifica los modos de fallo de la verificación formal; también enumera otros tipos de fallos. Por ejemplo, otro tipo principal es: la especificación formal en sí está equivocada, o la prueba contiene una afirmación errónea que el sistema de construcción acepta silenciosamente.
Finalmente, también podemos observar fallos de verificación formal en el límite entre software y hardware. Un problema común aquí es verificar si un sistema puede resistir ataques de canales laterales. Incluso si proteges un mensaje con un cifrado teóricamente completamente seguro, si alguien a unos metros de distancia puede capturar fluctuaciones eléctricas y extraer tu clave privada después de cientos de miles de cifrados, aún no estás seguro.
El "análisis diferencial de potencia" (differential power analysis) es un ejemplo de esta técnica, ahora bien entendido.
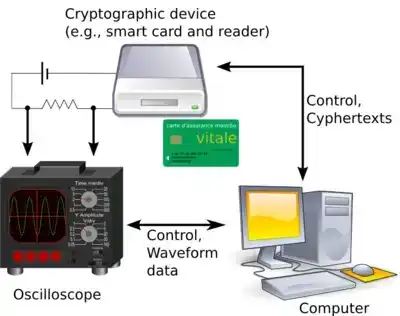
El análisis diferencial de potencia es un ataque de canal lateral común. Fuente: Wikipedia
En el pasado, también se han intentado pruebas de que los sistemas pueden resistir a este tipo de atacantes. Sin embargo, cualquier prueba de este tipo requiere algún tipo de modelo matemático del atacante, y luego puedes probar la seguridad bajo ese modelo. A veces, las personas usan el "modelo de sondeo d" (d-probing model): es decir, suponer que hay un límite superior conocido en la cantidad de ubicaciones en el circuito que el atacante puede sondear. Pero el problema es que algunas formas de fuga no son capturadas por este modelo.
Un problema común observado en este artículo es la fuga de transición (transitional leakage): si la señal que observas no depende del valor específico en una ubicación, sino del cambio en ese valor, entonces, en muchos casos, puedes recuperar la información necesaria de la diferencia entre dos valores, el antiguo y el nuevo, en lugar de depender solo de un valor. El artículo también clasifica otras formas de fuga.
A lo largo de las décadas, estas críticas a la verificación formal, a su vez, han ayudado a que la verificación formal mejore. En comparación con el pasado, ahora somos más cautelosos con este tipo de problemas. Pero incluso hoy, todavía no es perfecto.
Si tomamos perspectiva, en realidad hay un hilo común: la verificación formal es poderosa. Pero por mucho que el marketing la presente como algo que puede traer "corrección demostrable", la llamada "corrección demostrable" fundamentalmente no prueba que el software, o el hardware, sean "correctos" en el sentido verdadero.
Para la mayoría de las personas, "correcto" significa más o menos: esta cosa se comporta de acuerdo con la comprensión que el usuario tiene de la intención del desarrollador.
Y "seguro" significa más o menos: esta cosa no se desvía de las expectativas del usuario de una manera que perjudique sus intereses.
En ambos casos, la corrección y la seguridad finalmente se reducen a una comparación: por un lado, un objeto matemático; por el otro, la intención o expectativa humana. Técnicamente, la intención y la expectativa humana también son objetos matemáticos, después de todo, el cerebro humano es parte del universo, y el universo sigue las leyes de la física; con suficiente poder de cómputo, teóricamente podrías simularlos. Pero son objetos matemáticos extremadamente complejos que ni las computadoras ni nosotros mismos podemos realmente comprender, ni siquiera leer. Para propósitos prácticos, podemos tratarlos como cajas negras. La única razón por la que tenemos alguna comprensión de nuestras propias intenciones y expectativas es porque cada uno de nosotros tiene años de experiencia observando nuestros propios pensamientos e inferiendo los pensamientos de los demás.
Y precisamente porque no podemos introducir la intención humana cruda directamente en una computadora, la verificación formal no tiene forma de probar la comparación entre un sistema y la intención humana. Por lo tanto, la "corrección demostrable" y la "seguridad demostrable" en realidad no prueban la "corrección" y la "seguridad" que los humanos entienden, y hasta que podamos simular cerebros humanos, no hay forma de hacerlo realmente.
Entonces, ¿para qué sirve realmente la verificación formal?
Tiendo a ver los conjuntos de pruebas, los sistemas de tipos y la verificación formal como diferentes implementaciones del mismo método de seguridad de lenguaje de programación subyacente, y probablemente la única manera que realmente tiene sentido. Lo que tienen en común es: expresar nuestra intención de maneras redundantes, y luego verificar automáticamente si estas diferentes expresiones son compatibles entre sí.
Por ejemplo, mira este código de Python:

Aquí, expresas tu intención de tres maneras diferentes:
Primera, expresión directa: mediante la implementación del código de la fórmula de Fibonacci.
Segunda, expresión indirecta: a través del sistema de tipos, indicando que las entradas, salidas y pasos intermedios en la recursión son enteros.
Tercera, adoptando un método de "paquete de casos": es decir, casos de prueba.
Al ejecutar este archivo, el sistema usará estos ejemplos para verificar si la fórmula se cumple. El verificador de tipos puede verificar si los tipos son compatibles: sumar dos enteros es una operación válida y producirá otro entero. Los sistemas de tipos también suelen ser útiles en física computacional: si estás calculando la aceleración pero obtienes un resultado en m/s en lugar de m/s², sabes que algo salió mal. Y las definiciones de tipo "paquete de casos", de las cuales los casos de prueba son un ejemplo, a menudo se alinean más con la forma en que los humanos procesan conceptos que las definiciones directas y explícitas.
Cuantas más formas diferentes tengas de expresar tu intención, mejor; idealmente, estas formas deberían ser lo suficientemente diferentes como para obligarte a abordar el mismo problema de diferentes maneras. De esta manera, si todas estas expresiones finalmente resultan ser compatibles entre sí, la probabilidad de que realmente hayas expresado lo que querías expresar es mayor.
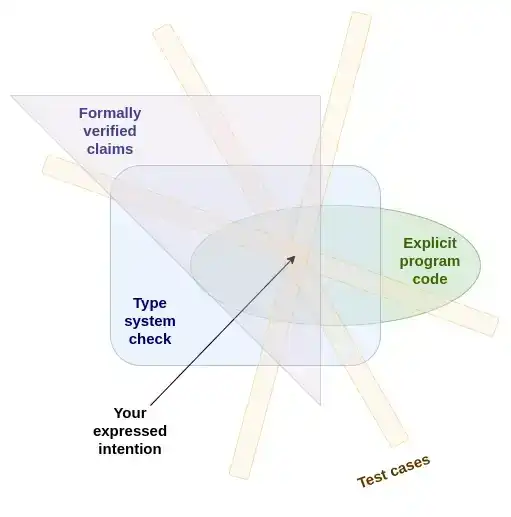
El núcleo de la programación segura es expresar tu intención de múltiples maneras diferentes y luego verificar automáticamente si estas expresiones son compatibles entre sí.
La verificación formal puede llevar este método aún más lejos. Con la verificación formal, casi puedes describir tu intención con tantas formas redundantes como quieras; solo cuando todas estas descripciones sean compatibles entre sí, el programa pasará la verificación.
Puedes escribir simultáneamente una implementación optimizada y una implementación ineficiente pero fácil de leer para humanos, y luego verificar si las dos son consistentes. También puedes pedirle a diez amigos que enumeren las propiedades matemáticas que creen que el programa debería satisfacer, y luego verificar si el programa las satifica todas; si no pasa, puedes determinar si el programa está equivocado o si la propiedad matemática en sí es incorrecta. Y la IA puede hacer que todo este trabajo sea extremadamente eficiente.
Entonces, ¿cómo empiezo?
De manera realista, es probable que no escribas pruebas tú mismo. La razón fundamental por la que los métodos formales nunca se han generalizado realmente es que a la mayoría de las personas les resulta difícil entender cómo escribir estas malditas pruebas.
¿Puedes decirme qué significa este código?
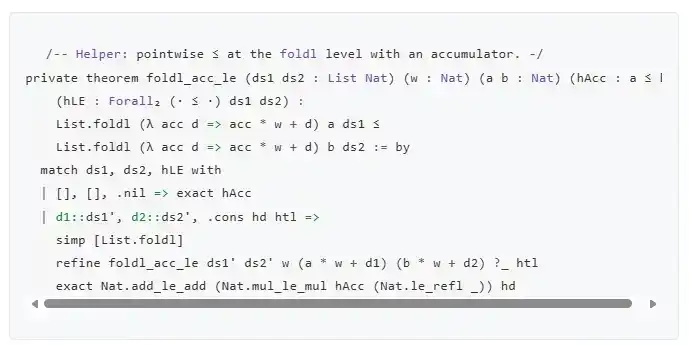
(Si tienes curiosidad, es uno de los muchos sublemas en una prueba. Esta prueba es para una afirmación de seguridad específica de una variante de la firma SPHINCS: es decir, a menos que ocurra una colisión de hash, generar una firma para un mensaje en particular, en comparación con la firma de cualquier otro mensaje, requiere al menos usar un valor más alto en una cadena de hash particular. Por lo tanto, la información que necesita no se puede calcular a partir de otra firma).
No necesitas escribir el código y las pruebas a mano, sino dejar que la IA escriba el programa por ti, directamente en Lean si quieres, o en ensamblador si buscas velocidad, y en el proceso probar todas las propiedades que deseas.
Una ventaja de esta tarea es que es inherentemente autoverificable, por lo que no necesitas vigilarla constantemente. Puedes dejar que la IA se ejecute por sí sola durante horas seguidas. Lo peor que puede pasar es que se quede atascada sin progresar, o que, como hizo mi Leanstral una vez, simplemente reemplace la declaración que se le pidió probar para facilitar su trabajo.
Lo que finalmente necesitas verificar es: si la proposición que probó es realmente lo que querías probar.
En esta variante de firma SPHINCS, la declaración final es la siguiente:

Esto en realidad está al borde de ser "legible":
Si el número generado por un resumen de hash (dig1) no es igual al número generado por otro resumen de hash (dig2), entonces la siguiente afirmación no es cierta:
Para todos los números, cada dígito de dig1 es menor o igual que el dígito correspondiente de dig2;
Para todos los números, cada dígito de dig2 es menor o igual que el dígito correspondiente de dig1.
Aquí se comparan los "dígitos extendidos" (wotsFullDigits) generados después de agregar una suma de verificación (checksum). Es decir, inevitablemente, en algunas posiciones, los dígitos extendidos de dig1 serán más altos; y en otras posiciones, los dígitos extendidos de dig2 serán más altos.
En cuanto a escribir pruebas con modelos de lenguaje grande, he encontrado que Claude ya es lo suficientemente bueno, y DeepSeek 4 Pro también es competente. Leanstral es una alternativa prometedora: es un modelo más pequeño, de pesos abiertos, ajustado específicamente para escribir en Lean. Tiene 119 mil millones de parámetros, pero solo activa 6 mil millones de parámetros por token, por lo que puede ejecutarse localmente, aunque lentamente, en mi computadora portátil, aproximadamente 15 tokens por segundo.
Según los puntos de referencia, Leanstral supera a muchos modelos generales mucho más grandes:
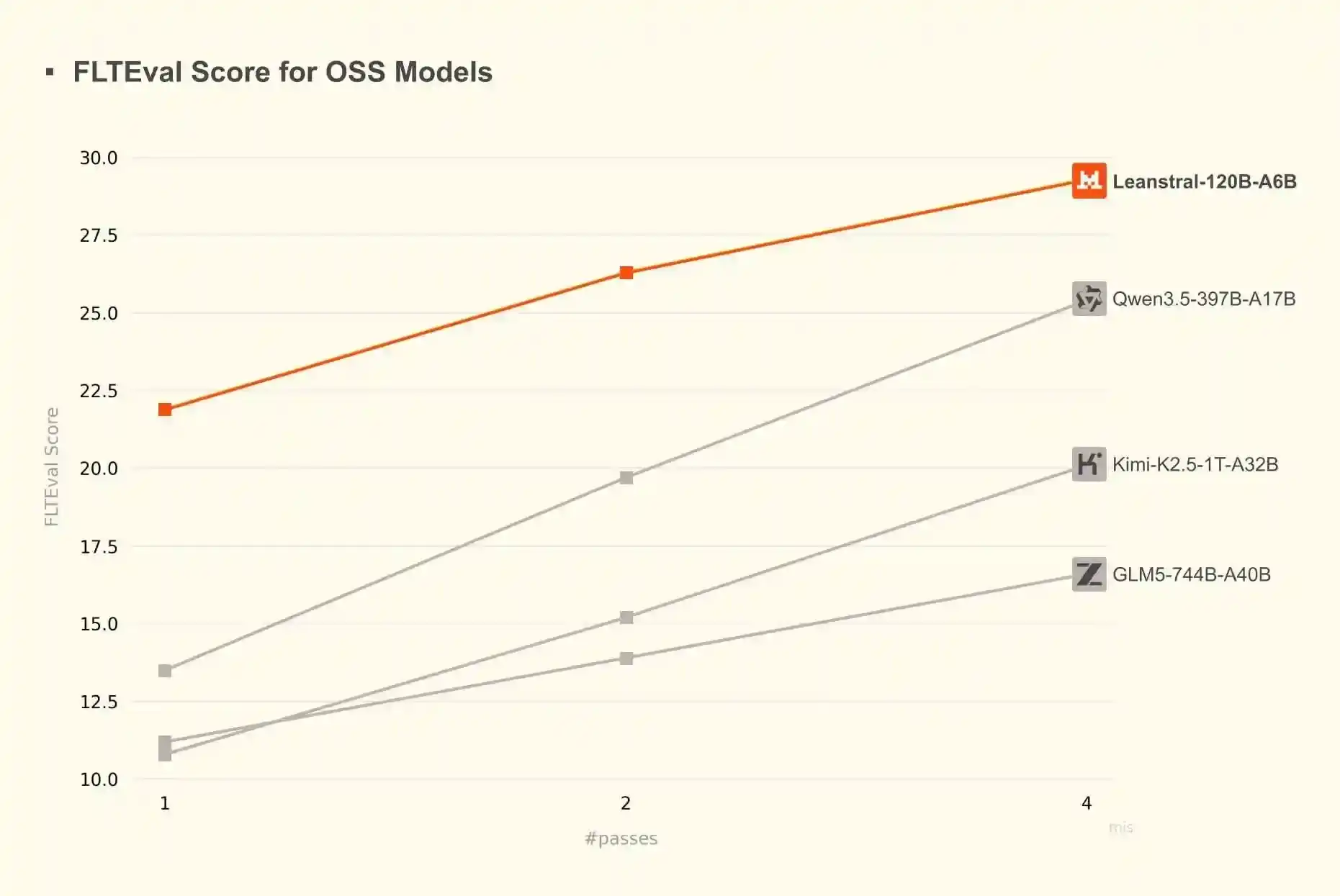
Según mi experiencia personal actual, es ligeramente más débil que DeepSeek 4 Pro, pero aún efectivo.
La verificación formal no resolverá todos nuestros problemas. Pero si queremos establecer un modelo de seguridad en Internet en lugar de que todos confíen en unas pocas organizaciones poderosas, entonces necesitamos poder confiar en el código, incluso frente a adversarios de IA poderosos. La verificación formal asistida por IA puede darnos un paso importante en esa dirección.
Al igual que blockchain y ZK-SNARKs, la IA y la verificación formal también son tecnologías altamente complementarias.
Blockchain trae verificabilidad abierta y resistencia a la censura a costa de privacidad y escalabilidad; y ZK-SNARKs devuelven la privacidad y la escalabilidad, de hecho, incluso más fuertes que antes.
La IA te permite escribir código a gran escala, pero a costa de una menor precisión; y la verificación formal devuelve la precisión, de hecho, también más fuerte que antes.
Por defecto, la IA generará una gran cantidad de código muy deficiente, y el número de errores también aumentará. De hecho, en algunos escenarios, incluso es el equilibrio correcto permitir que aumenten los errores: si el impacto de estos errores es leve, entonces incluso el software defectuoso es mejor que no tener ese software. Pero aquí, aún existe un futuro optimista para la seguridad de la red: el software continuará dividiéndose en "componentes periféricos inseguros" alrededor de un "núcleo seguro".
Estos componentes periféricos inseguros se ejecutarán en sandboxes y solo tendrán los privilegios mínimos necesarios para realizar su tarea. El núcleo seguro se encargará de gestionarlo todo. Si el núcleo seguro falla, todo falla, tus datos personales, tu dinero y mucho más se verán afectados. Pero si un componente periférico inseguro falla, el núcleo seguro aún puede protegerte.
Cuando se trata del núcleo seguro, no permitiremos que el código con errores se multiplique sin control. Controlaremos activamente el tamaño del núcleo seguro, manteniéndolo lo suficientemente pequeño, incluso reduciéndolo aún más. En cambio, dirigiremos toda la capacidad adicional que brinda la IA hacia mejorar la seguridad del propio núcleo seguro, permitiéndole soportar la alta carga de confianza en una sociedad altamente digital.
El kernel de tu sistema operativo, o al menos parte de él, será uno de esos núcleos seguros. Ethereum será otro. Idealmente, al menos en todo el cómputo no intensivo en alto rendimiento, el hardware que uses será un tercer núcleo seguro. Algunos sistemas relacionados con IoT serán un cuarto.
Al menos en estos núcleos seguros, el viejo dicho—los errores son inevitables, solo puedes intentar encontrarlos antes que los atacantes—ya no será cierto. Será reemplazado por un mundo más prometedor: uno donde podemos lograr una verdadera seguridad.
Por supuesto, si estás dispuesto a confiar tus activos y datos a un software mal escrito que incluso podría enviarlos accidentalmente a un agujero negro, aún tendrás esa libertad.
Enlace al original







